gpt2架构学习(1)
多头注意力机制的代码逻辑
主要参考:<从零开始大模型>
整体结构如图:
https://www.processon.com/view/link/689d8bc94f0dbc7fcf49883f?cid=689d873239b7227d867825c8
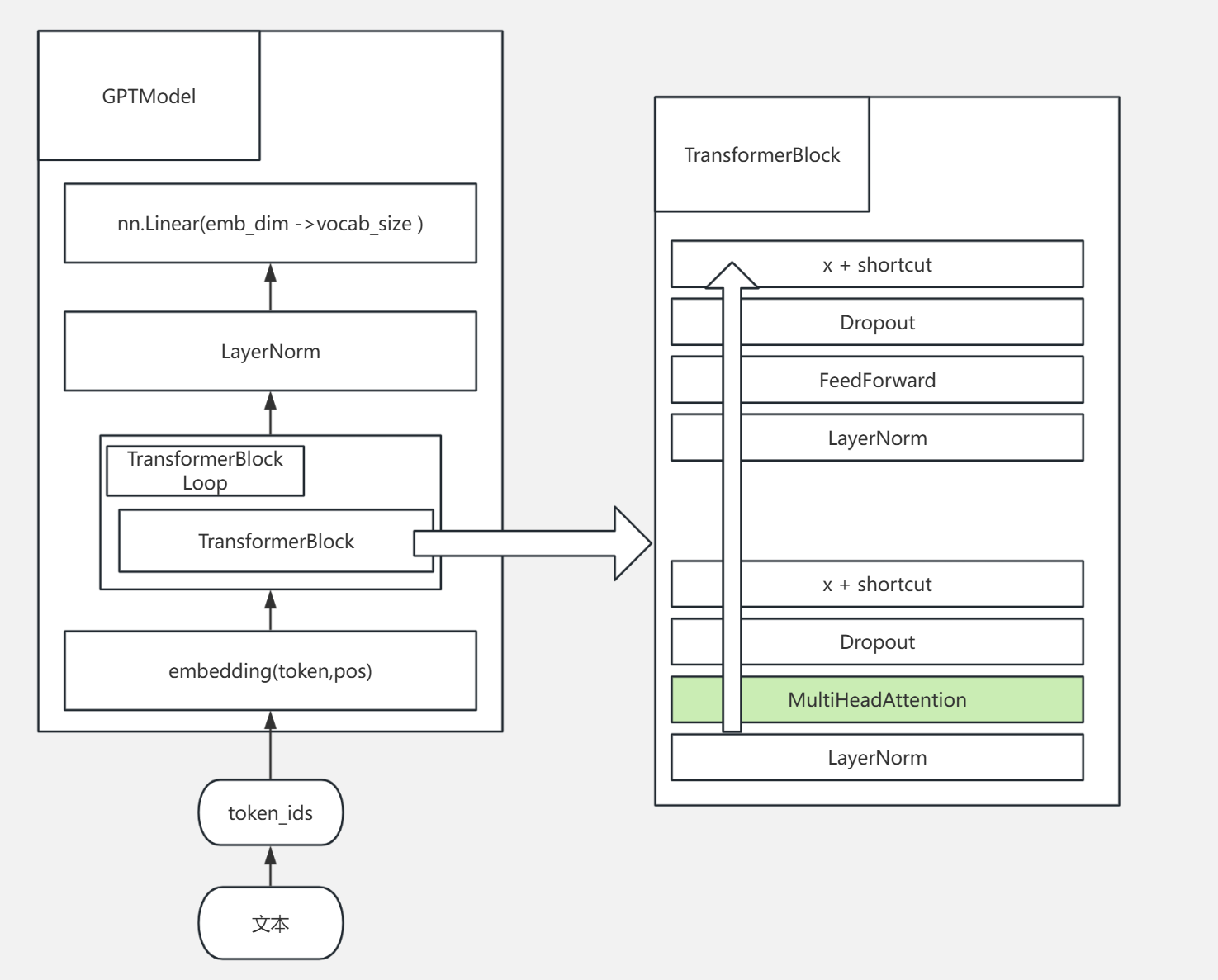
本节主要是写token, embedding和MultiHeadAttention模块
名词说明
token: 词汇, 不一定是一个词,是tokenizer.encode()返回
context_length, 输入长度(token数)
emb_dim = 嵌入向量的维度[…]
qkv 权重, 被训练的权重, 形状上一般是 (emb_dim, emb_dim)的方阵,这里用到区分: (emb_dim, qkv_out_dim)
文本输入相关
1, 输入文本
2, 转成token,再转成向量矩阵(n, emb_dim),
(1), token_embedding (X*emb_dim) 训练生成的
(2), pos_embedding (n*emb_dim) 训练生成的
→ out_embedding
转成token需要词汇表映射(tokenize), 可以找对应的,
