AAAI 2025丨具身智能+多模态感知如何精准锁定目标
关注gongzhonghao【计算机sci论文精选】!
具身智能指通过物理载体与环境实时交互的智能系统,具备感知、决策与执行一体化能力,实现“大脑思考+身体行动”的协同。
2025年首次被写入中国《政府工作报告》作为未来产业,全球人形机器人新品年超百款。中国在“天工”机器人奔跑控制、“慧思开物”通用平台等领域领先,技术加速从实验室迈向工业制造、家庭服务等场景。今天小图给大家精选3篇AAAI有关具身智能方向的论文,请注意查收!
论文一:DigitalLLaVA: Incorporating Digital Cognition Capability for Physical World Comprehension in Multimodal LLMs
方法:
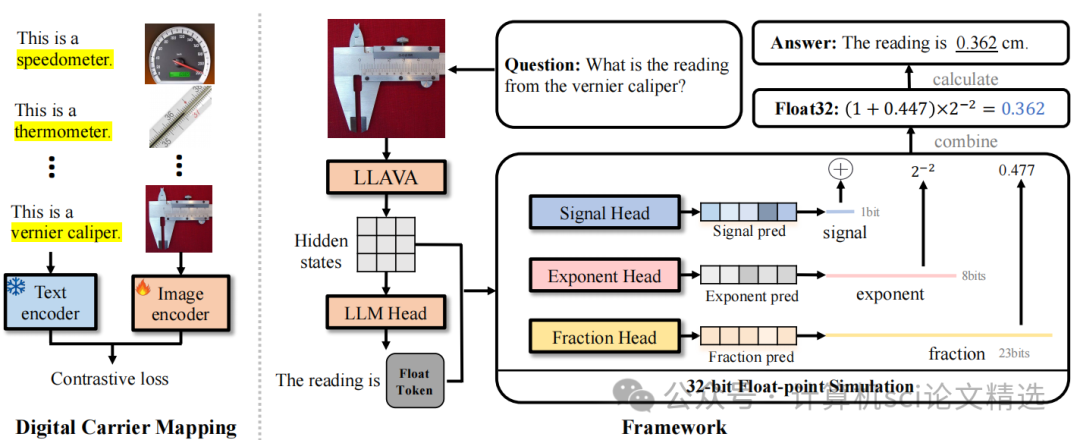
文章首先通过数字载体映射方法,利用对象级文本-图像对来增强模型对物理数字载体的理解;其次,采用32位浮点数模拟方法,将数字预测转化为整体的0/1二进制分类问题,显著减少了搜索空间,使预测过程更加稳健和直接;最后,通过大量实验验证了该方法在多个领域的有效性和适用性。

创新点:
首次识别并分析了当前多模态大语言模型在物理数字认知方面的局限性,为后续改进提供了明确的方向。
提出了DigitalLLaVA方法,通过数字载体映射和32位浮点数模拟两个步骤,明确地将数字认知能力注入多模态大语言模型。
