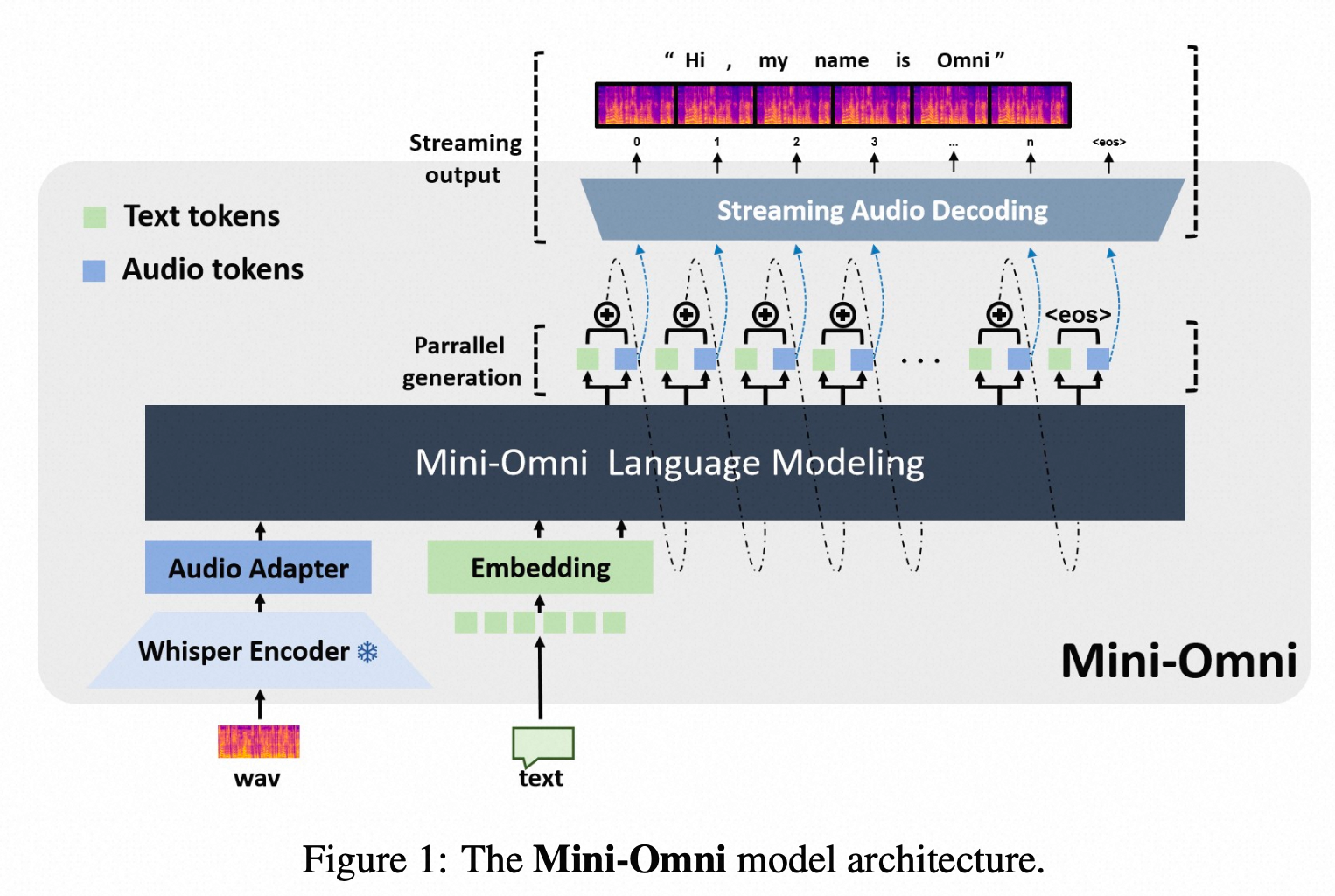
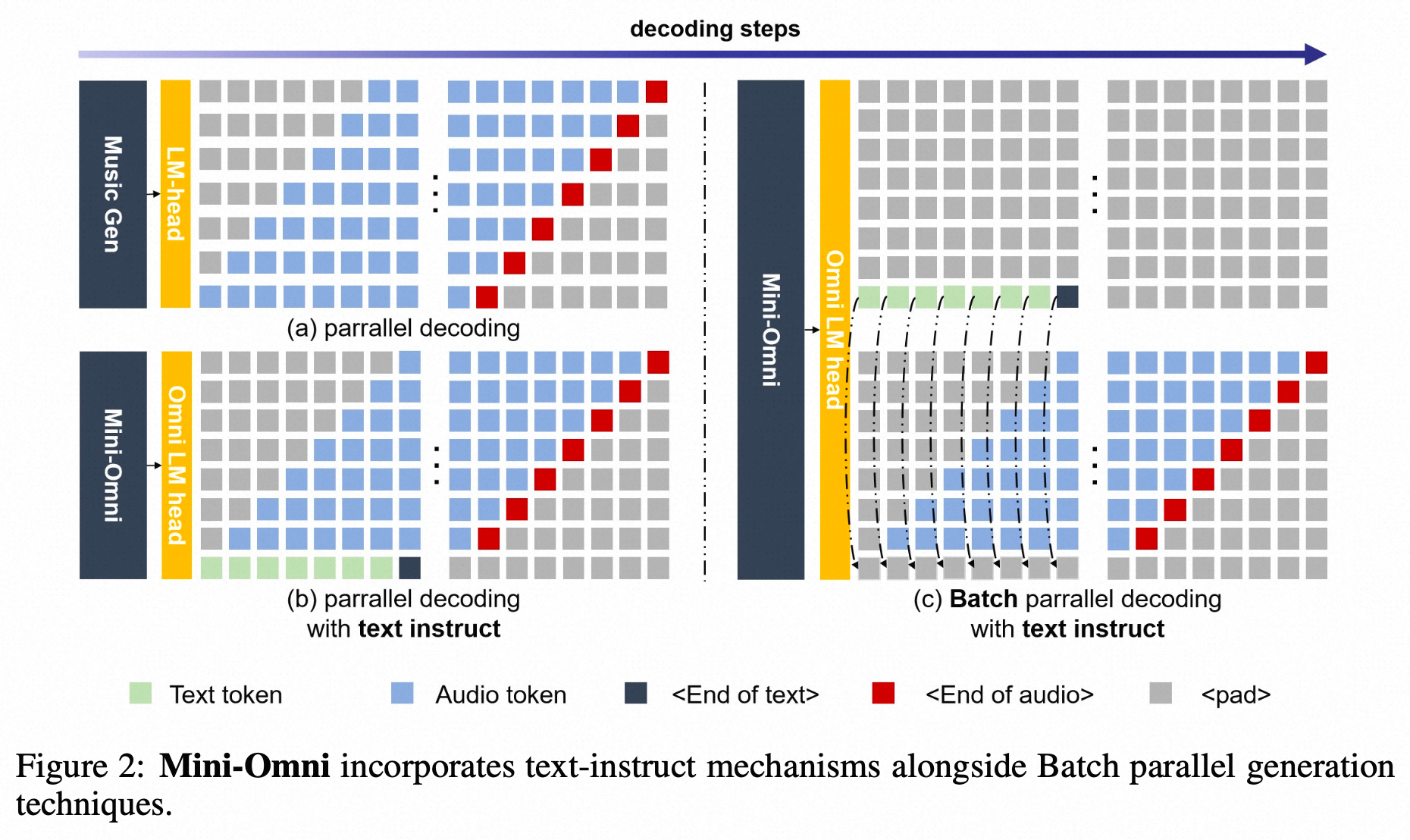
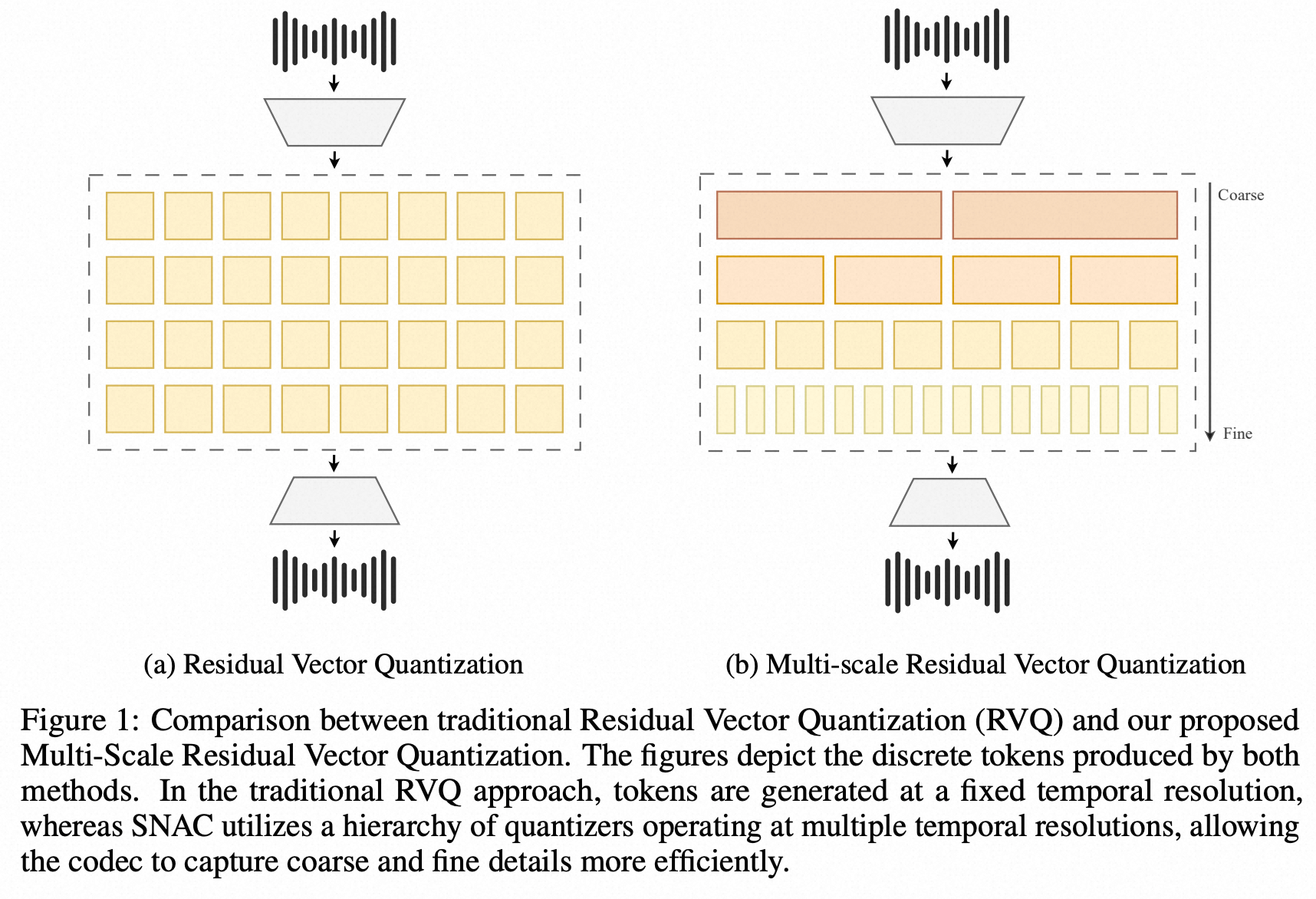
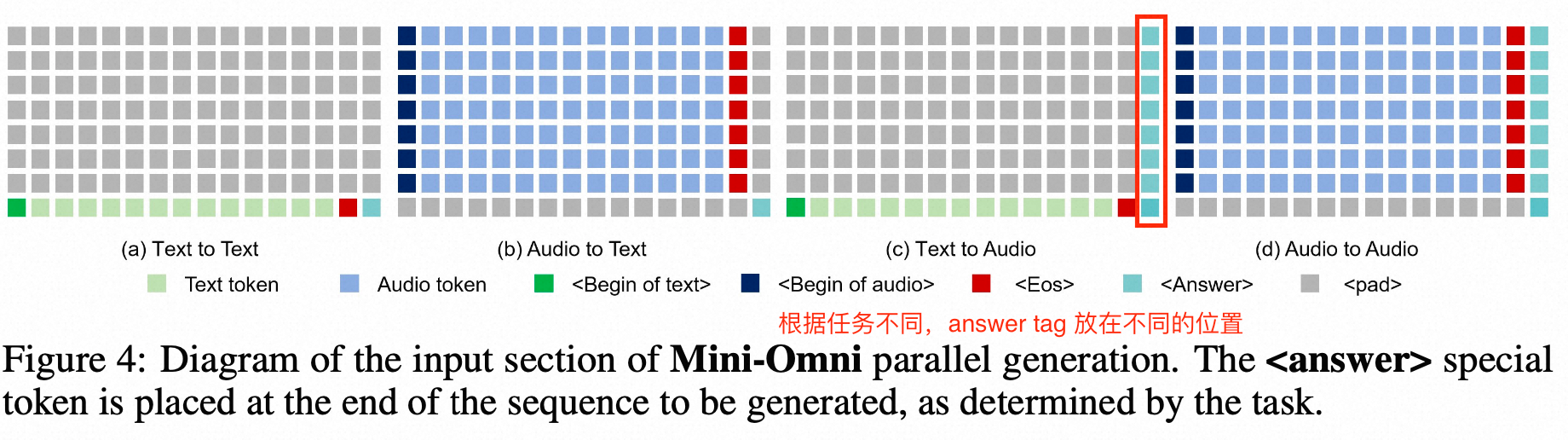
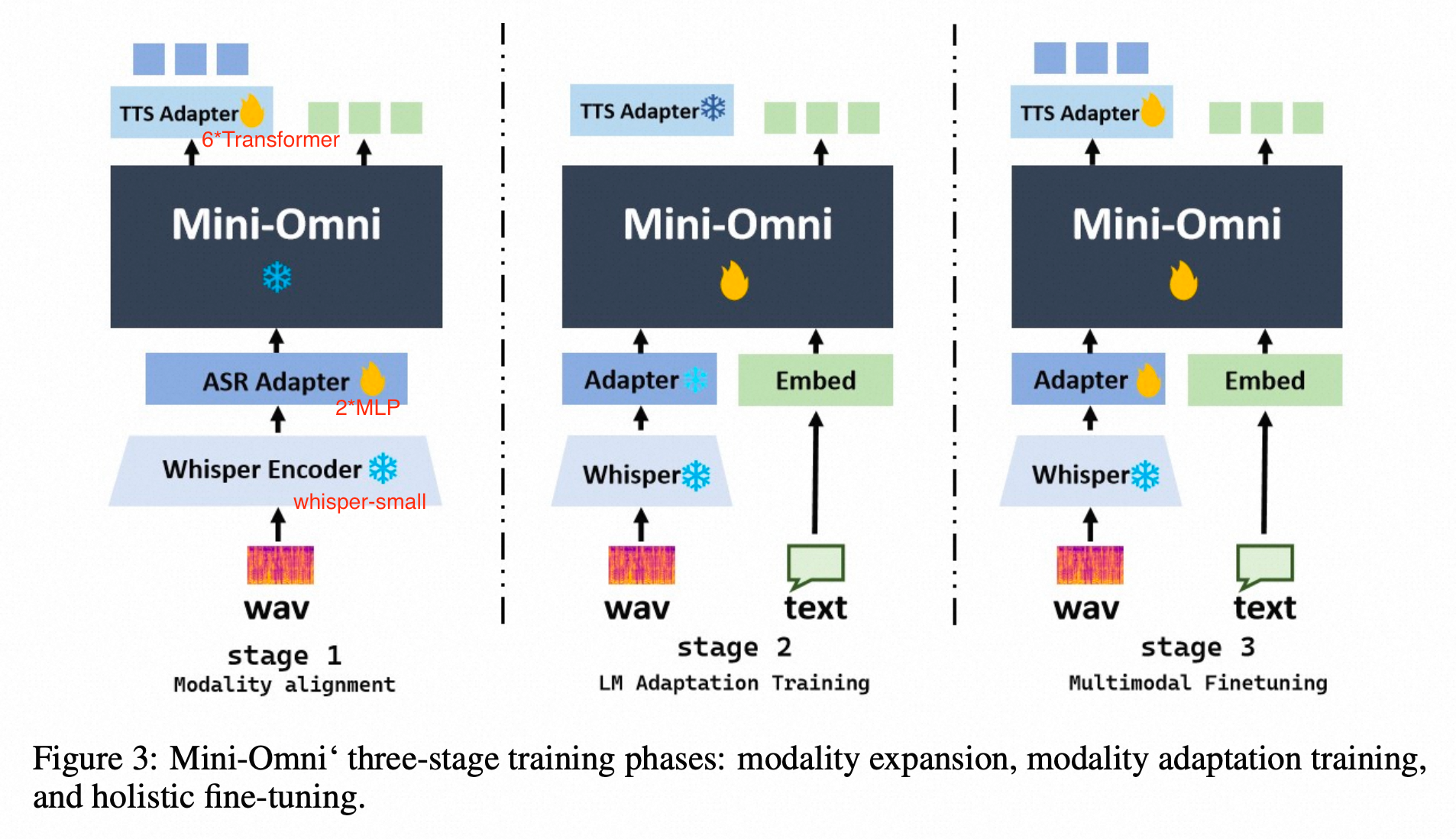
当前位置: 首页 > news >正文 Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming news 2025/8/12 7:24:48 2024.8tsinghua method whisper encoder: