Linux:线程
Linux:线程
线程概念:
线程(Thread)是进程内的一个执行单元,是操作系统调度的基本单位。
所以CPU在运行里,根本没有进程的概念,CPU中运行的全是线程。
线程与进程的区别:
线程是属于进程里的一部分,线程是进程里的一个执行流,并且线程是可以在进程中同时存在多份的,也就是多线程。
那进程是什么呢?
从之前认识来说,进程=内核数据结构+代码和数据。当我们在开始运行可执行程序时,操作系统会为该可执行程序建立task_struct,建立mm_struct,分配地址空间,建立页表映射关系,所以准确来说进程是承担分配系统资源的基本实体。
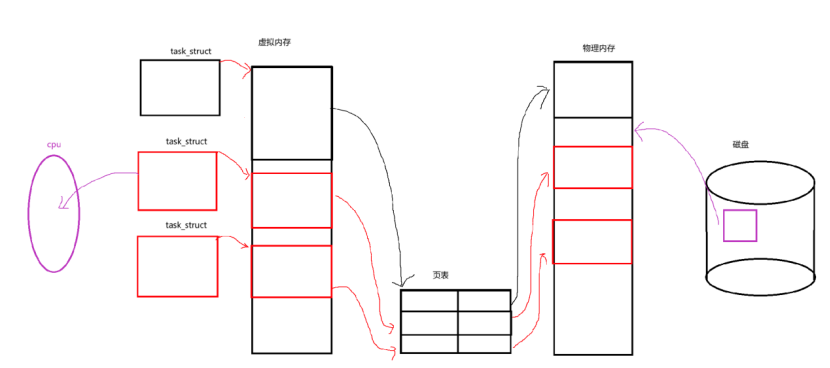
在上图,我们可以看到有3个task_struct同时指向同一个虚拟内存,但这里不要误会,Linux是采用轻量级进程来模拟线程。
Linux 之所以用轻量级进程模拟线程,核心原因在于复用进程机制实现线程的核心需求:
从行为上看,线程作为进程内的执行流,其调度、上下文切换等行为与进程高度相似。Linux 内核没有为线程单独设计数据结构,而是通过 “轻量级进程”(本质是共享资源的task_struct)来实现 —— 这避免了重构内核现有进程管理逻辑,既保证了代码的稳定性,又高效支持了线程的特性。
从资源访问角度看,进程的资源(如代码、数据、文件描述符等)通过地址空间(mm_struct)统一管理,地址空间就像一个 “窗口”,让进程能访问到对应的物理资源。而线程(轻量级进程)的关键在于:多个task_struct共享同一个地址空间,它们虽然各自执行不同的代码(对应虚拟地址中的不同函数),但指向同一块虚拟内存。这种天然的资源共享特性,让线程无需额外机制就能直接访问同一份数据,满足了线程 “共享资源、高效通信” 的核心需求。
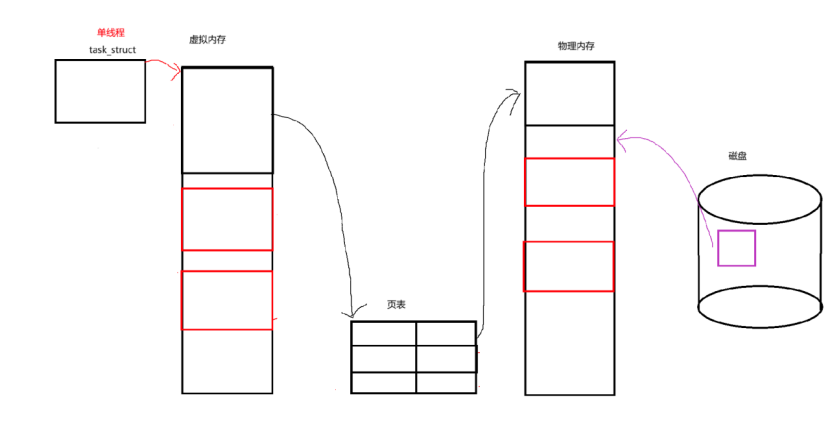
所以回顾我们之前所学的进程,本质上是一个特殊的单线程的进程,是一种特殊的情况。
结论:
- Linux”线程”采用轻量级进程来模拟
- 对资源的划分,本质上是对虚拟地址空间进行划分,虚拟地址就是资源的代表
深入探讨资源划分:
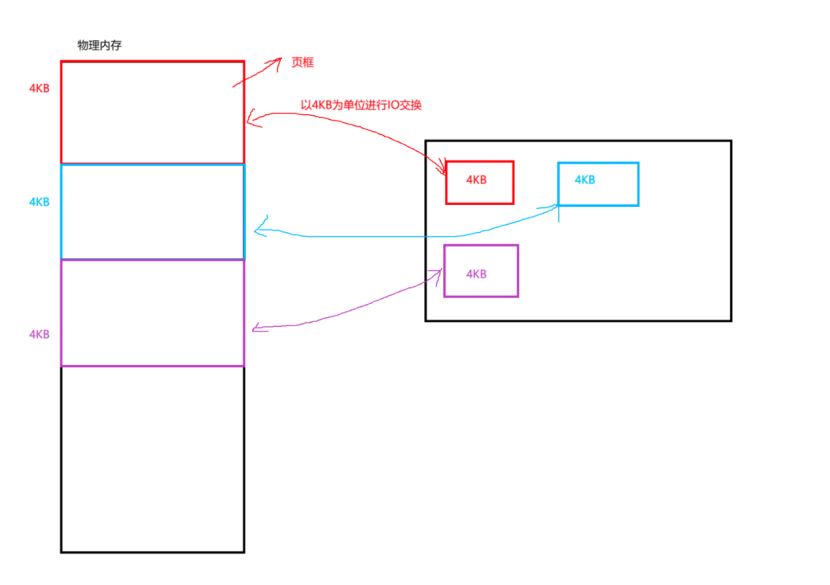
在文件系统章节我们知道,磁盘上存储文件的大小是以4KB进行内存块进行存储的,而我们物理内存假设有4GB,而4GB的内存也需要管理,而4GB的内存会被划分为一块一块的4KB内存进行管理。
一个4KB的物理内存称之为页框,所以物理内存与磁盘文件进行IO交换时,是以4KB大小的内存块进行交换数据。
那么对于4KB内存,有些内存正在被占用,有些内存空闲,内存有4GB/4KB=1048576个页框。对于这么多页框操作系统肯定也要先描述这些页框,并且对这些页框进行管理。
Struct page:

该结构体就是用于描述一个4KB页框,那么我们知道我们的物理地址是一个线性地址,所以管理page,就可以使用数组进行管理,刚刚算出来物理内存一共有1048576个page,所以 struct_page mem[1048576],对page的增删查改就转为了对数组的增删查改。
所以每一个page都有自己的下标,那么也就能得出每一个page的起始物理地址为struct_page mem的index(下标)*4KB,而知道page的起始物理地址后,它的具体物理地址=起始物理地址+页内偏移量(后面再谈)。
