JavaWeb-后端Web实战(IOC + DI)
目录
前言
1.开发规范
1.1 前后端分离开发
1.2 Restful
2.环境准备
2.1 Apifox
2.2 工程搭建
3.查询部门
3.1 基本实现
3.1.1 需求
3.1.2 实现思路
3.1.4 @ResponseBody
3.2 统一响应结果
3.2.1 分析
3.2.2 统一响应结果
3.2.3 功能优化
3.3 前后端联调测试
3.3.1 联调测试
3.3.2 请求访问流程
4.分层解耦
4.1 问题分析
4.2 三层架构
4.2.1 介绍
4.2.2 代码拆分
4.2.3 问题分析
4.2.4 程序优化
4.3 分层解耦
4.3.1 问题分析
4.3.2 解耦思路
4.3.3 IOC&DI入门
4.3.4 IOC详解
4.3.5 DI详解
前言
Web开发的基础知识 ,包括 Tomcat、Servlet、HTTP协议等,我们都已经学习完毕了,那接下来,我们就要进入Web开发的实战篇。在实战篇中,我们将通过一个案例,来讲解Web开发的核心技术。
我们先来看一下,在这个实战篇中,我们都要完成哪些功能。
1). 部门管理
2). 员工管理
3). 员工信息统计
4). 日志信息统计
5). 班级管理
6). 学员管理
7). 学员信息统计
8). 登录认证
上述需求,都是在这个案例中,我们需要完成的功能 。
而我们今天主要完成如下功能:
开发规范
环境准备
查询部门
分层解耦(IOC+DI)
1.开发规范
1.1 前后端分离开发
在之前的课程中,我们介绍过,现在的企业项目开发有2种开发模式:前后台混合开发和前后台分离开发。
前后台混合开发,顾名思义就是前台后台代码混在一起开发,如下图所示:

这种开发模式有如下缺点:
-
沟通成本高:后台人员发现前端有问题,需要找前端人员修改,前端修改成功,再交给后台人员使用
-
分工不明确:后台开发人员需要开发后台代码,也需要开发部分前端代码。很难培养专业人才
-
不便管理:所有的代码都在一个工程中
-
难以维护:前端代码更新,和后台无关,但是需要整个工程包括后台一起重新打包部署。
所以我们目前基本都是采用的前后台分离开发方式,如下图所示:
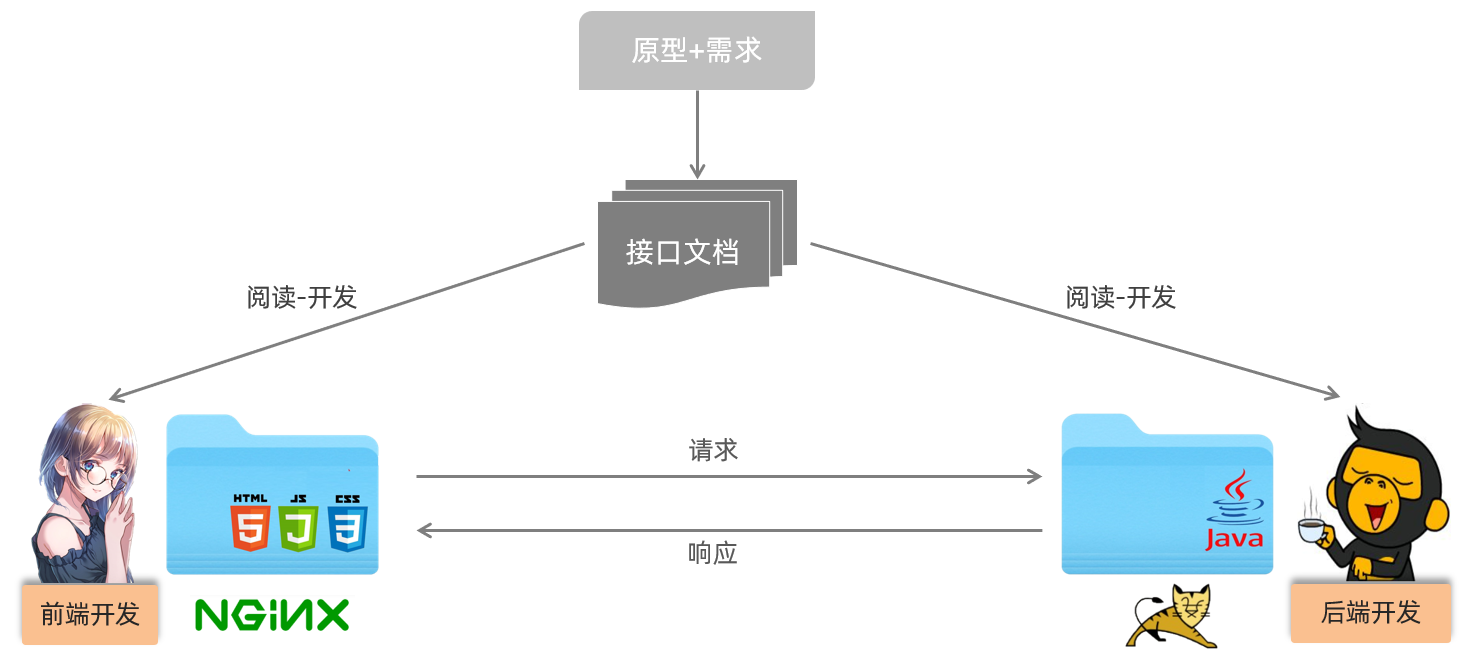
我们将原先的工程分为前端工程和后端工程这2个工程,然后前端工程交给专业的前端人员开发,后端工程交给专业的后端人员开发。
前端页面需要数据,可以通过发送异步请求,从后台工程获取。但是,我们前后台是分开来开发的,那么前端人员怎么知道后台返回数据的格式呢?后端人员开发,怎么知道前端人员需要的数据格式呢?
所以针对这个问题,我们前后台统一制定一套规范!我们前后台开发人员都需要遵循这套规范开发,这就是我们的接口文档。接口文档有离线版和在线版本,接口文档示可以查询今天提供资料/接口文档里面的资料。
那么基于前后台分离开发的模式下,我们后台开发者开发一个功能的具体流程如何呢?如下图所示:

-
需求分析:首先我们需要阅读需求文档,分析需求,理解需求。
-
接口定义:查询接口文档中关于需求的接口的定义,包括地址,参数,响应数据类型等等
-
前后台并行开发:各自按照接口文档进行开发,实现需求
-
测试:前后台开发完了,各自按照接口文档进行测试
