机器学习之词向量转换
机器学习中的词向量转换:从文本到数值的魔法
在机器学习和自然语言处理(NLP)领域,文本数据的处理始终是一个核心挑战。计算机无法直接理解人类语言,因此我们需要一种将文本转换为数值形式的技术 —— 这就是词向量(Word Embedding)的用武之地。本文将详细介绍词向量的基本概念、常见方法及实战应用,帮助你理解如何将文本数据转换为机器学习模型能够处理的数值特征。
一、词向量转换的原理
CountVectorizer 是 scikit-learn 库中的一个文本向量化工具,它将文本数据转换为词频特征矩阵。以下是 CountVectorizer 的算法原理和步骤:
1.原理
1.文本预处理:
分词:将文本分割成单词或短语(tokens)。
小写化:将所有单词转换为小写,以确保大小写不敏感。
去除停用词:可选步骤,移除常见的、意义不大的单词,如“the”、“is”等。
去除标点和特殊字符:可选步骤,清理文本中的非字母数字字符。
2.构建词汇表:
从所有文本中提取唯一的单词或短语,构建一个词汇表。
每个单词或短语被分配一个唯一的整数索引。
3.向量化:
根据词汇表,计算每个单词或短语在每个文本中的出现次数。
生成一个词频矩阵,其中行对应于文本,列对应于词汇表中的单词或短语。
4.n-gram 范围:
ngram_range=(1, 3) 表示考虑从单个单词(1-gram)到三词短语(3-gram)的所有组合。
这增加了模型能够捕捉的上下文信息的复杂性。
5.特征选择:
max_features=6 限制了词汇表中单词或短语的最大数量,选择最常见的6个特征。
2.算法步骤
1.初始化:
- 创建
CountVectorizer实例,设置参数如max_features和ngram_range。
from sklearn.feature_extraction.text import CountVectorizer
texts=['dog cat fish','dog cat cat','fisg bird','bird']
conts=[]
cv=CountVectorizer(max_features=6,ngram_range=(1,3))2.拟合(Fit):
cv_fit = cv.fit(texts)3.转换(Transform):
调用 transform 方法,将文本数据转换为词频矩阵。
cv_fit = cv.transform(texts)4.输出:
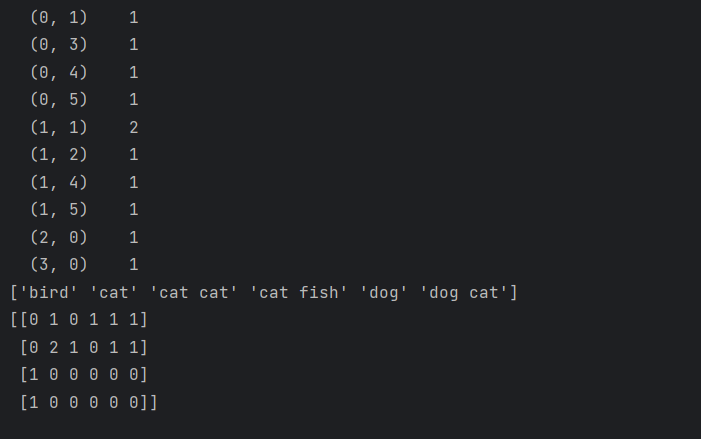
get_feature_names_out()方法返回词汇表中的单词或短语。toarray()方法将稀疏矩阵转换为常规数组,便于查看和分析。
print(cv.get_feature_names_out())
print(cv_fit.toarray())运行结果如下:
二、项目案列
项目背景与目标
在电商平台运营中,用户评论包含了大量有价值的信息。本项目旨在通过对商品评论进行情感分析,自动识别用户评论的情感倾向(好评 / 差评),帮助商家快速了解产品优缺点和用户需求,为产品改进和客户服务优化提供数据支持。
项目目标:
- 构建一个能够区分好评和差评的情感分析模型
- 实现从原始评论文本到情感预测的完整流程
- 分析评论中高频关键词,挖掘用户关注点
项目实施步骤
1. 导入必要的库
import pandas as pd
import jiebapandas:用于数据处理和存储,特别是 DataFrame 数据结构非常适合处理表格型数据jieba:中文分词工具,能够将连续的中文文本分割成有意义的词语
2. 读取评论文本数据
with open('优质好评.txt', 'r', encoding='utf-8') as file:positive_comments = [line.strip() for line in file if line.strip()]
with open('差评.txt', 'r', encoding='gbk') as file1:negative_comments = [line.strip() for line in file1 if line.strip()]- 分别读取好评和差评文件,注意两个文件使用了不同的编码(utf-8 和 gbk)
