Adapting Vision-Language Models Without Labels A Comprehensive Survey
Adapting Vision-Language Models Without Labels: A Comprehensive Survey
Authors: Hao Dong, Lijun Sheng, Jian Liang, Ran He, Eleni Chatzi, Olga Fink
Deep-Dive Summary:
视觉-语言模型的无标签适应:无标签适应的全面综述
作者:Hao Dong*, Lijun Sheng*, Jian Liang’, Ran He, Eleni Chatzi, Olga Fink
摘要:视觉-语言模型(VLMs)在广泛的任务中展示了卓越的泛化能力。然而,当直接应用于特定的下游场景而没有进行任务特定的适应时,其性能往往不够理想。为了在保持数据效率的同时提升其实用性,近期研究越来越多地关注不需要标注数据的无监督适应方法。尽管该领域的研究兴趣日益增长,但仍缺乏一个统一的、以任务为导向的关于无监督VLM适应的综述。为了填补这一空白,我们提供了该领域的全面且结构化的概述。我们提出了一种基于无标签视觉数据的可用性和性质的分类法,将现有方法分为四个关键范式:无数据迁移(无数据)、无监督域迁移(丰富数据)、 episodic测试时适应(批量数据)和在线测试时适应(流式数据)。在这一框架内,我们分析了每个范式相关的核心方法和适应策略,旨在建立对该领域的系统性理解。此外,我们回顾了跨多样化应用的代表性基准,并强调了未来的开放挑战和有前景的研究方向。相关文献的活跃维护仓库可在以下链接获取:https://github.com/tim-learn/Awesome-LabelFree-VLMs。
索引词:无监督学习,测试时适应,多模态学习,视觉-语言模型。
I. 引言
视觉-语言模型(VLMs),如 CLIP [1]、ALIGN [2]、Flamingo [3] 和 LLaVA [4],因其强大的跨模态推理能力而受到学术界和工业界的广泛关注。这些模型从大规模数据集中学习图像-文本联合表示 [5],并在多种任务中展示了令人印象深刻的零样本性能和泛化能力。VLMs 已被成功应用于多个领域,包括自动驾驶 [6]、机器人技术 [7]、异常检测 [8] 和跨模态检索 [9]。
然而,由于预训练阶段无法完全捕捉下游任务和环境的多样性,将 VLMs 适应于特定应用仍然是一个基本挑战。早期的努力主要依赖于有监督微调 [10]-[13],通过标注样本探索更多知识。尽管这些方法有效,但它们仍然面临高昂的标注成本以及训练和测试数据分布偏移导致的性能下降问题 [14]。为了解决这些限制,越来越多的研究探索了无监督适应技术 [15]-[20]。这些方法——通常被称为零样本推理 [21]-[23]、测试时方法 [18], [24], [25] 或无监督调优 [17], [26], [27]——旨在在不依赖昂贵标注的情况下提升 VLMs 在下游任务中的性能。这些方法在图像分类 [15], [17], [18]、分割 [16], [28], [29]、医学图像诊断 [30], [31] 和动作识别 [32], [33] 等广泛应用中已被证明有效。
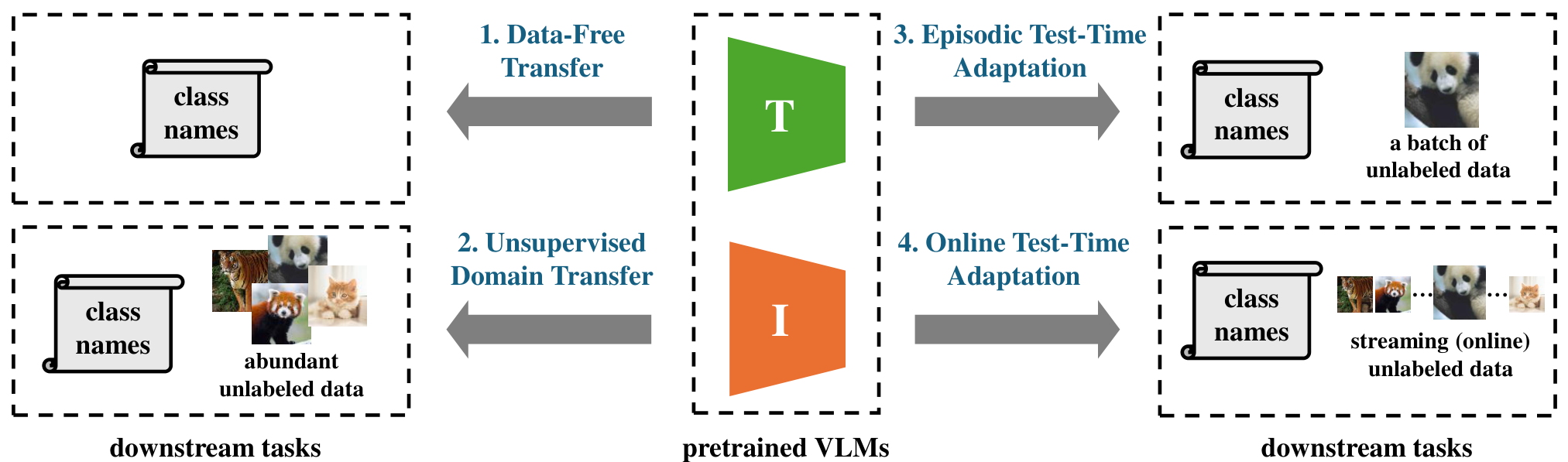
鉴于该研究领域的快速发展,本综述提供了对现有 VLMs 无监督适应方法的全面且结构化的概述。据我们所知,我们首次引入了一个以无标签视觉数据可用性为中心的分类法——这是一个在现实世界部署中常被忽视但至关重要的因素。如图 1 所示,我们将现有方法分为四种范式:(1) 无数据转移 [15], [16], [21],仅使用文本类别名称适应模型;(2) 无监督域转移 [17], [34], [35],利用下游任务中的大量无标签数据;(3) 阶段性测试时适应 [18], [24], [36],将模型适应于一批测试实例;(4) 在线测试时适应 [19], [23], [25],解决流式测试数据的挑战。这一分类法为理解无监督 VLM 适应的格局提供了原则性框架,指导从业者选择合适的技术。我们也相信我们的分类法将有助于在同一范式内进行未来工作的公平比较。
本综述的组织结构如图 2 所示。第 II 节概述了与 VLMs 无监督学习相关的几个研究主题。第 III 节介绍了 VLMs 的零样本推理,并基于无标签视觉数据的可用性提出了全面的分类法。本综述的重点在第 IV 节至第 VII 节,分别分析了无数据转移、无监督域转移、阶段性测试时适应和在线测试时适应中的现有方法。第 VIII 节探讨了利用无监督技术的多种应用场景,并介绍了相关基准测试,从更广泛的视角展示了其实践意义和现实世界的效用。最后,我们在第 IX 节总结了该领域的新兴趋势,并确定了可能启发未来工作的关键科学问题。
与以往综述的比较。近年来,几篇综述 [37]-[40] 探讨了 VLMs 无监督适应和微调的各个方面。现有工作 [40]-[42] 主要关注单模态模型转移,对该领域进行了深入分析,但对 VLMs 的覆盖有限。早期工作 [37] 讨论了 VLMs 的预训练阶段,并简要分析了其针对视觉任务的微调方法。另一篇综述 [38] 讨论了多模态模型的适应和泛化,但粒度较粗。近期工作 [39] 使用泛化来理解 VLMs 的下游任务,并从参数空间的视角回顾了现有方法。尽管这些综述提供了有价值的见解,但我们的工作通过首次引入基于无标签视觉数据可用性的分类法,并分析每个范式中的尖端技术而独树一帜。我们认为这是对该领域的一个新颖且重要的贡献,特别是在 VLMs 部署方面。
E. 传统测试时适应
测试时适应(Test-Time Adaptation, TTA)专注于在线调整预训练的源模型以应对分布变化,而无需访问源数据或目标标签。在线TTA方法[79]、[80]利用无监督目标,通过传入的测试样本更新特定模型参数。此类方法[81]、[82]处理具有挑战性的现实世界场景,包括标签偏移、单样本适应和混合域偏移。同时,持续性TTA方法[83]、[84]处理随时间遇到的不断演变的分布变化,这在动态现实世界应用中尤为相关。尽管大多数传统TTA方法是为纯视觉架构引入的,但其核心机制,如熵最小化和伪标签,已被重新用于视觉语言模型(VLMs)的TTA[18]、[24]、[85]。有关测试时适应的全面综述,我们建议读者参考最近的调查论文[40]、[41]。
HI. 预备知识
视觉-语言模型 (VLMs)
视觉-语言模型 (VLMs) 通常由一个图像编码器和一个文本编码器组成。图像编码器将高维图像映射到一个低维嵌入空间,而文本编码器则从自然语言生成文本表示。自从 CLIP [1] 模型推出以来,许多改进模型被提出,包括 ALIGN [2]、EVA-CLIP [86] 和 SigLIP [87],其中 CLIP 仍然是现有工作中使用最广泛的模型。CLIP 在 4 亿个图像-文本对上进行训练,通过对比损失来对齐图像和文本嵌入。在训练过程中,对于一批图像-文本对,CLIP 最大化匹配对的余弦相似度,同时最小化不匹配对的相似度。在推理阶段,目标数据集的类别名称通过文本编码器嵌入,使用的提示形式为“a photo of a [CLASS]”,其中 [CLASS] 被替换为具体的类别名称(例如,cat、dog、car)。文本编码器随后为每个类别 ccc 生成文本嵌入 tct_ctc,对于输入图像 xxx 及其嵌入 fxf_xfx,预测概率计算如下:
KaTeX parse error: Expected '\right', got 'EOF' at position 301: …t)\big/T\right)}̲\,,
其中 cos(⋅,⋅)cos(\cdot,\cdot)cos(⋅,⋅) 表示余弦相似度,TTT 是一个温度参数。
提示调优 (Prompt Tuning)
与依赖手动设计的提示不同,提示调优方法通过优化提示来提升下游任务的性能。具体来说,提示调优在嵌入空间中进行,其中 MMM 是令牌数量,ddd 是嵌入大小。给定下游任务的训练数据 Dtrain={(xi,yi)}D_{train} = \{(x_i, y_i)\}Dtrain={(xi,yi)},目标是生成形式为 [V]1[V]2…[V]m[CLASS] 的文本输入,为模型提供最相关的上下文信息。对于使用交叉熵损失 CECECE 的图像分类任务,该优化问题可以表示为:
KaTeX parse error: Undefined control sequence: \* at position 50: …iptsize{\small{\̲*̲}}}}}=\arg\math…
分类体系 (Taxonomy)
在本综述中,我们提出了一个分类体系,系统地根据适配过程中是否可以使用无标签视觉数据来分类无监督 VLM 适配方法(见图 1)。该框架定义了四种不同的适配范式,每种范式都有独特的假设和挑战。第一种是无数据迁移(data-free transfer),这是最受限的设置,其中下游任务的视觉数据不可用。相比之下,无监督域迁移(unsupervised domain transfer)假设可以访问大量静态的无标签目标数据,从而在推理前进行更全面的离线适配。最后两种类别涉及测试阶段本身的适配。 episodic 测试时适配(episodic test-time adaptation)针对小批量测试实例进行模型适配,而在线测试时适配(on-line test-time adaptation)则处理最具动态性的场景,模型必须从连续的数据流中不断学习并实时更新自己。这一分类体系突出了无监督 VLM 适配在数据访问、计算限制和算法设计方面的根本差异。在接下来的章节中,我们将详细概述每种范式内的现有方法。
IV. 数据无关迁移
范式描述:在视觉语言模型(VLMs)的背景下,数据无关迁移指的是在没有下游任务的任何视觉数据(例如图像)的情况下,将预训练模型适应到下游任务中。这种设置尤其具有挑战性,因为它完全依赖于文本类别名称来指导适应过程。因此,数据无关迁移被认为是无监督VLM适应中最困难的范式。尽管存在这些困难,为此设置开发的方法往往具有很高的泛化性和广泛的适用性,为视觉数据稀缺、敏感或不可用的跨领域无监督任务提供了鲁棒的解决方案。
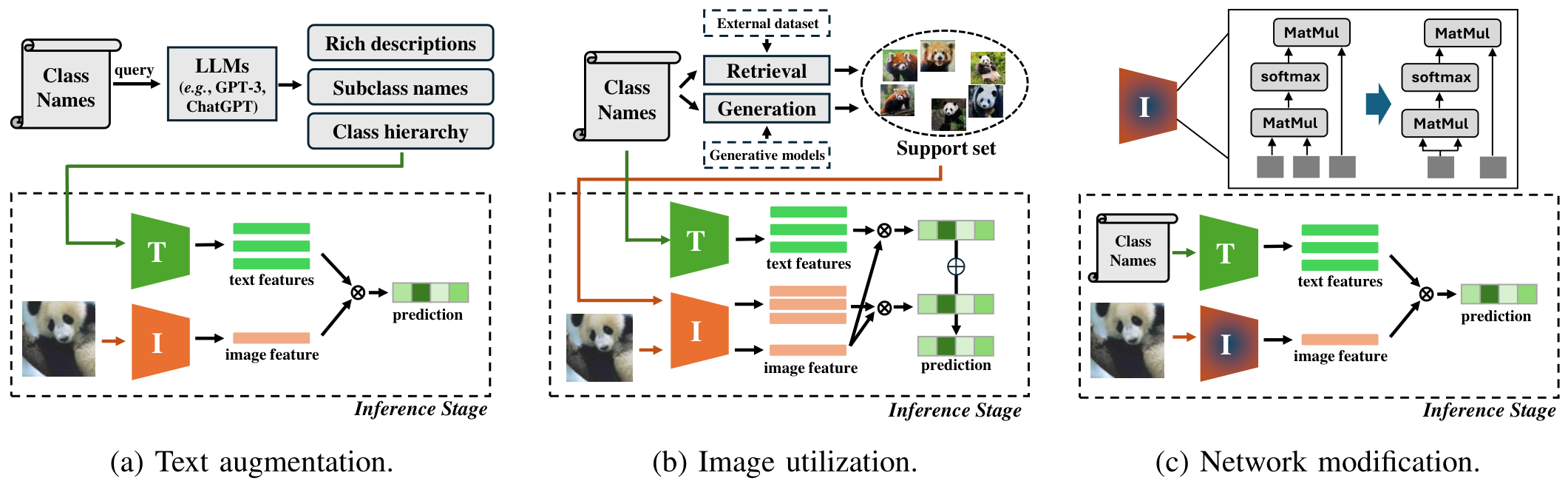
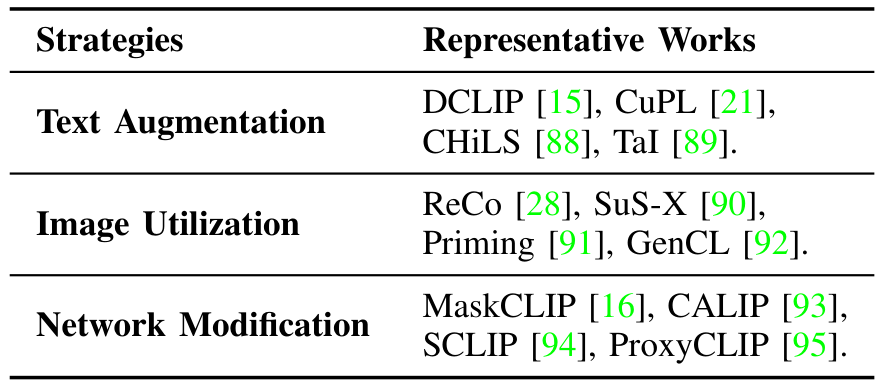
我们回顾了现有的数据无关迁移方法,并将其分为文本增强、图像利用和网络修改三大类。这些类别在表I中进行了总结,我们将在接下来的小节中详细介绍每种策略及其相关方法。
A. 文本增强
在无数据迁移范式中,仅有类别名称可用,直接推断会导致文本编码器的丰富语义能力未被充分利用。为了缓解这一限制,已提出了几种通过文本增强来增强文本输入的方法,旨在生成更具信息量的表示,如图 3 (a) 所示。这些增强的文本有助于挖掘文本编码器的潜在知识,从而在缺乏视觉数据的情况下提升模型性能。
利用大型语言模型(LLMs)如 GPT-3 [96] 的强大能力,几种无数据迁移方法 [15], [21], [97] 采用了文本增强策略,通过更具信息量和区分性的描述来丰富类别表示。这些方法旨在用更丰富的文本内容替换简单的类别名称,从而改善与视觉概念的对齐。例如,DCLIP [15] 和 CuPL [21] 使用 GPT-3 生成多个语义描述符和完整的描述性句子,将区分性知识注入类别表示中。REAL-Prompt [98] 识别出在预训练语料库中低频术语的类别性能下降,并通过提示 ChatGPT [99] 将其替换为编码器更熟悉的高频同义词来解决这一问题。MPVR [97] 引入了两步提示机制,首先由 LLMs 生成与任务相关的查询,然后用于推导出类别特定的提示,提升相关性和多样性。在医学图像诊断等特定领域应用中,ChatGPT [99] 被用来生成基于症状的疾病类别描述 [31]。此外,Parashar 等人 [100] 表明,将科学物种名称替换为常见英文术语可以提高分类性能。有趣的是,对 LLMs 的依赖并非绝对必要。WaffleCLIP [101] 证明,即使对类别名称进行随机词增强,也能获得与使用 LLMs 生成的结果相当的效果。在一个互补的方向上,TAG [102] 提出了一种基于排列提示模板的评分机制的分布外(OOD)检测方法。该评分捕捉了模型在不同措辞下的预测一致性,从而实现更准确的检测。
拓展这一研究方向,现有研究 [32], [88], [103], [104] 还探索了使用子类名称作为丰富文本描述的替代方法,旨在更精确地描述每个类别的语义范围。CHiLS [88] 利用 GPT-3 [96] 为每个原始类别生成子类名称,并通过聚合图像与超类及其相关子类之间的相似性进行最终预测。在语义分割的背景下,子类提示允许与目标超类进行更细粒度的补丁级对齐,从而显著提升性能 [103]。对于基于视频的动作识别,TEAR [32] 将复杂动作分解为多个子动作,为每个子动作生成简洁描述,并通过平均其特征形成鲁棒的复合表示。除了子分类外,其他方法通过与类别相关的属性来丰富语义理解,帮助捕捉细微的类内变化并提高图像识别精度 [104]。此外,EOE [105] 将这一策略扩展到 OOD 检测,通过提示 LLMs 生成潜在的 OOD 类别名称,从而扩展模型超出训练分布的识别能力。
与其对所有可能的类别进行对象分类,一些方法 [106]-[108] 通过将类别组织成簇或层次结构来简化任务,将复杂的分类问题分解为一系列层次子任务。早期工作 [106] 构建了候选类别的层次簇,并使用 ChatGPT [99] 生成特定组的区分性文本描述。最近,Lee 等人 [107] 利用文本特征相似性识别语义相似的类别,然后提示 LLM 生成视觉描述符,以区分一个类别与其最近的语义邻居。除了准确性之外,HAPrompts [108] 引入了一个层次分类框架,鼓励模型在发生误分类时预测语义相关的标签,从而促进更好的错误。