-
前后段联调测试:前段工程请求后端工程,测试功能
1.2 Restful
我们的案例是基于当前最为主流的前后端分离模式进行开发。
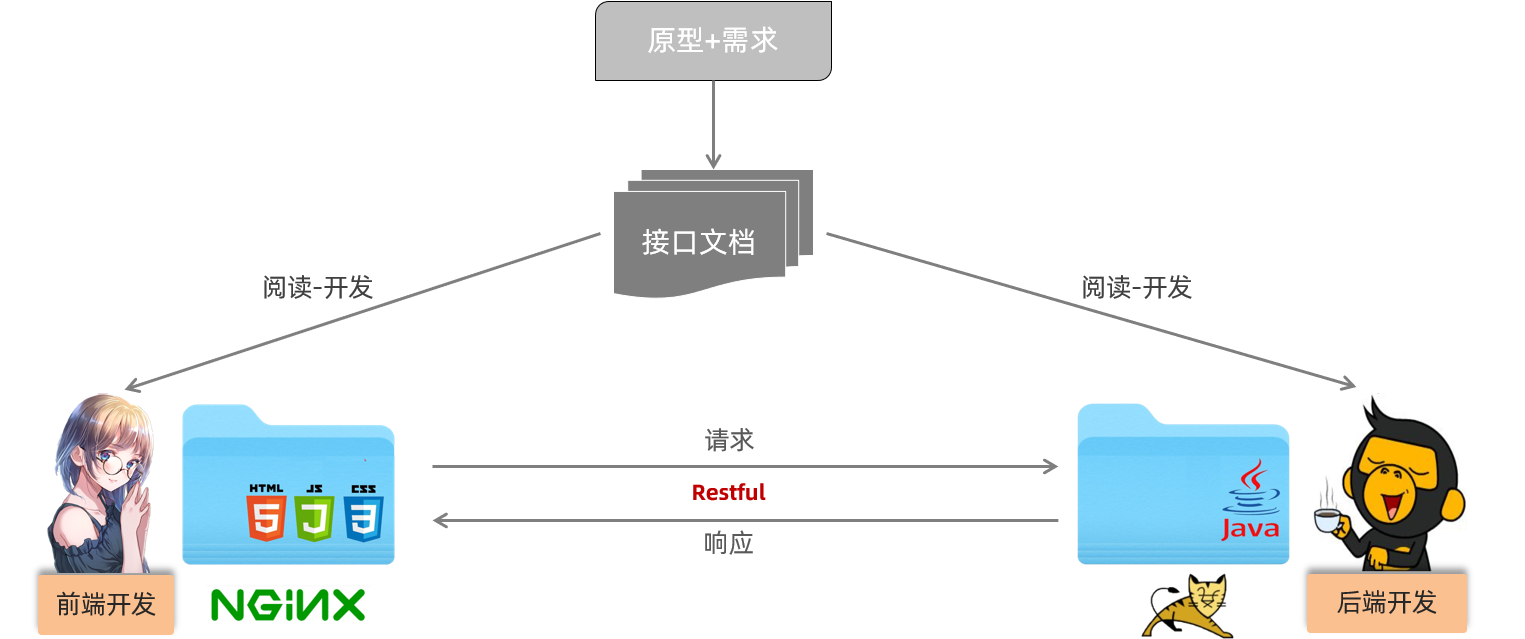
在前后端分离的开发模式中,前后端开发人员都需要根据提前定义好的接口文档,来进行前后端功能的开发。
后端开发人员:必须严格遵守提供的接口文档进行后端功能开发(保障开发的功能可以和前端对接)
而在前后端进行交互的时候,我们需要基于当前主流的REST风格的API接口进行交互。
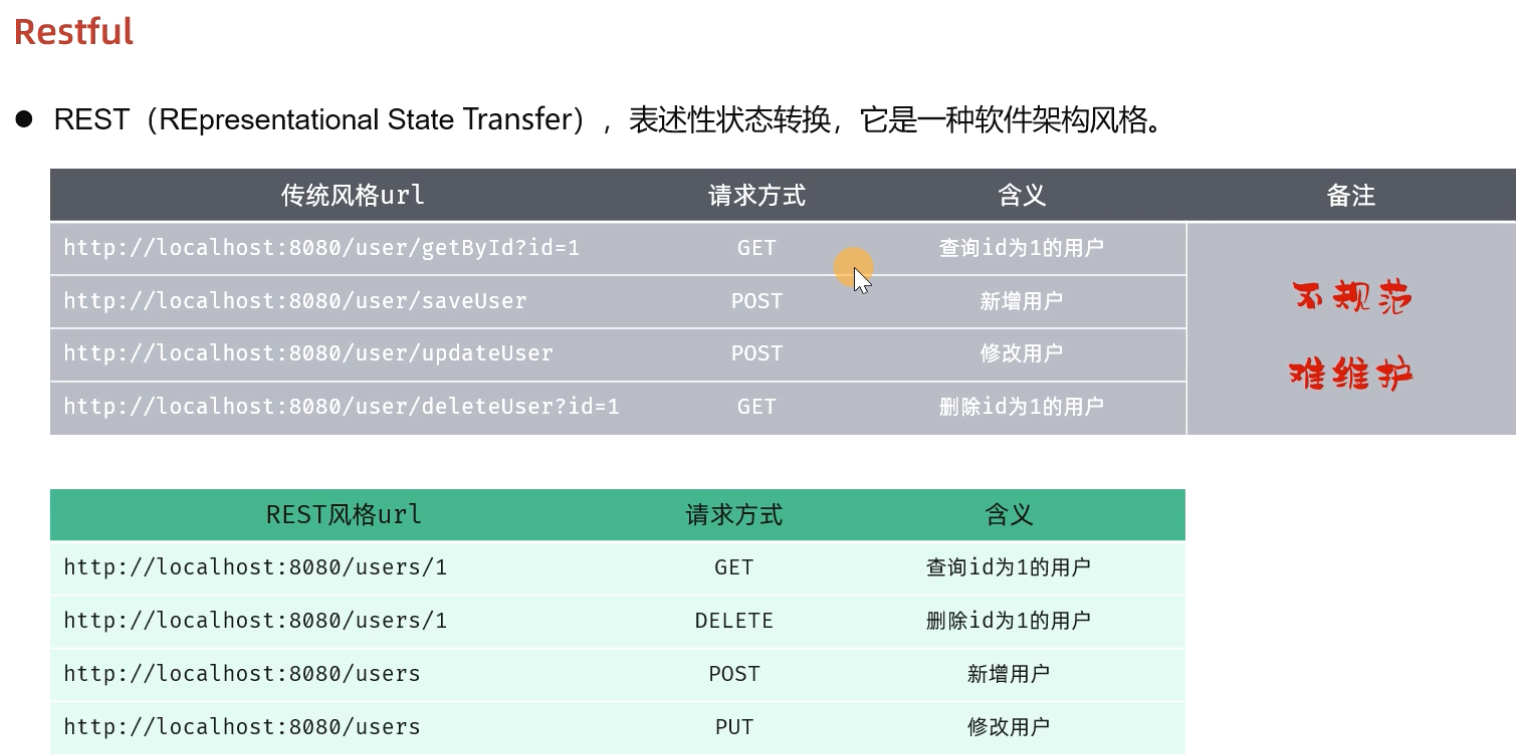
我们看到如果是基于REST风格,定义URL,URL将会更加简洁、更加规范、更加优雅。
注意事项:
REST是风格,是约定方式,约定不是规定,可以打破
描述模块的功能通常使用复数,也就是加s的格式来描述,表示此类资源,而非单个资源。如:users、emps、books…
2.环境准备
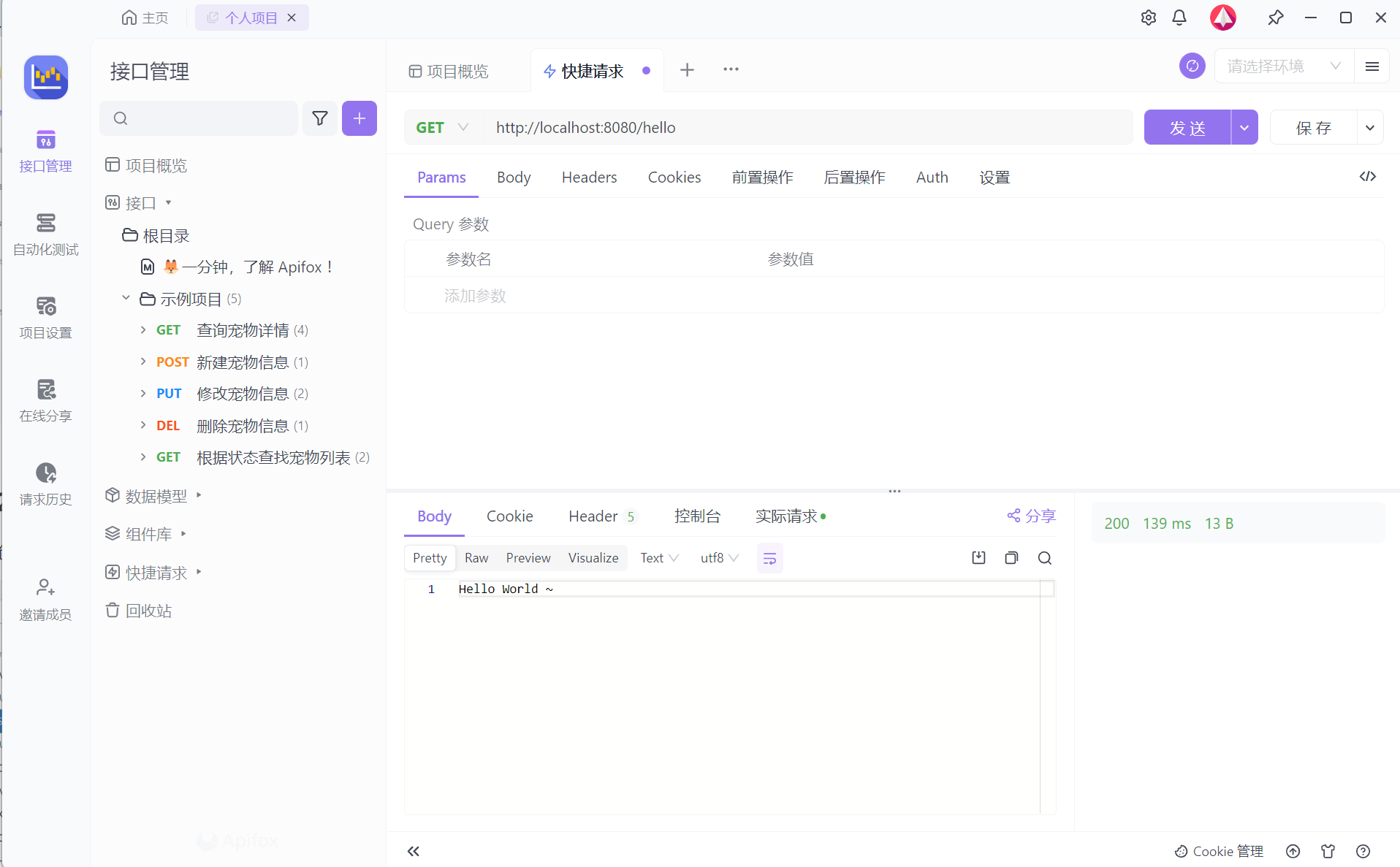
2.1 Apifox
我们上面讲到,在这个案例中,我们将会基于Restful风格的接口进行交互,那么其中就涉及到常见的4中请求方式,包括:POST、DELETE、PUT、GET。
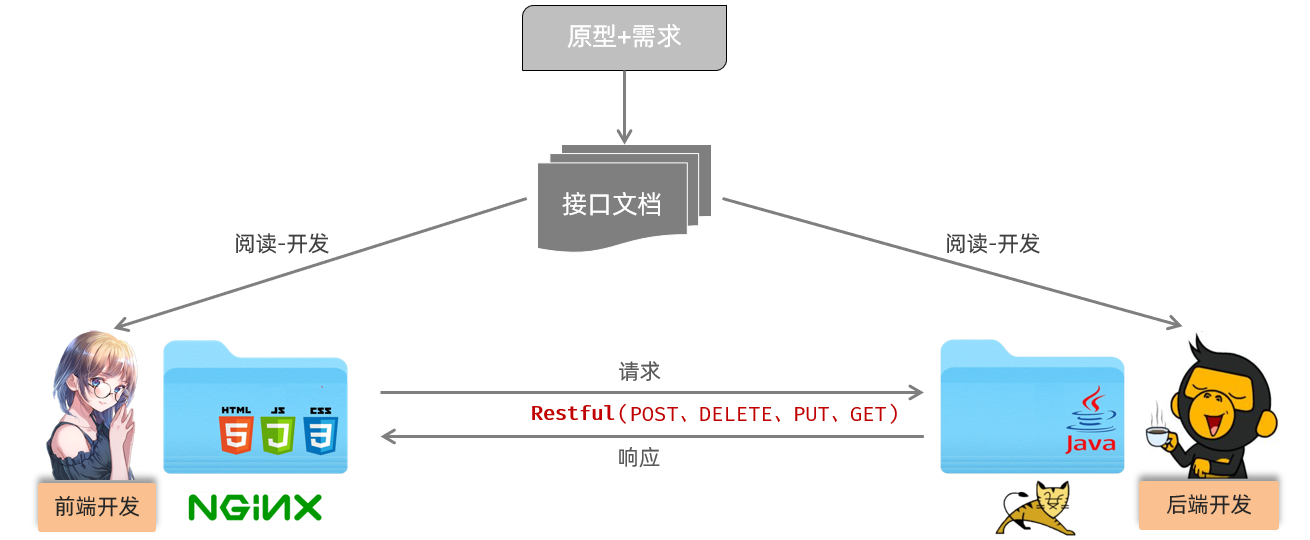

那这里我们就可以借助一些接口测试工具,比如项:Postman、ApiPost、ApiFox等。

那这些工具的使用基本类似,只不过Apifox工具的功能更强强大、更加完善,所以我们会采用功能更为强大的ApiFox工具。

2.2 工程搭建
1). 创建SpringBoot工程,并引入Web开发的起步依赖、lombok的依赖。
3.查询部门
3.1 基本实现
3.1.1 需求
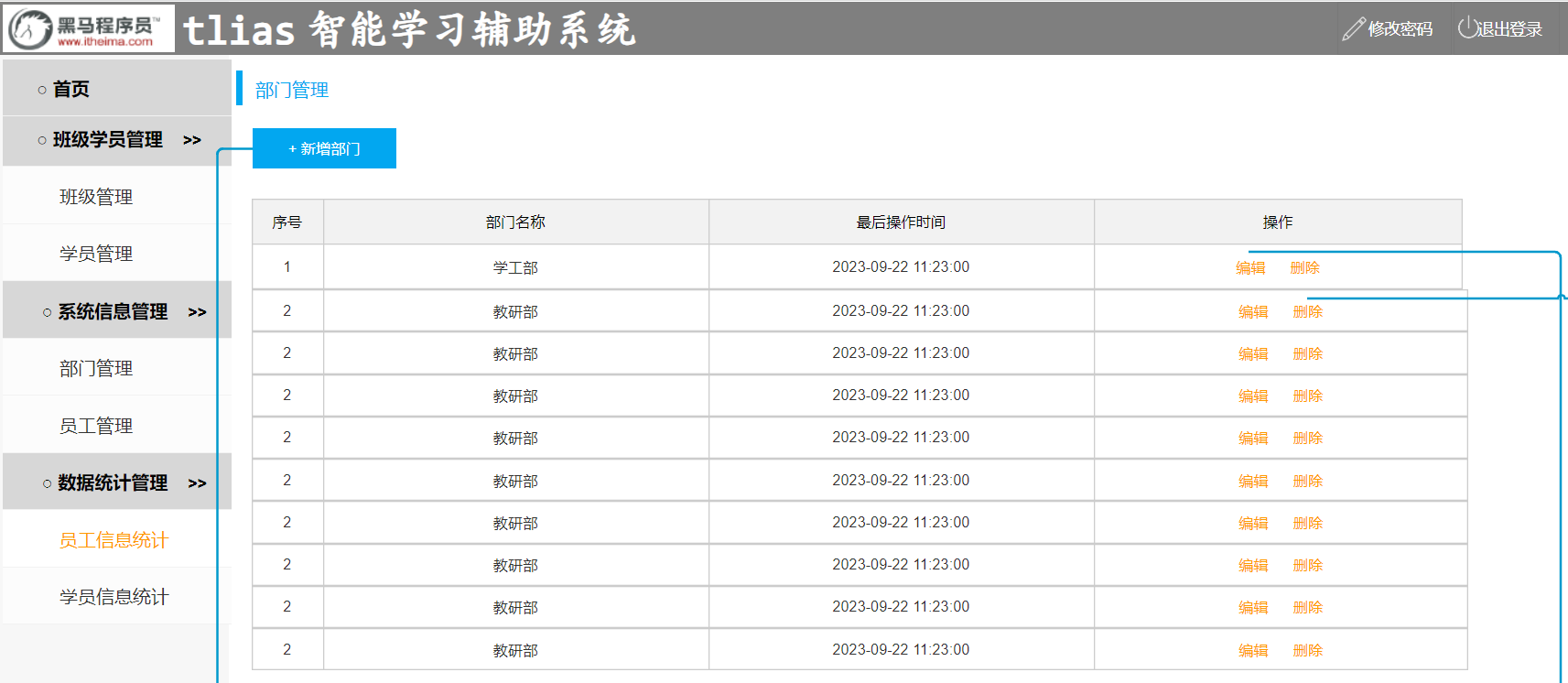
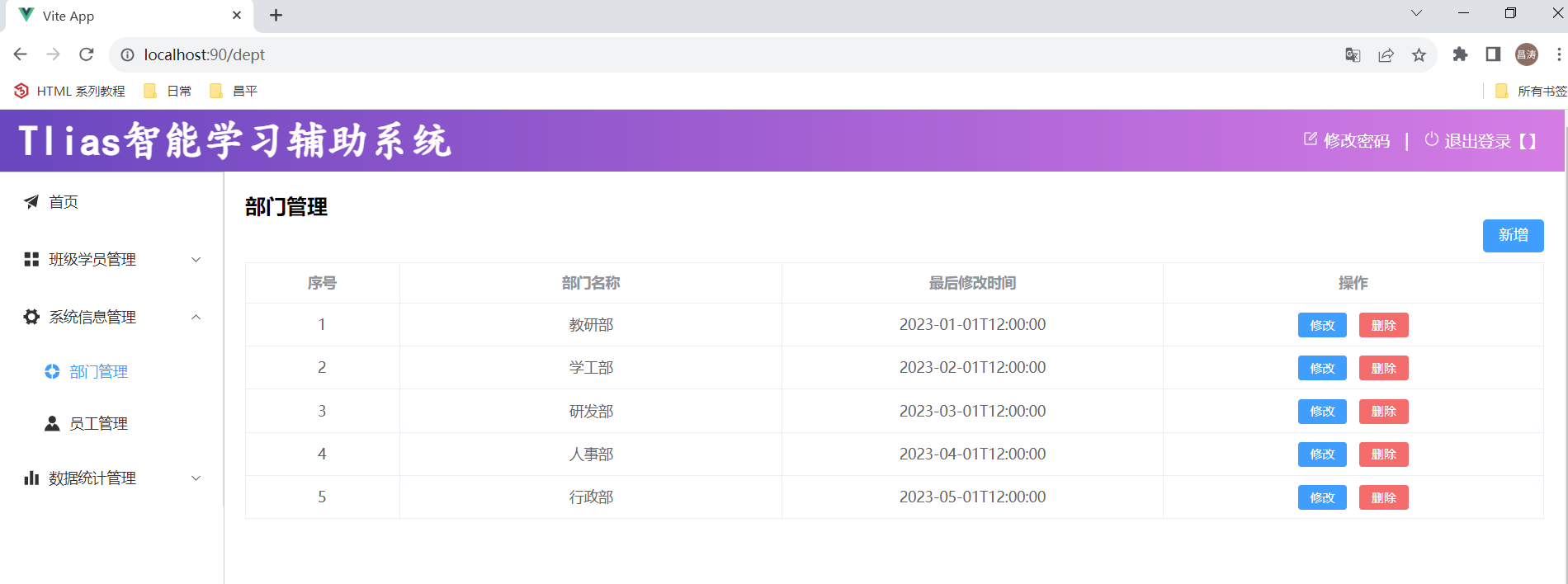
查询所有的部门数据:将 dept.txt 文件中存储的部门数据,查询出来展示在部门管理的页面中。
3.1.2 实现思路
-
加载并读取dept.txt文本中的数据
-
解析文本中的数据,并将其封装为集合
-
响应数据(json格式)
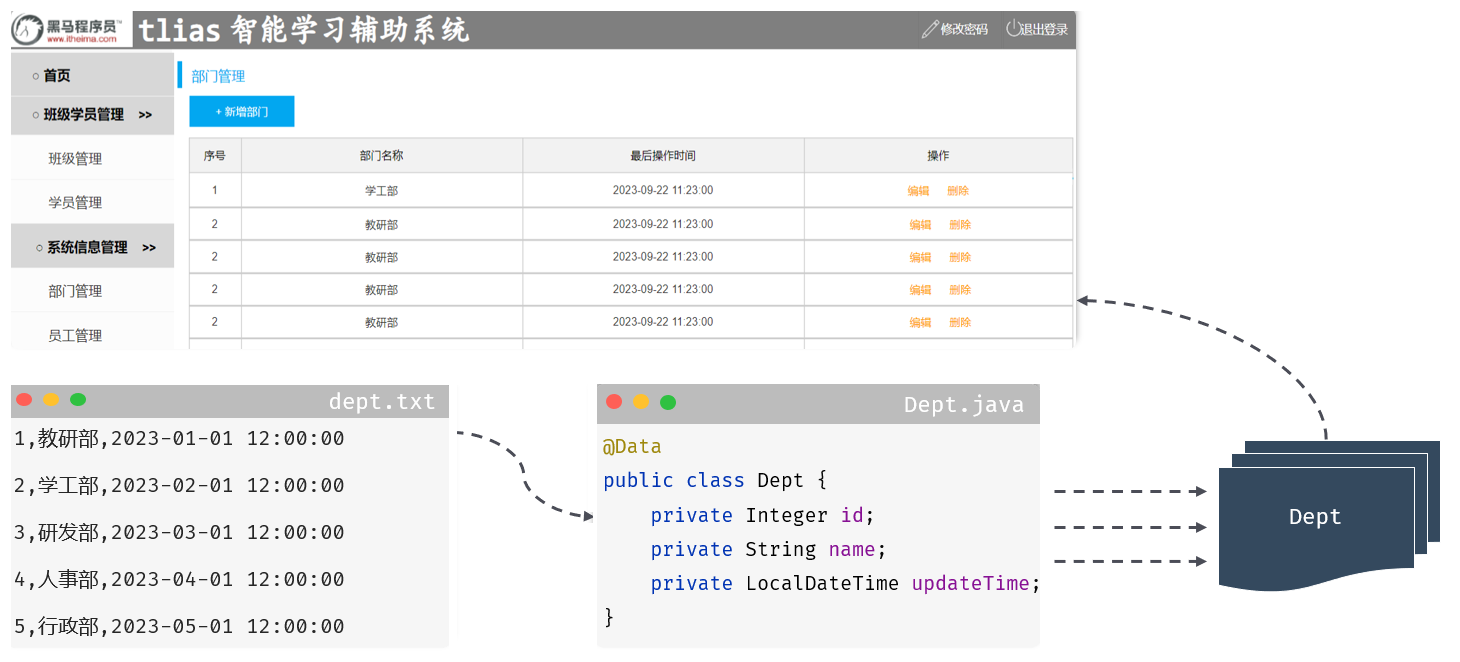
package com.itheima.entity;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;import java.time.LocalDateTime;@Data
@NoArgsConstructor
@AllArgsConstructor
public class Dept {private Integer id;private String name;private LocalDateTime updateTime;}
package com.itheima.controller;import com.itheima.entity.Dept;