对页表的深入理解:
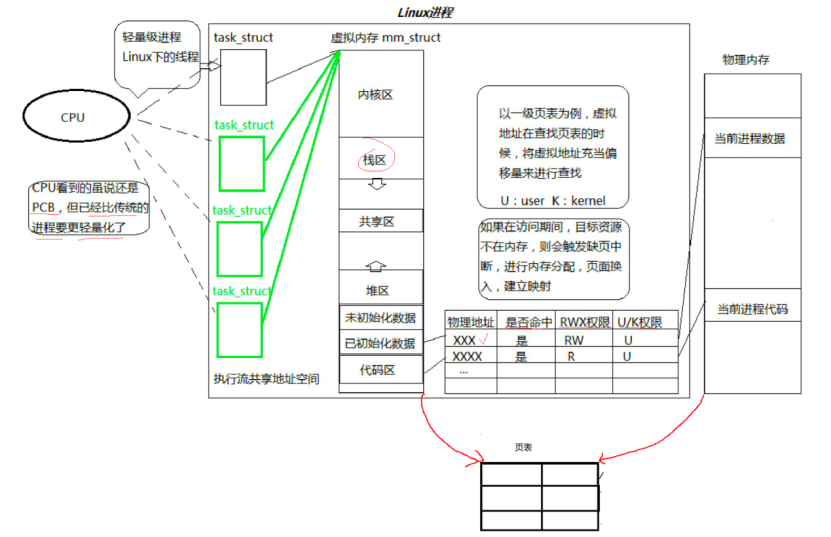
我们知道页表是用于物理地址与虚拟地址进行相互映射的作用,那我们有必要对每一个物理地址与虚拟地址都进行一一映射吗,要知道页表同样也要占用内存,如果给每一个物理地址和虚拟地址都进行映射的话,那页表的内存不就大的夸张。
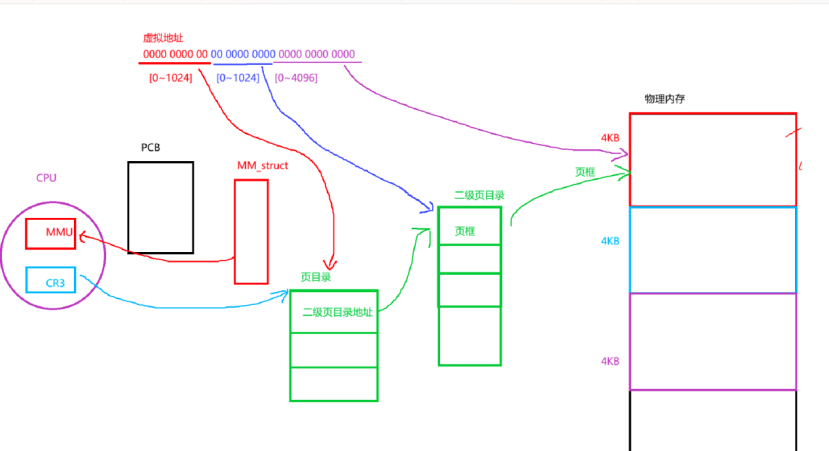
在 32 位架构中,虚拟地址到物理地址的转换依赖两级页表(这是 x86 等架构的典型设计),其核心目的是通过分级管理减少页表本身的内存开销。具体机制如下:
一、页表的分级设计
第一级页表(页目录,Page Directory):存储二级页表的物理基地址,整个系统(或进程)有一个页目录。
第二级页表(页表,Page Table):存储物理页框的基地址,每个页目录项对应一个二级页表。
二、32 位虚拟地址的拆分
32 位虚拟地址被划分为三部分(总长度 32 位),对应两级页表的索引和页内偏移:
高 10 位:页目录索引(用于定位页目录中对应的二级页表项);
中 10 位:页表索引(用于定位二级页表中对应的物理页框项);
低 12 位:页内偏移(物理页框内的具体位置,因页框大小为 4KB=2¹²,故 12 位足够)。
三、地址转换的完整流程
当 CPU 访问某个虚拟地址时,由内存管理单元(MMU) 硬件完成转换,依赖 CR3 寄存器和两级页表:
定位页目录:CR3 寄存器存储当前进程的页目录物理基地址,MMU 以此为起点访问页目录。
查找二级页表:用虚拟地址的高 10 位作为索引,在页目录中找到对应的表项 —— 该表项存储二级页表的物理基地址。同时,MMU 会检查表项中的 “存在位(P 位)”:若 P=0(表示二级页表不存在),则触发缺页异常(由内核处理,如动态创建页表)。
查找物理页框:用虚拟地址的中 10 位作为索引,在二级页表中找到对应的页框起始地址 —— 该表项存储目标物理页框的物理基地址(由物理页框号 PFN 左移 12 位得到)。同样检查 P 位:若 P=0,触发缺页异常(内核可能从磁盘加载数据到物理页)。
计算物理地址:将二级页表找到的物理页框基地址,加上虚拟地址的低 12 位页内偏移,最终得到完整的物理地址。
四、核心硬件与寄存器的作用
MMU:专用硬件,负责执行地址转换流程,无需 CPU 干预,保证转换效率。
CR3 寄存器:存储当前页目录的物理基地址,是进程切换时的关键切换项(不同进程有独立页目录,通过更新 CR3 实现地址空间隔离)。
结论:
- 所以我们malloc申请内存,本质是查询page数组,找到没有使用的page,找到page后通过page的下标就能获取到具体物理页框地址,接着建立映射关系。
- 所以缺页中断,内存申请等,在还没使用这些内存时候,OS并不会给我们建立页框的映射关系,当真正在使用时,OS发现你所使用的虚拟地址是合法的,但页表中并没有实际查询到与物理页框的映射关系,此时就会触发缺页中断,接着OS执行中断服务,申请物理内存,构建映射关系。
- 所以一张页目录表+n张页表构建的映射关系,虚拟地址就是索引,物理地址页框就是目标虚拟地址的低12位+页框地址=物理地址。
- 为什么是低12位?
