AI Agent——基于 LangGraph 的多智能体任务路由与执行系统实战
在智能体应用开发中,常常需要根据用户输入的意图,将任务分发给不同的专业 Agent(智能体)执行。例如,用户可能会提问旅游规划、请求讲笑话、生成对联,或提出其他问题。如果每个功能都写在同一个 LLM 调用逻辑里,不仅耦合度高,还不利于扩展与维护。
本文将演示如何借助 LangGraph 构建一个多智能体任务路由系统,并结合 MCP 工具调用、Redis 向量数据库检索、LangChain 大语言模型调用 等技术,实现一个可扩展的多功能对话助手。
🎯 系统设计目标
-
多任务分类与路由
自动判断用户问题类型,并将任务派发给对应的智能体节点。 -
模块化节点实现
每种任务逻辑由独立节点实现,降低耦合度,方便扩展。 -
外部工具调用
旅游规划功能通过 MCP 调用高德地图 API。 -
知识检索增强
对联生成功能结合 Redis 向量检索,参考已有素材生成更贴切的答案。 -
可视化流程编排
使用 LangGraph 构建任务流转关系,实现灵活的条件跳转。
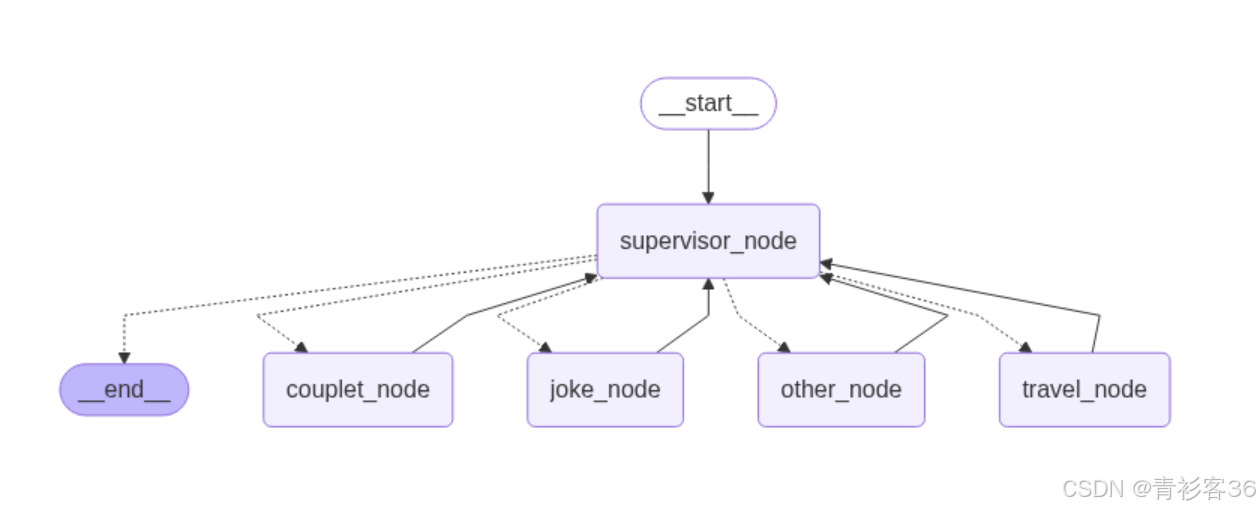
🏗 系统架构
整体逻辑分为五个主要节点:
- supervisor_node:任务分类器,根据用户输入确定任务类型。
- travel_node:旅游规划助手,调用高德地图 MCP 工具。
- joke_node:笑话生成器。
- couplet_node:对联生成器,结合 Redis 进行向量检索。
- other_node:兜底处理节点,回复默认信息。
任务流转由 LangGraph 进行编排:
📦 核心依赖
笔者已经通过 pip freeze > requirements.txt 生成了requirements.txt,读者只需在自己的虚拟环境中执行pip install -r requirements.txt即可。(对于创建venv虚拟环境,不太了解的小伙伴可以参考 使用venv为Python项目创建一个独立的虚拟环境 这篇博客)
aiohappyeyeballs==2.6.1
aiohttp==3.12.15
aiosignal==1.4.0
annotated-types==0.7.0
anyio==4.10.0
async-timeout==4.0.3
attrs==25.3.0
certifi==2025.8.3
cffi==1.17.1
charset-normalizer==3.4.3
click==8.2.1
cryptography==45.0.6
dashscope==1.24.1
dataclasses-json==0.6.7
distro==1.9.0
exceptiongroup==1.3.0
frozenlist==1.7.0
greenlet==3.2.4
h11==0.16.0
httpcore==1.0.9
httpx==0.28.1
httpx-sse==0.4.1
idna==3.10
Jinja2==3.1.6
jiter==0.10.0
jsonpatch==1.33
jsonpath-ng==1.7.0
jsonpointer==3.0.0
jsonschema==4.25.0
jsonschema-specifications==2025.4.1
langchain==0.3.27
langchain-community==0.3.27
langchain-core==0.3.74
langchain-mcp-adapters==0.1.9
langchain-openai==0.3.29
langchain-redis==0.2.3
langchain-text-splitters==0.3.9
langgraph==0.6.4
langgraph-checkpoint==2.1.1
langgraph-prebuilt==0.6.4
langgraph-sdk==0.2.0
langsmith==0.4.13
MarkupSafe==3.0.2
marshmallow==3.26.1
mcp==1.12.4
ml_dtypes==0.5.3
multidict==6.6.4
mypy_extensions==1.1.0
numpy==2.2.6
openai==1.99.9
orjson==3.11.1
ormsgpack==1.10.0
packaging==25.0
ply==3.11
propcache==0.3.2
pycparser==2.22
pydantic==2.11.7
pydantic-settings==2.10.1
pydantic_core==2.33.2
python-dotenv==1.1.1
python-multipart==0.0.20
python-ulid==3.0.0
PyYAML==6.0.2
redis==6.4.0
redisvl==0.8.0
referencing==0.36.2
regex==2025.7.34
requests==2.32.4
requests-toolbelt==1.0.0
rpds-py==0.27.0