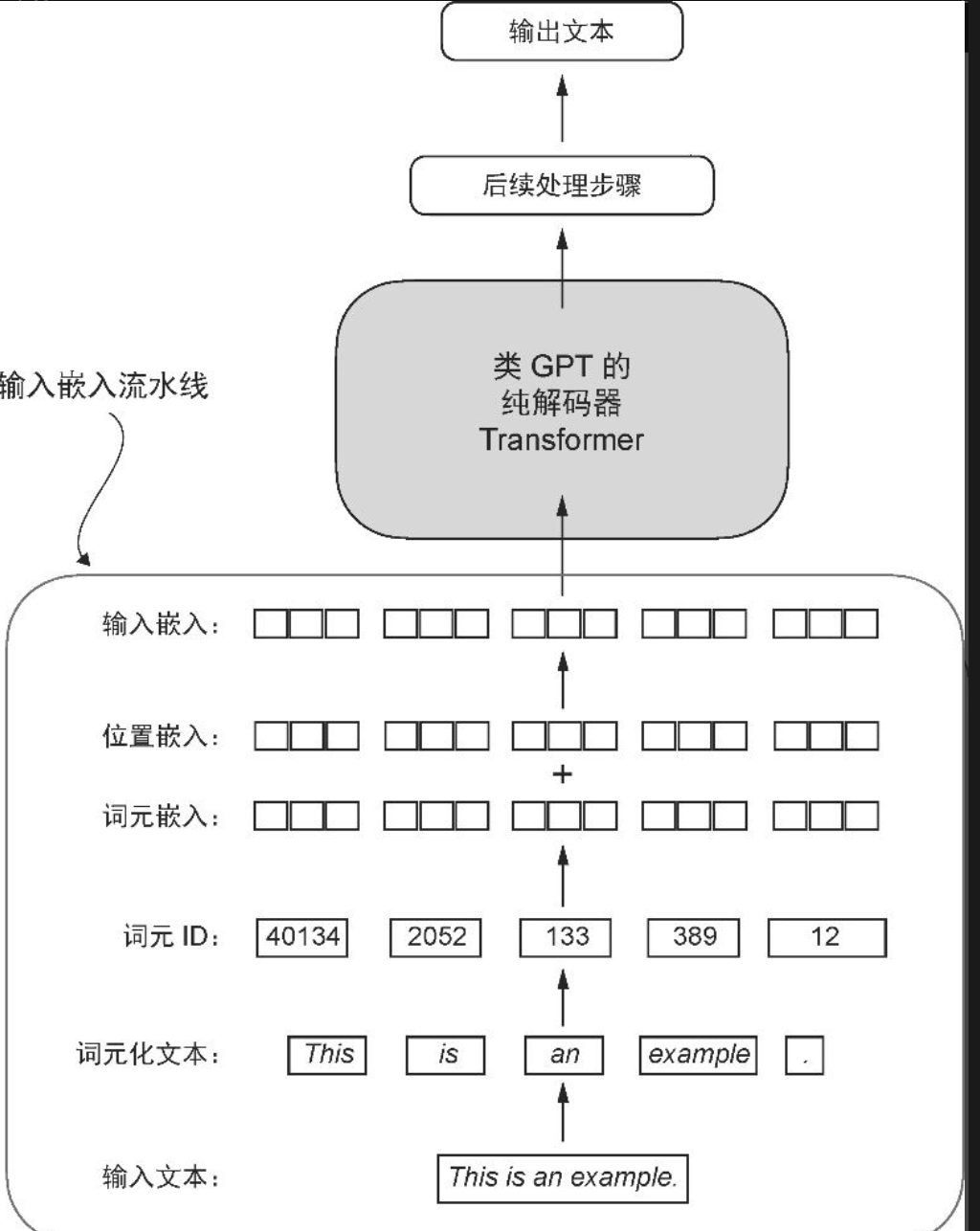
token相关代码大概是如下
tokenid:
tokenizer = tiktoken.get_encoding("gpt2")encoded = tokenizer.encode(start_context)encoded_tensor = torch.tensor(encoded).unsqueeze(0)
embedding相关
class GPTModel(nn.Module):def __init__(self, cfg):super().__init__()self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])self.drop_emb = nn.Dropout(cfg["drop_rate"])# todo 注意力层# todo LayerNorm# 输出self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False)def forward(self, in_idx):batch_size, seq_len = in_idx.shapetok_embeds = self.tok_emb(in_idx) # 即token_embedding pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]# todo 扔给注意力层&LayerNormlogits = self.out_head(x) # 输出return logits
LayerNorm 是归一化技术,主要用于稳定训练过程、加速收敛并提升模型性,
注意力模块相关
3, 初始化qkv向量矩阵(n*qkv_out_dim), , 输入矩阵(n,emb_dim) @ qkv 权重(emb_dim, qkv_out_dim)
4, 得到注意力分数(attn_weight)
注意力分数是每个token的q各token的k, (1qkv_out_dim) @ 转置(nqkv_out_dim) 得到 (1n),
则注意力矩阵 是(n*n) 的方阵, 注意力分数再 softmax 得到 注意力权重矩阵,
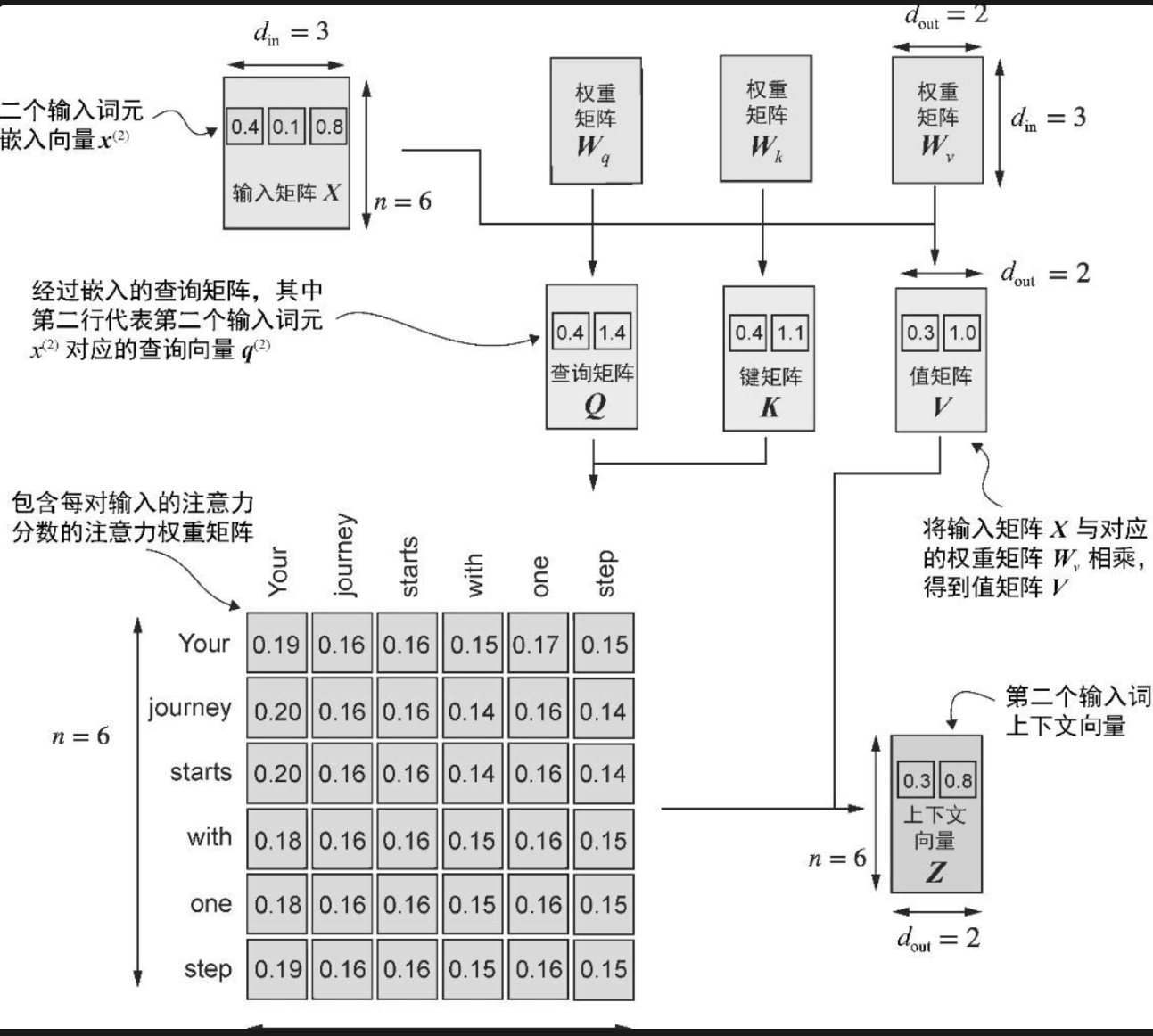
5, 得到上下文向量(context_vec)
attn_weight @ v向量矩阵, 即 (n, n) @ (n, qkv_out_dim) = (n, qkv_out_dim)
6, 训练时,要mask 和 drop_out, 针对 attn_weight, 另外上面矩阵计算时要留意 batch的处理.
