HunyuanVideo-Avatar:为多个角色制作高保真音频驱动的人体动画
1. 前言/动机
- Page: https://hunyuanvideo-avatar.github.io
- Model: https://huggingface.co/tencent/HunyuanVideo-Avatar
- Code: https://github.com/Tencent-Hunyuan/HunyuanVideo-Avatar
1.1. 问题:在生成高动态视频的同时保持角色的一致性
描述:目前的音频驱动人体动画方法通常在推理过程中依赖参考图像,以加强生成视频与参考图像之间的一致性。然而,这种方法往往会导致动作不自然,因为模型倾向于复制参考图像中的表情和姿势,而不是生成动态的、与音频对齐的动作。
解决方案:
设计了角色图像注入模块,以取代传统的基于加法的字符调节方案,消除了训练和推理之间固有的条件不匹配问题。这确保了动态运动和强大的角色一致性;
1.2. 问题:怎么实现角色与音频之间精确的情感对齐
描述:全身动画方法通过将运动扩展到全身来解决动画人物与其环境之间的根本脱节这一空间限制问题。然而,这些方法面临着持续的挑战,包括角色动作不自然、音频情感与面部表情不一致,以及无法用音频驱动多角色场景。这些限制是目前开发真正令人信服的音频驱动人体动画的最大障碍。尤其在情绪表达方面,现有方法缺乏有效的机制来实现音频语义与面部表情之间的高精度对齐。
解决方案:
引入音频情感模块(AEM),从情感参考图像中提取情感线索并将其传输到目标生成视频中,该模块利用音频中的情感线索与图像中的情绪表达进行融合,确保生成人物的视频表情在时序上与音频语义一致,实现细粒度且可控的情绪表达,显著提升了人物动画的真实感与情感表现力。
1.3. 问题:实现多角色音频驱动
描述:目前的音频驱动系统在多角色场景下面临巨大挑战,传统方法难以区分和独立控制多个角色的语音驱动效果,容易导致人物动作混乱、表情不一致,严重影响多人物对话或群体互动场景的真实感和可控性。
解决方案:
提出了 “面部感知音频适配器”(Face-Aware Audio Adapter,FAA),该模块在潜在特征空间中引入面部区域掩码,用于隔离不同角色的面部表征。在此基础上,在多角色场景下通过交叉注意力机制(Cross-Attention)将各自的音频信息注入对应的角色面部区域,实现了不同角色的音频独立驱动。
核心模块与创新点
浑源视频-阿凡达的关键模块如下:
- 角色图像注入模块:
提出了角色图像注入模块,将人物图像特征注入到通道维度,而非直接添加到潜在空间,从而消除训练与推理之间的一致性-动态性矛盾,提高了前景与背景区域的整体动作质量。解决了因使用参考图像而导致的动态性和一致性之间的权衡问题,提高了前景和背景区域的整体运动质量。 - 音频情感模块(AEM):
为实现角色情绪与音频情感的对齐,HunyuanVideo-Avatar引入 AEM 模块。它通过参考图像引导情绪映射,确保面部表情能够真实反映音频所传达的情绪,从而提升人物动画的真实感。 - 面部感知音频适配器 (FAA):