另一类无数据迁移方法 [89], [109], [110] 利用外部文本数据作为训练信号,引导模型实现更鲁棒的任务性能。例如,TaI [89] 用丰富的文本描述替代标注图像进行提示调整,引入了捕捉全局语义上下文和局部区分特征的双粒度提示。在相关方法中,TAP [109] 构建类别特定的文本描述,并使用交叉熵损失训练纯文本分类器。然后在推理时将该分类器与视觉编码器集成以提高识别精度。更进一步,ProText [110] 优化深度提示参数,引导文本编码器从 LLM 生成的描述中提取有意义的表示,这些描述嵌入了广泛的语言知识和细粒度的概念区分。
B. 图像利用
在缺乏视觉数据的情况下,单纯依赖文本信息的方法面临固有的局限性,这主要是由于视觉语言模型(VLMs)中存在的模态差距。为了弥合这一差距,越来越多的研究(如 [28]、[91]、[111])通过从外部数据集中检索相关图像或使用生成模型合成图像来引入视觉信号,如图 3 (b) 所示。
基于检索的方法试图通过利用大规模未标记数据集提供视觉 grounding。例如,ReCo [28] 使用 CLIP [1] 从外部语料库中检索语义相关的图像,并为每个类别计算参考图像嵌入。然后,这种嵌入被用来指导相应图像 patch 的识别,并优化原始的零样本密集预测。Neural Priming [91] 通过从预训练数据集中为每个类别计算检索图像集的中心点,引入一个新的分类头,随后将该头与原始零样本分类器整合以增强识别能力。生成方法通过合成视觉数据来模拟下游任务的示例,进一步扩展了这一方向。例如,Shipard 等人 [111] 使用扩散模型 [49] 构建了一个合成训练集,生成一组多样化的图像,在缺乏真实数据的情况下提供丰富的视觉线索。AttrSyn [112] 通过利用大型语言模型(LLMs)生成广泛的属性,进一步提升图像多样性,这些属性指导生成模型产生类别一致且具有区分性的样本。SuS-X [90] 结合了检索和生成策略,通过引入视觉支持集(该支持集可以从大规模数据集中构建或通过先进的扩散模型 [49] 生成),实现信息整合并在推理过程中提供辅助监督。最后,在持续学习的背景下,GenCL [92] 使用基于提示的扩散模型为新类别生成合成图像,然后引入基于集成的选择器从生成的样本中筛选出具有代表性的核心集,以支持随时间推移的稳健且有效的类别表示。
C. 网络修改
许多无数据方法(如 [16]、[29]、[93]、[113])专注于修改视觉语言模型(VLMs)的网络架构,以增强其对下游任务的适应性,特别是密集预测任务,如分割,如图 3 © 所示。尽管这些方法主要针对分类导向的 VLMs 开发,但其架构改进显著提升了密集预测性能。
一项开创性工作 MaskCLIP [16] 表明,最终注意力层中的值嵌入(value embeddings)比全局特征捕获了更丰富的局部信息,因此在分割任务中尤为有效。为了进一步优化值嵌入的密集预测,MaskCLIP 引入了基于键的平滑策略和去噪技术。在此基础上,CALIP [93] 通过一个无参数的注意力模块促进视觉和文本特征之间的交互,并通过集成多个特征表示的输出实现更好的分类结果。CLIP Surgery [114] 通过引入值-值注意力机制来增强局部特征一致性,并采用特征手术策略抑制噪声激活,从而提高分割精度和可解释性。GEM [115] 将值-值注意力泛化为任意-任意注意力机制,通过对每一 transformer 层的键、查询和值嵌入应用修改后的注意力机制,增强相似 token 组之间的一致性,并集成输出结果。SCLIP [94] 引入了相关自注意力机制,生成空间协变的特征,从而更好地保留精细的局部细节。最后,ProxyCLIP [95] 提出了一种无需训练的框架,通过整合来自视觉基础模型(如 DINO [116] 和 SAM [117])生成的空间一致性代理注意力图,增强了 CLIP 的开放词汇分割能力。
V. 无监督域迁移
范式描述:VLMs 的无监督域迁移指的是将预训练模型适应到具有大量未标记数据的下游任务中。与无数据迁移相比,无监督域迁移可以利用下游任务的未标记数据更好地掌握数据分布,从而实现更好的性能。该范式的挑战主要来自于未标记数据的过滤和处理,以及 VLM 与未标记数据的无监督对齐。
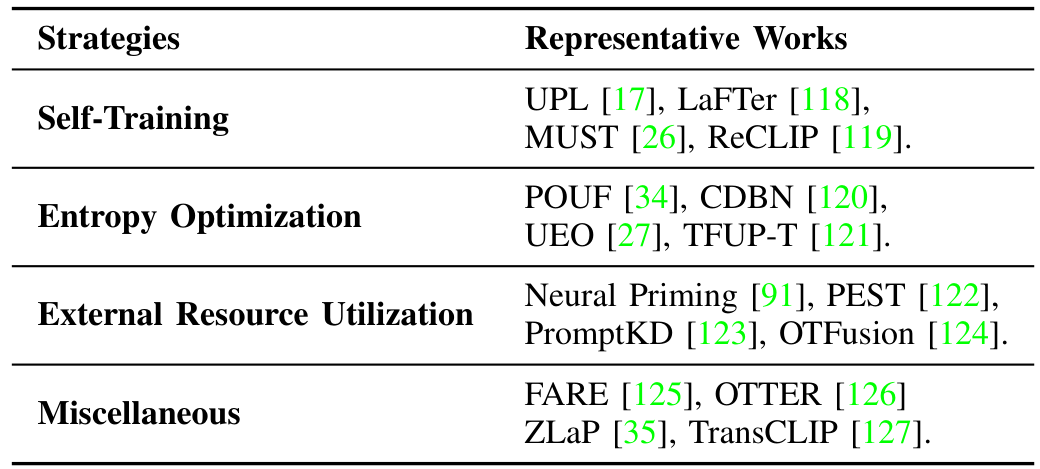
我们回顾了现有的无监督域迁移方法,并将其策略分为三大主要方法:自训练、熵优化和外部资源利用。这些类别总结于表 II 中,我们将在以下小节中详细介绍每种策略及相关方法。
A. 自训练(Self-Training)
自训练是一种在无监督学习中广泛使用的策略,如图4(a)所示,在这种情况下,训练数据的真实标签是缺失的。使用这种方法,无监督算法通常设法在未标记样本上计算高质量的伪标签作为监督信号。如何获取并迭代优化伪标签,使视觉语言模型(VLM)更好地适应未标记数据的分布,是这些方法面临的关键挑战。
UPL [17] 是最早探索VLM无监督域迁移的努力之一。它为每个类别选择一小组高置信度的未标记样本,并优化以下目标:
ΔΓ⊙ΘΠΠΠˉ(x,y^)∼DselectZCE(P(x),Y^),\Delta\Gamma_{\odot}^{\Theta}\,\Pi\Pi\,\bar{\Pi}(\mathrm{x},\hat{y})\sim\mathcal{D}_{\mathrm{select}}\mathcal{Z}C E\left(\mathcal{P}(\mathrm{x}),\hat{\mathcal{Y}}\right), ΔΓ⊙ΘΠΠΠˉ(x,y^)∼DselectZCE(P(x),Y^),
其中 DselectD_{select}Dselect 表示选定的高置信度样本,LCEL_{CE}LCE 表示交叉熵损失。这种选择性伪标签方法随后被许多后续工作所采用 [19], [120], [128], [129]。SwapPrompt [19] 通过另一种交换预测机制扩展了自训练策略,让同一图像的两个增强视图通过EMA更新的提示为彼此提供软伪标签优化监督。RS-CLIP [130] 引入了一个课程学习框架,从一小组高置信度样本开始自训练,并随着优化的进行逐步纳入更多数据,从而减轻早期伪标签噪声的影响。GTA-CLIP [131] 提出了一种归纳推理方法来进行伪标签标注,通过迭代优化的、属性增强的图像和文本嵌入相似性来提高标签质量。在相关方法中,CPL [132] 通过引入实例内和实例间标签来优化候选伪标签,以减少VLM通常产生的错误硬伪标签的负面影响。另一项工作 [133] 系统地研究了多种无监督设置下的伪标签策略,并展示了伪标签在促进跨类别更平衡和稳健的性能方面的有效性。