上面(3-6)逻辑的参考代码:
class CausalAttention(nn.Module):def __init__(self, d_in, d_out, context_length,dropout, qkv_bias=False):super().__init__()self.d_out = d_outself.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)self.dropout = nn.Dropout(dropout) # Newself.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1)) # Newdef forward(self, x):b, num_tokens, d_in = x.shape # New batch dimension b# For inputs where `num_tokens` exceeds `context_length`, this will result in errors# in the mask creation further below.# In practice, this is not a problem since the LLM (chapters 4-7) ensures that inputs # do not exceed `context_length` before reaching this forward method. keys = self.W_key(x)queries = self.W_query(x)values = self.W_value(x)attn_scores = queries @ keys.transpose(1, 2) # Changed transposeattn_scores.masked_fill_( # New, _ ops are in-placeself.mask.bool()[:num_tokens, :num_tokens], -torch.inf) # `:num_tokens` to account for cases where the number of tokens in the batch is smaller than the supported context_sizeattn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)attn_weights = self.dropout(attn_weights) # Newcontext_vec = attn_weights @ valuesreturn context_vectorch.manual_seed(123)context_length = batch.shape[1]
ca = CausalAttention(d_in, d_out, context_length, 0.0)context_vecs = ca(batch)
多头注意力
7, 多头注意力的逻辑
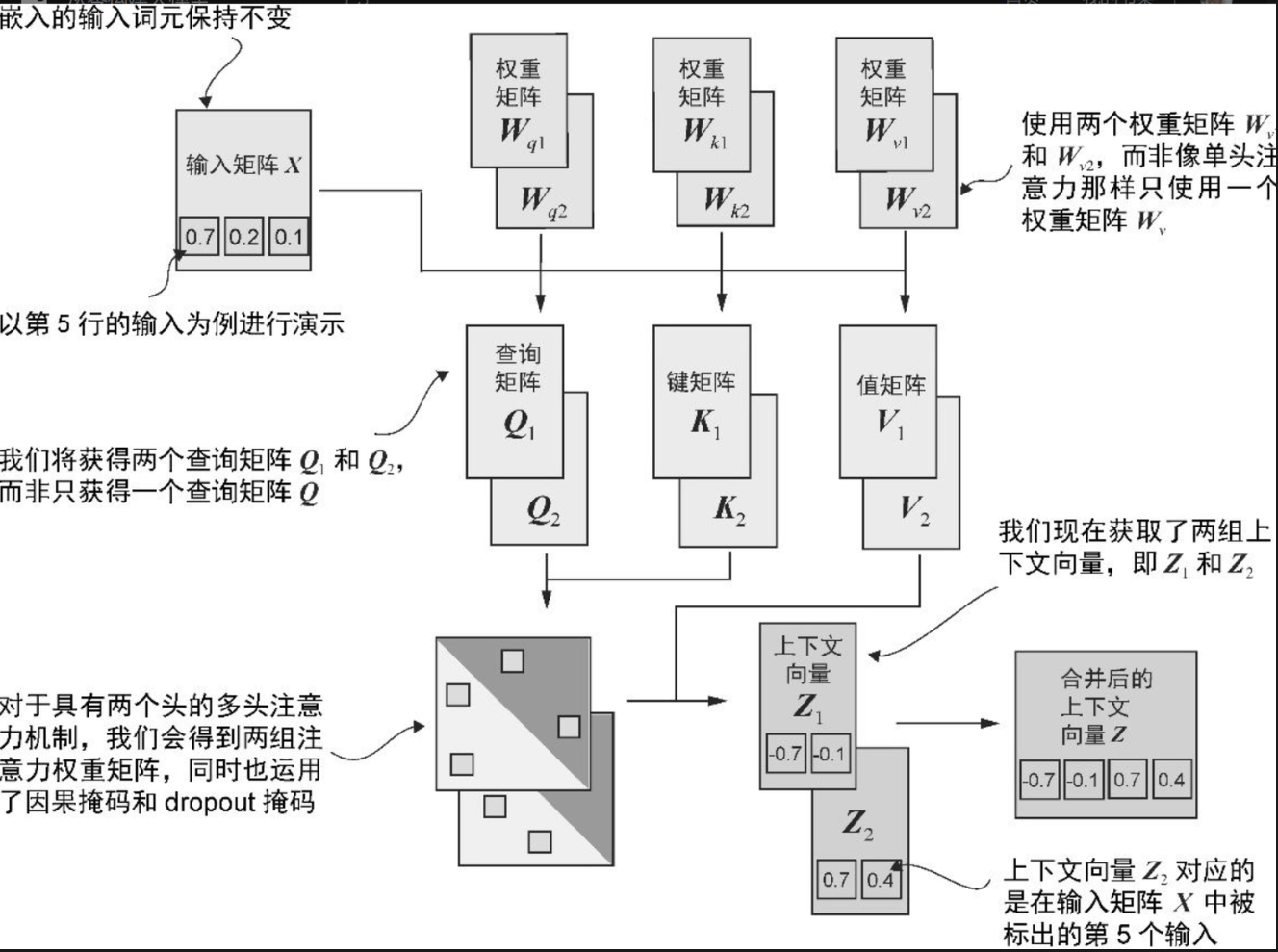
上面(3-7)的代码如下:
class MultiHeadAttention(nn.Module):def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):super().__init__()assert (d_out % num_heads == 0), \"d_out must be divisible by num_heads" # 整除self.d_out = d_outself.num_heads = num_heads # 多少个头self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dimself.