- 首先页框大小是4KB,而2的12次方也是4KB,所以一个低12位就能充分覆盖一个页框的整个范围。
- 因此我们就可以通过4KB的前20位地址来判断是否处在同一个页框中。若前20位相同,则说明这两个地址位于同一个物理页框内,剩下的低12位则用于定位页框内的具体偏移位置。这种方式有效地将虚拟地址转换为了对应的物理地址,并实现了内存的按需分配与管理。通过这样的机制,操作系统能够高效地管理有限的物理内存资源,同时为每个进程提供独立且连续的虚拟地址空间。
再次深刻理解线程:
线程进行资源划分,本质是划分空间,获得一定范围内的合法虚拟地址,说白了就是划分页表。
线程进行资源共享时,本质是对地址空间的共享,说白了就是共享页表条目。
相比于进程之间的切换,对应线程切换来说操作系统所做的工作会更少,首先线程的虚拟地址是相同的,但进程不同,也就是说在进行线程切换时,不需要更改页表。
虽然线程强调共享,但不可否认的是线程也有自己独立的东西:
线程在进行切换时候,CPU同样要保存线程的上下文数据,本质就是线程的独立调度。
以及线程的栈是独立的结构,线程是一个动态的概念。
线程控制:
之前所谈论的都是线程的理论概念,为了验证上述理论,我们来进行线程控制的学习。
函数:int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *arg);
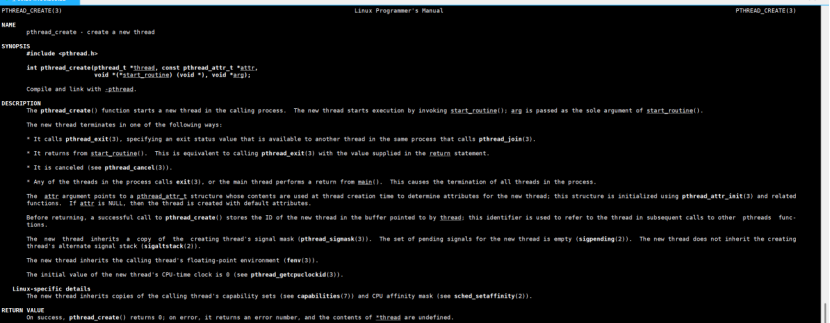
pthread_create 是 POSIX 线程库(如 Linux 下的 NPTL)中用于创建新线程的核心函数。它的作用是在当前进程中启动一个新的执行流(线程),该线程会执行指定的函数,并可接收传入的参数。
函数参数:
pthread_t *thread(输出参数)
