Spark02 - SparkContext介绍
一、应用入口:SparkContext
Spark Application 程序入口为:SparkContext,任何一个应用首先需要构建 SparkContext 对象,如下两步构建:
- 第一步、创建 SparkConf 对象
- 设置 Spark Application 基本信息,比如应用的名称 AppName 和应用运行 Master
- 第二步、基于 SparkConf 对象,创建 SparkContext 对象

# Import SparkConf class into program
from pyspark import SparkConf
# Import SparkContext and SparkSession classes
from pyspark import SparkContext # Spark
from pyspark.sql import SparkSession # Spark SQLif __name__=="__main__":# local[*]: run Spark in local mode with as many working processors as logical cores on your machine# If we want Spark to run locally with 'k' worker threads, we can specify as "local[k]".master = "local[*]"# The `appName` field is a name to be shown on the Spark cluster UI pageapp_name = "RDD-basics"# Setup configuration parameters for Sparkspark_conf = SparkConf().setMaster(master).setAppName(app_name)# Method 2: Getting or instantiating a SparkContextsc = SparkContext.getOrCreate(spark_conf)sc.setLogLevel('ERROR')data_list = [1, 2, 3, 3]rdd = sc.parallelize(data_list)print(rdd.collect())二、spark实现wordCount程序的流程图
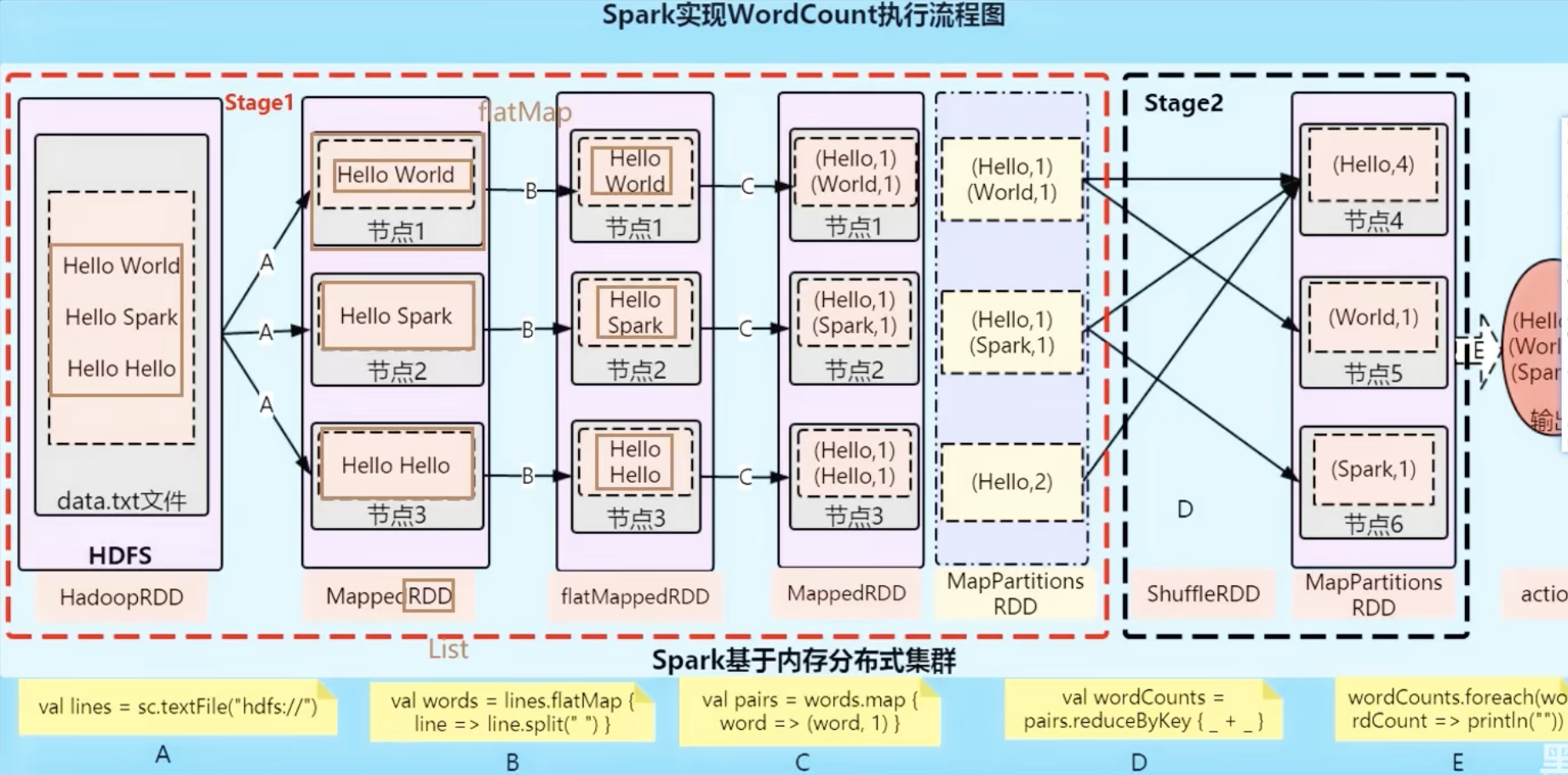
三、Spark集群角色
当spark application运行在集群上时,主要有四个部分组成,如下图所示:
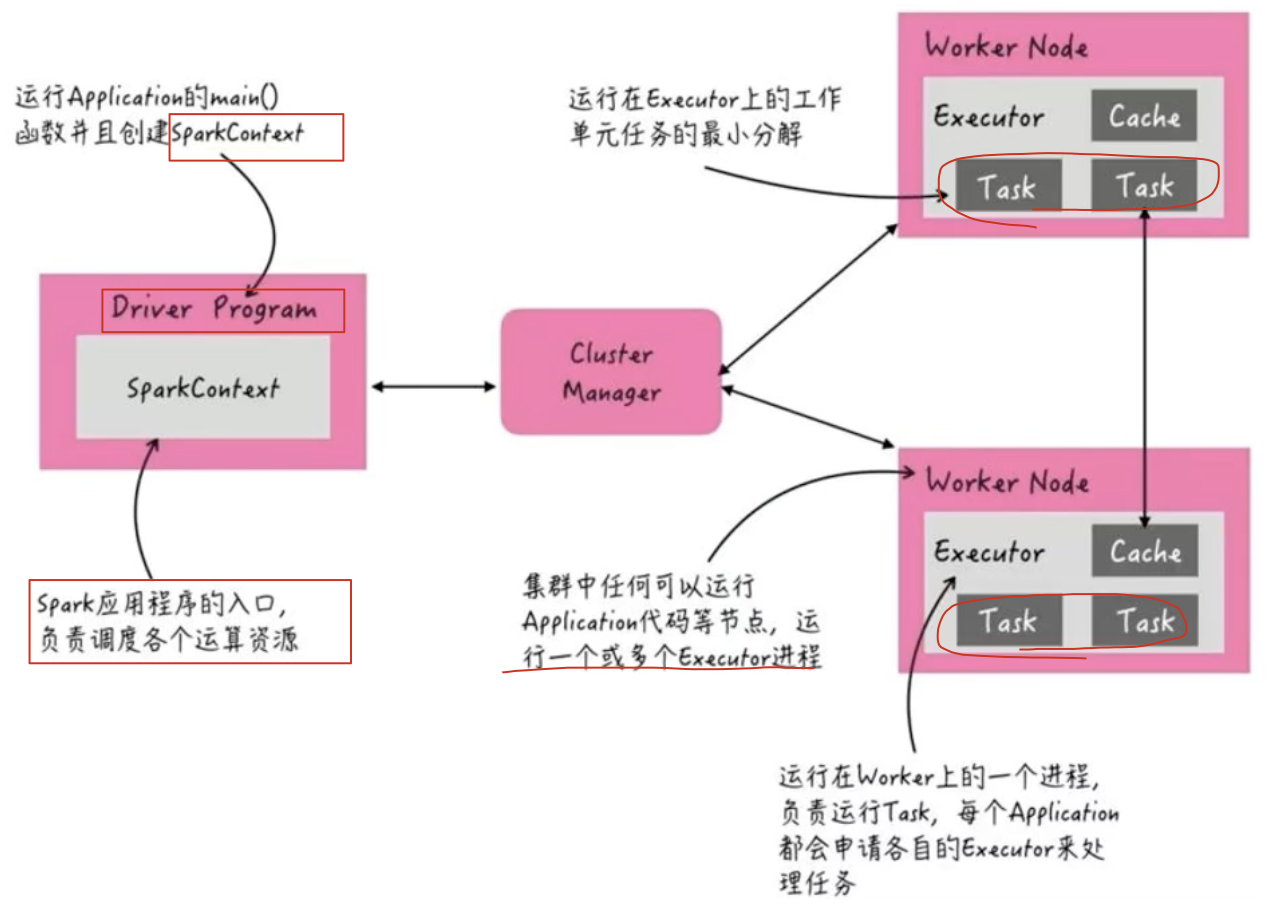
1)、Master (被yarn中的 ResourceManager 代替):集群大管家,整个集群的资源管理和分配
2)、Worker (被yarn中的 NodeManager 代替):单个机器的管家,负责在单个服务器上提供运行容器,管理当前机器的资源.