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputsself.dropout = nn.Dropout(dropout)self.register_buffer("mask",torch.triu(torch.ones(context_length, context_length),diagonal=1))def forward(self, x):b, num_tokens, d_in = x.shape# As in `CausalAttention`, for inputs where `num_tokens` exceeds `context_length`, # this will result in errors in the mask creation further below. # In practice, this is not a problem since the LLM (chapters 4-7) ensures that inputs # do not exceed `context_length` before reaching this forwarkeys = self.W_key(x) # Shape: (b, num_tokens, d_out)queries = self.W_query(x)values = self.W_value(x)# 要把 head_num 加到矩阵中: # We implicitly split the matrix by adding a `num_heads` dimension# Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)keys = keys.view(b, num_tokens, self.num_heads, self.head_dim) values = values.view(b, num_tokens, self.num_heads, self.head_dim)queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)# Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim), 即转置一下, 让num_tokens, head_dim 放最后用于后台的@操作keys = keys.transpose(1, 2)queries = queries.transpose(1, 2)values = values.transpose(1, 2)# Compute scaled dot-product attention (aka self-attention) with a causal maskattn_scores = queries @ keys.transpose(2, 3) # Dot product for each head# Original mask truncated to the number of tokens and converted to booleanmask_bool = self.mask.bool()[:num_tokens, :num_tokens]# Use the mask to fill attention scoresattn_scores.masked_fill_(mask_bool, -torch.inf)attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)attn_weights = self.dropout(attn_weights)# Shape: (b, num_tokens, num_heads, head_dim)context_vec = (attn_weights @ values).transpose(1, 2) # Combine heads, where self.d_out = self.num_heads * self.head_dimcontext_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)context_vec = self.out_proj(context_vec) # optional projectionreturn context_vectorch.manual_seed(123)
batch_size, context_length, d_in = batch.shape
d_out = 2
mha = MultiHeadAttention(d_in, d_out, context_length, 0.0, num_heads=2)context_vecs = mha(batch)print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)