作用:用于接收新创建线程的唯一标识符(用户级线程 ID)。
细节:pthread_t 是线程 ID 的类型(通常是结构体或整数),后续对线程的操作(如等待线程结束 pthread_join、取消线程 pthread_cancel)都需要通过这个 ID 进行。
注意:必须传入有效的指针(不能为 NULL),函数会将新线程的 ID 写入该指针指向的内存。
const pthread_attr_t *attr(输入参数,可选)
一般为NULL
void *(*start_routine) (void *)(输入参数,函数指针)
作用:新线程创建后要执行的入口函数(线程的 “主函数”)。
这是一个函数指针,指向的函数必须满足:参数为 void *(可接收任意类型数据),返回值为 void *(可返回任意类型结果)。
线程启动后会从该函数开始执行,函数执行完毕后线程自动终止。
若函数返回,返回值会被 pthread_join 捕获(若线程未分离)。
void *arg(输入参数,可选)
作用:传递给线程入口函数 start_routine 的参数。
Demo代码演示:
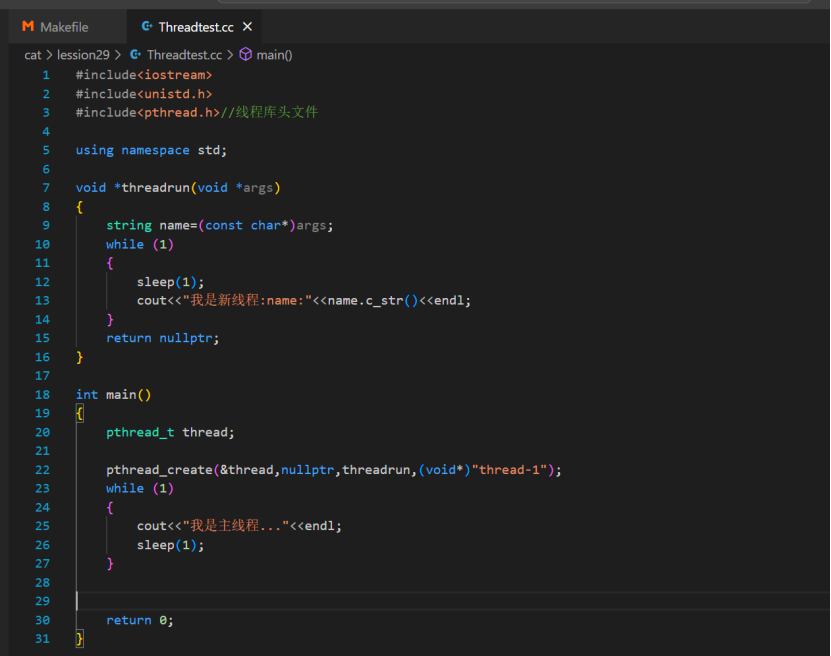
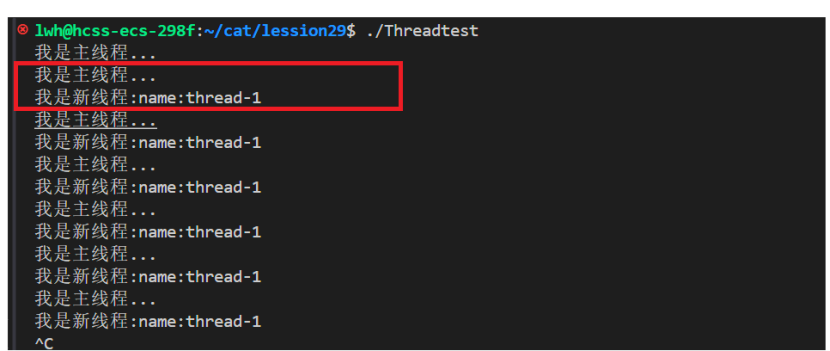
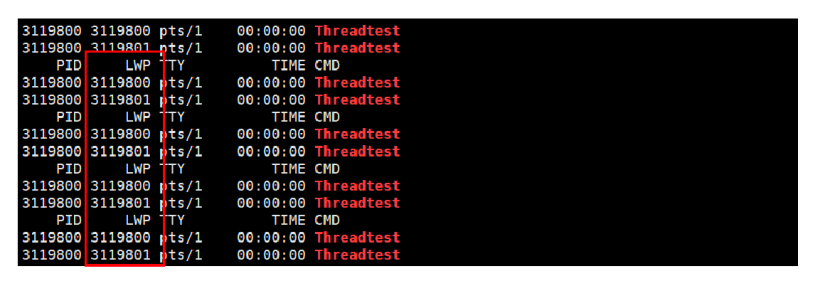
在Linux使用 ps -aL 命令用于查看当前线程信息
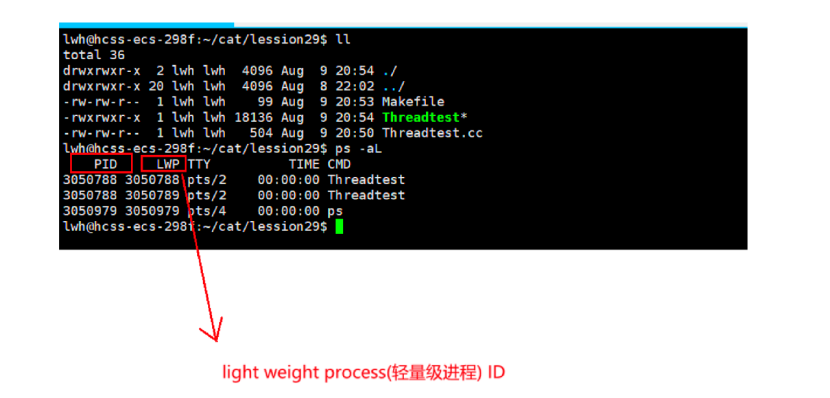
根据上图示例,我们确实创建新线程时,因为两个线程会同时往显示器文件上进程输出打印,并且使用 ps -aL查看到当前是用两个线程正在运行,它们的PID是一样的,LWP就是线程ID。
