深度学习模型实现高效公平调度-MU-MIMO场景
系统模型:
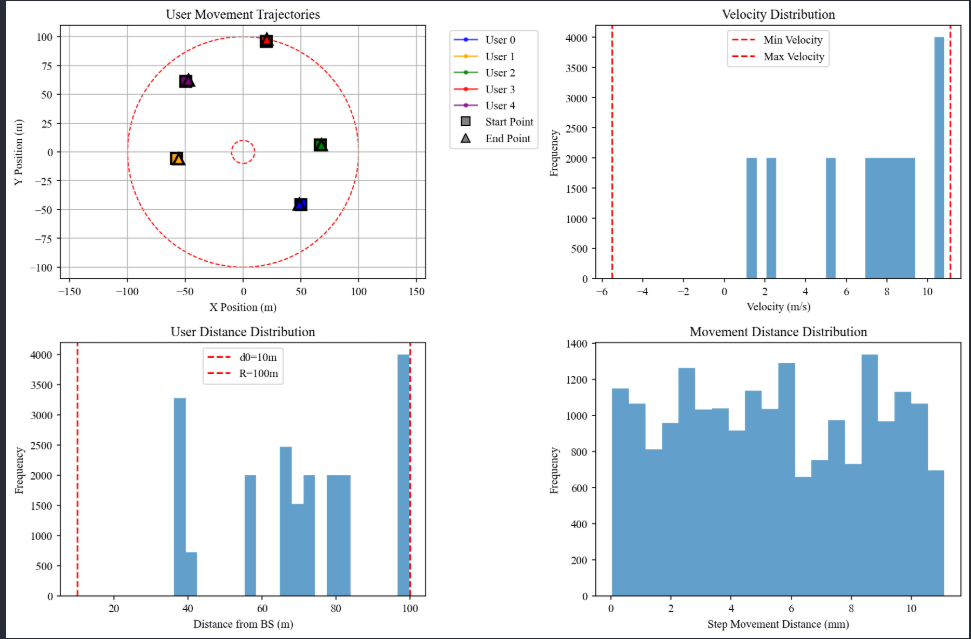
由于任务是在MU-MIMO模型下开展的,因此,前期通信系统模型搭建也非常重要。
考虑到用户移动性质,我们在两类常用信道模型中都引入了移动性,模拟真实世界的用户运动
算法设计:
实现了传统迭代式算法
PF,Greedy,SUS,RR
基于NN实现了CNN,aTTENTION,C-ATTENTION网络
实验结果说明,所提出网络相比于单一模块的网络能够实现更好的拟合,不会仅关注一小部分信道条件最好的用户而忽视了整体的公平性,在整个调度周期内,模型实现的调度频率对每个用户来说都是大致均匀的,因此,我们认为所提出模型能够最好拟合PF调度,并且在运行时间上面,相比于迭代式的PF将会随着系统内用户数量的增加迭代次数也会增加,而所提出算法能够通过一次前向传播就获得相似效果的输出,大大减少运行时间,增加实际部署可能性。
后续代码将在github开源;