机器学习⑤【线性回归(Linear Regression】
文章目录
- 先言
- 一、线性回归简介
- 1.什么是线性回归
- 2.问题定义给定特征 X和目标 y,拟合线性关系 y=wX+b。
- 二、损失函数定义和公式求解
- 三、最小二乘法(OLS)
- 1.数学目标:最小化残差平方和 ∑(wx−y)^2。
- 2.解析解:w=(XTX)−1XTy 的推导与局限性(计算复杂度高、需矩阵可逆)
- 四、梯度下降(Gradient Descent)
- 1.核心思想:通过迭代调整参数 w 和 b,逐步逼近最优解
- 2.详细步骤(梯度下降公式)
- 五、梯度下降的三大变种思想
- 1.批量梯度下降(BGD):全量数据计算梯度,稳定但慢。
- 2.随机梯度下降(SGD):单样本更新,快但波动大。
- 3.小批量梯度下降(MBGD):平衡速度与稳定性(深度学习常用)。
- 结语
先言
在机器学习的入门阶段,线性回归(Linear Regression)是最基础且最重要的算法之一。它不仅是理解统计建模的起点,也是后续复杂模型(如逻辑回归、神经网络)的基石。
本文将深入讲解:
线性回归的原理:如何用数学描述变量间的线性关系?
最小二乘法(OLS):为什么它是线性回归的经典解法?
梯度下降(Gradient Descent):如何通过迭代优化模型参数?
无论你是初学者还是希望巩固基础,这篇文章都会让你对线性回归的核心思想有清晰的认识!
一、线性回归简介
线性回归(Linear Regression)是机器学习中最基础且广泛应用的算法之一。
1.什么是线性回归
线性回归是机器学习中一种有监督学习的算法,回归问题主要关注的是因变量(需要预测的值)和一个或多个数值型的自变量(预测变量)之间的关系.
需要预测的值:即目标变量,target,y
影响目标变量的因素:X1,X2...XnX_1,X_2...X_nX1,X2...Xn,可以是连续值也可以是离散值
因变量和自变量之间的关系:即模型,model,就是我们要求解的
人工智能中的线性回归:数据集中,往往找不到一个完美的方程式来100%满足所有的y目标
我们就需要找出一个最接近真理的方程式
2.问题定义给定特征 X和目标 y,拟合线性关系 y=wX+b。
线性回归 (Linear Regression) 是一种用于预测连续值的最基本的机器学习算法,它假设目标变量 y 和特征变量 x 之间存在线性关系,并试图找到一条最佳拟合直线来描述这种关系。
y = w * x + b
其中:
- y 是预测值
- x 是特征变量
- w 是权重 (斜率)
- b 是偏置 (截距)
二、损失函数定义和公式求解
所有样本数据经过模型训练后,测试集中通过模型预测得到真事值和预测值之间的差距,这就是损失我们通过方差的形式描述这一种差距我们就叫做损失:
loss=(y1−y1,)2+(y2−y2,)2+....(yn−yn,)2{(y_1-y_1^,)^2}+{(y_2-y_2^,)^2}+....{(y_n-y_n^,)^2}(y1−y1,)2+(y2−y2,)2+....(yn−yn,)2