如果细心的话可以观察到我们的Makefile文件上除了正常链接C++的库,还额外链接pthread的第三方库。
Pthread库:
Pthread是一个线程库,因为Linux系统不存在所谓真正的线程,它所谓的概念本质上是由轻量级进程进行模拟的,因此Linux只会提供给你轻量级进程的系统调用。
那可能就会有疑问了,那我们直接是哦那个Linux提供的轻量级进程的系统调用不就好了吗,为什么还要多此一举?
那么其实在用户的角度上只有线程,因为所有操作系统的理念里只有线程的概念,只是Linux使用轻量级进程来模拟线程。那么在Windows操作系统的环境下是它是专门设计的线程的数据结构,采用真正的线程进行操控。
那么所有编译语言为了实现自己语言的跨平台的可移植性,在用户层面上,本质是对线程函数进行了封装,在Linux中用户态线程的函数,是调用Linux提供的轻量级进程的系统调用,而在Winodws又是它自己的调用函数,所以语言都是在各自的用户层又进行了一次封装。
函数 int pthread_join(pthread_t thread, void **retval);
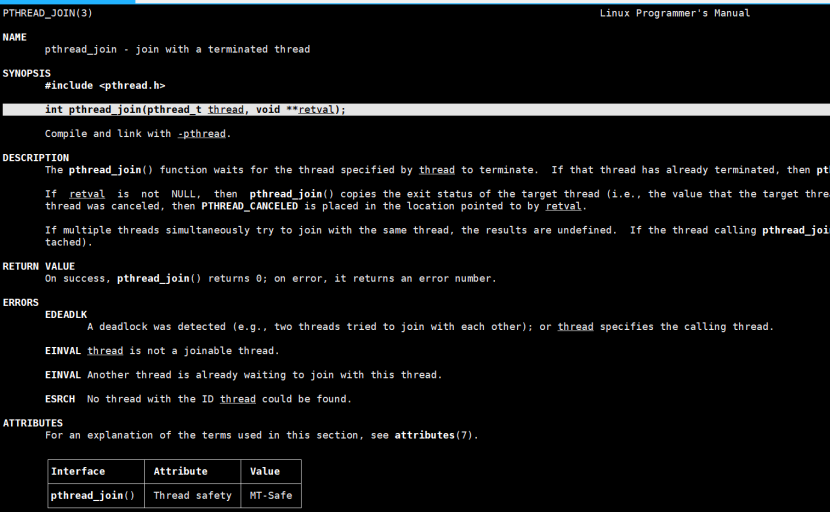
调用 pthread_join 的线程会阻塞自身,直到目标线程(thread 指定)终止。目标线程终止后,回收其占用的系统资源(如栈、内核结构体等),避免 “僵尸线程”。
函数参数:
pthread_t thread(输入参数)
含义:目标线程的 唯一标识符(线程 ID),由 pthread_create 创建线程时返回。
void **retval(输出参数,可选)
含义:用于存储目标线程的 退出状态
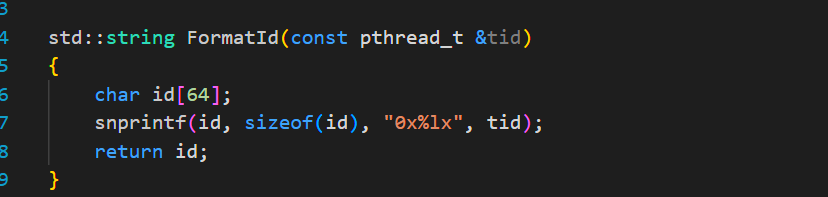
