【网络与爬虫 52】Scrapyd-k8s集群化爬虫部署:Kubernetes原生分布式爬虫管理平台实战指南
关键词: Scrapyd-k8s, Kubernetes爬虫部署, 容器化爬虫管理, 云原生数据采集, 分布式爬虫集群, Docker爬虫, K8s工作负载, Scrapy部署自动化
摘要: 本文深入解析Scrapyd-k8s这一革命性的Kubernetes原生爬虫管理平台,通过费曼学习法从传统部署痛点出发,详细讲解如何利用容器编排技术实现爬虫的自动化部署、弹性扩缩容和高可用集群管理。涵盖从基础概念到生产实战的完整指南,帮助开发者构建现代化、可扩展的分布式爬虫系统。
文章目录
- 开篇:为什么传统爬虫部署让人头疼?
- 什么是Scrapyd-k8s?容器化爬虫管理的革命
- 核心概念理解
- 架构设计理念
- 传统Scrapyd vs Scrapyd-k8s:为什么需要升级?
- 传统Scrapyd的局限性
- Scrapyd-k8s的优势
- Scrapyd-k8s核心组件深度解析
- 1. 控制器(Controller)组件
- 2. 任务模板(Job Template)
- 3. 存储层集成
- 实战部署:从零搭建Scrapyd-k8s集群
- 第一步:准备Kubernetes环境
- 第二步:安装Scrapyd-k8s
- 第三步:配置自定义资源定义(CRD)
- 第四步:部署第一个爬虫项目
- 第五步:创建爬虫任务
- 高级功能配置
- 1. 自动扩缩容配置
- 2. 监控和告警系统
- 3. 持久化存储和数据管理
- 生产环境最佳实践
- 1. 安全性配置
- 2. 网络策略和服务发现
- 3. 资源配额和限制
- 常见问题与解决方案
- 问题1:Pod频繁重启
- 问题2:任务调度失败
- 问题3:数据持久化问题
- 监控和运维
- 1. Prometheus监控配置
- 2. 日志收集和分析
- 性能优化策略
- 1. 资源调优
- 2. 网络优化
- 扩展和集成
- 1. 与数据管道集成
- 2. 自动化CI/CD集成
- 未来发展趋势
- 1. 无服务器架构集成
- 2. AI驱动的智能调度
- 总结与展望
- 核心价值
- 适用场景
- 实施建议
- 参考资料
- 进一步学习资源
- 实施建议
- 参考资料
- 进一步学习资源
开篇:为什么传统爬虫部署让人头疼?
想象一下,你刚刚开发完一个完美的Scrapy爬虫项目,本地测试运行得非常顺畅。然而,当你准备部署到生产环境时,却发现需要面对这样的问题:
- 服务器资源浪费:单台服务器跑几个爬虫,CPU利用率只有20%
- 扩容复杂:数据量增大时,需要手动在多台服务器上部署相同的爬虫
- 监控困难:分散在不同服务器上的爬虫任务难以统一监控和管理
- 故障恢复慢:某台服务器宕机,爬虫任务中断,需要手动迁移
- 环境不一致:开发、测试、生产环境差异导致的"在我机器上能跑"问题
这就像是在古代,你需要骑马在各个村庄之间传递消息,效率低下且容易出错。而Scrapyd-k8s就像是现代的通信网络,让所有的爬虫任务都能在统一的平台上高效运行。
什么是Scrapyd-k8s?容器化爬虫管理的革命
核心概念理解
Scrapyd-k8s是一个专门为Kubernetes环境设计的Scrapy项目管理平台,它将传统的Scrapyd服务容器化,并利用Kubernetes的强大编排能力来管理爬虫的生命周期。
简单来说,如果把爬虫比作工人,传统部署就像是手工作坊,每个工人都在固定的工位上工作。而Scrapyd-k8s就像是现代化的智能工厂,能够根据工作量自动调配工人数量,当某个工位出现问题时能立即安排其他工位接手。
架构设计理念
Scrapyd-k8s采用了云原生的设计理念:
- 微服务架构:将爬虫管理功能拆分为独立的服务组件
- 声明式配置:通过YAML文件描述期望的运行状态
- 自动化运维:Kubernetes自动处理容器的调度、重启和扩缩容
- 资源隔离:每个爬虫任务运行在独立的容器中,互不影响
传统Scrapyd vs Scrapyd-k8s:为什么需要升级?