sniffio==1.3.1
SQLAlchemy==2.0.43
sse-starlette==3.0.2
starlette==0.47.2
tenacity==9.1.2
tiktoken==0.11.0
tqdm==4.67.1
typing-inspect==0.9.0
typing-inspection==0.4.1
typing_extensions==4.14.1
urllib3==2.5.0
uvicorn==0.35.0
websocket-client==1.8.0
xxhash==3.5.0
yarl==1.20.1
zstandard==0.23.0
🔍 代码核心解析
1. 定义全局 State
LangGraph 的状态对象采用 TypedDict 定义,方便类型约束和合并:
class State(TypedDict):messages: Annotated[list[AnyMessage], add] # 对话消息type: str # 任务类型
2. Supervisor 节点(任务路由)
功能:将用户问题分类到 travel / joke / couplet / other。
def supervisor_node(state: State):print(">>> supervisor_node")writer = get_stream_writer()writer({"node": ">>>> supervisor_node"})# 如果已经有 type 属性了,表明问题已经由其它节点处理完成了了,可以直接返回if "type" in state:writer({"supervisor_step": f"已获得 {state['type']} 智能体处理结果"})return {"type": END}else:# 根据用户的问题对问题进行分类,并将分类的结果保存到 type 中prompt = """你是一个专业的客服助手,负责对用户的问题进行分类,并将任务分给其他Agent执行。如果用户的问题是和旅游路线规划相关的,那就返回 travel。如果用户的问题是希望讲一个笑话,那就返回 joke。如果用户的问题是希望对一个对联,那就返回 couplet。如果是其他问题,返回 other。除了这几个选项外,不要返回任何其他的内容。"""prompts = [{"role": "system", "content": prompt},{"role": "user", "content": state["messages"][0]}]response = llm.invoke(prompts)type_res = response.contentwriter({"supervisor_step": f"问题分类结果:{type_res}"})if type_res in nodes:return {"type": type_res}else:raise ValueError("Invalid type")
这里 LLM 只负责分类,不直接执行任务,从而降低单次调用的复杂度。
3. 讲笑话节点(调用LLM)
通过提示词模板来限定模型的输出。
def joke_node(state: State):print(">>> joke_node")writer = get_stream_writer()writer({"node": ">>>> joke_node"})system_prompt = "你是一个笑话大师,根据用户的问题,写一个不超过100字的笑话。"prompts = [{"role": "system", "content": system_prompt},{"role": "user", "content": state["messages"][0]}]response = llm.invoke(prompts)writer({"joke_result": response.content})return {"messages": [AIMessage(content=response.content)], "type": "joke"}
4. 旅游规划节点(调用 MCP 工具)
通过 MultiServerMCPClient 调用高德地图的 MCP 服务:
def travel_node(state: State):print(">>> travel_node")writer = get_stream_writer()writer({"node": ">>>> travel_node"})system_prompt = "你是一个专业的旅行规划助手,根据用户的问题,生成一个旅游路线规划。请用中文回答,并返回一个不超过100字的规划结果。"