[论文阅读] 人工智能 + 软件工程 | Posterior-GRPO:优化代码生成推理过程的新框架
Posterior-GRPO:优化代码生成推理过程的新框架
论文:Posterior-GRPO: Rewarding Reasoning Processes in Code Generation
arXiv:2508.05170
Posterior-GRPO: Rewarding Reasoning Processes in Code Generation
Lishui Fan, Yu Zhang, Mouxiang Chen, Zhongxin Liu
Subjects: Software Engineering (cs.SE); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
一段话总结:
本文提出Posterior-GRPO(P-GRPO) 框架,旨在通过强化学习(RL)优化代码生成中的推理过程质量,解决现有方法依赖结果奖励导致的推理过程被忽视及奖励黑客问题。该框架包含三部分:构建LCB-RB基准(含187对优劣推理过程偏好对)用于推理评估;提出OD-based奖励模型训练方法,通过优化和降级推理路径(基于事实准确性、逻辑严谨性、连贯性维度)生成高质量偏好对,训练的7B模型在LCB-RB上达SOTA;设计P-GRPO算法,仅对成功结果的推理过程应用奖励,缓解奖励黑客。实验显示,7B模型在代码生成任务上超仅结果奖励基线4.5%,性能接近GPT-4-Turbo,且在数学任务上泛化性良好(相对提升7.3%)。
研究背景
在大语言模型(LLMs)的代码生成领域,强化学习(RL)已成为重要的后训练范式。然而,现有方法存在明显局限:它们仅依赖测试用例结果(如代码通过率)来给予模型奖励,却忽视了模型生成代码时的中间推理过程质量。
这就好比老师批改作业只看答案对错,不关注学生的解题思路。长此以往,模型可能学会“走捷径”——比如生成看似正确但逻辑混乱的代码,或者在推理过程中存在漏洞却侥幸通过测试,这种现象被称为“奖励黑客”。
更关键的是,研究发现推理过程质量与最终代码正确性存在显著关联(χ²检验显示p=9.3×10⁻¹⁵≪0.001),忽视推理过程可能导致模型性能难以持续提升。因此,如何让模型在生成正确代码的同时,具备高质量的推理过程,成为亟待解决的问题。
主要作者及单位信息
- 作者:Lishui Fan、Yu Zhang*、Mouxiang Chen、Zhongxin Liu†
- 单位:1. 区块链与数据安全国家重点实验室;2. 浙江大学
创新点
- LCB-RB基准:首个专门用于评估奖励模型对推理过程区分能力的基准,包含187对“优质推理+正确代码”与“劣质推理+错误代码”的偏好对。
- OD-based奖励模型训练方法:通过系统地优化和降级初始推理路径(基于事实准确性、逻辑严谨性、连贯性三个维度),生成高质量偏好对,让奖励模型更精准地评估推理质量。
- Posterior-GRPO(P-GRPO)算法:一种新型强化学习方法,仅对“测试通过的代码”对应的推理过程给予奖励,既避免奖励黑客,又让模型的推理过程与代码正确性对齐。
研究方法和思路
1. LCB-RB基准构建
- 从LiveCodeBench选取880个代码问题,用Qwen2.5-Coder-32B-Instruct生成50个带推理过程的解决方案;
- 经GPT-4o过滤,保留“推理与代码一致”的样本,最终形成187对偏好对(优质推理+正确代码 vs 劣质推理+错误代码)。
2. OD-based奖励模型训练
- 步骤1:用强大的LLM生成初始推理路径;