函数pthread_t pthread_self(void);
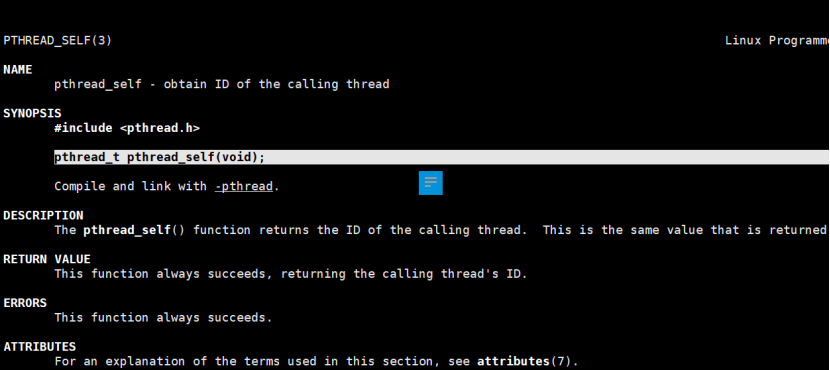
用于返回当前线程ID,这里的线程ID是用户级线程ID与之前见到的LWP是有区别的。
Demo代码:
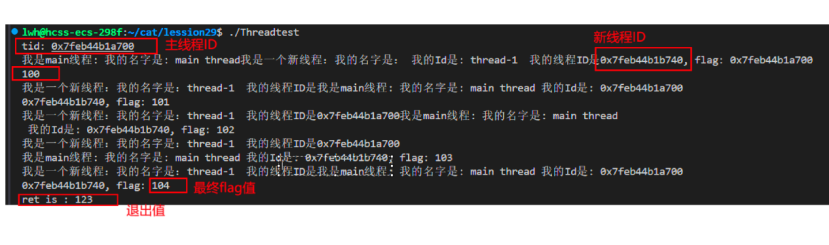
从上图可以看到,线程函数的退出值是可以被主线程拿到的,并且两个线程都能同时访问同一个函数,所以这个FormatID函数就是一个可重入函数
并且一个线程修改flag值,另一个线程也能拿到,这也印证了线程的资源共享理念。
但是 pthread_self(void)函数返回的线程ID跟LWP完全不一样,这里就涉及到用户级线程ID与内核级线程ID的区别,具体我们等后面再说。
因为线程传入的参数与返回值类型都是void,这也就说明了,线程参数与返回值可以传入任何类型,甚至是以对象的形式进行传递,为了验证这一点,我们来进行Deom代码测试
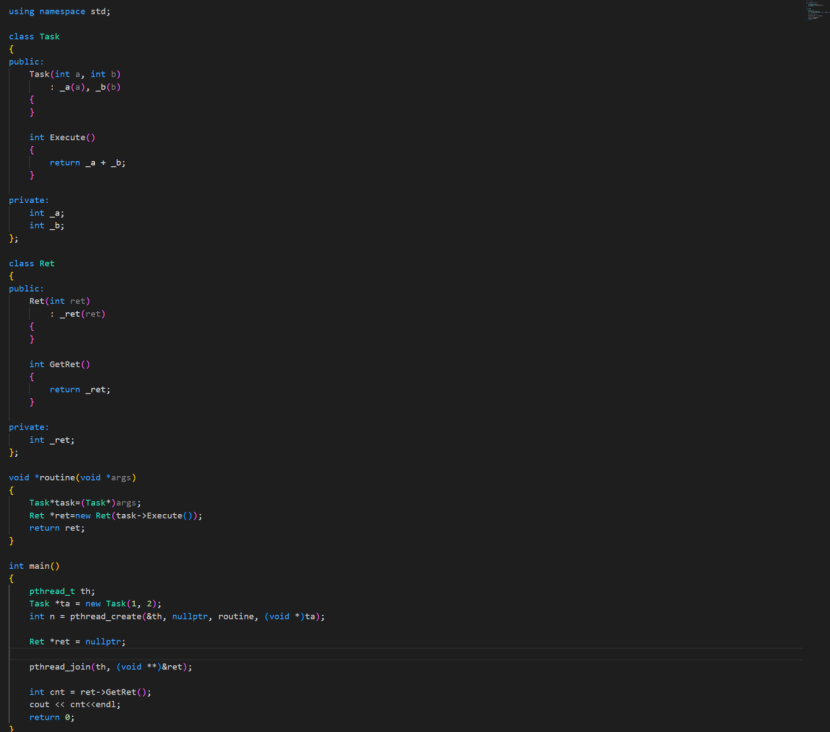
线程分离:
在线程设定中,主线程(main)是需要等待其他线程的退出,以防资源泄露,所以主线程就会在join处阻塞运行。那么如果主线程不想等待其他线程退出,或其他线程并不想让主线程进行阻塞等待。此时主线程可以为其他线程进行线程分离,或是其他线程主动与主线程进行分离。
对于分离的概念,我们在共享内存中也有介绍过。
函数int pthread_detach(pthread_t thread);
pthread_detach 是 POSIX 线程库中的一个函数,用于将指定线程标记为分离状态(detached)。处于分离状态的线程在执行结束后会自动释放所有资源(如栈空间、线程描述符等),无需其他线程调用 pthread_join 来回收资源,避免了资源泄漏。