传统Scrapyd的局限性
传统的Scrapyd虽然为爬虫部署提供了基础的管理能力,但在现代化的数据采集需求面前显得力不从心:
# 传统Scrapyd部署的问题示例
# 1. 单点故障风险
scrapyd_server = "http://192.168.1.100:6800" # 服务器宕机=全部停止# 2. 手动扩容
servers = ["http://192.168.1.100:6800","http://192.168.1.101:6800", # 手动添加新服务器"http://192.168.1.102:6800" # 配置管理复杂
]# 3. 资源利用率低
# CPU: 20%, Memory: 30% - 大量资源闲置
Scrapyd-k8s的优势
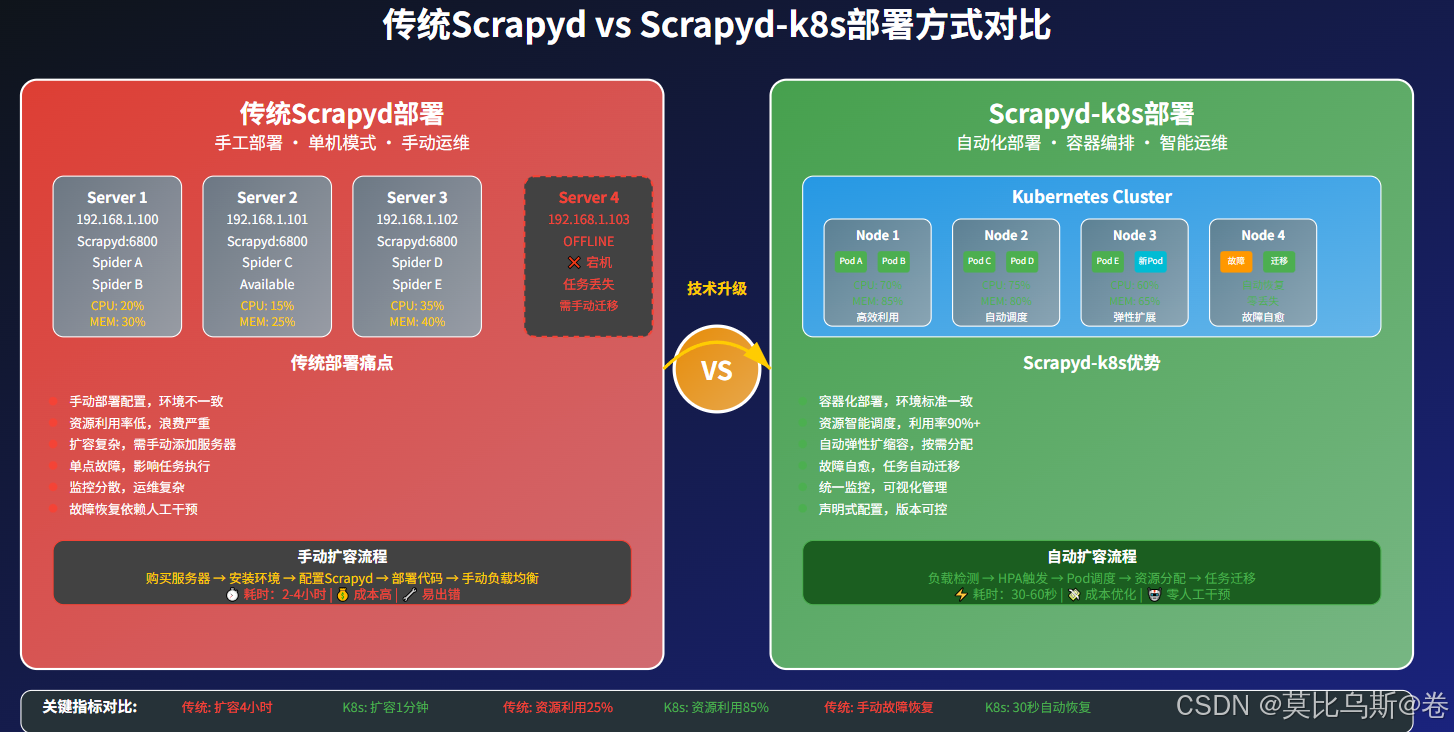
| 特性 | 传统Scrapyd | Scrapyd-k8s |
|---|---|---|
| 部署复杂度 | 需要在每台服务器手动部署 | 声明式YAML一键部署 |
| 扩缩容 | 手动添加服务器 | 自动弹性扩缩容 |
| 故障恢复 | 手动迁移任务 | 自动故障转移 |
| 资源利用 | 固定资源分配 | 动态资源调度 |
| 监控管理 | 分散式监控 | 统一监控面板 |
| 环境一致性 | 依赖服务器环境 | 容器化标准环境 |
Scrapyd-k8s核心组件深度解析
1. 控制器(Controller)组件
控制器是Scrapyd-k8s的大脑,负责监听爬虫任务的创建、更新和删除事件:
# scrapyd-controller.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: scrapyd-controllernamespace: scraping
spec:replicas: 1selector:matchLabels:app: scrapyd-controllertemplate:metadata:labels:app: scrapyd-controllerspec:containers:- name: controllerimage: scrapyd-k8s/controller:latestports:- containerPort: 6800env:- name: SCRAPYD_K8S_NAMESPACEvalue: "scraping"- name: SCRAPYD_K8S_JOB_TEMPLATEvalue: "/etc/scrapyd-k8s/job-template.yaml"
2. 任务模板(Job Template)
