vivo Pulsar 万亿级消息处理实践(4)-Ansible运维部署
作者:Liu Sikang、互联网大数据团队-Luo Mingbo
Pulsar作为下一代云原生架构的分布式消息中间件,存算分离的架构设计能有效解决大数据场景下分布式消息中间件老牌一哥"Kafka"存在的诸多问题,2021年vivo 分布式消息中间件团队正式开启对Pulsar的调研,2022年正式引入Pulsar作为大数据场景下的分布式消息中间件,本篇文章主要从Pulsar运维痛点、Ansible简介、Ansible核心模块详解、Ansible自动化部署zk集群、Ansible自动化部署Pulsar集群几个维度向大家介绍vivo Pulsar万亿级消息处理实践之运维部署。
注:本文是《vivo Pulsar万亿级消息处理实践》系列文章第4篇。
1分钟看图掌握核心观点👇
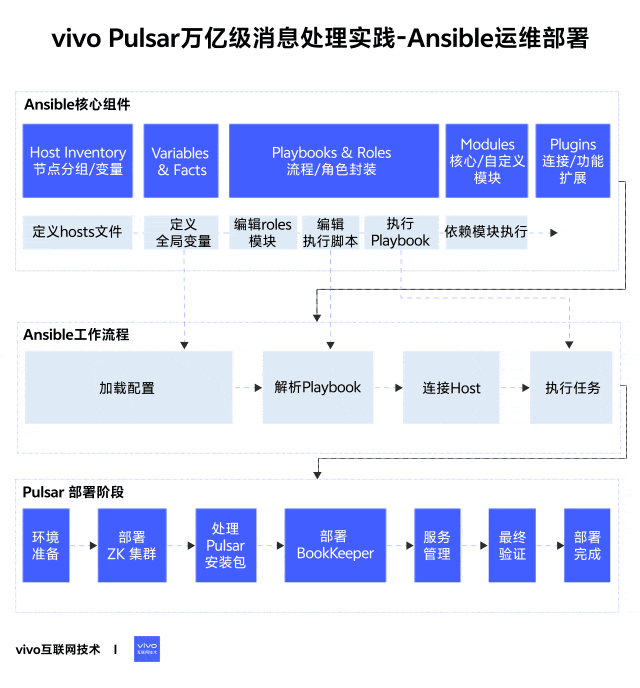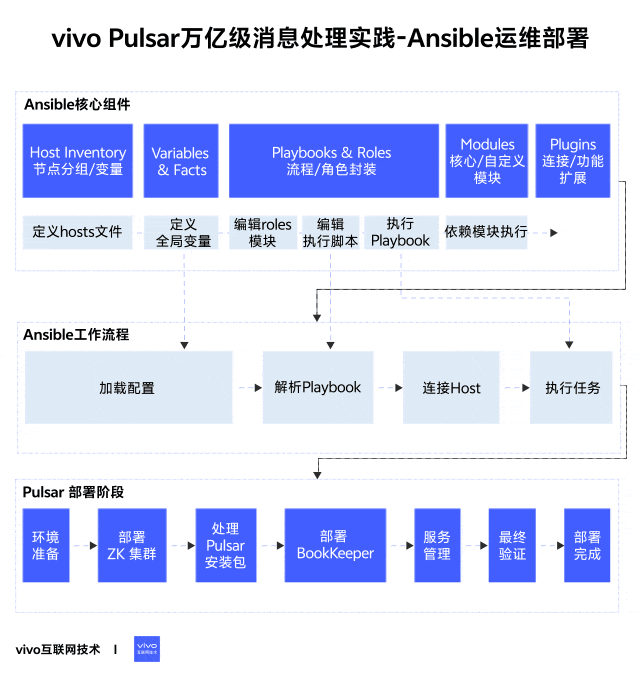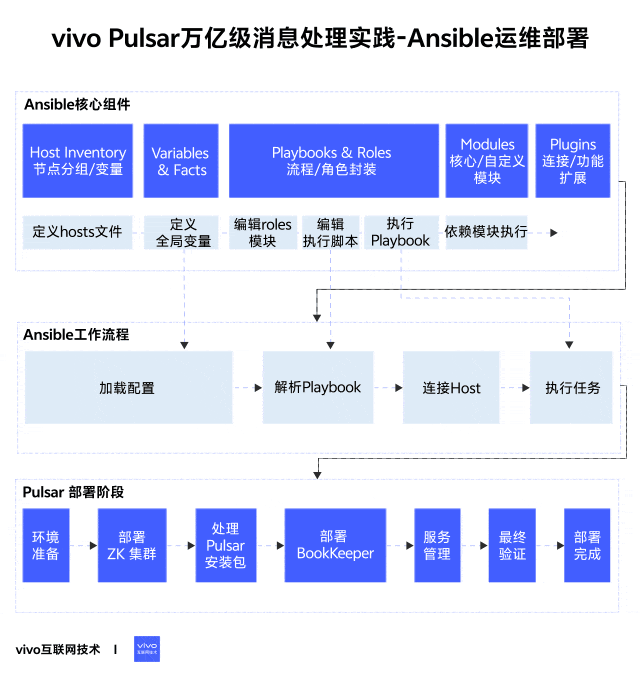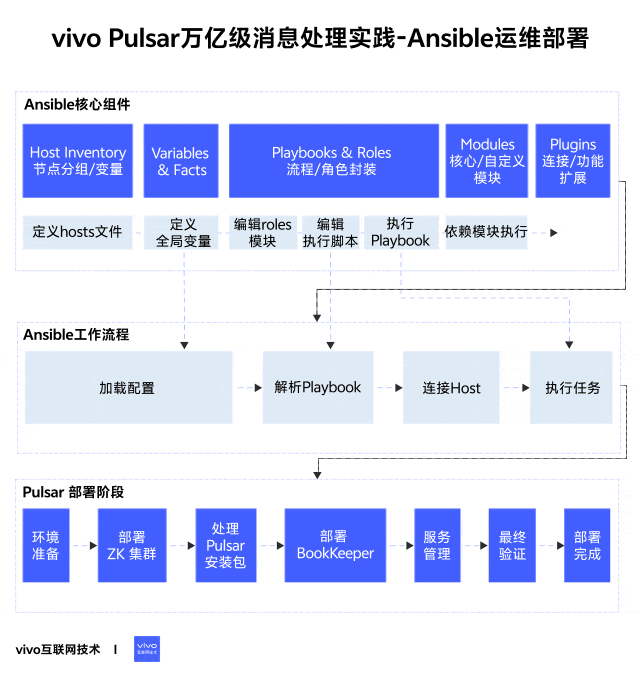
1、简介
1.1 Pulsar 运维面临的问题
新业务增长快,很多新业务接入需要搭建独立的集群或者资源组。
升级频次高,对于bug修复,配置更改以及依赖组件替换等,都需要对全集群进行升级、配置更改或组件替换。
人力投入大,在集群运维时,需要对公共的执行步骤进行批处理封装,否则会耗费大量人力在集群的部署和升级上。
1.2 什么是 Ansible Playbook
Asnible Playbooks是Ansible自动化工具的核心部分。它是基于YAML文件格式,用于在多个主机上执行的任务。通过在Playbook中设置变量、处理器、角色和任务标签等功能,可以大大提高自动化脚本的复用性和可维护性。可以理解为批处理任务。
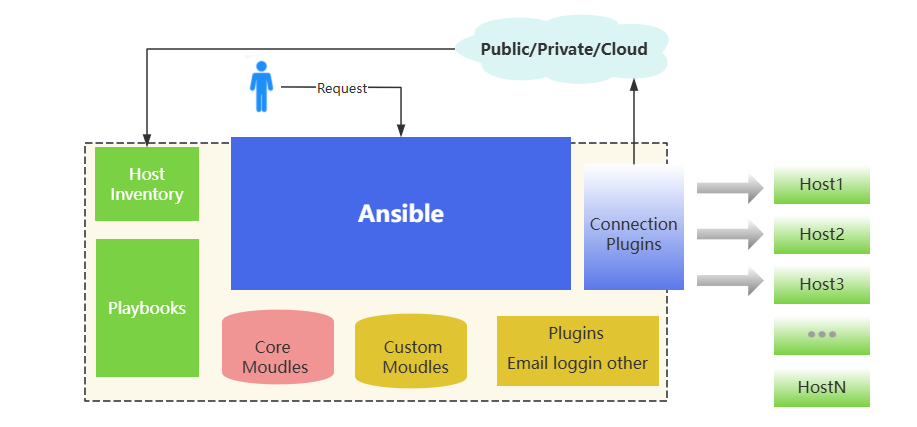
上图中我们看到Playbook的主要模块如下:
-
Ansible:Ansible 的核心程序。
-
HostInventory:记录由 Ansible 管理的主机信息,包括端口、密码、ip 等。
-
Playbooks:“剧本” YAML 格式文件,多个任务定义在一个文件中,定义主机需要调用哪些模块来完成的功能。
-
CoreModules:核心模块,主要操作是通过调用核心模块来完成管理任务。
-
CustomModules:自定义模块,完成核心模块无法完成的功能,支持多种语言。
-
ConnectionPlugins:连接插件,Ansible 和 Host 通信使用。
2、Playbook 语法
2.1 书写格式
playbook 常用到的YMAL格式:
-
文件的第一行应该以 “—” (三个连字符)开始,表明 YMAL 文件的开始。
-
在同一行中,# 之后的内容表示注释,类似于 shell,python 和 ruby。
-
YMAL 中的列表元素以 “-” 开头然后紧跟着一个空格,后面为元素内容。
-
同一个列表中的元素应该保持相同的缩进。否则会被当做错误处理。
-
play 中 hosts,variables,roles,tasks 等对象的表示方法都是键值中间以 “:” 分隔表示,“:” 后面还要增加一个空格。
以下是 Playbook 的基本语法书写格式:
- name: playbook的名称hosts: 目标主机或主机组 # 可以使用普通的 IP 地址或域名,也可以使用主机组名称remote_user: 远程用户 # 使用 SSH 登录远程主机时使用的用户名become: yes # 是否使用特权(例如 sudo)运行命令tasks: # Playbook 中的任务列表- name: 任务名称module_name: 参数 # Ansible 模块的名称和参数组成的字典,用于执行操作tags: # 与该任务相关的标记列表,用于执行特定的任务- 标签名称when: 条件 # 指定该任务在满足特定条件下才会被执行notify: 通知列表 # 指定依赖于该任务的另一个任务列表,当这个任务被执行后会自动触发这些任务
2.2 Tasks & Modules
在Ansible Playbook的语法中,
"Tasks"和"Modules"是两个核心概念。
Tasks(任务):Tasks是Playbook中的操作步骤或任务,它们定义了要在目标主机上执行的操作。可以在Playbook中定义一个或多个任务。Tasks按照顺序执行,并且可以有条件地执行或跳过。
Modules(模块):Modules提供了执行特定任务的功能单元。每个模块负责处理不同的操作,如管理文件、安装软件包、查询系统信息等。Ansible提供了许多内置模块,可以满足大多数常见的操作。
通过组合不同的模块和任务,可以构建复杂的Playbooks来执行各种操作和配置任务。
2.3 任务之间的依赖关系
在 Ansible 的 playbook 中,任务之间可以有依赖关系,你可以使用 dependencies 或者 notify 语句来定义。
2.3.1 使用 dependencies 定义任务依赖关系
如果任务 A 依赖任务 B 完成,可以使用 dependencies 定义任务依赖关系,语法如下:
- hosts: webtasks:- name: Install Nginxyum:name: nginxstate: present- name: Start Nginxservice:name: nginxstate: startedbecome: truedependencies:- Install Nginx
在上面的示例中,Start Nginx 任务在 Install Nginx 任务完成之后才会执行。如果在执行 Start Nginx 任务之前,Install Nginx 任务未完成或者执行失败,则 Start Nginx 任务也会失败。