线性回归的目标是找到最佳的 w 和 b,使得预测值 y 与真实值之间的误差最小。常用的误差函数是均方误差 (MSE),就得到的下面的损失函数:
eˉ=1n∑i=1n(yi−wxi−b)2\bar e = \frac{1}{n} \textstyle\sum_{i=1}^{n}(y_{i}-w x_{i} - b)^{2}eˉ=n1∑i=1n(yi−wxi−b)2
- yiy_iyi 是实际值。
- wxi−bw x_{i} - bwxi−b 是预测值。
- n 是数据点的数量。
我们的目标是通过调整 w 和 b ,使得 MSE 最小化,这里讲述了两种方式求解:
- 最小二乘法
- 梯度下降求解
三、最小二乘法(OLS)
最小二乘法是一种常用的求解线性回归的方法,它通过求解矩阵方程的方法来找到最佳的 ( w ) 和 ( b )。
1.数学目标:最小化残差平方和 ∑(wx−y)^2。
最小二乘法的目标是最小化残差平方和(RSS),其公式为:

通过最小化 RSS,可以得到以下正规方程:
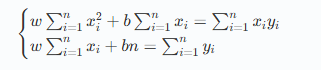
转为矩阵方程:
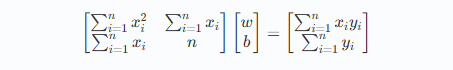
这是最小二乘法的整体数学概念,而我们的目标就是对此矩阵求解。
2.解析解:w=(XTX)−1XTy 的推导与局限性(计算复杂度高、需矩阵可逆)
对此类矩阵求解有两种方式:
第一种方式高斯最小二乘法
loss=[(h1(x)−y1)2+(h2(x)−y2)2+...(hn(x)−yn)2]/nloss=[(h_1(x)-y_1)^2+(h_2(x)-y_2)^2+...(h_n(x)-y_n)^2]/nloss=[(h1(x)−y1)2+(h2(x)−y2)2+...(hn(x)−yn)2]/n
=1n∑i=1n(h(xi)−yi)2\\=\frac{1}{n} \textstyle\sum_{i=1}^{n}(h(x_{i})-y_{i})^{2}=n1∑i=1n(h(xi)−yi)2
=1n∣∣(XW−y)∣∣2\\=\frac{1}{n}||(XW-y)||^2=n1∣∣(XW−y)∣∣2
=12∣∣(XW−y)∣∣2\\=\frac{1}{2}||(XW-y)||^2=21∣∣(XW−y)∣∣2
这就是传说中的最小二乘法公式 ∣∣A∣∣2\ ||A||^2 ∣∣A∣∣2 是欧几里得范数的平方,也就是每个元素的平方相加
通过矩阵求导运算和求导法则对上式求导得到求导后方程:
loss′=XTXW−XTyloss'=X^TXW-X^Tyloss′=XTXW−XTy
令导数loss′=0loss'=0loss′=0可得到损失的极小值
0=XTXW−XTy0=X^TXW-X^Ty0=XTXW−XTy
XTXW=XTyX^TXW=X^TyXTXW=XTy
矩阵没有除法,使用逆矩阵转化
(XTX)−1(XTX)W=(XTX)−1XTy(X^TX)^{-1}(X^TX)W=(X^TX)^{-1}X^Ty(XTX)−1(XTX)W=(XTX)−1XTy
