万由nas做网站网站设计为什么要域名
目录
K最近邻(KNN) - 基于距离的模型
决策边界可视化
查看特定样本的最近邻
随机森林(RF) - 树模型
feature_importances_
SHAP值分析
可视化单棵树
多层感知器(MLP) - 神经网络
部分依赖图
LIME解释器
权重可视化
支持向量回归(SVR) - 核方法
支持向量可视化
部分依赖图
决策边界可视化(对于分类问题)
通用解释方法(适用于所有模型)
Permutation Importance
全局代理模型
Anchor解释法
可视化工具推荐
总结建议
针对不同类型的机器学习模型,我们需要使用不同的可解释性技术。以下是不同模型类型的可解释性分析方法
K最近邻(KNN) - 基于距离的模型
-
决策边界可视化
## KNN-基于距离的模型
# 1. 决策边界可视化import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.inspection import DecisionBoundaryDisplay# 加载数据
iris = load_iris()
X = iris.data[:, :2]
y = iris.target# 训练模型
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X, y)disp = DecisionBoundaryDisplay.from_estimator(knn, X, response_method="predict",alpha=0.5, grid_resolution=200,xlabel=iris.feature_names[0], ylabel=iris.feature_names[1],
)
disp.ax_.scatter(X[:, 0], X[:, 1], c=y, edgecolor="k")
plt.title("KNN Decision Boundaries")
plt.show()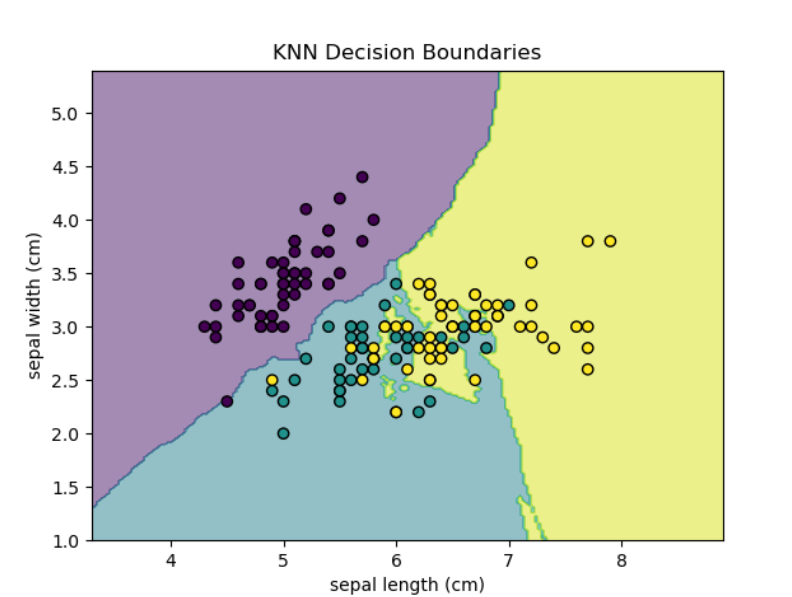
-
查看特定样本的最近邻
# 2. 查看特定样本的最近邻import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.inspection import DecisionBoundaryDisplay# 加载数据
iris = load_iris()
X = iris.data[:, :2]
y = iris.target# 训练模型
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X, y)sample_idx = 10
distances, indices = knn.kneighbors(X[sample_idx].reshape(1, -1))
print(f"最近邻索引: {indices}")
