【深度学习计算性能】03:自动并行

【作者主页】Francek Chen
【专栏介绍】⌈⌈⌈PyTorch深度学习⌋⌋⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
文章目录
- 一、基于GPU的并行计算
- 二、并行计算与通信
- 小结
深度学习框架(例如,MxNet、飞桨和PyTorch)会在后端自动构建计算图。利用计算图,系统可以了解所有依赖关系,并且可以选择性地并行执行多个不相互依赖的任务以提高速度。
通常情况下单个操作符将使用所有CPU或单个GPU上的所有计算资源。例如,即使在一台机器上有多个CPU处理器,dot操作符也将使用所有CPU上的所有核心(和线程)。这样的行为同样适用于单个GPU。因此,并行化对单设备计算机来说并不是很有用,而并行化对于多个设备就很重要了。虽然并行化通常应用在多个GPU之间,但增加本地CPU以后还将提高少许性能。例如,把结合GPU和CPU的训练应用到计算机视觉模型中。借助自动并行化框架的便利性,我们可以依靠几行Python代码实现相同的目标。对自动并行计算的讨论主要集中在使用CPU和GPU的并行计算上,以及计算和通信的并行化内容。
请注意,本文中的实验至少需要两个GPU来运行。
import torch
from d2l import torch as d2l
一、基于GPU的并行计算
从定义一个具有参考性的用于测试的工作负载开始:下面的run函数将执行101010次矩阵-矩阵乘法时需要使用的数据分配到两个变量(x_gpu1和x_gpu2)中,这两个变量分别位于选择的不同设备上。
devices = d2l.try_all_gpus()
def run(x):return [x.mm(x) for _ in range(50)]x_gpu1 = torch.rand(size=(4000, 4000), device=devices[0])
x_gpu2 = torch.rand(size=(4000, 4000), device=devices[1])
现在使用函数来处理数据。通过在测量之前需要预热设备(对设备执行一次传递)来确保缓存的作用不影响最终的结果。torch.cuda.synchronize()函数将会等待一个CUDA设备上的所有流中的所有核心的计算完成。函数接受一个device参数,代表是哪个设备需要同步。如果device参数是None(默认值),它将使用current_device()找出的当前设备。
run(x_gpu1)
run(x_gpu2) # 预热设备
torch.cuda.synchronize(devices[0])
torch.cuda.synchronize(devices[1])with d2l.Benchmark('GPU1 time'):run(x_gpu1)torch.cuda.synchronize(devices[0])with d2l.Benchmark('GPU2 time'):run(x_gpu2)torch.cuda.synchronize(devices[1])
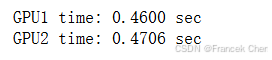
如果删除两个任务之间的synchronize语句,系统就可以在两个设备上自动实现并行计算。
with d2l.Benchmark('GPU1 & GPU2'):run(x_gpu1)run(x_gpu2)torch.cuda.synchronize()
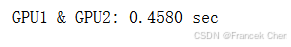
在上述情况下,总执行时间小于两个部分执行时间的总和,因为深度学习框架自动调度两个GPU设备上的计算,而不需要用户编写复杂的代码。
二、并行计算与通信
在许多情况下,我们需要在不同的设备之间移动数据,比如在CPU和GPU之间,或者在不同的GPU之间。例如,当执行分布式优化时,就需要移动数据来聚合多个加速卡上的梯度。让我们通过在GPU上计算,然后将结果复制回CPU来模拟这个过程。
def copy_to_cpu(x, non_blocking=False):return [y.to('cpu', non_blocking=non_blocking) for y in x]with d2l.Benchmark('在GPU1上运行'):y = run(x_gpu1)torch.cuda.synchronize()with d2l.Benchmark('复制到CPU'):y_cpu = copy_to_cpu(y)torch.cuda.synchronize()
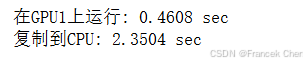
这种方式效率不高。注意到当列表中的其余部分还在计算时,我们可能就已经开始将y的部分复制到CPU了。例如,当计算一个小批量的(反传)梯度时。某些参数的梯度将比其他参数的梯度更早可用。因此,在GPU仍在运行时就开始使用PCI-Express总线带宽来移动数据是有利的。在PyTorch中,to()和copy_()等函数都允许显式的non_blocking参数,这允许在不需要同步时调用方可以绕过同步。设置non_blocking=True以模拟这个场景。
with d2l.Benchmark('在GPU1上运行并复制到CPU'):y = run(x_gpu1)y_cpu = copy_to_cpu(y, True)torch.cuda.synchronize()
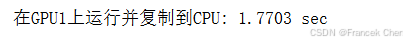
两个操作所需的总时间少于它们各部分操作所需时间的总和。请注意,与并行计算的区别是通信操作使用的资源:CPU和GPU之间的总线。事实上,我们可以在两个设备上同时进行计算和通信。如上所述,计算和通信之间存在的依赖关系是必须先计算y[i],然后才能将其复制到CPU。幸运的是,系统可以在计算y[i]的同时复制y[i-1],以减少总的运行时间。
最后,本文给出了一个简单的两层多层感知机在CPU和两个GPU上训练时的计算图及其依赖关系的例子,如图1所示。手动调度由此产生的并行程序将是相当痛苦的。这就是基于图的计算后端进行优化的优势所在。

小结
- 现代系统拥有多种设备,如多个GPU和多个CPU,还可以并行地、异步地使用它们。
- 现代系统还拥有各种通信资源,如PCI Express、存储(通常是固态硬盘或网络存储)和网络带宽,为了达到最高效率可以并行使用它们。
- 后端可以通过自动化地并行计算和通信来提高性能。