Agent智能体基础
概述
Agent是由LLM驱动的助手,被分配特定任务并配备相应工具来完成这些任务。一个典型的AI Agent可能具备存储和管理用户交互的内存、与外部数据源通信的能力,以及使用功能来执行任务的能力。
AI Agent,更严格意义上来说应该叫做LLM Agent,因为整个Agent最重要的控制中枢Brain,其底层是LLM大模型。
从结构上来说,包括三部分:
- Perception:输入,通过文字输入、传感器、摄像头、麦克风等,建立起对外部世界或环境的感知。
- Brain:大脑,最重要部分,包括信息存储、记忆、知识库、规划决策系统。
- Action:行动,基于Brain给出的决策进行下一步行动,主要包括对外部工具的API调用、对物理控制组件的信号输出。
Agent使用语言模型来解决问题,其定义可能包括要使用的LLM(大或小)、内存、存储、外部知识源、向量数据库、指令、描述、名称等。
agent = Agent(model=OpenAI(id="o1-mini"),memory=AgentMemory(),storage=AgentStorage(),knowledge=AgentKnowledge(vector_db=PgVector(search_type=hybrid)),tools=[Websearch(), Reasoning(), Marketplace()],description="You are a useful marketplace AI agent",
)
Agent与环境互动,通常包含几个重要组成部分:
- Environments:环境,Agent互动的世界
- Sensors:传感器,用于观察环境
- Actuators:执行器,用于与环境互动的工具
- Effectors:效应器,决定如何从观察到行动的大脑或规则
架构
Agent的核心架构由Planning、Tools、Memory三个模块组成,即Agent=LLM+规划+工具+记忆:
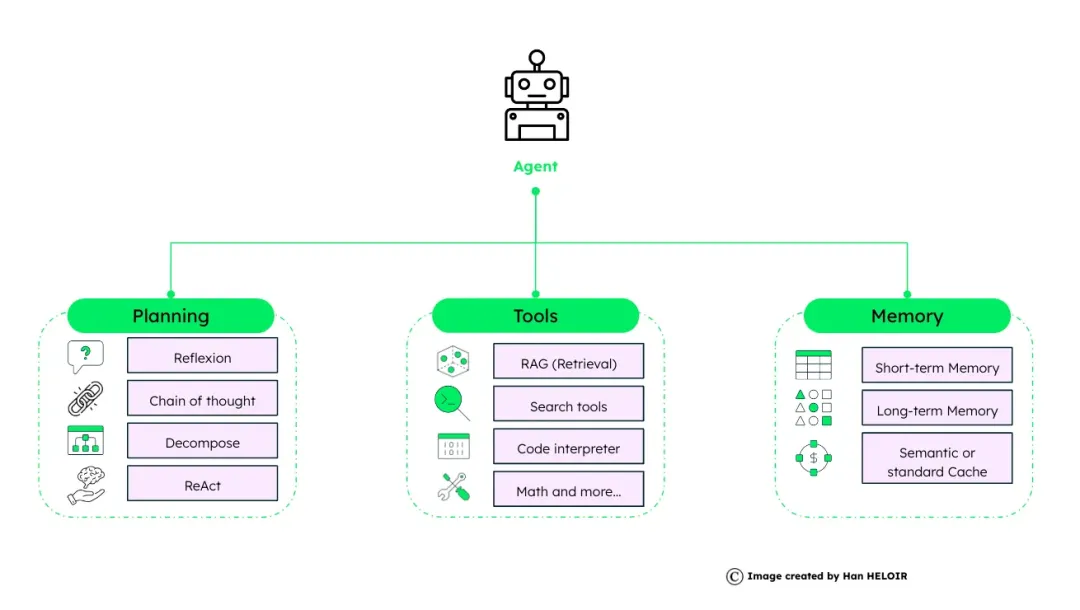
论文提出Agent由四个核心模块组成:
- Profile:主要用于Agent之间协作与编排;
- Memory:
- 记忆结构:
- 统一记忆:仅模拟人类的短期记忆,通常通过上下文学习实现;
- 混合记忆:明确模拟人类的短期和长期记忆。
- 记忆格式:
- 自然语言:记忆信息直接使用自然语言描述;
- 嵌入:记忆信息被编码为嵌入向量;
- 数据库;
- 结构化列表:记忆信息被组织成列表;
- 记忆操作:
- 读取:从记忆中提取有意义的信息以增强代理的行动;
- 记忆写入:将感知到的环境信息存储在记忆中;
- 记忆反思:模拟人类反思能力,生成更抽象、复杂和高层次的信息。
- 记忆结构:
- Planning:旨在赋予代理类似人类的能力,即将复杂任务分解为更简单的子任务并分别解决。规划模块根据代理在规划过程中是否可以接收反馈分为两类:
- 无反馈规划:
- 单路径推理:最终任务被分解为几个中间步骤,每个步骤只导致一个后续步骤;
- 多路径推理:推理步骤被组织成树状结构,每个中间步骤可能有多个后续步骤;
- 外部规划器:利用外部规划器生成计划。