print(f"距离: {distances}")
# 最近邻索引: [[10 48 5 16 36]]
# 距离: [[0. 0.1 0.2 0.2 0.2236068]]# 可视化最近邻
plt.scatter(X[:, 0], X[:, 1], c=y, alpha=0.3, label="All points")
plt.scatter(X[sample_idx, 0], X[sample_idx, 1], c='red', s=100, label="Query point")
plt.scatter(X[indices[0], 0], X[indices[0], 1], c='blue', s=50, label="Neighbors")
plt.legend()
plt.title(f"KNN Neighbors (k={knn.n_neighbors})")
plt.show()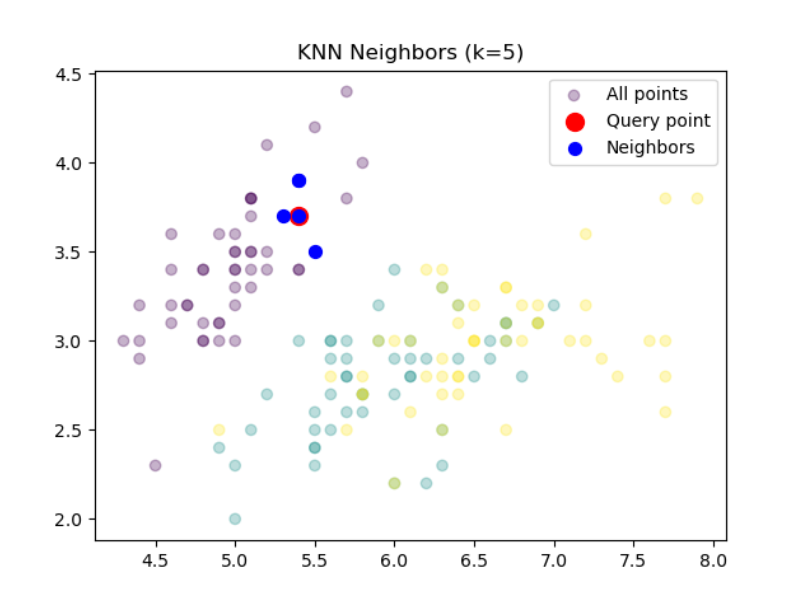 随机森林(RF) - 树模型
随机森林(RF) - 树模型
-
feature_importances_
## RF-树模型
from sklearn.ensemble import RandomForestClassifier
import shap
from sklearn.datasets import load_iris
from sklearn.tree import plot_tree
import matplotlib.pyplot as pltiris = load_iris()
X = iris.data
y = iris.target# 训练模型
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X, y)# 1. 特征重要性
importances = rf.feature_importances_
plt.barh(iris.feature_names, importances)
plt.title("Random Forest Feature Importance")
plt.tight_layout()
plt.show()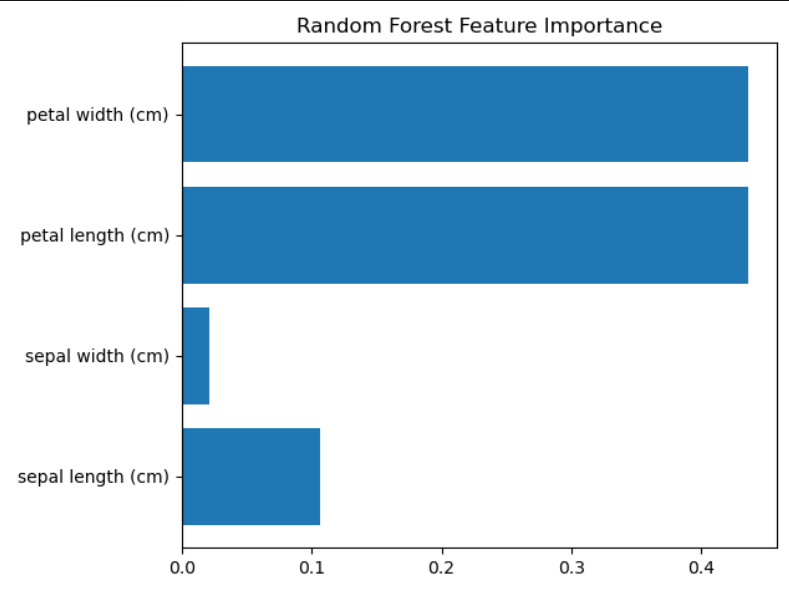
-
SHAP值分析
# 2. SHAP值分析
explainer = shap.TreeExplainer(rf)
shap_values = explainer.shap_values(X[:100]) # 计算前100个样本的SHAP值shap.summary_plot(shap_values, X[:100], feature_names=iris.feature_names, class_names=iris.target_names)
plt.title("SHAP Summary Plot")
