6- Python 网络爬虫—验证码突破全解析: 从 OCR 到深度学习的对抗实战指南
目录
1、验证码的本质与对抗逻辑
2、OCR(光学字符识别):让计算机 “读懂” 图像中的文字
2.1 技术定义与核心目标
2.2 工作流程拆解
2.3 主流工具
2.4 实战案例
2.4.1 完整实现步骤
步骤 1:环境准备
步骤 2:获取验证码图片
步骤 3:图片预处理(灰度化 + 二值化)
步骤 4:调用 Tesseract 识别验证码
步骤 5:处理特殊情况(字符轻微变形)
步骤 6:自动填写验证码并提交
2.5 局限性与适用边界
3、OpenCV:图像分析与处理的 “瑞士军刀”
3.1 技术定义与核心功能
3.2 核心技术模块与应用
3.3 滑动验证码识别实战案例
3.4 技术优势与扩展场景
4、OCR 与 OpenCV 的协同应用
5、完整代码
6、实验结果
7、深度学习:复杂验证码的终极解法
7.1 技术框架:CNN(卷积神经网络)
数据准备:
模型搭建(Keras 示例 ):
训练与预测:
7.2 优势与适用场景
7.3 案例
8、技术选型与演进路径
在网络安全和自动化交互场景里,验证码是区分人机操作的关键防线。从简单的字符验证到复杂的行为校验,验证码形式不断演进,识别技术也随之迭代。下面结合实际需求,深度拆解验证码识别的技术逻辑与落地方法,涵盖从基础到进阶的完整流程 。
1、验证码的本质与对抗逻辑
验证码的核心是构建 “人类能轻松完成、机器难直接识别” 的交互任务,常见类型及对抗思路:
- 静态图形验证码:用字符变形、干扰线、背景噪声增加识别难度,对抗关键是 “还原字符特征”(如 OCR 预处理)。
- 滑动验证码:通过缺口位置匹配验证人机交互,核心是 “图像几何特征分析”(如 OpenCV 模板匹配 )。
- 行为验证码:结合鼠标轨迹、点击行为判断人机,需模拟或分析人类操作模式(复杂场景常依赖深度学习或打码平台 )。
2、OCR(光学字符识别):让计算机 “读懂” 图像中的文字
2.1 技术定义与核心目标
OCR 是一种通过计算机算法将图像中的文字(数字、字母、汉字等)转换为可编辑文本的技术。其核心目标是模拟人类视觉系统对字符的识别过程,解决 “图像文字无法直接被机器解析” 的问题。在验证码识别中,主要用于处理由字符构成的静态图形验证码(如登录页常见的 4 位数字字母组合验证码)。
2.2 工作流程拆解
OCR 识别字符的过程可分为 4 个关键步骤,每一步都直接影响最终识别准确率:
- 图像预处理:消除干扰,突出字符特征。常见操作包括:
from PIL import Imageimg = Image.open("captcha.png").convert("L") # 转灰度threshold = 150 # 阈值可根据图片亮度调整binary_img = img.point(lambda x: 0 if x < threshold else 255, "1") # 二值化-
- 灰度化:将彩色图像转为黑白灰度图(减少颜色通道干扰),公式为
(R、G、B分别为红、绿、蓝通道值)。
- 二值化:将灰度图转为纯黑白图(字符为黑 / 白,背景为白 / 黑),通过设定阈值T实现:像素值<T则为 0(黑),否则为 255(白)。例如用 Python 的 Pillow 库实现:
- 降噪:去除图像中的孤立噪点(如验证码背景的随机斑点),常用中值滤波(适合去除椒盐噪声)或均值滤波(适合平滑高斯噪声)。
- 灰度化:将彩色图像转为黑白灰度图(减少颜色通道干扰),公式为
- 字符定位与分割:从预处理后的图像中提取单个字符。对于无粘连的验证码,可通过像素投影法(统计每行 / 列像素值,找到字符边界)分割;若字符粘连,需用轮廓检测(如 OpenCV 的findContours)提取字符轮廓,再裁剪为单个字符图像。
- 特征提取:提取字符的关键特征(如笔画数量、拐角位置、长宽比等),将图像信息转化为计算机可理解的数值特征。例如数字 “0” 的特征可能是 “闭合圆形、无交叉笔画”。
- 字符识别:将提取的特征与预设的字符特征库匹配,输出最可能的结果。传统 OCR 依赖人工设计特征(如模板匹配),现代 OCR 则结合深度学习(如 CNN)自动学习特征,识别准确率更高。
2.3 主流工具
- Tesseract OCR:谷歌开源的 OCR 引擎,支持多语言,适合入门级字符识别。搭配 Python 的pytesseract库可快速调用:
import pytesseract# 识别二值化后的验证码result = pytesseract.image_to_string(binary_img, config="--psm 6") # --psm 6表示假设图像为单一文本块print(f"识别结果:{result.strip()}")优化技巧:若识别错误率高,可通过config参数调整识别模式(如--oem 3启用 LSTM 神经网络模式),或训练自定义字符集(用tesseract_training工具生成专属模型)。
2.4 实战案例
识别某页面登录验证码(以Scrape | Captcha为例),该网站登录页的验证码为4 位纯数字,无干扰线、无字符粘连,背景干净但可能存在轻微噪点,属于最基础的图形验证码类型,非常适合用「Pillow 预处理 + Tesseract OCR」方案解决。
2.4.1 完整实现步骤
步骤 1:环境准备
需安装以下工具和库:
- Tesseract OCR:OCR 识别引擎(下载地址,需配置环境变量)
- Python 库:
bash
pip install pillow pytesseract selenium # 图像处理+OCR+自动化操作
步骤 2:获取验证码图片
用 Selenium 自动化打开网站并截取验证码图片:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time# 初始化浏览器