- 步骤2:基于“事实准确性、逻辑严谨性、连贯性”三个维度,生成优化版(y⁺)和降级版(y⁻)推理路径;
- 步骤3:用三种偏好对((x,y⁺,y⁻)、(x,y,y⁻)、(x,y⁺,y))训练Bradley-Terry奖励模型,使其能给推理质量打分(0-1之间)。
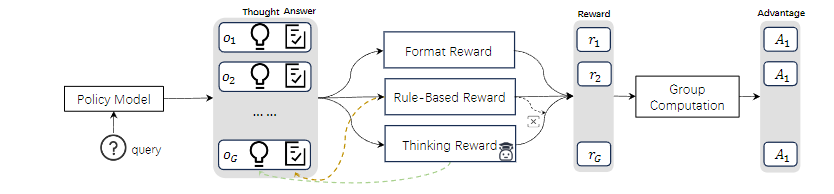
3. P-GRPO算法设计
- 奖励组成:格式奖励(Rf,检查输出结构是否合规)、规则奖励(Ro,测试用例通过率)、思维奖励(R^t,推理质量评分);
- 后验策略:仅当Ro=1(代码通过所有测试)时,才保留Rt,否则R^t=0;
- 总奖励公式:R_i = R_i^f + R_i^o + R_io·R_it,解决了传统GRPO中“成功样本奖励无差异”的问题。
实验方法
- 奖励模型:基于Qwen2.5-Coder-3B/7B-Base训练,在LCB-RB和RewardBench上评估;
- 强化学习:以Qwen2.5-Coder-7B-Instruct为策略模型,在HumanEval(+)、MBPP(+)等4个代码基准上测试,用Pass@1指标评估;
- 数学任务扩展:用Qwen2.5Math-7B模型,在MATH500等3个数学基准上验证泛化性。
主要贡献
- 性能提升显著:7B参数模型经P-GRPO训练后,在代码生成任务上平均超“仅结果奖励”基线4.5%,在LiveCodeBench上相对提升18.1%,性能接近GPT-4-Turbo。
- 奖励模型表现优异:OD-based方法训练的7B模型在LCB-RB上准确率达58.28%,超GPT-4-Turbo,在RewardBench推理子集上平均准确率82.22%,为SOTA。
- 跨领域泛化性强:扩展到数学任务时,Qwen2.5Math-7B相对“仅结果奖励”基线提升7.3%,验证了方法的通用性。
- 解决核心痛点:有效缓解奖励黑客问题,让模型同时关注“推理质量”和“结果正确性”,为代码生成与复杂推理任务提供新范式。
思维导图:
详细总结:
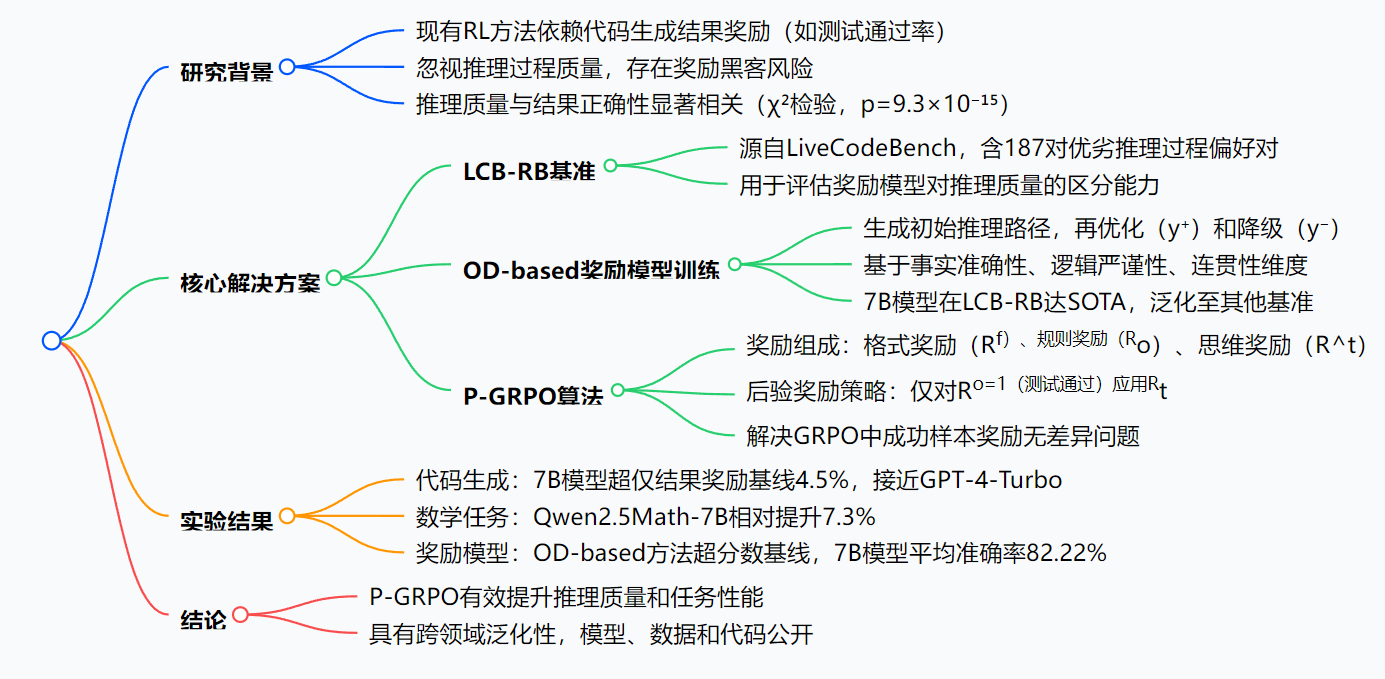
1. 研究背景与挑战
- 现状:现有RL方法在代码生成中仅依赖结果奖励(如测试通过率),忽视推理过程质量,可能导致推理过程不佳,最终影响结果准确性。
- 挑战:
- 缺乏评估推理过程的基准(现有基准侧重结果);
- 缺少针对推理评估的可靠奖励模型(现有模型基于结果训练);
- 现有RL算法易受奖励黑客影响(模型利用奖励信号而非提升结果)。
2. 核心方法
| 组成部分 | 细节描述 | 关键成果 |
|---|---|---|
| LCB-RB基准 | 基于LiveCodeBench的880个问题,用Qwen2.5-Coder-32B-Instruct生成50个带推理的解决方案,经GPT-4o过滤,最终得到187对偏好对(优推理+正确代码 vs 劣推理+错误代码) | 首个针对代码生成推理过程的偏好评估基准 |
| OD-based奖励模型训练 | 1. 生成初始推理路径;2. 基于事实准确性、逻辑严谨性、连贯性优化(y⁺)和降级(y⁻);3. 用三种偏好对((x,y⁺,y⁻)、(x,y,y⁻)、(x,y⁺,y))训练Bradley-Terry模型 | 7B模型在LCB-RB准确率58.28%,超GPT-4-Turbo,在RewardBench推理子集达SOTA |
| P-GRPO算法 | 奖励公式:(R_i = R_i^f + R_i^o + R_i^o \cdot R_it),其中(Rt)仅在(R^o=1)时有效;解决GRPO中成功样本奖励无差异问题 | 提升数据利用效率,使成功样本因推理质量差异产生奖励区分 |