W=(XTX)−1XTyW=(X^TX)^{-1}X^TyW=(XTX)−1XTy
第二种方式链式求导(推荐,因为后期深度学习全是这种):
内部函数是f(W)=XW−yf(W) = XW - yf(W)=XW−y,外部函数是 g(u)=12u2g(u) = \frac{1}{2} u^2g(u)=21u2,其中 u=f(W)u = f(W)u=f(W)。
外部函数的导数:
∂g∂u=u=XW−y\frac{\partial g}{\partial u} = u = XW - y ∂u∂g=u=XW−y
内部函数的导数:
∂f∂W=XT\frac{\partial f}{\partial W} = X^T ∂W∂f=XT
应用链式法则,我们得到最终的梯度:
∂L∂W=(∂g∂u)(∂f∂W)=(XW−y)XT\frac{\partial L}{\partial W} = \left( \frac{\partial g}{\partial u} \right) \left( \frac{\partial f}{\partial W} \right) = (XW - y) X^T ∂W∂L=(∂u∂g)(∂W∂f)=(XW−y)XT
对这个感兴趣的可以去看看最小二乘法详解
四、梯度下降(Gradient Descent)
使用正规方程W=(XTX)−1XTyW=(X^TX)^{-1}X^TyW=(XTX)−1XTy 求解要求X的特征维度(x1,x2,x3...)(x_1,x_2,x_3...)(x1,x2,x3...) 不能太多,逆矩阵运算时间复杂度为O(n3)O(n^3)O(n3) , 也就是说如果特征x的数量翻倍,计算时间就是原来的232^323倍,8倍太恐怖了,假设2个特征1秒,4个特征8秒,8个特征64秒,16个特征512秒,而往往现实生活中的特征非常多,尤其是大模型,运行时间太长了
所以 正规方程求出最优解并不是机器学习和深度学习常用的手段,梯度下降算法更常用
1.核心思想:通过迭代调整参数 w 和 b,逐步逼近最优解
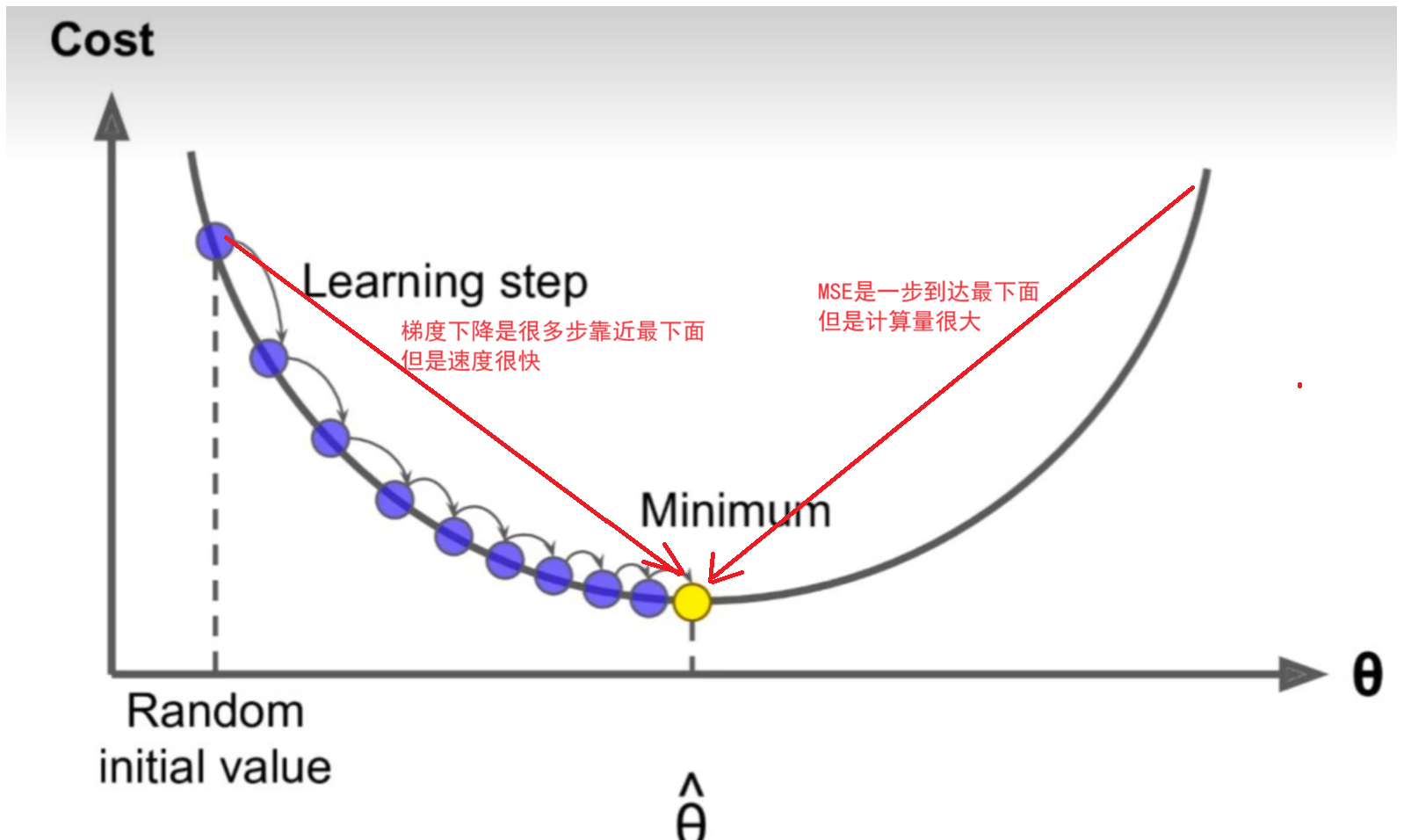
往期文章中有讲到过梯度的概念,没看过的可以回顾一下梯度的定义以及数学意义
在机器学习中,梯度表示损失函数对于模型参数的偏导数。具体来说,对于每个可训练参数,梯度告诉我们在当前参数值下,沿着每个参数方向变化时,损失函数的变化率。通过计算损失函数对参数的梯度,梯度下降算法能够根据梯度的信息来调整参数,朝着减少损失的方向更新模型,从而逐步优化模型
2.详细步骤(梯度下降公式)
梯度下降流程就是“猜"正确答案的过程:
1、Random随机数生成初始W,随机生成一组成正太分布的数值w0,w1,w2....wnw_0,w_1,w_2....w_nw0,w1,w2....wn,这个随机是成正太分布的(高斯说的)
2、求梯度g,梯度代表曲线某点上的切线的斜率,沿着切线往下就相当于沿着坡度最陡峭的方向下降.