whisper small LLM Qwen0.5b init预测方式:text + 7*audio token, parallel generation的方式预测,delay-step=1----先预测文本token,再预测SNAC 第一级码本,然后序列化的逐渐预测后续码本,也遵循了coarse-to-fine的预测; audio token:SNAC的码本,7级 SNAC 的不同级别,码本的预测粒度不同; data VoiceAssistant-400K 的数据集 查看全文 http://www.dtcms.com/a/325831.html 相关文章: 数据库的基本操作(约束与DQL查询) 分治-归并-912.排序数组-力扣(LeetCode) 京东科技集团寻求稳定币链上活动规划师 150V降压芯片DCDC150V100V80V降压12V5V1.5A车载仪表恒压驱动H6203L惠洋科技 shape转换ersi json 修改增加多部件要素处理和空洞处理 安卓\android程序开发之基于 Android 的校园报修系统的设计与实现 Android.mk教程 RFID系统:物联网时代的数字化管理中枢 算法训练营day45 动态规划⑫ 115.不同的子序列、583. 两个字符串的删除操作、72. 编辑距离、编辑距离总结篇 Java -- 集合 --Collection接口和常用的方法 (3万字详解)Linux系统学习:深入了解Linux系统开发工具 leetcode 15 三数之和 【《数字货币量化交易:Linux下策略回测平台的搭建》】 