提出 FAA 模块。该模块对输入的潜在特征施加面部掩码,生成带有面部遮罩的视频特征,然后与音频信息融合。由于音频主要影响被掩码的面部区域,可以为不同角色注入独立的音频输入,从而实现多角色对话动画,适用于影视级应用场景。
2. 方法
输入:一个角色图像(可以头肩、半身、全身人像,也可以动画形象)、一段音频和一段prompt用来控制人物动作
输出:一段音频驱动的角色视频
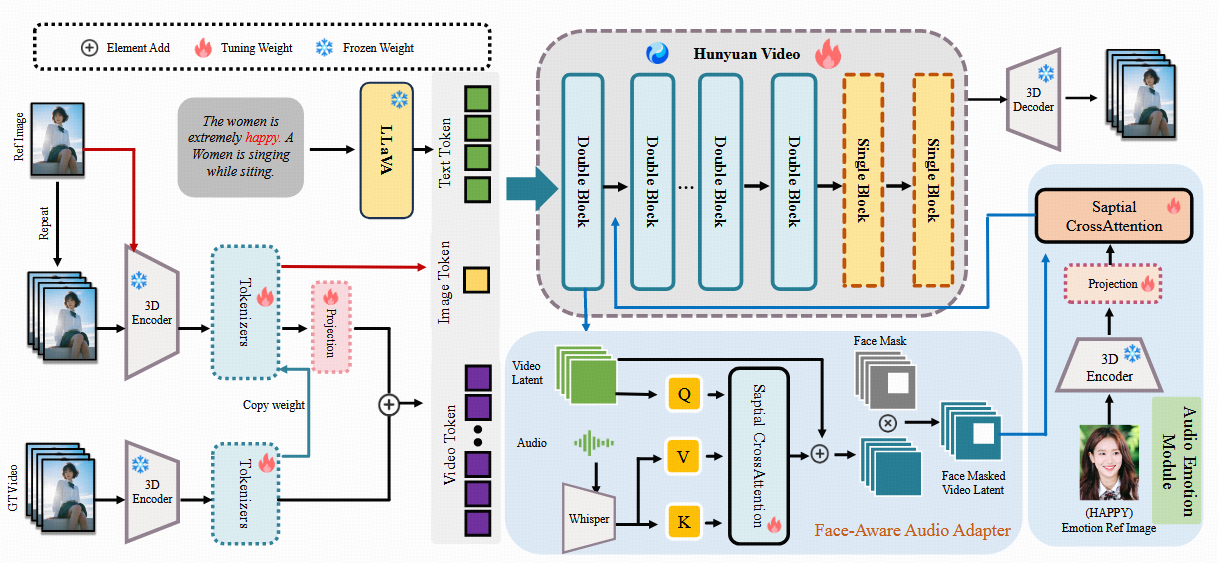
2.1 角色图像注入模块(Character Image Injection Module)
在传统图像到视频(Image-to-Video, I2V)方法中,常通过引入填充帧(padding frames)增强推理阶段的角色一致性。然而,该策略存在明显不足:
- 限制生成视频的运动动态性;
- 引入训练与推理之间的条件不一致;
- 可能导致模型行为僵化,影响多样性与自然性
若完全移除填充帧,虽然动作更自然,但会严重破坏角色一致性及整体视觉质量。
模块设计与对比:
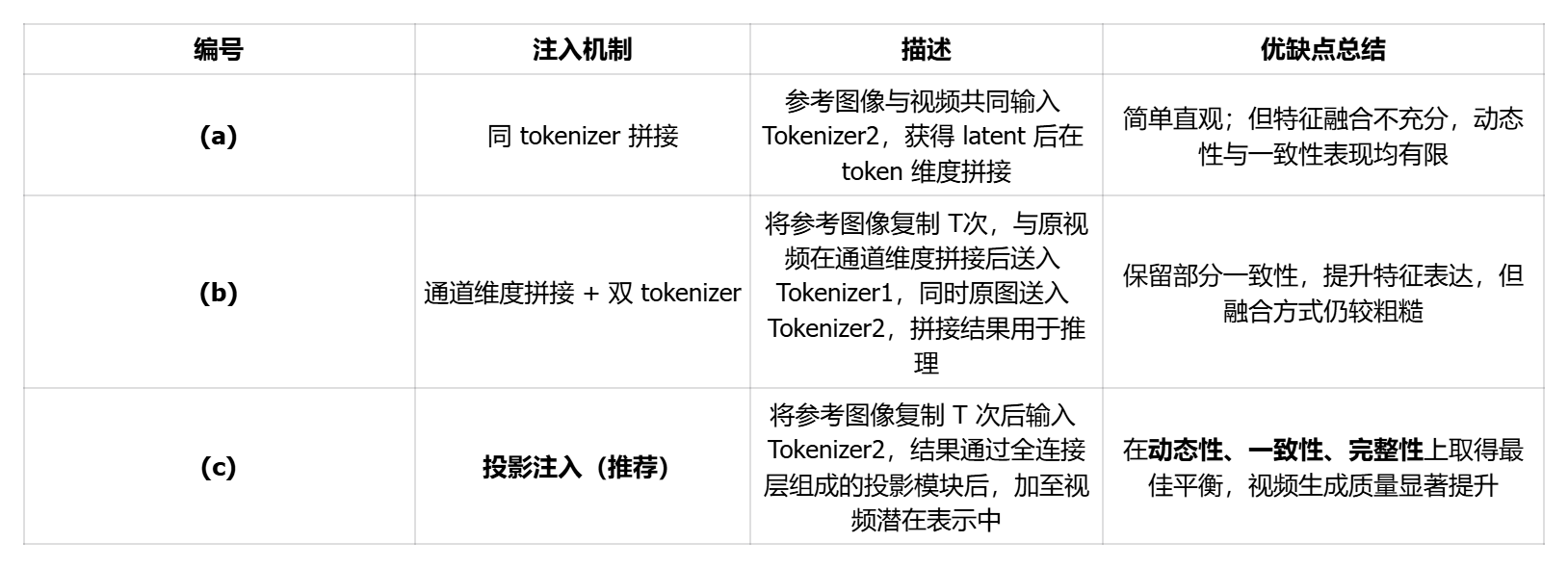
为解决上述问题,HunyuanVideo-Avatar提出并实验了三种角色图像注入机制,如图 3 所示。以下是各方案的结构与性能对比:
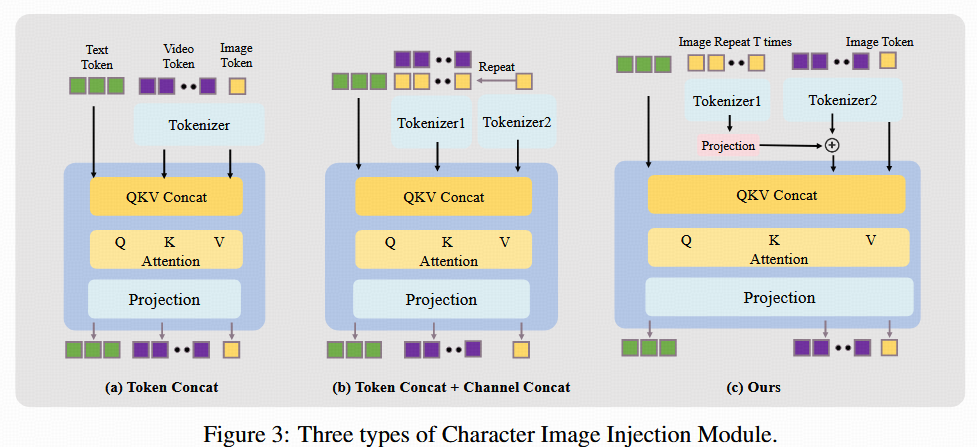
实现细节:
- 为适配图像与视频的异构表示形式,引入额外的 Tokenizer2 专用于图像路径,Tokenizer2 的权重初始化自主干网络中的 Tokenizer1,可加速收敛;
- 图像注入采用 通道投影(Channel-wise Projection)方式融合。
- 时间维度上将参考图像放置于 时间索引 -1(第一帧的前一桢),配合 3D-RoPE 位置编码,实现身份信息的有效时序传播;
- 受 OmniControl 启发,HunyuanVideo-Avatar对图像位置编码施加空间偏移(spatial shift),防止模型直接套用图像姿态,提升动作自然性。
2.2 面部感知音频适配器(Face-aware Audio Adapter, FAA)
在多角色音频驱动的视频生成中,为避免音频信号彼此干扰并实现人物独立驱动,部感知音频适配器(FAA),结合人脸区域掩码(face mask)和跨注意力机制,实现在时空对齐条件下的局部音频注入。
模块输入:
- 音频特征提取:
使用 Whisper 对输入音频进行逐帧特征提取,对于 n′ 帧音频序列,每帧提取 10 个 token,得到的特征张量维度为:[n′,10,d] - 人脸掩码提取:
使用 InsightFace 检测视频中每帧人脸区域的边界框,用于生成人脸掩码(face mask)。 - 视频潜在表示:
输入视频通过预训练的 3D VAE 压缩后,原始 n′ 帧压缩为n=⌊n′/4⌋+1n=⌊n′/4⌋+1n=⌊n′/4⌋+1 帧,其中额外的 “+1” 表示未压缩的初始帧,压缩因子为 4。 - 身份图像拼接:
为引入身份信息,HunyuanVideo-Avatar在视频序列前拼接一张角色图像,最终视频潜在特征为 n+1帧。
音频特征时间对齐:
将音频特征在初始帧之前补齐,使其总长度达到(n+1)×4(n+1)×4(n+1)×4;
每连续 4 帧音频聚合为 1 帧,对齐后维度为:
gA=Rearrange(gA,0):[b,(n+1)×4,10,d]→[b,(n+1),40,d]gA=Rearrange(gA,0):[b,(n+1)×4,10,d]→[b,(n+1),40,d]gA=Rearrange(gA,0):[b,(n+1)×4,10,d]→[b,(n+1),40,d]
人脸掩码时间对齐:
- 对应初始帧的人脸掩码设为 1;
同样构造(n+1)×4(n+1)×4(n+1)×4 的掩码序列,并压缩聚合为gM∈[b,(n+1),1,1]g_M \in [b, (n+1), 1, 1]gM∈[b,(n+1),1,1],实现与视频潜在表示的时空对齐。
空间级跨注意力注入
为实现每一帧的独立音频注入,FAA 采用空间注意力(spatial cross-attention)策略: - 解耦时间和空间维度,仅在每个时间步内,令音频与对应帧的空间 token 交互;
- 避免不同时间步之间的音频信息干扰;
- 注入过程如下所示:
yt,A′=Rearrange(yt):[b,(n+1)wh,d]→[b,n+1,wh,d]y_{t,A}'=Rearrange(yt):[b,(n+1)wh,d]→[b,n+1,wh,d]yt,A′=Rearrange(yt):[b,(n+1)wh,d]→[b,n+1,wh,d]
yt,A′′=yt,A′+αA×CrossAttn(gA,yt,A′)×gMy_{t,A}''=y'_{t,A}+αA×CrossAttn(g_A,y'_{t,A})×g_Myt,A′′=yt,A′+αA×CrossAttn(gA,yt,A′)×gM
yt,A=Rearrange(yt,A′′):[b,n+1,wh,d]→[b,(n+1)wh,d]y_{t,A}=Rearrange(y''_{t,A}):[b,n+1,wh,d]→[b,(n+1)wh,d]yt,A=Rearrange(yt,A′′):[b,n+1,wh,d]→[b,(n+1)wh,d]
其中,
- αA\alpha_AαA 是控制音频注入强度的缩放因子;
- gAg_AgA 是对齐后的音频特征张量;
- gMg_MgM是掩码张量,确保仅在人脸区域注入音频特征。
模块优势总结:
- 局部注入控制: 仅在人脸区域引入音频,避免影响全身或背景区域;
- 多角色解耦: 各角色使用独立音频,互不干扰;
- 强时序一致性: 精确对齐压缩后的视频 latent 和音频特征;
