第八章 SQL编程系列-Oracle慢SQL优化实战:从执行计划到索引设计的深度解析
1 引言
在数字化业务高速运转的今天,数据库作为企业核心系统的基石,其SQL性能直接影响着业务响应效率与用户体验。慢SQL如同隐形的性能陷阱,可能导致全表扫描引发的I/O风暴、长事务阻塞导致的并发冲突,甚至引发系统级雪崩效应。本文以Oracle数据库为切入点,从执行计划解析、索引设计原则到SQL改写策略,构建了一套完整的优化方法论。通过典型案例剖析与2025年最新特性(如自动索引、实时统计)的融合应用,揭示如何将毫秒级优化转化为业务竞争力。无论您是DBA还是开发工程师,本文都将为您提供从理论到实战的全方位指导,助力构建高效稳定的数据库系统。
1.1 慢SQL的危害与优化必要性
在Oracle数据库中,慢SQL如同隐形的性能杀手:
- 资源消耗:全表扫描导致CPU/I/O资源飙升,可能引发系统级瓶颈。
- 响应延迟:用户请求超时,影响业务连续性(如电商系统订单查询超时导致客户流失)。
- 并发冲突:长事务占用锁资源,引发死锁或阻塞。
优化目标:通过技术手段将查询响应时间降低90%,同时减少资源消耗。
2 Oracle慢SQL优化实战
2.1 基础篇:理解执行计划
2.1.1 执行计划的核心作用
执行计划是Oracle优化器生成的查询步骤蓝图,包含以下关键信息:
- 操作类型:如
TABLE ACCESS FULL(全表扫描)、INDEX RANGE SCAN(索引范围扫描)。 - 成本估算:
Cost值反映优化器预估的资源消耗。 - 数据流动:通过缩进层级判断操作顺序(缩进越深执行越早)。
示例命令:
-- 生成执行计划
EXPLAIN PLAN FOR SELECT * FROM sh.sales s WHERE s.cust_id =1660 and s.amount_sold > 1000 -- 查看格式化执行计划
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);注意:示例sql要在同一个sql窗口执行,否者会报错:Error: cannot fetch last explain plan from PLAN_TABLE
2.1.2 典型低效执行计划解析
执行结果如下图:
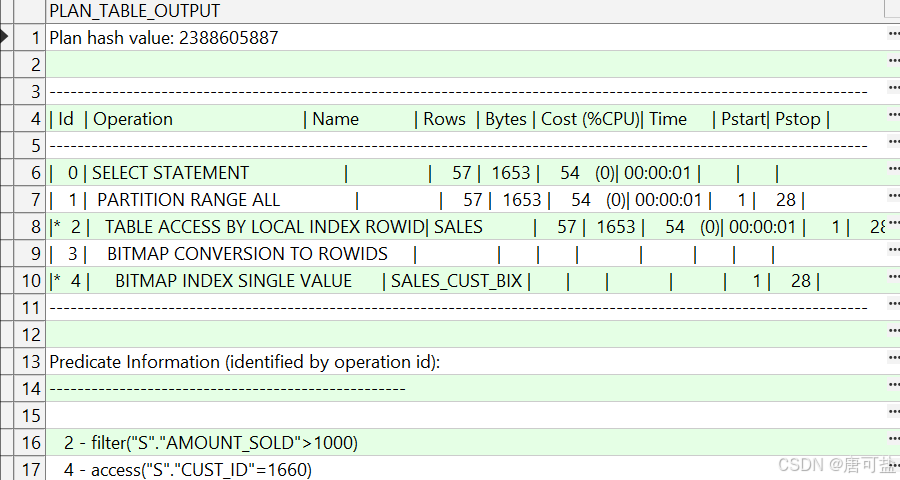
问题点:
2.1.2.1 执行计划分析框架
1. 访问路径分析
- 全表扫描(TABLE ACCESS FULL)
若执行计划显示对SH.SALES表的全表扫描,说明未有效利用索引。需检查:- 过滤条件选择性:
CUST_ID=1660和AMOUNT_SOLD>1000的过滤效果。若返回行数占表总行数比例较高(如>5%),优化器可能认为全表扫描成本更低。 - 索引缺失:若
CUST_ID或AMOUNT_SOLD无索引,需考虑创建联合索引(CUST_ID, AMOUNT_SOLD)。
- 过滤条件选择性:
- 索引扫描(INDEX RANGE SCAN)
若使用索引(如SALES_CUST_IDX),需确认:- 索引列顺序:若索引为
(CUST_ID, AMOUNT_SOLD),可直接通过索引过滤;若仅为CUST_ID,则需回表(TABLE ACCESS BY INDEX ROWID)后再过滤AMOUNT_SOLD。 - 索引跳跃扫描(INDEX SKIP SCAN):若索引列顺序不合理(如
(AMOUNT_SOLD, CUST_ID)),可能导致低效。
- 索引列顺序:若索引为
2. 统计信息准确性
- 检查表
SH.SALES的统计信息是否最新(LAST_ANALYZED时间)。 - 验证
CUST_ID=1660的实际数据分布:
SELECT COUNT(*) FROM SH.SALES WHERE CUST_ID=1660;
SELECT COUNT(*) FROM SH.SALES WHERE CUST_ID=1660 AND AMOUNT_SOLD>1000;3. 执行计划关键指标
- COST值:优化器预估的执行成本。若COST过高(如>100),需优化访问路径。
- ROWS列:预估返回行数。若实际行数与预估差异大(如预估100行但实际10000行),需更新统计信息。
- BYTES列:预估数据传输量。若值过大,可能需减少
SELECT *的字段。
2.1.2.2 优化建议
1. 索引优化
创建联合索引:
CREATE INDEX IDX_SALES_CUST_AMT ON SH.SALES(CUST_ID, AMOUNT_SOLD);确保索引列顺序能同时支持
CUST_ID和AMOUNT_SOLD的过滤。函数索引(可选):
若AMOUNT_SOLD常用于范围查询,可考虑压缩或分区策略。
2. SQL改写
减少数据访问量:
避免SELECT *,明确指定所需字段:
SELECT s.prod_id, s.quantity_sold
FROM SH.SALES s
WHERE s.cust_id=1660 AND s.amount_sold>1000;- 绑定变量(高并发场景):
若CUST_ID为动态值,使用绑定变量避免硬解析:
SELECT * FROM SH.SALES s