在多个数据集上进行了广泛的实验,证明了该方法能够显著提高模型对物理数字的识别精度,达到±0.001的准确度。
论文链接:
https://ojs.aaai.org/index.php/AAAI/article/view/32522
图灵学术论文辅导
论文二:EMHI: A Multimodal Egocentric Human Motion Dataset with HMD and Body-Worn IMUs
方法:
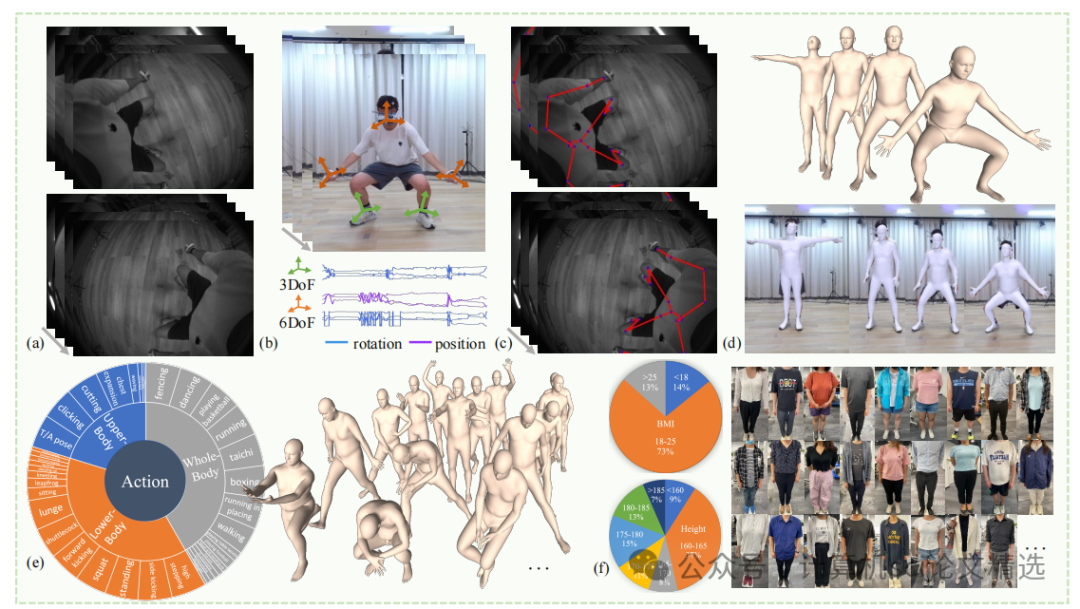
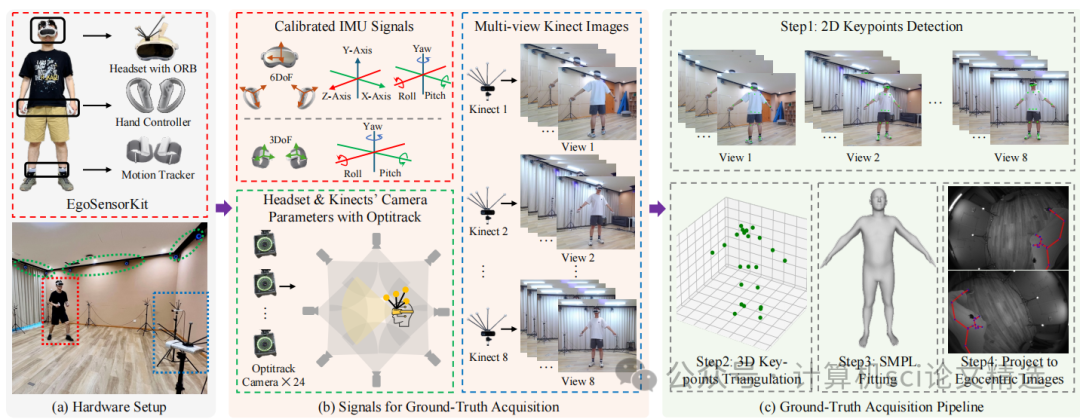
文章首先构建了EMHI数据集,通过真实VR设备采集了包含立体图像和全身IMU信号的数据,并利用多视角相机系统和OptiTrack进行时空同步和姿态注释。接着,提出了MEPoser方法,其多模态融合编码器分别对图像和IMU数据进行特征提取并融合,时间特征编码器利用LSTM模块捕捉时间信息,最后通过MLP回归头估计SMPL模型的姿态和形状参数。实验表明,该方法在多模态数据融合方面具有显著优势,有效提升了人体姿态估计的准确性和鲁棒性。
创新点:
首次构建了一个大规模真实VR设备上的多模态第一人称人体运动数据集EMHI,填补了该领域的空白。
提出了一种新的基线方法MEPoser,实现了在独立VR头显上实时人体姿态估计,显著提升了姿态估计的准确性和鲁棒性。
通过广泛的实验验证了EMHI数据集和MEPoser方法的有效性,为未来的研究和实际应用提供了重要的参考。