2.3 音频情感模块(Audio Emotion Module,AEM)
音频驱动的角色动画中,往往存在语音语调表达的情绪与面部表情呈现的情绪不一致问题。为了实现音频情感与角色表情之间的精确对齐,本模块引入情感参考图像作为中介,辅助模型感知并映射细腻的情绪风格。
核心设计思路:
AEM采用一张情感参考图像(I_ref),通过预训练的 3D VAE 编码器提取其特征表示 ErefE_{ref}Eref,再通过全连接层(FC Layer)+ 交叉注意力机制(Cross-Attention),将情感信号注入到视频的潜在特征中,实现更自然、准确的情感表达。
模块实现流程:
- 情感图像特征提取:
使用 3D VAE 编码器获取情感参考图像的潜在特征表示:
Eref=Encoder(Iref)E_{ref}=Encoder(I_{ref})Eref=Encoder(Iref) - 视频潜在表示重排:
为了将这些潜在特征注入视频潜在表示中,将视频潜在表示 yt,Ay_{t,A}yt,A 重新排列为时空维度结构:
yt,A′=Rearrange(yt,A):[b,(n+1)wh,d]→[b,n+1,wh,d]y'_{t,A}=Rearrange(y_{t,A}):[b,(n+1)wh,d]→[b,n+1,wh,d]yt,A′=Rearrange(yt,A):[b,(n+1)wh,d]→[b,n+1,wh,d] - 情感特征注入:
通过全连接层对情感图像特征进行变换后,与 yt,A′y'_{t,A}yt,A′执行空间级跨注意力操作,注入情感信息:
yt,A,E′′=yt,A′+γE×CrossAttn(FC(Eref),yt,A′)y''_{t,A,E}=y'_{t,A}+γE×CrossAttn(FC(E_{ref}),y'_{t,A})yt,A,E′′=yt,A′+γE×CrossAttn(FC(Eref),yt,A′) - 恢复原始结构:
将融合情感的特征重排回视频潜在表示的结构:
yt,A,E=Rearrange(yt,A,E′′):[b,n+1,wh,d]→[b,(n+1)wh,d]y_{t,A,E}=Rearrange(y''_{t,A,E}):[b,n+1,wh,d]→[b,(n+1)wh,d]yt,A,E=Rearrange(yt,A,E′′):[b,n+1,wh,d]→[b,(n+1)wh,d]
模块位置与效果验证:
- 本模块被嵌入于 HunyuanVideo 框架中的 Double Block 内部;
- 实验发现:将情感模块置于 Single Block 无法有效传达情绪信号;
- 相比之下,Double Block 结构更有助于捕捉复杂的“语音情绪 → 面部表情”映射关系,在情绪表现力方面效果显著更佳
2.4 长视频生成(Long Video Generation)