- 使用列表推导式处理每行文本:
line.strip()去除首尾空格和换行符 if line.strip()过滤空行,避免后续处理无效数据- 最终得到两个列表:
positive_comments(好评) 和negative_comments(差评)
评论数据图如下:


3. 中文分词处理
# 处理差评
cp = []
for content in negative_comments:results = jieba.lcut(content) # 使用jieba进行精确分词if len(results) > 1: # 过滤分词后词语数量小于等于1的评论cp.append(results)
cp_fc = pd.DataFrame({'content': cp})
cp_fc.to_excel('差评分词结果.xlsx', index=False)# 处理好评(与差评处理逻辑相同)
hp = []
for content in positive_comments:results = jieba.lcut(content)if len(results) > 1:hp.append(results)
hp_fc = pd.DataFrame({'content': hp})
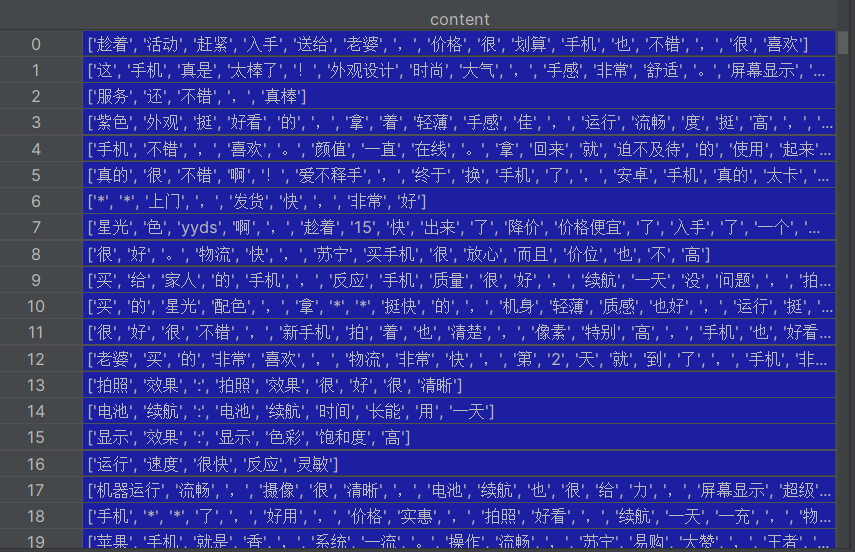
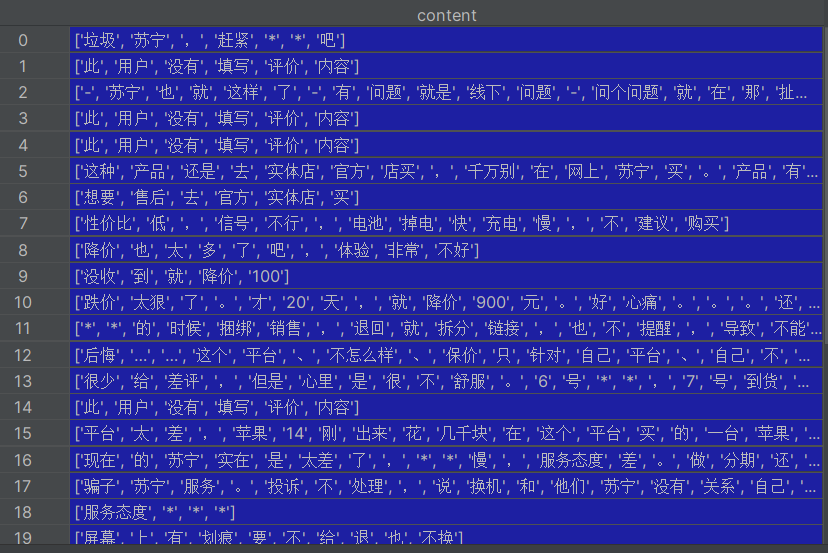
hp_fc.to_excel('好评分词结果.xlsx', index=False)jieba.lcut(content):对每条评论进行分词,返回词语列表- 过滤掉分词后词语数量≤1 的评论,因为这类文本通常信息量太少
- 将分词结果存储到 DataFrame 并导出为 Excel,方便后续查看和验证分词效果
处理完数据结果如下:
4. 停用词处理
# 读取停用词表
def read_stopwords(file_path, encoding='utf-8'):stopwords = []with open(file_path, 'r', encoding='utf-8') as f:for line in f:word = line.strip()if word: # 过滤空行stopwords.append(word)return stopwordsstopwords_list = read_stopwords('StopwordsCN1.txt', encoding='utf-8')# 去除文本中的停用词
def drop_stopwords(contents, stopwords):segments_clean = []for content in contents: # 遍历每条评论line_clean = []for word in content: # 遍历每个词语if word not in stopwords: # 保留非停用词line_clean.append(word)segments_clean.append(line_clean)return segments_clean停顿词文件如下:
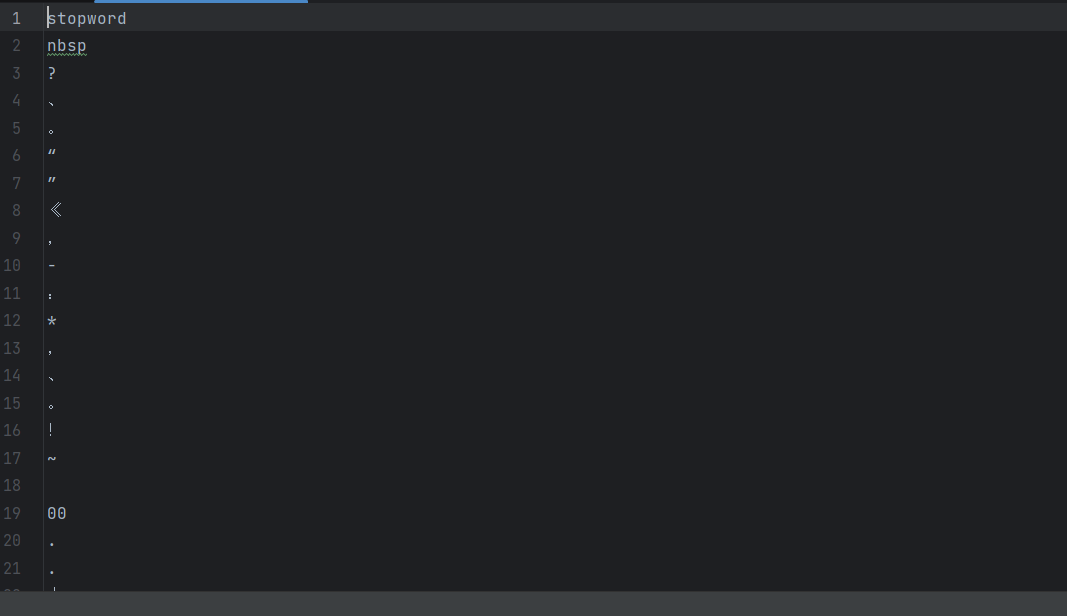
- 停用词是指对文本分析没有实际意义的词(如 "的"、"是"、"在" 等)
read_stopwords函数:从文件读取停用词列表drop_stopwords函数:过滤文本中的停用词,保留有意义的词汇
5. 应用停用词处理
# 处理差评数据
cp_contents = cp_fc['content'].tolist()
cp_fc_contents_clean_s = drop_stopwords(cp_contents, stopwords_list)# 处理好评数据
hp_contents = hp_fc['content'].tolist()
hp_fc_contents_clean_s = drop_stopwords(hp_contents, stopwords_list)- 将 DataFrame 中的分词结果转换为列表
