什么是缓存击穿、缓存穿透、缓存雪崩及其解决方案
什么是缓存击穿、缓存穿透、缓存雪崩及其解决方案
开篇:缓存系统就像城市交通
想象一下,我们的缓存系统就像一座繁忙城市的交通网络。数据库是城市的中心商业区,而缓存则是环绕商业区的高速公路和立交桥系统,它们的作用是分流交通压力,让数据能够快速到达目的地。
但是,就像城市交通会遇到各种问题一样,我们的缓存系统也会面临三种典型的"交通故障":缓存击穿就像某个关键路口突然关闭,所有车辆都不得不绕行到市中心;缓存穿透则像是无数辆寻找不存在地址的车辆在街道上漫无目的地行驶;而缓存雪崩则如同所有立交桥同时坍塌,导致交通完全瘫痪。
今天,我们就来详细探讨这三种缓存问题,了解它们的成因,并学习如何构建更健壮的缓存系统来应对这些挑战。通过本文,你将掌握实用的解决方案,让你的应用在面对高并发时依然能够保持稳定和高效。
一、缓存击穿及其解决方案
理解了缓存系统的基本概念后,我们首先来看缓存击穿这个常见问题。缓存击穿通常发生在热点数据上,当某个热点key突然失效时,大量并发请求会直接打到数据库上,造成数据库压力骤增甚至崩溃。
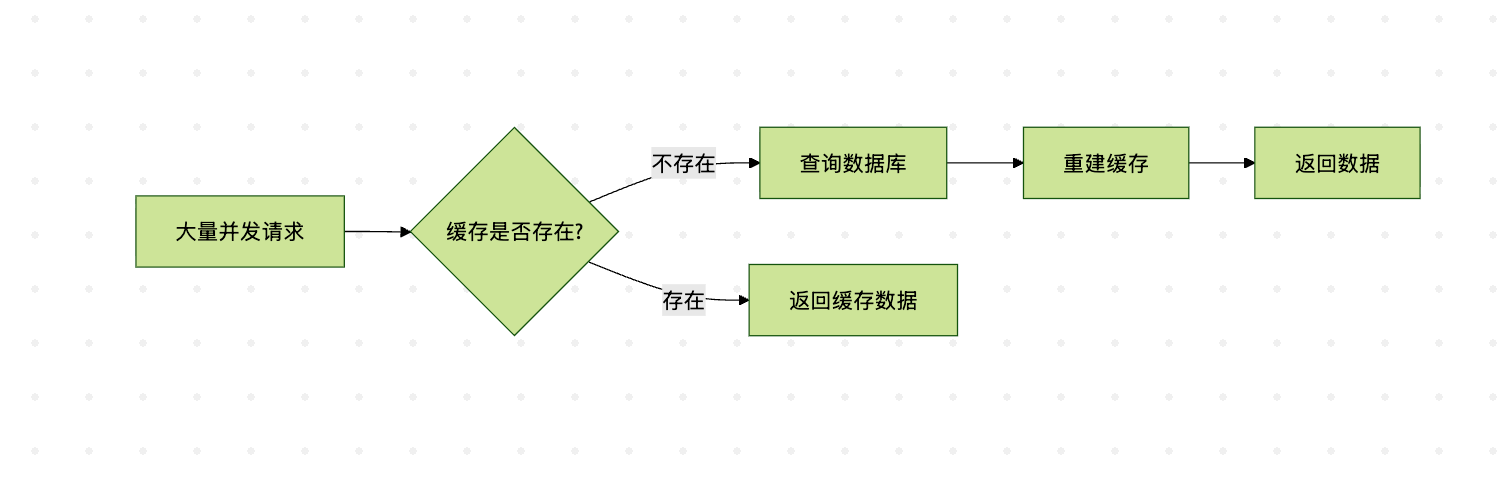
以上流程图说明了缓存击穿的基本过程:当缓存失效时,所有请求都会直接访问数据库。
1.1 互斥锁解决方案
为了防止多个线程同时重建缓存,我们可以使用互斥锁机制。下面是一个Java实现示例:
public class CacheService {private final Cache cache; // 缓存实例private final Database database; // 数据库实例private final Lock lock = new ReentrantLock(); // 互斥锁public Object getData(String key) {// 1. 尝试从缓存获取数据Object value = cache.get(key);if (value != null) {return value;}// 2. 缓存不存在,尝试获取锁if (lock.tryLock()) {try {// 3. 再次检查缓存,防止其他线程已经重建value = cache.get(key);if (value != null) {return value;}// 4. 从数据库获取数据value = database.query(key);// 5. 写入缓存if (value != null) {cache.set(key, value);}} finally {lock.unlock();}} else {// 6. 获取锁失败,短暂等待后重试try {Thread.sleep(100);return getData(key);} catch (InterruptedException e) {Thread.currentThread().interrupt();return null;}}return value;}