在真实对话或长语音场景中,角色发声常持续数十秒甚至数分钟。而现有的 HunyuanVideo-13B 模型基于 MM-DiT 架构,仅支持生成 129 帧 的短视频,这远远不能覆盖完整语音内容。为此,HunyuanVideo-Avatar引入 时间感知偏移融合(Time-aware Position Shift Fusion) 策略,扩展模型的长视频生成能力。
方法原理:
该方法借鉴自 Sonic ,在不增加模型训练或推理开销的前提下,有效解决了以下问题:
- 音频时长 > 视频最大帧数 的不匹配;
- 视频片段拼接过程中的抖动(jitter)与突变(abrupt transition)现象;
- 长视频中上下文信息衔接不流畅问题。
实现机制:
在生成过程中,HunyuanVideo-Avatar采用滑动窗口式的音频段输入策略:
- 将完整音频划分为多个重叠片段;
- 模型每次接收一个音频片段作为输入,生成对应视频 latent;
- 当前时间步的视频生成起点,相较上一个片段偏移 α\alphaα 帧;
- 所有片段间通过重叠区域平滑连接,最终拼接成完整连贯视频。
参数设置:
- 偏移步长α\alphaα:实验设置为 3~7 帧;
- 步长越小,衔接越平滑,但推理次数越多;
- 实验证明此范围内生成质量最佳,人物连贯性和动态性表现最优。
3. 实验
3.1 实验设置(Experiment Settings)
基于 HunyuanVideo-I2V 模型构建 HunyuanVideo-Avatar 系统,训练流程分为两个阶段:
- 阶段一:仅使用音频驱动数据,构建基础的音频-视觉对齐能力;
- 阶段二:引入图像与音频混合训练(音频:图像 = 1:1.5),增强角色动作的稳定性与一致性。
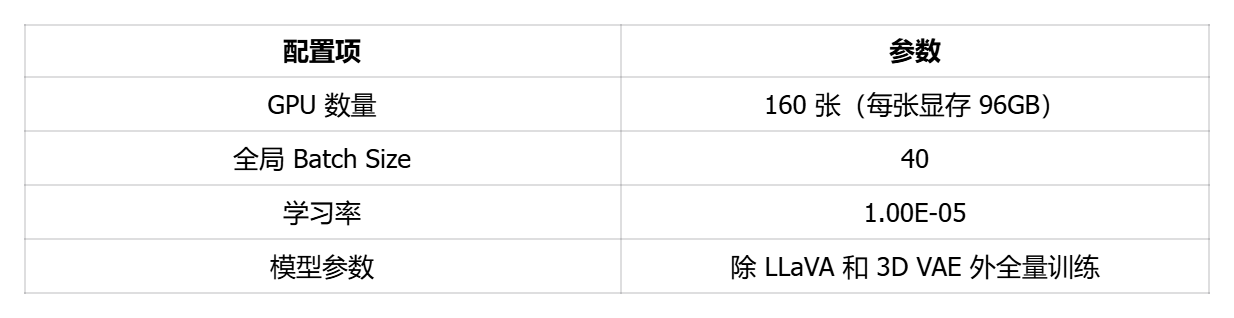
训练数据分辨率为 704×704 至 704×1216,训练时冻结 LLaVA 和 3D VAE 模块,仅对其余可学习参数进行更新。
训练环境与参数如下:
3.2 数据集(Datasets)
为了构建高质量训练样本,我们进行了严格筛选:
- 使用 LatentSync [18] 剔除音画不同步样本;
- 结合 Koala-36M [36] 工具过滤低亮度/低美学质量视频。
最终构建了一个包含约 50 万条音频角色样本、总时长约 1250 小时的大规模训练集。
测试阶段,我们选择了以下公开肖像动画数据集进行评估:

3.3 评估指标(Evaluation Metrics)
采用多种客观与主观指标全面评估模型性能:
- 图像质量与美学:使用 Q-align 视觉语言模型获取 IQA(图像质量)和 ASE(美学分数);
- 生成分布评估:使用 FID 与 FVD 衡量生成视频与真实视频的距离;
- 运动稳定性:采用 VBench 的 Smoothness 指标;
- 视听同步性:使用 Sync-C 衡量音画同步程度;
- 主观评价:邀请 30 名用户从四个维度评分:
- 口型同步性(LS: Lip Sync)
- 身份保持性(IP: Identity Preservation)