3、if g < 0,w变大,if g >0,w变小(目标左边是斜率为负右边为正 )
4、判断是否收敛,如果收敛跳出迭代,如果没有达到收敛,回第2步再次执行2~4步收敛的判断标准是:随着迭代进行查看损失函数Loss的值,变化非常微小甚至不再改变,即认为达到收敛
公式:

skearn库中不支持内部求导函数这里我们模拟一下梯度下降的过程:
import numpy as np
#损失函数
def e(w):return 10*w**2-15.9*w+6.5
#模拟求偏导(梯度)
def g(w):return 20*w-15.9
w = 11
print(w)
a=0.001
while True:w_new= w-a*g(w)print(w_new)if abs(w_new-w)<0.000000000001:breakw = w_newprint(w_new)
print(e(w_new))
数据变化:
7.338146953431016
7.207284014362395
7.079038334075148
6.9533575673936445
6.830190416045772
6.709486607724856
6.591196875570359
6.475272938058952
6.361667479297773
6.250334129711817
6.141227447117581
6.03430289817523
5.929516840211725
5.82682650340749
损失值:
233.7167082485721
随着梯度的变化率越来越小损失函数的值接近极小值
这里的学习率表示梯度下降的变化速度更具实际实验而定或者通过梯度下降的循环结构使学习率岁梯度下降的同时变化,下图是学习率对梯度下降的影响直观图:

五、梯度下降的三大变种思想
1.批量梯度下降(BGD):全量数据计算梯度,稳定但慢。
原理:
批量梯度下降的基本思想是在每个迭代步骤中使用所有训练样本来计算损失函数的梯度,并据此更新模型参数。这使得更新方向更加准确,因为它是基于整个数据集的梯度,而不是像随机梯度下降那样仅基于单个样本。
更新规则
假设我们有一个包含 ( m ) 个训练样本的数据集
{(x(i),y(i))}i=1m\{(x^{(i)}, y^{(i)})\}_{i=1}^{m} {(x(i),y(i))}i=1m
,其中 $ x^{(i)} 是输入特征,是输入特征,是输入特征, y^{(i)} $ 是对应的标签。我们的目标是最小化损失函数 $J(\theta) $ 相对于模型参数 $ \theta $ 的值。
损失函数可以定义为:
J(θ)=12m∑i=1m(hθ(x(i))−y(i))2J(\theta) = \frac{1}{2m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)})^2 J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2
其中 $ h_\theta(x^{(i)}) $ 是模型对第 $ i $ 个样本的预测输出。
批量梯度下降的更新规则为:
θj:=θj−α1m∑i=1m(hθ(x(i))−y(i))⋅xj(i)\theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)}) \cdot x_j^{(i)} θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))⋅xj(i)
对于 $ j = 0, 1, \ldots, n $ (其中 $n $ 是特征的数量),并且 $ \alpha $ 是学习率。
特点
- 准确性:由于使用了所有训练样本,所以得到的梯度是最准确的,这有助于找到全局最小值。
- 计算成本:每次更新都需要遍历整个数据集,因此计算量较大,特别是在数据集很大的情况下。
- 收敛速度:虽然每一步的更新都是准确的,但由于计算成本较高,实际收敛到最小值的速度可能不如其他方法快。
- 内存需求:需要在内存中存储整个数据集,对于大型数据集来说可能成为一个问题。
使用场景
- 小数据集:当数据集较小时,批量梯度下降是一个不错的选择,因为它能保证较好的收敛性和准确性。
- 不需要实时更新:如果模型不需要实时更新,例如在离线训练场景下,批量梯度下降是一个合理的选择。
实现注意事项
- 选择合适的学习率:选择合适的学习率对于快速且稳定的收敛至关重要。如果学习率太小,收敛速度会很慢;如果太大,则可能会导致不收敛。
- 数据预处理:对数据进行标准化或归一化,可以提高批量梯度下降的效率。
- 监控损失函数:定期检查损失函数的变化趋势,确保算法正常工作并朝着正确的方向前进。