import org.apache.commons.io.IOUtils;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.io.InputStream;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.List;
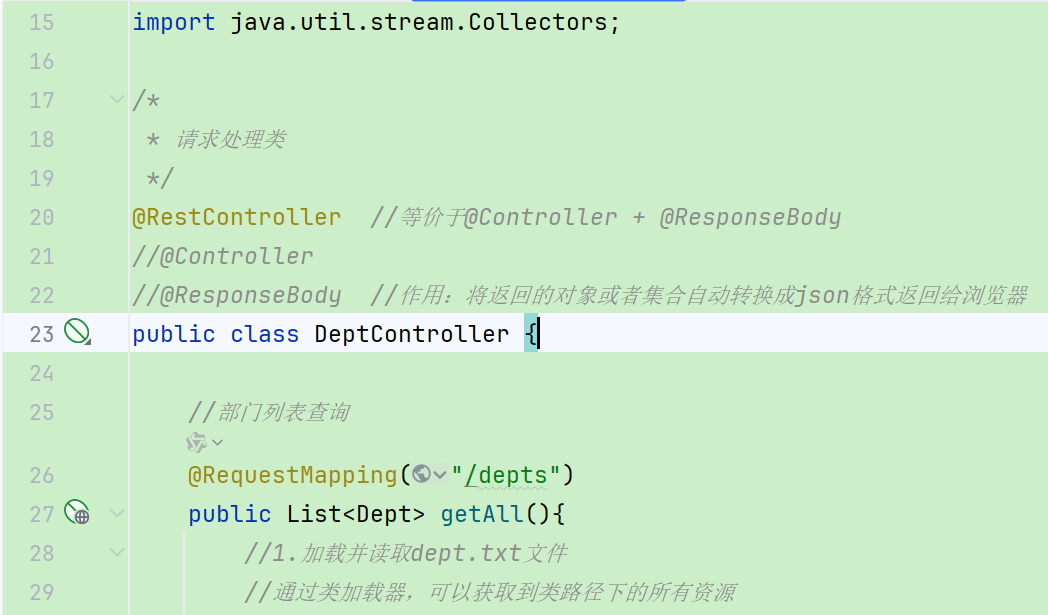
import java.util.stream.Collectors;/** 请求处理类*/
@RestController
public class DeptController {//部门列表查询@RequestMapping("/depts")public List<Dept> getAll(){//1.加载并读取dept.txt文件//通过类加载器,可以获取到类路径下的所有资源InputStream input = this.getClass().getClassLoader().getResourceAsStream("dept.txt");List<String> strings = IOUtils.readLines(input,"UTF-8");//2.解析文本中的数据,并将其封装成集合List<Dept> depts = strings.stream().map((str) -> {String[] parts = str.split(",");Integer id = Integer.valueOf(parts[0]);String name = parts[1];LocalDateTime updateTime = LocalDateTime.parse(parts[2], DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));return new Dept(id, name, updateTime);}).collect(Collectors.toList());// List<Dept> depts = new ArrayList<>();
// for (String str : strings) {
// String[] parts = str.split(",");
// Integer id = Integer.valueOf(parts[0]);
// String name = parts[1];
// LocalDateTime updateTime = LocalDateTime.parse(parts[2]);
// Dept dept = new Dept(id, name, updateTime);
// depts.add(dept);
// }//3.将集合中的数据以json格式返回给浏览器return depts;}
}
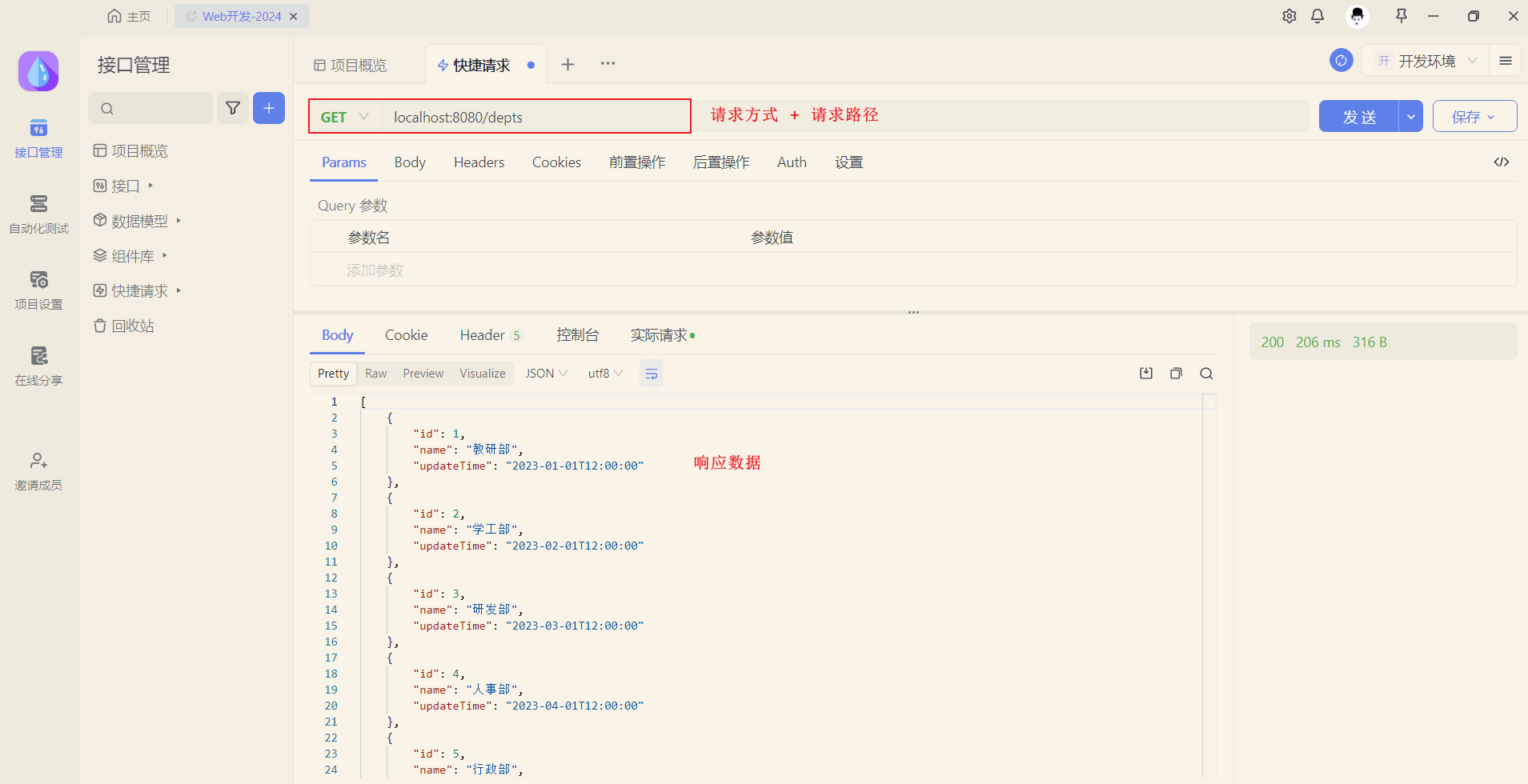
打开Apifox,来测试当前接口:
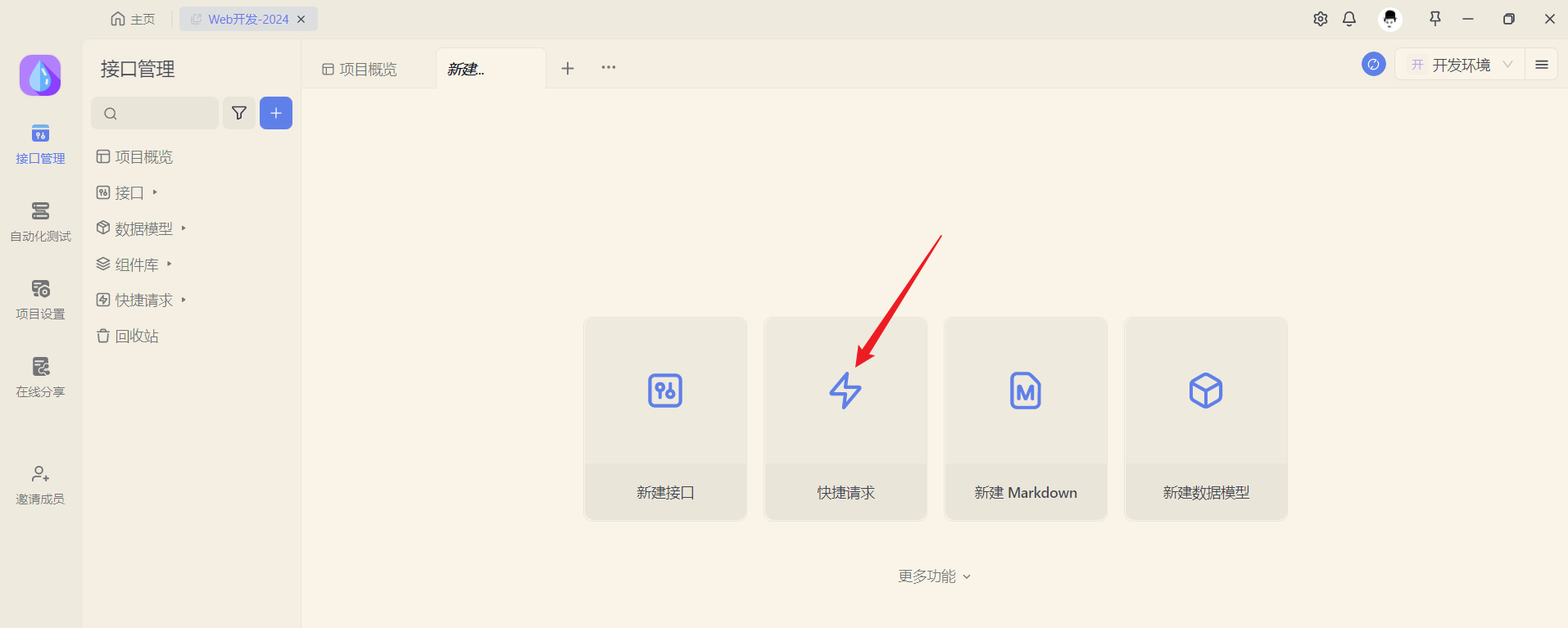
新建请求,请求 http://localhost:8080/depts
3.1.4 @ResponseBody
为什么上面的代码中只需要return depts;就可以返回json格式的数据给浏览器呢?