- 全身自然度(FBN: Full-body Naturalness)
- 面部自然度(FCN: Facial Naturalness
对比基线方法(Compared Baselines):
为全面评估 HunyuanVideo-Avatar 的性能,我们选择当前主流的音频驱动视频生成方法进行对比:
- 肖像动画对比方法:
Sonic [15]、EchoMimic [24]、EchoMimic-V2 [24]、Hallo-3 [7]、OmniHuman-1 [21] - 全身动画对比方法:
Hallo-3 [7]、FantasyTalking [35]、OmniHuman-1 [21]
(均在自构的全身动画测试集上进行评估)
3.4 定性结果(Qualitative Results)

为验证 HunyuanVideo-Avatar 在不同任务中的性能优势,在标准人脸数据集(HDTF)与自构全身动画测试集上,分别与当前主流音频驱动视频生成方法进行了定性对比。对比重点包括:
- 视频质量与美学效果;
- 口型同步性与面部表情自然度;
- 多人物场景适应性;
- 全身动作连贯性与环境一致性。
肖像动画对比(Portrait Animation on HDTF):
- HunyuanVideo-Avatar在口型同步、眼部动作、面部表情维度展现出更自然流畅的运动效果;
- 生成视频的整体清晰度更高,面部区域无明显伪影或僵硬;
- 美学评分方面,视频色彩与光照更加真实协调;
- 相比其他方法,我们的方法在背景处理上亦保持较高的一致性与稳定性。
🔍 图 4:展示了在人脸驱动任务下,各方法的典型生成结果。我们的模型生成视频在视觉质量与情感表达方面均领先其他对比方法。

3.5 定量结果(Qualitative Results
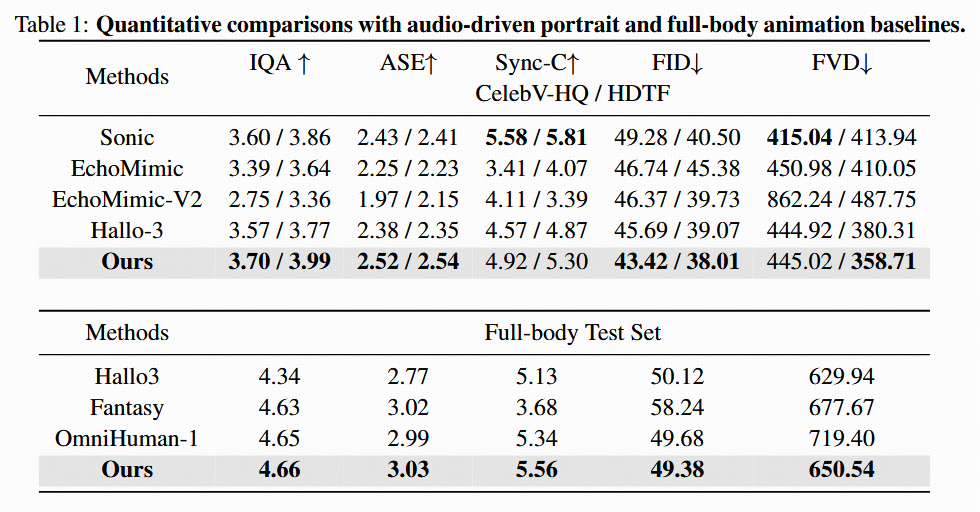
肖像动画定量评估:
在 CelebV-HQ 与 HDTF 两大公开人脸数据集上,HunyuanVideo-Avatar对比了现有主流方法在多个指标下的表现,包括:
- FID(Fréchet Inception Distance):评估生成视频与真实数据分布的差异;
- FVD(Fréchet Video Distance):评估视频序列间的时序一致性;
- IQA(Image Quality Assessment):图像质量评价指标;
- ASE(Aesthetic Score Estimation):美学评分;
- Sync-C(音视频同步评分):衡量口型与语音同步程度。
✅ 实验结果如表 1 所示,HunyuanVideo-Avatar 在上述全部指标中均取得最佳结果,显著优于
Sonic、EchoMimic、Hallo-3 等方法,表明其在音频驱动肖像动画任务中具备卓越的表现力与同步控制能力。
全身动画定量评估:
在自构的 Full-Body Wild Test Set 上,HunyuanVideo-Avatar与 Hallo-3、FantasyTalking 和 OmniHuman-1 进行了系统对比,继续采用与肖像动画相同的五个评估指标。