- 应用
drop_stopwords函数去除停用词,得到净化后的词语列表
处理后的结果如下:

6. 构建训练数据集
# 为评论添加标签:1表示差评,0表示好评
cp_train = pd.DataFrame({'segments_clean': cp_fc_contents_clean_s, 'label': 1})
hp_train = pd.DataFrame({'segments_clean': hp_fc_contents_clean_s, 'label': 0})# 合并正负样本
pj_train = pd.concat([cp_train, hp_train])
pj_train.to_excel('pj_train.xlsx', index=False)- 为不同情感的评论添加标签:差评标记为 1,好评标记为 0
- 使用
pd.concat合并正负样本,构建完整的训练数据集 - 将合并后的数据集导出为 Excel,方便后续使用
7. 划分训练集和测试集
from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(pj_train['segments_clean'].values, # 特征数据:分词后的评论pj_train['label'].values, # 标签数据:0或1random_state=0, # 随机种子,保证结果可复现test_size=0.2 # 测试集占比20%
)- 使用
train_test_split将数据集划分为训练集 (80%) 和测试集 (20%) random_state=0确保每次运行划分结果一致,便于调试和比较- 返回四个变量:训练特征、测试特征、训练标签、测试标签
8. 文本特征提取
# 将分词列表转换为字符串格式
words = []
for line_index in range(len(x_train)):words.append(' '.join(x_train[line_index])) # 用空格连接词语# 使用CountVectorizer构建词袋模型
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(max_features=5000, # 保留词频最高的5000个词ngram_range=(1, 3) # 考虑1-3元语法(单个词、两个词组合、三个词组合)
)
vec.fit(words) # 拟合训练数据,构建词汇表
model = vec.fit_transform(words) # 将文本转换为词频矩阵- 文本特征提取是将文本转换为机器学习模型可识别的数值特征的关键步骤
- 先将词语列表转换为字符串(用空格分隔),因为
CountVectorizer要求输入为字符串 CountVectorizer参数说明:max_features=5000:限制特征数量,只保留出现频率最高的 5000 个词,避免维度灾难ngram_range=(1,3):不仅考虑单个词,还考虑连续的 2 个词和 3 个词组合,能捕捉更多语义信息model是一个稀疏矩阵,每行代表一条评论,每列代表一个词(或词组),值为该词在评论中出现的次数
提取文本之后的数据为:

这样就变成了模型可以训练的数据
总结
这段代码完整实现了中文评论情感分析的预处理流程,包括:
- 文本数据读取与清洗
- 中文分词处理
- 停用词去除
- 带标签数据集构建
- 训练集与测试集划分
- 文本特征提取(词袋模型)
这样就完成了从原始评论文本到特征提取的完整预处理流程。
完整代码如下:
import pandas as pd
import jieba
with open('优质好评.txt', 'r', encoding='utf-8') as file:positive_comments = [line.strip() for line in file if line.strip()]