受 FixMatch [134] 的启发,一些无监督域迁移方法 [118], [120] 对未标记数据应用弱增强和强增强,以增强VLM中的一致性学习。这些方法通常使用弱增强视图生成伪标签,并将其作为强增强视图上自训练的监督信号。LaFTer [118] 利用大型语言模型(LLMs)生成多样化的文本数据来训练文本分类器,进而为弱增强视图生成高质量伪标签以进行有效的自训练。MedUnA [30] 提出了一种双分支架构,包括视觉编码器的弱分支和强分支,并使用伪标签目标联合优化它们,以增强医学图像分类。NoLA [129] 使用基于DINO的标签网络,输入弱增强数据以提高伪标签质量,用于训练视觉提示。DPA [135] 引入了视觉和文本分支的双原型表示,整合其输出以生成更稳健的伪标签。此外,LP-CLIP [136] 将置信度估计纳入伪标签目标,从而提高分类准确性和校准。一些方法不是通过筛选高置信度样本和增强不同增强之间的一致性来生成伪标签,而是以其他方式生成伪标签。MUST [26] 维护一个EMA模型以生成高质量伪标签,并结合掩码图像建模策略来改进局部图像表示学习。PEST [122] 通过集成多个文本提示和视觉增强视图的预测来增强伪标签质量。ReCLIP [119] 学习一个投影空间以更好地对齐视觉和文本特征,并通过使用标签传播 [137] 优化的伪标签进行自训练。NtUA [138] 构建了一个基于置信度加权的伪标签特征键值缓存,并通过知识蒸馏进行优化,有效缓解了未标记数据有限场景下的标签噪声。类似地,TFUP-T [121] 通过构建包含代表性样本的缓存模型,并基于特征级别和语义级别的相似性优化预测来提高伪标签质量。为了解决低置信度伪标签的问题,FST-CBDG [139] 在自训练期间采用了软监督策略。对于回归任务,CLIPPR [22] 使用零样本伪标签训练图像编码器的适配器,通过最小化预测和先验标签分布之间的距离来优化性能。
B. 熵优化
熵优化是一种经典的无监督学习目标,旨在鼓励模型对未标记数据做出自信的预测,如图4(b)所示。与自训练不同,熵优化不受错误伪标签的影响,在低性能任务上表现得更加稳定。许多算法通过最小化样本级熵来适配模型至未标记数据的分布 [34], [120],同时也最大化类别级边缘熵以避免模式崩溃 [34], [120], [121]。
POUF [34] 和 CDBN [120] 通过样本级熵最小化和类别级边缘熵最大化来优化文本提示参数。POUF 还引入了最优传输目标,以更好地对齐文本原型和未标记数据的分布。为了提高视觉语言模型(VLMs)的泛化能力和分布外检测性能,UEO [27] 提出了通用熵的概念,利用边缘预测而非样本预测进行熵最大化,以稳定优化过程。
C. 外部资源利用
近年来,一些方法通过引入超出可用未标记数据的外部资源来增强视觉语言模型(VLMs)的性能。这些资源通常包括基于检索的图像增强、引入(多模态)大型语言模型(MLLMs)以及从强大的视觉语言模型或视觉模型中进行知识蒸馏,如图4©所示。
Neural Priming [91] 采用了一种转导学习范式,通过基于类别名称构建图像检索集。对于每个未标记样本,它选择视觉上最相似的图像组成一个微调数据集,从而使 VLM 适配到目标领域。LaFTer [118] 利用 GPT-3 [96] 生成多样化的文本描述,随后用于训练针对下游任务的文本分类器。类似地,PEST [122] 和 GTA-CLIP [131] 查询如 GPT-3 [96] 和 LLaMA [140] 等大型语言模型,以创建基于多提示集成的提示推理。LatteCLIP [141] 利用 LLaVA [4] 生成图像标题,支持更准确的文本原型构建以适配 VLM。
在知识蒸馏方面,PromptKD [123] 重用来自更大教师 VLM 的文本特征来指导图像编码器的训练,从而转移语义知识。更进一步,KDPL [142] 在视觉和文本输入空间中联合优化提示,平衡性能和效率。NtUA [138] 通过引入更强 VLM 的图像编码器来提高伪标签的可靠性,增强标签质量和置信度估计。OTFusion [124] 通过最优传输将 VLMs 的嵌入与从强大视觉模型(如 DINO)提取的特征对齐,以获得更精细的预测。
D. 其他方法
近年来,有多种方法通过不同的策略解决视觉语言模型(VLMs)的无监督域迁移问题[125], [143]。ZPE [144] 设计了一种提示集成策略,利用未标记数据解决词汇和概念的频率偏差问题,并为多个提示模板分配合适的集成权重。uCAP [145] 将图像生成表述为类别名称和潜在的、特定于域的提示的函数,采用基于能量的似然框架从未标记数据中推断最优提示。为了在保持对干净输入的性能的同时增强对抗鲁棒性,FARE [125] 优化视觉编码器,使对抗扰动图像的特征与原始 VLM 计算的干净图像特征对齐。OTTER [126] 通过利用最优传输来解决标签分布不匹配问题,将模型预测与目标域中估计的标签分布对齐。此外,InMaP [146] 使用从文本嵌入中提炼的伪标签直接在视觉空间中学习类别代理,从而缩小 VLMs 中视觉和文本表示之间的模态差距。后续方法利用多种策略对视觉-文本特征建模,包括标签传播 [35] 和 Dirichlet 分布 [147]。TransCLIP [127] 提出了一种即插即用的转导框架,通过高效的块主化-最小化算法优化 KL 正则化目标,整合文本编码器的知识。
VI. episodically 测试时适应
范式描述:episodically 测试时适应是一种流行的学习范式,其中预训练的 VLM 在推理时使用单个批次的未标记测试数据进行适应。其目标是利用预训练 VLM 中嵌入的知识准确预测当前批次的标签,而无需在适应过程中访问多个测试批次或标记数据。
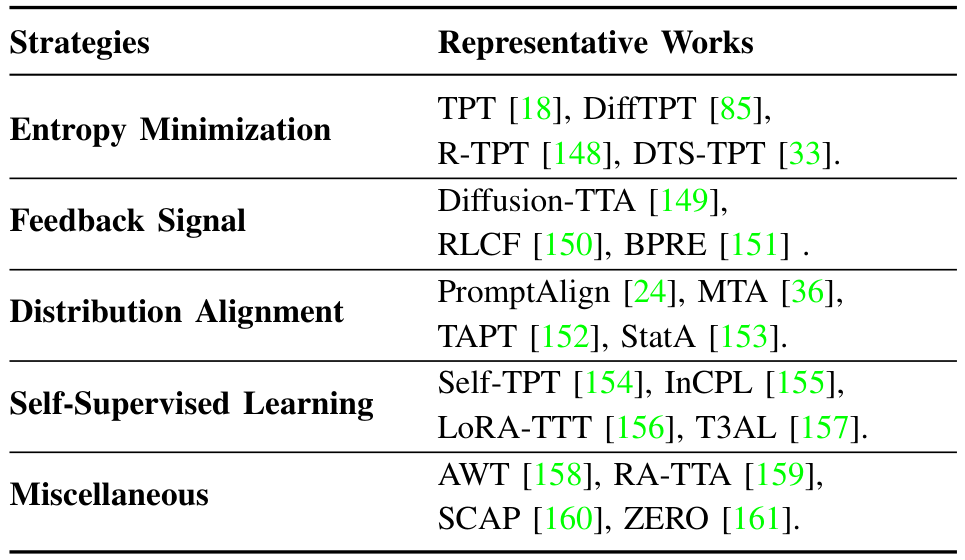
我们回顾了现有的 episodically 测试时适应方法,并将其策略分为四种主要方法:熵最小化、反馈信号、分布对齐和自监督学习。这些类别总结在表 IHI 中,我们将在以下小节中详细介绍每种策略及相关方法。
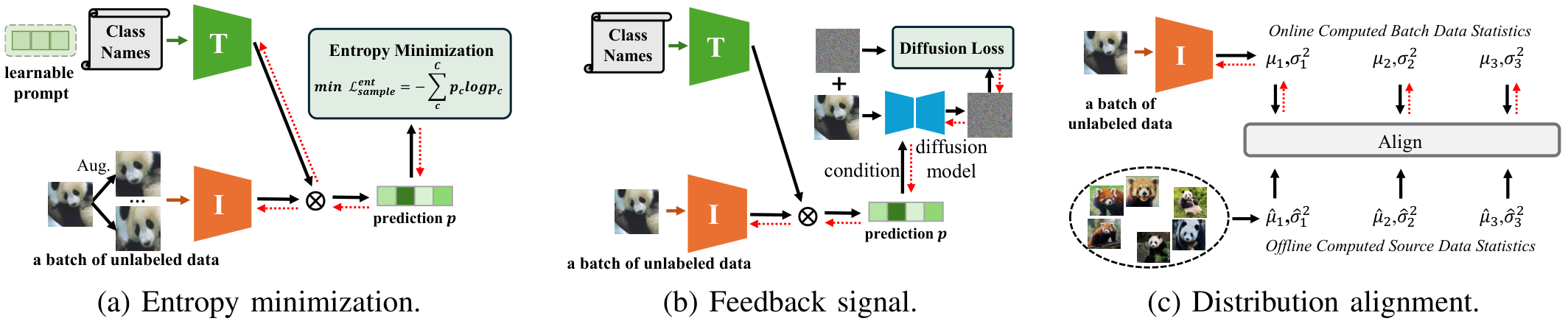
A. 熵最小化
熵最小化是一种广泛采用的测试时适应(TTA)策略 [40],通过调整模型参数使输出预测更加自信,熵值更低,如图5(a)所示。这一过程鼓励模型对测试数据产生低不确定性的输出,通常在分布偏移的情况下提升模型性能。
舒等人 [18] 提出了测试时提示调整(TPT),这是首个在测试时适应预训练视觉语言模型(VLM)的方法。TPT 通过熵最小化优化每个测试样本的文本提示 p=[V]1[V]2...[V]mp = [V]_1[V]_2...[V]_mp=[V]1[V]2...[V]m,并结合置信度选择来确保跨增强视图的预测一致性。具体来说,TPT 使用一组随机增强方法 AAA 为测试图像 xxx 生成 NNN 个随机增强视图,并最小化平均预测概率分布的熵:
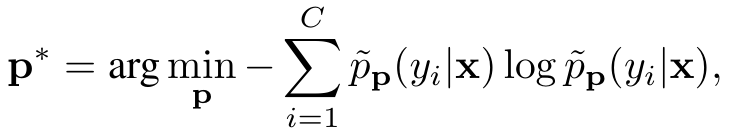
p~p(yi∣x)=1ρN∑i=1N∣Π(pi)≤η∣pp(y∣Ai(x)).\tilde{p}_{\bf p}(y_{i}|{\bf x})=\frac{1}{\rho N}\sum_{i=1}^{N}\vert\Pi(\cal{p}_{i})\leq\eta\vert p_{\bf p}(y|\mathcal{A}_{i}({\bf x})). p~p(yi∣x)=ρN1i=1∑N∣Π(pi)≤η∣pp(y∣Ai(x)).