prompts = [{"role": "system", "content": system_prompt},{"role": "user", "content": state["messages"][0]}]# 高德地图的 MCP 配置信息client = MultiServerMCPClient({"amap-maps": {"command": "npx","args": ["-y", "@amap/amap-maps-mcp-server"],"env": {"AMAP_MAPS_API_KEY": "your_secret_key"},"transport": "stdio"}})tools = asyncio.run(client.get_tools())agent = create_react_agent(model=llm, tools=tools)response = agent.invoke({"messages": prompts})writer({"travel_result": response["messages"][-1].content})return {"messages": [AIMessage(content=response["messages"][-1].content)], "type": "travel"}
这样一来,旅游规划不仅依赖 LLM 的文本生成,还可以调用地图 API 获取更精准的路线信息。
5. 对联生成节点(Redis 向量检索)
RAG外挂的数据库,数据来源:https://huggingface.co/datasets/wb14123/couplet
笔者是将它下载到本地,保存为CSV文件,然后通过脚本将CSV文件中的全部对联信息保存到 Redis 向量数据库。这样 couplet_node 才能通过 RedisVectorStore.similarity_search_with_score() 检索到参考对联。
脚本如下所示,该脚本读取本地 CSV 文件中的对联数据,将其转换为向量并存储到 Redis 向量数据库的 couplet 索引中。
# 把对联数据保存到Redis向量数据库中import redis
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_redis import RedisConfig, RedisVectorStoreembedding_model = DashScopeEmbeddings(model="text-embedding-v1",dashscope_api_key="your_secret_key")# 保存向量数据库
redis_url = "redis://localhost:6379"
redis_client = redis.from_url(redis_url)
# print(redis_client.ping()) # 测试连接,返回 True 表示连接成功config = RedisConfig(index_name="couplet",redis_url=redis_url
)vector_store = RedisVectorStore(embedding_model, config=config)lines = []
with open("resource/couplettest.csv", "r", encoding="utf-8") as f:for line in f:print(line)lines.append(line)
vector_store.add_texts(lines)
在couplet_node中就可以利用 Redis 向量数据库进行语义检索了,具体实现如下:
def couplet_node(state: State):print(">>> couplet_node")writer = get_stream_writer()writer({"node": ">>>> couplet_node"})prompt_template = ChatPromptTemplate.from_messages([("system", """你是一个专业的对联大师,你的任务是根据用户给出的对联,设计一个下联。回答时,可以参考下面的参考对联。参考对联:{samples}请用中文回答问题"""),("user", "{text}")])query = state["messages"][0]embedding_model = DashScopeEmbeddings(model="text-embedding-v1", dashscope_api_key="your_secret_key")redis_url = "redis://localhost:6379"config = RedisConfig(index_name="couplet",redis_url=redis_url)vector_store = RedisVectorStore(embedding_model, config=config)samples = []scored_results = vector_store.similarity_search_with_score(query, k=10)for doc, score in scored_results:samples.append(doc.page_content)prompt = prompt_template.invoke({"samples": samples, "text": query})writer({"couplet_prompt": prompt})response = llm.invoke(prompt)writer({"couplet_result": prompt})return {"messages": [AIMessage(content=response.content)], "type": "couplet"}