driver = webdriver.Chrome()
driver.get("https://captcha7.scrape.center/")
time.sleep(2) # 等待页面加载# 定位验证码元素并截图
captcha_elem = driver.find_element(By.CSS_SELECTOR, ".captcha-image") # 验证码图片的CSS选择器
captcha_elem.screenshot("captcha.png") # 保存验证码图片
步骤 3:图片预处理(灰度化 + 二值化)
用 Pillow 去除背景噪点,突出数字特征:
from PIL import Image# 打开图片并转灰度(减少颜色通道干扰)
img = Image.open("captcha.png").convert("L") # "L"表示灰度模式# 二值化处理(将灰度图转为纯黑白,突出数字)
threshold = 150 # 阈值(可根据图片亮度调整,值越小越容易保留细节)
binary_img = img.point(lambda x: 0 if x < threshold else 255, "1") # 像素<阈值则为黑(0),否则为白(255)
binary_img.save("processed_captcha.png") # 保存处理后的图片
预处理效果:
- 原始图可能存在的浅灰色噪点被去除
- 数字边缘更清晰,与背景对比强烈
步骤 4:调用 Tesseract 识别验证码
import pytesseract# 配置Tesseract路径(若已加入环境变量可省略)
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe"# 识别处理后的验证码(只识别数字,提高准确率)
result = pytesseract.image_to_string(binary_img,config="--psm 6 -c tessedit_char_whitelist=0123456789" # --psm 6:假设图片为单一文本块;whitelist:限定只识别数字
)
captcha_code = result.strip() # 去除空格和换行
print(f"识别到的验证码:{captcha_code}")
步骤 5:处理特殊情况(字符轻微变形)
若数字存在轻微扭曲(如网站偶尔出现的字体变形),可通过 OpenCV 的膨胀 / 腐蚀操作强化边缘:
import cv2
import numpy as np# 将Pillow图片转为OpenCV格式
cv_img = np.array(binary_img)# 定义卷积核(控制膨胀/腐蚀强度)
kernel = np.ones((2, 2), np.uint8)# 膨胀操作(加粗字符边缘,填补细小缺口)
dilated_img = cv2.dilate(cv_img, kernel, iterations=1)# 腐蚀操作(细化字符边缘,去除多余噪点)
eroded_img = cv2.erode(dilated_img, kernel, iterations=1)# 转回Pillow格式重新识别
processed_img = Image.fromarray(eroded_img)
result = pytesseract.image_to_string(processed_img, config="--psm 6 -c tessedit_char_whitelist=0123456789")
print(f"优化后识别结果:{result.strip()}")
步骤 6:自动填写验证码并提交
# 定位验证码输入框并填写
input_elem = driver.find_element(By.CSS_SELECTOR, ".captcha-input") # 输入框的CSS选择器
input_elem.clear()
input_elem.send_keys(captcha_code)# 定位登录按钮并点击(假设已有账号密码)
login_btn = driver.find_element(By.CSS_SELECTOR, ".login-btn")
login_btn.click()# 关闭浏览器
time.sleep(2)
driver.quit()
2.5 局限性与适用边界
OCR 在处理字符清晰、无复杂干扰的场景时效率极高,但面对以下情况会失效:
- 字符严重变形(如扭曲、拉伸、重叠);
- 背景含大量干扰线、色块(遮挡字符特征);
- 非标准字符(如手写体、特殊符号)。
此时需结合深度学习或人工辅助识别(如打码平台)。
3、OpenCV:图像分析与处理的 “瑞士军刀”
3.1 技术定义与核心功能
OpenCV(Open Source Computer Vision Library)是一个跨平台的开源计算机视觉库,包含超过 2500 个优化的算法,可实现图像读取、特征提取、几何变换、目标检测等功能。在验证码识别中,其核心价值是通过图像分析解决几何类验证问题(如滑动验证码的缺口定位、拼图验证码的碎片匹配)。
3.2 核心技术模块与应用
- 图像读取与格式转换:支持多种图像格式(JPG、PNG 等),可快速转为灰度图、HSV 图(便于颜色筛选)。例如:
import cv2# 读取彩色图像并转灰度img = cv2.imread("slider.png")gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # OpenCV默认BGR格式,需转为RGB或灰度- 边缘检测:通过 Canny 算法提取图像边缘(如滑块缺口的轮廓),为后续匹配提供特征:
# Canny边缘检测(阈值100-200可调整)edges = cv2.Canny(gray_img, 100, 200)- 模板匹配:在目标图像中寻找与模板图像最相似的区域,是滑动验证码缺口定位的核心算法。原理是通过滑动模板计算与目标图像各区域的匹配度(如归一化相关系数),取最大值位置作为匹配结果:
# 模板匹配(滑块为模板,背景图为目标)bg = cv2.imread("bg.png", 0) # 背景图(灰度)slider = cv2.imread("slider.png", 0) # 滑块图(灰度)result = cv2.matchTemplate(bg, slider, cv2.TM_CCOEFF_NORMED) # 归一化相关系数匹配# 获取匹配度最高的位置min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)gap_x, gap_y = max_loc # 缺口左上角坐标- 形态学操作:通过腐蚀(去除小噪点)、膨胀(填补字符缝隙)、开运算(先腐蚀后膨胀,去除背景噪点)等操作优化图像:
# 定义卷积核(3x3矩形)kernel = np.ones((3, 3), np.uint8)# 开运算去除背景噪点opening = cv2.morphologyEx(gray_img, cv2.MORPH_OPEN, kernel)3.3 滑动验证码识别实战案例
以某电商平台的滑动验证码为例,完整流程如下:
- 步骤 1:获取图像资源:用 Selenium 截图保存背景图(带缺口)和滑块图(缺口模板)。
- 步骤 2:预处理图像:
# 转灰度并去噪bg_gray = cv2.cvtColor(bg, cv2.COLOR_BGR2GRAY)slider_gray = cv2.cvtColor(slider, cv2.COLOR_BGR2GRAY)# 二值化(突出缺口边缘)_, bg_bin = cv2.threshold(bg_gray, 127, 255, cv2.THRESH_BINARY)_, slider_bin = cv2.threshold(slider_gray, 127, 255, cv2.THRESH_BINARY)- 步骤 3:定位缺口位置:
# 模板匹配找缺口match_result = cv2.matchTemplate(bg_bin, slider_bin, cv2.TM_SQDIFF_NORMED)min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(match_result)gap_x = max_loc[0] # 缺口横坐标- 步骤 4:模拟人类滑动:用 Selenium 的ActionChains模拟滑块拖动,加入加速度(先慢后快再慢),避免被检测为机器行为:
from selenium.webdriver.common.action_chains import ActionChainsslider_elem = driver.find_element_by_css_selector(".slider-btn")# 分3段拖动,模拟人类操作ActionChains(driver).click_and_hold(slider_elem).perform()ActionChains(driver).move_by_offset(gap_x//3, 0).pause(0.2).perform() # 第一段ActionChains(driver).move_by_offset(gap_x//3, 0).pause(0.1).perform() # 第二段ActionChains(driver).move_by_offset(gap_x - 2*gap_x//3, 0).release().perform() # 第三段3.4 技术优势与扩展场景
OpenCV 的优势在于高效处理几何特征,除滑动验证码外,还可应用于:
- 拼图验证码:通过轮廓匹配拼接碎片;
- 点选验证码:定位图片中的目标物体(如 “点击所有汽车”);
- 图像扭曲校正:对倾斜、旋转的验证码进行几何修正,提升后续 OCR 识别率。
4、OCR 与 OpenCV 的协同应用
在复杂验证码场景中,两者常结合使用:
- 流程示例:识别带干扰线的字符验证码
- 用 OpenCV 去除干扰线(通过形态学操作提取水平线 / 垂直线并删除);
- 对处理后的图像做二值化、降噪;
- 用 OCR 引擎识别字符,准确率可从 50% 提升至 85% 以上。
通过以上解析可见,OCR 和 OpenCV 是验证码识别的基础工具,掌握其原理和操作,能为应对各类图像验证场景提供扎实的技术支撑。在实际应用中,需根据验证码复杂度灵活选择工具组合,并结合预处理优化、参数调优等技巧提升识别效果。
5、完整代码
# 导入必要的库
import time # 用于添加延迟,模拟人类操作
import re # 用于正则表达式处理,过滤验证码中的无效字符
import random # 生成随机数,用于随机延迟
import numpy as np # 用于图片数组处理(验证码预处理)
import traceback # 用于捕获和打印详细错误信息
from io import BytesIO # 用于处理图片二进制数据
from PIL import Image # 用于图片处理(打开、保存、转换等)
from retrying import retry # 用于实现重试机制,失败后自动重试
from selenium import webdriver # Selenium核心库,用于控制浏览器
from selenium.webdriver.common.by import By # 用于指定元素定位方式(如ID、CSS选择器等)