3. 实验结果
- 代码生成任务(表1):
- 7B模型(Qwen2.5-Coder-Instruct)经P-GRPO训练,在HumanEval(+)、MBPP(+)等4个基准上平均相对提升13.9%,超仅结果奖励基线4.5%,LiveCodeBench上相对提升18.1%,性能接近GPT-4-Turbo。
- 数学任务(表3):
- Qwen2.5Math-7B经P-GRPO训练,在MATH500、AIME2024等3个基准上平均相对提升7.3%,超仅结果奖励基线,性能接近Eurus-2-PRIME等SOTA模型。
- 奖励模型对比:
- OD-based方法训练的7B模型在LCB-RB、RewardBench(代码+数学)上平均准确率82.22%,超Starling-RM(75.71%)、EURS-RM(76.44%)等基线。
4. 结论与展望
- 核心贡献:提出LCB-RB基准、OD-based奖励模型训练方法、P-GRPO算法,有效提升推理质量和任务性能。
- 局限与未来:受计算资源限制,计划扩展至更大模型(如DeepSeek-R1-Distill-Qwen-7B),开发自迭代学习框架。
关键问题:
-
问题:P-GRPO如何缓解奖励黑客问题?其奖励机制有何特点?
答案:P-GRPO通过“后验奖励分配策略”缓解奖励黑客:仅当规则奖励(Ro=1)(代码通过所有测试)时,才保留思维奖励(Rt);若(Ro≠1),则(Rt=0)。这确保模型仅因成功结果的高质量推理受奖励,避免利用错误结果的推理获取奖励。奖励机制包含三部分:格式奖励(确保输出结构合规)、规则奖励(测试通过率)、思维奖励(推理质量评分),最终奖励公式为(R_i = R_i^f + R_i^o + R_i^o \cdot R_i^t)。 -
问题:OD-based奖励模型训练方法与现有方法相比,优势何在?
答案:OD-based方法通过系统优化和降级初始推理路径(基于事实准确性、逻辑严谨性、连贯性)生成对比鲜明的偏好对,而非依赖直接数值评分。优势在于:1. 解决LLM对细粒度数值不敏感的问题,提供更清晰的学习信号;2. 训练的7B模型在LCB-RB上准确率58.28%,超分数基线23.5%,在RewardBench推理子集达SOTA(平均82.22%);3. 泛化能力强,可迁移至其他推理评估基准。 -
问题:P-GRPO在代码生成和数学任务上的性能表现如何?体现了其什么特性?
答案:在代码生成任务上,7B模型经P-GRPO训练后,平均超仅结果奖励基线4.5%,在LiveCodeBench上相对提升18.1%,性能接近GPT-4-Turbo;在数学任务上,Qwen2.5Math-7B相对提升7.3%,在AIME2024等基准上表现优于基线。这体现了P-GRPO不仅能有效提升代码生成中的推理质量和结果正确性,还具有跨领域泛化能力,可迁移至依赖高质量推理的数学任务。
总结
本文提出的Posterior-GRPO框架,通过构建LCB-RB基准、OD-based奖励模型训练方法和P-GRPO算法,系统性地解决了现有强化学习在代码生成中忽视推理过程的问题。
解决的主要问题:
- 缺乏评估推理过程的基准;
- 缺少针对推理的可靠奖励模型;
- 强化学习易受奖励黑客影响。
主要成果:
- 7B模型在代码生成任务上性能接近GPT-4-Turbo;
- 奖励模型在推理评估上达SOTA;
- 方法在数学任务上展现强泛化性。
该研究不仅提升了模型的代码生成能力,更推动了“推理过程优化”在AI任务中的重视,相关模型、数据集和代码已公开,为后续研究提供便利。