检索出的参考对联被插入到提示词模板中,让 LLM 生成更契合的下联。
6. 图结构构建
# 条件路由
def routing_rules(state: State):if state["type"] == "travel":return "travel_node"elif state["type"] == "joke":return "joke_node"elif state["type"] == "couplet":return "couplet_node"elif state["type"] == END:return ENDelse:return "other_node"# 构建图
builder = StateGraph(State)
# 添加节点
builder.add_node("supervisor_node", supervisor_node)
builder.add_node("travel_node", travel_node)
builder.add_node("joke_node", joke_node)
builder.add_node("couplet_node", couplet_node)
builder.add_node("other_node", other_node)
# 添加边
builder.add_edge(START, "supervisor_node")
builder.add_conditional_edges("supervisor_node", routing_rules,["travel_node", "joke_node", "couplet_node", "other_node", END])
builder.add_edge("travel_node", "supervisor_node")
builder.add_edge("joke_node", "supervisor_node")
builder.add_edge("couplet_node", "supervisor_node")
builder.add_edge("other_node", "supervisor_node")# 构建Graph
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)
这里 add_conditional_edges 决定了路由的灵活性,不同的任务类型走不同分支,执行完毕后再回到 supervisor_node,直到返回 END。
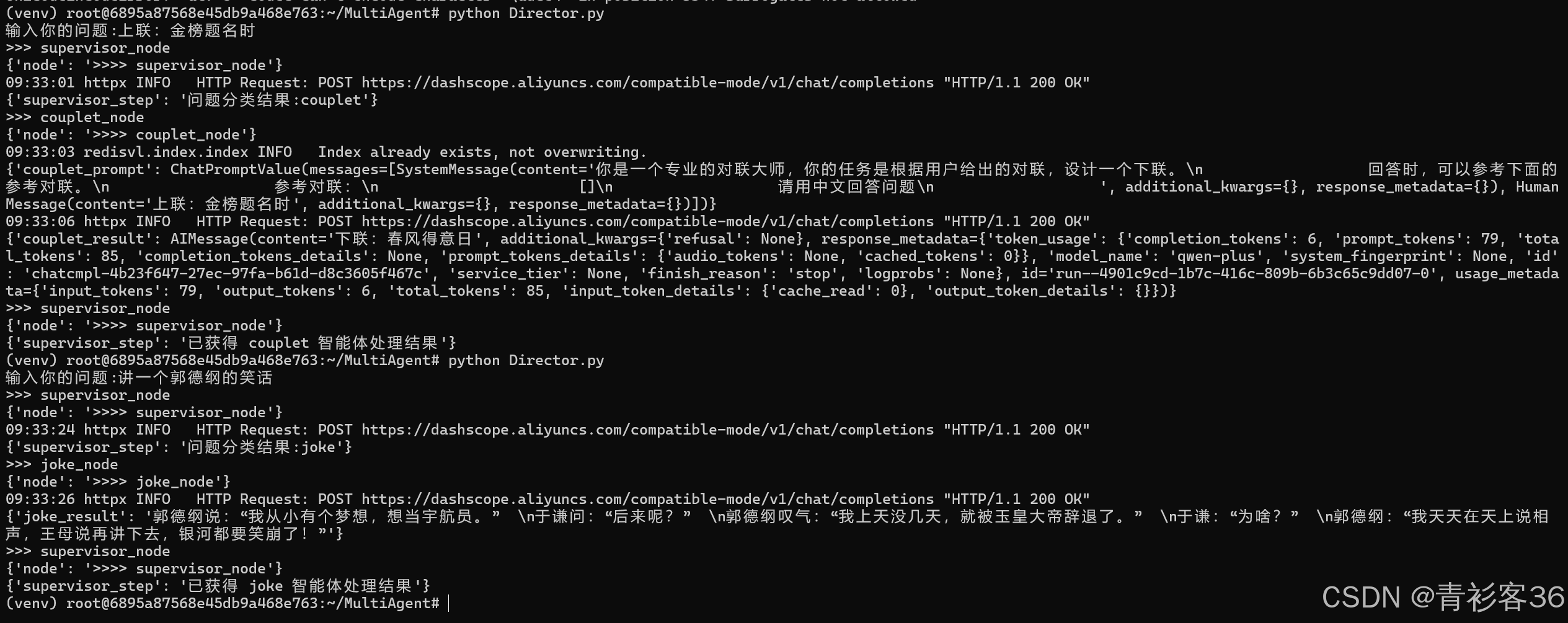
🖥 运行效果
执行脚本:
python Director.py
🔑 技术亮点
- LangGraph 条件路由:实现多智能体任务分发。
- MCP 工具集成:LLM+外部 API 结合,提升任务精度。
- Redis 向量检索:实现知识增强生成(RAG)。
- 模块化设计:节点间低耦合,方便扩展新功能。
- 实时流式输出:
get_stream_writer带来交互式调试体验。
📌 适用场景
- 多功能对话机器人(旅游、娱乐、知识问答等)
- 企业内部多部门协作 AI 助手
- 跨领域多智能体研究与开发平台
🏁 总结
本文展示了一个可扩展的多智能体任务路由系统,从 任务分类 到 功能执行,再到 结果返回,实现了模块化、可维护的架构。借助 LangGraph、MCP、Redis 向量数据库等技术,可以快速构建出功能丰富的智能体应用,并能灵活接入新的业务场景。
附完整代码
import asyncio
from operator import add
from typing import TypedDict, Annotatedfrom langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.messages import AnyMessage, AIMessage
from langchain_core.prompts import ChatPromptTemplate
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.config import get_stream_writer
from langchain_redis import RedisConfig, RedisVectorStore