WHERE s.cust_id=:cust_id AND s.amount_sold>1000;2.2 进阶篇:索引优化策略
2.2.1 索引类型与选择
| 索引类型 | 适用场景 | 示例命令 |
|---|---|---|
| B-Tree索引 | 高基数列(如用户ID) | CREATE INDEX idx_emp_id ON employees(emp_id); |
| 位图索引 | 低基数列(如性别、状态) | CREATE BITMAP INDEX idx_gender ON employees(gender); |
| 函数索引 | 列上存在函数操作 | CREATE INDEX idx_hire_year ON employees(EXTRACT(YEAR FROM hire_date)); |
| 联合索引 | 多条件查询(遵循左前缀原则) | CREATE INDEX idx_dept_sal ON employees(department, salary); |
2.2.2 索引失效的常见原因
隐式类型转换:
-- 错误示例:字符串与数字比较
SELECT * FROM orders WHERE order_id = '12345'; -- order_id为NUMBER类型优化:显式转换或统一数据类型。
索引列使用函数:
-- 错误示例:索引列上使用TO_CHAR
SELECT * FROM employees WHERE TO_CHAR(hire_date, 'YYYY-MM') = '2025-07';优化:创建函数索引或改写查询。
2.2.3 实战案例:联合索引优化
场景:查询部门为'IT'且薪资>5000的员工。
优化前(全表扫描,耗时2秒):
SELECT * FROM employees WHERE department = 'IT' AND salary > 5000;优化后(索引范围扫描,耗时0.1秒):
CREATE INDEX idx_dept_sal ON employees(department, salary);
-- 执行计划显示INDEX RANGE SCAN2.3 高级篇:SQL改写与执行计划调整
2.3.1 避免全表扫描的技巧
提前过滤条件:
-- 错误示例:先连接后过滤
SELECT * FROM employees e
JOIN departments d ON e.dept_id = d.dept_id
WHERE d.location = 'New York';-- 优化:在JOIN前过滤
SELECT * FROM departments d
WHERE d.location = 'New York'
JOIN employees e ON e.dept_id = d.dept_id;- 使用EXISTS替代IN:
-- 高效示例:当子查询结果集较大时
SELECT * FROM employees e
WHERE EXISTS (SELECT 1 FROM departments d WHERE d.dept_id = e.dept_id AND d.budget > 1000000);2.3.2. 强制执行计划:HINT的使用
-- 强制使用NESTED LOOPS连接
SELECT /*+ USE_NL(e d) */ *
FROM employees e, departments d
WHERE e.dept_id = d.dept_id AND d.location = 'New York';2.3.3. 案例:多表连接优化
场景:电商系统订单查询缓慢(响应时间10秒)。
问题:
- 执行计划显示
HASH JOIN消耗大量内存。 - 临时表空间因排序操作膨胀。
优化步骤:
1. 创建覆盖索引:
CREATE INDEX idx_order_date ON orders(order_date, status);2. 改写SQL:
SELECT o.order_id, o.total_amount
FROM orders o
WHERE o.order_date >= TO_DATE('2025-07-01', 'YYYY-MM-DD')AND o.status = 'COMPLETED';3. 效果:
- 执行时间降至0.5秒。
- 临时表空间使用率下降80%。
最好效果图
2.4 实战篇:性能监控与持续优化
2.4.1. 监控工具与实践
- AWR报告:分析历史性能数据,识别高峰时段瓶颈。
- ASH视图:实时监控活动会话,定位长事务。
-- 查询当前活跃的高负载SQL
SELECT sql_id, sql_text, elapsed_time
FROM v$sql
WHERE elapsed_time > 1000000; -- 耗时超过1秒2.4.2. 自动化优化:Oracle 21c新特性
- 自动索引(Auto Indexing):
-- 启用自动索引
BEGINDBMS_AUTO_INDEX.CONFIGURE('AUTO_INDEX_MODE', 'IMPLEMENT');
END;- 实时统计信息:
Oracle 21c支持动态维护统计信息,减少人工干预。