参数thread标识需要分离的线程ID。
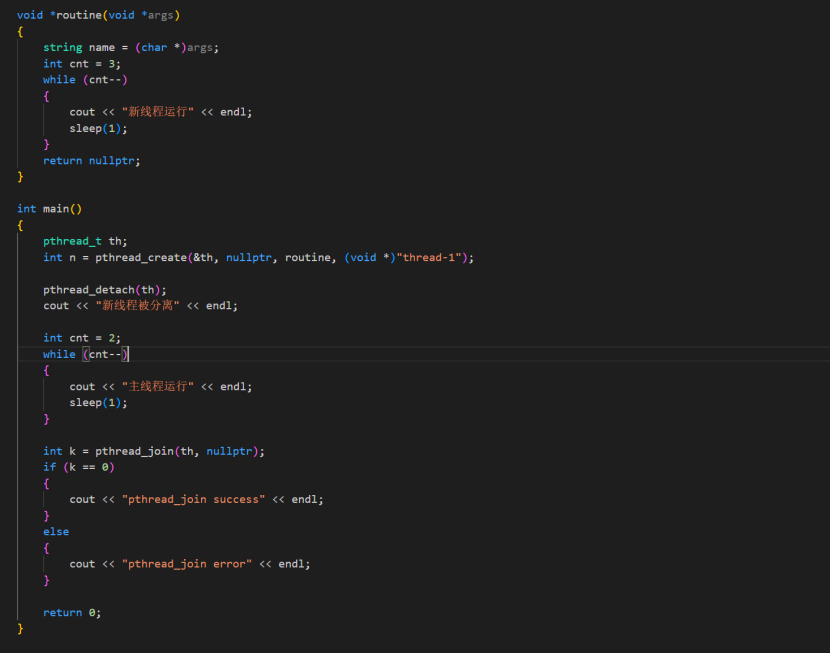
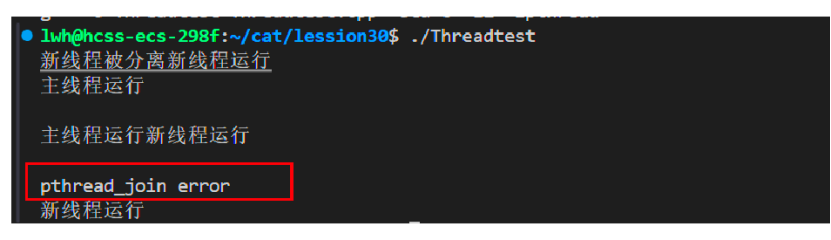
从上图可以看到,主线程结束后,进行join时候会失败,并且新线程还在继续运行。所以当进行线程分离的时候,主线程就不需要join了。上述也说过,新线程可以被主线程分离,同样的也可以进行自主分离操作。
分离的线程,依旧在进程的地址空间中,进程的所有资源,被分离的线程,依旧可以访问,可以操作。
线程终止:
我们在之前的学习中认识到exit函数可以终止进程,那么exit是否可以终止线程呢?
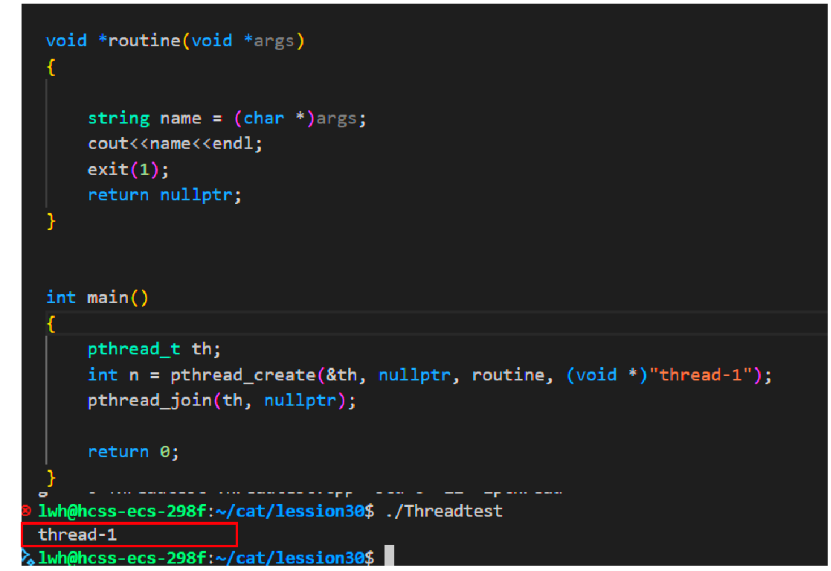
通过测试代码可以看见,exit只能用来终止进程,当线程调用exit会结束整个进程运行。
新线程结束通常只在return语句正常结束,如果想要主动结束线程,就要调用指定函数。
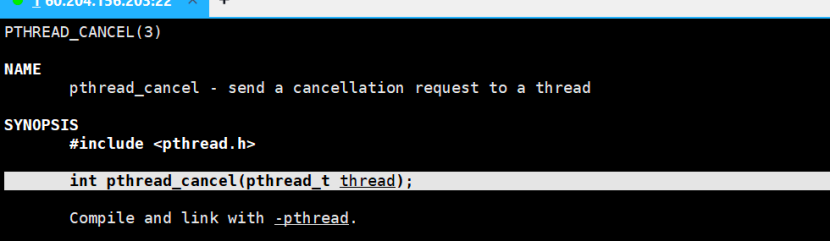
函数:int pthread_cancel(pthread_t thread);
![]()
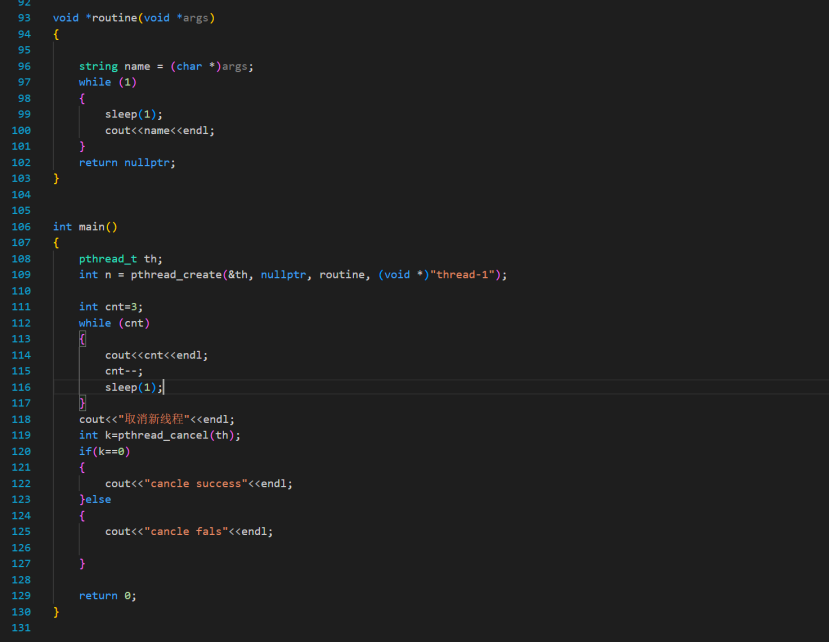
多线程:
介于之前写的代码最多只有两个线程,所以这次写一个多线程的简单demo
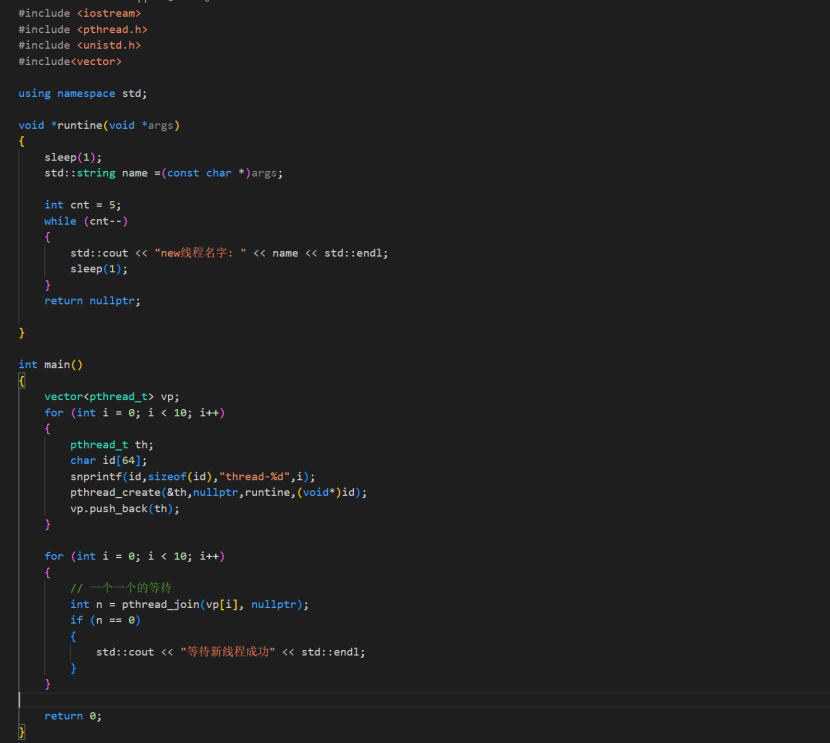
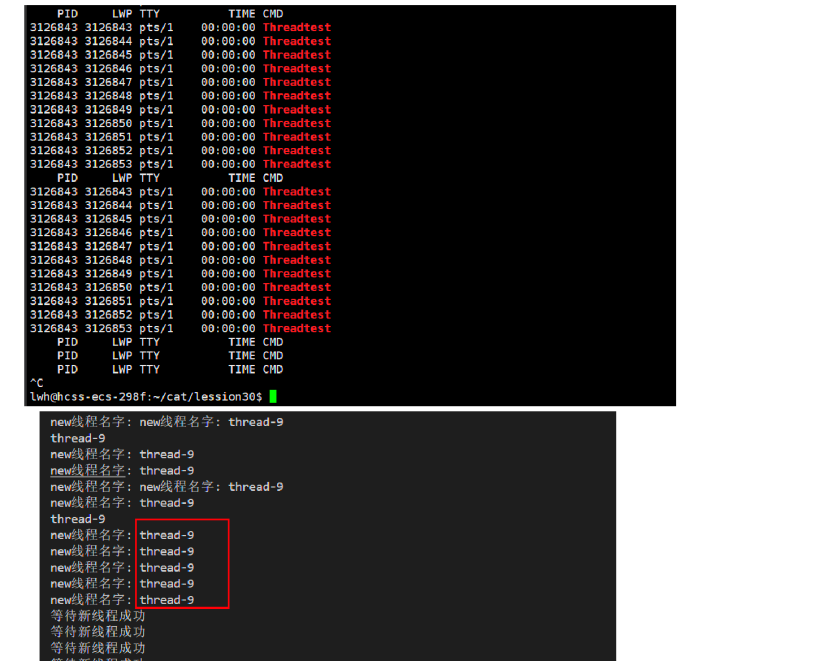
从上图可以发现,输出打印的新线程名字都是thread-9,而这并非我们所想的,原因是什么?