plt.tight_layout()
plt.show()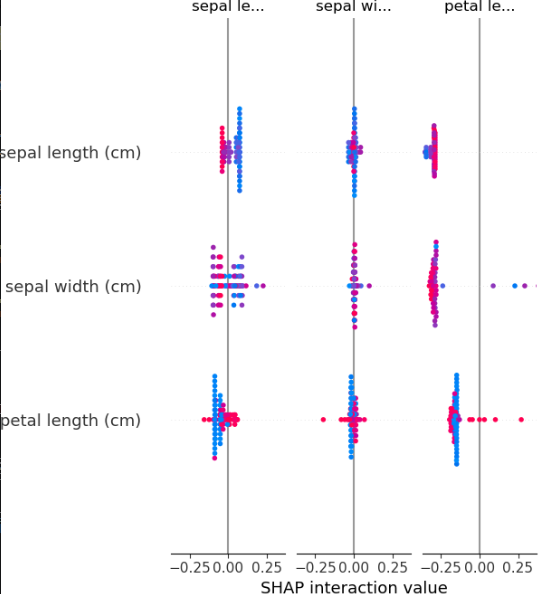
-
可视化单棵树
# 3. 可视化单棵树
plt.figure(figsize=(20,10))
plot_tree(rf.estimators_[0], feature_names=iris.feature_names,class_names=iris.target_names, filled=True, rounded=True)
plt.title("Example Decision Tree from Random Forest")
plt.tight_layout()
plt.show()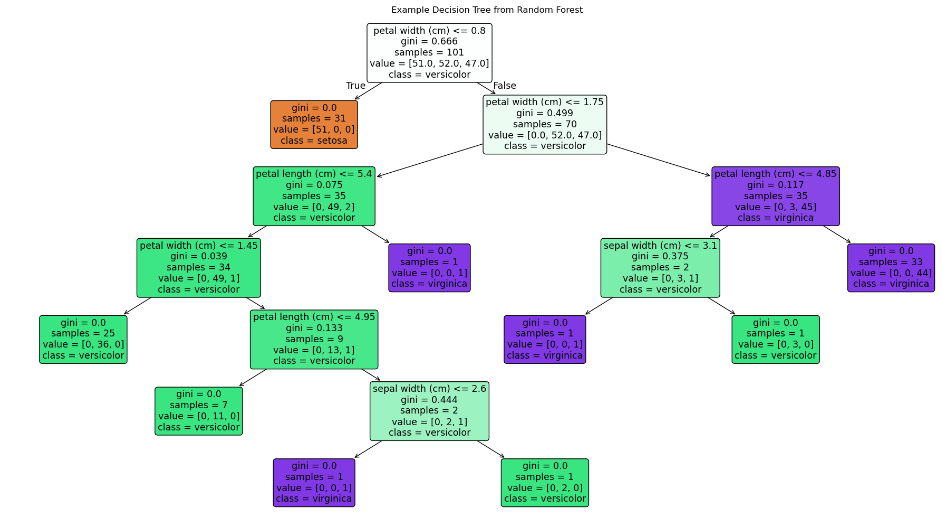
多层感知器(MLP) - 神经网络
-
部分依赖图
## MLP-神经网络
from sklearn.neural_network import MLPClassifier
from sklearn.inspection import PartialDependenceDisplay
import lime
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import lime.lime_tabulariris = load_iris()
X = iris.data[:, :2]
y = iris.target# 训练模型
mlp = MLPClassifier(hidden_layer_sizes=(10,), max_iter=1000,early_stopping=True ,random_state=42)
mlp.fit(X, y)# 1. 部分依赖图
fig, ax = plt.subplots(figsize=(10, 5))
PartialDependenceDisplay.from_estimator(mlp, X, features=[0, 1], target=0 ,ax=ax)
plt.title("Partial Dependence Plots")
plt.show()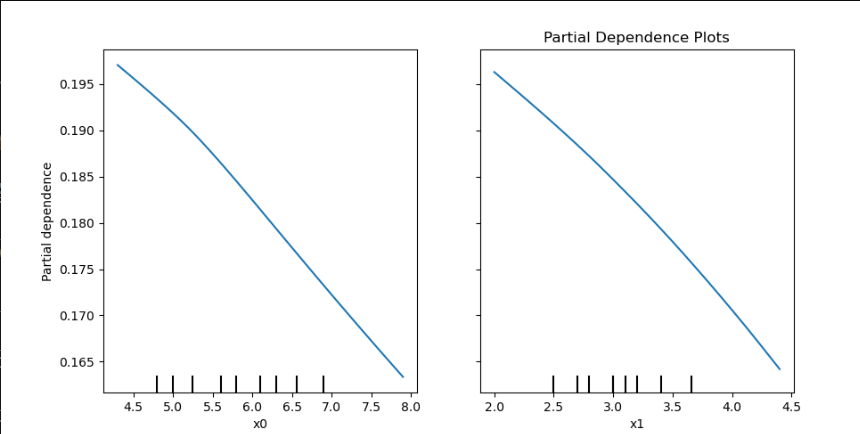
-
LIME解释器
# 2. LIME解释器
import matplotlib.pyplot as plt
explainer = lime.lime_tabular.LimeTabularExplainer(X, feature_names=iris.feature_names[:2],class_names=iris.target_names, discretize_continuous=True)exp = explainer.explain_instance(X[10], mlp.predict_proba, num_features=2)
