从零开始实现Qwen3(MOE架构)
文章目录
- 从零开始实现一个Qwen3(MoE)
- 简介
- Qwen3 MoE架构
- 参考
- 结构
- RMSNorm(Root Mean Square Layer Normalization)
- RMSNorm介绍
- 数学公式
- 代码实现
- Rotary Position Embedding (RoPE)
- RoPE介绍
- RoPE的数学公式
- 代码实现
- Grouped Query Attention (GQA)
- GQA介绍
- 数学公式
- 代码实现
- MoE前馈网络
- MoE介绍
- 数学公式
- 代码实现
- 标准前馈网络
- Transformer Block
- Transformer Block介绍
- 代码实现
- Qwen3-30B-A3B 完整模型
- 模型架构
- 代码实现
- 文本生成+推理
- 文本生成
- Tokenizer实现
- 权重加载
- 整体代码
从零开始实现一个Qwen3(MoE)
简介
-
实现一个Qwen3-MoE架构,Qwen3 MoE模型与dense模型共享基本架构,所以这里除了MOE架构的代码,其他基本和dense的实现一致。
另外这里是在一张H20上去跑的,实际显存用了67G左右,因为原作者实现的这个,可以支持30B-A3B,同时也支持235B-A22B(可能需要4张H20/H100/A100),所以本章下面的,都是针对Qwen3-30B-A3B模型。
Qwen3 MoE架构
-
我们结合Qwen/Qwen3-30B-A3B-Instruct-2507的配置参数
{"architectures": ["Qwen3MoeForCausalLM"],"attention_bias": false,"attention_dropout": 0.0,"bos_token_id": 151643,"decoder_sparse_step": 1,"eos_token_id": 151645,"head_dim": 128,"hidden_act": "silu","hidden_size": 2048,"initializer_range": 0.02,"intermediate_size": 6144,"max_position_embeddings": 262144,"max_window_layers": 48,"mlp_only_layers": [],"model_type": "qwen3_moe","moe_intermediate_size": 768,"norm_topk_prob": true,"num_attention_heads": 32,"num_experts": 128,"num_experts_per_tok": 8,"num_hidden_layers": 48,"num_key_value_heads": 4,"output_router_logits": false,"rms_norm_eps": 1e-06,"rope_scaling": null,"rope_theta": 10000000,"router_aux_loss_coef": 0.001,"sliding_window": null,"tie_word_embeddings": false,"torch_dtype": "bfloat16","transformers_version": "4.51.0","use_cache": true,"use_sliding_window": false,"vocab_size": 151936 }以及下面的图
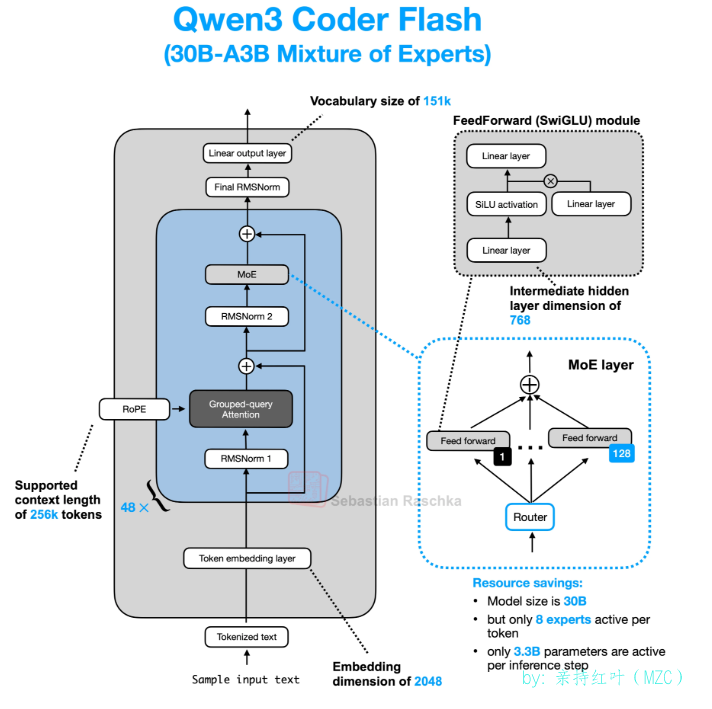
备注:Qwen3-Coder-30B-A3B-Instruct 被称为Qwen3 Coder Flash,原作者这里使用的是Qwen3 Coder Flash,但是这里我使用的是Qwen3-30B-A3B-Instruct-2507,不影响,架构一样的,另外moe架构的Decoder中也是使用了qk_norm的,这里原作者没有画。
先来简单的看一下Qwen3-MoE系列的整体架构
- 词汇表大小: 151936
- 训练的上下文长度: 262144
- MoE专家数量:128
- 每个token使用的专家数:8
- MoE中间层大小:768
- 激活函数:SwiGLU (Swish/SiLU + GLU)
- 使用ROPE位置编码
- 使用Pre-Norm,且Normalization函数为RMSNorm
- 使用GQA, q共32个头,G=4
使用pydantic定义一个config的数据模型,后续代码中出现的cfg即是这个数据模型的实例化
import torch from pydantic import BaseModel, Fieldclass Qwen3MoeConfig(BaseModel):"""Pydantic model for Qwen3 moe configuration"""model_config = {"arbitrary_types_allowed": True}vocab_size: int = Field(..., description="词汇表大小")context_length: int = Field(..., description="用于训练模型的上下文长度")emb_dim: int = Field(..., description="Embedding 维度")n_heads: int = Field(..., description="注意力头的数量")n_layers: int = Field(..., description="层数")head_dim: int = Field(..., description="GQA 中每个注意力头的维度大小")qk_norm: bool = Field(..., description="是否在 GQA 中对key和value进行归一化")n_kv_groups: int = Field(..., description="用于分组查询注意力的 KV 组数")rope_base: float = Field(..., description="RoPE 中'theta'的基数值")dtype: torch.dtype = Field(..., description="较低精度的数据类型,用于降低显存占用")# MoE 相关参数num_experts: int = Field(..., description="专家数量")num_experts_per_tok: int = Field(..., description="每个token使用的专家数量")moe_intermediate_size: int = Field(..., description="MoE中间层大小")QWEN3_CONFIG = {"vocab_size": 151_936,"context_length": 262_144,"emb_dim": 2048,"n_heads": 32,"n_layers": 48,"head_dim": 128,"qk_norm": True,"n_kv_groups": 4,"rope_base": 10_000_000.0,"dtype": torch.bfloat16,"num_experts": 128,"num_experts_per_tok": 8,"moe_intermediate_size": 768,}cfg = Qwen3MoeConfig(**QWEN3_CONFIG) -
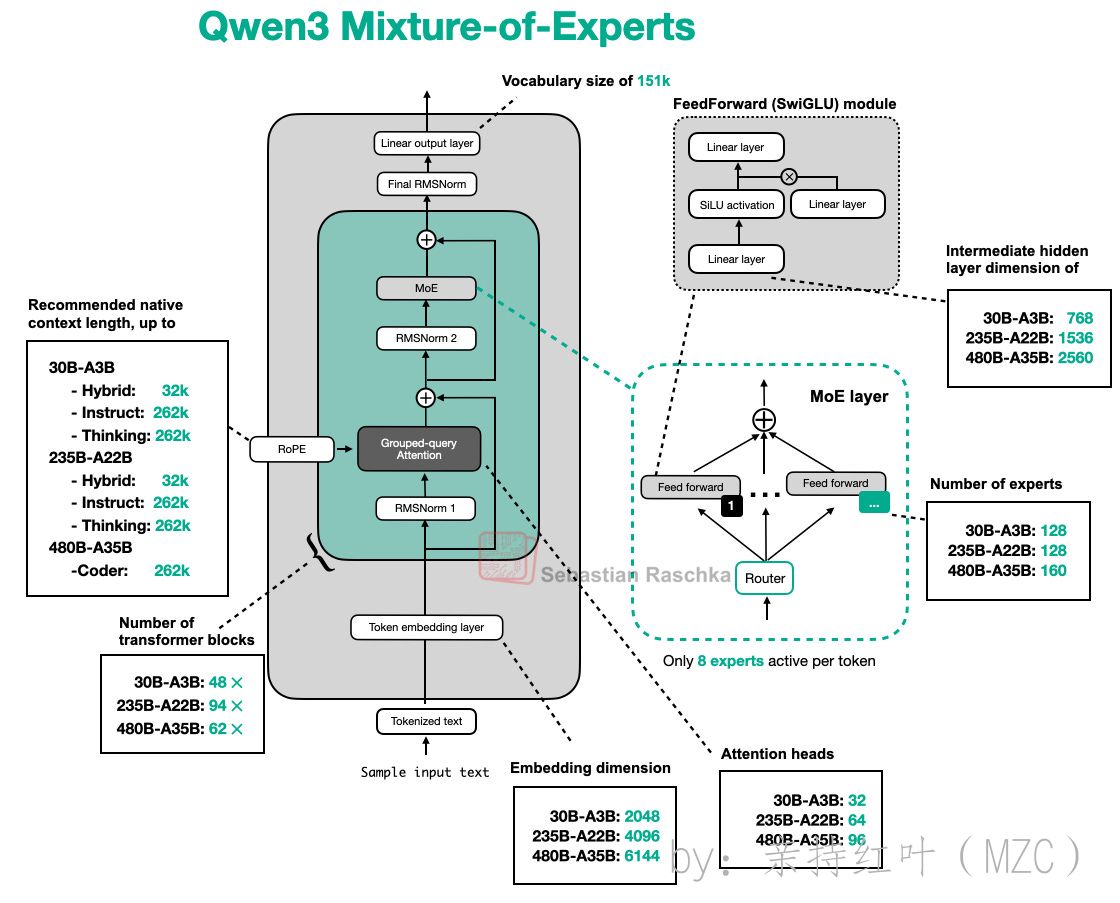
备注,下面是各不同的Qwen3-moe模型的架构图
参考
-
参考代码:
https://github.com/rasbt/LLMs-from-scratch/blob/main/ch05/11_qwen3/standalone-qwen3-moe.ipynb
-
Qwen3: Think Deeper, Act Faster
https://qwenlm.github.io/blog/qwen3/
-
Qwen3 Technical Report Qwen3 技术报告
https://arxiv.org/abs/2505.09388
结构
RMSNorm(Root Mean Square Layer Normalization)
RMSNorm介绍
-
transformer-RMSNorm
-
RMSNorm通过对神经元输出的均方根值进行缩放,在保持训练稳定性的同时降低计算复杂度。与LayerNorm相比,RMSNorm移除了均值中心化操作,仅通过均方根值进行缩放,减少了约30%的计算量。
在Qwen3中,RMSNorm被广泛应用于每个Transformer层的归一化操作,包括注意力层前后和前馈网络前后的归一化。该方法通过单一缩放参数调整特征幅度,避免对输入进行平移操作,特别适合大规模模型训练。
数学公式
-
RMSNorm对输入张量最后一个维度进行均方根标准化:
RMS(x)=1emb_dim∑i=1emb_dimxi2out=γ⋅xRMS(x)2+ϵ+β\text{RMS}(x) = \sqrt{\frac{1}{emb\_{dim}}\sum_{i=1}^{emb\_{dim}}x_i^2} \\ \text{out} = \gamma \cdot \frac{x}{\sqrt{\text{RMS}(x)^2 + \epsilon}} + \beta RMS(x)=emb_dim1i=1∑emb_dimxi2out=γ⋅RMS(x)2+ϵx+β
其中:- γ∈Remb_dim\gamma \in \mathbb{R}^{emb\_{dim}}γ∈Remb_dim:可学习缩放参数(初始化为1)
- β\betaβ: 科学系平移参数(初始化为0)
- ϵ\epsilonϵ:数值稳定系数(默认1e-6)
emb_dimemb\_dimemb_dim 为特征维度。
代码实现
-
Qwen3中的RMSNorm实现
class RMSNorm(nn.Module):def __init__(self, emb_dim, eps=1e-6, bias=False, qwen3_compatible=True):super().__init__()self.eps = epsself.qwen3_compatible = qwen3_compatibleself.scale = nn.Parameter(torch.ones(emb_dim))self.shift = nn.Parameter(torch.zeros(emb_dim)) if bias else Nonedef forward(self, x):input_dtype = x.dtypeif self.qwen3_compatible:x = x.to(torch.float32)variance = x.pow(2).mean(dim=-1, keepdim=True)norm_x = x * torch.rsqrt(variance + self.eps)norm_x = norm_x * self.scaleif self.shift is not None:norm_x = norm_x + self.shiftreturn norm_x.to(input_dtype)
Rotary Position Embedding (RoPE)
RoPE介绍
-
transformer-旋转位置编码RoPE
-
旋转位置编码(Rotary Position Embedding, RoPE)是Qwen3模型中使用的位置编码方法,通过对查询和键向量进行旋转变换来注入位置信息。与传统的绝对位置编码不同,RoPE能够更好地处理相对位置关系,并且对序列长度具有更好的外推能力。
在Qwen3中,RoPE被应用于每个注意力头的查询和键向量,通过预计算的正弦和余弦值对向量进行旋转变换,使得模型能够感知token之间的相对位置关系。
RoPE的数学公式
-
RoPE通过复数域的旋转操作实现位置编码:
对于位置为mmm的向量x\mathbf{x}x,RoPE变换定义为:
f(x,m)=RΘ,mxf(\mathbf{x}, m) = \mathbf{R}_{\Theta, m} \mathbf{x} f(x,m)=RΘ,mx其中旋转矩阵RΘ,m\mathbf{R}_{\Theta, m}RΘ,m的计算公式为:
RΘ,m=(cos(mθ0)−sin(mθ0)00⋯sin(mθ0)cos(mθ0)00⋯00cos(mθ1)−sin(mθ1)⋯00sin(mθ1)cos(mθ1)⋯⋮⋮⋮⋮⋱)\mathbf{R}_{\Theta, m} = \begin{pmatrix} \cos(m\theta_0) & -\sin(m\theta_0) & 0 & 0 & \cdots \\ \sin(m\theta_0) & \cos(m\theta_0) & 0 & 0 & \cdots \\ 0 & 0 & \cos(m\theta_1) & -\sin(m\theta_1) & \cdots \\ 0 & 0 & \sin(m\theta_1) & \cos(m\theta_1) & \cdots \\ \vdots & \vdots & \vdots & \vdots & \ddots \end{pmatrix} RΘ,m=cos(mθ0)sin(mθ0)00⋮−sin(mθ0)cos(mθ0)00⋮00cos(mθ1)sin(mθ1)⋮00−sin(mθ1)cos(mθ1)⋮⋯⋯⋯⋯⋱其中θi=base−2i/d\theta_i = \text{base}^{-2i/d}θi=base−2i/d,在Qwen3-MoE中base=10,000,000。
代码实现
-
RoPE参数计算函数
def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, dtype=torch.float32):assert head_dim % 2 == 0, "Embedding dimension must be even"# 计算逆频率inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float() / head_dim))# 生成位置索引positions = torch.arange(context_length, dtype=dtype)# 计算角度angles = positions[:, None] * inv_freq[None, :] # Shape: (context_length, head_dim // 2)# 扩展角度以匹配head_dimangles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)# 预计算正弦和余弦cos = torch.cos(angles)sin = torch.sin(angles)return cos, sin -
RoPE应用函数
def apply_rope(x, cos, sin):# x: (batch_size, num_heads, seq_len, head_dim)batch_size, num_heads, seq_len, head_dim = x.shapeassert head_dim % 2 == 0, "Head dimension must be even"# 将x分为前半部分和后半部分x1 = x[..., : head_dim // 2] # 前半部分x2 = x[..., head_dim // 2 :] # 后半部分# 调整sin和cos的形状cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)# 应用旋转变换rotated = torch.cat((-x2, x1), dim=-1)x_rotated = (x * cos) + (rotated * sin)# 使用与输入相同的精度return x_rotated.to(dtype=x.dtype)
Grouped Query Attention (GQA)
GQA介绍
-
MHA、MQA、GQA:大模型注意力机制的演进
-
分组查询注意力(Grouped Query Attention, GQA)是Qwen3模型中使用的高效注意力机制。GQA通过减少键值对(Key-Value)的数量来降低内存使用和计算复杂度,同时保持与多头注意力相近的性能。
在传统的多头注意力中,每个头都有独立的查询、键、值投影。而在GQA中,多个查询头共享同一组键值对,通过分组的方式实现计算效率的提升。Qwen3-30B-A3B使用4个KV组来支持32个注意力头。
数学公式
-
GQA的计算过程可以表示为:
GQA(X)=Concat(head1,head2,...,headh)WO\text{GQA}(X) = \text{Concat}(\text{head}_1, \text{head}_2, ..., \text{head}_h) W^O GQA(X)=Concat(head1,head2,...,headh)WO
其中每个头的计算为:
headi=Attention(XWiQ,XW⌊i/g⌋K,XW⌊i/g⌋V)\text{head}_i = \text{Attention}(XW_i^Q, XW_{\lfloor i/g \rfloor}^K, XW_{\lfloor i/g \rfloor}^V) headi=Attention(XWiQ,XW⌊i/g⌋K,XW⌊i/g⌋V)关键参数:
- hhh:查询头的总数
- ggg:每组的大小(group_size = num_heads / num_kv_groups)
- ⌊i/g⌋\lfloor i/g \rfloor⌊i/g⌋:第i个查询头对应的KV组索引
代码实现
-
Qwen3中的GQA实现
class GroupedQueryAttention(nn.Module):def __init__(self, d_in, num_heads, num_kv_groups, head_dim=None, qk_norm=False, dtype=None):super().__init__()assert num_heads % num_kv_groups == 0, "num_heads must be divisible by num_kv_groups"self.num_heads = num_headsself.num_kv_groups = num_kv_groupsself.group_size = num_heads // num_kv_groupsif head_dim is None:assert d_in % num_heads == 0, "`d_in` must be divisible by `num_heads` if `head_dim` is not set"head_dim = d_in // num_headsself.head_dim = head_dimself.d_out = num_heads * head_dimself.W_query = nn.Linear(d_in, self.d_out, bias=False, dtype=dtype)self.W_key = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)self.W_value = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)self.out_proj = nn.Linear(self.d_out, d_in, bias=False, dtype=dtype)if qk_norm:self.q_norm = RMSNorm(head_dim, eps=1e-6)self.k_norm = RMSNorm(head_dim, eps=1e-6)else:self.q_norm = self.k_norm = Nonedef forward(self, x, mask, cos, sin):b, num_tokens, _ = x.shape# 应用投影queries = self.W_query(x) # (b, num_tokens, num_heads * head_dim)keys = self.W_key(x) # (b, num_tokens, num_kv_groups * head_dim)values = self.W_value(x) # (b, num_tokens, num_kv_groups * head_dim)# 重塑queries = queries.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)# 可选的归一化if self.q_norm:queries = self.q_norm(queries)if self.k_norm:keys = self.k_norm(keys)# 应用RoPEqueries = apply_rope(queries, cos, sin)keys = apply_rope(keys, cos, sin)# 扩展K和V以匹配头的数量keys = keys.repeat_interleave(self.group_size, dim=1)values = values.repeat_interleave(self.group_size, dim=1)# 注意力attn_scores = queries @ keys.transpose(2, 3)attn_scores = attn_scores.masked_fill(mask, -torch.inf)attn_weights = torch.softmax(attn_scores / self.head_dim**0.5, dim=-1)context = (attn_weights @ values).transpose(1, 2).reshape(b, num_tokens, self.d_out)return self.out_proj(context) -
关键特性解析
特性 说明 Qwen3-30B-A3B配置 num_heads 查询头数量 32 num_kv_groups 键值组数量 4 group_size 每组大小 8 head_dim 每个头的维度 128 qk_norm QK归一化 True -
维度变化流程
操作步骤 张量形状变化示例 输入数据 [batch_size, seq_len, emb_dim] 查询投影 [batch_size, seq_len, num_heads * head_dim] 键值投影 [batch_size, seq_len, num_kv_groups * head_dim] 重塑查询 [batch_size, num_heads, seq_len, head_dim] 重塑键值 [batch_size, num_kv_groups, seq_len, head_dim] 扩展键值 [batch_size, num_heads, seq_len, head_dim] 注意力计算 [batch_size, num_heads, seq_len, head_dim] 输出投影 [batch_size, seq_len, emb_dim]
MoE前馈网络
MoE介绍
-
MoE (Mixture of Experts) 是一种稀疏激活的神经网络架构,其核心思想是不让所有参数都参与每个token的计算,而是为每个token动态选择一部分"专家"(experts)进行计算。这种方法可以显著增加模型参数量,同时保持计算效率。
在Qwen3-MoE中,每个token通过门控网络选择最适合的8个专家(从128个专家中),然后将这些专家的输出进行加权组合。这种稀疏激活机制使得模型能够拥有更大的参数量,同时保持合理的计算成本。
数学公式
-
MoE前馈网络的计算过程可以表示为:
y=∑i=1EG(x)i⋅Ei(x)y = \sum_{i=1}^{E} G(x)_i \cdot E_i(x) y=i=1∑EG(x)i⋅Ei(x)
其中:
- EEE 是专家总数
- G(x)iG(x)_iG(x)i 是门控网络为第i个专家分配的权重
- Ei(x)E_i(x)Ei(x) 是第i个专家对输入x的处理结果
在Qwen3-MoE中,门控网络选择top-k个专家(k=8),并对它们的输出进行加权求和。
代码实现
-
Qwen3中的MoE前馈网络实现