这里,pp(y∣Ai(x))p_{\bf p}(y|\mathcal{A}_i({\bf x}))pp(y∣Ai(x)) 表示在提示 ppp 下,xxx 的第 iii 个增强视图的类别概率向量。TPT 选择预测熵低于阈值 η\etaη 的 ppp-百分位自信样本,通过置信度掩码 Π[H(pi)≤η]\Pi[H(p_i) \leq \eta]Π[H(pi)≤η] 过滤掉噪声预测,其中 HHH 表示增强样本预测的熵。与 TPT 不同,DiffTPT [85], [162] 利用预训练扩散模型生成多样化的增强,并采用基于余弦相似度的过滤方法去除伪样本。R-TPT [148] 采用基于可靠性的加权集成策略,聚合测试样本可信增强视图的信息。C-TPT [163] 通过最大化文本特征分散来优化提示,观察到更好的校准预测与更高的文本特征分散相关。O-TPT [164] 通过在调整过程中对类别特定的文本提示特征施加正交约束,最大化其角度分离,从而改善校准。此外,DTS-TPT [33] 将 TPT 扩展到视频数据,用于零样本活动识别。
除了通过调整文本提示来最小化熵,一些研究还探索了视觉提示 [165]、多模态提示 [24]、低秩注意力权重 [166] 和可学习噪声 [167]。例如,PromptAlign [24] 使用多模态提示学习,将预计算的源代理数据集与测试样本之间的图像 token 分布对齐。TTL [166] 在测试时通过置信度最大化目标调整低秩注意力权重,实现高效适应,而无需更改提示或骨干参数。
B. 反馈信号
一些研究探索了利用扩散模型 [149] 或类似 CLIP 的模型 [150]、[151] 的反馈信号来进行测试时适应(TTA),如图 5(b) 所示。例如,Diffusion-TTA [149] 利用扩散模型的生成反馈,在测试时通过优化图像似然来适应预训练的判别模型,显著提升了分类、分割和深度预测等任务的性能。Diffusion-TTA 包括判别模块和生成模块。给定图像 xxx,判别模型 fof_ofo 预测任务输出 yyy(对于视觉语言模型(VLMs)见公式 (1))。任务输出 yyy 被转换为条件 ccc。对于图像分类,yyy 表示 CCC 个类别上的概率分布,y∈[0,1]Cy \in [0,1]^Cy∈[0,1]C,且 yT1C=1y^T 1_C = 1yT1C=1。给定文本条件扩散模型为 CCC 个类别学习的文本嵌入 tj∈Rd,j∈{1..C}t_j \in \mathbb{R}^d, j \in \{1..C\}tj∈Rd,j∈{1..C},扩散条件为 c=∑j=1Cyjtjc = \sum_{j=1}^C y_j t_jc=∑j=1Cyjtj,用于测量输入图像在条件 ccc 下的似然。这包括使用扩散模型 eΦe_\PhieΦ 从噪声图像 xtx_txt 和条件 ccc 预测添加的噪声 eee。通过扩散损失最大化图像似然,通过反向传播更新判别和生成模型的权重:
Ddiff=Et,ϵ∥ϵϕ(αˉtx+1−αˉtϵ,c,t)−ϵ∥2,\mathcal{D}_{\mathrm{diff}} = \mathbb{E}_{t,\epsilon} \|\epsilon_{\phi}(\sqrt{\bar{\alpha}_t} x + \sqrt{1 - \bar{\alpha}_t} \epsilon, \mathbf{c}, t) - \epsilon\|^2, Ddiff=Et,ϵ∥ϵϕ(αˉtx+1−αˉtϵ,c,t)−ϵ∥2,
其中 αt\alpha_tαt 定义了每个时间步 ttt 添加的噪声量。不同的是,RLCF [150] 通过强化学习利用基于 CLIP 的反馈,并采用 CLIPScore [168] 作为奖励信号为 VLMs 提供反馈。BPRE [151] 通过基于内在视觉特征的质量感知奖励模块缓解文本条件偏差,形成一个自我进化的反馈循环,并通过原型精炼增强对分布偏移的适应。
分布对齐方法将测试样本分布与已知的源特征对齐或优化表示以提高一致性 [169],如图 5© 所示。例如,PromptAlign [24] 通过联合更新多模态提示,将增强测试视图的每层图像-token 统计与离线计算的源统计对齐,通过组合对齐和熵最小化损失来弥合源到目标的分布差距。为了增强对抗鲁棒性,TAPT [152] 通过使用损失函数在推理时将测试样本的增强视觉嵌入与预计算的干净和对抗扰动图像的统计对齐来进行统计对齐适应。StatA [153] 在适应过程中通过使用统计锚点来保留文本编码器知识,这些锚点会对偏离文本派生的 Gaussian 先验的行为进行惩罚。
作为这些方法的补充,MTA [36] 采用鲁棒的 MeanShift 算法在特征空间中识别密度模式,同时通过内点分数优化它们以自动评估每个视图的质量。除了全局分布对齐外,一些方法专注于类别感知的原型对齐。PromptSync [170] 执行测试样本与源类别原型的类别感知原型对齐,并根据从置信增强视图得出的平均类别概率进行加权。同样利用类别原型,TPS [169] 预计算类别原型,然后对于每个测试样本,在共享嵌入空间中动态学习偏移向量以直接调整这些原型。
D. 自监督学习
自监督学习 [171], [172] 是一种学习可迁移表示的强大技术。Self-TPT [154] 引入了对比提示调整作为一种自监督方法,通过利用对比学习原则,在最小化类内距离的同时最大化类间分离。具体来说,对于每个类别的令牌,通过改变类别令牌的插入位置(例如,提示序列的开始、中间或末尾)生成多个提示变体。这形成了来自同一类别的正样本对和来自不同类别的负样本对,从而鼓励模型学习更鲁棒的类别表示。对比损失函数形式化为:
L=−∑i=14C∣Og∑j∈P(i)exp(ti⋅tjτ)∑j=1,j≠iexp(ti⋅tjτ),\mathcal{L}=-\sum_{i=1}^{4C}|_{\mathrm{Og}}\frac{\sum_{j\in P(i)}\exp\left(\frac{{\bf t}_{i}{\cdot}{\bf t}_{j}}{\tau}\right)}{\sum_{j=1,j\neq i}\exp\left(\frac{{\bf t}_{i}{\cdot}{\bf t}_{j}}{\tau}\right)}, L=−i=1∑4C∣Og∑j=1,j=iexp(τti⋅tj)∑j∈P(i)exp(τti⋅tj),
其中 ttt 和 tjt_jtj 是不同视图的投影文本特征,P(i)P(i)P(i) 表示视图 iii 的正样本集合,τ\tauτ 是一个温度参数。相比之下,LoRA-TTT [156] 仅更新图像编码器中的低秩参数,使用内存高效的重构损失(计算为高置信度增强视图和掩码视图的类别令牌的均方误差),以增强全局特征理解。此外,InCPL [155] 通过上下文感知的无监督损失和循环学习策略,从少量标注样本中优化视觉提示,实现高效的模型适应。T3AL [157] 通过首先从预训练的视觉语言模型(VLM)中获取视频级伪标签,然后使用自监督方法创建初始提案,最后结合帧级文本描述进行优化,生成并细化时间动作提案。
