Spring AI 的特性 及其 最佳实践
1.本文简介
当前文章是基于3分钟 Spring AI 实现对话功能-CSDN博客 这个文章之后的拓展,主要讲解使用SpringAI如何实现 流式输出 及 自定义 Advisor 实现敏感消息的记录 以及 自定义ChatMemory实现聊天会话 持久化
零基础的先去阅读该文章3分钟 Spring AI 实现对话功能-CSDN博客,
有基础的同学可以直接食用该文章
2.自定义Advisor
2.1实现日志记录
Ai的调用分为阻塞式调用 和 流式调用,所以自定义Advisor 需要实现两个不同的接口,分别是
CallAroundAdvisor 和 StreamAroundAdvisor , 第一个需要实现的方法为 aroundCall ,第二个为 aroundStream
每当阻塞式调用 就会走aroundCall 方法 流式调用则走 aroundStream 方法
所以我们需要记录日志就需要在两个方法中都进行记录。
package com.example.demo.advisor;import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.advisor.api.*;
import org.springframework.ai.chat.model.MessageAggregator;
import reactor.core.publisher.Flux;@Slf4j
public class MyAdvisorLog implements CallAroundAdvisor, StreamAroundAdvisor {public AdvisedRequest before(AdvisedRequest advisedRequest){log.info("MyAdvisorLog before: {}",advisedRequest.userText()); //记录用户输入return advisedRequest;}public void after(AdvisedResponse advisedResponse){log.info("MyAdvisorLog after: {}",advisedResponse.response().getResult().getOutput().getText()); //打印模型返回结果}@Overridepublic AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {//记录请求输入AdvisedRequest request = before(advisedRequest);AdvisedResponse response = chain.nextAroundCall(request); //调用下一个切面//记录模型返回结果after(response);return response;}@Overridepublic Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {advisedRequest = before(advisedRequest);Flux<AdvisedResponse> advisedResponse = chain.nextAroundStream(advisedRequest);return new MessageAggregator().aggregateAdvisedResponse(advisedResponse, this::after);}@Overridepublic String getName() {return MyAdvisorLog.class.getName();}@Overridepublic int getOrder() {return 0;}
}
并且在初始化大模型时 配置 自定义Advisor
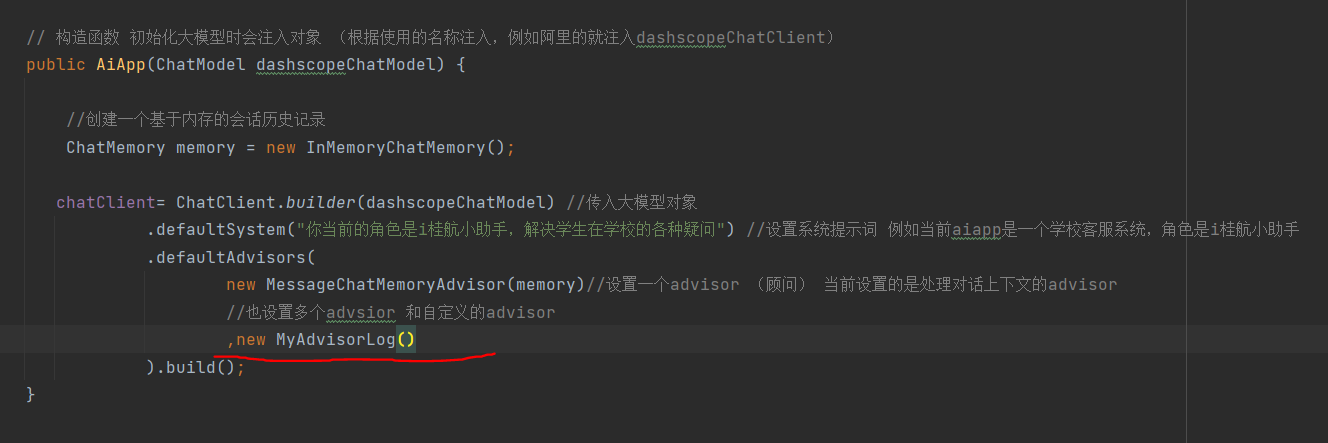
进行测试
日志成功打印

2.2 实现 Re2 提高大模型的推理能力
RE2(Re-Reding)是一种通过结合 检索(Retrieval)机制 提升大模型推理能力的技术。它的核心思想是让模型在生成答案或推理时减少对纯参数化记忆的依赖,增强事实准确性和逻辑推理能力
让大模型对输入进行多次阅读或“重复理解”(类似人类的“重读”行为)
本质上就算你提问一次,但是让大模型对你的提问进行两次阅读,避免阅读出幻觉,就像我们如果做题时,第一次没理解题目意思,再读一遍可能就理解了题目意思。
优点:提升大模型的推理能力
缺点: 输入Token数量翻倍
package com.xiaog.aiapp.advisor;import org.springframework.ai.chat.client.advisor.api.*;
import reactor.core.publisher.Flux;import java.util.HashMap;
import java.util.Map;/*** 自定义 Re2 Advisor* 可提高大型语言模型的推理能力* //弊端:token数量翻倍*/
public class ReReadingAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {private AdvisedRequest before(AdvisedRequest advisedRequest) {Map<String, Object> advisedUserParams = new HashMap<>(advisedRequest.userParams());advisedUserParams.put("key1", advisedRequest.userText());return AdvisedRequest.from(advisedRequest).userText("""{key1}Read the question again: {key1}""") //模板 将输入内容作为参数传入模板 例如 将key1对应的value转为字符串再传入大模型.userParams(advisedUserParams).build();}// /**