3.2 统一响应结果
3.2.1 分析
1). 刚才我们执行查询部门操作,查询返回的结果是一个List<Dept> ,原始代码及响应给前端的结果如下:

2). 如果我们还要实现一个需求,根据ID查询部门名称,原始代码及响应给前端的结果如下:
 3). 如果我们还要实现一个需求,根据ID查询部门数据,原始代码及响应给前端的结果如下:
3). 如果我们还要实现一个需求,根据ID查询部门数据,原始代码及响应给前端的结果如下:
 上述的每一个需求我们都能实现,但是所有的RestController的方法返回值是各式各样的,最终就会造成项目不便管理、难以维护。
上述的每一个需求我们都能实现,但是所有的RestController的方法返回值是各式各样的,最终就会造成项目不便管理、难以维护。
而为了解决这个问题,我们就需要统一响应结果。 也就是说,无论什么实现什么功能,最终响应给前端的格式应该是统一的 。
3.2.2 统一响应结果
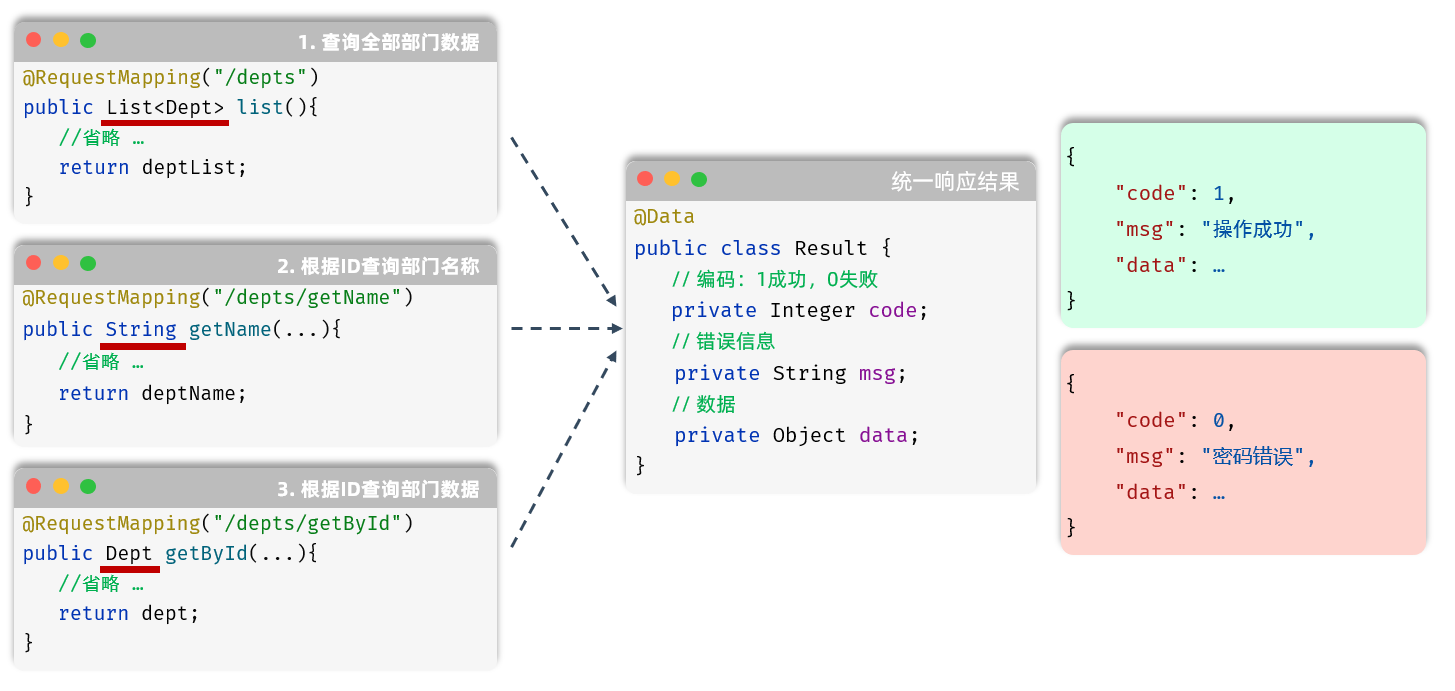
前端:只需要按照统一格式的返回结果进行解析(仅一种解析方案),就可以拿到数据。
统一的返回结果使用类来描述,在这个结果中包含:
-
响应状态码:当前请求是成功,还是失败
-
状态码信息:给页面的提示信息
-
返回的数据:给前端响应的数据(字符串、对象、集合)
定义在一个实体类Result来包含以上信息。代码如下:
package com.itheima.entity;import lombok.Data;import java.io.Serializable;/*** 后端统一返回结果*/
@Data
public class Result {private Integer code; //编码:1成功,0为失败private String msg; //错误信息private Object data; //数据public static Result success() {Result result = new Result();result.code = 1;result.msg = "success";return result;}public static Result success(Object object) {Result result = new Result();result.data = object;result.code = 1;result.msg = "success";return result;}public static Result error(String msg) {Result result = new Result();result.msg = msg;result.code = 0;return result;}}
3.2.3 功能优化
1). 引入统一响应结果 Result
2). 改造DeptController中的方法返回值
package com.itheima.controller;import com.itheima.entity.Dept;
import com.itheima.entity.Result;
import org.apache.commons.io.IOUtils;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;import java.io.InputStream;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;/** 请求处理类*/
@RestController //等价于@Controller + @ResponseBody
//@Controller
//@ResponseBody //作用:将返回的对象或者集合自动转换成json格式返回给浏览器
public class DeptController {//部门列表查询//@RequestMapping(value = "/depts",method = RequestMethod.GET)@GetMapping("/depts") //限制请求方式为GETpublic Result getAll() {//1.加载并读取dept.txt文件//通过类加载器,可以获取到类路径下的所有资源InputStream input = this.getClass().getClassLoader().getResourceAsStream("dept.txt");List<String> strings = IOUtils.readLines(input, "UTF-8");//2.解析文本中的数据,并将其封装成集合List<Dept> depts = strings.stream().map((str) -> {String[] parts = str.split(",");Integer id = Integer.valueOf(parts[0]);String name = parts[1];LocalDateTime updateTime = LocalDateTime.parse(parts[2], DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));return new Dept(id, name, updateTime);}).collect(Collectors.toList());// List<Dept> depts = new ArrayList<>();
// for (String str : strings) {
// String[] parts = str.split(",");
// Integer id = Integer.valueOf(parts[0]);
// String name = parts[1];
// LocalDateTime updateTime = LocalDateTime.parse(parts[2]);
// Dept dept = new Dept(id, name, updateTime);
// depts.add(dept);
// }//3.将集合中的数据以json格式返回给浏览器return Result.success(depts);}
}
而我们在测试时候发现,即使我们将请求方式设置为 POST PUT DELETE,也都是可以请求成功的。 如下所示:
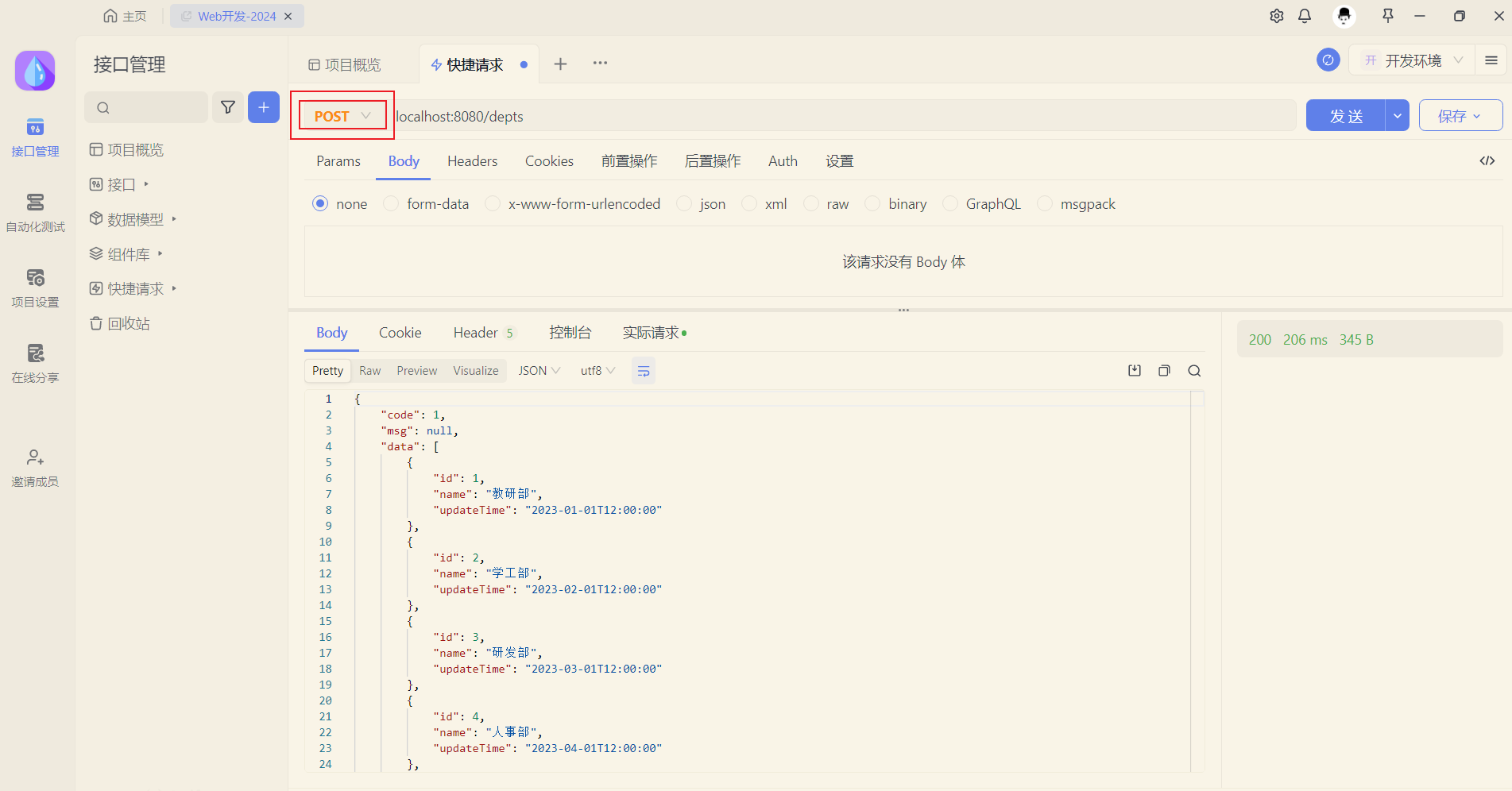
这是因为,我们服务器端,也就是RestController程序中并没有限制该接口的请求方式,那么此时任何请求方式都是可以的。 如果要设置请求方式,可以通过如下两种方式来设置:
-
在controller的方法上,声明
@RequestMapping注解的method属性,通过method属性指定请求方式。 如下:
@RequestMapping(value = "/depts", method = RequestMethod.GET)直接使用 `@GetMapping` 来替换 @RequestMapping 注解,@GetMapping其实就是对@RequestMapping的封装,并限定了请求方式为GET。
@GetMapping("/depts")3.3 前后端联调测试
3.3.1 联调测试
完成了查询部门的功能,我们也通过 Apifox 工具测试通过了,下面我们再基于前后端分离的方式进行接口联调。具体操作如下:
1.双击启动nginx.exe启动Nginx。
2.打开浏览器,访问:http://localhost:90
3.测试:系统信息管理 -> 查询部门列表
3.3.2 请求访问流程
前端工程请求服务器的地址为http://localhost:90/dept,但我们原来的地址是http://localhost:8080/depts,他是如何访问到后端的tomcat服务器的?