3)、Driver:单个 Spark 任务的管理者,管理 Executor 的任务执行和任务分解分配,类似 YARN 的 ApplicationMaster;
4)、Executor:具体干活的进程,Spark 的工作任务 (Task) 都由 Executor 来负责执行.
【注意】:
只有干活的代码是excutor运行的,其余剩下的都是由driver运行的。
四、分布式代码执行分析

对应的流程如图:
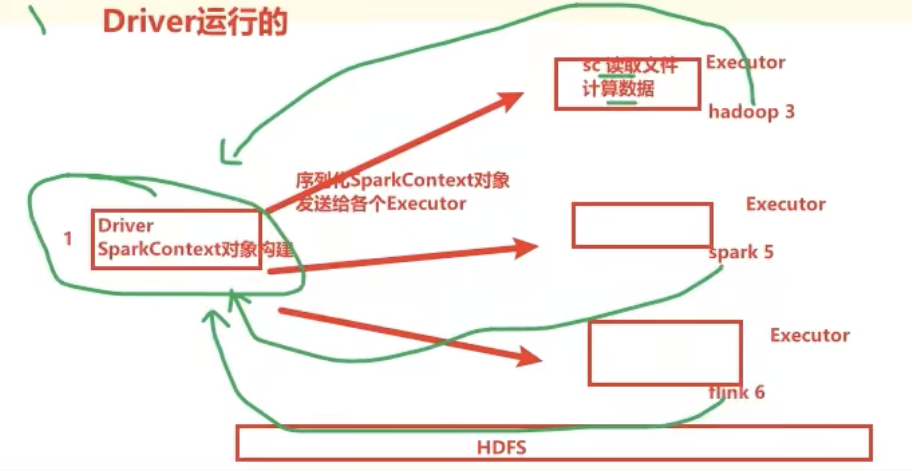