2.3.2 使用 notify 定义任务依赖关系
如果任务 A 完成后需要通知任务 B 执行,可以使用 notify 定义任务依赖关系,语法如下:
- hosts: webtasks:- name: Install Nginxyum:name: nginxstate: presentnotify:-Start Nginx- name: Start Nginxservice:name: nginxstate: startedbecome: truelisten: Start Nginx
在上面的示例中,Install Nginx 任务完成后会通知 Start Nginx 任务执行。然后 Start Nginx 任务会通过 listen 参数监听,等待通知执行。
总之,Ansible 支持在 playbook 中定义任务之间的依赖关系。你可以使用 dependencies 或 notify 语句来定义任务之间的顺序和依赖关系。
2.4 条件判断
在Playbook中,可以使用when关键字来添加条件判断。when关键字后面跟一个条件表达式,如果表达式返回True,则任务会被执行;如果返回False,则任务会被跳过。
条件表达式可以使用Ansible的Jinja2模板来编写,例如:
tasks:- name: Install Apache if not installedpackage:name: apache2state: presentwhen: ansible_pkg_mgr == 'apt'
在这个例子中,如果ansible_pkg_mgr变量等于"apt",则安装Apache;否则跳过这个任务。
除了使用任务级别的条件判断,还可以使用Play级别的条件判断来控制整个Playbook的执行。这可以通过在Play的开始处添加when关键字来实现,例如:
- name: Deploy Web Apphosts: allvars:deploy_web_app: truetasks:- name: Install Dependenciesapt:name: "{{ item }}"state: presentwith_items:- python3- python3-pipwhen: deploy_web_app
在这个例子中,deploy_web_app变量的值为True时,才会执行任务Install Dependencies。如果deploy_web_app变量的值为False,则跳过整个Playbook的执行。
2.5 循环
在Playbook中,可以使用循环结构来遍历列表或其他可迭代对象,并对每个迭代项执行相同的任务。这可以使用Ansible的with_*系列模块来实现。
以下是一些常见的循环结构的示例:
2.5.1 使用with_items模块来遍历列表
tasks:- name: Install packagesapt:name: "{{ item }}"state: presentwith_items:- python3- python3-pip- git
在这个例子中,将依次安装python3、python3-pip和git。
3、Playbook 组织
3.1 Inclusions
在Playbook的组织中,include和import两个指令都可以用来将其他的yaml文件(也就是Tasks文件)包含到当前的Playbook中。
它们的区别在于,当主Playbook执行到include指令时,它将处理包含的文件中的所有任务,并且在处理完之后继续主Playbook的执行。而当主Playbook执行到import指令时,它只会处理被导入的文件中的变量定义,而不会处理任务,任务只有在需要的时候才会被引入执行。
下面是一个使用include指令包含其他文件的例子:
- hosts: webserverstasks:- name: Include web tasksinclude: web-tasks.yml
在这个例子中,主Playbook从web-tasks.yml文件中导入任务,并在执行完后继续执行余下的任务。
下面是一个使用import指令包含其他文件的例子:
- name: Load variablesimport_vars: vars.yml- name: Deploy web apphosts: webserverstasks:- name: Install dependenciesapt:name: "{{ item }}"state: presentwith_items:- python3- python3-pip- name: Deploy appinclude: app-tasks.yml
在这个例子中,在主Playbook中使用import_vars指令来导入变量定义,然后在每个任务中都可以使用这些变量。然后我们使用include指令从app-tasks.yml文件中包含任务,这些任务可以使用在vars.yml文件中定义的变量。这种方式可以在需要时懒加载任务,提高性能。
需要注意的是,在被引入的文件中,不能再次使用- hosts:指令定义新的主机组,因为Ansible只允许在主Playbook中定义主机组。被引入的文件只包含任务,任务必须使用被定义的主机组来指定目标主机。
3.2 Roles
Ansible的Roles是一种组织Playbook的方式,它将Playbook和相关的变量、模板和其他资源打包在一起,并且可以轻松地在Playbook中重用和分享。一个Role通常适用于一种操作或功能,比如安装和配置一个应用程序、部署Web服务、安装软件包等等。
一个Role目录通常包含以下文件和目录:
my-role/
├── README.md
├── defaults/
│ └── main.yml
├── files/
├── handlers/
│ └── main.yml