from selenium.webdriver.support.ui import WebDriverWait # 用于等待元素加载
from selenium.webdriver.support import expected_conditions as EC # 用于定义等待条件
from selenium.common.exceptions import ( # Selenium常见异常类TimeoutException, NoSuchElementException,StaleElementReferenceException, WebDriverException
)
from selenium.webdriver.chrome.service import Service # 用于配置Chrome驱动服务
from webdriver_manager.chrome import ChromeDriverManager # 自动管理Chrome驱动版本
import pytesseract # OCR识别库,用于识别验证码文字
import os # 用于处理文件路径和环境变量# ====================== 基础配置 ======================
# 配置pytesseract的执行路径(必须修改为你的Tesseract安装路径)
pytesseract.pytesseract.tesseract_cmd = r'D:\App\tesseract\tesseract.exe'
# 配置Tesseract的语言包路径(用于识别不同语言)
os.environ['TESSDATA_PREFIX'] = r'D:\App\tesseract\tessdata'# 登录成功后跳转的目标URL(用于验证登录结果)
SUCCESS_URL = 'https://captcha7.scrape.center/success'
# 登录页面的URL
LOGIN_PAGE = 'https://captcha7.scrape.center/'
# 最大重试次数(登录失败后最多重试多少次)
MAX_RETRY = 10
# Chrome驱动的手动路径(当自动获取失败时使用)
MANUAL_DRIVER_PATH = r"D:\chromedriver.exe" # 替换为你的ChromeDriver路径# ====================== 工具函数 ======================
def preprocess(image):"""验证码预处理函数:优化图片质量,提高OCR识别率步骤:灰度化→二值化(黑白处理)→转为PIL图片:param image: PIL打开的原始验证码图片:return: 处理后的图片"""# 1. 将图片转为灰度图(去除色彩干扰)image = image.convert('L')# 2. 转为numpy数组(方便进行像素级处理)array = np.array(image)# 3. 二值化处理:像素值大于50的设为白色(255),否则设为黑色(0)# (阈值50可根据验证码实际情况调整,目的是去除背景噪点)array = np.where(array > 50, 255, 0)# 4. 将数组转回PIL图片格式return Image.fromarray(array.astype('uint8'))def safe_locate(browser, by, selector, step_name, timeout=10):"""安全定位元素的工具函数:封装了元素定位逻辑,增加错误处理避免因元素未加载或定位失败导致程序直接崩溃:param browser: 浏览器实例:param by: 定位方式(如By.ID、By.CSS_SELECTOR):param selector: 定位表达式(如"#captcha"、".username"):param step_name: 该元素对应的操作步骤名称(用于日志输出):param timeout: 最大等待时间(秒):return: 找到的元素对象,或None(定位失败)"""try:# 等待元素可点击(最多等待timeout秒)element = WebDriverWait(browser, timeout).until(EC.element_to_be_clickable((by, selector)))print(f"【定位成功】{step_name}:{by}={selector}")return elementexcept (TimeoutException, NoSuchElementException):# 元素未找到或超时print(f"【定位失败】{step_name}:{by}={selector}(元素未找到)")except StaleElementReferenceException:# 元素已失效(页面刷新导致)print(f"【定位失败】{step_name}:{by}={selector}(元素已失效)")except Exception as e:# 其他未知错误print(f"【定位异常】{step_name}:{str(e)}")return Nonedef init_browser():"""初始化浏览器函数:配置Chrome选项,隐藏自动化特征,返回浏览器实例目的是让浏览器行为更接近真实用户,避免被网站识别为爬虫:return: 配置好的Chrome浏览器实例"""# 配置Chrome浏览器选项chrome_options = webdriver.ChromeOptions()# 忽略证书错误(避免HTTPS网站的证书问题)chrome_options.add_argument('--ignore-certificate-errors')# 