操作系统:多线程模型(Multithreading Models)与超线程技术(Hyperthreading)
目录
线程的两种类型
用户线程(User Threads)
内核线程(Kernel Threads)
三种多线程模型(Multithreading Models)
1. Many-to-One Model(多对一模型)
2. One-to-One Model(一对一模型)
3. Many-to-Many Model(多对多模型)
现代处理器中的超线程技术(Hyper-Threading)
如何查看你的电脑是否启用了超线程
线程的两种类型
线程分为“用户线程”和“内核线程”并不是指线程“属于谁”,而是从线程的实现位置和调度权限来看:
-
用户线程 —— 在用户空间(user space)实现,操作系统内核看不见它们;
-
内核线程 —— 在内核空间(kernel space)实现,由操作系统管理和调度。
| 类型 | 描述 | 运行在哪 | 是否被内核感知 |
|---|---|---|---|
| 用户线程(User Threads) | 由用户空间的线程库管理 | 应用程序层面 | 不被内核直接感知 |
| 内核线程(Kernel Threads) | 由操作系统内核管理 | 操作系统内核层 | 由内核调度执行 |
用户线程(User Threads)
用户线程是完全由用户态库(如线程库)创建、管理和调度的线程,操作系统的内核并不知道这些线程的存在。
工作原理:
-
用户线程通过一个线程库(如 POSIX pthread、Java 早期线程模型)来创建和切换;
-
所有调度逻辑在用户空间执行,不涉及内核调用;
-
操作系统只把整个进程当作一个“单一线程”的实体。
| 优点 | 解释 |
|---|---|
| 创建快、切换快 | 不需要系统调用或内核干预,代价低 |
| 跨平台性强 | 只依赖用户空间库,与操作系统无关 |
| 更灵活 | 程序员可以自定义调度策略(例如优先级) |
| 缺点 | 解释 |
|---|---|
| 阻塞问题 | 如果一个用户线程进行 I/O 操作被阻塞,整个进程都会被挂起 |
| 不能并行 | 在多核系统中,所有用户线程仍只能运行在一个 CPU 上(因为内核只看见一个线程) |
| 缺乏内核支持 | 无法使用操作系统提供的线程管理、优先级调度等功能 |
内核线程(Kernel Threads)
内核线程是由操作系统内核创建和调度的线程。内核直接管理这些线程,它们是真正由 CPU 执行的调度单位。
工作原理:
-
每一个内核线程都有独立的栈、寄存器等执行上下文;
-
它们是操作系统调度器直接控制的线程;
-
操作系统可以将不同的内核线程调度到不同的 CPU 核上并行运行。
| 优点 | 解释 |
|---|---|
| 支持并发与并行 | 多核 CPU 上可以将多个线程分配给不同的核心执行 |
| 阻塞互不影响 | 一个线程阻塞时,操作系统可以调度其他线程运行 |
| 使用系统资源更丰富 | 可以结合内核的优先级、实时性调度、CPU 亲和性等特性 |
| 缺点 | 解释 |
|---|---|
| 创建开销较大 | 需要进入内核态,申请系统资源 |
| 切换成本高 | 上下文切换要保存/恢复内核状态和寄存器 |
| 依赖操作系统 | 不同平台线程 API 不同,移植性差 |
为什么要建立“映射关系”?
-
用户线程虽然轻量,但不能独立运行,最终必须借助内核线程;
-
操作系统必须有一种方式把用户线程映射到内核线程;
-
所以,线程模型的核心问题就是:用户线程与内核线程之间如何建立映射关系、共享调度机制。

但映射关系有不同的设计方式 —— 也就是我们接下来要讲的三种多线程模型。
三种多线程模型(Multithreading Models)
这三种模型定义了 用户线程如何与内核线程关联,操作系统如何调度它们。
1. Many-to-One Model(多对一模型)
多个用户线程(User Threads)全部映射到同一个内核线程(Kernel Thread),由线程库在用户空间进行调度和管理。
操作系统只知道 “一个线程” 的存在 —— 即这个进程的那一个内核线程;至于程序内部是不是有成千上万个用户线程,操作系统一概不知。
这个模型是怎么运作的?