id 是循环体内的局部变量,其内存地址在每次循环中是相同的(栈上的同一块空间被重复使用)。
线程创建后并不会立即执行(存在调度延迟),而主线程的循环执行速度很快,会在子线程开始读取 id 之前,就已经将 id 反复覆盖为下一个值(最终覆盖为 thread-9)。
所有子线程最终读取的都是同一块内存(id 的地址),而此时这块内存已经被最后一次循环(i=9)的内容覆盖,因此所有线程都输出 thread-9。
为了解决这个问题,我们为id命名时并不应该在栈上使用空间,而是在堆上重新开辟空间。
用堆时,每个线程都会有独属自己的堆空间地址,就不会像栈一样复用地址,就解决了ID覆盖的问题。
再次剖析线程
Linux下没有真正的线程,都是用轻量级进程来进行模拟的,并且我们也看见了,LWP与pthread ID的不同。
操作系统不会直接提供线程接口,而是在用户层进行轻量级进程的封装,形成原生线程库也就是pthread库。
![]()
它是一个动态库,也是一个ELF文件格式的库。动态库也是一个可执行程序。所以我们的可执行程序加载形成进程,进行库的动态链接与动态地址的重定向时,就必须把动态库加载到内存并且映射到当前进程的地址空间中。
因此线程的概念的是在库中维护的,在库内部就一定会存在多个被创建好的线程,有些线程正在运行,有些线程需要退出,而有如此之多的线程,库就必须对这些线程进行管理。所以库要对线程进行管理,就必须”先描述,在组织”。

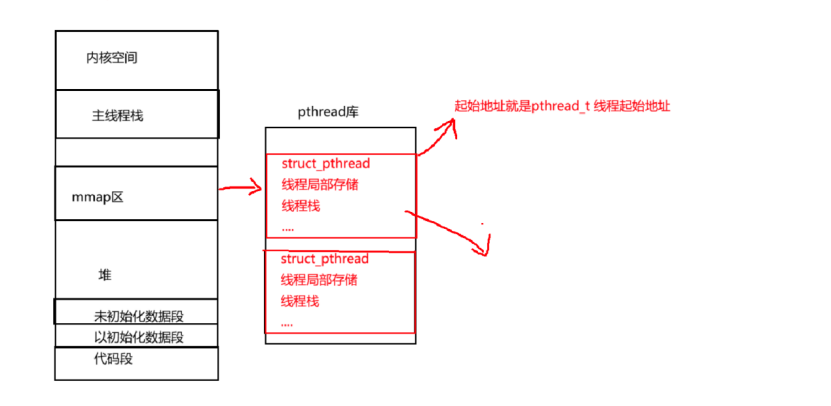
所以线程就应该如上图一样,拥有描述自己的结构体,并且也能知道所有的线程都会在pthread库中被管理起来。
重谈三个问题:
- 线程ID是什么?
所谓的线程ID,其实就是当我们在Creat创造线程时,pthread库在内存中帮我们申请了struct_pthread结构体里的起始地址。因此拿到了线程的起始地址就能对线程权限状态进行修改等操作。
所以线程在库中就是一个管理控制块,主线程就能在join时候释放新线程的地址。当有多个线程创建时候,就在pthread库中建立多个管理控制块。
- 线程传参与返回值
在之前我们主线程能对新线程能传参,并且还能获取新线程的返回值是为什么?
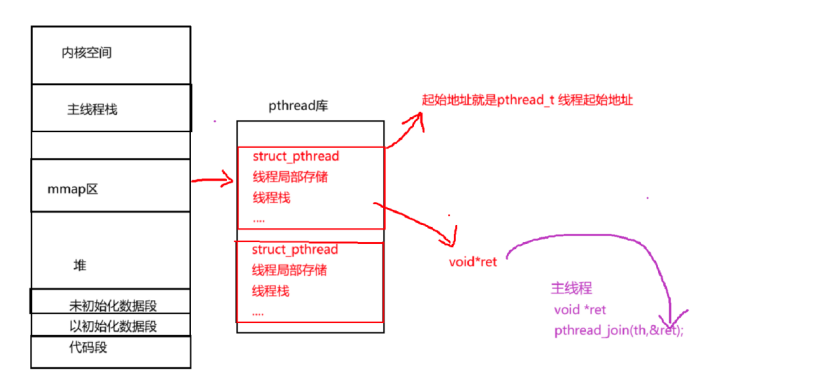
在线程的结构体里,有一个void*ret的变量,当线程运行结束时,就会把返回值写入ret里,那么我们主线程进行join时,会拿到子线程管理控制块的起始地址,再通过起始地址找到对应的void*ret,所以主线程就能获取到子线程的退出信息。
在传参中,主线程传递的是 参数的内存地址,而由于线程共享虚拟地址空间:
子线程看到的地址空间和主线程是完全重叠的(同一虚拟地址在不同线程中指向同一物理内存,除非发生写时复制,但传参一般是读操作)。
因此,子线程通过 args 拿到地址后,解引用就能直接读取主线程准备好的参数(如字符串、结构体等)。
- 线程分离
线程的分离状态(detached) 与可连接状态(joinable) 本质上是线程的两种生命周期管理状态,用于决定线程终止后资源的回收方式。在操作系统的线程控制块(TCB,即线程结构体)中,通常会通过一个标志位(如 detach_state)来标识这一状态:
当标志位为分离状态(如值为 1) 时,线程终止后会自动释放所有资源(如栈、线程描述符等),无需其他线程调用 pthread_join 回收。
当标志位为可连接状态(如值为 0) 时,线程终止后不会自动释放资源,必须由其他线程调用 pthread_join 等待其终止并回收资源,否则会产生 “僵尸线程”(资源泄漏)。
用户级线程与内核轻量级进程的联动:
Linux下我们用户所使用的线程库,本质上是在线程库里调用Linux的系统调用创建轻量级进程,而创建轻量级进程的函数是
int clone(int (*fn)(void *), void *stack, int flags, void *arg, ...
/* pid_t *parent_tid, void *tls, pid_t *child_tid */ );
但我们并不需要去学习底层clone函数,只需要掌握用户级线程库的调用方法,就能在任何平台下使用线程库函数,都是大同小异的。
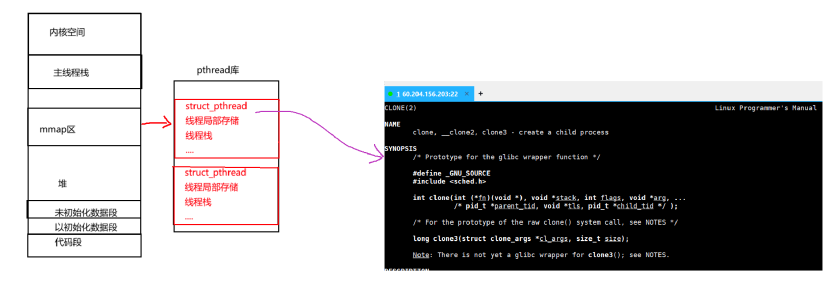
所以在调用pthread_creat时候,其实传入的是clone函数必要的参数,接着在pthread库里给我们再次调用clone,所以我们用户根本就不需要管Linux底层轻量级进程的创建过程。
---------本篇文章就到这里感谢各位观看