✅ 表 1 中全身动画结果显示,我们的方法在大多数评估指标上同样取得领先,特别是在 FVD、Sync-C 与 IQA 等方面,充分验证了
HunyuanVideo-Avatar 在复杂多人物场景下的可控性与生成质量。
用户主观评价(User Study):

每位参与者针对每个维度对生成视频进行 1~5 分等级评分,评分结果见表 2。
✅ 实验表明,HunyuanVideo-Avatar 在 LS(口型同步)与
IP(身份保持)两个核心维度上显著优于其他对比方法,归因于我们提出的 角色图像注入模块(CIIM)与面部感知音频适配器(FAA)
的协同作用。 ⚠️ 然而,在 FCN 与 FBN 两项指标上,我们方法略逊于 OmniHuman-1,这主要由于:
- OmniHuman-1 并非开源,其在线服务默认采用了超分辨率增强,在视觉观感上具备先天优势;
- 我们的方法基于 HunyuanVideo 主体框架,仍继承其部分局限性(如动作边界模糊、背景轻微抖动等)。
3.6 消融实验与分析
为全面验证各关键模块对 HunyuanVideo-Avatar 性能的贡献,分别对以下三个核心组件进行了消融实验:角色图像注入模块(CIIM)、音频情感模块(AEM)与面部感知音频适配器(FAA)。实验采用主观与客观评价结合的方式,从多个维度分析模块作用。
角色图像注入模块(Character Image Injection Module)消融分析

结果如表 3 所示,HunyuanVideo-Avatar提出的通道注入+特征投影方式(即最终采用的机制 c),在视频动作的动态性和角色一致性方面表现最优。相比其他方案,该方法有效避免了“参考图像复制”现象,提升了动作真实度。

音频情感模块(Audio Emotion Module, AEM)消融分析
图 7(a) 展示了使用与不使用音频情感模块对视频角色表情情感效果的影响。
- 仅使用文本信息(如说话语气描述)进行情感驱动时,模型难以准确地将情感映射到人物面部,导致表情模糊或失真;
- 当通过 AEM 将情感参考图像注入模型后,模型能够更加清晰地捕捉和转移参考图中的情感特征,实现更自然、准确的面部情绪表达与音频语气一致性。
该实验结果验证了 AEM 在音频-情感-面部映射建模中的关键作用。
面部感知音频适配器(Face-Aware Audio Adapter, FAA)消融分析
图 7(b) 展示了在多角色音频驱动场景中,使用与不使用 FAA 模块的对比结果。
- 无面部遮罩控制的情况下,所有角色都会受到同一音频的驱动,导致模型无法对角色进行独立控制;
- 引入 FAA 后,模型通过面部区域遮罩,精确控制音频影响区域,实现了仅驱动指定角色表演。当面部遮罩切换时,模型可自然转向控制另一个角色,从而实现多角色音频驱动对话生成。
该模块显著提升了模型的控制能力与多人物交互生成能力。