Qwen-Image深度解析:突破文本渲染与图像编辑的视觉革命
> 中文乱码、字母错位、段落断裂——传统AI图像生成的“文字恐惧症”被彻底治愈
2025年8月,阿里云通义千问团队开源了**Qwen-Image模型**,一举攻克了AI图像生成领域长期存在的**文本渲染难题**。这个拥有**200亿参数**的多模态大模型不仅在中文文本生成准确率上达到97.29%,更实现了生成、编辑、理解三大能力的统一。本文将深度解析其技术原理、应用场景及实战方法。
---
### 一、为什么文本渲染是AI生图的“阿喀琉斯之踵”?
传统文生图模型(如Stable Diffusion、Midjourney)在图像美学上已炉火纯青,但在处理文字时却常“漏洞百出”:
- 中文部首断裂、标点错位
- 英文单词字母缺失或重复
- 段落布局混乱,无法自动换行对齐
- 多语言混排时风格不统一
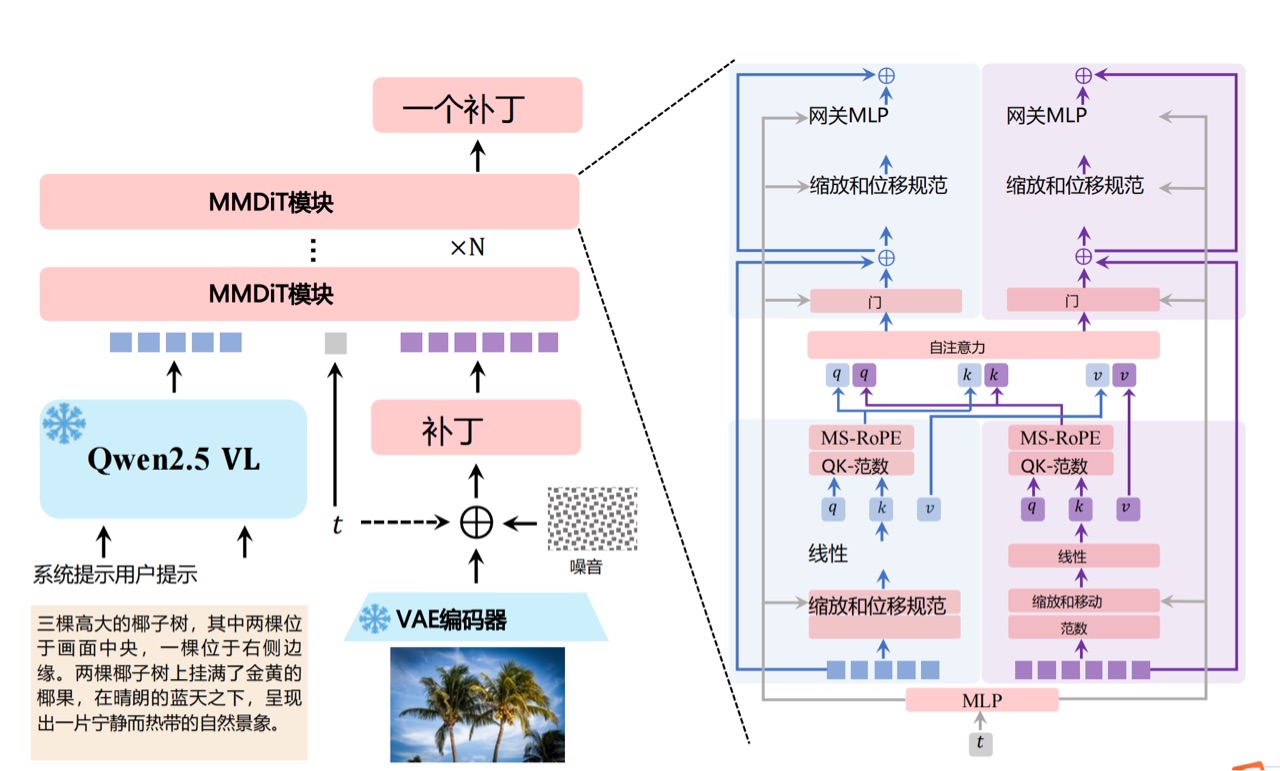
**根本原因**在于传统模型将文字视为“图像纹理”而非**语义符号**。Qwen-Image通过革命性的**MMDiT架构**(多模态扩散变换器)解决了这一本质问题。
---
### 二、核心技术突破:双通道编码与渐进式训练
#### 1. MMDiT架构设计
Qwen-Image的核心创新在于**多模态混合设计**:
```python
# 架构伪代码示意
class MMDiT(nn.Module):