// * 执行请求前改写prompt
// * @param advisedRequest
// * @return
// */
// private AdvisedRequest before(AdvisedRequest advisedRequest) {
//
//
// // 构造"读两遍"的提示词 让模型推理能力更强 //弊端:token数量翻倍
// String doubleReadPrompt = advisedRequest.userText() +
// "\nRead the question again: " + advisedRequest.userText();
//
// return AdvisedRequest.from(advisedRequest)
// .userText(doubleReadPrompt)
// .build();
// }@Overridepublic AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {return chain.nextAroundCall(this.before(advisedRequest));}@Overridepublic Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {return chain.nextAroundStream(this.before(advisedRequest));}@Overridepublic int getOrder() {return 0;}@Overridepublic String getName() {return this.getClass().getSimpleName();}
}
设置到大模型初始化中
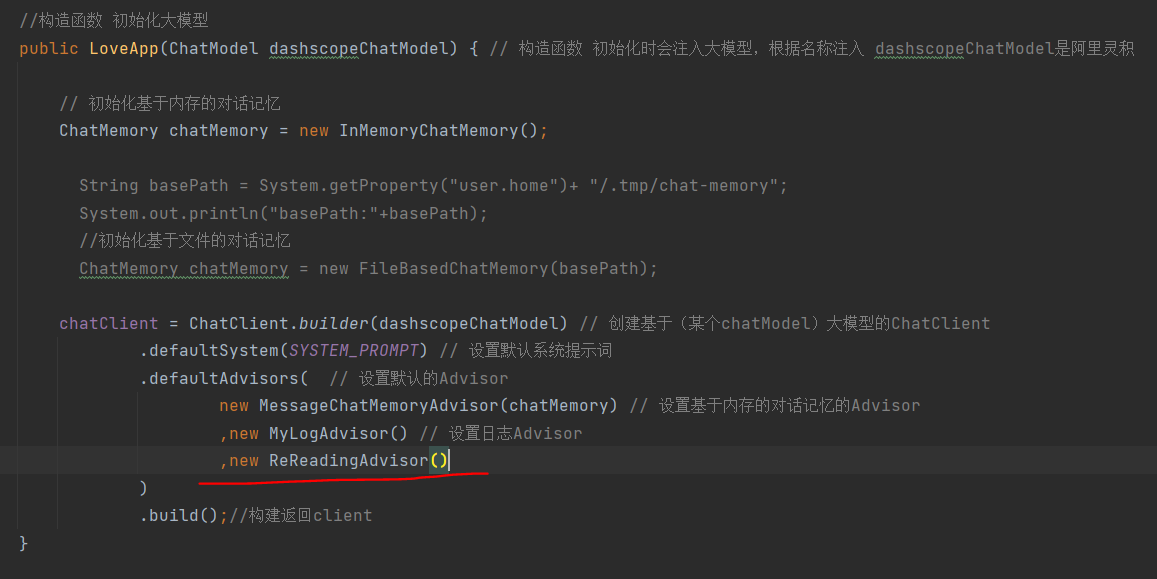
Re2并不好演示,大家只需要知道有这个东西就好了,例如用户点击了深度思考,就可以开启RE2。
2.3 实现用户敏感词输入进行报警
比如现在教育部门非常在意在校学生的心理健康问题,学校选择在学校部署一个心理健康小助手大模型,用于解决学生的心理健康问题,当发现有学生输入例如:(紫砂,跳喽)等关键字眼,则进行记录,识别用户身份,向该学生的辅导员进行短信告知,及时发现心理存在问题的学生
代码中获取当前用户调用dochat聊天会话的方法,找到用户的信息和其辅导员信息
//Chatclien对话public String dochat(String message,String sessionId){//模拟获取当前访问此接口的用户tokenString userToken="user-token";ChatResponse chatResponse = chatClient.prompt().user(message)//传入用户输入信息.advisors(advisorSpec -> advisorSpec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, sessionId)//对话的会话id 用于查看是否是当前上下文.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 3) //检索上下文的长度 如果长度过长所消耗的Token数量会过大//可以自定义参数,会作为参数传递给自定义advisor 比如用户的登陆Token//用于在advisor层面进行学生的信息识别.param("userToken", userToken)).call().chatResponse();log.info("chatResponse: {}", chatResponse.getResult().getOutput().getText());//输出模型返回的结果return chatResponse.getResult().getOutput().getText();}3.自定义Chatmemoty
3.1基于文件存储保存 用户聊天信息
这里使用到了
Kryo
需要引入Maven
<!--支持文件会话记忆的序列化会话--> <dependency><groupId>com.esotericsoftware</groupId><artifactId>kryo</artifactId><version>5.6.2</version> </dependency>
编写自定义
FileBasedChatMemory
package com.xiaog.aiapp.chatmemory;import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;
import org.objenesis.strategy.StdInstantiatorStrategy;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.messages.Message;import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;/*** //自定义对话存储* 对话记忆存储 到文件中*/public class FileBasedChatMemory implements ChatMemory {// 文件路径private final String BASE_PATH ;// kryo序列化private static final Kryo kryo = new