├── meta/
│ └── main.yml
├── tasks/
│ └── main.yml
├── templates/
├── tests/
│ ├── inventory
│ └── test.yml
└── vars/└── main.yml
-
README.md:Role的说明文档。
-
defaults/main.yml:默认变量定义文件。
-
files:包含角色使用的文件。
-
handlers/main.yml:Role的处理程序。
-
meta/main.yml:Role的元数据,例如角色名称、作者、依赖等。
-
tasks/main.yml:包含Role组成部分的主要任务。
-
templates:包含角色使用的Jinja2模板。
-
tests:Role的测试脚本。
-
vars/main.yml:包含Role的变量。
要使用Role,需要在Playbook中定义roles扩展,例如:
- hosts: webserversroles:- my-role
这将运行my-role目录中包含的所有任务。
通过使用Role,可以更好地组织和重复使用代码,并提高代码的可读性和可维护性。它还可以帮助您在Ansible社区中分享自己的工作,或从其他用户那里获得高质量的Roles。
3.3 引用/定义变量
在Playbook中,可以使用vars关键字来定义变量。例如:
vars:my_var: "Hello World"
这将定义一个名为my_var的变量,其值为字符串"Hello World"。
要在Playbook中访问这个变量,可以使用{{ my_var }}语法。例如:
tasks:- name: Print Messagedebug:msg: "{{ my_var }}"
除了在vars中定义变量,还可以通过set_fact模块来动态设置变量。例如:
tasks:- name: SetDynamic Variableset_fact:my_var: "{{ inventory_hostname }} is awesome"
3.4 使用插件和模板
Ansible提供了插件和模板的功能,使得在Playbook中使用动态内容变得更加简单和方便。
插件是一种可以扩展和定制Ansible功能的机制,可以在Playbook中调用和使用。常见的插件包括Action、Lookup、Filter、Callback等。使用插件和模板可以使Playbook更加具有可读性和可维护性,使得动态内容的生成更加灵活和方便。
4、服务安装与主机管理
4.1 安装服务器依赖
Playbook是Ansible的核心组件之一,用于定义和执行一系列任务。在使用Playbook之前,需要确保服务器上已经安装了Ansible和相关的依赖项。以下是安装服务器依赖的步骤:
4.1.1 安装Python3及其相关依赖项
sudo apt update
sudo apt-get install -y python3 python3-pip python3-dev build-essential libssl-dev libffi-dev
4.1.2 安装Ansible
sudo apt-add-repository ppa:ansible/ansible
sudo apt update
sudo apt-get install -y ansible
4.1.3 (可选)安装 git
sudo apt update
sudo apt-get install -y git
4.1.4 检查Ansible是否安装
ansible --version
这样,您的服务器就已经安装了所需的依赖项以及Ansible。如果您计划在多台服务器上使用Ansible,则需要在每台服务器上重复这些步骤。
4.2 配置远程服务器
在使用Playbook配置远程服务器之前,需要确保Ansible已经正确安装在本地机器上。然后,您需要做以下几个步骤:
4.2.1 创建inventory文件
创建新的inventory文件,用于定义您要配置的远程服务器的IP地址或域名。例如,您可以创建一个名为inventory的文件,并包含以下内容:
[webservers]
192.168.1.100
192.168.1.101[dbservers]
192.168.1.102
在此示例中,我们定义了两个组,webservers和dbservers,并列出了它们中每个服务器的IP地址。
4.2.2 编写Playbook
编写一个Playbook,用于在远程服务器上执行特定的任务。例如,您可以创建一个名为web.yml的Playbook,并包含以下内容:
- name: Install andstart Nginxhosts: webserversbecome: truetasks:- name: Install Nginxapt:name: nginxupdate_cache: yesstate: latest- name: Start Nginxservice:name: nginxstate: startedenabled: true
在这个Playbook示例中,我们定义了一个名为Install and start Nginx的任务,它会在webservers组中的服务器上启动Nginx服务器。
4.2.3 运行Playbook
运行Playbook,在远程服务器上执行配置任务。例如,要在远程服务器上运行示例中的web.yml Playbook,可以使用以下命令:
ansible-playbook -i inventory web.yml
在执行此命令后,Ansible将使用inventory文件中定义的远程服务器的IP地址,并执行web.yml Playbook中定义的任务。
这是一个基本的Playbook配置远程服务器的示例。需要根据具体的场景和任务需求来进行个性化配置和修改。
4.3 部署应用程序
Playbook部署应用程序一般步骤:
1、准备应用程序的部署包。这通常是一个.tar.gz或.zip文件,包含应用程序代码、依赖项和其他必要文件。
2、在目标主机上安装所需的依赖项和软件包。例如,在部署Python应用程序时,需要安装Python解释器、pip和其他依赖项。
3、创建一个目录用于应用程序的部署。这通常是在目标主机上的一个新目录,例如/home/user/myapp。
4、上传应用程序部署包到目标主机并解压缩。您可以使用copy模块将部署包部署到目标主机上。
5、配置应用程序的运行环境。例如,在部署Flask应用程序时,需要设置环境变量、安装必要的Python包等。
6、配置Web服务器以侦听应用程序的请求。例如,您可以使用Nginx或Apache等Web服务器来代理应用程序请求。
5、常用模块的 playbook 语法
-
file模块:可以管理文件系统中的文件和目录。下面是该模块的常用参数:
-
copy模块:可以将本地文件复制到远程服务器上。
-
unarchive模块:Ansible 中用于将压缩文件解压缩的模块。
-
apt模块:可以在Ubuntu或Debian系统上安装、升级、删除软件包。
-
service模块:可以在系统上管理服务。
-
user模块:可以管理系统用户。
-
shell模块:可以在远程服务器上运行基于命令行的任务。该模块只能运行命令,不能使用管道、重定向和通配符。
-
script模块:可以将本地脚本或可执行文件上传到远程服务器并在远程服务器上运行。该模块适用于运行复杂的命令和复杂的脚本。
-
template模块:可以将在Ansible中定义的Jinja2模板应用于远程服务器上的文件。在应用模板时,您可以使用变量来一次生成多个文件的不同版本。
-
lineinfile模块:可以从文件中添加、修改或删除单行文本。该模块可用于修改文件中的配置文件或语言文件,或添加新行。
-
blockinfile模块:可以在远程服务器文件中添加、修改或删除代码块。该模块可以替代lineinfile模块,以单个块更新文件。
-
debug模块:可以输出调试信息。该模块在编写Playbooks时非常有用,因为可以检查任务的变量和结果。
6、Ansible部署Pulsar集群运维实战
6.1 部署zookeeper集群
6.1.1 定义host文件
host 文件指定了要在哪些主机上执行任务。在 playbook 中,可以将 hosts 指定为一个变量,也可以通过 -i 参数指定一个主机清单文件,该文件包含要操作的主机列表。
[all:vars]
ansible_ssh_user=xxx
ansible_ssh_pass=xxx[zk]
127.xxx.xxx.1 myid=1
127.xxx.xxx.2 myid=2
127.xxx.xxx.3 myid=3
127.xxx.xxx.4 myid=4
127.xxx.xxx.5 myid=5
6.1.2 定义变量
group_vars 目录用于存放针对不同主机组的变量文件,其中 all 文件是一种特殊的变量文件,它包含了全局的变量定义,将适用于所有主机组。路径结构如下:
group_vars/
├── all
在all文件中,我们可以定义安装路径、JDK版本为、zookeeper版本以及zookeeper相关的配置信息。比如:
inst_home: /opt/bigdata/inst
app_home: /opt/bigdata/app
zk_inst_home: zookeeper-3.6.3
zk_app_home: zookeeper
jdk_inst_home: jdk1.8.0_192
jdk_app_home: jdk
jdk_tgz: jdk1.8.0_192.tar.gz
zk_tgz: zookeeper-3.6.3.tar.gzcluster_name=clusterName
client_port=2181
server_port1=2881
server_port2=2882
jmx_port=9012
admin_port=18080
dataDir="/data/bigdata/zookeeper_{{cluster_name}}/zkDataDir"
dataLogDir="/data/bigdata/zookeeper_{{cluster_name}}/zkDataLogDir"
zoo_log_dir="/opt/bigdata/inst/zookeeper-3.6.3-{{cluster_name}}/logs/"
6.1.3 编辑roles模块
① check_port:检查端口
判断配置的端口是否被占用,如果被占用,则不能执行后续的步骤。
目录结构如下:
check_port/
├── tasks/
│ └── main.yml
main.yml
#循环检查端口是否是停用状态
- name: Check portwait_for:host: "{{ inventory_hostname }}"port: "{{ item }}"delay: 2timeout: 3state: stoppedregister: resultwith_items:- "{{ client_port }}"- "{{ server_port1 }}"- "{{ server_port2 }}"- "{{ jmx_port }}"- "{{ admin_port }}"- name: print resultdebug:msg: "Port {{ item.item }} is {{ item.state }}"with_items: "{{ result.results }}"
② dispatch_zk:分发安装包
目录结构如下:
dispatch_zk/
├── files/
│ └── zookeeper-3.6.3.tar.gz
├── tasks/
│ └── main.yml
files:放zookeeper安装包文件。