class MoEFeedForward(nn.Module):def __init__(self, cfg):super().__init__()self.num_experts_per_tok = cfg.num_experts_per_tokself.num_experts = cfg.num_expertsself.gate = nn.Linear(cfg.emb_dim, cfg.num_experts, bias=False, dtype=cfg.dtype)# meta device用于减少初始化模型时的内存压力meta_device = torch.device("meta")self.fc1 = nn.ModuleList([nn.Linear(cfg.emb_dim, cfg.moe_intermediate_size,bias=False, dtype=cfg.dtype, device=meta_device)for _ in range(cfg.num_experts)])self.fc2 = nn.ModuleList([nn.Linear(cfg.emb_dim, cfg.moe_intermediate_size,bias=False, dtype=cfg.dtype, device=meta_device)for _ in range(cfg.num_experts)])self.fc3 = nn.ModuleList([nn.Linear(cfg.moe_intermediate_size, cfg.emb_dim,bias=False, dtype=cfg.dtype, device=meta_device)for _ in range(cfg.num_experts)])def forward(self, x):b, seq_len, embed_dim = x.shapescores = self.gate(x) # (b, seq_len, num_experts)topk_scores, topk_indices = torch.topk(scores, self.num_experts_per_tok, dim=-1)topk_probs = torch.softmax(topk_scores, dim=-1)expert_outputs = []for e in range(self.num_experts):hidden = torch.nn.functional.silu(self.fc1[e](x)) * self.fc2[e](x)out = self.fc3[e](hidden)expert_outputs.append(out.unsqueeze(-2))expert_outputs = torch.cat(expert_outputs, dim=-2) # (b, t, num_experts, emb_dim)gating_probs = torch.zeros_like(scores)for i in range(self.num_experts_per_tok):indices = topk_indices[..., i:i+1]prob = topk_probs[..., i:i+1]gating_probs.scatter_(dim=-1, index=indices, src=prob)gating_probs = gating_probs.unsqueeze(-1) # (b, t, num_experts, 1)# 对专家输出进行加权求和y = (gating_probs * expert_outputs).sum(dim=-2)return y -
关键特性解析
-
门控机制:- 门控网络: 通过线性层将输入映射到专家得分
- Top-k选择: 选择得分最高的k个专家
- 软门控: 使用softmax对选中专家的得分进行归一化
-
专家网络:- SwiGLU激活: 每个专家使用SwiGLU激活函数
- Meta设备: 初始化时使用meta设备减少内存压力
- 模块化设计: 使用ModuleList管理多个专家
-
-
维度变化流程
操作步骤 张量形状变化示例 Qwen3-30B-A3B配置 输入数据 [batch_size, seq_len, emb_dim] [4, 100, 2048] 门控网络 [batch_size, seq_len, num_experts] [4, 100, 128] Top-k选择 [batch_size, seq_len, num_experts_per_tok] [4, 100, 8] 专家计算 [batch_size, seq_len, num_experts, emb_dim] [4, 100, 128, 2048] 门控概率 [batch_size, seq_len, num_experts, 1] [4, 100, 128, 1] 加权求和 [batch_size, seq_len, emb_dim] [4, 100, 2048]
标准前馈网络
-
代码:
class FeedForward(nn.Module):def __init__(self, cfg):super().__init__()self.fc1 = nn.Linear(cfg.emb_dim, cfg.hidden_dim, dtype=cfg.dtype, bias=False)self.fc2 = nn.Linear(cfg.emb_dim, cfg.hidden_dim, dtype=cfg.dtype, bias=False)self.fc3 = nn.Linear(cfg.hidden_dim, cfg.emb_dim, dtype=cfg.dtype, bias=False)def forward(self, x):x_fc1 = self.fc1(x)x_fc2 = self.fc2(x)x = nn.functional.silu(x_fc1) * x_fc2return self.fc3(x) -
这个标准前馈网络使用SwiGLU激活函数,与MoE中每个专家使用的激活函数相同。
Transformer Block
Transformer Block介绍
-
Qwen3-MoE的Transformer Block是模型的核心构建单元,每个Block包含一个分组查询注意力层和一个MoE前馈网络层(或标准前馈网络层)。与标准Transformer不同,Qwen3采用了Pre-Norm结构,即在每个子层之前应用RMSNorm,这种设计有助于训练稳定性和梯度流动。
每个Transformer Block通过残差连接将输入与子层输出相加,形成深度网络中的信息高速公路。Qwen3-30B-A3B模型包含48个这样的Transformer Block,通过层层堆叠实现复杂的语言理解和生成能力。
代码实现
-
Qwen3中的Transformer Block实现
class TransformerBlock(nn.Module):def __init__(self, cfg):super().__init__()self.att = GroupedQueryAttention(d_in=cfg.emb_dim,num_heads=cfg.n_heads,head_dim=cfg.head_dim,num_kv_groups=cfg.n_kv_groups,qk_norm=cfg.qk_norm,dtype=cfg.dtype)if cfg.num_experts > 0:self.ff = MoEFeedForward(cfg)else:self.ff = FeedForward(cfg)self.norm1 = RMSNorm(cfg.emb_dim, eps=1e-6)self.norm2 = RMSNorm(cfg.emb_dim, eps=1e-6)def forward(self, x, mask, cos, sin):# 注意力子层的残差连接shortcut = xx = self.norm1(x)x = self.att(x, mask, cos, sin) # Shape [batch_size, num_tokens, emb_size]x = x + shortcut # 添加原始输入# 前馈子层的残差连接shortcut = xx = self.norm2(x)x = self.ff(x)x = x + shortcut # 添加原始输入return x -
关键设计特点
-
条件选择前馈网络:- 根据配置选择MoE前馈网络或标准前馈网络
- 允许在同一架构中灵活切换稀疏和密集模型
-
Pre-Norm结构:- 在每个子层之前应用归一化,而不是之后
- 有助于训练稳定性,特别是在深层网络中
- 减少梯度消失问题
-
残差连接:- 每个子层都有直接的跳跃连接
- 保证信息流动和梯度传播
- 使得深层网络训练成为可能
-
Qwen3-30B-A3B 完整模型
模型架构
-
Qwen3-MoE的完整架构包含以下组件:
- 词嵌入层(Token Embedding):将输入token映射为高维向量
- 多层Transformer Block:核心的特征提取和变换层
- 最终归一化层(Final Norm):输出前的最后一次归一化
- 输出投影层(Output Head):将隐藏状态映射到词汇表空间
模型支持因果语言建模,通过上三角掩码确保生成过程中不会看到未来信息。
代码实现
-
Qwen3-MoE完整模型实现
class Qwen3MoeModel(nn.Module):def __init__(self, cfg):super().__init__()# Main model parametersself.tok_emb = nn.Embedding(cfg.vocab_size, cfg.emb_dim, dtype=cfg.dtype)self.trf_blocks = nn.ModuleList( # ModuleList since Sequential can only accept one input, and we need `x, mask, cos, sin`[TransformerBlock(cfg) for _ in range(cfg.n_layers)])self.final_norm = RMSNorm(cfg.emb_dim)self.out_head = nn.Linear(cfg.emb_dim, cfg.vocab_size, bias=False, dtype=cfg.dtype)# Reusuable utilitiesif cfg.head_dim is None:head_dim = cfg.emb_dim // cfg.n_headselse:head_dim = cfg.head_dimcos, sin = compute_rope_params(head_dim=head_dim,theta_base=cfg.rope_base,context_length=cfg.context_length)self.register_buffer("cos", cos, persistent=False)self.register_buffer("sin", sin, persistent=False)self.cfg = cfgdef forward(self, in_idx):# Forward passtok_embeds = self.tok_emb(in_idx)x = tok_embedsnum_tokens = x.shape[1]mask = torch.triu(torch.ones(num_tokens, num_tokens, device=x.device, dtype=torch.bool), diagonal=1)for block in self.trf_blocks:x = block(x, mask, self.cos, self.sin)x = self.final_norm(x)logits = self.out_head(x.to(self.cfg.dtype))return logits -
模型配置