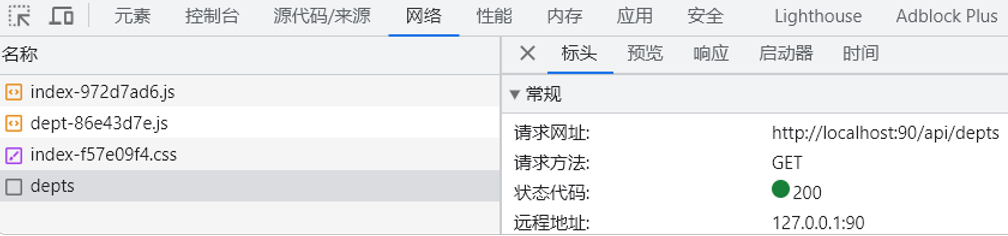
其实这是通过Nginx中提供的反向代理功能实现的。
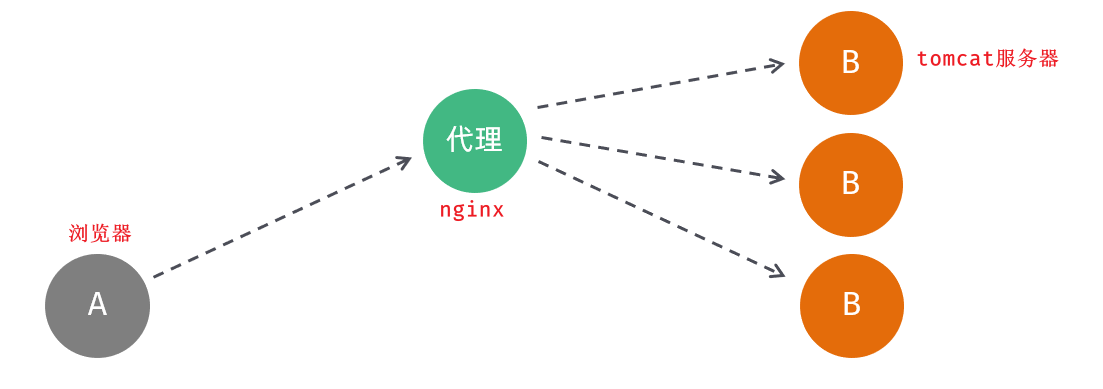 1.浏览器发起请求,请求的是localhost:90,那其实请求的是nginx服务器。
1.浏览器发起请求,请求的是localhost:90,那其实请求的是nginx服务器。
2.在nginx服务器中,并没有对请求直接进行处理,而是将请求转发给了后端的tomcat服务器,最终由tomcat服务器来处理该请求。
这个过程就是通过nginx的反向代理实现的,那为什么浏览器不直接请求后端的tomcat服务器,而是直接请求nginx服务器呢,主要有以下几点原因:
1). 安全:由于后端的tomcat服务器一般都会搭建集群,会有很多的服务器,把所有的tomcat暴露给前端,让前端直接请求tomcat,对于后端服务器是比较危险的。
2). 灵活:基于nginx的反向代理实现,更加灵活,后端想增加、减少服务器,对于前端来说是无感知的,只需要在nginx中配置即可。
3). 负载均衡:基于nginx的反向代理,可以很方便的实现后端tomcat的负载均衡操作。
具体的请求访问流程如下:
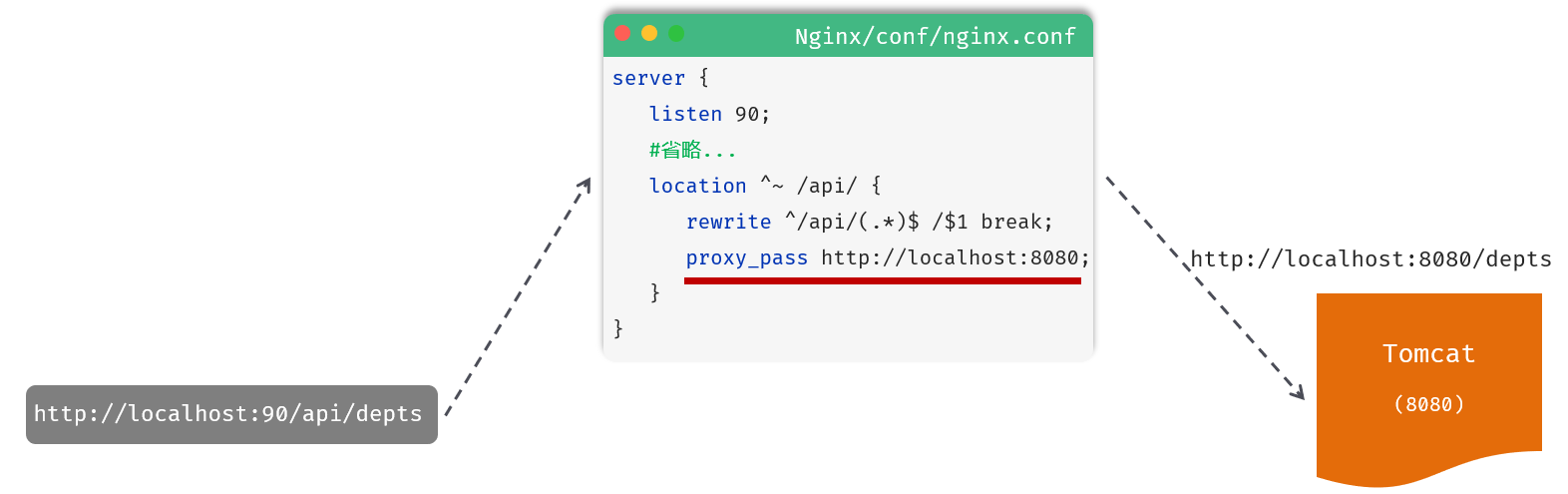
location:用于定义匹配特定uri请求的规则。
^~ /api/:表示精确匹配,即只匹配以/api/开头的路径。
rewrite:该指令用于重写匹配到的uri路径。
proxy_pass:该指令用于代理转发,它将匹配到的请求转发给位于后端的指令服务器。
4.分层解耦
4.1 问题分析
上述案例的功能,我们虽然已经实现,但是我们发现案例中解析文本文件中的数据,处理数据的逻辑代码,给页面响应的代码全部都堆积在一起了,全部都写在controller方法中了

当前程序的这个业务逻辑还是比较简单的,如果业务逻辑再稍微复杂一点,我们会看到Controller方法的代码量就很大了。
-
当我们要修改操作数据部分的代码,需要改动Controller
-
当我们要完善逻辑处理部分的代码,需要改动Controller
-
当我们需要修改数据响应的代码,还是需要改动Controller
这样呢,就会造成我们整个工程代码的复用性比较差,而且代码难以维护。 那如何解决这个问题呢?其实在现在的开发中,有非常成熟的解决思路,那就是分层开发。
4.2 三层架构
4.2.1 介绍
在我们进行程序设计以及程序开发时,尽可能让每一个接口、类、方法的职责更单一些(单一职责原则)。
单一职责原则:一个类或一个方法,就只做一件事情,只管一块功能。
这样就可以让类、接口、方法的复杂度更低,可读性更强,扩展性更好,也更利用后期的维护。
我们之前开发的程序呢,并不满足单一职责原则。下面我们来分析下之前的程序:
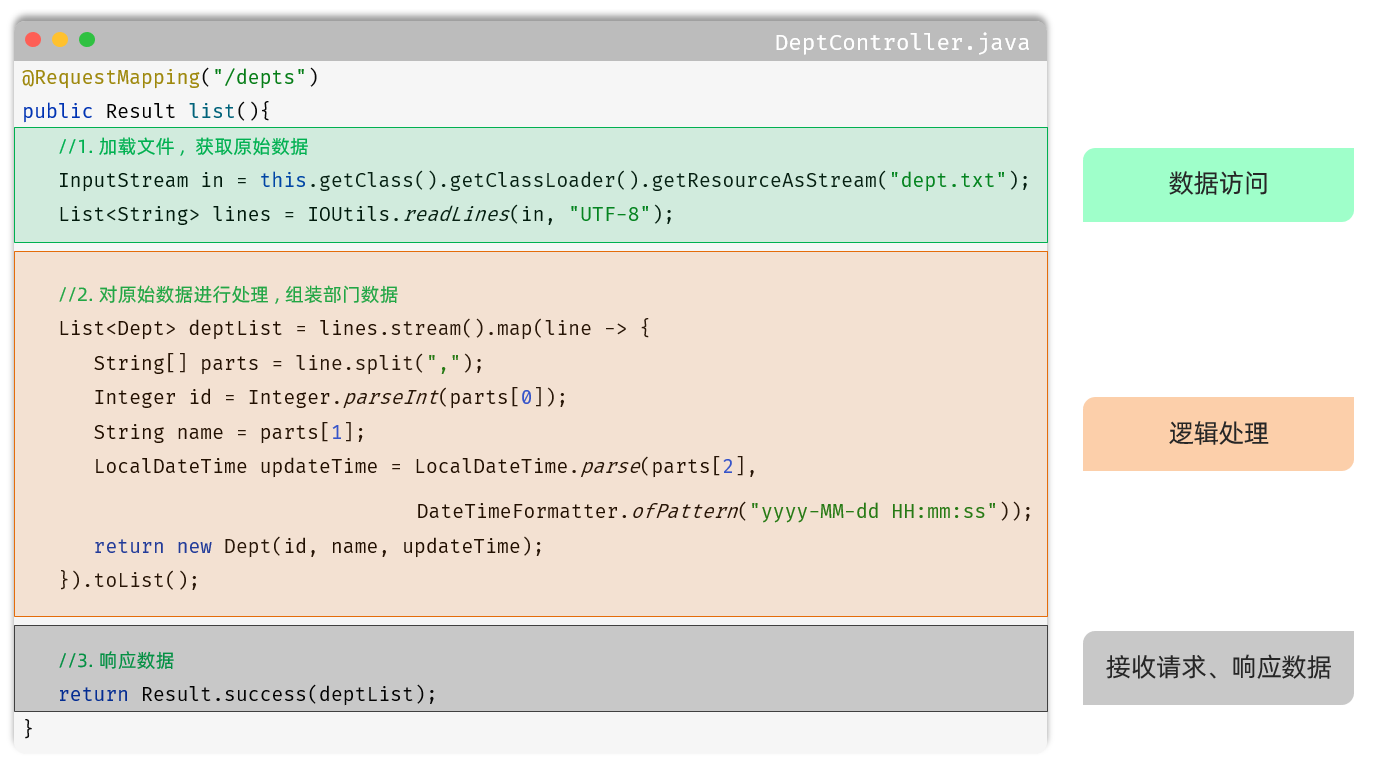
那其实我们上述案例的处理逻辑呢,从组成上看可以分为三个部分:
-
数据访问:负责业务数据的维护操作,包括增、删、改、查等操作。
-
逻辑处理:负责业务逻辑处理的代码。
-
请求处理、响应数据:负责,接收页面的请求,给页面响应数据。
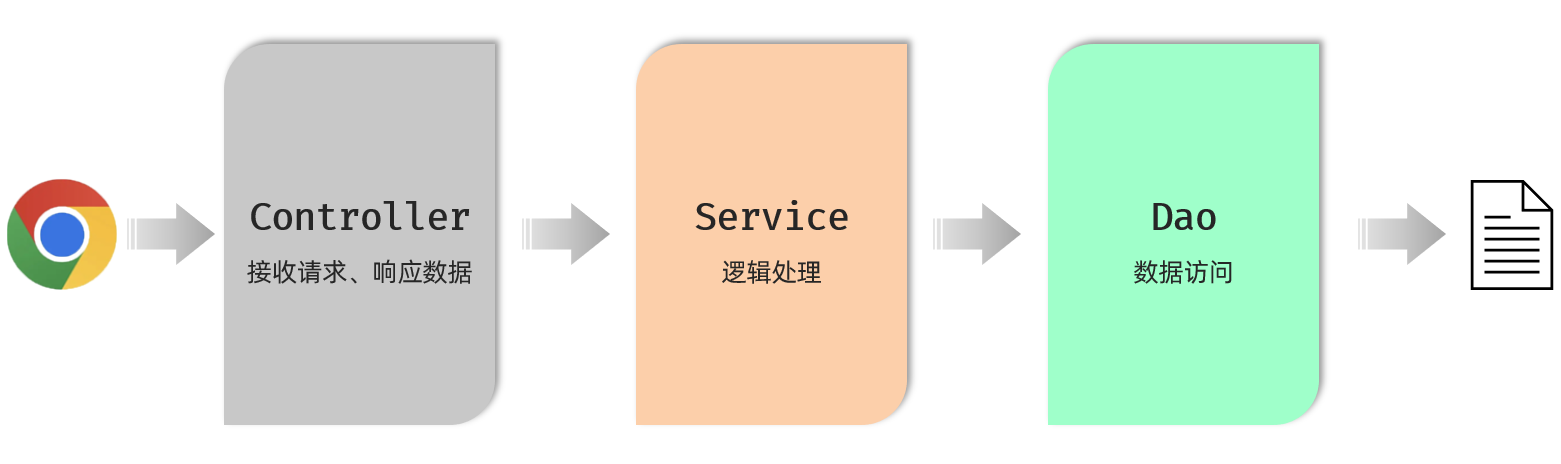
按照上述的三个组成部分,在我们项目开发中呢,可以将代码分为三层,如图所示:

-
Controller:控制层。接收前端发送的请求,对请求进行处理,并响应数据。
-
Service:业务逻辑层。处理具体的业务逻辑。
-
Dao:数据访问层(Data Access Object),也称为持久层。负责数据访问操作,包括数据的增、删、改、查。
基于三层架构的程序执行流程,如图所示:
-
前端发起的请求,由Controller层接收(Controller响应数据给前端)
-
Controller层调用Service层来进行逻辑处理(Service层处理完后,把处理结果返回给Controller层)
-
Serivce层调用Dao层(逻辑处理过程中需要用到的一些数据要从Dao层获取)
-
Dao层操作文件中的数据(Dao拿到的数据会返回给Service层)
思考:按照三层架构的思想,如何要对业务逻辑(Service层)进行变更,会影响到Controller层和Dao层吗?