代码从Driver开始,到Driver结束,中间是excutor分布式运行。
写的是一份代码,但是底层执行的是好多个excutor(机器)
五、Python on Spark执行原理
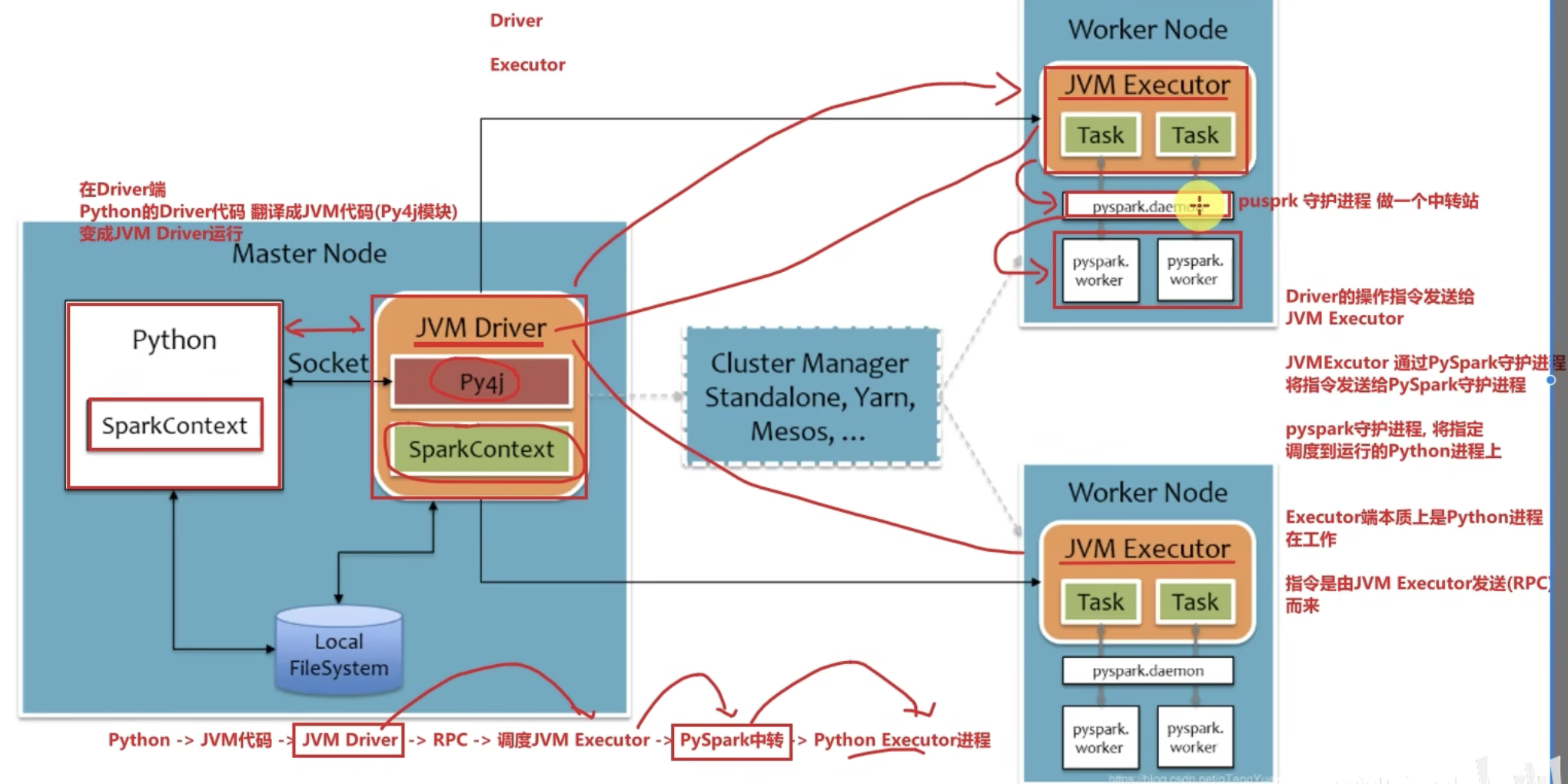
driver由JVM driver运行(翻译),excutor由python excutor运行。
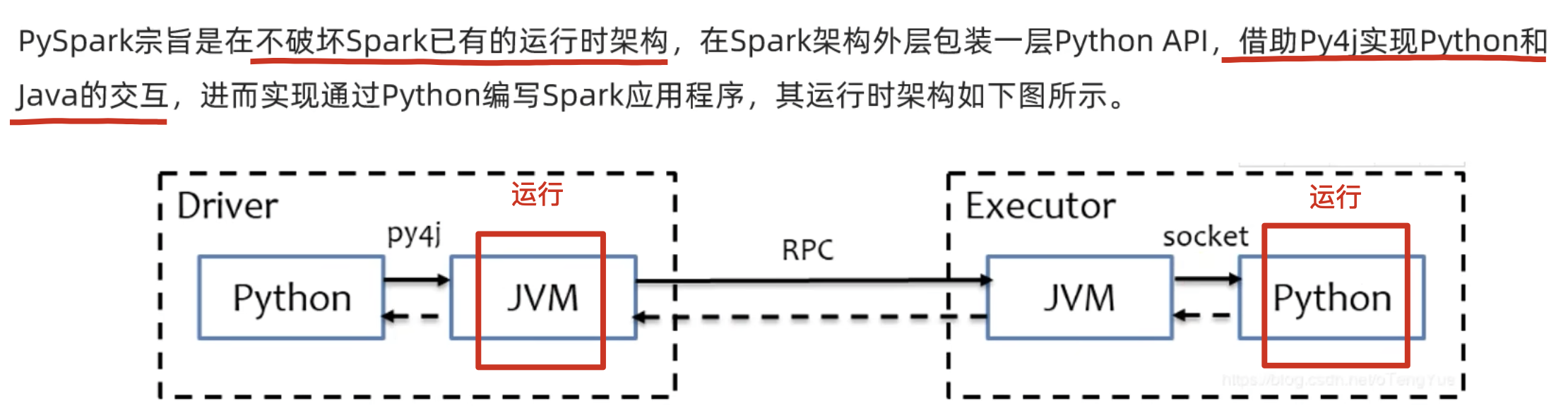
- Driver翻译过去
- Excutor中转调度。