def set_qwen3_moe_config(repo_id):repo_id_list = ["Qwen/Qwen3-30B-A3B", "Qwen/Qwen3-235B-A22B-Instruct-2507","Qwen/Qwen3-30B-A3B-Thinking-2507", "Qwen/Qwen3-Coder-30B-A3B-Instruct","/root/Qwen/Qwen3-30B-A3B-Instruct-2507"]assert repo_id in repo_id_list, f"repo_id error,must be one of {repo_id_list}"list_30B = ["Qwen/Qwen3-30B-A3B","Qwen/Qwen3-30B-A3B-Thinking-2507", "Qwen/Qwen3-Coder-30B-A3B-Instruct","/root/Qwen/Qwen3-30B-A3B-Instruct-2507"]list_235B = ["Qwen/Qwen3-235B-A22B-Instruct-2507"]if repo_id in list_30B:# 30BQWEN3_CONFIG = {"vocab_size": 151_936,"context_length": 262_144,"emb_dim": 2048,"n_heads": 32,"n_layers": 48,"head_dim": 128,"qk_norm": True,"n_kv_groups": 4,"rope_base": 10_000_000.0,"dtype": torch.bfloat16,"num_experts": 128,"num_experts_per_tok": 8,"moe_intermediate_size": 768,}elif repo_id in list_235B:## 235BQWEN3_CONFIG = {"vocab_size": 151_936,"context_length": 262_144,"emb_dim": 4096,"n_heads": 64,"n_layers": 94,"head_dim": 128,"qk_norm": True,"n_kv_groups": 4,"rope_base": 5_000_000.0,"dtype": torch.bfloat16,"num_experts": 128,"num_experts_per_tok": 8,"moe_intermediate_size": 1536,}else:raise ValueError(f"{repo_id} is not supported.")return Qwen3MoeConfig(**QWEN3_CONFIG) -
不同规模模型对比
模型规模 参数量 嵌入维度 注意力头 层数 专家数量 每token专家数 MoE中间层大小 30B-A3B 30B/3B 2048 32 48 128 8 768 235B-A22B 235B/22B 4096 64 94 128 8 1536 -
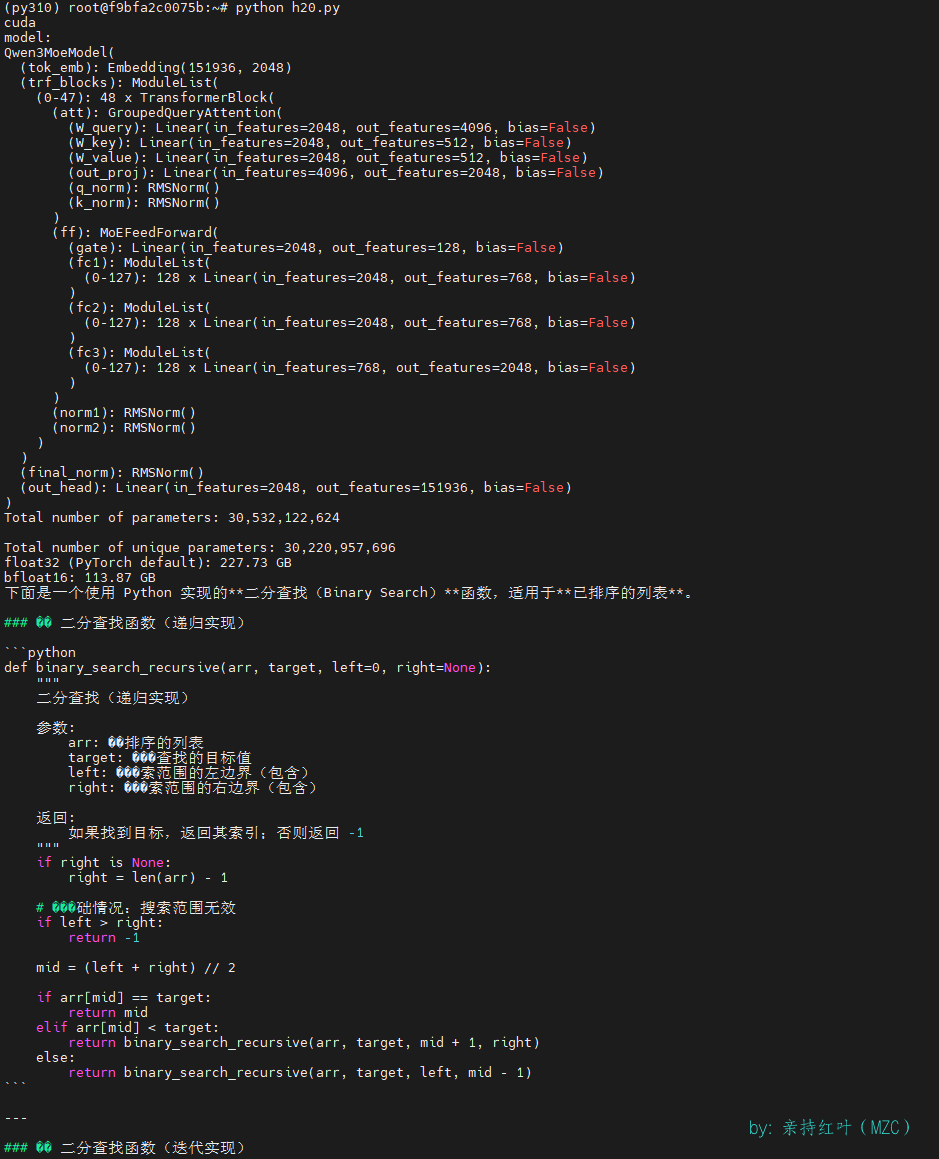
Qwen3-30B-A3B加载后的模型print
Qwen3MoeModel((tok_emb): Embedding(151936, 2048)(trf_blocks): ModuleList((0-47): 48 x TransformerBlock((att): GroupedQueryAttention((W_query): Linear(in_features=2048, out_features=4096, bias=False)(W_key): Linear(in_features=2048, out_features=512, bias=False)(W_value): Linear(in_features=2048, out_features=512, bias=False)(out_proj): Linear(in_features=4096, out_features=2048, bias=False)(q_norm): RMSNorm()(k_norm): RMSNorm())(ff): MoEFeedForward((gate): Linear(in_features=2048, out_features=128, bias=False)(fc1): ModuleList((0-127): 128 x Linear(in_features=2048, out_features=768, bias=False))(fc2): ModuleList((0-127): 128 x Linear(in_features=2048, out_features=768, bias=False))(fc3): ModuleList((0-127): 128 x Linear(in_features=768, out_features=2048, bias=False)))(norm1): RMSNorm()(norm2): RMSNorm()))(final_norm): RMSNorm()(out_head): Linear(in_features=2048, out_features=151936, bias=False) )
文本生成+推理
文本生成
-
基础的贪婪解码算法:
def generate_text_basic_stream(model, token_ids, max_new_tokens, eos_token_id=None):model.eval()with torch.no_grad():for _ in range(max_new_tokens):# 前向传播获取logitsout = model(token_ids)[:, -1] # 只取最后一个位置的输出# 贪婪解码:选择概率最高的tokennext_token = torch.argmax(out, dim=-1, keepdim=True)# 检查是否遇到结束tokenif (eos_token_id is not Noneand torch.all(next_token == eos_token_id)):breakyield next_token# 将新token添加到序列中token_ids = torch.cat([token_ids, next_token], dim=1)
Tokenizer实现
-
Qwen3专用的Tokenizer实现
class Qwen3Tokenizer:_SPECIALS = ["<|endoftext|>","<|im_start|>", "<|im_end|>","<|object_ref_start|>", "<|object_ref_end|>","<|box_start|>", "<|box_end|>","<|quad_start|>", "<|quad_end|>","<|vision_start|>", "<|vision_end|>","<|vision_pad|>", "<|image_pad|>", "<|video_pad|>",]_SPLIT_RE = re.compile(r"(<\|[^>]+?\|>)")def __init__(self, tokenizer_file_path="tokenizer.json", repo_id=None,apply_chat_template=True, add_generation_prompt=False, add_thinking=False):self.apply_chat_template = apply_chat_templateself.add_generation_prompt = add_generation_promptself.add_thinking = add_thinkingtok_file = Path(tokenizer_file_path)self._tok = Tokenizer.from_file(str(tok_file))self._special_to_id = {t: self._tok.token_to_id(t) for t in self._SPECIALS}self.pad_token_id = self._special_to_id.get("<|endoftext|>")self.eos_token_id = self.pad_token_idif repo_id and "Base" not in repo_id:eos_token = "<|im_end|>"else:eos_token = "<|endoftext|>"if eos_token in self._special_to_id:self.eos_token_id = self._special_to_id[eos_token]def encode(self, text, chat_wrapped=None):if chat_wrapped is None:chat_wrapped = self.apply_chat_templatestripped = text.strip()if stripped in self._special_to_id and "\n" not in stripped:return [self._special_to_id[stripped]]if chat_wrapped:text = self._wrap_chat(text)ids = []for part in filter(None, self._SPLIT_RE.split(text)):if part in self._special_to_id:ids.append(self._special_to_id[part])else:ids.extend(self._tok.encode(part).ids)return idsdef decode(self, ids):return self._tok.decode(ids, skip_special_tokens=False)def _wrap_chat(self, user_msg):s = f"<|im_start|>user\n{user_msg}<|im_end|>\n"if self.add_generation_prompt:s += "<|im_start|>assistant"if self.add_thinking:s += "\n"else:s += "\n<think>\n\n</think>\n\n"return s
权重加载
-
Qwen3-MoE模型权重加载函数
def load_weights_into_qwen(model, param_config, params):def assign(left, right, tensor_name="unknown"):if left.shape != right.shape:raise ValueError(f"Shape mismatch in tensor '{tensor_name}'. Left: {left.shape}, Right: {right.shape}")return torch.nn.Parameter(right.clone().detach() if isinstance(right, torch.Tensor) else torch.tensor(right))model.tok_emb.weight = assign(model.tok_emb.weight, params["model.embed_tokens.weight"], "model.embed_tokens.weight")for l in range(param_config.n_layers):block = model.trf_blocks[l]att = block.att# Q, K, V projectionsatt.W_query.weight = assign(att.W_query.weight,params[f"model.layers.{l}.self_attn.q_proj.weight"],f"model.layers.{l}.self_attn.q_proj.weight")att.W_key.weight = assign(att.W_key.weight,params[f"model.layers.{l}.self_attn.k_proj.weight"],f"model.layers.{l}.self_attn.k_proj.weight")att.W_value.weight = assign(att.W_value.weight,params[f"model.layers.{l}.self_attn.v_proj.weight"],f"model.layers.{l}.self_attn.v_proj.weight")# Output projectionatt.out_proj.weight = assign(att.out_proj.weight,params[f"model.layers.{l}.self_attn.o_proj.weight"],f"model.layers.{l}.self_attn.o_proj.weight")# QK normsif hasattr(att, "q_norm") and att.q_norm is not None:att.q_norm.scale = assign(att.q_norm.scale,params[f"model.layers.{l}.self_attn.q_norm.weight"],f"model.layers.{l}.self_attn.q_norm.weight")if hasattr(att, "k_norm") and att.k_norm is not None:att.k_norm.scale = assign(att.k_norm.scale,params[f"model.layers.