}
上述代码展示了使用互斥锁防止缓存击穿的典型实现。关键点在于:
- 使用双重检查避免不必要的数据库查询;
- 使用tryLock()避免线程阻塞;
- 获取锁失败的线程会短暂等待后重试。
1.2 永不过期策略
另一种解决方案是为热点数据设置"逻辑过期时间"而非实际过期时间:
public class CacheItem {private Object data;private long expireTime; // 逻辑过期时间// getters and setters
}public class CacheService {public Object getDataWithLogicalExpire(String key) {CacheItem item = cache.get(key);if (item == null) {// 缓存不存在,从数据库加载return loadFromDB(key);}if (System.currentTimeMillis() > item.getExpireTime()) {// 数据已过期,异步重建asyncRebuildCache(key);}return item.getData();}private void asyncRebuildCache(String key) {// 使用线程池异步重建缓存executorService.submit(() -> {Object data = database.query(key);if (data != null) {// 设置新的过期时间cache.set(key, new CacheItem(data, System.currentTimeMillis() + 30 * 60 * 1000)); // 30分钟后过期}});}
}
这种方案的优势在于:
- 缓存永远不会真正过期,避免了击穿问题;
- 异步重建减少了用户等待时间;
- 逻辑过期时间可以灵活调整。
二、缓存穿透及其解决方案
了解了缓存击穿后,我们来看缓存穿透问题。缓存穿透是指查询一个根本不存在的数据,由于缓存中查不到,每次请求都会打到数据库上,如果有恶意攻击者大量请求不存在的数据,可能导致数据库压力过大甚至崩溃。
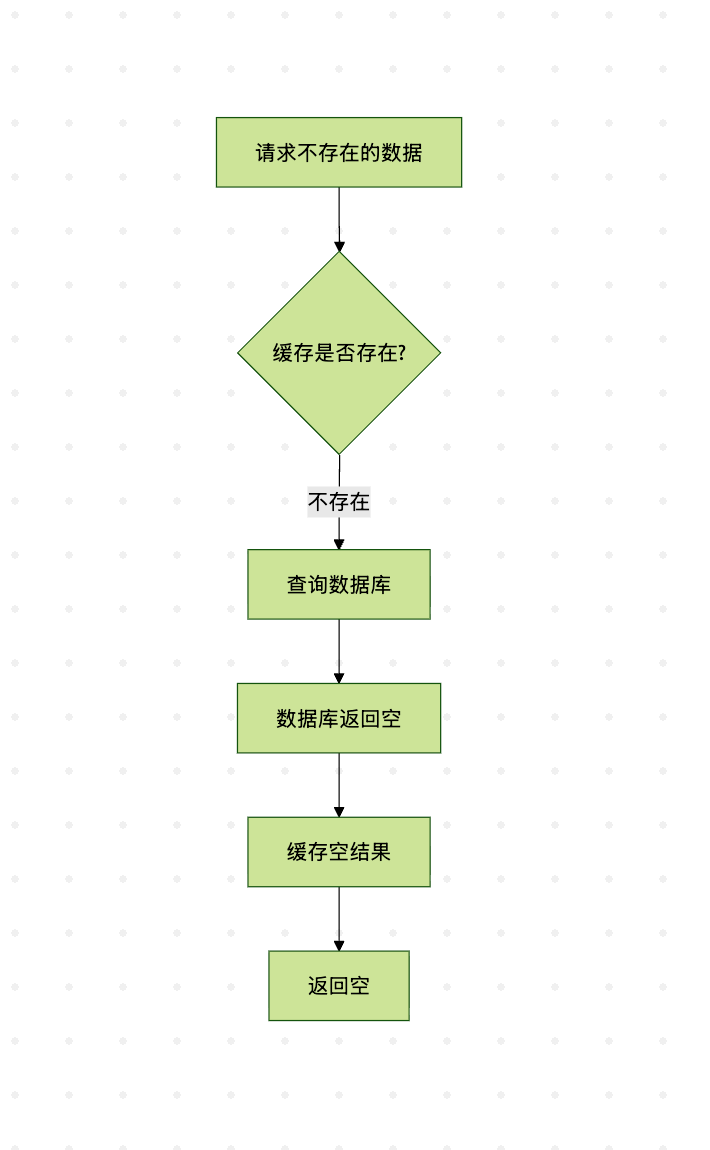
以上流程图说明了缓存穿透的基本过程:请求不存在的数据会导致每次都要查询数据库。
2.1 布隆过滤器解决方案
布隆过滤器是一种空间效率很高的概率型数据结构,可以用来判断一个元素是否在一个集合中。下面是一个使用Guava布隆过滤器的示例:
public class BloomFilterCacheService {private final BloomFilter<String> bloomFilter;private final Cache cache;private final Database database;public BloomFilterCacheService(int expectedInsertions, double fpp) {this.bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()),expectedInsertions,fpp);// 初始化时加载所有存在的key到布隆过滤器loadAllKeysToBloomFilter();}public Object getData(String key) {// 1. 先检查布隆过滤器if (!bloomFilter.mightContain(key)) {return null; // 确定不存在}// 2. 检查缓存Object value = cache.get(key);if (value != null) {return value;}// 3. 查询数据库value = database.query(key);if (value != null) {cache.set(key, value);} else {// 数据库也没有,可能是布隆过滤器误判// 可以记录日志或进行其他处理}return value;}
}
上述代码展示了布隆过滤器的典型用法。需要注意的是:
- 布隆过滤器有误判率(false positive),但不会漏判(false negative);
- 需要预先加载所有可能存在的key;
- 适用于key数量相对固定且可预知的场景。
2.2 缓存空对象方案
对于无法使用布隆过滤器的场景,我们可以缓存空对象:
public class NullObjectCacheService {private static final Object NULL_OBJECT = new Object();private final Cache cache;private final Database database;public Object getData(String key) {// 1. 尝试从缓存获取Object value = cache.get(key);if (value != null) {return value == NULL_OBJECT ? null : value;}// 2. 查询数据库value = database.query(key);if (value != null) {cache.set(key, value);} else {// 3. 缓存空对象,设置较短的过期时间cache.set(key, NULL_OBJECT, 5 * 60); // 5分钟}return value;}
}
这种方案的优点是实现简单,缺点是:
- 需要为不存在的key占用缓存空间;
- 如果key后来变得有效,需要额外的处理机制。
三、缓存雪崩及其解决方案
最后,我们来看最严重的缓存问题——缓存雪崩。缓存雪崩是指缓存中大量key同时失效,导致所有请求都直接访问数据库,造成数据库瞬时压力过大而崩溃。

以上流程图说明了缓存雪崩的连锁反应:缓存失效导致数据库过载,最终系统崩溃。
3.1 过期时间随机化
最简单的解决方案是为缓存设置随机的过期时间:
public class RandomExpireCacheService {private final Cache cache;private final Database database;private final Random random = new Random();public void setData(String key, Object value) {// 基础过期时间30分钟,加上0-10分钟的随机偏移int expireSeconds = 30 * 60 + random.nextInt(10 * 60);cache.set(key, value, expireSeconds);}public Object getData(String key) {Object value = cache.get(key);if (value == null) {value = database.query(key);if (value != null) {setData(key, value);}}return value;}
}
这种方案通过分散缓存过期时间,避免了大量key同时失效的情况。实现简单但效果显著。
3.2 多级缓存架构
对于大型系统,可以采用多级缓存架构:
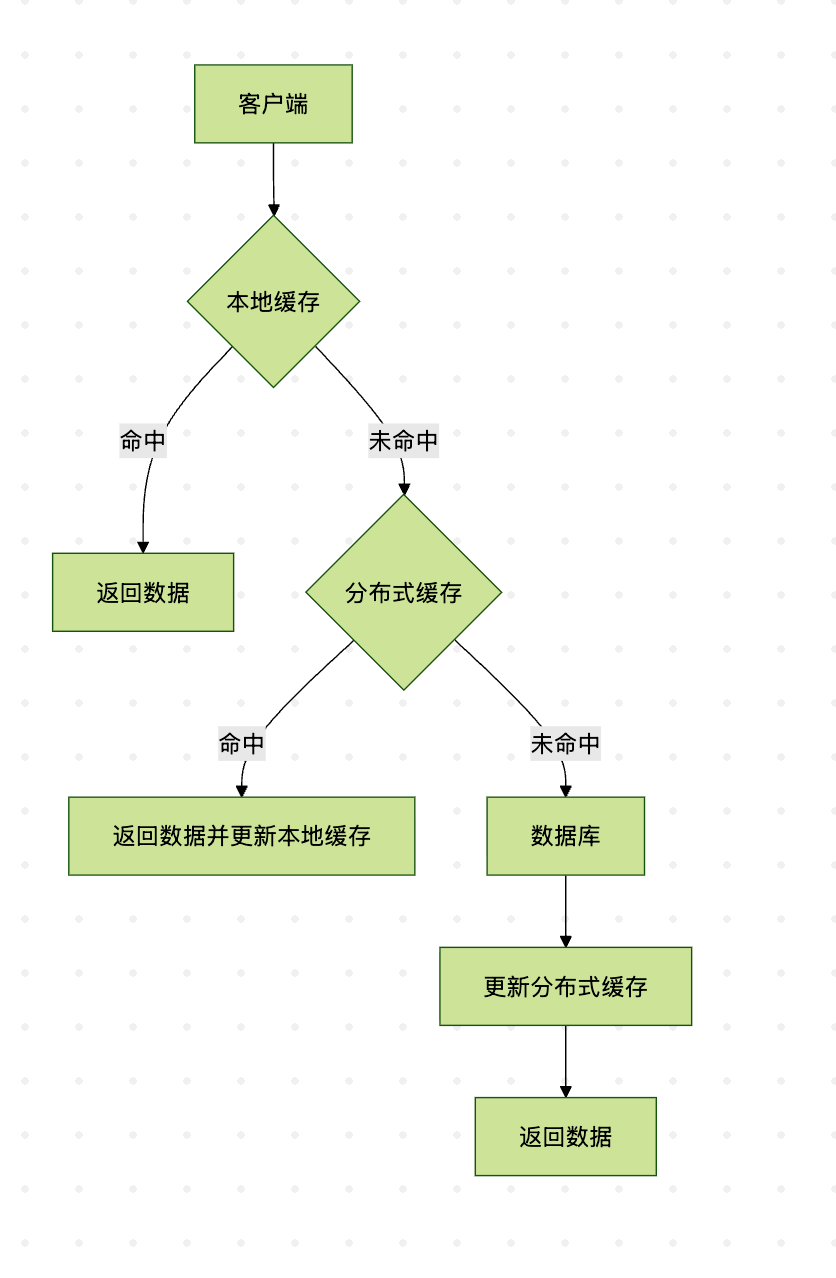
以上流程图展示了两级缓存架构:本地缓存作为第一级,分布式缓存作为第二级,最后才是数据库。
public class MultiLevelCacheService {private final Cache localCache; // 本地缓存,如Caffeineprivate final Cache distributedCache; // 分布式缓存,如Redisprivate final Database database;public Object getData(String key) {// 1. 检查本地缓存Object value = localCache.get(key);if (value != null) {return value;}// 2. 检查分布式缓存value = distributedCache.get(key);if (value != null) {// 3. 更新本地缓存localCache.set(key, value);return value;}// 4. 查询数据库value = database.query(key);if (value != null) {// 5. 更新分布式缓存distributedCache.set(key, value);// 6. 更新本地缓存localCache.set(key, value);}return value;}