定义爬虫任务在Kubernetes中的运行规范:
# job-template.yaml
apiVersion: batch/v1
kind: Job
metadata:name: "{{ .JobName }}"namespace: scraping
spec:template:spec:restartPolicy: Nevercontainers:- name: scrapy-spiderimage: "{{ .Image }}"command: ["scrapy", "crawl", "{{ .Spider }}"]env:- name: JOB_IDvalue: "{{ .JobID }}"resources:requests:memory: "256Mi"cpu: "100m"limits:memory: "512Mi"cpu: "500m"
3. 存储层集成
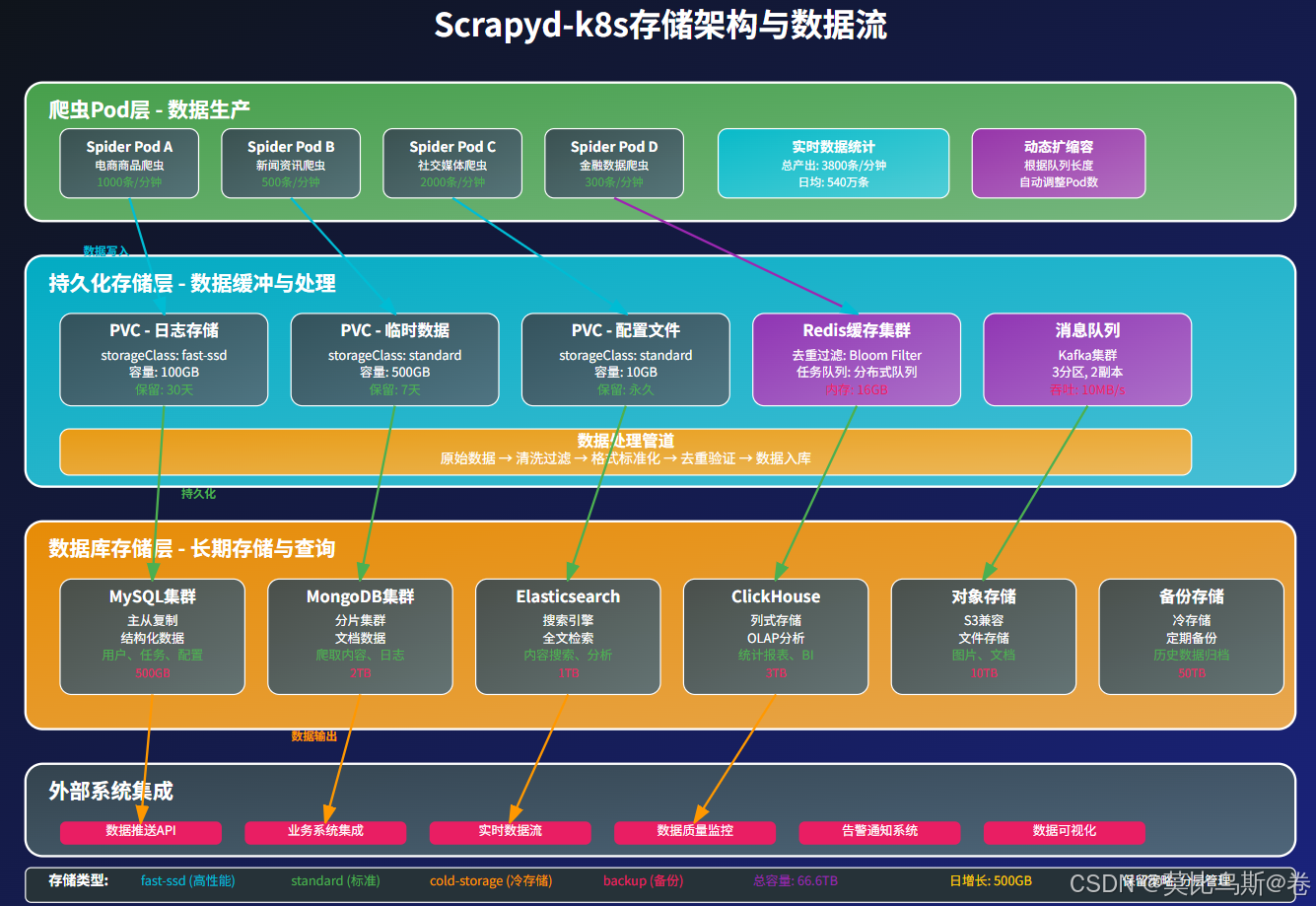
Scrapyd-k8s支持多种存储后端:
# 配置持久化存储
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: scrapyd-data
spec:accessModes:- ReadWriteOnceresources:requests:storage: 10GistorageClassName: fast-ssd
实战部署:从零搭建Scrapyd-k8s集群
第一步:准备Kubernetes环境
# 1. 检查Kubernetes集群状态
kubectl cluster-info
kubectl get nodes# 2. 创建专用命名空间
kubectl create namespace scraping# 3. 设置默认命名空间
kubectl config set-context --current --namespace=scraping
第二步:安装Scrapyd-k8s
# 使用Helm安装(推荐方式)
helm repo add scrapyd-k8s https://scrapyd-k8s.github.io/helm-charts
helm repo update# 安装scrapyd-k8s
helm install scrapyd scrapyd-k8s/scrapyd-k8s \--namespace scraping \--set image.tag="latest" \--set service.type="LoadBalancer" \--set persistence.enabled=true \--set persistence.size="20Gi"
第三步:配置自定义资源定义(CRD)
# scrapydjob-crd.yaml
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:name: scrapydjobs.scraping.io
spec:group: scraping.ioversions:- name: v1served: truestorage: trueschema:openAPIV3Schema:type: objectproperties:spec:type: objectproperties:project:type: stringspider:type: stringsettings:type: objectjobid:type: stringstatus:type: objectproperties:phase:type: stringstartTime:type: stringfinishTime:type: stringscope: Namespacednames:plural: scrapydjobssingular: scrapydjobkind: ScrapydJob
第四步:部署第一个爬虫项目
# 准备爬虫项目 - myspider/spiders/example.py
import scrapyclass ExampleSpider(scrapy.Spider):name = 'example'start_urls = ['http://quotes.toscrape.com']def parse(self, response):for quote in response.css('div.quote'):yield {'text': quote.css('span.text::text').get(),'author': quote.css('span small::text').get(),'tags': quote.css('div.tags a.tag::text').getall(),}next_page = response.css('li.next a::attr(href)').get()if next_page:yield response.follow(next_page, self.parse)
# Dockerfile
FROM python:3.9-slimWORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txtCOPY . .