# 获取解释结果数据
exp_list = exp.as_list(label=exp.available_labels()[0])plt.barh([x[0] for x in exp_list], [x[1] for x in exp_list])
plt.title('LIME Explanation')
plt.xlabel('Feature Importance')
plt.tight_layout()
plt.show()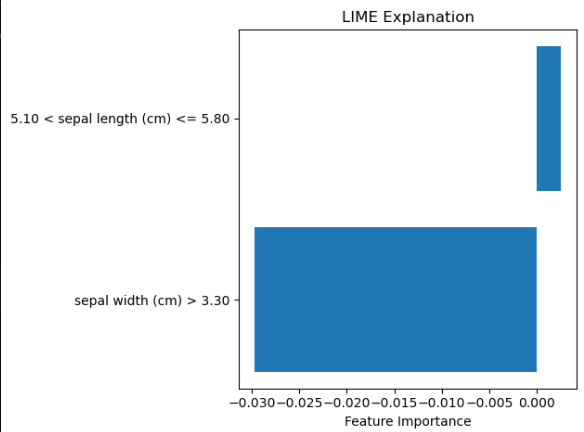
-
权重可视化
# 3. 权重可视化
plt.figure(figsize=(8, 4))
plt.imshow(mlp.coefs_[0], cmap='viridis', aspect='auto')
plt.colorbar()
plt.xlabel("Input features")
plt.ylabel("Hidden neurons")
plt.title("First Layer Weights Visualization")
plt.xticks([0, 1], iris.feature_names[:2])
plt.show()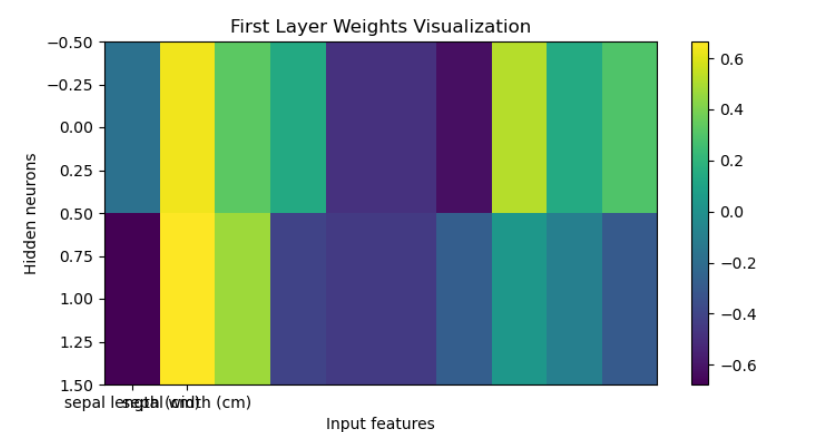
支持向量回归(SVR) - 核方法
-
支持向量可视化
## SVR-核方法
# 1. 支持向量可视化
from sklearn.svm import SVR, SVC
from sklearn.datasets import make_regression, load_iris
from sklearn.inspection import partial_dependence
from sklearn.inspection import PartialDependenceDisplay
from sklearn.inspection import DecisionBoundaryDisplay
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as npplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
sns.set_palette("viridis")X_reg, y_reg = make_regression(n_samples=1000, n_features=2,n_informative=2, noise=20,random_state=42)# 调整y的范围,模拟房价数据
y_reg = (y_reg - y_reg.min()) / (y_reg.max() - y_reg.min()) * 5 + 1
feature_names = ['房屋面积', '房间数量'] svr = SVR(kernel='rbf', C=100, gamma=0.1)