2.随机梯度下降(SGD):单样本更新,快但波动大。
随机梯度下降(Stochastic Gradient Descent, SGD)是一种常用的优化算法,在机器学习和深度学习领域中广泛应用。与批量梯度下降(BGD)和小批量梯度下降(MBGD)相比,SGD 每一步更新参数时仅使用单个训练样本,这使得它更加灵活且计算效率更高,特别是在处理大规模数据集时。
基本步骤
-
初始化参数:
- 选择一个初始点作为参数向量 θ\thetaθ的初始值。
-
选择样本:
- 随机选取一个训练样本$
(x(i),y(i))(x^{(i)}, y^{(i)}) (x(i),y(i))
$。
- 随机选取一个训练样本$
-
计算梯度:
- 使用所选样本 (x(i),y(i))(x^{(i)}, y^{(i)})(x(i),y(i))来近似计算损失函数 $J(\theta) $的梯度 ∇J(θ)\nabla J(\theta)∇J(θ)。
-
更新参数:
-
根据梯度的方向来更新参数 θ\thetaθ。更新公式为:
θ:=θ−α⋅∇J(θ)\theta := \theta - \alpha \cdot \nabla J(\theta) θ:=θ−α⋅∇J(θ) -
其中 α\alphaα 是学习率,决定了每次迭代时参数更新的步长。
-
-
重复步骤 2 到 4:
- 对所有的训练样本重复此过程,直到完成一个完整的 epoch(即所有样本都被访问过一次)。
-
重复多个 epoch:
- 重复上述过程,直到满足某个停止条件,比如达到最大迭代次数或者梯度足够小。
-
输出结果:
- 输出最小化损失函数后的最优参数 θ∗\theta^*θ∗。
更新规则
参数 θ\thetaθ 的更新规则为:
θj:=θj−α⋅∂J(θ)∂θj\theta_j := \theta_j - \alpha \cdot \frac{\partial J(\theta)}{\partial \theta_j} θj:=θj−α⋅∂θj∂J(θ)
注意事项
- 学习率 α\alphaα: 需要适当设置,太大会导致算法不收敛,太小则收敛速度慢。
- 随机性: 每次迭代都从训练集中随机选择一个样本,这有助于避免陷入局部最小值。
- 停止条件: 可以是达到预定的最大迭代次数,或者梯度的范数小于某个阈值。
示例如下(代码):
from sklearn.datasets import fetch_california_housing
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error
#获取数据集
x,y = fetch_california_housing(return_X_y=True,data_home='../src')
print(x.shape)
#数据集划分
x_train,x_test,y_train,y_test= train_test_split(x,y,test_size=0.2,random_state=42)
#数据标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
#创建模型
model = SGDRegressor(loss="squared_error",learning_rate="constant",#学习率设为常数max_iter=1000,#训练次数eta0=0.01)
model.fit(x_train,y_train)
y_predict = model.predict(x_test)
print("测试集上的均方误差为:",mean_squared_error(y_test,y_predict))
3.小批量梯度下降(MBGD):平衡速度与稳定性(深度学习常用)。
原理
小批量梯度下降的基本思想是在每个迭代步骤中使用一小部分(即“小批量”)训练样本来计算损失函数的梯度,并据此更新模型参数。这样做的好处在于能够减少计算资源的需求,同时保持一定程度的梯度准确性。
更新规则
假设我们有一个包含 ( m ) 个训练样本的数据集 {(x(i),y(i))}i=1m\{(x^{(i)}, y^{(i)})\}_{i=1}^{m}{(x(i),y(i))}i=1m,其中 $ x^{(i)} $ 是输入特征,$y^{(i)} $ 是对应的标签。我们将数据集划分为多个小批量,每个小批量包含 ( b ) 个样本,其中 ( b ) 称为批量大小(batch size),通常 ( b ) 远小于 ( m )。
损失函数可以定义为:
$ J(\theta) = \frac{1}{2m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y{(i)})2 $