答案:不会影响。 (程序的扩展性、维护性变得更好了)
4.2.2 代码拆分
我们使用三层架构思想,来改造下之前的程序:
-
控制层包名:com.itheima.controller
-
业务逻辑层包名:com.itheima.service.impl
-
数据访问层包名:com.itheima.dao.impl
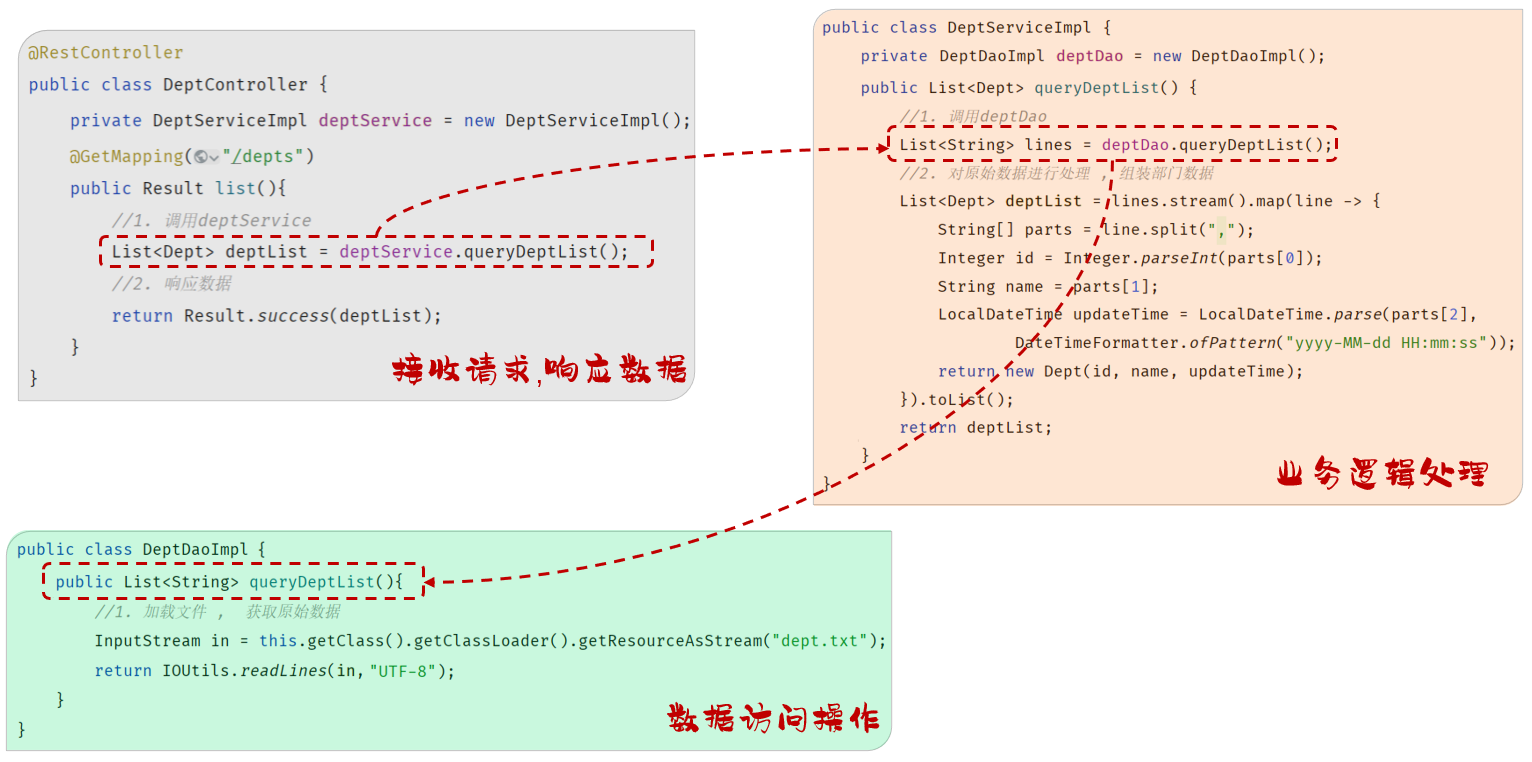
1). 控制层:接收前端发送的请求,对请求进行处理,并响应数据
@RestController
public class DeptController {private DeptServiceImpl deptService = new DeptServiceImpl();@GetMapping("/depts")public Result list(){//1. 调用deptServiceList<Dept> deptList = deptService.queryDeptList();//2. 响应数据return Result.success(deptList);}}2). 业务逻辑层:处理具体的业务逻辑
public class DeptServiceImpl {private DeptDaoImpl deptDao= new DeptDaoImpl();@Overridepublic List<Dept> queryDeptList() {//1. 调用deptDaoList<String> lines = deptDao.queryDeptList();//2. 对原始数据进行处理 , 组装部门数据List<Dept> deptList = lines.stream().map(line -> {String[] parts = line.split(",");Integer id = Integer.parseInt(parts[0]);String name = parts[1];LocalDateTime updateTime = LocalDateTime.parse(parts[2],DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));return new Dept(id, name, updateTime);}).toList();//......return deptList;}
}3). 数据访问层:负责数据的访问操作,包含数据的增、删、改、查
public class DeptDaoImpl {@Overridepublic List<String> queryDeptList(){//1. 加载文件 , 获取原始数据InputStream in = this.getClass().getClassLoader().getResourceAsStream("dept.txt");return IOUtils.readLines(in, "UTF-8");}
}
具体的请求调用流程:
三层架构的好处:
-
复用性强
-
便于维护
-
利用扩展
4.2.3 问题分析
Dao层在进行获取数据时,可能是从文件中获取 ,也可能有数据库中获取 ,那也就意味着Dao层的实现方式有多种 。
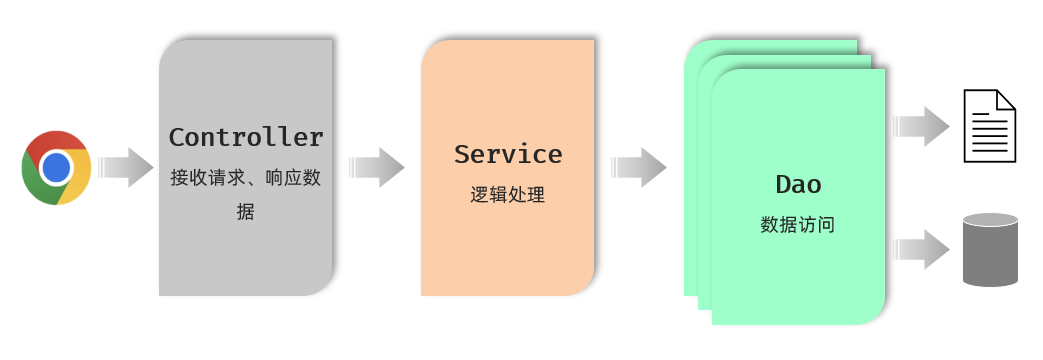
Dao层的实现方式有多种,我们可以用接口和面向接口编程来增强程序的扩展性,接下来我们就需要为Dao层,Service层来设计对应的接口,并让实现类继承对应的接口。
4.2.4 程序优化
1). Dao层
接口:
public interface DeptDao {//查询全部部门数据public List<String> queryDeptList();
}实现:
public class DeptDaoImpl implements DeptDao {@Overridepublic List<String> queryDeptList(){//1. 加载文件 , 获取原始数据InputStream in = this.getClass().getClassLoader().getResourceAsStream("dept.txt");return IOUtils.readLines(in, "UTF-8");}
}2). Service层
接口:
public interface DeptService {//查询所有的部门数据public List<Dept> queryDeptList();
}实现:
public class DeptServiceImpl implements DeptService {private DeptDao deptDao= new DeptDaoImpl();@Overridepublic List<Dept> queryDeptList() {//1. 调用deptDaoList<String> lines = deptDao.queryDeptList();//2. 对原始数据进行处理 , 组装部门数据List<Dept> deptList = lines.stream().map(line -> {String[] parts = line.split(",");Integer id = Integer.parseInt(parts[0]);String name = parts[1];LocalDateTime updateTime = LocalDateTime.parse(parts[2],DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));return new Dept(id, name, updateTime);}).toList();//......return deptList;}
}3). Controller层
由于Controller层,就是请求处理层,用来接收请求,响应数据,不涉及到数据的访问、也不涉及逻辑处理,所以一般可以不要接口。
@RestController
public class DeptController {private DeptService deptService = new DeptServiceImpl();//多态@GetMapping("/depts")public Result list(){//1. 调用deptServiceList<Dept> deptList = deptService.queryDeptList();//2. 响应数据return Result.success(deptList);}}
如果是面向接口编程,扩展的时候就只需要加一个实现类就好,不需要改动原来的实现类,对扩展开放,对修改封闭,遵守开放封闭原则
4.3 分层解耦
4.3.1 问题分析
由于我们现在在程序中,需要什么对象,直接new一个对象 new DeptServiceImpl() 。
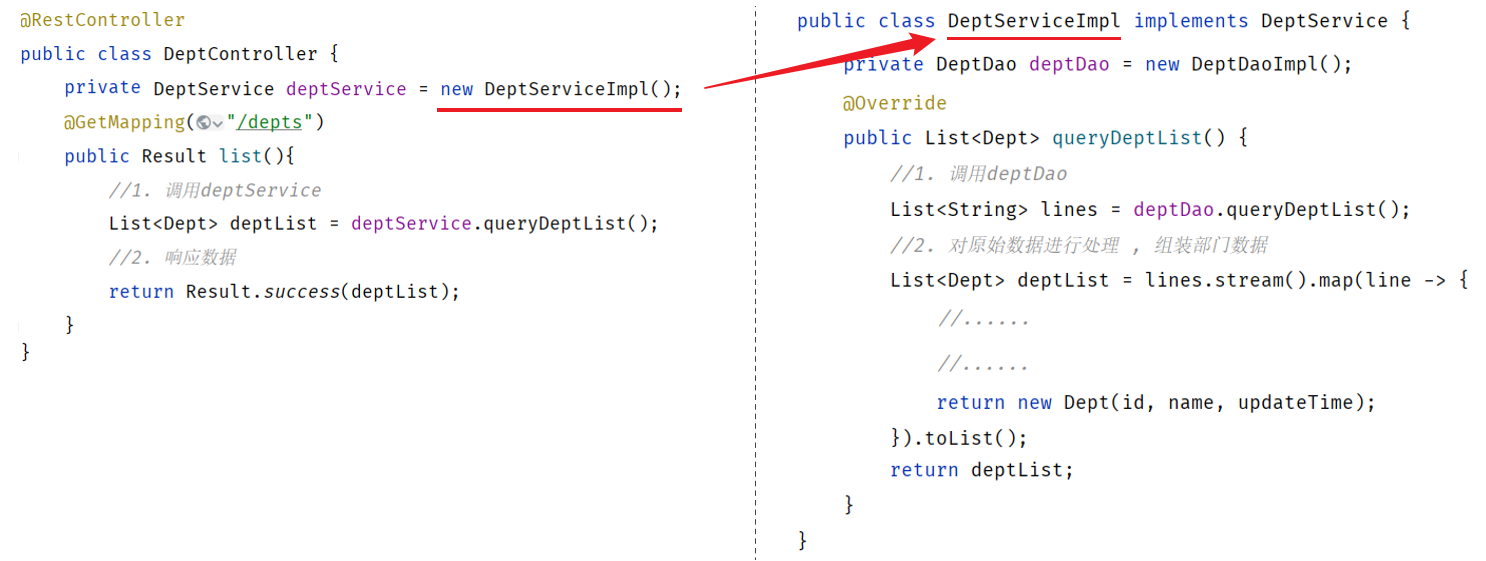
如果说我们需要更换实现类,比如由于业务的变更,DeptServiceImpl不能满足现有的业务需求,我们需要切换为DeptServiceImpl2这套实现,就需要修改Contorller的代码,需要重新创建DeptServiceImpl2 的实现new DeptServiceImpl2() 。
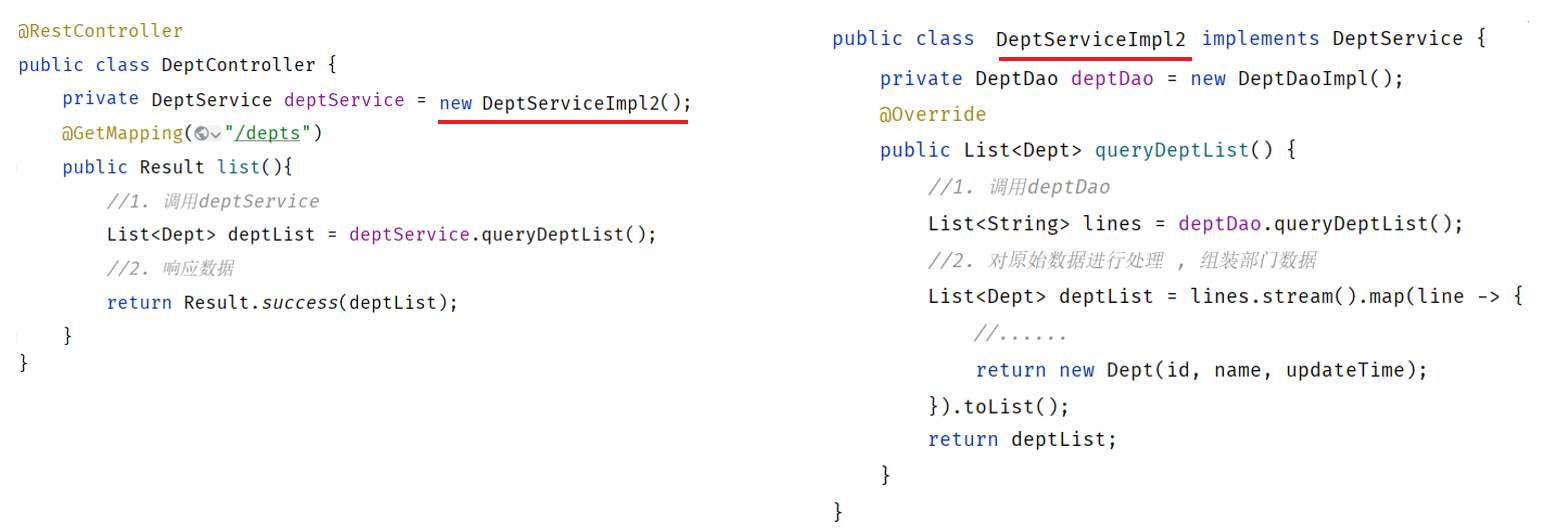
Service中调用Dao,也是类似的问题,这种问题我们称为层与层之间耦合了,什么是耦合呢?
首先需要了解软件开发涉及到的两个概念:内聚和耦合。
-
内聚:软件中各个功能模块内部的功能联系。
-
耦合:衡量软件中各个层/模块之间的依赖、关联的程度。
软件设计原则:高内聚低耦合。
高内聚:指的是一个模块中各个元素之间的联系的紧密程度,如果各个元素(语句、程序段)之间的联系程度越高,则内聚性越高,即 "高内聚"。
低耦合:指的是软件中各个层、模块之间的依赖关联程序越低越好。
目前层与层之间是存在耦合的,Controller耦合了Service、Service耦合了Dao。而 高内聚、低耦合的目的是使程序模块的可重用性、移植性大大增强。
那最终我们的目标呢,就是做到层与层之间,尽可能的降低耦合,甚至解除耦合。
4.3.2 解耦思路
之前我们在编写代码时,需要什么对象,直接new一个就可以了。这种做法层与层之间就会耦合,当service层的实现变了之后,我们还需要修改controller层的代码,那么应该怎么解耦呢?
1). 首先不能在EmpController中使用new对象。代码如下:

此时,就存在另一个问题了,不能new,就意味着没有业务层对象(程序运行就报错),怎么办呢?
