库的制作和原理
1.库的概念
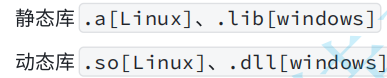
2动静态库
在使用动静态库的时候的系统默认规则:
结论1:gcc/g++默认使用动态库!非得静态链接 只能-static!一旦-static,就必须存在对应的静态库
结论2:在linux系统下,默认情况安装的大部分库,默认都优先安装的是动态库!
结论3:库:应用程序=1:n
结论4:vs不仅仅形成可执行程序,也能形成动静态库只存在静态库,可执行程序,对于该库,只能静态链接了!
2.1.静态库的制作和使用
场景再现:
此时有两名同学,张三和李四。

李四有一个usercode.c的文件,但是李四的代码依赖张三的代码,那么如何将李四的代码给运行起来呢?
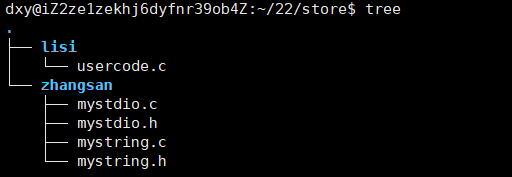
方法一:只需将张三所有的.o文件和.h文件给李四,李四再将自己的.c文件编译成.o文件,再将所有的.o文件生成可执行文件即可
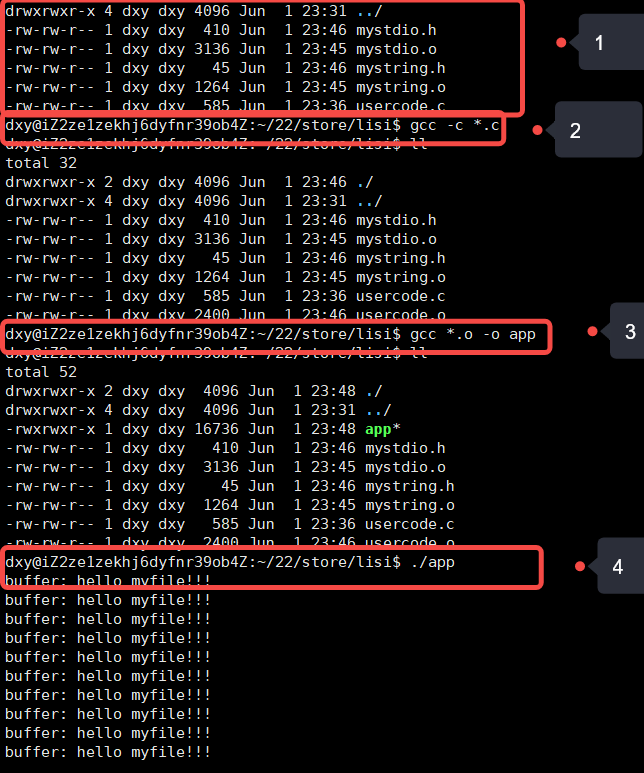
方法二:当.o文件太多的话,少一个.o文件,程序都运行不了,所以此时我们就需要张三将所有.o文件进行打包处理一起交给李四(这个过程就是制作一个静态库的过程)
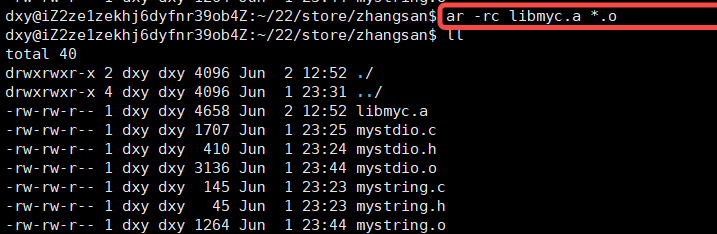
libmyc.a :lib是前缀 , .a:后缀 myc:才是真实的名字
ar -rc libmyc.a *.o
此时李四有了所有的头文件和所有.o文件打包后的.a文件,李四此时将自己的usercode.c文件编成.o文件,指定路径 指定文件进行连接(这个过程就是静态库使用的过程)
gcc -o app usercode.o -L. -l mycL .:指定路径是当前路径
l: 指定文件是 myc文件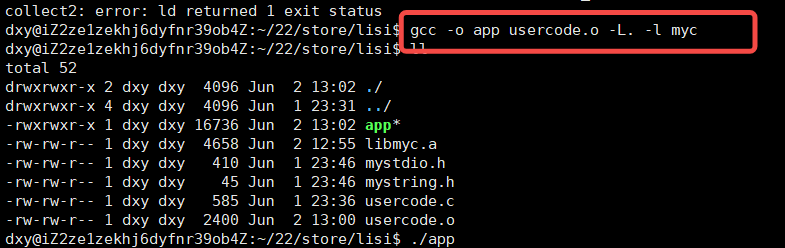
但是还是太low了,所以我们将所有的.h文件放在include目录下 所有的.a文件放再 mylib路径下,