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agentllm = ChatOpenAI(base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="your_secret_key",model="qwen-plus")nodes = ["supervisor", "travel", "couplet", "joke", "other"]class State(TypedDict):messages: Annotated[list[AnyMessage], add]type: strdef supervisor_node(state: State):print(">>> supervisor_node")writer = get_stream_writer()writer({"node": ">>>> supervisor_node"})# 如果已经有 type 属性了,表明问题已经由其它节点处理完成了了,可以直接返回if "type" in state:writer({"supervisor_step": f"已获得 {state['type']} 智能体处理结果"})return {"type": END}else:# 根据用户的问题对问题进行分类,并将分类的结果保存到 type 中prompt = """你是一个专业的客服助手,负责对用户的问题进行分类,并将任务分给其他Agent执行。如果用户的问题是和旅游路线规划相关的,那就返回 travel。如果用户的问题是希望讲一个笑话,那就返回 joke。如果用户的问题是希望对一个对联,那就返回 couplet。如果是其他问题,返回 other。除了这几个选项外,不要返回任何其他的内容。"""prompts = [{"role": "system", "content": prompt},{"role": "user", "content": state["messages"][0]}]response = llm.invoke(prompts)type_res = response.contentwriter({"supervisor_step": f"问题分类结果:{type_res}"})if type_res in nodes:return {"type": type_res}else:raise ValueError("Invalid type")def travel_node(state: State):print(">>> travel_node")writer = get_stream_writer()writer({"node": ">>>> travel_node"})system_prompt = "你是一个专业的旅行规划助手,根据用户的问题,生成一个旅游路线规划。请用中文回答,并返回一个不超过100字的规划结果。"prompts = [{"role": "system", "content": system_prompt},{"role": "user", "content": state["messages"][0]}]# 高德地图的 MCP 配置信息client = MultiServerMCPClient({"amap-maps": {"command": "npx","args": ["-y", "@amap/amap-maps-mcp-server"],"env": {"AMAP_MAPS_API_KEY": "your_secret_key"},"transport": "stdio"}})tools = asyncio.run(client.get_tools())agent = create_react_agent(model=llm, tools=tools)response = agent.invoke({"messages": prompts})writer({"travel_result": response["messages"][-1].content})return {"messages": [AIMessage(content=response["messages"][-1].content)], "type": "travel"}def joke_node(state: State):print(">>> joke_node")writer = get_stream_writer()writer({"node": ">>>> joke_node"})system_prompt = "你是一个笑话大师,根据用户的问题,写一个不超过100字的笑话。"prompts = [{"role": "system", "content": system_prompt},{"role": "user", "content": state["messages"][0]}]response = llm.invoke(prompts)writer({"joke_result": response.content})return {"messages": [AIMessage(content=response.content)], "type": "joke"}def couplet_node(state: State):print(">>> couplet_node")writer = get_stream_writer()writer({"node": ">>>> couplet_node"})prompt_template = ChatPromptTemplate.from_messages([("system", """你是一个专业的对联大师,你的任务是根据用户给出的对联,设计一个下联。