数据结构5-哈希表
一、哈希表
1、 基本概念
1.1 哈希算法
将数据通过哈希算法映射成一个键值,存取都在同一位置实现数据的高效存储和查找,将时间复杂度尽可能降低至O(1)
1.2 哈希碰撞
多个数据通过哈希算法得到的键值相同,称为产生哈希碰撞
1.3 哈希表
是一种非常高效的数据结构,用于实现键值对(key-value)的存储与快速查找。它通过一种特殊的函数(称为哈希函数,Hash Function)将键(key)映射到一个固定大小的数组的某个索引位置,从而实现接近常数时间复杂度(O(1))的数据存取
2、哈希表应用
2.1 题目
- 构建哈希表存放0-100之间的数据
- 哈希算法选择:将0 - 100之间的数据的个位作为键值
2.2 哈希表的实现
2.2.1 哈希表的创建
基本结构-如图所示
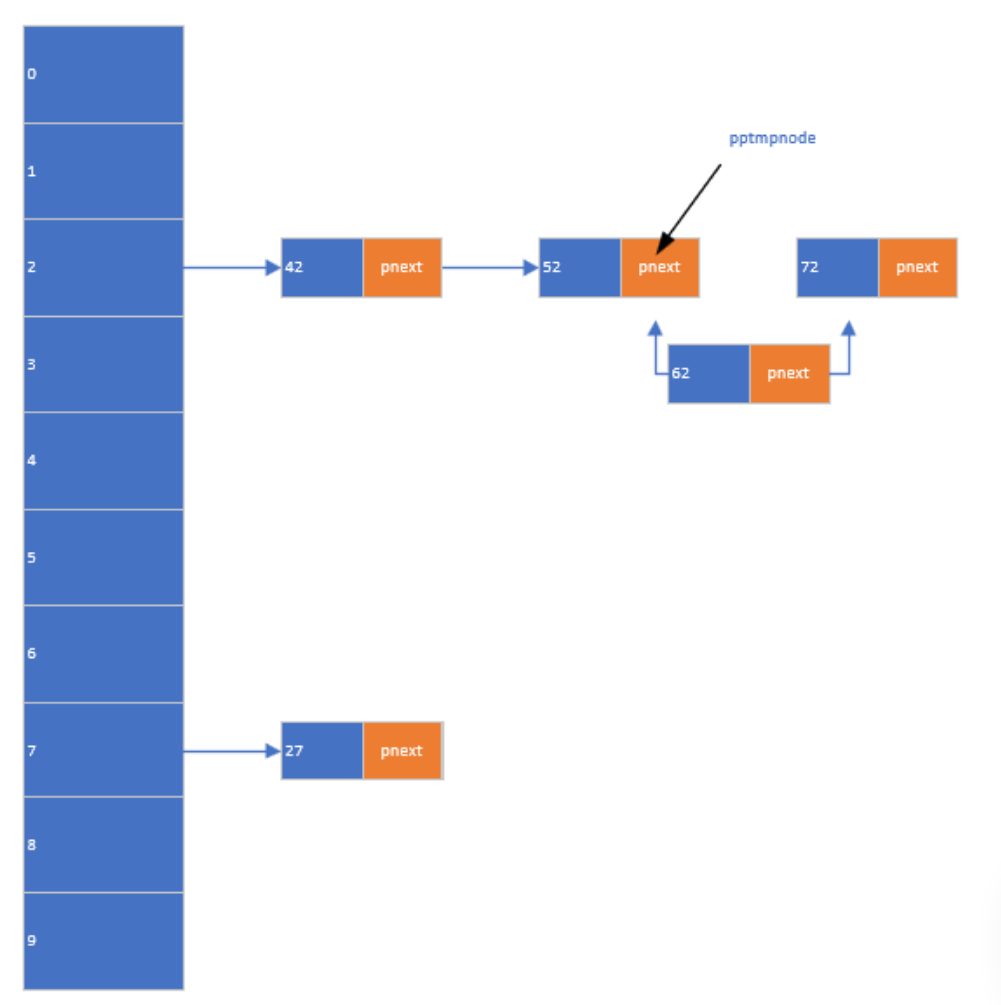 通过对哈希表概念的理解,转化为上图所示。对结构的创建如下:
通过对哈希表概念的理解,转化为上图所示。对结构的创建如下:
1)分析:
首先建立一个二级指针数组,确保哈希表内的键值是连续的(0-9),能够确保任意数得到任意的键值便能够访问其对应的地址。其次创建链表存放数据。
2)代码实现:
#define INDEX 10 //.h文件定义:对象宏
typedef struct node{ //.h文件定义:链表的结构体类型
int data;
struct node *pnext;
}linknode;linknode *phashtable[INDEX]; //.c文件定义:全局变量的指针数组
//其类型与后面的链表类型相匹配
2.2.2 哈希表的数据插入
1)分析:
首先对接收的数据进行处理得到键值。按键值大小插入后续的链表中。
2)代码实现:
int insert_hashtable(int tmpdata)
{
int key = 0;
linknode **pptmpnode = NULL;
linknode *pnewnode = NULL;key = tmpdata % INDEX;
//for后面加分号表示按条件进行但不执行任何语句
for (pptmpnode = &phashtable[key];*pptmpnode != NULL && (*pptmpnode)->data < tmpdata; pptmpnode = &(*pptmpnode)->pnext);//申请链表节点空间,并插入数据
pnewnode = malloc(sizeof(linknode));
if (NULL == pnewnode)
{
perror("fail to malloc");
return -1;
}
pnewnode->data = tmpdata;
pnewnode->pnext = *pptmpnode;
*pptmpnode = pnewnode;return 0;
}
2.2.3 哈希表的遍历
1)分析:
利用循环,外循环对指针数组遍历,内循环若有链表对链表进行循环
2)代码实现:
int show_hashtable(void)
{
int i = 0;
linknode *ptmpnode = NULL;for (i = 0; i < INDEX; i++)
{
printf("%d: ",i);
ptmpnode = phashtable[i];
while (ptmpnode != NULL)
{
printf("%d ",ptmpnode->data);
ptmpnode = ptmpnode->pnext;
}
printf("\n");
}
return 0;
}
2.2.4 哈希表的数据查找
linknode *find_hashtable(int num)
{
linknode *ptmpnode = NULL;
int key = 0;key = num % INDEX;
ptmpnode = phashtable[key];
while (ptmpnode != NULL && ptmpnode->data <= num)
{
if (ptmpnode->data == num)
{
return ptmpnode;
}
ptmpnode = ptmpnode->pnext;
}
return NULL;
}
2.2.5 哈希表的销毁
int destroy_hashtable(void)
{
linknode *ptmpnode = NULL;
linknode *pfreenode = NULL;
int i = 0;for (i = 0; i < INDEX; i++)
{
ptmpnode = phashtable[i];
pfreenode = phashtable[i];
while (ptmpnode != NULL)
{
ptmpnode = ptmpnode->pnext;
free(pfreenode);
pfreenode = ptmpnode;
}
phashtable[i] = NULL;
}
return 0;}
二、排序算法
1、冒泡排序
1.1 概念:
- 时间复杂度为O(n^2)
- 稳定的排序算法
- 排序方法:相邻的两个元素比较,大的向后走,小的向前走;循环找len-1个大的值
1.2 代码实现:


2、选择排序
2.1 概念:
- 时间复杂度O(n^2)
- 不稳定排序算法
- 排序方法:从前到后找最小值与前面的元素交换;找到len-1个最小值,最后一个最大值即排序完成
2.2 代码实现:


3、插入排序
3.1概念:
- 时间复杂度O(n^2) ,如果素组有序时间复杂度降低至O(n)
- 稳定的排序算法
- 排序方法:
- 将数组中的每个元素插入到有序数列中
- 先将要插入的元素取出
- 依次和前面元素比较,比元素大的向后走,直到前一个元素比要插入的元素小,或者到
- 达有序数列开头停止
- 插入元素即可
3.2 代码实现:

4.、希尔排序
4.1 概念:
- 时间复杂度O(nlogn)
- 不稳定的排序算法
- 通过选择不同的步长,将数组拆分成若干个小的数组实现插入排序
- 若干个小的数组称为有序数列后,使得数组中的数据大致有序
- 最后再对整体完成一个插入排序
4.2 代码实现:


5、快速排序
5.1 概念:
- 时间复杂度为O(nlogn)
- 不稳定的排序算法
- 选择左边的作为键值,从后面找一个比键值小的放前面,从前面找一个比键值大的放后面,键值放中间
- 左右两边有元素则递归调用快速排序
5.2代码实现:


6、折半查找(二分查找)
6.1 概念
时间复杂度为O(log)
6.2 代码实现