Kryo();static{//允许序列化未预先注册的类kryo.setRegistrationRequired(false);//设置实例化策略kryo.setInstantiatorStrategy(new StdInstantiatorStrategy());}//构造对象时,指定存储地址public FileBasedChatMemory(String basePath) {this.BASE_PATH = basePath;File file = new File(BASE_PATH);//如果文件不存在,则创建文件if (!file.exists()) {file.mkdirs();}}@Overridepublic void add(String conversationId, List<Message> messages) {//获取全部消息List<Message> allMessages = getOrCreateConversation(conversationId);//将此条消息添加到全部会话中allMessages.addAll(messages);//保存会话saveConversation(conversationId, allMessages);}@Override //lastN = 5 表示获取最近的 5 条对话消息public List<Message> get(String conversationId, int lastN) { //lastN//获取全部消息List<Message> allMessages = getOrCreateConversation(conversationId);//获取最新N条消息List<Message> collect = allMessages.stream().skip(Math.max(0, allMessages.size() - lastN)) //需要跳过的消息数量=(总消息数 - 需要最新的消息数量).collect(Collectors.toList());return collect;}@Overridepublic void clear(String conversationId) {//删除会话文件File file = new File(conversationId);if (file.exists()) {file.delete();}}/*** 创建 或 读取会话消息*/private List<Message> getOrCreateConversation(String conversationId) {File file = getConversationFile(conversationId);List<Message> messages = new ArrayList<>();if (file.exists()) { //如果文件存在,则读取文件//创建输入流try (Input input = new Input(new FileInputStream(file))) {//反序列化messages = kryo.readObject(input, ArrayList.class);} catch (IOException e) {e.printStackTrace();}}return messages;}/*** 保存会话信息*/private void saveConversation(String conversationId, List<Message> messages) {//获取到文件路径File file = getConversationFile(conversationId);//获取到输出流try (Output output = new Output(new FileOutputStream(file))) {//将信息写到文件中(这是覆写操作)kryo.writeObject(output, messages);} catch (IOException e) {e.printStackTrace();}}/*** 每个文件单独保存* conversationId 是Srping AI框架生成的*/private File getConversationFile(String conversationId) {return new File(BASE_PATH, conversationId + ".kryo");}}
修改初始化大模型内容
//构造函数 初始化大模型public LoveApp(ChatModel dashscopeChatModel) { // 构造函数 初始化时会注入大模型,根据名称注入 dashscopeChatModel是阿里灵积// 初始化基于内存的对话记忆
// ChatMemory chatMemory = new InMemoryChatMemory();String basePath = System.getProperty("user.home")+ "/.tmp/chat-memory";System.out.println("basePath:"+basePath);//初始化基于文件的对话记忆ChatMemory chatMemory = new FileBasedChatMemory(basePath);chatClient = ChatClient.builder(dashscopeChatModel) // 创建基于(某个chatModel)大模型的ChatClient.defaultSystem(SYSTEM_PROMPT) // 设置默认系统提示词.defaultAdvisors( // 设置默认的Advisornew MessageChatMemoryAdvisor(chatMemory) // 设置基于内存的对话记忆的Advisor,new MyLogAdvisor() // 设置日志Advisor,new ReReadingAdvisor()).build();//构建返回client}将会话内存存储修改为文件存储