RUN pip install -e .CMD ["scrapyd"]
# 构建和推送镜像
docker build -t myregistry/myspider:v1.0 .
docker push myregistry/myspider:v1.0
第五步:创建爬虫任务
# spider-job.yaml
apiVersion: scraping.io/v1
kind: ScrapydJob
metadata:name: example-spider-jobnamespace: scraping
spec:project: myspiderspider: exampleimage: myregistry/myspider:v1.0settings:DOWNLOAD_DELAY: 1CONCURRENT_REQUESTS: 16USER_AGENT: "MySpider 1.0"resources:requests:memory: "256Mi"cpu: "100m"limits:memory: "1Gi"cpu: "1000m"
# 提交爬虫任务
kubectl apply -f spider-job.yaml# 查看任务状态
kubectl get scrapydjobs
kubectl describe scrapydjob example-spider-job
高级功能配置
1. 自动扩缩容配置
# hpa.yaml - 水平Pod自动扩缩容
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:name: scrapyd-hpa
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: scrapyd-controllerminReplicas: 2maxReplicas: 10metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 70- type: Resourceresource:name: memorytarget:type: UtilizationaverageUtilization: 80
2. 监控和告警系统
# prometheus-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:name: prometheus-config
data:prometheus.yml: |global:scrape_interval: 15sscrape_configs:- job_name: 'scrapyd-k8s'kubernetes_sd_configs:- role: podnamespaces:names:- scrapingrelabel_configs:- source_labels: [__meta_kubernetes_pod_label_app]action: keepregex: scrapyd-controller
3. 持久化存储和数据管理
# storage-class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: scrapyd-storage
provisioner: kubernetes.io/aws-ebs
parameters:type: gp2fsType: ext4
allowVolumeExpansion: true
---
# pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: scrapyd-logs
spec:accessModes:- ReadWriteManyresources:requests:storage: 50GistorageClassName: scrapyd-storage
生产环境最佳实践
1. 安全性配置
# rbac.yaml - 基于角色的访问控制
apiVersion: v1
kind: ServiceAccount
metadata:name: scrapyd-operatornamespace: scraping
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: scrapyd-operator
rules:
- apiGroups: [""]resources: ["pods", "services", "configmaps"]verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
- apiGroups: ["batch"]resources: ["jobs"]verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
- apiGroups: ["scraping.io"]resources: ["scrapydjobs"]verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: scrapyd-operator
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: scrapyd-operator
subjects:
- kind: ServiceAccountname: scrapyd-operatornamespace: scraping
2. 网络策略和服务发现
# network-policy.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:name: scrapyd-network-policy
spec:podSelector:matchLabels:app: scrapydpolicyTypes:- Ingress- Egressingress:- from:- namespaceSelector:matchLabels:name: monitoringports:- protocol: TCPport: 6800egress:- to: [] # 允许所有出站流量(爬虫需要访问外部网站)ports:- protocol: TCPport: 80- protocol: TCPport: 443
3. 资源配额和限制
# resource-quota.yaml
apiVersion: v1
kind: ResourceQuota
metadata:name: scraping-quotanamespace: scraping
spec:hard:requests.cpu: "10"requests.memory: 20Gilimits.cpu: "20"limits.memory: 40Gipods: "50"persistentvolumeclaims: "10"
---
apiVersion: v1
kind: LimitRange
metadata:name: scraping-limits
spec:limits:- default:cpu: "500m"memory: "1Gi"defaultRequest:cpu: "100m"memory: "256Mi"type: Container