main.yml
#分发zk安装包并解压到/tmp路径下
- name: dispatch_zkunarchive:src: "{{zk_tgz}}"dest: "/tmp"mode: 755owner: rootgroup: root
③ config_zk:配置zookeeper
目录结构如下:
config_zk/
├── tasks/
│ └── main.yml
├── templates/
│ └── zoo.cfg
main.yml
#zoo.cfg模板文件应用到指定的路径下
- name: zoo.cfgtemplate:src: zoo.cfgdest: "{{ app_home }}/zk-{{ cluster_name }}/conf"
#创建zoo_log_dir目录
- name: mkdir forlogshell: mkdir -p "{{zoo_log_dir}}"#创建zk数据目录
- name: mkdir for dataDirshell: mkdir -p "{{dataDir}}"#创建zk日志目录
- name: mkdir for dataLogDirshell: mkdir -p "{{dataLogDir}}"#myid文件中输入每台主机的编号
- name: myid fileshell: echo "{{myid}}" > {{dataDir}}/myid
zoo.cfg:zookeeper配置文件模板。
tickTime=2000
initLimit=10
syncLimit=5
maxClientCnxns=65535
autopurge.snapRetainCount=30
autopurge.purgeInterval=48
clientPort={{client_port}}
admin.serverPort={{admin_port}}
dataDir={{dataDir}}
dataLogDir={{dataLogDir}}
{% for host in groups.zk%}
server.{{ hostvars[host]['myid'] }}={{host}}:{{server_port1}}:{{server_port2}}
{% endfor %}
④ deploy_zk:部署zookeeper服务
目录结构如下:
deploy_zk/
├── files/
│ └── env.sh
│ └── jdk1.8.0_192.tar.gz
├── tasks/
│ └── main.yml
env.sh:jdk环境变量配置
JAVA_HOME=/opt/bigdata/app/jdk
JRE_HOME=$JAVA_HOME/jre
PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib/rt.jar:$CLASSPATH
main.yml
#创建/opt/bigdata/inst目录
- name: mkdir for inst_homeshell: mkdir -p {{ inst_home }}#创建/opt/bigdata/app目录
- name: mkdir for app_homeshell: mkdir -p {{ app_home }}#注册zk_dir变量
- name: stat_dirstat: path={{ inst_home }}/{{zk_inst_home}}-{{cluster_name}}register: zk_dir#当zk_dir存在时,将/tmp路径安装包移到指定目录并重命名
- name: rename zookeeper dircommand: mv /tmp/{{zk_inst_home}} {{ inst_home }}/{{zk_inst_home}}-{{cluster_name}}when: zk_dir.stat.exists == False#创建zk集群软连接
- name: soft linkfile:path: "{{ app_home }}/zk-{{ cluster_name }}"src: "{{ inst_home }}/{{ zk_inst_home }}-{{ cluster_name }}"state: link#分发并解压jdk安装包
- name: deploy jdkunarchive:src: "{{ jdk_tgz }}"dest: "{{ inst_home }}"#创建jdk软连接
- name: create soft link for jdkfile:path: "{{ app_home }}/{{ jdk_app_home }}"src: "{{ inst_home }}/{{ jdk_inst_home }}"state: link#运行jdk环境变量,使其生效
- name: envscript: env.sh
⑤ start_zk:启动zookeeper服务
目录结构如下:
start_zk/
├── tasks/
│ └── main.yml
main.yml
#启动zk服务
- name: start zookeepershell: cd {{ app_home }}/zk-{{cluster_name}}; sh bin/zkServer.sh start
6.1.4 编辑任务执行和启动脚本
zookeeper.yml:任务执行脚本
---
- name: check_porthosts: zkremote_user: rootroles:- check_porttags: check_port- name: dispatch_zkhosts: zkremote_user: rootroles:- dispatch_zktags: dispatch_zk- name: deploy_zkhosts: zkremote_user: rootroles:- deploy_zktags: deploy_zk- name: config_zkhosts: zkremote_user: rootroles:- config_zktags: config_zk- name: start_zkhosts: zkremote_user: rootroles:- start_zktags: start_zk