再将其进行打包,一起发送个李四,(这就是下载安装包的过程)
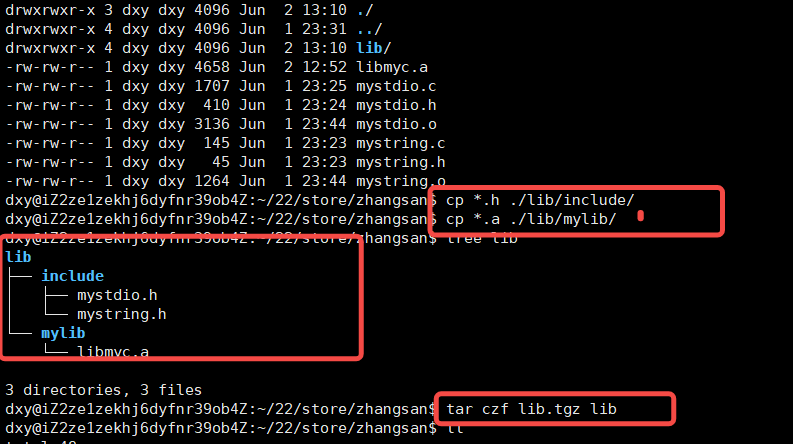
此时李四的只需依靠一个 lib就可以形成可执行文件
gcc -o app usercode.c -I ./lib/include/ -L ./lib/mylib/ -lmycI:.c文件编译成 .o文件 需要头文件的地址,I就是指定头文件的地址,时成功编译成 .o文件
2.2.动态库的制作和使用
动态库的制作和静态库的制作有着异曲同工之处,它们的只要的目的就是将所有的.文件进行打包和所有的.o文件进行打包,只是打包的命令不一样而已。
gcc -shared -o libmyc.so *.olib:前缀.so:后缀myc:文件名动态库的制作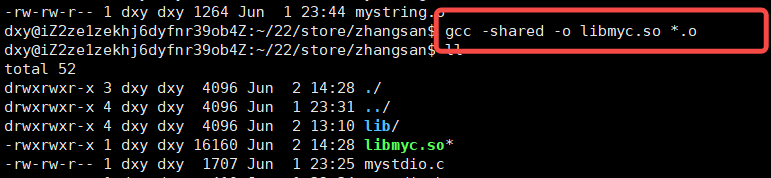
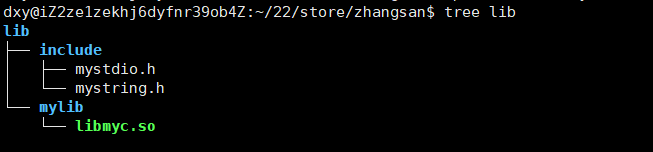
此时我们像使用静态库的时候,使用动态库形成可执行文件,可以通过但是运行的时候,却不行,
ldd 查看原因系统并不知道这个动态库
解决方法:就是让系统知道有这个动态库
有四种:
1.拷⻉ .so ⽂件到系统共享库路径下, ⼀般指 /usr/lib、/usr/local/lib、/lib64
2.向系统共享库路径下建⽴同名软连接
3.更改环境变量: LD_LIBRARY_PATH
4.ldconfig⽅案:配置/ etc/ld.so.conf.d/ ,ldconfig更新

3.ELF文件
1.可重定位文件(Relocatable File):即xxx.0文件。包含适合于与其他目标文件链接来创建可执行件或者共享目标文件的代码和数据。
2.可执行文件(Executable File):即可执行程序。
3.共享目标文件(Shared 0bject File):即xxx.So文件。
4.内核转储(core dumps),存放当前进程的执行上下文,用于dump信号触发。