常见问题与解决方案
问题1:Pod频繁重启
症状:爬虫Pod不断重启,任务无法完成
原因分析:
- 内存限制过低,爬虫被OOMKilled
- 网络问题导致健康检查失败
- 爬虫代码存在内存泄漏
解决方案:
# 调整资源限制
resources:requests:memory: "512Mi" # 增加内存请求cpu: "200m"limits:memory: "2Gi" # 增加内存限制cpu: "1000m"# 添加健康检查
livenessProbe:httpGet:path: /port: 6800initialDelaySeconds: 30periodSeconds: 10timeoutSeconds: 5failureThreshold: 3readinessProbe:httpGet:path: /port: 6800initialDelaySeconds: 5periodSeconds: 5
问题2:任务调度失败
症状:ScrapydJob资源创建成功,但Pod未启动
排查步骤:
# 1. 查看事件日志
kubectl get events --sort-by=.metadata.creationTimestamp# 2. 检查控制器日志
kubectl logs -l app=scrapyd-controller# 3. 查看节点资源状态
kubectl describe nodes
kubectl top nodes# 4. 检查镜像拉取
kubectl describe pod <pod-name>
问题3:数据持久化问题
解决方案:
# 使用StatefulSet管理有状态爬虫
apiVersion: apps/v1
kind: StatefulSet
metadata:name: scrapyd-stateful
spec:serviceName: scrapyd-headlessreplicas: 3template:spec:containers:- name: scrapydimage: scrapyd-k8s:latestvolumeMounts:- name: datamountPath: /var/scrapydvolumeClaimTemplates:- metadata:name: dataspec:accessModes: ["ReadWriteOnce"]resources:requests:storage: 10Gi
监控和运维
1. Prometheus监控配置
# 在爬虫中添加指标收集
from prometheus_client import Counter, Histogram, start_http_server
import time# 定义监控指标
REQUESTS_TOTAL = Counter('scrapy_requests_total', 'Total requests', ['spider', 'status'])
REQUEST_DURATION = Histogram('scrapy_request_duration_seconds', 'Request duration')class PrometheusMiddleware:def __init__(self):start_http_server(8000) # 启动指标服务器def process_request(self, request, spider):request.meta['start_time'] = time.time()return Nonedef process_response(self, request, response, spider):duration = time.time() - request.meta['start_time']REQUEST_DURATION.observe(duration)REQUESTS_TOTAL.labels(spider=spider.name, status=response.status).inc()return response
2. 日志收集和分析
# fluentd-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:name: fluentd-config
data:fluent.conf: |<source>@type kubernetes_logspath /var/log/containers/scrapyd-*.logpos_file /var/log/fluentd-scrapyd.log.postag kubernetes.scrapydformat json</source><filter kubernetes.scrapyd>@type parserkey_name logreserve_data true<parse>@type json</parse></filter><match kubernetes.scrapyd>@type elasticsearchhost elasticsearch.logging.svc.cluster.localport 9200index_name scrapyd-logs</match>
性能优化策略
1. 资源调优
# 针对不同类型爬虫的资源配置
apiVersion: v1
kind: ConfigMap
metadata:name: spider-profiles
data:lightweight.yaml: |resources:requests: { cpu: "50m", memory: "128Mi" }limits: { cpu: "200m", memory: "512Mi" }heavy.yaml: |resources:requests: { cpu: "500m", memory: "1Gi" }limits: { cpu: "2000m", memory: "4Gi" }gpu.yaml: |resources:requests: { cpu: "1000m", memory: "2Gi", nvidia.com/gpu: 1 }limits: { cpu: "4000m", memory: "8Gi", nvidia.com/gpu: 1 }
2. 网络优化
# 爬虫网络优化配置
DOWNLOAD_DELAY = 0.5
RANDOMIZE_DOWNLOAD_DELAY = 0.5
CONCURRENT_REQUESTS = 32
CONCURRENT_REQUESTS_PER_DOMAIN = 8# 启用HTTP/2支持
DOWNLOADER_MIDDLEWARES = {'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}# 连接池优化
DOWNLOAD_TIMEOUT = 180
DOWNLOAD_WARNSIZE = 0
DOWNLOAD_MAXSIZE = 0
扩展和集成
1. 与数据管道集成
# Kafka输出管道
import json