-
程序在用户空间通过线程库创建多个线程(例如:
Thread A,Thread B,Thread C); -
操作系统只看到一个内核线程,调度这个内核线程;
-
用户线程之间的切换(比如 A 执行完后换 B)是由线程库自己决定的,不需要进入内核;
-
所有这些线程的执行其实都由那个唯一的内核线程跑起来。
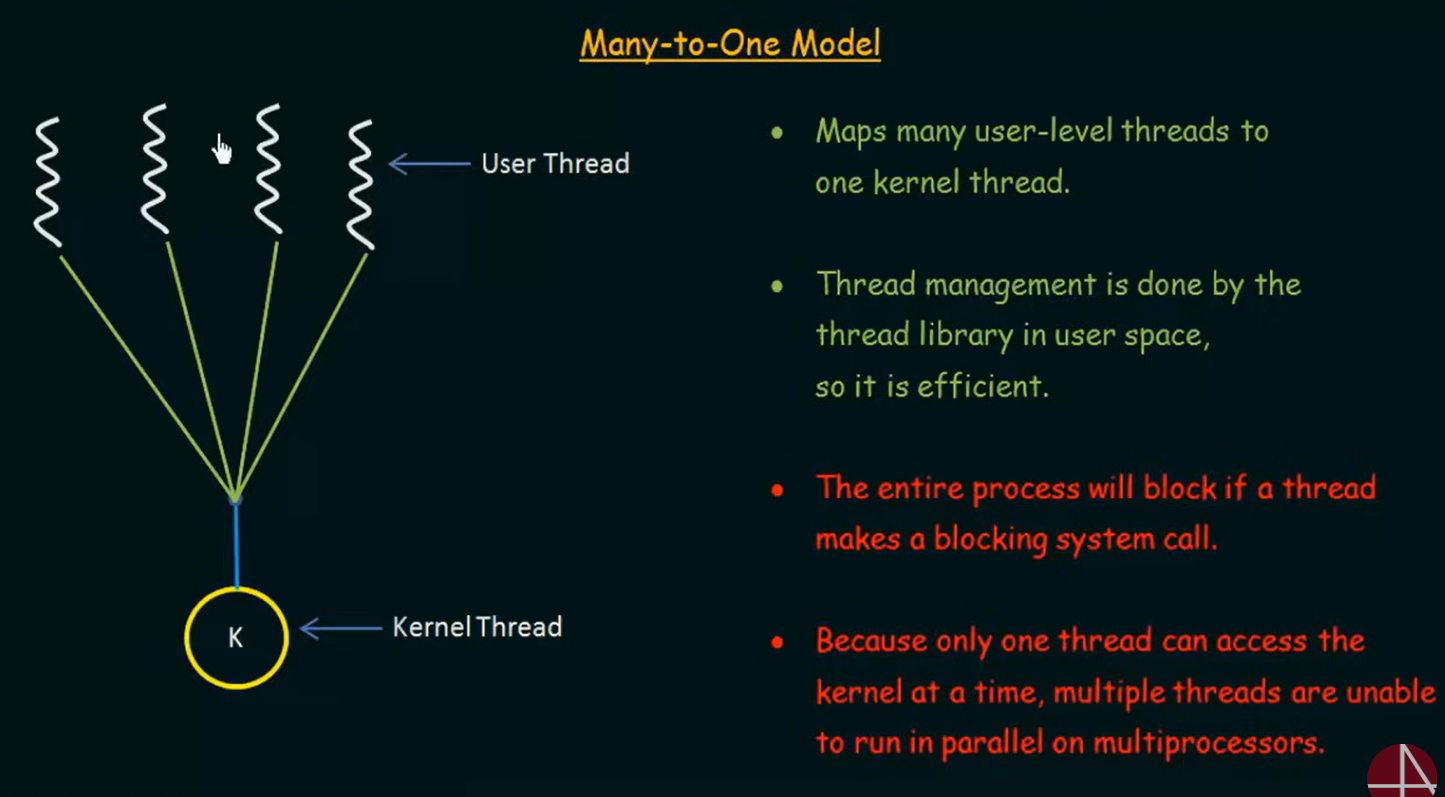
| 优点 | 描述 |
|---|---|
| 高效率 | 所有线程操作在用户态完成,无需系统调用,切换快、开销小 |
| 易于实现 | 不依赖操作系统,线程库负责一切,结构简单 |
| 跨平台性强 | 因为不需要依赖内核线程,线程库可以在不同系统上移植使用 |
| 限制 | 描述 |
|---|---|
| 无法并行 | 因为只有一个内核线程,CPU 只调度一个线程,无法在多核 CPU 上同时运行多个线程 |
| 阻塞导致全体挂起 | 如果某个用户线程执行了阻塞系统调用(如读文件、等待输入),内核线程也会被挂起,所有用户线程都会被迫停滞 |
| 无内核级优化 | 无法使用优先级调度、线程亲和性、调试工具等内核级功能 |
一个形象比喻:你可以把 多对一模型想象成:
一个剧团(用户线程)只有一个演员(内核线程),虽然剧团排练了很多角色(用户线程),但每次只能上台一个人(因为只有一个内核线程能被调度)。
一旦这个演员感冒了(被阻塞),整个剧团的演出就要暂停。
1. 阻塞系统调用问题
如果调用阻塞了(比如等待网络响应),由于所有用户线程都运行在同一个内核线程上,整个进程都无法运行 —— 即使其他线程还有工作要做。
这是此模型最大的缺陷。
2. 不能利用多核 CPU
哪怕你是 8 核 CPU,你的用户线程再多,也只能在一个 CPU 核上顺序执行,无法实现真正的并发处理。
现代并发程序大多追求多核并行,Many-to-One 在这方面就显得力不从心。
2. One-to-One Model(一对一模型)