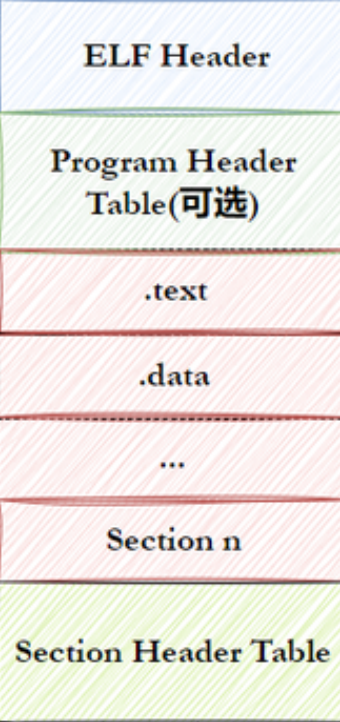
一个FLF文件有下面四个组成部分:
1.ELF头(ELF header):描述文件的主要特性。其位于文件的开始位置,它的主要目的是定位文件的其他部分。
2.程序头表(Program header table):2列举了所有有效的段(segments)和他们的属性。表里记着每个段的开始的位置和位移(offset)、长度,毕竟这些段,都是紧密的放在二进制文件中,需要段表的描述信息,才能把他们每个段分割开。
3.节头表(Section header table):包含对节(sections)的描述。
4.节(Section):ELF文件中的基本组成单位,包含了特定类型的数据。ELF文件的各种信息和数据都存储在不同的节中,如代码节存储了可执行代码,数据节存储了全局变量和静态数据等。
最常见的节
代码节(.text):用于保存机器指令,是程序的主要执行部分。
数据节(.data):保存已初始化的全局变量和局部静态变量。
3.1.ELF文件形成可执行
分两步:
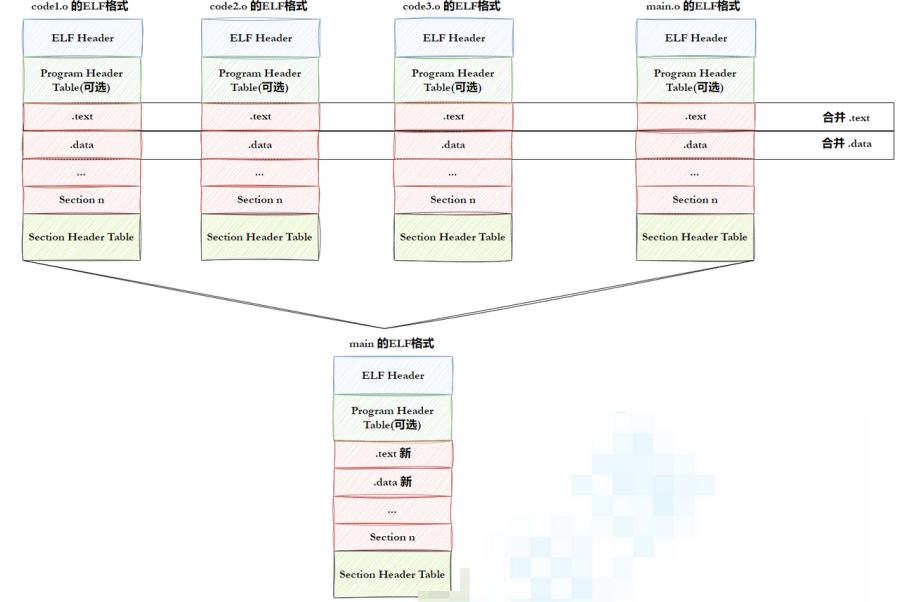
step-1:将多份C/C++ 源代码,翻译成为目标.o 文件
step-2:将多份.o文件section进行合并
3.2.ELF文件可执行加载
一个ELF会有多种不同的Section,在加载到内存的时候,也会进行Section合并,形成segment合并原则:相同属性,比如:可读,可写,可执行,需要加载时申请空间等.
这样,即便是不同的Section,在加载到内存中,可能会以segment的形式,加载到一起很显然,这个合并工作也已经在形成ELF的时候,合并方式已经确定了,具体合并原则被记录在了ELF的 程序头表(Program header table)
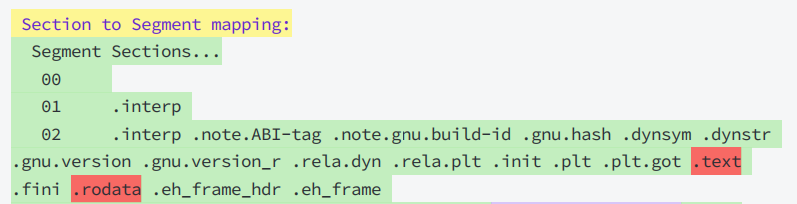
为什么要将section合并成为segment?