svr.fit(X_reg, y_reg)plt.figure(figsize=(10, 6))
scatter = plt.scatter(X_reg[:, 0], X_reg[:, 1],c=y_reg, cmap='viridis', alpha=0.6,label='数据点')
plt.scatter(svr.support_vectors_[:, 0], svr.support_vectors_[:, 1],facecolors='none', edgecolors='red', s=100,linewidths=1.5, label='支持向量')
plt.xlabel(feature_names[0])
plt.ylabel(feature_names[1])
cbar = plt.colorbar(scatter)
cbar.set_label('模拟房价 (单位: 百万元)', rotation=270, labelpad=15)
plt.legend(loc='upper right')
plt.title("模拟房价数据集 - SVR支持向量可视化", pad=20)
plt.tight_layout()
plt.show()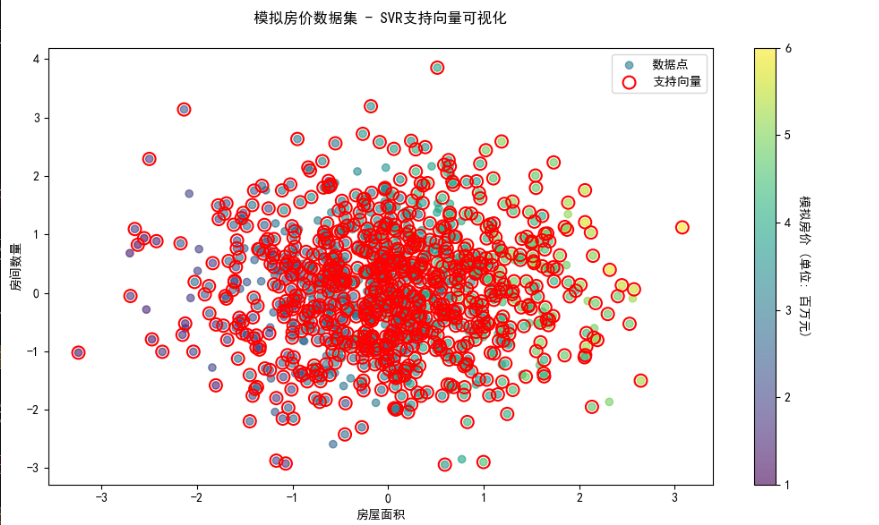
-
部分依赖图
# 2. 部分依赖图
pdp = partial_dependence(svr, X_reg, features=[0, 1],grid_resolution=50)disp = PartialDependenceDisplay.from_estimator(estimator=svr,X=X_reg,features=[0, 1],feature_names=feature_names,kind='average',grid_resolution=50
)
disp.figure_.suptitle("模拟房价 - 部分依赖图 (SVR模型)", y=1.05)
plt.tight_layout()
plt.show()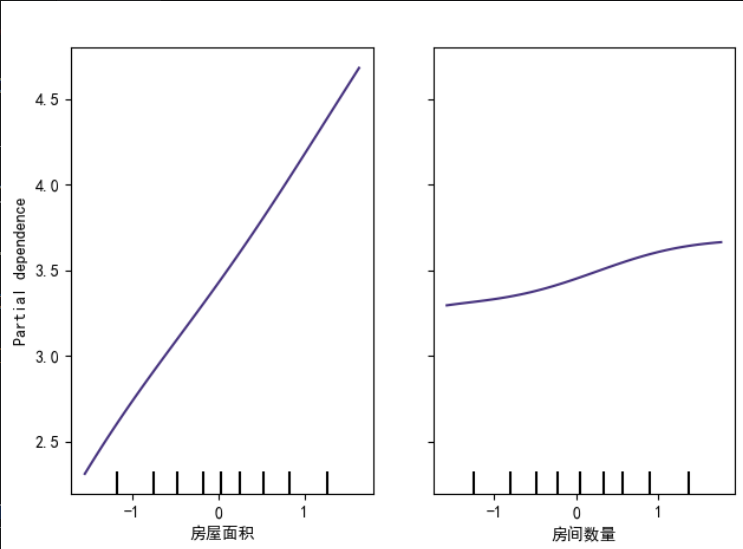
-
决策边界可视化(对于分类问题)
# 3. 决策边界可视化iris = load_iris()
X_iris = iris.data[:, :2] # 只使用前两个特征
y_iris = iris.target
iris_feature_names = [name[:-5] for name in iris.feature_names[:2]] # 移除" (cm)"后缀# 训练SVC模型
svc = SVC(kernel='rbf', probability=True, gamma='auto')
svc.fit(X_iris, y_iris)plt.figure(figsize=(10, 6))
