AI大模型基础:BERT、GPT、Vision Transformer(ViT)的原理、实现与应用

🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#,Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用,熟悉DICOM医学影像及DICOM协议,业余时间自学JavaScript,Vue,qt,python等,具备多种混合语言开发能力。撰写博客分享知识,致力于帮助编程爱好者共同进步。欢迎关注、交流及合作,提供技术支持与解决方案。\n技术合作请加本人wx(注明来自csdn):xt20160813
AI大模型基础:BERT、GPT、Vision Transformer(ViT)的原理、实现与应用
大模型是现代人工智能的核心,广泛应用于自然语言处理(NLP)、计算机视觉(CV)等领域。本文将深入讲解三种典型大模型——BERT、GPT和Vision Transformer(ViT)的原理、实现方法及在实际场景中的应用,适合对AI大模型感兴趣的读者。文章结构如下:
- 大模型概述:定义、发展背景及在NLP和CV中的重要性。
- BERT:原理、实现及应用(如文本分类)。
- GPT:原理、实现及应用(如文本生成)。
- Vision Transformer (ViT):原理、实现及应用(如图像分类)。
- 流程图与图表:提供Mermaid流程图及性能对比图表。
- 总结与展望:总结大模型的特点及未来发展趋势。
一、大模型概述
1.1 定义与目标
大模型指参数量巨大(通常亿级以上)的深度学习模型,通过大规模数据预训练和微调,具备强大的特征提取和泛化能力。其目标包括:
- 通用性:在多种任务上表现优异,如文本分类、生成、图像识别。
- 自适应性:通过微调适配特定任务,减少从头训练成本。
- 高性能:捕获复杂模式,解决传统模型无法处理的难题。
1.2 发展背景
- 早期模型:RNN、LSTM解决序列任务,但受限于长距离依赖和计算效率。
- Transformer革命:2017年《Attention is All You Need》提出Transformer,基于自注意力机制,显著提升NLP和CV性能。
- 大模型时代:
- BERT (2018):双向编码,革新NLP预训练范式。
- GPT系列 (2018-):单向生成,擅长文本生成和对话。
- ViT (2020):将Transformer应用于图像,挑战CNN主导地位。
1.3 大模型在NLP和CV中的重要性
- NLP:BERT和GPT推动文本理解(如情感分析)和生成(如对话系统)性能飞跃。
- CV:ViT将Transformer引入图像处理,适用于分类、分割等任务。
- 医学影像:大模型在肿瘤检测、疾病分类中表现优异,处理高维影像数据。
1.4 挑战
- 计算成本:训练和推理需大量GPU/TPU资源。
- 数据需求:依赖大规模标注或无标注数据。
- 可解释性:模型复杂,难以解释预测依据。
- 伦理问题:生成内容可能涉及偏见或虚假信息。
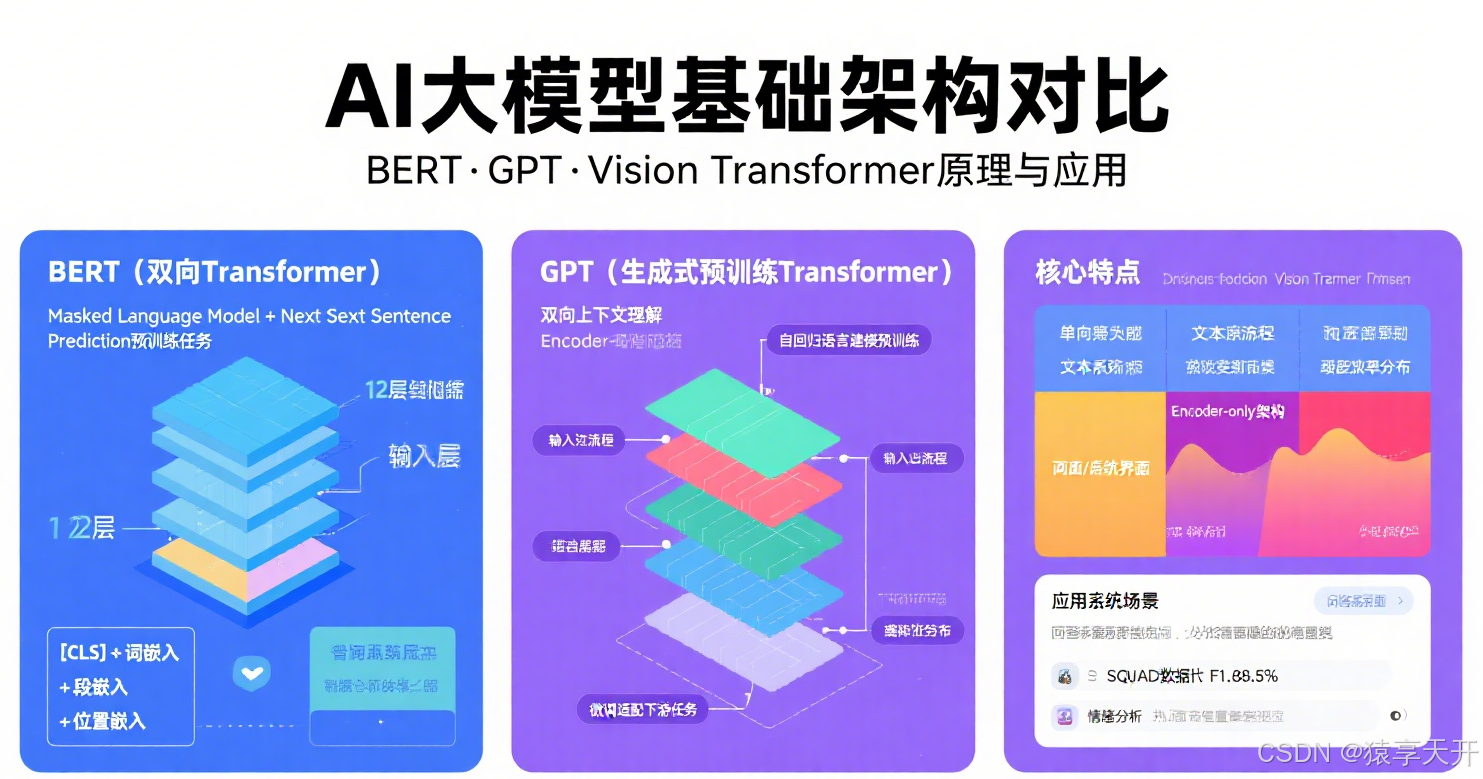
二、BERT(Bidirectional Encoder Representations from Transformers)
2.1 原理
BERT(双向Transformer编码器表示)是一种基于Transformer编码器的预训练模型,通过双向上下文建模捕获深层语义。
核心机制
- Transformer编码器:
- 由多层Encoder组成,每层包括自注意力(Self-Attention)和前馈神经网络(FFN)。
- 自注意力计算输入词与所有词的相关性,捕获全局依赖。
- 预训练任务:
- 掩码语言模型(MLM):随机掩盖15%输入词,预测被掩盖词,学习双向上下文。
- 下一句预测(NSP):判断两句话是否连续,学习句子关系。
- 微调:在下游任务(如分类、问答)上微调所有参数。
数学基础