{l}.self_attn.k_norm.weight"],f"model.layers.{l}.self_attn.k_norm.weight")# Attention layernormblock.norm1.scale = assign(block.norm1.scale,params[f"model.layers.{l}.input_layernorm.weight"],f"model.layers.{l}.input_layernorm.weight")# Feedforward weightsif "num_experts" in param_config.model_dump():# 加载路由器(门控)权重block.ff.gate.weight = assign(block.ff.gate.weight,params[f"model.layers.{l}.mlp.gate.weight"],f"model.layers.{l}.mlp.gate.weight")# 加载专家权重for e in range(param_config.num_experts):prefix = f"model.layers.{l}.mlp.experts.{e}"block.ff.fc1[e].weight = assign(block.ff.fc1[e].weight,params[f"{prefix}.gate_proj.weight"],f"{prefix}.gate_proj.weight")block.ff.fc2[e].weight = assign(block.ff.fc2[e].weight,params[f"{prefix}.up_proj.weight"],f"{prefix}.up_proj.weight")block.ff.fc3[e].weight = assign(block.ff.fc3[e].weight,params[f"{prefix}.down_proj.weight"],f"{prefix}.down_proj.weight")# 分配权重后,将专家层从meta移动到CPUblock.ff.fc1[e] = block.ff.fc1[e].to("cpu")block.ff.fc2[e] = block.ff.fc2[e].to("cpu")block.ff.fc3[e] = block.ff.fc3[e].to("cpu")else:block.ff.fc1.weight = assign(block.ff.fc1.weight,params[f"model.layers.{l}.mlp.gate_proj.weight"],f"model.layers.{l}.mlp.gate_proj.weight")block.ff.fc2.weight = assign(block.ff.fc2.weight,params[f"model.layers.{l}.mlp.up_proj.weight"],f"model.layers.{l}.mlp.up_proj.weight")block.ff.fc3.weight = assign(block.ff.fc3.weight,params[f"model.layers.{l}.mlp.down_proj.weight"],f"model.layers.{l}.mlp.down_proj.weight")block.norm2.scale = assign(block.norm2.scale,params[f"model.layers.{l}.post_attention_layernorm.weight"],f"model.layers.{l}.post_attention_layernorm.weight")# Final normalization and output headmodel.final_norm.scale = assign(model.final_norm.scale, params["model.norm.weight"], "model.norm.weight")if "lm_head.weight" in params:model.out_head.weight = assign(model.out_head.weight, params["lm_head.weight"], "lm_head.weight")else:# 模型使用权重绑定,因此我们在这里重用嵌入层权重print("Model uses weight tying.")model.out_head.weight = assign(model.out_head.weight, params["model.embed_tokens.weight"], "model.embed_tokens.weight")
整体代码
-
完整的代码实现可以在
2_qwen3_archtecture_moe.py文件中找到,包括模型定义、权重加载、文本生成等功能。 -
使用示例
#!/usr/bin/env python # -*- coding: utf-8 -*- # # @File : 2_qwen3_archtecture_moe.py # @Date : 2025/8/5 # @Author : mengzhichao # @Version : 1.0 # @Desc : import torch import torch.nn as nn import json import os from pathlib import Path from safetensors.torch import load_file from huggingface_hub import snapshot_download import re from tokenizers import Tokenizer from pydantic import BaseModel, Field from tqdm import tqdm import timeclass Qwen3MoeConfig(BaseModel):"""Pydantic model for Qwen3 moe configuration"""model_config = {"arbitrary_types_allowed": True}vocab_size: int = Field(..., description="词汇表大小")context_length: int = Field(..., description="用于训练模型的上下文长度")emb_dim: int = Field(..., description="Embedding 维度")n_heads: int = Field(..., description="注意力头的数量")n_layers: int = Field(..., description="层数")head_dim: int = Field(..., description="GQA 中每个注意力头的维度大小")qk_norm: bool = Field(..., description="是否在 GQA 中对key和value进行归一化")n_kv_groups: int = Field(..., description="用于分组查询注意力的 KV 组数")rope_base: float = Field(..., description="RoPE 中'theta'的基数值")dtype: torch.dtype = Field(..., description="较低精度的数据类型,用于降低显存占用")# MoE 相关参数num_experts: int = Field(..., description="专家数量")num_experts_per_tok: int = Field(..., description="每个token使用的专家数量")moe_intermediate_size: int = Field(..., description="MoE中间层大小")class FeedForward(nn.Module):def __init__(self, cfg):super().__init__()self.fc1 = nn.Linear(cfg.emb_dim, cfg.hidden_dim, dtype=cfg.dtype, bias=False)self.fc2 = nn.Linear(cfg.emb_dim, cfg.hidden_dim, dtype=cfg.dtype, bias=False)self.fc3 = nn.Linear(cfg.hidden_dim, cfg.emb_dim, dtype=cfg.dtype, bias=False)def forward(self, x):x_fc1 = self.fc1(x)x_fc2 = self.fc2(x)x = nn.functional.silu(x_fc1) * x_fc2return self.fc3(x)class MoEFeedForward(nn.Module):def __init__(self, cfg):super().__init__()self.num_experts_per_tok = cfg.num_experts_per_tokself.num_experts = cfg.num_expertsself.gate = nn.Linear(cfg.emb_dim, cfg.num_experts, bias=False, dtype=cfg.dtype)# meta device to reduce memory pressure when initializing the model before loading weightsmeta_device = torch.device("meta")self.fc1 = nn.ModuleList([nn.Linear(cfg.emb_dim, cfg.moe_intermediate_size,bias=False, dtype=cfg.dtype, device=meta_device)for _ in range(cfg.num_experts)])self.fc2 = nn.ModuleList([nn.Linear(cfg.emb_dim, cfg.moe_intermediate_size,bias=False, dtype=cfg.dtype, device=meta_device)for _ in range(cfg.num_experts)])self.fc3 = nn.ModuleList([nn.Linear(cfg.moe_intermediate_size, cfg.emb_dim,bias=False, dtype=cfg.dtype, device=meta_device)for _ in range(cfg.num_experts)])def forward(self, x):b, seq_len, embed_dim = x.shapescores = self.gate(x) # (b, seq_len, num_experts)topk_scores, topk_indices = torch.topk(scores, self.num_experts_per_tok, dim=-1)topk_probs = torch.softmax(topk_scores, dim=-1)expert_outputs = []for e in range(self.num_experts):hidden = torch.nn.functional.silu(self.fc1[e](x)) * self.fc2[e](x)out = self.fc3[e](hidden)expert_outputs.append(out.unsqueeze(-2))expert_outputs = torch.cat(expert_outputs, dim=-2) # (b, t, num_experts, emb_dim)gating_probs = torch.zeros_like(scores)for i in range(self.num_experts_per_tok):indices = topk_indices[..., i:i + 1]prob = topk_probs[..., i:i + 1]gating_probs.scatter_(dim=-1, index=indices, src=prob)gating_probs = gating_probs.unsqueeze(-1) # (b, t, num_experts, 1)# Weighted sum over expertsy = (gating_probs * expert_outputs).sum(dim=-2)return yclass RMSNorm(nn.Module):def __init__(self, emb_dim, eps=1e-6, bias=False, qwen3_compatible=True):super().