disp = DecisionBoundaryDisplay.from_estimator(svc, X_iris, response_method="predict",alpha=0.5, grid_resolution=200,xlabel=iris_feature_names[0], ylabel=iris_feature_names[1],cmap='Pastel2'
)scatter = disp.ax_.scatter(X_iris[:, 0], X_iris[:, 1], c=y_iris,edgecolor="k", cmap='Dark2', s=60)
disp.ax_.set_title("鸢尾花数据集 - SVM决策边界", pad=20)handles, labels = scatter.legend_elements()
legend = disp.ax_.legend(handles, iris.target_names,title="鸢尾花种类",loc="upper right")
plt.tight_layout()
plt.show()
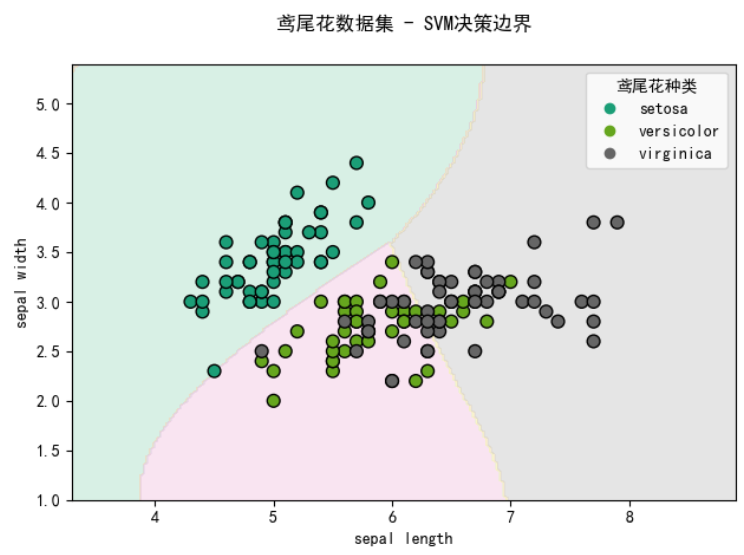
通用解释方法(适用于所有模型)
-
Permutation Importance
## 通用解释方法
# 1. Permutation Importancefrom sklearn.datasets import load_iris
from sklearn.inspection import permutation_importance
import matplotlib.pyplot as plt
import numpy as np
from sklearn.ensemble import RandomForestClassifieriris = load_iris()
X = iris.data[:, :2]
y = iris.targetrf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X, y)result = permutation_importance(rf, X, y, n_repeats=10, random_state=42)
sorted_idx = result.importances_mean.argsort()plt.boxplot(result.importances[sorted_idx].T,vert=False, labels=np.array(iris.feature_names[:2])[sorted_idx])
plt.title("Permutation Importance")
plt.tight_layout()
plt.show()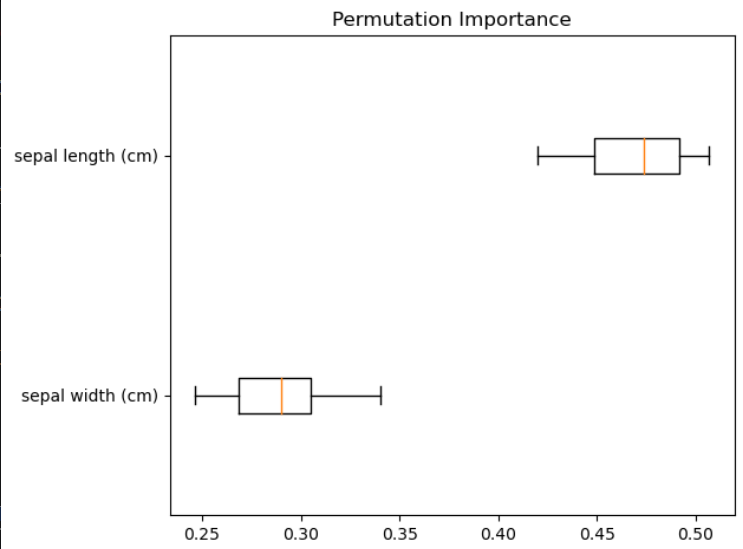
-
全局代理模型