1.Section合并的主要原因是为了减少页面碎片,提高内存使用效率。如果不进行合并假设页面大小为4096字节内存块基本大小,加载,管理的基本单位),如果.text部分为4097字节,.init部分为512字节,那么它们将占用3个页面,而合并后,它们只需2个页面。
2.此外,操作系统在加载程序时,会将具有相同属性的section合并成一个大的segment,这样就可以实现不同的访问权限,从而优化内存管理和权限访问控制
对于 程序头表 和 节头表 又有什么用呢,其实 ELF 文件提供2个不同的视图/视角来让我们理解这
两个部分
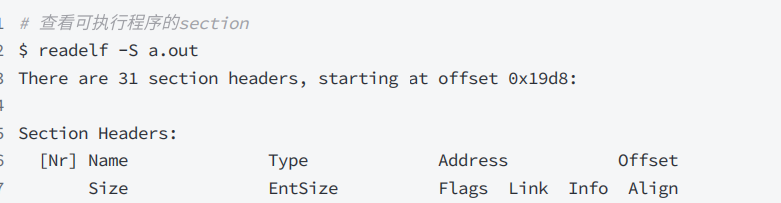
命令 readelf -s hello.o 可以帮助査看ELF文件的 节头表。
1.text节 :是保存了程序代码指令的代码节。
2..data节:保存了初始化的全局变量和局部静态变量等数据。
3..rodata节:保存了只读的数据,如一行C语言代码中的字符串。由于.rodata节是只读的,所以只能存在于一个可执行文件的只读段中。因此,只能是在text段(不是data段)中找到.rodata节。
3.BSS节:为未初始化的全局变量和局部静态变量预留位置
4..symtab节:SymbolTable 符号表,就是源码里面那些函数名、变量名和代码的对应关系。
5.got.plt节 (全局偏移表-过程链接表):.got节保存了全局偏移表。
..6got节和.plt节一起提供了对导入的共享库函数的访问入口,由动态链接器在运行时进行修改。对于GOT的理解
2.执⾏视图(execution view) - 对应程序头表 Program header table
4.理解连接与加载
4.1.静态链接
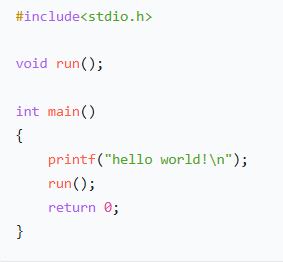
假设此时有这样的两段代码:
run调用printf

main调用 run()和printf()
此时查看它们的汇编代码
objdump -d code.o![]()
现象是:它们的位置都被置为了0,hello.o 中的 main 函数不认识 printf和run 函数,code.o 不认识 printf 函数


原因:
4.2.静态加载

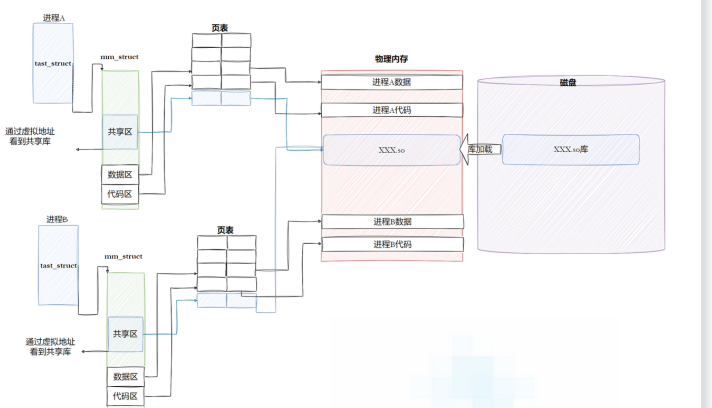
4.3.动态链接和加载
动态库就不是像静态库一样需要把自己和其他,o文件共同进行链接,动态库其实是放在一个叫做共享区的地方,当需要调用的使用再去共享区里进行寻找