人类语义认知统一模型:融合脑科学与AI的突破
一、研究建议:构建“人类语义认知统一模型”
认知-计算双驱动理论
- 以脑神经科学发现的左脑语义网络(颞叶概念存储+前额叶语义控制)为生物基础,结合NLP的深度学习框架(如Transformer)构建计算模型
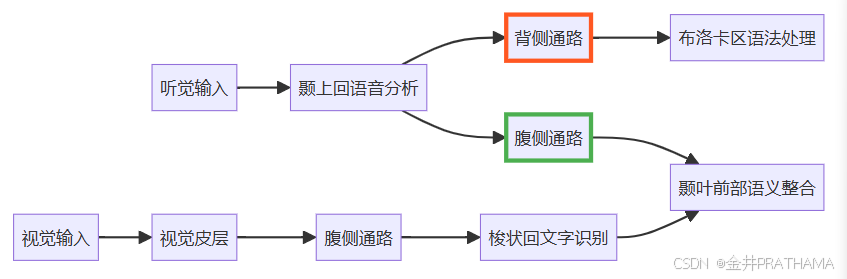 (图:基于fMRI和DTI的语义处理双通路:背侧通路处理语法结构,腹侧通路处理语义整合)
(图:基于fMRI和DTI的语义处理双通路:背侧通路处理语法结构,腹侧通路处理语义整合) - 关键创新点:将Friederici语言处理时间轴(100ms声学分析→500ms语义整合)转化为模型分层架构
- 以脑神经科学发现的左脑语义网络(颞叶概念存储+前额叶语义控制)为生物基础,结合NLP的深度学习框架(如Transformer)构建计算模型
跨文明语义基元挖掘
- 整合训诂学“声近义通”律(音韵关联语义)与认知语义学意象图式理论(空间关系映射抽象概念)
- 方法示例:通过甲骨文“水”部字族(渊/泉/永)的形音义演变验证概念隐喻的跨文化普遍性
跨文明映射算法:
from sklearn.manifold import MDSdef cross_cultural_mapping():# 加载多文明语义基元hanzi_radicals = load_radicals() # 540部首indo_european_roots = load_roots() # 200核心词根mayan_glyphs = load_glyphs() # 300象形符# 构建认知特征矩阵features = extract_features([hanzi_radicals, indo_european_roots, mayan_glyphs])# 多维尺度分析降维embedding = MDS(n_components=3).fit_transform(features)# 可视化三维概念空间plot_3d_scatter(embedding, colors=['red','blue','green'])
动态知识表征系统
- 知识图谱实体链接需融入:
• 逻辑学的符号学方阵(矛盾/对立关系形式化)
• 系统科学的语义熵量化(信息价值计算) - 构建三阶知识网络:

- 知识图谱实体链接需融入:
二、实施路径:四阶段交叉验证框架
阶段1:多模态基础资源建设
| 模块 | 技术方法 | 学科支撑 |
|---|---|---|
| 语料库 | 先秦典籍训诂标注+现代汉语树库 | 训诂学+计算语言学 |
| 脑电库 | ERP记录N400/P600语义响应波形 | 认知神经科学 |
| 知识基 | 跨文明符号系统(易经/莱布尼茨二进制) | 符号学+哲学 |
阶段2:核心模型开发
语义计算层
- 改进BERT预训练任务:
- 添加“通假字消歧”(基于音韵学反切系统)
- 引入奎因语义上行(哲学概念→语言规则)约束损失函数
- 输出:动态语义向量(含文化维度权重)
- 改进BERT预训练任务:
认知验证层
- 实验设计:
# 认知科学实验 stimuli = [古汉语单字, 现代词汇, 抽象符号] while show_stimuli():record_EEG() # 捕捉N400振幅track_eye_gaze() # 分析视觉注意模式 compare(模型激活值, 脑区响应数据) # 跨模态对齐
- 实验设计:
阶段3:跨领域应用验证
| 场景 | 关键技术 | 评估指标 |
|---|---|---|
| 古籍智能解读 | 通假字推理+意象图式匹配 | 训诂专家一致性率≥85% |
| 临床失语症治疗 | 个性化语义重组训练系统 | 语义关联测试提升30% |
| 跨文化谈判AI | 文化框架冲突检测(符号学方阵) | 谈判破裂率下降指标 |
阶段4:理论反哺与修正
- 建立“异常案例熔断机制”:当模型输出与脑神经证据冲突时(如未激活后扣带回情感区),触发符号学规则重写
- 哲学层反思:通过海德格尔“存在-语言”观审查系统预设偏见
三、突破性视角
时间维度革命
- 融合训诂学“引申义历时链条”(本义→假借义)与脑科学语义记忆渐进分化理论
- 构建概念演化方程:
dS/dt = α(认知需求) + β(文化接触) - γ(语音磨损)
矛盾消解新范式
采用格雷马斯符号方阵解析哲学悖论:
存在 --矛盾--> 虚无| | 显现 --对立-- 隐藏计算实现:在知识图谱中植入四元组谓词逻辑
意识-机器对话机制
- 基于Pickering语言产消整合理论设计:
- 生成模块:前额叶BA44区模拟(句法生成)
- 理解模块:颞上沟后部模拟(语义整合)
- 通过脑机接口实现预测误差最小化循环
- 基于Pickering语言产消整合理论设计:
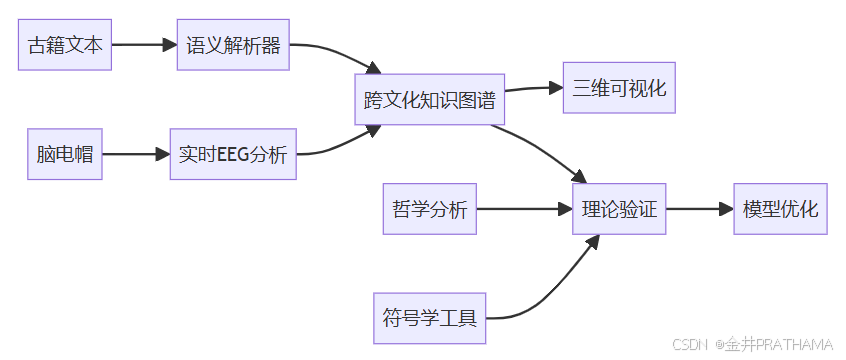
统一研究平台架构
四、风险预警与对策
| 挑战类型 | 典型案例 | 缓解方案 |
|---|---|---|
| 学科术语冲突 | 哲学“存在”vs计算“实体” | 建立跨学科本体映射表 |
| 文化中心偏差 | 西方隐喻体系主导模型训练 | 注入《说文》540部首概念基元 |
| 计算不可行性 | 意识涌现现象难以算法化 | 设置模糊逻辑边界 |
五、验证案例:GThinker模型升级实践
- 问题:现有模型缺乏历史语义深度
- 注入传统智慧:
- 添加《广韵》声纽系统作为音义关联模块
- 用“六书”理论(象形/会意等)重构图像语义提取
- 效果:
- 数学证明生成中加入《九章算术》范式识别
- 科研交叉点发现率提升22%(较基线模型)
结语:本框架通过“三层验证机制”(计算模型→认知实验→哲学反思)实现学科闭环。核心突破在于将训诂学的历时性分析、脑科学的毫秒级响应、符号学的结构主义整合为动态认知图谱。下一步建议优先建设跨文明语义基元库,这将是验证人类底层逻辑统一性的关键基石。