回答时,可以参考下面的参考对联。参考对联:{samples}请用中文回答问题"""),("user", "{text}")])query = state["messages"][0]embedding_model = DashScopeEmbeddings(model="text-embedding-v1", dashscope_api_key="your_secret_key")redis_url = "redis://localhost:6379"config = RedisConfig(index_name="couplet",redis_url=redis_url)vector_store = RedisVectorStore(embedding_model, config=config)samples = []scored_results = vector_store.similarity_search_with_score(query, k=10)for doc, score in scored_results:samples.append(doc.page_content)prompt = prompt_template.invoke({"samples": samples, "text": query})writer({"couplet_prompt": prompt})response = llm.invoke(prompt)writer({"couplet_result": prompt})return {"messages": [AIMessage(content=response.content)], "type": "couplet"}def other_node(state: State):print(">>> other_node")writer = get_stream_writer()writer({"node": ">>>> other_node"})return {"messages": [AIMessage(content="我暂时无法回答这个问题")], "type": "other"}# 条件路由
def routing_rules(state: State):if state["type"] == "travel":return "travel_node"elif state["type"] == "joke":return "joke_node"elif state["type"] == "couplet":return "couplet_node"elif state["type"] == END:return ENDelse:return "other_node"# 构建图
builder = StateGraph(State)
# 添加节点
builder.add_node("supervisor_node", supervisor_node)
builder.add_node("travel_node", travel_node)
builder.add_node("joke_node", joke_node)
builder.add_node("couplet_node", couplet_node)
builder.add_node("other_node", other_node)
# 添加边
builder.add_edge(START, "supervisor_node")
builder.add_conditional_edges("supervisor_node", routing_rules,["travel_node", "joke_node", "couplet_node", "other_node", END])
builder.add_edge("travel_node", "supervisor_node")
builder.add_edge("joke_node", "supervisor_node")
builder.add_edge("couplet_node", "supervisor_node")
builder.add_edge("other_node", "supervisor_node")# 构建Graph
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)# 执行任务的测试代码
if __name__ == "__main__":config = {"configurable": {"thread_id": "1"}}user_query = input("输入你的问题:")for chunk in graph.stream({"messages": [user_query]}, config,stream_mode="custom"):print(chunk)