每一个用户线程都会被 映射为一个内核线程,每个用户线程都是独立的、完整的“执行单元”,背后由自己的内核线程支撑。
行为细节解析
系统调用阻塞不会影响其他线程:
线程 A 正在读取磁盘文件(阻塞);线程 B 正在处理网络请求。→ A 阻塞时,B 仍被调度执行,程序仍然响应及时。
多核并行真正生效:
在 4 核 8 线程的 CPU 上,系统可将线程 A、B、C 同时安排在 3 个物理核心上运行 → 实现真正的 并行执行。
⚠️ 线程越多,性能可能下降
-
每个线程都有自己的栈(常为 1MB);
-
数万个线程会占据大量内存、带来频繁上下文切换;
-
过度使用线程会“拖垮”系统,需要线程池等方式优化。
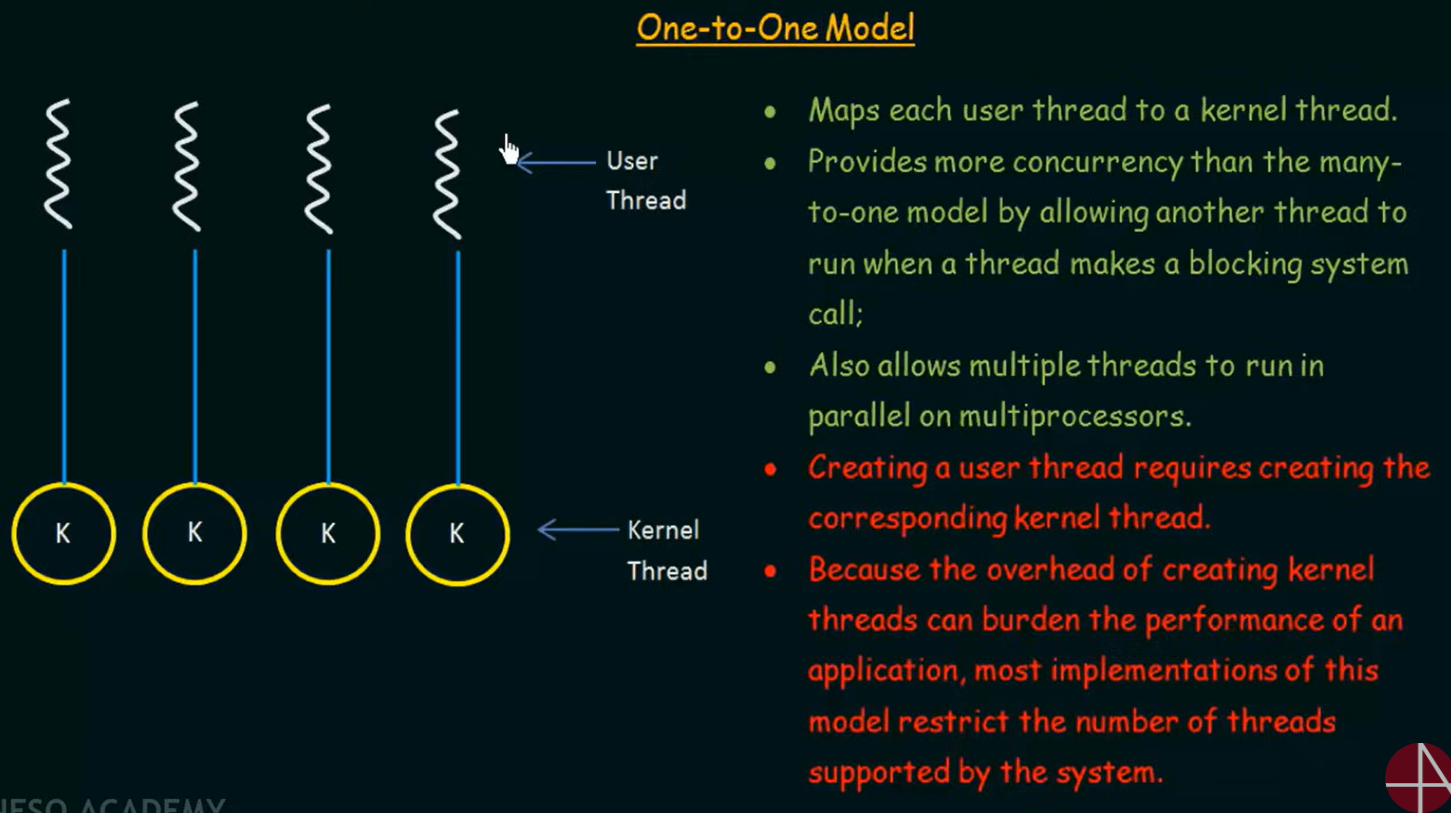
One-to-One 模型的优势
1. 支持真正的并发(Concurrency)与并行(Parallelism)
-
每个线程对应一个内核线程,可以被 独立调度;
-
当一个线程因阻塞操作(如 I/O)挂起时,其他线程可以继续执行;
-
在多核 CPU 上,多个线程可被同时分配到不同的核心上运行。
这解决了 Many-to-One 模型的两个大问题:
-
线程阻塞会拖垮整个进程 → 每个线程独立阻塞;
-
线程无法在多核上并行执行 → 可以同时在多个 CPU 上运行。
2. 编程语义更清晰,行为更可预测
-
程序员不用考虑复杂的用户态线程调度逻辑;
-
系统级调度器负责一切;
-
更适合多任务、GUI 应用、服务端高并发任务等场景。
虽然性能强大,但它也带来了两个核心问题:
1. 线程创建代价高
-
创建内核线程需要系统调用;
-
操作系统为每个线程分配栈空间、创建内核对象;
-
相比纯用户线程模型(Many-to-One),创建慢、资源耗费多。
2. 线程数量受限
-
操作系统往往限制一个进程可拥有的内核线程数(如 1024、32768 等);
-