我们的解决思路是:
-
提供一个容器,容器中存储一些对象(例:DeptService对象)
-
Controller程序从容器中获取DeptService类型的对象
2). 将要用到的对象交给一个容器管理。

3). 应用程序中用到这个对象,就直接从容器中获取
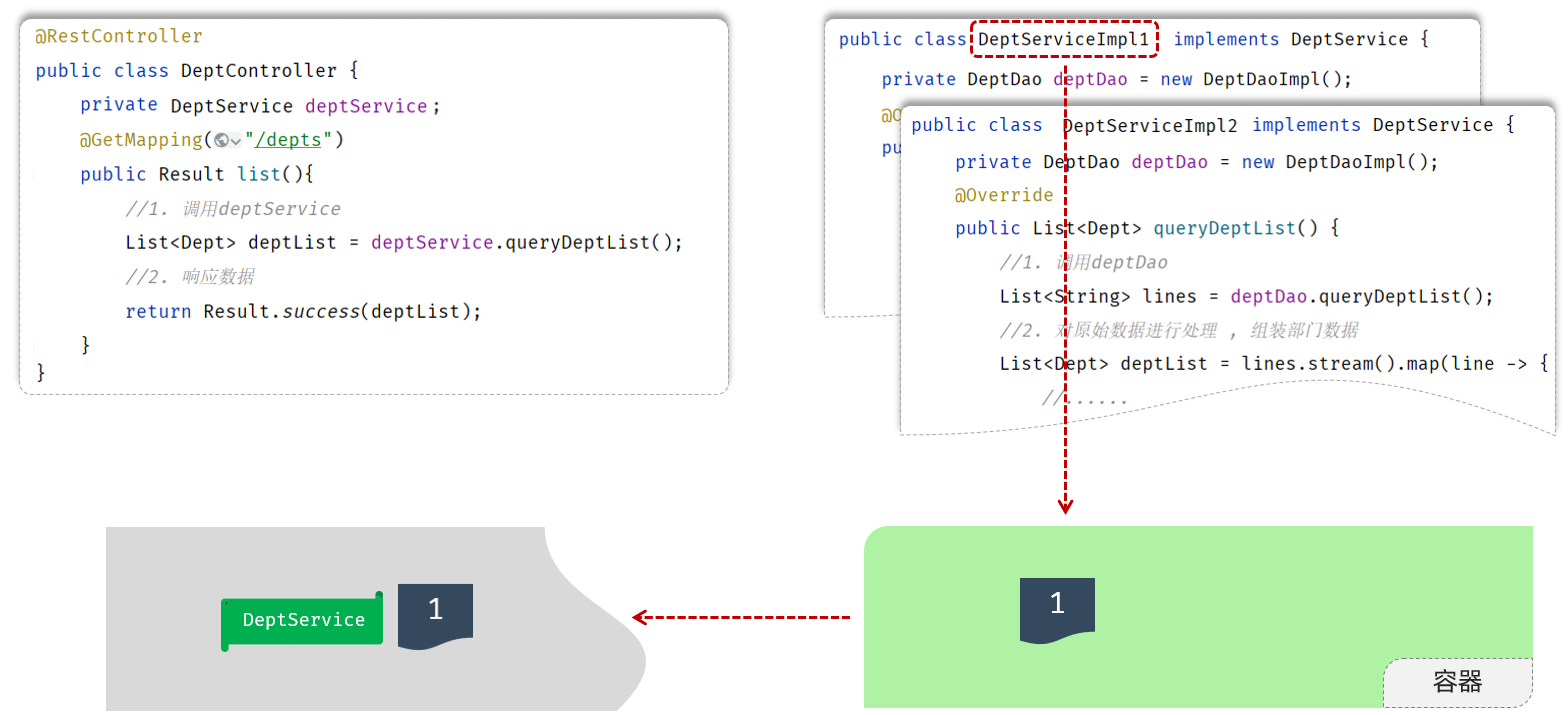
那问题来了,我们如何将对象交给容器管理呢?程序运行时,容器如何为程序提供依赖的对象呢?
我们想要实现上述解耦操作,就涉及到Spring中的两个核心概念:
-
控制反转: Inversion Of Control,简称IOC。对象的创建控制权由程序自身转移到外部(容器),这种思想称为控制反转。
对象的创建权由程序员主动创建转移到容器(由容器创建、管理对象)。这个容器称为:IOC容器或Spring容器
-
依赖注入: Dependency Injection,简称DI。容器为应用程序提供运行时,所依赖的资源,称之为依赖注入。
程序运行时需要某个资源,此时容器就为其提供这个资源。
例:EmpController程序运行时需要EmpService对象,Spring容器就为其提供并注入EmpService对象
IOC容器中创建、管理的对象,称之为:bean对象。
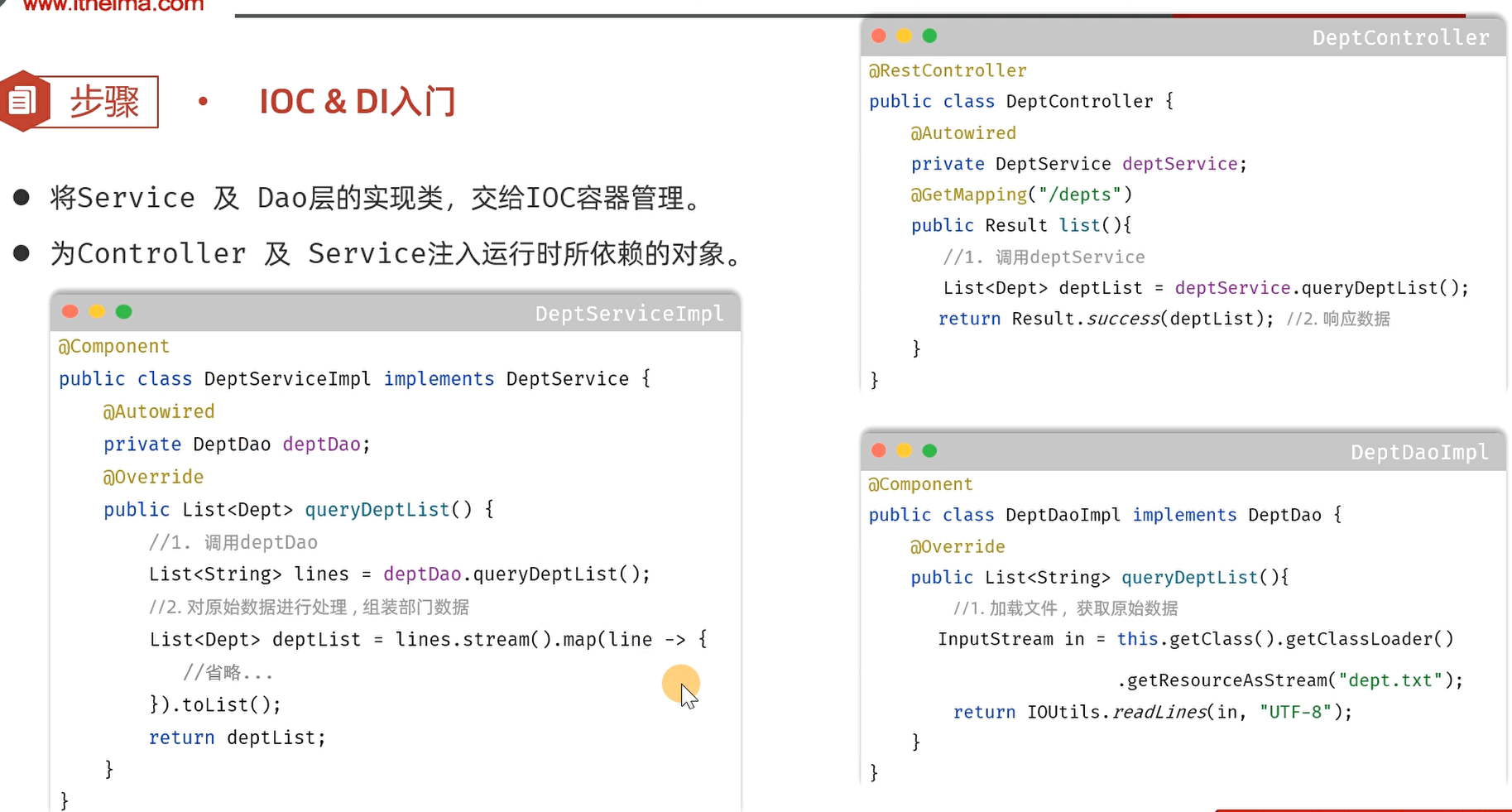
4.3.3 IOC&DI入门
1). 将Service及Dao层的实现类,交给IOC容器管理
在实现类加上 @Component 注解,就代表把当前类产生的对象交给IOC容器管理。
2). 为Controller 及 Service注入运行时所依赖的对象
在实现类加上 @Component 注解,就代表把当前类产生的对象交给IOC容器管理。
4.3.4 IOC详解
Bean的声明
前面我们提到IOC控制反转,就是将对象的控制权交给Spring的IOC容器,由IOC容器创建及管理对象。IOC容器创建的对象称为bean对象。

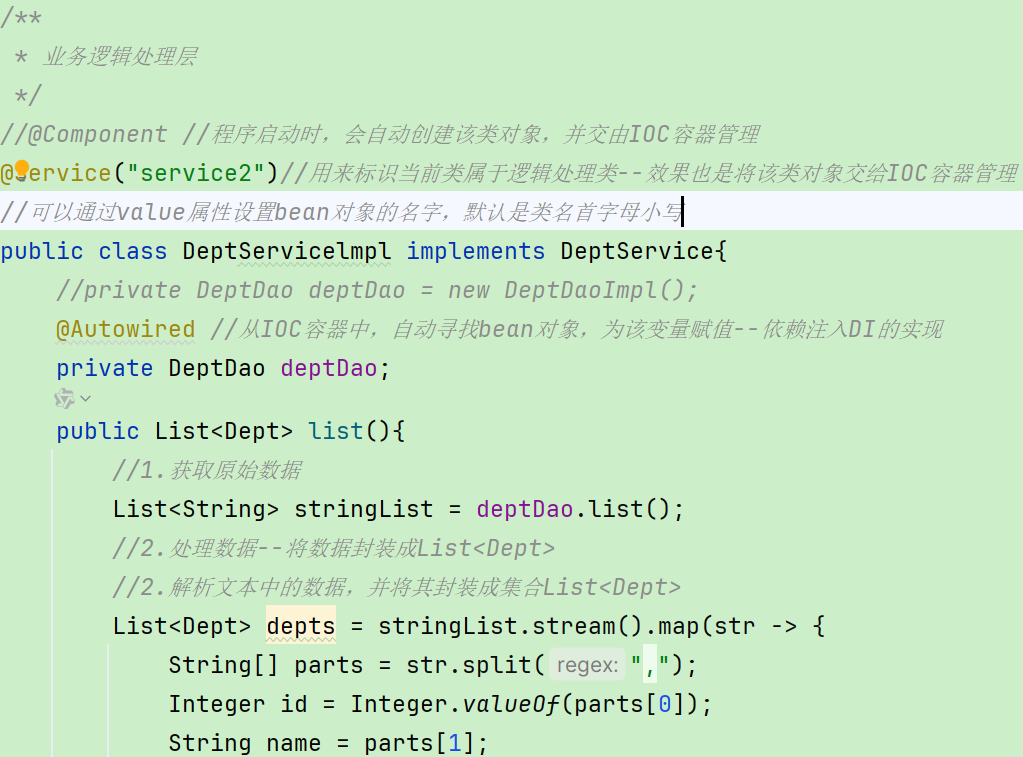
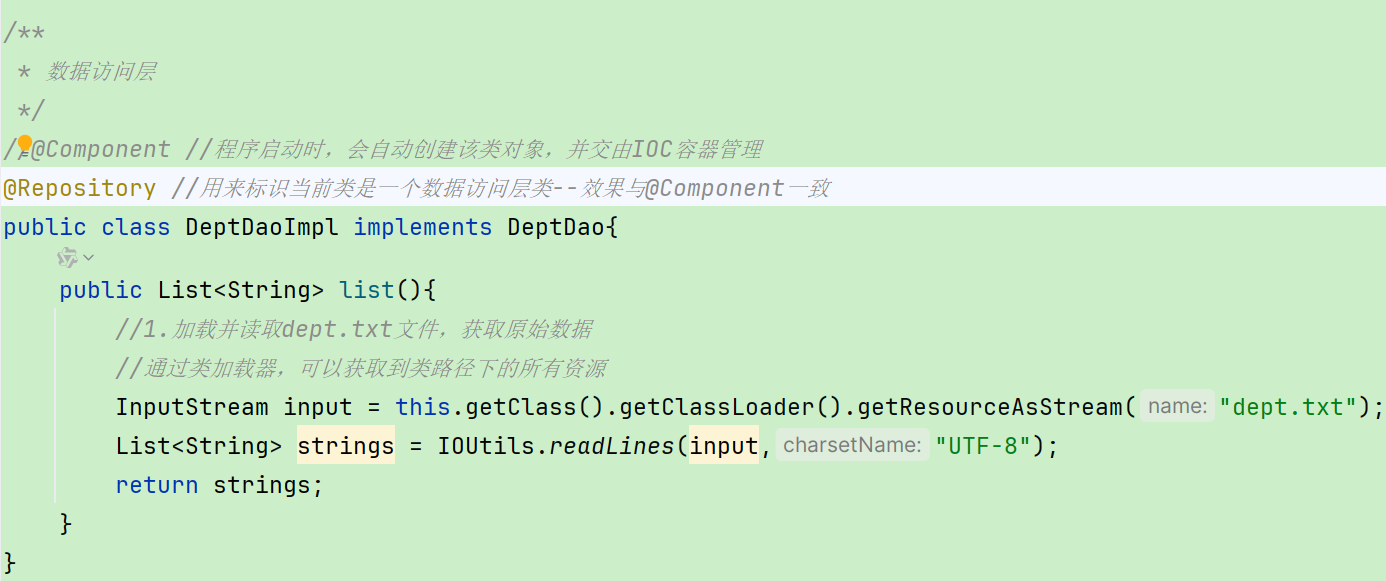

注意1:声明bean的时候,可以通过注解的value属性指定bean的名字,如果没有指定,默认为类名首字母小写。
注意2:使用以上四个注解都可以声明bean,但是在springboot集成web开发中,声明控制器bean只能用@Controller。
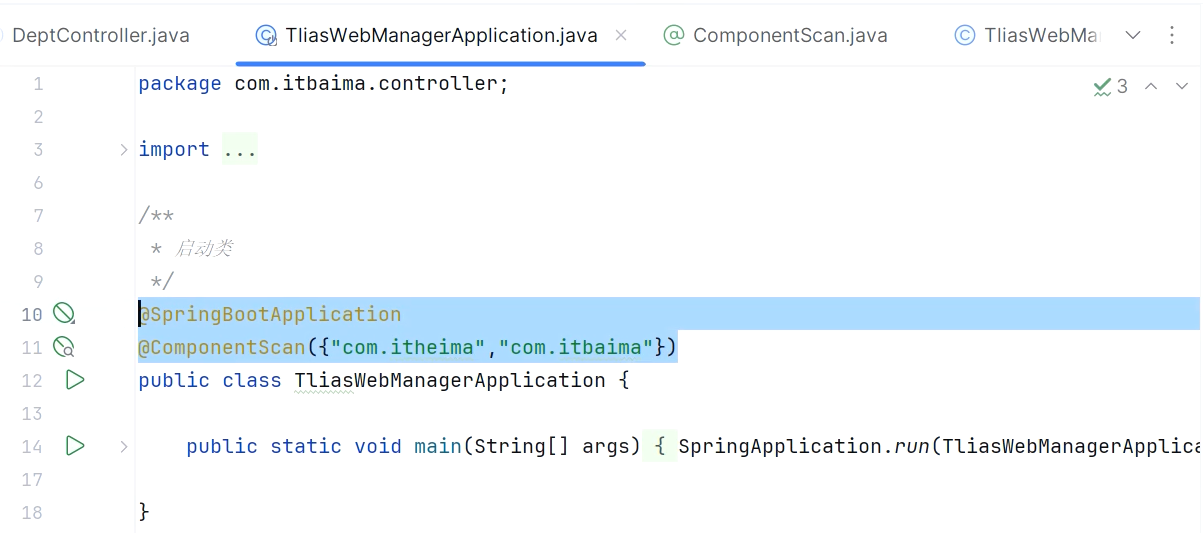
组件扫描
问题:使用前面学习的四个注解声明的bean,一定会生效吗?