E. 其他方法
除了之前讨论的方法外,还开发了用于视觉语言模型(VLM)情景式测试时适应的其他技术 [173]-[180]。其中一类工作采用基于检索的策略 [159], [181], [182]。例如,X-MoRe [181] 通过两步跨模态检索获取相关标题,并使用动态加权的模态置信度分数对图像和文本预测进行集成。RA-TTA [159] 利用细粒度的文本描述指导两步检索相关外部图像,随后在基于描述的适应过程中优化模型的初始预测。另一类工作致力于改善 VLM 的校准 [161], [163], [164], [183]。除了检索和校准外,其他代表性工作包括最优传输 [158]、虚假特征消除 [184]、损失景观 [185]、反击 [186] 以及支持性小团体 [160]。一些方法专注于提升 CLIP 的密集预测能力,以解决其图像级预训练局限性,应用于开放词汇语义分割 [28], [29], [103], [115], [187]-[189]。外部知识,如多模态大语言模型(MLLMs)和大语言模型(LLMs),也可在推理过程中使用,而无需针对特定任务数据进行额外训练或微调 [190]-[197]。
VII. 在线测试时适应
范式描述:在线测试时适应(Online Test-Time Adaptation, TTA)是另一种针对流式数据场景设计的TTA范式,其中未标记数据以小批量(mini-batch)的形式按顺序到达。给定一个预训练的视觉语言模型(VLM),目标是在线适应模型以适应每个传入的小批量,从而在潜在的分布偏移下准确预测其标签。与每次独立适应每个批量的情景式适应(episodic adaptation)不同,在线适应通过利用从先前观察到的小批量中积累的知识,持续更新模型。这使得在动态的流式环境中能够进行更有效和高效的标签预测。
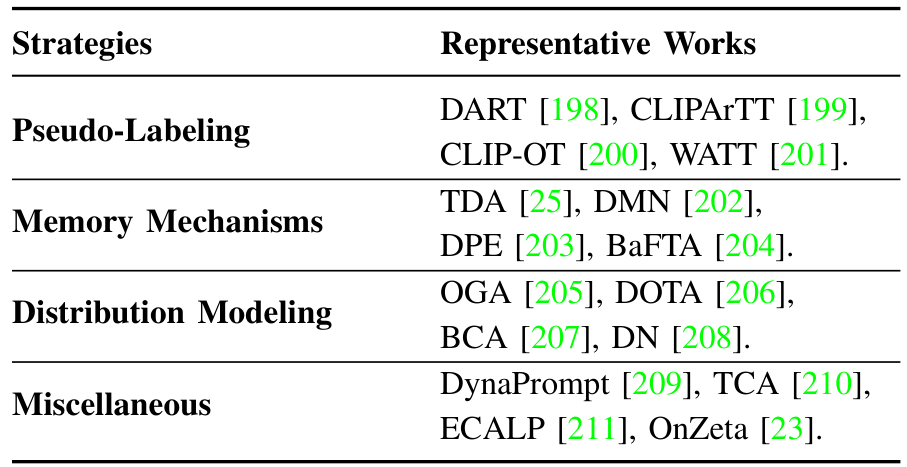
方法综述:我们回顾了现有的在线测试时适应方法,并将其策略分为三大主要方法:伪标签(pseudo-labeling)、记忆机制(memory mechanisms)和分布建模(distribution modeling)。这些类别总结在表IV中,我们将在以下小节中详细介绍每种策略及其相关方法。
A. 伪标签
伪标签方法:伪标签为未标记的测试样本分配类别标签,并通过优化预测和伪标签之间的交叉熵损失来指导模型适应,如图6(a)所示。然而,由于分布偏移,伪标签可能存在噪声,这会对学习产生负面影响。为解决这一问题,提出了多种方法。许多方法改进伪标签过程本身,例如,IST [212] 采用基于图的校正和非极大值抑制进行伪标签细化,并通过参数移动平均稳定更新。其他方法如CLIPArTT [199] 动态构建来自前K个预测类别的文本提示作为伪标签,而CLIP-OT [200] 利用最优传输进行标签分配,同时结合多模板知识蒸馏。CTPT [213] 关注由稳定类别原型和准确伪标签引导的迭代提示更新。SwapPrompt [19] 提出了一种双提示和交换预测机制,以实现高效的提示适应。
增强伪标签的方法:一些方法通过将伪标签与其他机制结合来增强其效果。例如,SCP [214] 使用带有共轭伪标签的自我文本蒸馏来提高鲁棒性并减少过拟合。WATT [201] 结合了多样化的文本模板、基于伪标签的更新与定期权重平均以及文本集成。为了处理噪声目标数据,AdaND [215] 引入了一个自适应噪声检测器,该检测器使用冻结模型的伪标签进行训练,将噪声检测与分类解耦。DART [198] 学习自适应的多模态提示(类别特定的文本和实例级图像),同时保留来自先前测试样本的知识。ROSITA [216] 采用对比学习目标,并动态更新特征库,以增强对分布外(OOD)样本的区分能力。最后,TIPPLE [217] 采用两阶段方法,首先使用在线伪标签结合辅助文本分类任务和多样性正则化进行面向任务的提示学习,然后为每个测试实例调整任务级提示的可调残差。
B. 记忆机制
记忆机制相关方法利用动态或静态记忆结构来存储和检索测试样本的特征表示和伪标签,如图 6 (b) 所示。这些方法通过利用高置信度的输出和历史信息,实现预测的逐步优化,从而在不需要大量重新训练或反向传播的情况下增强鲁棒性和适应性 [218]-[221]。受 Tip-Adapter [222] 的启发,Karmanov 等人 [25] 提出了一种无需训练的动态适配器 (TDA),该方法不需要反向传播。TDA 的核心是一个动态键值缓存系统,用于存储测试样本的伪标签和对应的特征表示。通过利用测试时的高置信度输出,该缓存系统能够逐步优化预测,促进高效适应。类似地,DMN [202] 利用静态记忆存储训练数据知识,并使用动态记忆在线保存测试特征。Boost-Adapter [223] 利用轻量级键值记忆,从实例无关的历史样本和实例感知的增强样本中检索特征。HisTPT [224] 构建了三个互补的知识库——局部、困难样本和全局——以保存之前见过的测试样本中的有用信息。AdaPrompt [225] 引入了一个基于置信度的缓冲区,仅存储和利用类别平衡的高置信度样本,以确保提示更新的鲁棒性和稳定性。
其他研究利用动态演变的类别原型,在推理过程中捕捉准确的多模态表示。通过持续更新来自未标记测试样本的原型,这些方法增强了模型的适应性、鲁棒性和效率 [226], [227]。例如,DPE [203] 同时演变两组原型——文本和视觉——以在测试时逐步捕捉目标类别的准确多模态表示。BaFTA [204] 使用无反向传播的在线聚类来估计类别中心,并通过基于熵的可靠性指导,稳健地聚合类别嵌入与视觉-文本对齐,从而提升零样本性能。BATCLIP [228] 引入了投影匹配损失以改善视觉类别原型与文本特征的对齐,并通过可分离性损失增加原型之间的距离,从而获得更具区分性的特征。
分布建模方法通过对视觉或多模态特征的分布建模(通常使用高斯估计)来优化推理过程中的预测,如图 6 © 所示。通过利用概率框架并结合零样本先验,这些方法在不需要大量超参数调整或反向传播的情况下增强了适应性和鲁棒性。例如,OGA [205] 使用多元高斯分布建模视觉特征的可能性,并在最大后验估计框架中引入零样本先验。类似地,DOTA [206] 估计高斯类别分布以计算基于贝叶斯的后验概率进行适应,实现无需梯度反向传播的快速推理,并引入了人在回路机制来处理不确定样本并提升测试时性能。BCA [207] 持续更新基于文本的类别嵌入以对齐可能性与传入的图像特征,同时使用所得的后验概率优化类别先验。另一方面,DN [208] 使用测试样本的平均表示近似负样本信息,增强与模型优化目标的对齐,而无需重新训练或微调。
D. 其他内容