大量线程会占用大量内核资源(每个线程独立的栈空间),增加上下文切换开销
所以:实现上通常会限制可创建的线程总数,防止线程滥用导致系统崩溃。
One-to-One 是现代操作系统中最主流的线程实现模型。它为每一个用户线程创建一个对应的内核线程,带来真正的并发、并行、可控性,但同时也带来了资源消耗和性能权衡的问题。
3. Many-to-Many Model(多对多模型)
多个用户线程映射到较少或相等数量的内核线程(Kernel-Level Threads)上,用户线程数量可以很多,但真正由系统调度的线程数量(内核线程)是有限的。
这就像是一组乘客(用户线程)共享一组出租车(内核线程)在城市中运行(CPU 上执行)。
工作机制解析( 复用(multiplexing) 的含义)
在用户态:
-
有一个线程库(user-level thread library)负责管理成百上千个用户线程;
-
它负责决定哪个用户线程要运行、挂起、切换等调度决策;
在内核态:
-
有一组有限的内核线程被创建,作为执行容器;
-
内核线程可以并行地运行多个用户线程(通过线程库调度上来的);
-
操作系统对内核线程进行调度。
这种模式中,“用户线程” → “内核线程” 的映射是动态的,可能发生频繁的上下文切换,但每个内核线程不必对应一个用户线程。
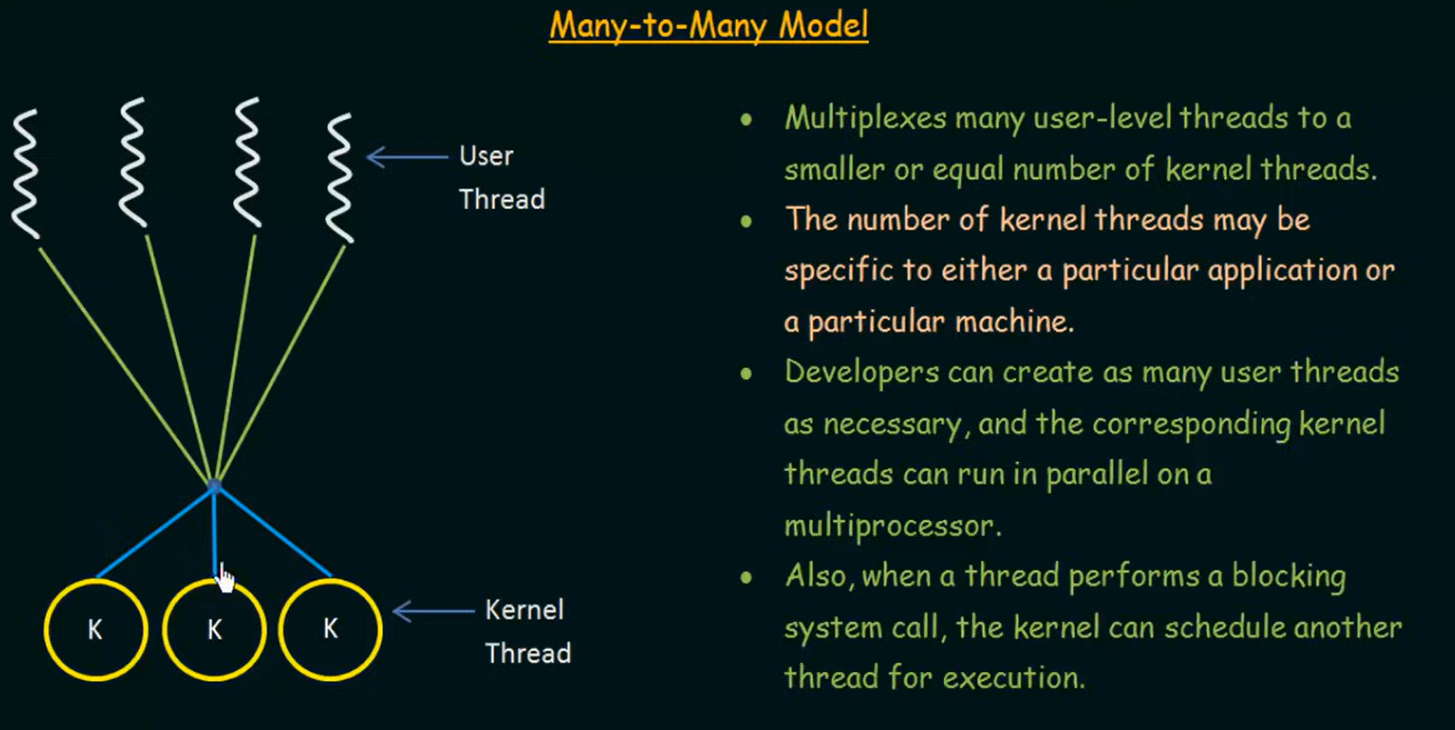
模型特点:灵活调度 + 高度并发 + 并行能力
1. 并发性强
-
程序员可以根据应用需要创建大量用户线程(例如处理成千上万个任务);
-
无需担心系统内核资源耗尽(不像 One-to-One 模型中每个线程都占一个内核线程)。
2. 并行性好
-
有多个内核线程(K1, K2, …)时,线程可以被分配到多个处理器上并发运行;
-
真正支持多核并行。
3. 阻塞互不影响
-
若一个用户线程阻塞,内核仍可调度其他用户线程在空闲内核线程上运行;
-
不再存在 Many-to-One 模型中“一个线程阻塞,全体挂起”的问题。