最大化窗口(模拟用户正常操作)chrome_options.add_argument('--start-maximized')# 禁用自动化控制特征(关键反检测配置)chrome_options.add_argument('--disable-blink-features=AutomationControlled')# 设置用户代理(模拟真实浏览器的标识)chrome_options.add_argument('--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36')# 排除自动化开关(隐藏Selenium痕迹)chrome_options.add_experimental_option("excludeSwitches", ["enable-automation"])# 禁用自动化扩展chrome_options.add_experimental_option("useAutomationExtension", False)# 初始化Chrome驱动服务try:# 尝试自动获取匹配当前Chrome版本的驱动service = Service(ChromeDriverManager().install())except:# 自动获取失败时,使用手动配置的驱动路径service = Service(MANUAL_DRIVER_PATH)# 创建浏览器实例browser = webdriver.Chrome(service=service, options=chrome_options)# 进一步隐藏自动化特征(通过Chrome DevTools协议注入JS)browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """// 覆盖navigator.webdriver属性(网站常用此检测自动化工具)Object.defineProperty(navigator, 'webdriver', {get: () => undefined});"""})return browser# ====================== 登录逻辑 ======================
@retry(stop_max_attempt_number=MAX_RETRY, # 最大重试次数(与MAX_RETRY保持一致)retry_on_result=lambda x: x is False, # 当函数返回False时触发重试wait_fixed=2000 # 重试间隔(毫秒):2000ms=2秒
)
def login(browser):"""核心登录函数:实现完整的登录流程,包含重试机制步骤:打开页面→输入用户名→输入密码→处理验证码→提交登录→验证结果:param browser: 浏览器实例:return: 登录成功返回True,失败返回False"""# 记录当前是第几次尝试(通过函数属性保存状态)attempt = login.__dict__.get('attempt', 1)login.attempt = attempt + 1 # 每次尝试后自增print(f"\n===== 登录尝试 {attempt}/{MAX_RETRY} =====")try:# 1. 打开登录页面并等待表单加载browser.get(LOGIN_PAGE) # 访问登录页面# 等待表单元素加载完成(最多15秒)WebDriverWait(browser, 15).until(EC.presence_of_element_located((By.TAG_NAME, 'form')))print("【页面状态】登录表单已加载")# 随机延迟0.5-1秒(模拟用户浏览)time.sleep(random.uniform(0.5, 1))# 2. 输入用户名# 通过CSS选择器定位用户名输入框(.username类下的text输入框)username_elem = safe_locate(browser, By.CSS_SELECTOR, '.username input[type="text"]',"用户名输入框")if not username_elem: # 定位失败则返回False,触发重试return Falseusername_elem.clear() # 清空输入框username_elem.send_keys('admin') # 输入用户名print("【操作成功】用户名已输入")time.sleep(random.uniform(0.3, 0.7)) # 随机延迟# 3. 输入密码# 通过CSS选择器定位密码输入框(.password类下的password输入框)password_elem = safe_locate(browser, By.CSS_SELECTOR, '.password input[type="password"]',"密码输入框")if not password_elem: # 定位失败则返回Falsereturn Falsepassword_elem.clear() # 清空输入框password_elem.send_keys('admin') # 输入密码print("【操作成功】密码已输入")time.sleep(random.uniform(0.3, 0.7)) # 随机延迟# 4. 处理验证码# 定位验证码图片(ID为captcha的元素)captcha_elem = safe_locate(browser, By.CSS_SELECTOR, '#captcha',"验证码图片")if not captcha_elem: # 定位失败则返回Falsereturn False# 获取验证码图片并保存# 1. 