- 有反馈规划:
- 环境反馈:从环境中获取反馈以影响代理的未来行为;
- 人类反馈:直接与人类互动以获取反馈;
- 模型反馈:利用预训练模型生成反馈。
- 无反馈规划:
- Action模块:定位同Tools。
Planning
Planning:制定计划,根据过去的行为与目标动态规划下一步的行动。实现Planning的几种技术:
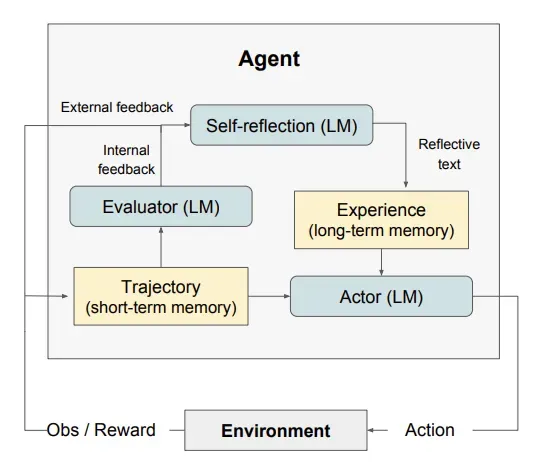
- Reflexion:反思,Agent思考从任务中获得的反馈,然后存储其任务回合中的记忆,在下一步做出更好决定。Agent内部的一种自我完善机制,使其能够从过去的行动中吸取教训,对结果进行反思,并在未来任务中做出更好的决策。
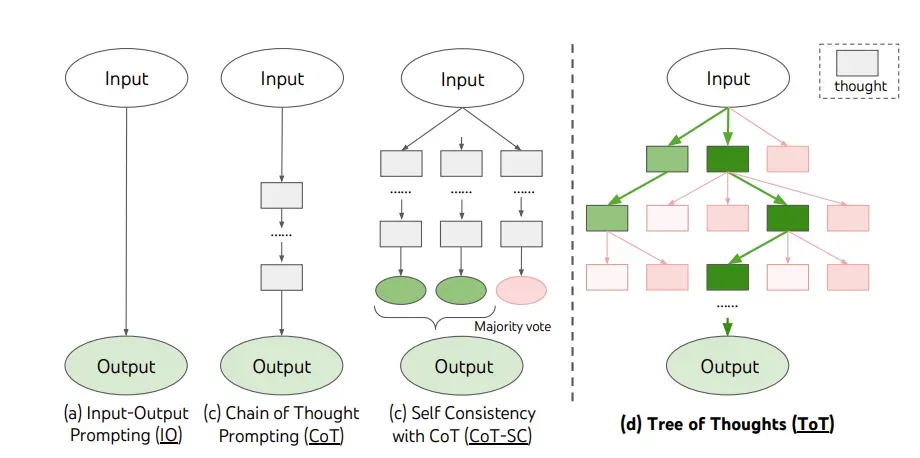
- Chain of Thought:思维链,利用提示技术,要求LLM建立与人类推理相似的思维,从而得到答案。论文Tree of Thoughts,提出采用树或图的结构进行上下文管理,减少所需提示次数。
- Decompose:分解,将复杂问题分解成更小、更容易解决的模块,再利用不同工具来处理模块化问题。
- ReAct:使用ReAct将Reflexion和Action结合起来,使Agent能够反复思考、行动和观察,动态地解决复杂的任务。LangChain和LlamaIndex等框架已实现。
Reflexion
Reflexion,亦Reflection,反思。

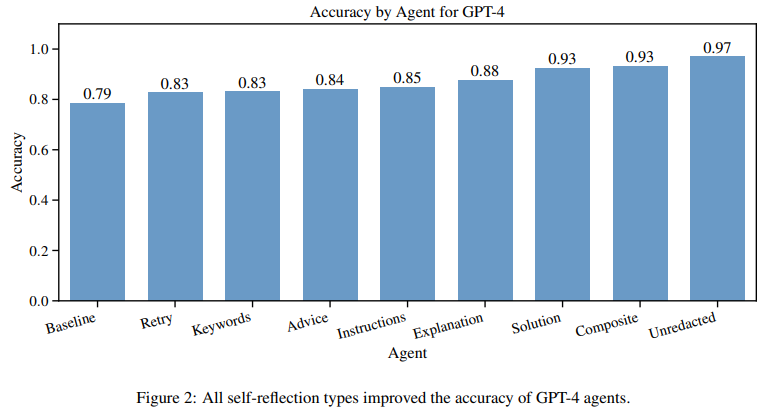
论文研究证明,反思可明显改善LLM的准确率。
- Baseline - no self-reflection capabilities.
- Retry - informed that it answered incorrectly and simply tries again.
- Keywords - a list of keywords for each type of error.
- Advice - a list of general advice for improvement.
- Explanation - an explanation of why it made an error.
- Instructions - an ordered list of instructions for how to solve the problem.
- Solution - a step-by-step solution to the problem.
- Composite - all six types of self-reflections.
- Unredacted - all six types without the answers redacted.
Tool
工具有很多:
- RAG:整合外部数据来增强Agent能力;
- 搜索:使用各种实用工具来浏览和检索信息,帮助他们做出决策,如Google、Bing、维基百科等;
- Code interpreter:理解和执行代码的外部工具;
- 自定义:在定制工具中利用任何外部功能或外部API端点。