答案:不一定。(原因:bean想要生效,还需要被组件扫描)
-
前面声明bean的四大注解,要想生效,还需要被组件扫描注解
@ComponentScan扫描。 -
该注解虽然没有显式配置,但是实际上已经包含在了启动类声明注解
@SpringBootApplication中,默认扫描的范围是启动类所在包及其子包。
4.3.5 DI详解
上一小节我们讲解了控制反转IOC的细节,接下来呢,我们学习依赖注解DI的细节。
依赖注入,是指IOC容器要为应用程序去提供运行时所依赖的资源,而资源指的就是对象。
在入门程序案例中,我们使用了@Autowired这个注解,完成了依赖注入的操作,而这个Autowired翻译过来叫:自动装配。
@Autowired注解,默认是按照类型进行自动装配的(去IOC容器中找某个类型的对象,然后完成注入操作)
入门程序举例:在DeptController运行的时候,就要到IOC容器当中去查找DeptService这个类型的对象,而我们的IOC容器中刚好有一个DeptService这个类型的对象,所以就找到了这个类型的对象完成注入操作。
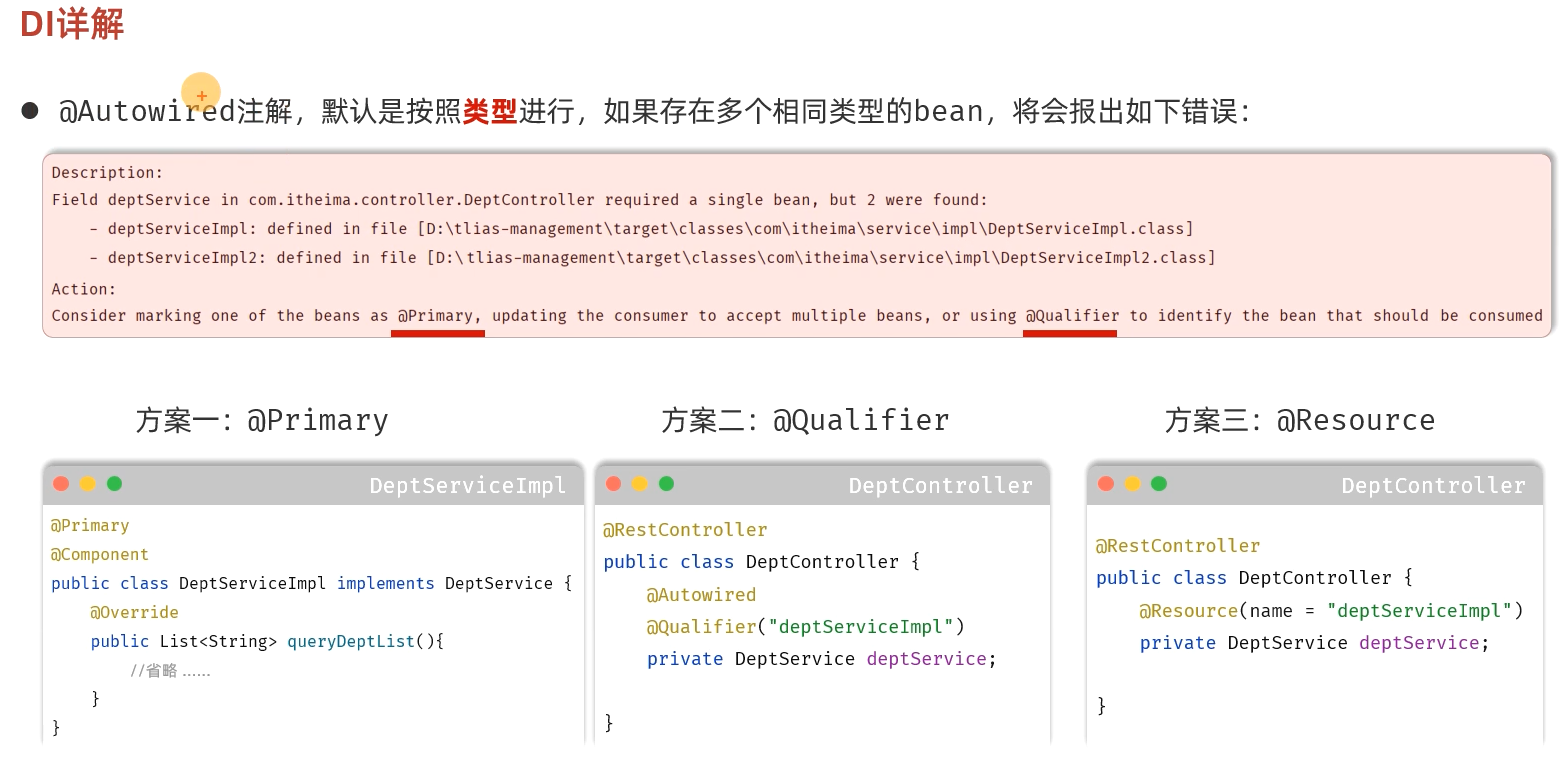
那如果在IOC容器中,存在多个相同类型的bean对象,会出现什么情况呢?
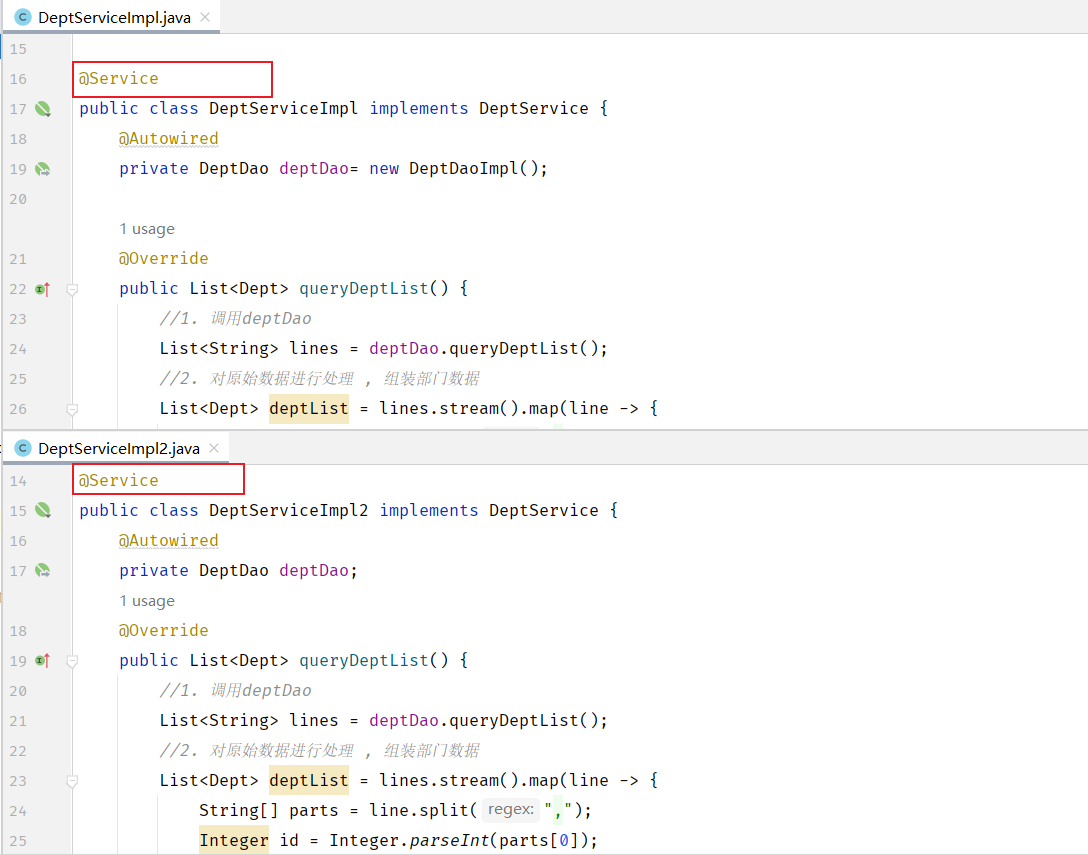
此时,我们运行程序,看到控制台已经报错了。

如何解决上述问题呢?Spring提供了以下几种解决方案:
-
@Primary
-
@Qualifier
-
@Resource
方案一:使用@Primary注解
当存在多个相同类型的Bean注入时,加上@Primary注解,来确定默认的实现。
@Primary //指定该bean优先级最高
@Service
public class DeptServiceImpl implements DeptService {
}方案二:使用@Qualifier注解
指定当前要注入的bean对象。 在@Qualifier的value属性中,指定注入的bean的名称。 @Qualifier注解不能单独使用,必须配合@Autowired使用
@RestController
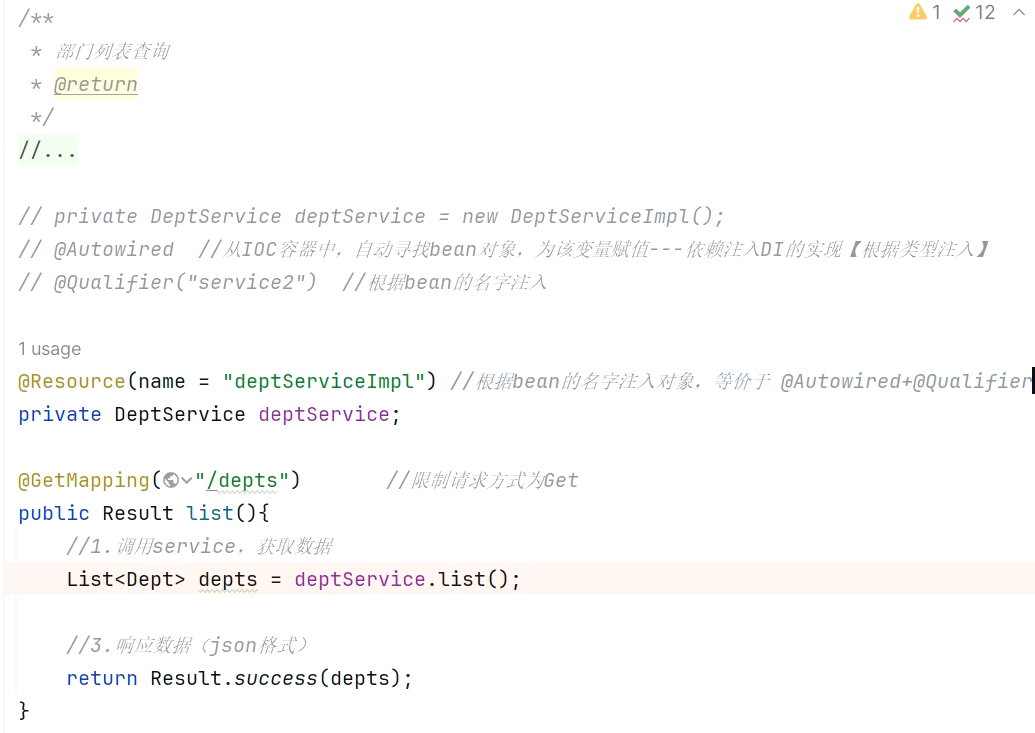
public class DeptController {@Qualifier("deptServiceImpl") //根据bean的名字注入@Autowired //从IOC容器中,自动寻找bean对象,为该变量赋值--依赖注入DI的实现【根据类型注入】private DeptService deptService;方案三:使用@Resource注解(不再需要Autowired)
是按照bean的名称进行注入。通过name属性指定要注入的bean的名称。
面试题 : @Autowird 与 @Resource的区别?
@Autowired 是spring框架提供的注解,而@Resource是JDK提供的注解
@Autowired 默认是按照类型注入,而@Resource是按照名称注入