截取验证码元素的截图,转为二进制数据captcha_img = Image.open(BytesIO(captcha_elem.screenshot_as_png))# 2. 保存原始验证码图片(用于调试)captcha_img.save(f"验证码_尝试{attempt}.png")# 3. 预处理验证码(提高识别率)processed_img = preprocess(captcha_img)# 4. 保存处理后的图片(用于分析预处理效果)processed_img.save(f"处理后验证码_尝试{attempt}.png")# 使用pytesseract识别验证码文字try:# 调用OCR识别处理后的图片captcha_text = pytesseract.image_to_string(processed_img)# 过滤非字母数字的字符,并转为大写(统一格式)captcha_text = re.sub('[^A-Za-z0-9]', '', captcha_text).upper()print(f"【自动识别】验证码:{captcha_text}(长度:{len(captcha_text)})")except Exception as e:print(f"【识别错误】{str(e)}")return False # 识别失败则返回False# 当自动识别失败(结果不是4位)时,切换为手动输入if len(captcha_text) != 4:print(f"【识别失败】结果长度不符,需要手动输入")# 显示验证码图片(方便用户查看)captcha_img.show(title=f"验证码(尝试{attempt})")# 循环获取用户输入,直到符合格式(4位字母或数字)while True:try:captcha_text = input(f"请输入4位验证码(尝试{attempt}):").strip().upper()# 验证输入格式:4位且仅包含字母数字if len(captcha_text) == 4 and captcha_text.isalnum():breakprint("输入错误!请输入4位字母或数字")except UnicodeDecodeError:# 处理输入编码错误(如特殊字符)print("输入编码错误,请重新输入")# 5. 输入验证码# 定位验证码输入框(.captcha类下的text输入框)captcha_input = safe_locate(browser, By.CSS_SELECTOR, '.captcha input[type="text"]',"验证码输入框")if not captcha_input: # 定位失败则返回Falsereturn Falsecaptcha_input.clear() # 清空输入框captcha_input.send_keys(captcha_text) # 输入验证码print("【操作成功】验证码已输入")time.sleep(random.uniform(0.3, 0.7)) # 随机延迟# 6. 点击登录按钮# 定位登录按钮(.login类的元素)login_btn = safe_locate(browser, By.CSS_SELECTOR, '.login',"登录按钮")if not login_btn: # 定位失败则返回Falsereturn Falselogin_btn.click() # 点击登录按钮print("【操作成功】已点击登录按钮")time.sleep(2) # 等待登录请求响应# 7. 验证登录是否成功try:# 等待页面出现"登录成功"的标识(最多10秒)WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.XPATH, '//h2[contains(., "登录成功")]')))print("【登录成功】验证通过")time.sleep(5) # 停留5秒,方便查看结果return True # 登录成功,返回Trueexcept TimeoutException:# 未找到成功标识,登录失败print("【登录失败】未找到成功标识")return Falseexcept Exception as e:# 捕获流程中的所有异常print(f"【流程错误】尝试{attempt}失败:{str(e)}")print("【错误详情】\n", traceback.format_exc()) # 打印详细错误栈return False # 异常时返回False,触发重试# ====================== 主函数 ======================
def main():"""程序入口函数:初始化浏览器,执行登录流程,处理最终结果"""print("===== 使用pytesseract的验证码登录程序 =====")# 初始化浏览器browser = init_browser()try:# 执行登录逻辑login_success = login(browser)# 输出最终结果if not login_success:print(f"\n【最终结果】经过{MAX_RETRY}次尝试,登录失败")finally:# 无论成功与否,最终关闭浏览器browser.quit()print("\n【程序结束】浏览器已关闭")# 当脚本直接运行时,执行主函数
if __name__ == '__main__':# 初始化登录尝试次数login.attempt = 1main()6、实验结果


7、深度学习:复杂验证码的终极解法
7.1 技术框架:CNN(卷积神经网络)
针对变形字符、3D 验证码等复杂场景,用深度学习训练专属模型:
数据准备:
from captcha.image import ImageCaptcha
import string