使用工具的方式:
- TALM+ToolFormer:对LLM进行微调,以学习使用外部工具API;
- HuggingGPT:使用ChatGPT作为任务规划器,根据模型的描述选择HuggingFace平台中可用的模型,并根据执行结果总结响应结果;
- API-Bank:包含常用API工具;
- Function Calling:实现LLM连接外部工具的机制。
Memory
记忆分几种:
- Short-term Memory:短期记忆,Agent在当前任务或对话会话中存储和使用的信息。它通常包含近期对话的上下文、当前任务的状态和临时数据。是临时的,只在当前任务或会话中有效,主要用于保持对话的连贯性和上下文。
- Long-term Memory:长期记忆,在多个任务或会话中存储和使用的信息。包含更稳定和持久的数据,如用户偏好、历史记录、知识库和经验教训。持久的,信息在不同任务和会话之间被保留,即使会话结束或系统重启。可通过多种方式实现,包括数据库、知识图谱和外部存储系统。长期记忆还可以将不同任务和会话中的信息关联起来,形成更全面的知识网络。
- Semantic or standard cache:语义缓存与标准缓存,作为长期记忆的扩展,可将指令对和LLM答案存储在数据库或向量数据库中。在向LLM发送下一个查询之前,代理先检查缓存,以加快响应时间,降低调用基于API的LLM的成本。
交互模式
从人和Agent互动的角度,主要经历三种模式:
- Embedding:人类完成大多数工作,Agent只是作为某些单点能力,嵌入在人类完成工作的某些节点;
- Copilot:Agent作为人类的坚实助手,随时辅助人类完成工作;
- Multi-Agents:人类提出任务和目标,由Agents自主完成大多数工作。
通信
Agents之间的通信协议有好几个,比如MCP、A2A。
局限
包括:
- 质量问题:这些智能体在各种场景中可能无法提供高质量的结果;
- 构建成本:开发、维护和扩展用于生产环境的人工智能智能体可能成本高昂。训练需要计算成本和人工智能专家;
- 延迟较高:智能体处理用户提示并提供响应所需的时间可能会影响实时服务中的用户体验;
- 安全问题:将这些智能体投入生产对于企业用例可能存在伦理和安全方面的担忧。
设计模式
核心在于将系统分解为多个具有独立功能的智能体,这些智能体可通过消息传递等方式进行通信和协作,从而实现复杂的功能和任务。
ReAct
一种将推理(Reasoning)和行动(Act)紧密结合的设计模式。传统Agent设计中,推理和行动往往是分开的,Agent先进行一系列的推理,再执行行动,在面对复杂环境和动态变化的任务时,可能会导致Agent无法及时调整自己的行为。而ReAct模式通过在每次行动后立即进行观察(Observation),并将观察结果反馈到下一次的推理过程中,使得Agent能够更好地适应环境变化,维持短期记忆,从而实现更加灵活和智能的行为。
交互流程:
- 接收任务:接收到用户或系统的任务指令,任务可能包含多个子任务;
- 推理:根据当前的任务和已有的知识进行推理,生成初步的行动计划;
- 行动:执行推理得出的行动;
- 观察:对行动的结果进行观察,获取反馈信息;