with open('差评.txt', 'r', encoding='gbk') as file1:negative_comments = [line.strip() for line in file1 if line.strip()]
cp = []
for content in negative_comments:results = jieba.lcut(content)if len(results) > 1:cp.append(results)
cp_fc = pd.DataFrame({'content': cp})
cp_fc.to_excel('差评分词结果.xlsx', index=False)
hp = []
for content in positive_comments:results = jieba.lcut(content)if len(results) > 1:hp.append(results)
hp_fc = pd.DataFrame({'content': hp})
hp_fc.to_excel('好评分词结果.xlsx', index=False)
def read_stopwords(file_path, encoding='utf-8'):stopwords = []with open(file_path, 'r', encoding=encoding) as f:for line in f:word = line.strip()if word:stopwords.append(word)return stopwords
stopwords_list = read_stopwords('StopwordsCN1.txt', encoding='utf-8')
def drop_stopwords(contents, stopwords):segments_clean = []for content in contents:line_clean = []for word in content:if word not in stopwords:line_clean.append(word)segments_clean.append(line_clean)return segments_clean
cp_contents = cp_fc['content'].tolist()
cp_fc_contents_clean_s = drop_stopwords(cp_contents, stopwords_list)
hp_contents = hp_fc['content'].tolist()
hp_fc_contents_clean_s = drop_stopwords(hp_contents, stopwords_list)cp_train=pd.DataFrame({'segments_clean':cp_fc_contents_clean_s,'label':1})
hp_train=pd.DataFrame({'segments_clean':hp_fc_contents_clean_s,'label':0})
pj_train=pd.concat([cp_train,hp_train])
pj_train.to_excel('pj_train.xlsx',index=False)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(pj_train['segments_clean'].values,pj_train['label'].values,random_state=0,test_size=0.2)
words=[]
for line_index in range(len(x_train)):words.append(' '.join(x_train[line_index]))
print(words)
from sklearn.feature_extraction.text import CountVectorizer
vec=CountVectorizer(max_features=5000,ngram_range=(1,3))
vec.fit(words)
model=vec.fit_transform(words)