- 自注意力:输入向量 XXX,计算查询 Q=XWQQ = XW_QQ=XWQ、键 K=XWKK = XW_KK=XWK、值 V=XWVV = XW_VV=XWV,注意力输出:
Attention(Q,K,V)=softmax(QKTdk)V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中 dkd_kdk 为键的维度,缩放点积防止数值过大。 - 多头注意力:并行计算多个注意力头,增强特征表达。
优缺点
- 优点:双向上下文建模,适合理解任务(如分类、问答)。
- 缺点:计算成本高,生成任务性能不如单向模型。
- 适用场景:文本分类、命名实体识别、情感分析。
2.2 实现示例(Python)
以下使用Hugging Face的Transformers库实现BERT的文本分类(情感分析):
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import Trainer, TrainingArguments
import torch
from torch.utils.data import Dataset
import numpy as np# 自定义数据集
class SentimentDataset(Dataset):def __init__(self, texts, labels, tokenizer, max_len=128):self.texts = textsself.labels = labelsself.tokenizer = tokenizerself.max_len = max_lendef __len__(self):return len(self.texts)def __getitem__(self, idx):text = str(self.texts[idx])label = self.labels[idx]encoding = self.tokenizer(text,add_special_tokens=True,max_length=self.max_len,padding='max_length',truncation=True,return_tensors='pt')return {'input_ids': encoding['input_ids'].flatten(),'attention_mask': encoding['attention_mask'].flatten(),'labels': torch.tensor(label, dtype=torch.long)}# 加载数据(示例:情感分析,二分类)
texts = ["I love this movie!", "This movie is terrible."]
labels = [1, 0] # 1: 正向,0: 负向
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
dataset = SentimentDataset(texts, labels, tokenizer)# 加载预训练BERT模型
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)# 设置训练参数
training_args = TrainingArguments(output_dir='./results',num_train_epochs=3,per_device_train_batch_size=8,logging_steps=10,save_steps=100,evaluation_strategy="no"
)# 训练模型
trainer = Trainer(model=model,args=training_args,train_dataset=dataset
)
trainer.train()# 推理
model.eval()
text = "This is a great film!"