from kafka import KafkaProducerclass KafkaPipeline:def __init__(self, kafka_servers, topic):self.kafka_servers = kafka_serversself.topic = topicself.producer = None@classmethoddef from_crawler(cls, crawler):return cls(kafka_servers=crawler.settings.get('KAFKA_SERVERS'),topic=crawler.settings.get('KAFKA_TOPIC'))def open_spider(self, spider):self.producer = KafkaProducer(bootstrap_servers=self.kafka_servers,value_serializer=lambda v: json.dumps(v).encode('utf-8'))def process_item(self, item, spider):self.producer.send(self.topic, dict(item))return itemdef close_spider(self, spider):if self.producer:self.producer.close()
2. 自动化CI/CD集成
# .github/workflows/deploy-spider.yml
name: Deploy Spider to K8s
on:push:branches: [main]paths: ['spiders/**']jobs:deploy:runs-on: ubuntu-lateststeps:- uses: actions/checkout@v2- name: Build and push Docker imagerun: |docker build -t ${{ secrets.REGISTRY }}/spider:${{ github.sha }} .docker push ${{ secrets.REGISTRY }}/spider:${{ github.sha }}- name: Deploy to Kubernetesrun: |sed -i 's|IMAGE_TAG|${{ github.sha }}|g' k8s/spider-job.yamlkubectl apply -f k8s/spider-job.yaml
未来发展趋势
1. 无服务器架构集成
# Knative Serving集成示例
apiVersion: serving.knative.dev/v1
kind: Service
metadata:name: serverless-spider
spec:template:metadata:annotations:autoscaling.knative.dev/minScale: "0"autoscaling.knative.dev/maxScale: "100"spec:containers:- image: scrapyd-k8s/spider:latestenv:- name: SPIDER_NAMEvalue: "example"
2. AI驱动的智能调度
# 基于机器学习的资源预测
class AIScheduler:def __init__(self):self.model = load_model('resource_predictor.h5')def predict_resources(self, spider_name, target_urls):features = self.extract_features(spider_name, target_urls)prediction = self.model.predict(features)return {'cpu': prediction[0],'memory': prediction[1],'estimated_time': prediction[2]}def schedule_job(self, job_spec):resources = self.predict_resources(job_spec['spider'], job_spec['start_urls'])job_spec['resources'] = resourcesreturn self.submit_to_k8s(job_spec)
总结与展望
Scrapyd-k8s代表了爬虫部署技术的重大进步,它将传统的单机部署模式升级为云原生的容器化集群管理。通过本文的深入解析,我们看到了这一技术栈的核心优势:
核心价值
- 标准化部署:容器化确保了环境的一致性
- 弹性扩缩容:根据负载自动调整资源
- 高可用性:自动故障检测和恢复
- 资源优化:更高效的资源利用率
- 运维简化:声明式配置和自动化管理
适用场景
- 大规模数据采集:需要处理海量网站的企业级爬虫
- 实时数据监控:金融、电商价格监控系统
- 多租户平台:SaaS爬虫服务提供商
- 研究机构:学术研究的大规模数据收集
实施建议
- 渐进式迁移:从小规模试点开始,逐步扩展
- 监控先行:建立完善的监控体系后再上线
- 安全第一:确保网络策略和访问控制配置正确
- 性能测试:在生产环境部署前进行充分的压力测试
Scrapyd-k8s不仅仅是一个技术工具,更是现代数据采集架构的重要组成部分。随着云原生技术的不断发展,我们可以期待看到更多智能化、自动化的功能集成,让爬虫开发者能够专注于业务逻辑,而不用担心基础设施的复杂性。
掌握Scrapyd-k8s,就是掌握了未来分布式爬虫系统的核心技术。无论你是爬虫新手还是经验丰富的开发者,这一技术栈都值得深入学习和实践。
参考资料
- Kubernetes官方文档
- Scrapy项目文档
- Helm Charts最佳实践
- Prometheus监控指南
- 云原生应用架构模式
进一步学习资源
-
开源项目:scrapyd-k8s GitHub
-
社区论坛:Kubernetes Slack、Scrapy Community
-
相关课程:云原生技术栈、容器化部署实践
-
大规模数据采集:需要处理海量网站的企业级爬虫
-
实时数据监控:金融、电商价格监控系统
-
多租户平台:SaaS爬虫服务提供商
-
研究机构:学术研究的大规模数据收集
实施建议
- 渐进式迁移:从小规模试点开始,逐步扩展
- 监控先行:建立完善的监控体系后再上线
- 安全第一:确保网络策略和访问控制配置正确
- 性能测试:在生产环境部署前进行充分的压力测试
Scrapyd-k8s不仅仅是一个技术工具,更是现代数据采集架构的重要组成部分。随着云原生技术的不断发展,我们可以期待看到更多智能化、自动化的功能集成,让爬虫开发者能够专注于业务逻辑,而不用担心基础设施的复杂性。
掌握Scrapyd-k8s,就是掌握了未来分布式爬虫系统的核心技术。无论你是爬虫新手还是经验丰富的开发者,这一技术栈都值得深入学习和实践。
参考资料
- Kubernetes官方文档
- Scrapy项目文档
- Helm Charts最佳实践
- Prometheus监控指南
- 云原生应用架构模式
进一步学习资源
- 开源项目:scrapyd-k8s GitHub
- 社区论坛:Kubernetes Slack、Scrapy Community
- 相关课程:云原生技术栈、容器化部署实践
- 实战项目:基于K8s的微服务爬虫平台构建