__init__()self.eps = epsself.qwen3_compatible = qwen3_compatibleself.scale = nn.Parameter(torch.ones(emb_dim))self.shift = nn.Parameter(torch.zeros(emb_dim)) if bias else Nonedef forward(self, x):input_dtype = x.dtypeif self.qwen3_compatible:x = x.to(torch.float32)variance = x.pow(2).mean(dim=-1, keepdim=True)norm_x = x * torch.rsqrt(variance + self.eps)norm_x = norm_x * self.scaleif self.shift is not None:norm_x = norm_x + self.shiftreturn norm_x.to(input_dtype)def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, dtype=torch.float32):assert head_dim % 2 == 0, "Embedding dimension must be even"# Compute the inverse frequenciesinv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float() / head_dim))# Generate position indicespositions = torch.arange(context_length, dtype=dtype)# Compute the anglesangles = positions[:, None] * inv_freq[None, :] # Shape: (context_length, head_dim // 2)# Expand angles to match the head_dimangles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)# Precompute sine and cosinecos = torch.cos(angles)sin = torch.sin(angles)return cos, sindef apply_rope(x, cos, sin):# x: (batch_size, num_heads, seq_len, head_dim)batch_size, num_heads, seq_len, head_dim = x.shapeassert head_dim % 2 == 0, "Head dimension must be even"# Split x into first half and second halfx1 = x[..., : head_dim // 2] # First halfx2 = x[..., head_dim // 2:] # Second half# Adjust sin and cos shapescos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)# Apply the rotary transformationrotated = torch.cat((-x2, x1), dim=-1)x_rotated = (x * cos) + (rotated * sin)# It's ok to use lower-precision after applying cos and sin rotationreturn x_rotated.to(dtype=x.dtype)class GroupedQueryAttention(nn.Module):def __init__(self, d_in, num_heads, num_kv_groups, head_dim=None, qk_norm=False, dtype=None):super().__init__()assert num_heads % num_kv_groups == 0, "num_heads must be divisible by num_kv_groups"self.num_heads = num_headsself.num_kv_groups = num_kv_groupsself.group_size = num_heads // num_kv_groupsif head_dim is None:assert d_in % num_heads == 0, "`d_in` must be divisible by `num_heads` if `head_dim` is not set"head_dim = d_in // num_headsself.head_dim = head_dimself.d_out = num_heads * head_dimself.W_query = nn.Linear(d_in, self.d_out, bias=False, dtype=dtype)self.W_key = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)self.W_value = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)self.out_proj = nn.Linear(self.d_out, d_in, bias=False, dtype=dtype)if qk_norm:self.q_norm = RMSNorm(head_dim, eps=1e-6)self.k_norm = RMSNorm(head_dim, eps=1e-6)else:self.q_norm = self.k_norm = Nonedef forward(self, x, mask, cos, sin):b, num_tokens, _ = x.shape# Apply projectionsqueries = self.W_query(x) # (b, num_tokens, num_heads * head_dim)keys = self.W_key(x) # (b, num_tokens, num_kv_groups * head_dim)values = self.W_value(x) # (b, num_tokens, num_kv_groups * head_dim)# Reshapequeries = queries.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)# Optional normalizationif self.q_norm:queries = self.q_norm(queries)if self.k_norm:keys = self.k_norm(keys)# Apply RoPEqueries = apply_rope(queries, cos, sin)keys = apply_rope(keys, cos, sin)# Expand K and V to match number of headskeys = keys.repeat_interleave(self.group_size, dim=1)values = values.repeat_interleave(self.group_size, dim=1)# Attentionattn_scores = queries @ keys.transpose(2, 3)attn_scores = attn_scores.masked_fill(mask, -torch.inf)attn_weights = torch.softmax(attn_scores / self.head_dim ** 0.5, dim=-1)context = (attn_weights @ values).transpose(1, 2).reshape(b, num_tokens, self.d_out)return self.out_proj(context)class TransformerBlock(nn.Module):def __init__(self, cfg):super().__init__()self.att = GroupedQueryAttention(d_in=cfg.emb_dim,num_heads=cfg.n_heads,head_dim=cfg.head_dim,num_kv_groups=cfg.n_kv_groups,qk_norm=cfg.qk_norm,dtype=cfg.dtype)if cfg.num_experts > 0:self.ff = MoEFeedForward(cfg)else:self.ff = FeedForward(cfg)self.norm1 = RMSNorm(cfg.emb_dim, eps=1e-6)self.norm2 = RMSNorm(cfg.emb_dim, eps=1e-6)def forward(self, x, mask, cos, sin):# Shortcut connection for attention blockshortcut = xx = self.norm1(x)x = self.att(x, mask, cos, sin) # Shape [batch_size, num_tokens, emb_size]x = x + shortcut # Add the original input back# Shortcut connection for feed-forward blockshortcut = xx = self.norm2(x)x = self.ff(x)x = x + shortcut # Add the original input backreturn xclass Qwen3MoeModel(nn.Module):def __init__(self, cfg):super().