微软推出AI恶意软件检测智能体 Project Ire
开篇
在8月5号,微软研究院发布了一篇博客文章,在该篇博客中推出了一款名为Project Ire的AI Agent。该Agent可以在无需人类协助的情况下,自主分析和分类二进制文件。它可以在无需了解二进制文件来源或用途的情况下,对文件进行完全的逆向工程,然后利用LLM来审查逆向后的输出内容,并确定软件是恶意的还是良性的。
我们知道,针对二进制的分析工作极具挑战性,因为它不像脚本文件那样能够直接的看到代码意图。通常需要使用逆向工具,从汇编代码或者反编译后的伪代码中去抽丝剥茧,总结出二进制文件的实际行为。
目前Project Ire还处于原型阶段,据称在使用 Windows 驱动程序的公共数据集上进行测试,能达到 0.98 的精确度和 0.83 的召回率,这在二进制分析领域已经可以算是很高的了。
遍历已有
事实上,随着MCP协议的出现,各类逆向MCP Server也如雨后春笋般层出不穷。
比如github上Ghidra逆向工具的MCP Server就有多个repo。
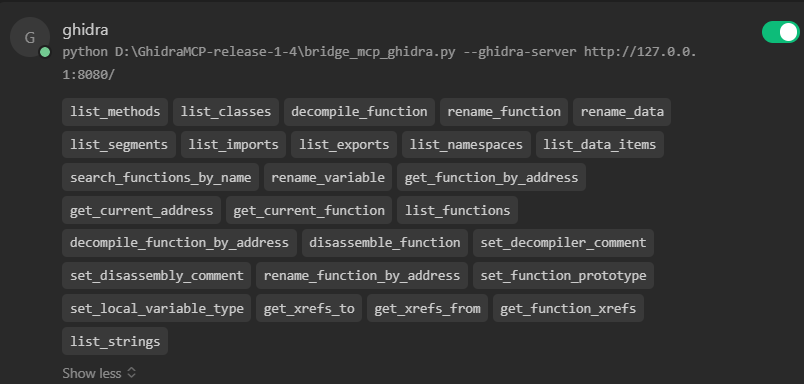
笔者尝试了其中的一些,发现它们的功能基本大同小异。都是通过IDA Pro或者Ghidra的插件能力,在实现的插件中启动http server对外暴漏了一些逆向的基本tools(工具),比如下面是Ghidra暴漏的一些tools,包括列举出二进制文件的所有函数(list_functions)、反编译指定函数(decompile_function)等等。
然后随便分析了一个恶意的二进制文件:
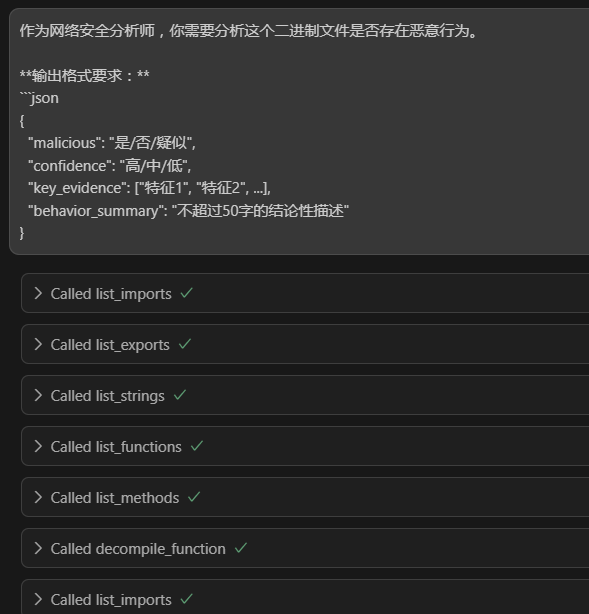
可见其调用了Ghidra MCP Sverver提供的工具来获取该二进制文件的信息。然后综合判断后给出了下面的结论:
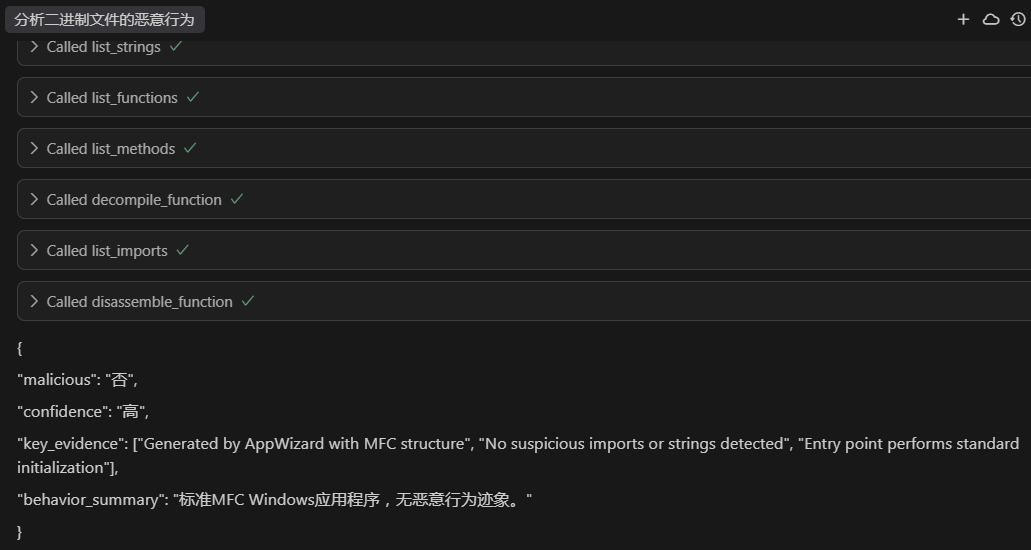
很可惜,大模型并没有分析出其包含的恶意行为。
简单的AI Agent可以提高人类分析二进制文件的效率,但不能把判断权完全交给大模型。
笔者尝试过让大模型分析反汇编后的函数汇编代码,大模型的表现非常敏感,经常会出现误报的情况,一个正常函数也会被认为存在恶意行为。无论怎么调整提示词也无法达到一个理想状态。