论文链接:
https://ojs.aaai.org/index.php/AAAI/article/view/32294
图灵学术论文辅导
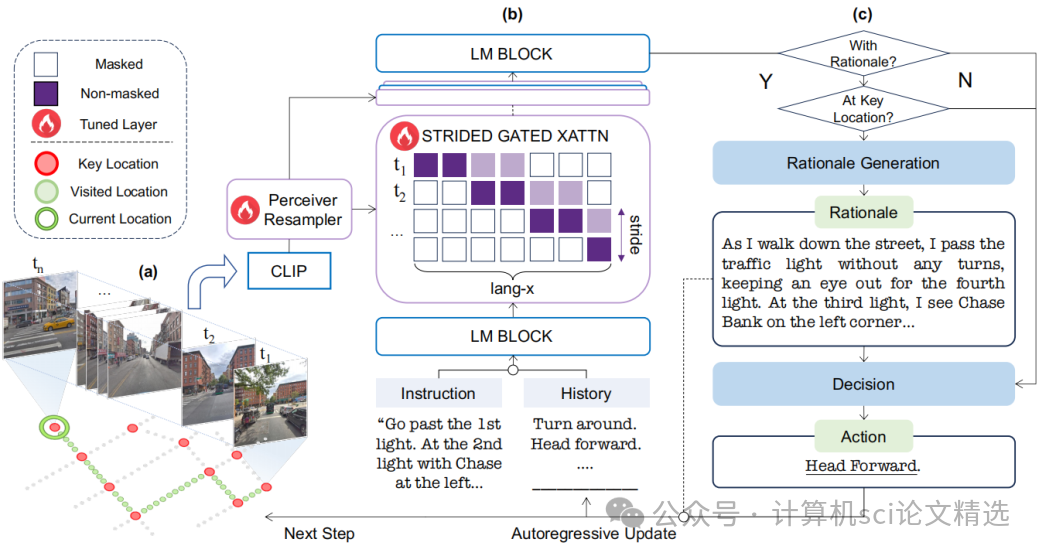
论文三:FLAME: Learning to Navigate with Multimodal LLM in Urban Environments
方法:
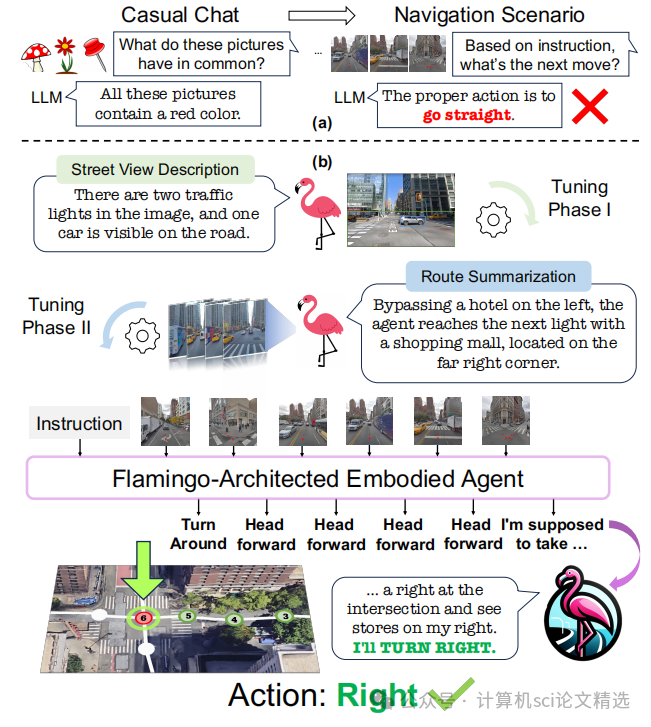
文章首先基于Flamingo架构构建FLAME,通过改进的跨注意力机制高效处理多模态输入。接着,通过三阶段微调技术逐步提升模型的导航能力:第一阶段进行单感知微调,学习街景描述;第二阶段进行多感知微调,学习路线总结;第三阶段在VLN数据集上进行端到端训练。最后,利用GPT-4自动生成合成数据,为模型训练提供丰富的标注信息,显著提升了模型的性能。
创新点:
FLAME是首个专门针对城市VLN任务设计的基于MLLM的智能体,有效解决了现有LLM在导航任务中的局限性。
提出了一种三阶段微调技术,通过街景描述、路线总结和端到端导航训练,逐步提升模型的导航能力。
利用GPT-4自动生成街景描述、路线总结和导航理由,为模型训练提供了丰富的合成数据,进一步增强了模型的推理能力。
论文链接:
https://arxiv.org/abs/2408.11051
本文选自gongzhonghao【计算机sci论文精选】