__init__()# Main model parametersself.tok_emb = nn.Embedding(cfg.vocab_size, cfg.emb_dim, dtype=cfg.dtype)self.trf_blocks = nn.ModuleList(# ModuleList since Sequential can only accept one input, and we need `x, mask, cos, sin`[TransformerBlock(cfg) for _ in range(cfg.n_layers)])self.final_norm = RMSNorm(cfg.emb_dim)self.out_head = nn.Linear(cfg.emb_dim, cfg.vocab_size, bias=False, dtype=cfg.dtype)# Reusuable utilitiesif cfg.head_dim is None:head_dim = cfg.emb_dim // cfg.n_headselse:head_dim = cfg.head_dimcos, sin = compute_rope_params(head_dim=head_dim,theta_base=cfg.rope_base,context_length=cfg.context_length)self.register_buffer("cos", cos, persistent=False)self.register_buffer("sin", sin, persistent=False)self.cfg = cfgdef forward(self, in_idx):# Forward passtok_embeds = self.tok_emb(in_idx)x = tok_embedsnum_tokens = x.shape[1]mask = torch.triu(torch.ones(num_tokens, num_tokens, device=x.device, dtype=torch.bool), diagonal=1)for block in self.trf_blocks:x = block(x, mask, self.cos, self.sin)x = self.final_norm(x)logits = self.out_head(x.to(self.cfg.dtype))return logitsdef model_memory_size(model, input_dtype=torch.float32):total_params = 0total_grads = 0for param in model.parameters():# Calculate total number of elements per parameterparam_size = param.numel()total_params += param_size# Check if gradients are stored for this parameterif param.requires_grad:total_grads += param_size# Calculate buffer size (non-parameters that require memory)total_buffers = sum(buf.numel() for buf in model.buffers())# Size in bytes = (Number of elements) * (Size of each element in bytes)# We assume parameters and gradients are stored in the same type as input dtypeelement_size = torch.tensor(0, dtype=input_dtype).element_size()total_memory_bytes = (total_params + total_grads + total_buffers) * element_size# Convert bytes to gigabytestotal_memory_gb = total_memory_bytes / (1024 ** 3)return total_memory_gbdef load_weights_into_qwen(model, param_config, params):def assign(left, right, tensor_name="unknown"):if left.shape != right.shape:raise ValueError(f"Shape mismatch in tensor '{tensor_name}'. Left: {left.shape}, Right: {right.shape}")return torch.nn.Parameter(right.clone().detach() if isinstance(right, torch.Tensor) else torch.tensor(right))model.tok_emb.weight = assign(model.tok_emb.weight, params["model.embed_tokens.weight"],"model.embed_tokens.weight")bar = tqdm(range(param_config.n_layers))for l in bar:bar.set_description(f"Loading weights into layer {l+1}")block = model.trf_blocks[l]att = block.att# Q, K, V projectionsatt.W_query.weight = assign(att.W_query.weight,params[f"model.layers.{l}.self_attn.q_proj.weight"],f"model.layers.{l}.self_attn.q_proj.weight")att.W_key.weight = assign(att.W_key.weight,params[f"model.layers.{l}.self_attn.k_proj.weight"],f"model.layers.{l}.self_attn.k_proj.weight")att.W_value.weight = assign(att.W_value.weight,params[f"model.layers.{l}.self_attn.v_proj.weight"],f"model.layers.{l}.self_attn.v_proj.weight")# Output projectionatt.out_proj.weight = assign(att.out_proj.weight,params[f"model.layers.{l}.self_attn.o_proj.weight"],f"model.layers.{l}.self_attn.o_proj.weight")# QK normsif hasattr(att, "q_norm") and att.q_norm is not None:att.q_norm.scale = assign(att.q_norm.scale,params[f"model.layers.{l}.self_attn.q_norm.weight"],f"model.layers.{l}.self_attn.q_norm.weight")if hasattr(att, "k_norm") and att.k_norm is not None:att.k_norm.scale = assign(att.k_norm.scale,params[f"model.layers.{l}.self_attn.k_norm.weight"],f"model.layers.{l}.self_attn.k_norm.weight")# Attention layernormblock.norm1.scale = assign(block.norm1.scale,params[f"model.layers.{l}.input_layernorm.weight"],f"model.layers.{l}.input_layernorm.weight")# Feedforward weightsif "num_experts" in param_config.model_dump():# Load router (gating) weightsblock.ff.gate.weight = assign(block.ff.gate.weight,params[f"model.layers.{l}.mlp.gate.weight"],f"model.layers.{l}.mlp.gate.weight")# Load expert weightsfor e in range(param_config.num_experts):prefix = f"model.layers.{l}.mlp.experts.{e}"block.ff.fc1[e].weight = assign(block.ff.fc1[e].weight,params[f"{prefix}.gate_proj.weight"],f"{prefix}.gate_proj.weight")block.ff.fc2[e].weight = assign(block.ff.fc2[e].weight,params[f"{prefix}.up_proj.weight"],f"{prefix}.up_proj.weight")block.ff.fc3[e].weight = assign(block.ff.fc3[e].weight,params[f"{prefix}.down_proj.weight"],f"{prefix}.down_proj.weight")# After assigning weights, move the expert layers from meta to CPUblock.ff.fc1[e] = block.ff.fc1[e].to("cpu")block.ff.fc2[e] = block.ff.fc2[e].to("cpu")block.ff.fc3[e] = block.ff.fc3[e].to("cpu")else:block.ff.fc1.weight = assign(block.ff.fc1.weight,params[f"model.layers.{l}.mlp.gate_proj.weight"],f"model.layers.{l}.mlp.gate_proj.weight")block.ff.fc2.weight = assign(block.ff.fc2.weight,params[f"model.layers.{l}.mlp.up_proj.weight"],f"model.layers.{l}.mlp.up_proj.weight")block.ff.fc3.weight = assign(block.ff.fc3.weight,params[f"model.layers.{l}.mlp.down_proj.weight"],f"model.layers.{l}.mlp.down_proj.weight")block.norm2.scale = assign(block.norm2.scale,params[f"model.layers.{l}.post_attention_layernorm.weight"],f"model.layers.{l}.post_attention_layernorm.weight")# Final normalization and output headmodel.final_norm.scale = assign(model.final_norm.scale, params["model.norm.weight"], "model.norm.weight")if "lm_head.weight" in params:model.out_head.weight = assign(model.out_head.weight, params["lm_head.weight"], "lm_head.weight")else:# Model uses weight tying, hence we reuse the embedding layer weights hereprint("Model uses weight tying.")model.out_head.weight = assign(model.out_head.weight, params["model.embed_tokens.weight"],"model.embed_tokens.weight")class Qwen3Tokenizer:_SPECIALS = ["<|endoftext|>","<|im_start|>", "<|im_end|>","<|object_ref_start|>", "<|object_ref_end|>","<|box_start|>", "<|box_end|>","<|quad_start|>", "<|quad_end|>","<|vision_start|>", "<|vision_end|>","<|vision_pad|>", "<|image_pad|>", "<|video_pad|>",]_SPLIT_RE = re.compile(r"(<\|[^>]+?