所以,微软推出的Project Ire并不是一个简单的AI Agent,能达到98%的准确率肯定是有其独特的技术创新和深度优化。
Project Ire
Project Ire 诞生于微软研究院、Microsoft Defender和Microsoft Discovery & Quantum 的合作,汇集了安全专业知识、安全运营知识、全球恶意软件威胁情报以及人工智能研究。
Microsoft Discovery是2025年微软推出的面向企业的AI科研平台。该平台集成了多种专业的 AI 模型与工具,其主要特点是具备高度的可扩展性。
它建立在 GraphRAG (知识图谱+RAG)和 Microsoft Discovery 的基础之上,使用高级大语言模型以及一套逆向和二进制分析工具来推动调查和判断。
逆向工具会识别文件类型、结构以及潜在的关注点。之后,系统会使用angr和Ghidra等二进制分析框架重建二进制文件的控制流图。这些构建的成果构成了Project Ire 内存模型的Graph,用于指导后续分析工作。
通过迭代函数进行分析,LLM 通过 API 调用二进制分析工具来识别和总结关键函数。每个分析的结果都会被输入到“证据链”中,这是一个详细且可审计的线索,展示了Project Ire是如何得出结论的。这份可追溯的证据日志支持安全团队进行二次审查,并有助于在出现错误分类的情况下改进系统。
为了验证其分析结果,Project Ire 可以调用一个验证工具,根据证据链对分析报告中的内容进行交叉核对。该工具借鉴了 Project Ire 团队恶意软件逆向工程师的专家知识。系统会根据这些证据及其内部模型,创建最终报告,并将样本分类为恶意或良性。
总结
基于LLM的AI Agent是AI时代进行二进制文件分析的重要工具,Project Ire作为微软在这一领域的杰出代表,是网络安全和恶意软件检测领域的一大进步。
但也要看到这类AI工具的局限性,降低误报率依旧是个大难题,仍然需要人类分析师参与其中。
不过以目前AI领域的发展速度,有理由相信,在不久的将来,AI工具在二进制文件分析上的表现将会取得质的飞跃。