# 字符集(数字+字母)
chars = string.digits + string.ascii_letters
captcha = ImageCaptcha(width=160, height=60)
# 生成验证码(如长度4)
img = captcha.generate_image('aB39')
- 采集 / 生成验证码样本(如用
captcha库生成 ):标注数据并划分训练集、测试集(建议用pandas管理标签 )。
模型搭建(Keras 示例 ):
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense model = Sequential([ # 卷积层提取特征Conv2D(32, (3,3), activation='relu', input_shape=(60, 160, 1)), MaxPooling2D((2,2)), Flatten(), # 全连接层分类Dense(128, activation='relu'), # 输出层(假设字符集长度36,验证码长度4,用CTC Loss需特殊处理)Dense(len(chars)*4, activation='softmax')
])
# 编译模型(用CTC Loss处理不定长字符)
model.compile(optimizer='adam', loss='categorical_crossentropy')
训练与预测:
- 用
model.fit训练模型,传入预处理后的图像数据(归一化到 [0,1] ); - 预测时,用
model.predict输出字符概率,解码得到结果(结合CTC解码逻辑 )。
7.2 优势与适用场景
深度学习适合高度定制化、复杂场景(如金融平台的 3D 旋转验证码 ),能通过大量样本训练适配特殊干扰,但需投入算力和数据标注成本。
7.3 案例
# 安装依赖:pip install captcha tensorflow pandas numpy pillow
import os
import numpy as np
import pandas as pd
from PIL import Image
from captcha.image import ImageCaptcha
import string
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, LSTM, Dense, Reshape, Lambda, Bidirectional
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import backend as K
import tensorflow as tf# 屏蔽TensorFlow冗余日志
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'# 1. 配置参数
chars = string.digits + string.ascii_letters # 字符集(62个字符)
char_to_idx = {c: i for i, c in enumerate(chars)} # 字符映射为索引
idx_to_char = {i: c for i, c in enumerate(chars)}
img_width = 160 # 验证码宽度
img_height = 60 # 验证码高度
max_length = 4 # 验证码长度
num_classes = len(chars)
batch_size = 32
epochs = 10 # 可根据需要增加# 2. 生成验证码数据集
def generate_captcha(text):"""生成验证码图片"""image = ImageCaptcha(width=img_width, height=img_height)img = image.generate_image(text)return np.array(img.convert('L')) / 255.0 # 转为灰度图并归一化def random_text(length):"""随机生成指定长度的验证码文本"""return ''.join(np.random.choice(list(chars), size=length))# 生成10000个训练样本(可根据需要增加样本量)
train_samples = 10000
train_texts = [random_text(max_length) for _ in range(train_samples)]
train_images = np.array([generate_captcha(text) for text in train_texts])
train_images = train_images.reshape(-1, img_height, img_width, 1) # 增加通道维度# 3. 数据预处理(转为CTC需要的格式)
def text_to_labels(text):"""文本转为标签序列"""return [char_to_idx[c] for c in text]def labels_to_text(labels):"""标签序列转为文本"""return ''.join([idx_to_char[i] for i in labels if i != -1]) # -1是CTC的空白符# 准备CTC输入
train_labels = [text_to_labels(text) for text in train_texts]
train_label_length = np.array([len(lab) for lab in train_labels])