- 循环迭代:将观察结果反馈到推理过程中,根据新的信息重新进行推理,生成新的行动计划,并继续执行行动和观察,直到任务完成。
优势:
- 适应性强:能够根据环境的变化及时调整自己的行为,适应动态环境;
- 维持短期记忆:通过观察和反馈,记住之前的行动和结果,避免重复错误或遗漏重要信息;
- 提高效率:减少不必要的行动。
Plan and Solve
一种先规划再执行的设计模式,适用于复杂任务的处理。首先会根据任务目标生成一个多步计划,然后逐步执行计划中的每个步骤。如果在执行过程中发现计划不可行或需要调整,重新规划,从而确保任务能够顺利进行。
交互流程:
- 接收任务;
- 规划(Plan):根据任务目标生成一个多步计划,明确每个步骤的具体内容和顺序。
- 执行(Solve):按照计划逐步执行每个步骤。
- 观察:对执行结果进行观察,判断是否需要重新规划。
- 重新规划(Replan):如果发现计划不可行或需要调整,根据当前状态重新生成计划,并继续执行。
- 循环迭代。
优势:
- 适应性强:能够根据任务的复杂性和环境的变化灵活调整计划;
- 任务导向:通过明确的计划,能够更高效地完成任务,避免盲目行动;
- 可扩展性:适用于复杂任务和多步骤任务,能够有效管理任务的各个阶段
REWOO
Reason without Observation的缩写,在传统ReAct模式的基础上优化,去掉显式观察步骤,而是将观察结果隐式地嵌入到下一步的执行中。核心在于通过推理和行动的紧密协作,实现更加高效和连贯的任务执行。
交互流程:
- 接收任务;
- 推理:根据当前的任务和已有的知识进行推理,生成初步的行动计划。
- 行动;
- 隐式观察(Implicit Observation):在执行行动时,自动将结果反馈到下一步的推理中,而不是显式地进行观察。
- 循环迭代。
优势:
- 高效性:去掉显式的观察步骤,减少交互复杂性;
- 连贯性:通过隐式观察,行动更加连贯,避免不必要的重复操作;
- 适应性。
LLMCompiler
一种通过并行函数调用提高效率的设计模式。核心在于优化任务的编排,能够同时处理多个任务,从而显著提升任务处理的速度和效率。特别适用于需要同时处理多个子任务的复杂任务场景。
交互流程:
- 接收任务;
- 任务分解(Task Decomposition):将复杂任务分解为多个子任务,并确定这些子任务之间的依赖关系。
- 并行执行(Parallel Execution):根据子任务之间的依赖关系,将可以并行处理的子任务同时发送给多个执行器进行处理。
- 结果合并(Result Merging):各个执行器完成子任务后,将结果合并,形成最终输出。
- 循环迭代。
优势:
- 高效率:通过并行处理多个子任务,显著减少任务完成的总时间;
- 灵活性:能够根据任务的复杂性和子任务之间的依赖关系动态调整任务分解和执行策略;
- 可扩展性:适用于大规模任务和复杂任务场景,能够有效利用多核处理器和分布式计算资源。
Basic Reflection
一种通过反思和修正来优化行为的设计模式。Agent行为可分为两个阶段:生成初始响应和对初始响应进行反思与修正。核心在于通过不断的自我评估和改进,使输出更加准确和可靠。
交互流程:
- 接收任务;
- 生成初始响应(Initial Response):根据任务生成一个初步的回答或解决方案;
- 反思:对初始响应进行评估,检查是否存在错误、遗漏或可以改进的地方;
- 修正(Revision):根据反思结果,对初始响应进行修正,生成最终的输出
- 循环迭代。
优势:
- 提高准确性:通过反思和修正,能够减少错误和遗漏;
- 增强适应性:能够根据不同的任务和环境调整自己的行为策略,增强适应性;
- 提升用户体验:通过不断优化输出,能够提供更高质量的服务,提升用户体验。
Reflexion
一种基于强化学习的模式,旨在通过引入外部数据评估和自我反思机制,进一步优化行为和输出。与Basic Reflection相比,不仅对初始响应进行反思和修正,还通过外部数据来评估回答的准确性和完整性,生成更具建设性的修正建议。
交互流程:
- 接收任务;
- 生成初始响应;
- 外部评估(External Evaluation):引入外部数据或标准,对初始响应进行评估,检查是否存在错误、遗漏或可以改进的地方。
- 反思:根据外部评估的结果,对初始响应进行自我反思,识别问题所在。
- 修正:根据反思的结果,对初始响应进行修正,生成最终的输出。
- 循环迭代。
优势:
- 提高准确性:通过外部数据评估和自我反思,能够更准确地识别错误和遗漏;
- 增强适应性;
- 提升用户体验;
- 强化学习:引入外部数据评估机制,使学习过程更加科学和有效,能够更好地适应复杂任务和动态环境。
LATS
Language Agent Tree Search的缩写,一种融合树搜索、ReAct、Plan&Solve、反思机制的设计模式。通过多轮迭代和树搜索的方式,对可能的解决方案进行探索和评估,从而找到最优解。特别适用于复杂任务的解决,尤其是在需要对多种可能性进行评估和选择的场景中。
交互流程:
- 接收任务;
- 树搜索(Tree Search):构建搜索树,将任务分解为多个子任务,并探索所有可能的解决方案路径;
- ReAct交互:在树搜索的过程中,使用ReAct模式对每个子任务进行推理和行动,获取反馈信息;
- Plan&Solve执行:根据树搜索的结果,生成一个多步计划,并逐步执行计划中的每个步骤;
- 反思与修正:对执行结果进行反思,评估每个步骤的正确性和效率,根据反思结果对计划进行修正;
- 循环迭代。
优势:
- 全局优化:通过树搜索,全面探索所有可能的解决方案,找到最优路径;
- 灵活性:结合ReAct和Plan&Solve模式,能够灵活应对任务中的动态变化;
- 准确性;
- 适应性:适用于复杂任务和多步骤任务,能够有效管理任务的各个阶段。
Self-Discover
一种让Agent在更小粒度上对任务本身进行反思的设计模式。核心在于通过自我发现和自我调整,更深入地理解任务的本质和需求,从而优化行为和输出。与Reflexion模式相比,不仅关注任务的执行结果,还注重任务本身的逻辑和结构,通过自我发现潜在问题和改进点,实现更深层次的优化。
交互流程:
- 接收任务;
- 任务分析(Task Analysis):对任务进行初步分析,识别任务的关键要素和目标;