6.1.5 部署并启动zookeeper服务
# 部署并启动zookeeper服务
ansible-playbook -i hosts-clusterName zookeeper.yml#只检查端口和分发安装包
ansible-playbook -i hosts-clusterName zookeeper.yml --tags "check_port,dispatch_packages"
6.2 部署Pulsar集群
6.2.1 定义hosts文件
[all:vars]
ansible_ssh_user=xxx
ansible_ssh_pass=xxx[pulsar]
127.xxx.xxx.1
127.xxx.xxx.2
127.xxx.xxx.3
127.xxx.xxx.4
127.xxx.xxx.5
6.2.2 定义全局变量
group_vars 目录用于存放针对不同主机组的变量文件,其中 all 文件是一种特殊的变量文件,它包含了全局的变量定义,将适用于所有主机组。路径结构如下:
group_vars/
├── all
all文件内容中定义变量信息,如下:
bigdata_home: /opt/bigdata
inst_home: /opt/bigdata/inst
app_home: /opt/bigdata/app
pulsar_app_home: pulsar
pulsar_inst_home: apache-pulsar-2.9.2-1.3
pulsar_tgz: apache-pulsar-2.9.2-1.3-bin.tar.gz
pulsar_conf: "{{ app_home }}/pulsar/conf"
secret_key_dir: "{{ app_home }}/pulsar/data"#bookkeeper.conf
ledgerDirectories: /data1/bookkeeper/ledger,/data2/bookkeeper/ledger,/data3/bookkeeper/ledger,/data4/bookkeeper/ledger#broker.conf or client.conf
zkServers: "127.xxx.xxx.1:2183,127.xxx.xxx.2:2183,127.xxx.xxx.3:2183/clusterName"
clusterName: wenzhu
webServiceUrl: http://clusterNamexxxx:8080
brokerServiceUrl: pulsar://clusterNamexxxx:6650
6.2.3 编辑roles模块
① dispatch_pulsar:分发安装包
目录结构如下:
dispatch_pulsar/
├── files/
│ └── apache-pulsar-2.9.2-1.3-bin.tar.gz
├── tasks/
│ └── main.yml
main.yml
#创建inst_home定义的目录
- name: mkdir_inst_homefile:path: "{{ inst_home }}"state: directory#创建app_home定义的目录
- name: mkdir_app_homefile:path: "{{ app_home }}"state: directory#分发并解压pulsar安装包到指定目录
- name: dispatch_packagesunarchive:src: "{{ pulsar_tgz }}"dest: "{{ inst_home }}"#创建pulsar软连接
- name: soft_linkfile:path: "{{ app_home }}/pulsar"src: "{{ inst_home }}/{{ pulsar_inst_home }}"state: link
② check_nar:校验分层存储和kop扩展的依赖包
目录结构如下:
check_nar/
├── tasks/
│ └── main.yml
main.yml
#匹配指定路径protocols和offloaders下是否有nar后缀的文件
- name: check narfind:paths: "{{ app_home }}/pulsar/{{ item }}/"patterns: "*.nar"register: resultwith_items:- "offloaders"- "protocols"#设置文件匹配的结果(大于0表示文件存在)
- name: set nar_files_exist variableset_fact:nar_files_exist_{{item.item}}: "{{ item.matched > 0 }}"with_items: "{{ result.results }}"#如果文件不存在,进行提示
- name: nar files not existfail:msg: "{{ item.item }} nar files not found"when: nar_files_exist_{{ item.item }} == falseignore_errors: truewith_items: "{{ result.results }}"#如果文件存在,列出存在的文件名