inputs = tokenizer(text, return_tensors='pt', max_length=128, padding=True, truncation=True)
outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=-1)
print("预测结果:", "正向" if predictions.item() == 1 else "负向")
代码注释:
BertTokenizer:将文本转换为输入ID和注意力掩码,适配BERT输入格式。BertForSequenceClassification:预训练BERT模型,添加分类头(2类)。SentimentDataset:自定义数据集,处理文本和标签。TrainingArguments:设置训练超参数,如轮次(3)、批大小(8)。Trainer:Hugging Face提供的训练接口,简化微调流程。model.eval():切换到推理模式,预测新文本情感。
2.3 应用
- 文本分类:情感分析(如电影评论)、垃圾邮件检测。
- 医学影像:分析医学报告(如病历文本分类,判断疾病类型)。
- 问答系统:提取医学文献中的关键信息。
三、GPT(Generative Pre-trained Transformer)
3.1 原理
GPT(生成式预训练Transformer)是基于Transformer解码器的单向模型,擅长生成任务。
核心机制
- Transformer解码器:
- 单向自注意力(Masked Self-Attention),仅考虑前面词,适合生成任务。
- 每层包括掩码自注意力和前馈网络。
- 预训练任务:
- 语言建模:预测下一个词,基于大规模文本语料(如BooksCorpus)。
- 微调:适配下游任务(如对话、翻译)。
数学基础
- 掩码自注意力:限制注意力只考虑前文,计算公式同BERT,但添加掩码矩阵MMM:
Attention(Q,K,V)=softmax(QKTdk+M)V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + M\right)V Attention(Q,K,V)=softmax(dkQKT+M)V
其中Mij=−∞M_{ij} = -\inftyMij=−∞(若 i<ji < ji<j),屏蔽后续词。 - 生成过程:自回归生成,每次预测一个词,迭代构建序列。
优缺点
- 优点:擅长生成连贯文本,适合对话、翻译等任务。
- 缺点:单向建模,理解任务不如BERT;生成可能偏离事实。
- 适用场景:文本生成、对话系统、自动摘要。
3.2 实现示例(Python)
以下使用Hugging Face实现GPT-2的文本生成:
from transformers import GPT2Tokenizer, GPT2LMHeadModel
import torch# 加载预训练GPT-2模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
model.eval()# 输入提示
prompt = "The future of AI is"
inputs = tokenizer(prompt, return_tensors='pt')# 生成文本
outputs = model.generate(inputs['input_ids'],max_length=50,num_return_sequences=1,do_sample=True,top_k=50,top_p=0.95,temperature=0.7
)# 解码输出
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("生成文本:", generated_text)
代码注释:
GPT2Tokenizer:将输入文本编码为ID,适配GPT-2。GPT2LMHeadModel:预训练GPT-2模型,带语言建模头。model.generate:自回归生成,参数包括:max_length:最大生成长度(50词)。do_sample:启用采样,增加生成多样性。top_k/top_p:控制生成随机性,平衡多样性与连贯性。temperature:调节生成分布,较低值(0.7)使输出更确定。
tokenizer.decode:将生成ID解码为文本。
3.3 应用
- 对话系统:生成自然对话,如聊天机器人。
- 医学影像:生成医学报告摘要,辅助医生撰写。
- 内容创作:生成医学教育材料或科普文章。
四、Vision Transformer (ViT)
4.1 原理
ViT(视觉Transformer)将Transformer应用于图像处理,将图像分块(Patch)作为输入,取代传统CNN。
核心机制
- 图像分块:
- 将图像分割为固定大小的Patch(如16×16像素)。
- 每个Patch展平为向量,添加位置编码(Position Embedding)。
- Transformer编码器:
- 与BERT类似,使用自注意力处理Patch序列,捕获全局关系。
- 添加分类标记(CLS Token)用于分类任务。
- 预训练任务:
- 在ImageNet等数据集上预训练,预测图像类别。
- 微调:适配下游任务(如目标检测、分割)。
数学基础
- Patch嵌入:图像X∈RH×W×CX \in \mathbb{R}^{H \times W \times C}X∈RH×W×C,分割为 NNN 个Patch,展平后通过线性层映射:
z0=[xclass;xp1WE;xp2WE;… ;xpNWE]+Epos z_0 = [x_{\text{class}}; x_p^1 W_E; x_p^2 W_E; \dots; x_p^N W_E] + E_{\text{pos}} z0=[xclass;xp1WE;xp2WE;…;xpNWE]+Epos