在之前讨论的方法之外,还开发了一些用于视觉-语言模型在线测试时适应的额外技术[210],[232]-[234]。例如,DynaPrompt [209] 通过基于熵和置信度分数动态选择和更新每个测试样本的提示,减轻在线适应中的错误累积,同时维护一个自适应缓冲区来添加信息丰富的提示并丢弃不活跃的提示。ECALP [211] 通过动态扩展文本提示、少样本示例和测试样本的图结构来进行推理,而无需特定任务的调整,使用上下文感知的特征重新加权来利用测试样本流形,而不需要额外的无标签数据。OnZeta [23] 按顺序处理测试图像以进行即时预测而无需存储,使用在线标签学习来建模目标分布,并通过类特定的视觉代理进行在线代理学习以弥合图像-文本模态差距。此外,其他代表性工作包括支持集[235]、令牌浓缩[210]、提示蒸馏[236]等[237]-[240]。
VIII. 应用
A. 物体分类
物体分类是评估视觉-语言模型(VLMs)的一项基本任务,其目标是将测试物体图像分配到候选类别名称之一。在无监督适应与 VLMs 的背景下,研究工作主要集中在两个方面:细粒度泛化和对分布偏移的鲁棒性。为了评估细粒度分类性能,常用的基准数据集包括 Caltech101 [241]、OxfordPets [242]、StanfordCars [243]、Flowers102 [244]、Food101 [245]、FGVC-Aircraft [246]、SUN397 [247]、DTD [248]、EuroSAT [249] 和 UCF101 [250]。为了评估对分布偏移的鲁棒性,研究人员[18],[19],[101] 经常使用 ImageNet [251] 及其变体,如 ImageNet-V2 [253]、ImageNet-Sketch [255]、ImageNet-A [252] 和 ImageNet-R [254]。此外,一些研究[27],[34] 纳入了传统上用于领域适应的数据集来评估其方法,如 Office-Home [256]、Office [14] 和 DomainNet [257]。
B. 语义分割
语义分割旨在为图像中的每个像素分配一个语义标签,在自动驾驶和医学图像分析等应用中发挥关键作用。基于 VLMs 的无监督分割方法主要关注通用和细粒度物体分割基准,包括 PASCAL VOC 2012 [258]、PASCAL Context [259]、COCO Stuff [260]、ADE20K [261] 和 COCO-Object [262]。此外,复杂场景理解数据集如 Cityscapes [263] 和 KITTI-STEP [264] 也常用于评估无监督分割方法的性能。为了评估识别稀有概念的能力,一些方法[28] 使用了 FireNet [265]。此外,研究人员[16] 探索了 VLMs 对损坏的鲁棒性[285]。分割性能通常使用平均交并比(mIoU)指标进行量化。
C. 视觉推理
上下文相关的视觉推理旨在根据一小组包含正例和反例的支持图像,识别测试图像是否包含给定概念。Bongard-HOI [266] 常用于评估 VLMs 从有限的支持示例中抽象出人-物交互概念并准确分类测试样本的能力。
D. 分布外检测(Out-of-Distribution Detection)
分布外(OOD)检测的重点在于识别测试样本是否属于由候选类别组成的分布内(ID)数据集,这在安全关键性应用中扮演着至关重要的角色。根据OOD和ID数据集之间的相似度程度,OOD检测可以分为三种主要类型:远距离OOD、近距离OOD和细粒度OOD。
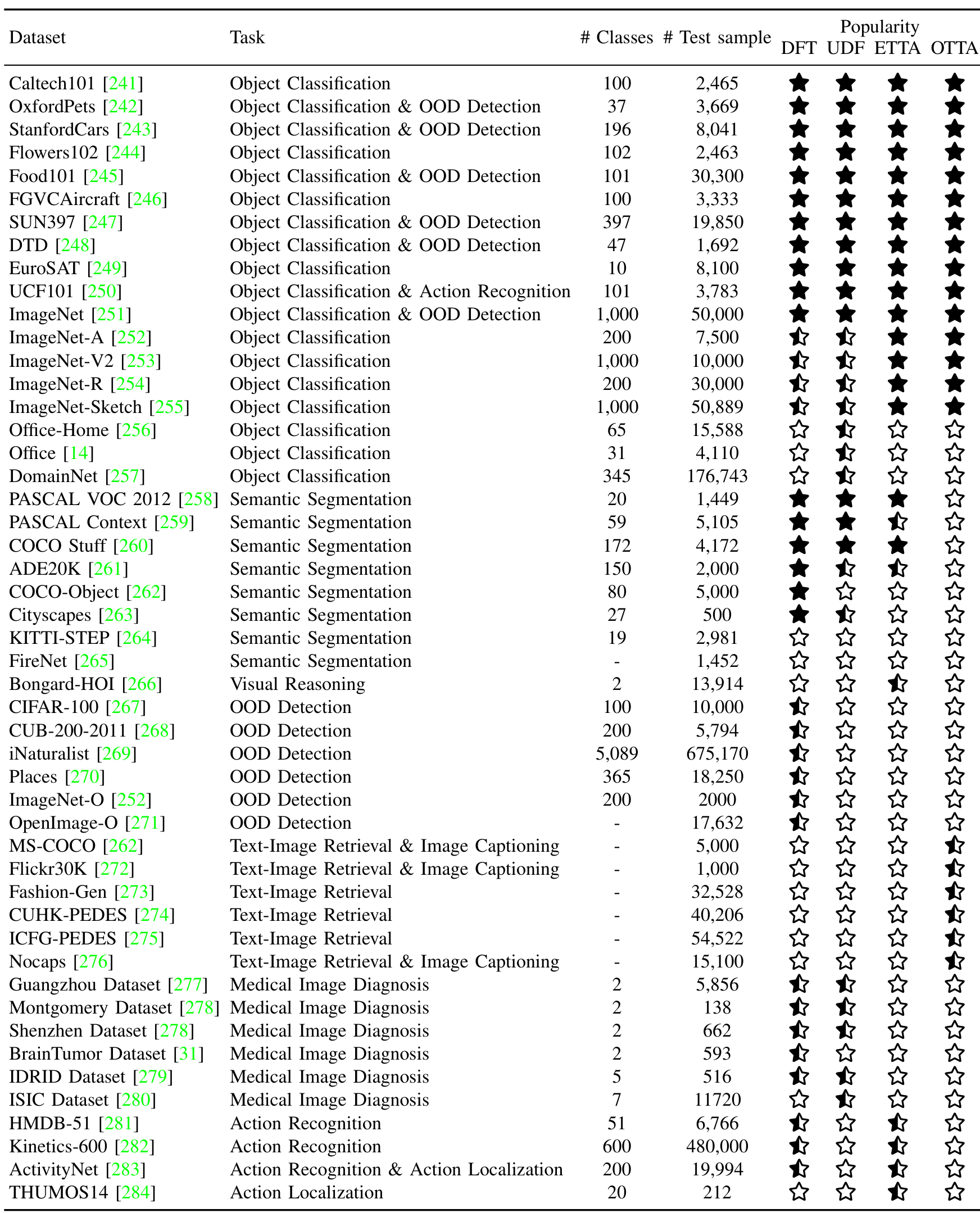
远距离OOD检测处理与ID分布明显不同的样本。例如,当使用CIFAR-100 [267]、CUB-200-2011 [268]、StanfordCars [243]、Food101 [245]、OxfordPets [242]和ImageNet [251]等数据集作为ID数据时,iNaturalist [269]、SUN397 [247]、Places [270]和DTD [248]等数据集通常作为典型的远距离OOD数据源。近距离OOD检测处理的是更具挑战性的场景,其中OOD样本与ID数据在视觉上具有相似性。常见的实验设置包括交替使用ImageNet-10和ImageNet-20作为ID和OOD数据集,以及使用ImageNet-O [252]和OpenImage-O [271]作为近距离OOD数据集。细粒度OOD检测则针对相似类别内的细微分布偏移。例如,可以将CUB-200-2011 [268]、StanfordCars [243]、Food101 [245]和OxfordPets [242]等数据集拆分,一半类别作为ID数据,另一半作为OOD数据。OOD检测性能的评估通常使用FPR95和AUROC指标。
IX. 研究挑战与未来方向
尽管无监督视觉语言模型(VLM)适配领域取得了显著进展,但这一问题仍然是一个开放且具有挑战性的课题。本节概述了关键的研究方向,识别了当前文献中的差距,并讨论了推动该领域发展的潜在途径。
A. 理论分析
虽然现有研究主要集中在开发有效的无监督学习方法上,但严谨的理论分析仍然不足。理解VLM的理论复杂性对于开发更具原则性的适配方法至关重要。未来的研究可以通过提供正式的泛化保证和表征联合嵌入空间来弥合这一差距,以解释跨模态对齐是如何出现的 [286]。
B. 开放世界场景
大多数现有方法都在闭集假设下操作,即假设跨域的标签空间相同。然而,在现实世界应用中,测试样本往往包含未知类别,因此有效检测和处理这些未知类别变得至关重要。尽管近期一些研究 [27]、[215]、[216] 已开始解决开放世界场景,但这一具有挑战性且实际的设置仍未被充分探索。需要进一步研究开发稳健的开放世界适配方法,使其能够在多样化领域中泛化,同时准确识别未见过的类别。来自分布外检测的技术 [287]-[289] 也可以被借鉴和适配,以促进未知类别的检测。
C. 对抗鲁棒性
尽管VLM表现出强大的泛化能力,但它们仍然极易受到对抗攻击的影响 [290]。近期的一些研究 [290]、[291] 从对抗训练技术 [292] 中汲取灵感,以增强VLM的鲁棒性。然而,这些方法通常依赖于大量标注数据,导致高昂的标注成本。因此,一个重要的研究方向是在无监督设置下探索稳健优化 [125] 和推理策略 [148],使VLM能够在复杂现实环境中可靠运行,这些环境中对抗威胁可能存在且标注数据稀缺。
D. 隐私考虑
隐私和安全考虑对于VLM的适配变得越来越关键,特别是在自动驾驶 [293] 和医疗保健 [294] 等敏感领域。在适配过程中,模型可能处理专有或个人数据,引发数据泄露和未经授权访问的担忧。此外,适配过程可能使模型暴露于对抗攻击 [292],这些攻击利用更新阶段的漏洞,可能导致性能下降或有害结果。为应对这些挑战,未来的研究应专注于开发隐私保护的适配技术,如联邦学习 [295],使模型能够在不直接访问原始数据的情况下有效适配。
E. 高效推理
VLM的部署需要大量的计算资源用于推理。一个关键的研究挑战是减少其延迟和内存占用,同时不牺牲性能。未来的工作可以适配量化 [296]、剪枝 [297] 和知识蒸馏 [298] 等技术,以适应这些模型独特的跨模态特性。核心难点在于压缩模型的同时保留预训练期间学习的微妙视觉-语言对齐。开发新型高效架构对于在资源受限的硬件上实现实时VLM应用至关重要,并将这些强大的模型从云端转移到边缘设备。