- name: print nar files listdebug:msg: "{{ item.files | map(attribute='path') | list }}"when: nar_files_exist_{{item.item}}with_items: "{{ result.results }}"
③ config_pulsar:配置pulsar
目录结构如下:
config_pulsar/
├── tasks/
│ └── main.yml
├── templates/
│ └── bkenv.sh
│ └── pulsar_env.sh
main.yml
#匹配broker.conf中的advertisedAddress值并设置为远程主机ip地址
- name: config_advertisedAddresslineinfile:path: "{{ pulsar_conf }}/broker.conf"regexp: "^advertisedAddress="line: "advertisedAddress={{ inventory_hostname }}"#配置broker.conf中的zookeeperServers值
- name: config_zookeeperServerslineinfile:path: "{{ pulsar_conf }}/broker.conf"regexp: "^zookeeperServers="line: "zookeeperServers={{ zkServers }}"#配置broker.conf中的clusterName值
- name: config_clusterNamelineinfile:path: "{{ pulsar_conf }}/broker.conf"regexp: "^clusterName="line: "clusterName={{ clusterName }}"#配置broker.conf中的kafkaAdvertisedListeners值
- name: config_kafkaAdvertisedListenerslineinfile:path: "{{ pulsar_conf }}/broker.conf"regexp: "^kafkaAdvertisedListeners="line: "kafkaAdvertisedListeners=PLAINTEXT://{{ inventory_hostname }}:9093"#配置bookkeeper.conf中的advertisedAddress值,设置为主机ip地址
- name: config_bk_advertisedAddresslineinfile:path: "{{ pulsar_conf }}/bookkeeper.conf"regexp: "^advertisedAddress="line: "advertisedAddress={{ inventory_hostname }}"#将模板文件bkenv.sh应用到pulsar的配置文件中
- name: config_bkenv.shtemplate:src: bkenv.shdest: "{{ pulsar_conf }}"#将模板文件pulsar_env.sh应用到pulsar的配置文件中
- name: config_pulsar_env.shtemplate:src: pulsar_env.shdest: "{{ pulsar_conf }}"
④ create_data_dir:创建存储数据的目录
目录结构如下:
create_data_dir/
├── tasks/
│ └── main.yml
main.yml
#循环创建with_items中的数据目录
- name: mkdir_data_dirfile:path: "{{ item }}"state: directorywith_items:- /data1/bookkeeper/ledger- /data2/bookkeeper/ledger- /data3/bookkeeper/ledger- /data4/bookkeeper/ledger
⑤ config_secret_key:配置安全秘钥
目录结构如下:
config_secret_key/
├── files/
│ └── admin-secret.key
├── tasks/
│ └── main.yml
main.yml
#创建存放安全秘钥的目录
- name: create_secret_key_dirfile:path: "{{ secret_key_dir }}"owner: rootgroup: rootstate: directory#将安装秘钥文件分发到指定的路径下
- name: dispatch_secret.keycopy:src: admin-secret.keydest: "{{ secret_key_dir }}"
⑥ init_meta:初始化集群元数据
目录结构如下:
init_meta/
├── tasks/
│ └── main.yml
├── templates/
│ └── init_meta.sh
main.yml
#应用init_meta.sh脚本到远程主机
- name: scp init_meta.shtemplate:src: init_meta.shdest: "{{ app_home }}/pulsar"#执行初始化脚本文件
- name: init_metashell: nohup sh {{ app_home }}/pulsar/init_meta.sh > {{ app_home }}/pulsar/init.log2>&1 &#等待20s查询初始化日志中是否出现初始化成功的日志
- name: wait20swait_for:path: "{{ app_home }}/pulsar/init.log"search_regex: "Cluster metadata for '{{ clusterName }}' setup correctly"delay: 20#杀掉集群元数据初始化进程