2025-2026 专升本论文写作【八项规范】 [202404-B]画矩形 微信小程序常用 API Arcpy-重采样记录 B站直播, 拼接4个窗口,能否实现 从源码看 Coze:Agent 的三大支柱是如何构建的? 【优化】图片批量合并为word 嵌入式学习day24 MySQL的索引(索引的数据结构-B+树索引): P2865 [USACO06NOV] Roadblocks G 音视频学习(五十三):音频重采样 数据备份与进程管理 AI大模型:(二)5.1 文生视频(Text-to-Video)模型发展史 Apache ECharts 6 核心技术解密 – Vue3企业级可视化实战指南 Apache Ignite 核心组件:GridClosureProcessor解析 ChatML vs Harmony:深度解析OpenAI全新对话结构格式的变化 基于Spring Boot房源信息推荐系统的设计与实现 -项目分享
2024.8tsinghua method whisper encoder: whisper small LLM Qwen0.5b init预测方式:text + 7*audio token, parallel generation的方式预测,delay-step=1----先预测文本token,再预测SNAC 第一级码本,然后序列化的逐渐预测后续码本,也遵循了coarse-to-fine的预测; audio token:SNAC的码本,7级 SNAC 的不同级别,码本的预测粒度不同; data VoiceAssistant-400K 的数据集