# 模型输出序列长度(根据卷积层输出计算:60→30→15→7,这里取7*20=140,需与实际匹配)
train_input_length = np.ones_like(train_label_length) * 140
train_output = np.zeros(train_samples) # CTC损失占位符# 4. 构建CNN+LSTM+CTC模型
input_layer = Input(shape=(img_height, img_width, 1))# 卷积层提取特征
x = Conv2D(32, (3, 3), activation='relu', padding='same')(input_layer)
x = MaxPooling2D(pool_size=(2, 2))(x) # 输出尺寸:(30, 80, 32)
x = Conv2D(64, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D(pool_size=(2, 2))(x) # 输出尺寸:(15, 40, 64)
x = Conv2D(128, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D(pool_size=(2, 2))(x) # 输出尺寸:(7, 20, 128)# 调整维度以适应LSTM(时间步=7*20=140,特征数=128)
x = Reshape(target_shape=(140, 128))(x)# 双向LSTM层捕捉序列特征
x = Bidirectional(LSTM(128, return_sequences=True))(x)
x = Bidirectional(LSTM(64, return_sequences=True))(x)# 输出层(每个时间步预测一个字符,+1为空白符)
x = Dense(num_classes + 1, activation='softmax')(x)# 定义CTC损失函数(关键修复:使用K.ctc_batch_cost)
def ctc_lambda_func(args):y_pred, labels, input_length, label_length = args# 注意:y_pred需要转置为(批次,时间步,类别)格式return K.ctc_batch_cost(labels, y_pred, input_length, label_length)# 构建完整模型
labels = Input(shape=[max_length], dtype='int32')
input_length = Input(shape=[1], dtype='int32')
label_length = Input(shape=[1], dtype='int32')# 定义损失层
loss_layer = Lambda(ctc_lambda_func, output_shape=(1,))([x, labels, input_length, label_length])
model = Model(inputs=[input_layer, labels, input_length, label_length], outputs=loss_layer)# 编译模型
model.compile(optimizer=Adam(learning_rate=0.001), loss=lambda y_true, y_pred: y_pred)# 5. 训练模型
model.fit(x=[train_images, np.array(train_labels), train_input_length, train_label_length],y=train_output,batch_size=batch_size,epochs=epochs,validation_split=0.1
)# 6. 构建预测模型(去除损失层)
pred_model = Model(inputs=input_layer, outputs=x)# 7. 预测函数(使用CTC解码)
def predict_captcha(image):image = image.reshape(1, img_height, img_width, 1) # 增加批次和通道维度pred = pred_model.predict(image)# CTC波束搜索解码(输入长度需与模型输出序列长度一致)decoded = K.ctc_decode(pred, input_length=np.ones(pred.shape[0])*pred.shape[1])[0][0]decoded = K.get_value(decoded) # 获取解码结果return labels_to_text(decoded[0])# 测试预测
test_text = random_text(max_length)
test_image = generate_captcha(test_text)
pred_text = predict_captcha(test_image)
print(f"真实值: {test_text}, 预测值: {pred_text}")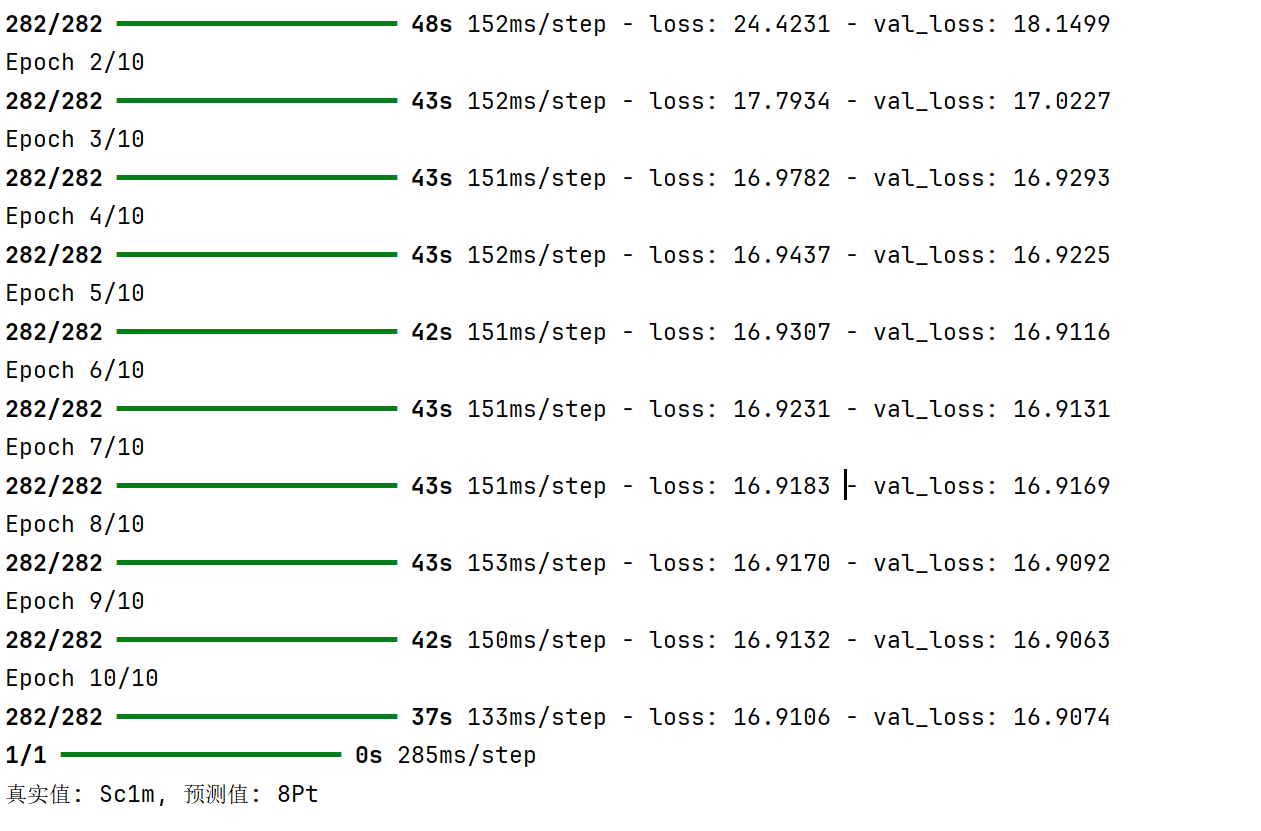
8、技术选型与演进路径
| 技术方案 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| OCR + 预处理 | 简单静态验证码 | 轻量、低成本 | 复杂干扰下准确率低 |
| OpenCV 匹配 | 滑动 / 拼图验证码 | 精准定位几何特征 | 依赖图像标准化 |
| 深度学习 | 高度定制化复杂验证码 | 适配特殊干扰 | 需算力、数据标注 |