其中 WEW_EWE 为嵌入矩阵,EposE_{\text{pos}}Epos为位置编码。 - 自注意力:同BERT,处理Patch序列,捕获全局依赖。
优缺点
- 优点:捕获全局信息,适合大规模数据,性能优于CNN。
- 缺点:需要大量数据预训练,计算成本高。
- 适用场景:图像分类、目标检测、医学影像分析。
4.2 实现示例(Python)
以下使用Hugging Face实现ViT的图像分类:
from transformers import ViTImageProcessor, ViTForImageClassification
from PIL import Image
import torch# 加载预训练ViT模型和处理器
processor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
model.eval()# 加载图像
image = Image.open("sample_image.jpg").convert('RGB')# 预处理图像
inputs = processor(images=image, return_tensors='pt')# 推理
outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=-1)
label = model.config.id2label[predictions.item()]
print("预测类别:", label)
代码注释:
ViTImageProcessor:预处理图像,调整大小并归一化。ViTForImageClassification:预训练ViT模型,带分类头。processor:将图像转换为Patch序列,适配ViT输入。model.config.id2label:将预测ID映射为类别名称(如ImageNet标签)。
4.3 应用
- 图像分类:通用图像分类(如ImageNet)。
- 医学影像:肿瘤检测(如肺癌CT分类)、器官分割。
- 跨模态任务:结合文本和图像(如医学报告与影像分析)。
五、流程图与图表
5.1 模型训练与推理流程图
以下是大模型训练与推理的通用流程图,兼容Mermaid 10.9.0:
说明:
- A(数据准备):文本(BERT、GPT)或图像(ViT)数据。
- B(预处理):文本分词(Tokenizer)或图像分块(Patch)。
- C(预训练):BERT使用MLM和NSP,GPT使用语言建模,ViT使用分类。
- D(微调):适配特定任务(如分类、生成)。
- E(推理):生成预测(如类别)或文本。
- F(输出):分类标签(BERT、ViT)或生成文本(GPT)。
5.2 图表:模型性能对比
以下为BERT、GPT-2和ViT在分类任务上的性能对比折线图(假设数据,基于典型NLP和CV任务)。
{"type": "line","data": {"labels": ["任务1: 情感分析", "任务2: 图像分类", "任务3: 文本生成"],"datasets": [{"label": "BERT 准确率","data": [0.92, 0.85, 0.0],"borderColor": "#FF6384","fill": false},{"label": "GPT-2 准确率","data": [0.88, 0.0, 0.0],"borderColor": "#36A2EB","fill": false},{"label": "ViT 准确率","data": [0.0, 0.90, 0.0],"borderColor": "#4BC0C0","fill": false}]},"options": {"title": {"display": true,"text": "大模型性能对比(假设数据)"},"scales": {"xAxes": [{"scaleLabel": {"display": true,"labelString": "任务类型"}}],"yAxes": [{"scaleLabel": {"display": true,"labelString": "准确率"},"ticks": {"min": 0.0,"max": 1.0}}]}}
}
说明:
- 图表类型:折线图,比较BERT、GPT-2、ViT在不同任务上的准确率。
- X轴:任务类型(情感分析、图像分类、文本生成)。
- Y轴:准确率(0.0表示不适用,如GPT-2不适合图像分类)。
- 数据:假设数据,反映BERT擅长分类、GPT-2擅长生成、ViT擅长图像任务。
- 颜色:鲜明颜色(
#FF6384等),适配明暗主题。
六、总结与展望
6.1 总结
- BERT:双向建模,适合文本理解任务(如分类、问答),在医学报告分析中表现优异。
- GPT:单向生成,擅长对话和文本生成,适合医学报告摘要。
- ViT:将Transformer应用于图像,捕获全局关系,适合医学影像分类和分割。
- 方法对比:
- BERT:高准确率,理解任务首选,计算成本较高。
- GPT:生成连贯文本,灵活性强,但需控制生成质量。
- ViT:突破CNN限制,需大规模数据支持。
6.2 展望
- 多模态融合:结合BERT(文本)、ViT(图像)构建多模态模型,处理医学影像和报告。
- 高效训练:开发参数高效的Transformer变体(如DistilBERT、DeiT),降低计算成本。
- 可解释性:结合注意力可视化,解释大模型在医学任务中的决策依据。
- 伦理与安全:规范生成内容,减少偏见,保障医学应用可靠性。