\|>)")def __init__(self, tokenizer_file_path="tokenizer.json", repo_id=None,apply_chat_template=True, add_generation_prompt=False, add_thinking=False):self.apply_chat_template = apply_chat_templateself.add_generation_prompt = add_generation_promptself.add_thinking = add_thinkingtok_file = Path(tokenizer_file_path)self._tok = Tokenizer.from_file(str(tok_file))self._special_to_id = {t: self._tok.token_to_id(t) for t in self._SPECIALS}self.pad_token_id = self._special_to_id.get("<|endoftext|>")self.eos_token_id = self.pad_token_idif repo_id and "Base" not in repo_id:eos_token = "<|im_end|>"else:eos_token = "<|endoftext|>"if eos_token in self._special_to_id:self.eos_token_id = self._special_to_id[eos_token]def encode(self, text, chat_wrapped=None):if chat_wrapped is None:chat_wrapped = self.apply_chat_templatestripped = text.strip()if stripped in self._special_to_id and "\n" not in stripped:return [self._special_to_id[stripped]]if chat_wrapped:text = self._wrap_chat(text)ids = []for part in filter(None, self._SPLIT_RE.split(text)):if part in self._special_to_id:ids.append(self._special_to_id[part])else:ids.extend(self._tok.encode(part).ids)return idsdef decode(self, ids):return self._tok.decode(ids, skip_special_tokens=False)def _wrap_chat(self, user_msg):s = f"<|im_start|>user\n{user_msg}<|im_end|>\n"if self.add_generation_prompt:s += "<|im_start|>assistant"if self.add_thinking:s += "\n"else:s += "\n<think>\n\n</think>\n\n"return sdef generate_text_basic_stream(model, token_ids, max_new_tokens, eos_token_id=None):model.eval()with torch.no_grad():for _ in range(max_new_tokens):out = model(token_ids)[:, -1]next_token = torch.argmax(out, dim=-1, keepdim=True)if (eos_token_id is not Noneand torch.all(next_token == eos_token_id)):breakyield next_tokentoken_ids = torch.cat([token_ids, next_token], dim=1)def set_qwen3_moe_config(repo_id):repo_id_list = ["Qwen/Qwen3-30B-A3B", "Qwen/Qwen3-235B-A22B-Instruct-2507","Qwen/Qwen3-30B-A3B-Thinking-2507", "Qwen/Qwen3-Coder-30B-A3B-Instruct","/root/Qwen/Qwen3-30B-A3B-Instruct-2507"]assert repo_id in repo_id_list, f"repo_id error,must be one of {repo_id_list}"list_30B = ["Qwen/Qwen3-30B-A3B", "Qwen/Qwen3-30B-A3B-Thinking-2507", "Qwen/Qwen3-Coder-30B-A3B-Instruct","/root/Qwen/Qwen3-30B-A3B-Instruct-2507"]list_235B = ["Qwen/Qwen3-235B-A22B-Instruct-2507"]if repo_id in list_30B:# 30BQWEN3_CONFIG = {"vocab_size": 151_936,"context_length": 262_144,"emb_dim": 2048,"n_heads": 32,"n_layers": 48,"head_dim": 128,"qk_norm": True,"n_kv_groups": 4,"rope_base": 10_000_000.0,"dtype": torch.bfloat16,"num_experts": 128,"num_experts_per_tok": 8,"moe_intermediate_size": 768,}elif repo_id in list_235B:## 235BQWEN3_CONFIG = {"vocab_size": 151_936,"context_length": 262_144,"emb_dim": 4096,"n_heads": 64,"n_layers": 94,"head_dim": 128,"qk_norm": True,"n_kv_groups": 4,"rope_base": 5_000_000.0,"dtype": torch.bfloat16,"num_experts": 128,"num_experts_per_tok": 8,"moe_intermediate_size": 1536,}else:raise ValueError(f"{repo_id} is not supported.")return Qwen3MoeConfig(**QWEN3_CONFIG)if __name__ == "__main__":# repo_id = "Qwen/Qwen3-30B-A3B" # Original Instruct/Thinking hybrind model# repo_id = "Qwen/Qwen3-235B-A22B-Instruct-2507" # New instruct model# repo_id = "Qwen/Qwen3-30B-A3B-Thinking-2507" # New thinking model# repo_id = "Qwen/Qwen3-Coder-30B-A3B-Instruct" # (Qwen3 Coder Flash)repo_id = "/root/Qwen/Qwen3-30B-A3B-Instruct-2507" # 模型提前下载在这个路径qwen3_moe_cfg = set_qwen3_moe_config(repo_id)if torch.cuda.is_available():device = torch.device("cuda")elif torch.backends.mps.is_available():device = torch.device("mps")else:device = torch.device("cpu")print(device)torch.manual_seed(123)with device:model = Qwen3MoeModel(qwen3_moe_cfg)# model.to(device)print(f"model: \n{model}")total_params = sum(p.numel() for p in model.parameters())print(f"Total number of parameters: {total_params:,}")# Account for weight tyingtotal_params_normalized = total_params - model.tok_emb.weight.numel()print(f"\nTotal number of unique parameters: {total_params_normalized:,}")print(f"float32 (PyTorch default): {model_memory_size(model, input_dtype=torch.float32):.2f} GB")print(f"bfloat16: {model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB")# local_dir = Path(repo_id).parts[-1]# repo_dir = snapshot_download(repo_id=repo_id, local_dir=local_dir)repo_dir = "/root/Qwen/Qwen3-30B-A3B-Instruct-2507"index_path = os.path.join(repo_dir, "model.safetensors.index.json")with open(index_path, "r") as f:index = json.load(f)weights_dict = {}for filename in set(index["weight_map"].values()):shard_path = os.path.join(repo_dir, filename)shard = load_file(shard_path)weights_dict.update(shard)load_weights_into_qwen(model, qwen3_moe_cfg, weights_dict)model.to(device);tokenizer_file_path = f"{repo_dir}/tokenizer.json"tokenizer = Qwen3Tokenizer(tokenizer_file_path=tokenizer_file_path,repo_id=repo_id,add_generation_prompt=True,add_thinking=True)prompt = "使用python实现一个二分查找的函数"input_token_ids = tokenizer.encode(prompt)text = tokenizer.decode(input_token_ids)input_token_ids_tensor = torch.tensor(input_token_ids, device=device).unsqueeze(0)start_time = time.perf_counter()llm_response = ""token_num = 0for token in generate_text_basic_stream(model=model,token_ids=input_token_ids_tensor,max_new_tokens=500,# eos_token_id=tokenizer.eos_token_id):token_id = token.squeeze(0).tolist()current_token = tokenizer.decode(token_id)llm_response += current_tokentoken_num += 1print(current_token,end="",flush=True)end_time = time.perf_counter()print(f"共生成token数:{token_num}, 耗时:{end_time - start_time}, tps: {token_num / (end_time - start_time)}")print(f"中文字符数:{len(current_token)}, 耗时:{end_time - start_time}, 每秒中文字符数: {len(current_token) / (end_time - start_time)}") -
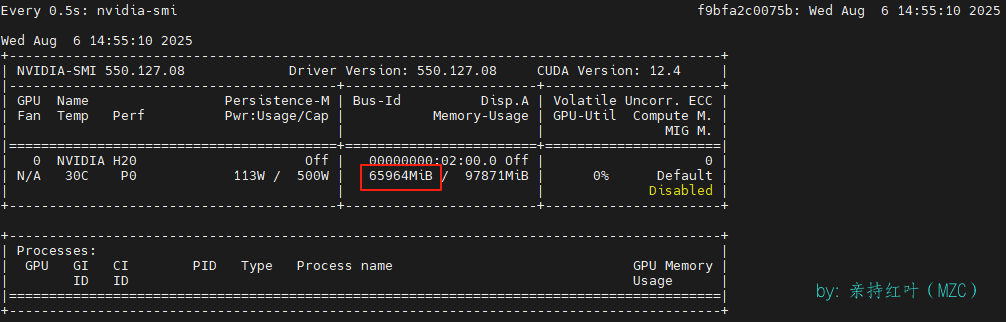
显存占用(H20上感觉只有3-4tokens/s)
-
输出示例