- 自我发现(Self-Discovery):对任务本身进行反思,发现潜在的问题、遗漏或可改进的地方。包括对任务逻辑、数据需求和目标的深入分析;
- 调整策略(Strategy Adjustment):根据自我发现的结果,调整任务执行策略,优化行为路径;
- 执行与反馈(Execution & Feedback):按照调整后的策略执行任务,并收集反馈信息,进一步优化行为;
- 循环迭代。
优势:
- 深度优化:通过自我发现和调整策略,能够深入理解任务的本质,实现更深层次的优化;
- 适应性强;
- 提高效率:通过不断优化任务执行路径,能够减少不必要的操作,提高任务完成的效率;
Storm
一种专注于从零开始生成复杂内容的设计模式,特别适用于需要系统化构建和优化内容生成的任务,例如生成类似维基百科的文章、报告或知识库。其核心在于通过逐步构建大纲,并根据大纲逐步丰富内容,从而生成高质量结构化的文本。
交互流程:
- 接收任务;
- 构建大纲(Outline Construction):根据任务主题生成一个详细的大纲,明确内容的结构和各个部分的主题;
- 内容生成(Content Generation):根据大纲逐步生成每个部分的具体内容,确保内容的连贯性和准确性;
- 内容优化(Content Optimization):对生成的内容进行优化,包括语言润色、逻辑调整和信息补充,以提高内容的质量;
- 循环迭代。
优势:
- 系统化生成:通过构建大纲和逐步填充内容,确保生成内容的结构化和系统性;
- 高质量输出:通过多轮优化,能够生成高质量、连贯且准确的内容;
- 适应性强:适用于多种内容生成任务,包括但不限于文章、报告、知识库等;
- 可扩展性:可以根据任务的复杂性和需求灵活调整大纲和内容生成策略。
开发
框架
有很多,如LangChain、LlamaIndex。
最佳实践
参考开源12原则。
实现
awesome-ai-agents,里汇聚很多开源或闭源的Agent产品。
XAgent
清华联合面壁开源的双循环机制。
Windsurf
Windsurf,可帮助任何人在几分钟内提示、运行、编辑、构建和部署全栈Web应用程序,支持使用多种Web技术和数据库,进行代码生成和应用程序构建。
CogVLM和CogAgent
智谱开源:
- CogVLM
- CogAgent
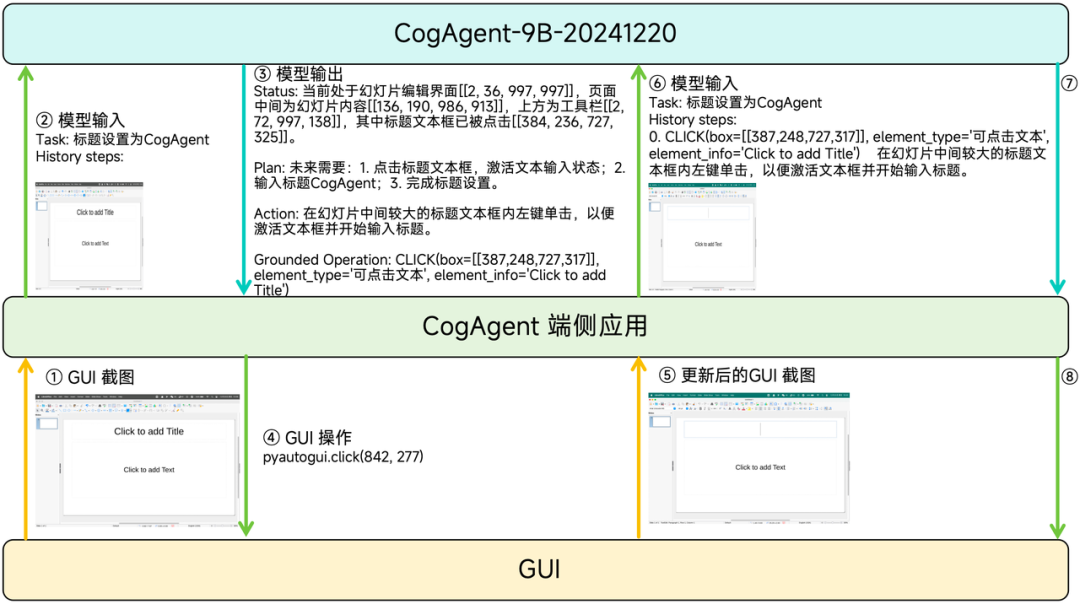
CogAgent,一个Agent类执行模型,而非对话模型,不支持连续对话,但支持连续执行历史;也即每次需要重开对话session,并将过往的历史给模型。
工作流示意图
Multi-Agent
参考Multi-Agent多智能体系统。
其他
商业模式
Agent的商业模式,包括:
- SaaS:Software as a Service
- AaaS:Agent as a Service
- MaaS:Model as a Service
- RaaS:Robot as a Service
- Agent Store模式
- 消费者服务模式
- 企业解决方案模式
- 按需平台模式
- 数据和分析模式
- 技术许可模式
- 众包和协作模式
参考
- Agent设计的九大模式
- 5W1H分析框架拆解AI Agent,系列文章,分上中下三篇