🔍 注意:大多数现代操作系统默认采用 One-to-One 模型,因为它更通用、开发成本低。但对于高并发服务器、网络服务、嵌入式系统等性能敏感场景,Many-to-Many 是一种理论上更高效的架构。
行为示例理解
你有一个服务器程序,要同时处理 5000 个网络连接请求:
-
One-to-One:需要创建 5000 个内核线程,系统资源可能不够;
-
Many-to-Many:创建 5000 个用户线程,系统只分配 8~16 个内核线程;
-
当有 I/O 阻塞时,其它用户线程继续执行;
-
运行时库动态决定将哪些用户线程映射到内核线程上;
-
前面学的是用户线程与内核线程在软件层面上的调度和映射,而超线程技术则是 CPU 在硬件层面如何优化线程执行效率的一种技术手段。
现在我们进入多线程调度模型背后的硬件层面——讲解超线程(Hyperthreading),也称为同时多线程(Simultaneous Multithreading, SMT)。
现代处理器中的超线程技术(Hyper-Threading)
除了操作系统管理线程,现代 CPU 也引入了硬件层面的多线程机制 —— 超线程(Hyper-Threading)技术,由 Intel 提出。
它的核心思想是:
一个物理 CPU 核心(core)可以模拟成多个逻辑处理器(logical processor),每个逻辑核心可以执行一个线程,从而在同一个周期内并行执行多个线程的指令。
-
系统层面看到的是“多个处理器”;
-
实际上只是一个核心利用其资源执行多个线程。

特点:
-
每个物理核心能并发执行两个线程;
-
比真正的双核心效率略低,但远优于单线程;
-
线程调度仍然由操作系统完成,操作系统将逻辑核心视为真实 CPU;
-
线程必须是内核线程,才可能分配给逻辑核心。
举例:
-
你电脑是 4 核 8 线程,说明每个核心支持 2 个线程并行(超线程);
-