# 2. 全局代理模型
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import plot_treeiris = load_iris()
X = iris.data[:, :2]
y = iris.targetrf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X, y)# 用决策树拟合黑盒模型的预测结果
dt_surrogate = DecisionTreeClassifier(max_depth=3)
dt_surrogate.fit(X, rf.predict(X))plt.figure(figsize=(12,6))
plot_tree(dt_surrogate, feature_names=iris.feature_names[:2],class_names=iris.target_names, filled=True)
plt.title("Surrogate Decision Tree Explanation")
plt.show()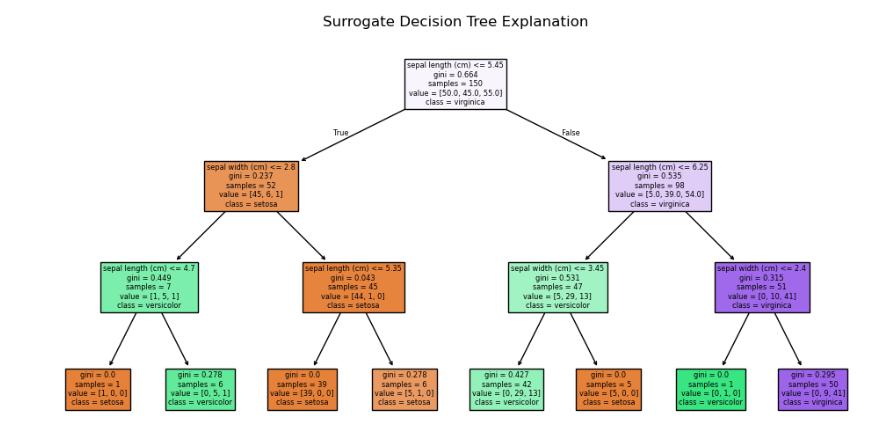
-
Anchor解释法
# 3. Anchor解释法from alibi.explainers import AnchorTabular
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifieriris = load_iris()
X = iris.data[:, :2]
y = iris.targetrf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X, y)explainer = AnchorTabular(predict_fn=rf.predict_proba, feature_names=iris.feature_names[:2])
explainer.fit(X)exp = explainer.explain(X[10], threshold=0.95)
print('Anchor:', exp.anchor)
print('Precision:', exp.precision)
print('Coverage:', exp.coverage)可视化工具推荐
- SHAP:适合树模型和部分线性模型
- LIME:适合所有模型的局部解释
- ELI5:提供多种解释方法
- Alibi:高级解释方法实现
- InterpretML:微软开发的解释性工具包
总结建议
- 对于树模型(RF):优先使用SHAP和特征重要性
- 对于神经网络(MLP):使用LIME、部分依赖图和激活可视化
- 对于距离模型(KNN):分析最近邻样本和决策边界
- 对于核方法(SVR):可视化支持向量和部分依赖图
- 所有模型都可以使用Permutation Importance和代理模型方法