论文摘要(中文)
以下是对论文中指定部分的中文总结,保留了原文中的 Markdown 格式和图片位置。
F. 超越 CLIP 的更多视觉语言模型 (VLMs)
虽然 CLIP 已成为无监督学习视觉语言模型 (VLMs) 的实际骨干,但仅依赖其对比学习框架限制了架构和目标的多样性。未来的研究应探索替代基础模型,例如先进的训练策略 [87]、结合文本编码器的掩码图像建模 [299] 或生成式视觉语言转换器 [300],以发掘新的归纳偏差。此外,研究不同的编码器-解码器配对如何影响对齐和可迁移性,将有助于选择更通用的模型。超越 CLIP 的扩展将催化新的无监督范式,并提高 VLM 在各种任务和领域中的鲁棒性。
G. 扩展到多模态大语言模型 (MLLMs)
另一个有前景的研究方向是将测试时适应 (TTA) 集成到具有测试时扩展的多模态大语言模型 (MLLMs) 中 [301], [302]。TTA 方法使模型能够在推理期间动态适应分布变化,无需重新训练即可增强鲁棒性。同时,测试时扩展技术在测试时分配额外的计算资源,允许模型在具有挑战性或分布外输入上“思考”更长时间或进行更深入的推理 [303]。通过融合这些方法,MLLM 不仅能根据传入数据流调整预测,还能根据样本难度灵活扩展推理计算能力。这种协同作用将在效率和准确性之间提供平衡的权衡,特别是在快速响应和高适应性都至关重要的现实应用中。
H. 新的下游任务
尽管无监督学习的 VLM 在图像分类和语义分割任务中已被广泛研究,但其在其他领域的潜力仍未被充分探索,包括回归 [304]、生成模型 [305]、跨模态检索 [306]、深度补全 [307]、误分类检测 [308] 和图像超分辨率 [309]。此外,在医学 [310] 和医疗保健 [311] 等其他领域的潜在应用也未被充分探索,值得更多关注。
I. 失败模式与负迁移
尽管许多无监督适应方法在 VLM 中取得了经验上的成功,但很少有研究系统地记录其失败模式或报告负迁移的实例。例如,熵最小化 [18] 虽被广泛使用,但当出现误分类甚至模式崩溃时,可能会强化错误的预测。同样,通过大语言模型 (LLMs) 生成的提示可能会引入幻觉或领域不适当的描述 [312],导致与视觉内容语义不对齐并降低性能。在持续适应设置中 [83],随着时间的推移,错误伪标签的积累可能会扭曲特征空间并破坏适应过程的稳定性。为了推动该领域的发展,未来的研究应更加重视鲁棒性分析,包括开发检测适应失败的指标以及识别和报告不稳定性的最佳实践。此外,分享负面结果或反例可以在揭示系统性弱点和指导设计更具弹性和可靠的适应流程中发挥关键作用。
X. 结论
在本次综述中,我们对无监督视觉-语言模型适应的快速发展领域进行了全面且结构化的概述。为了填补现有文献中的显著空白,我们提出了一种新颖的分类法,根据无标签视觉数据的可用性对方法进行分类,这是现实世界部署的关键因素。通过将该领域划分为四种不同的设置——无数据迁移、无监督域迁移、情景化测试时适应和在线测试时适应,我们系统地阐述了每种场景固有的假设。在这一框架内,我们分析了核心方法并回顾了代表性的基准测试,为该领域的最新进展提供了全面的视角。最后,我们确定了几个关键挑战和未来研究方向,包括理论分析的发展、开放世界场景和隐私考虑的处理,以及对新下游任务和应用领域的进一步探索。本综述不仅将作为从业者导航无监督视觉-语言模型适应领域的宝贵资源,还将通过提供清晰的比较基础和确定未来研究的有前景方向,激发进一步的创新。
Original Abstract: Vision-Language Models (VLMs) have demonstrated remarkable generalization
capabilities across a wide range of tasks. However, their performance often
remains suboptimal when directly applied to specific downstream scenarios
without task-specific adaptation. To enhance their utility while preserving
data efficiency, recent research has increasingly focused on unsupervised
adaptation methods that do not rely on labeled data. Despite the growing
interest in this area, there remains a lack of a unified, task-oriented survey
dedicated to unsupervised VLM adaptation. To bridge this gap, we present a
comprehensive and structured overview of the field. We propose a taxonomy based
on the availability and nature of unlabeled visual data, categorizing existing
approaches into four key paradigms: Data-Free Transfer (no data), Unsupervised
Domain Transfer (abundant data), Episodic Test-Time Adaptation (batch data),
and Online Test-Time Adaptation (streaming data). Within this framework, we
analyze core methodologies and adaptation strategies associated with each
paradigm, aiming to establish a systematic understanding of the field.
Additionally, we review representative benchmarks across diverse applications
and highlight open challenges and promising directions for future research. An
actively maintained repository of relevant literature is available at
https://github.com/tim-learn/Awesome-LabelFree-VLMs.
PDF Link: 2508.05547v1
部分平台可能图片显示异常,请以我的博客内容为准