多线程程序可以被调度到这些“虚拟核心”上运行,提高并发性。
超线程的好处:
-
在多线程程序中明显提升吞吐量;
-
对 I/O 密集型任务尤其有效(一个线程阻塞,另一个继续运行);
-
更高效地利用 CPU 的执行单元和缓存。
如何查看你的电脑是否启用了超线程
方法一:任务管理器(Task Manager)快速查看
-
打开任务管理器:
-
快捷键:
Ctrl + Shift + Esc
-
-
点击上方的 “性能”(Performance)选项卡;
-
选择左侧的 “CPU”;
-
查看右侧信息面板:
查看内容:
-
内核(Cores):物理核心数
-
逻辑处理器(Logical processors):系统中可用的逻辑线程数(包括超线程)

判断方式:
-
如果
逻辑处理器 > 核心数,说明超线程已启用
Cores: 4
Logical processors: 8 → 超线程启用
方法二:使用 systeminfo 命令(简单终端方法)
-
打开命令提示符(
Win + R输入cmd,回车); -
输入以下命令:systeminfo
-
在输出中查找:
-
Processor(s):后的逻辑信息(但此命令输出通常不包含核心/线程详细对比)
-
-
提示:不如方法一直观,但适合脚本分析。
方法三:使用 CPU-Z(图形工具,最直观)
CPU-Z 官网
-
下载并运行 CPU-Z;
-
查看 "CPU" 选项卡;
-
关注字段:
| 字段 | 含义 |
|---|---|
| Cores | 物理核心数量 |
| Threads | 逻辑处理器数量 |
如果 Threads > Cores,即为超线程开启。
方法四:使用 wmic 命令查询详细信息
wmic cpu get NumberOfCores,NumberOfLogicalProcessors
NumberOfCores NumberOfLogicalProcessors
4 8
说明:4 核 8 线程,支持超线程。