- name: kill metadatashell: ps -efww|grep PulsarClusterMetadataSetup|grep -v grep|cut -c 9-15|xargs kill -9
init_meta.sh:初始化集群元数据脚本{{ app_home }}/pulsar/bin/pulsar initialize-cluster-metadata \
--cluster {{ clusterName }} \
--zookeeper {{ zkServers }} \
--configuration-store {{ zkServers }} \
--web-service-url {{ webServiceUrl }} \
--broker-service-url {{ brokerServiceUrl }}
⑦ start_service:启动broker和bookkeeper服务
start_service/
├── tasks/
│ └── main.yml
main.yml
#启动远程主机bookkeeper服务
- name: start bookieshell: sh {{ app_home }}/pulsar/bin/pulsar-daemon start bookie#启动远程主机broker服务
- name: start brokershell: sh {{ app_home }}/pulsar/bin/pulsar-daemon start broker
6.2.4 编辑任务执行脚本
pulsar.yml:任务执行脚本
---
#分发pulsar安装包
- name: dispatch_pulsarhosts: pulsarremote_user: rootbecome: yesbecome_flags: '-i'roles:- dispatch_pulsartags: dispatch_pulsar#检查安装包中kop和分层存储nar包是否存在
- name: check_narhosts: pulsarremote_user: rootroles:- check_nartags: check_nar#修改pulsar配置
- name: config_pulsarhosts: pulsarremote_user: rootbecome: yesbecome_flags: '-i'roles:- config_pulsartags: config_pulsar#创建磁盘数据目录
- name: create_data_dirhosts: pulsarremote_user: rootbecome: yesbecome_flags: '-i'roles:- create_data_dirtags: create_data_dir#配置证书文件
- name: config_secret_keyhosts: pulsarremote_user: rootbecome: yesbecome_flags: '-i'roles:- config_secret_keytags: config_secret_key#初始化meta信息
- name: init_metahosts: pulsar[0]remote_user: rootbecome: yesbecome_flags: '-i'roles:- init_metatags: init_meta#启动broker和bookkeeper服务
- name: start_servicehosts: pulsarremote_user: rootbecome: yesbecome_flags: '-i'roles:- start_servicetags: start_service
6.2.5 执行playbook任务
#执行所有pulsar.yml中的任务
ansible-playbook -i hosts pulsar.yml#只执行pulsar.yml中标签为dispatch_pulsar,check_nar的任务
ansible-playbook -i hosts pulsar.yml --tags "dispatch_pulsar,check_nar"
7、Playbooks运维Pulsar集群总结
7.1 Pulsar运维实践总结
Pulsar作为新一代云原生架构的分布式消息中间件,目前再超大流量规模、海量分区、超高QPS等场景下缺乏长时间的稳定性验证,在极端场景下还存在较多稳定性风险,当前社区版本迭代活跃;Pulsar集群在vivo内部日均处理消息达万亿+,需要不断的合并社区issue及灰度升级高版本。运维事项较多、投入的运维人力较大。vivo分布式消息中间件团队通过借助Ansible的模块化、任务依赖、配置check、批量脚本执行等能力实现Pulsar集群从zk集群搭建、Pulsar安装包编译、自动化配置填充、批量分发部署、服务启动的一键运维部署能力。大大缩减了Pulsar集群的运维人力投入,Pulsar组件存算分离的架构设计优秀,但部署配置项非常繁杂,通过自动化配置填充可有效规避配置信息不一致、版本不一致等高频错误。
7.2 playbooks服务部署步骤
根据以上实战经验,我们可以总结出部署某个服务时编写playbooks脚本的一般步骤如下:
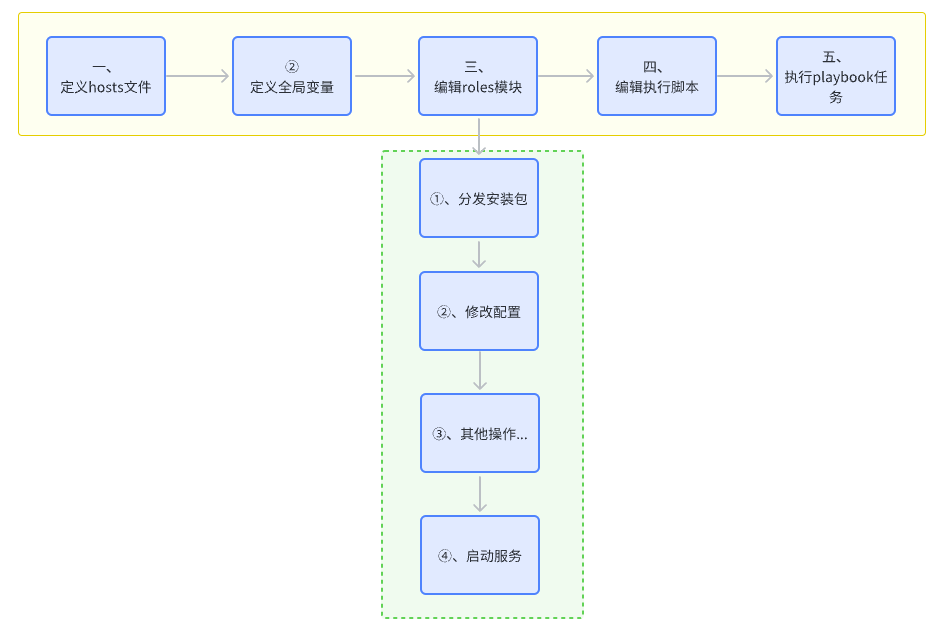
Ansible更多运维实践可参考:https://github.com/ansible/ansible-examples
猜你喜欢
-
vivo Pulsar万亿级消息处理实践(1)-数据发送原理解析和性能调优
-
vivo Pulsar万亿级消息处理实践(2)-从0到1建设Pulsar指标监控链路
-
vivo Pulsar万亿级消息处理实践(3)-KoP指标异常修复