其中 $ h_\theta(x^{(i)}) $ 是模型对第 $ i $ 个样本的预测输出。
小批量梯度下降的更新规则为:
$ \theta_j := \theta_j - \alpha \frac{1}{b} \sum_{i \in B} (h_\theta(x^{(i)}) - y^{(i)}) \cdot x_j^{(i)} $
对于 $ j = 0, 1, \ldots, n $ (其中 $n $是特征的数量),并且 $ \alpha $ 是学习率,$ B $ 表示当前小批量中的样本索引集合。
特点
- 计算效率:相比于批量梯度下降,小批量梯度下降每次更新只需要处理一部分数据,减少了计算成本。
- 梯度估计:相比于随机梯度下降,小批量梯度下降提供了更准确的梯度估计,这有助于更稳定地接近最小值。
- 内存需求:相比批量梯度下降,小批量梯度下降降低了内存需求,但仍然比随机梯度下降要高。
- 收敛速度与稳定性:小批量梯度下降能够在保持较快的收敛速度的同时,维持相对较高的稳定性。
使用场景
- 中等规模数据集:当数据集大小适中时,小批量梯度下降是一个很好的折衷方案,既能够高效处理数据,又能够保持良好的收敛性。
- 在线学习:在数据流式到达的场景下,小批量梯度下降可以有效地处理新到来的数据批次。
- 分布式环境:在分布式计算环境中,小批量梯度下降可以更容易地在多台机器上并行执行。
实现注意事项
- 选择合适的批量大小:批量大小的选择对性能有很大影响。较大的批量可以减少迭代次数,但计算成本增加;较小的批量则相反。
- 选择合适的学习率:选择合适的学习率对于快速且稳定的收敛至关重要。如果学习率太小,收敛速度会很慢;如果太大,则可能会导致不收敛。
- 数据预处理:对数据进行标准化或归一化,可以提高小批量梯度下降的效率。
- 监控损失函数:定期检查损失函数的变化趋势,确保算法正常工作并朝着正确的方向前进。
在sklearn库中没有有关批量和小批量下降的API我们可以通过使用SGD手动实现一下小批量梯度下降的方法:
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import math
import numpy as np
ch = fetch_california_housing(data_home="../src")
# print(ch.data)
#数据集划分
X_train, X_test, y_train, y_test = train_test_split(ch.data, ch.target, test_size=0.2, random_state=42)
print(X_train.shape,y_train.shape)
#数据集标准化
transfer = StandardScaler()
X_train = transfer.fit_transform(X_train)
X_test = transfer.transform(X_test)
#创建模型
model = SGDRegressor(loss="squared_error",learning_rate="constant",#学习率设为常数max_iter=1000,#训练次数eta0=0.01,shuffle=True)
#每次训练的批次大小
batch_size = 32
#训练的次数
batchs = math.ceil(len(X_train)/batch_size)
#训练集大小
size = len(X_train)
print(size)
#打乱数据集索引
indexs = np.arange(size)
# indexs = np.random.permutation(len(X_train))
np.random.shuffle(indexs)
print(indexs)#训练轮次
ss = 10
for s in range(ss):for i in range(batchs):index = indexs[i*batch_size:min((i+1)*batch_size,size)]y = y_train[index]X = X_train[index]#训练模型model.partial_fit(X,y)print(f"第{s+1}/{ss}次训练,loss:",mean_squared_error(y_test,model.predict(X_test)))结语
线性回归看似简单,却是理解机器学习优化思想的窗口。梯度下降不仅是线性回归的求解工具,更是深度学习的基础。希望本文能帮助你掌握其核心数学原理和实现技巧!
🔍 思考:如果数据存在多重共线性,梯度下降和OLS分别会面临什么问题?欢迎在评论区讨论!
📌 下一篇预告:逻辑回归(Logistic Regression)——从线性回归到分类任务的跨越!