}
多级缓存架构的优势在于:
- 本地缓存响应极快;
- 分布式缓存作为共享层;
- 数据库作为最后防线。这种架构能有效缓解缓存雪崩的影响。
3.3 熔断降级机制
作为最后一道防线,我们可以实现熔断降级机制:
public class CircuitBreakerCacheService {private final Cache cache;private final Database database;private final CircuitBreaker circuitBreaker;public Object getData(String key) {// 1. 尝试从缓存获取Object value = cache.get(key);if (value != null) {return value;}// 2. 检查熔断器状态if (circuitBreaker.isOpen()) {// 熔断器已打开,执行降级逻辑return getFallbackData(key);}try {// 3. 查询数据库value = database.query(key);if (value != null) {cache.set(key, value);circuitBreaker.recordSuccess();}return value;} catch (Exception e) {// 4. 记录失败circuitBreaker.recordFailure();return getFallbackData(key);}}private Object getFallbackData(String key) {// 返回默认值或缓存中的旧数据// 可以记录日志或发送告警return null;}
}
熔断器模式可以在数据库压力过大时自动切断请求,防止系统完全崩溃,同时提供降级方案保证基本功能可用。
总结与最佳实践
通过今天的探讨,我们深入了解了缓存系统的三大问题及其解决方案。让我们总结一下关键点:
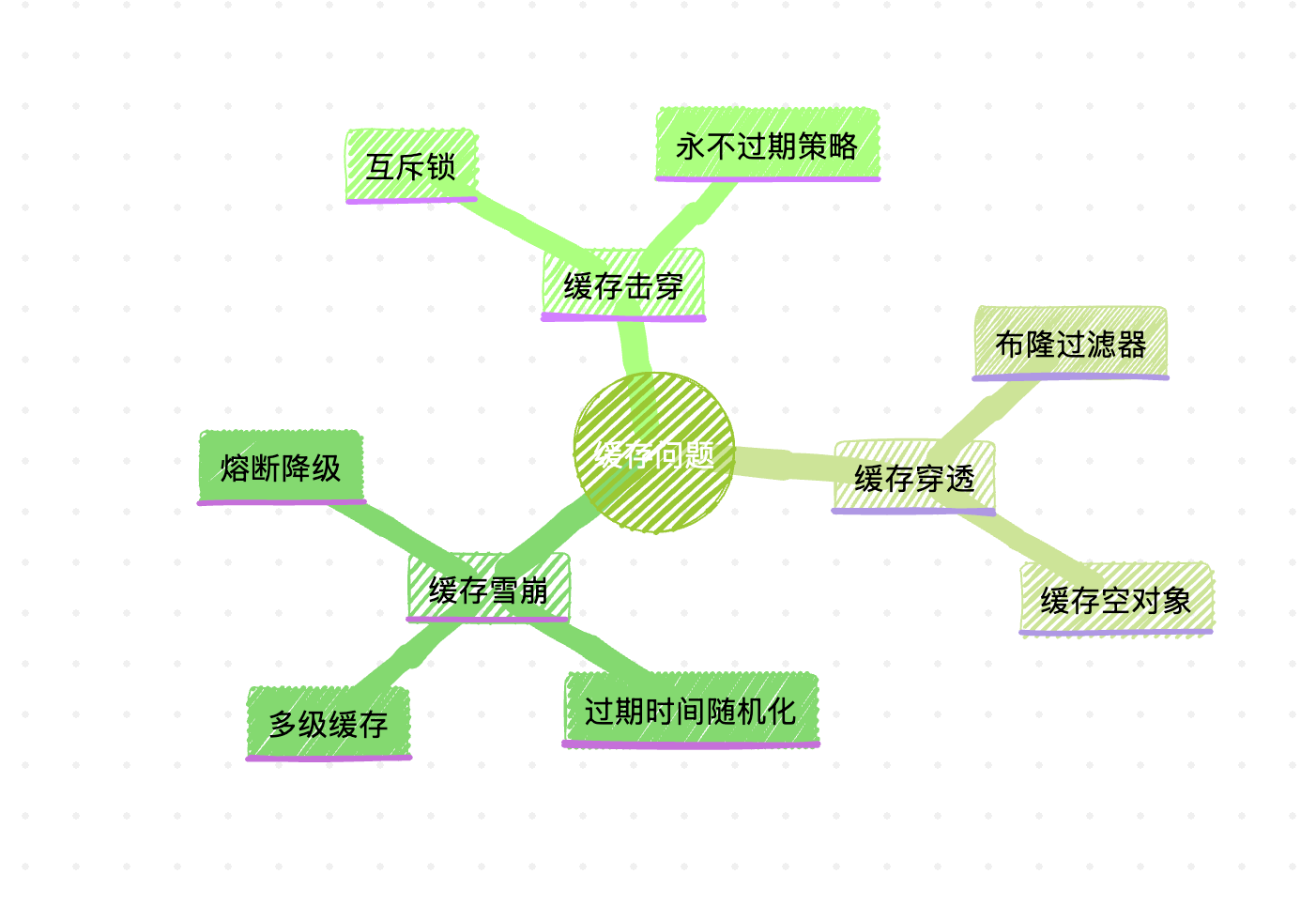
以上思维导图总结了本文讨论的主要问题和解决方案。
在实际应用中,我建议根据业务特点选择合适的组合方案。例如:
- 对于热点数据:使用互斥锁+永不过期策略防止击穿
- 对于用户查询:使用布隆过滤器防止穿透
- 对于系统核心数据:采用多级缓存+熔断机制防止雪崩
记住,没有放之四海而皆准的解决方案,最重要的是理解原理并根据实际业务场景灵活应用。