探索人类底层逻辑一致性的跨学科研究框架:建议、方法与展望
摘要
本报告旨在提出一个全面的跨学科研究框架,以探索“人类底层逻辑一致性”这一核心科学问题。该问题不仅是人工智能通向通用智能的关键瓶颈,也是理解人类心智与语言本质的终极挑战。我们将论证,深层语义分析是解开此问题的核心路径。报告将整合多个学科的理论与工具,提出一个“认知-计算”双循环研究模型,并提供具体的建议、方法、步骤与前瞻性看法。本研究的核心目标是建立一个既符合神经认知现实、又能在计算上被验证的“认知一致性”理论。
1. 引言:问题的提出与研究的重要性
人类的认知与交流能力,其基石是一种深刻而灵活的“逻辑一致性”。这种一致性并非等同于计算机科学中的形式逻辑,它允许模糊、隐喻和语境依赖,却能在宏观上保证意义的连贯与推理的有效。理解并模拟这种底层逻辑,是当前人工智能(AI)、认知科学和语言学面临的共同挑战。
传统的AI方法,无论是基于符号逻辑还是纯粹的深度学习,都遇到了瓶颈。符号方法过于僵硬,难以处理真实世界的复杂性;而深度学习模型虽功能强大,却常因缺乏逻辑一致性而产生无意义或自相矛盾的输出,成为“黑箱”。
因此,本报告主张,必须打破学科壁垒,构建一个全新的研究框架。该框架将融合人文科学对意义的深刻洞察、认知科学对心智过程的实证研究,以及计算机科学的建模与验证能力,共同致力于回答这个核心问题:人类赖以进行有效沟通和思维的底层逻辑一致性规律究竟是什么?
2. 核心理念:以“深层语义分析”为中心的跨学科整合
我们认为,逻辑是在意义的土壤中生长的。因此,探索逻辑一致性的最佳路径,就是进行“深层语义分析”。这需要我们从以下几个层面重新定义和审视“意义”:
- 符号学视角:意义产生于符号(如文字、词语)与其所指代概念及解释者之间的动态关系。一个知识图谱中的三元组(头实体、关系、尾实体)本身就是一个基本的符号结构。
- 认知语义学视角:意义并非客观存在,而是人类基于身体经验和心智活动(如范畴化、隐喻、转喻)对世界进行概念化的结果。
- 中国传统语言文字学视角:以训诂学、文字学、音韵学为代表的“小学”,为我们提供了上千年的、关于汉语言文字形、音、义演变关系的珍贵数据和分析方法 。特别是“新训诂学”所倡导的,对语言意义本身进行历时与共时研究,并关注音、形、义、法(语法)之间互动关系的理念,为现代语义研究提供了丰富的思想资源 。
基于此,我们提出,研究人类逻辑一致性的核心,在于理解和建模“语义场”的内在结构与动态演化,以及大脑处理语义一致性与非一致性信息时的神经机制。
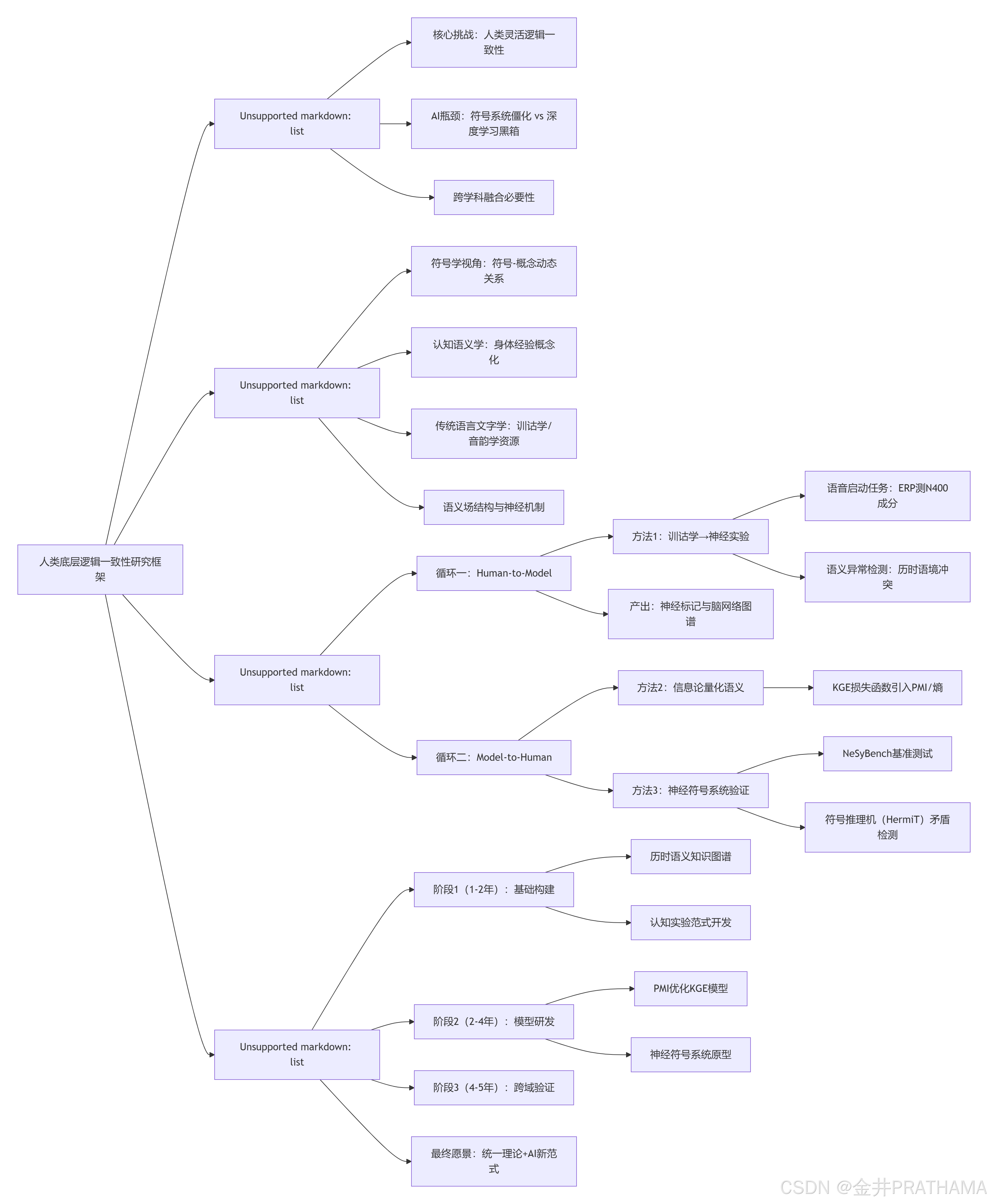
3. 核心研究框架:“认知-计算”双循环模型
为了系统性地推进此项研究,我们提出一个“认知-计算”(Cognitive-Computational)双循环模型。该模型旨在建立一个从“人类认知数据”到“计算模型构建”,再从“计算模型验证”回到“人类认知假设检验”的闭环反馈路径。
循环一:从人类到模型(Human-to-Model)—— 挖掘认知规律与神经证据
这一循环的目标是从人类语言和大脑活动中,提炼出关于语义处理和逻辑一致性的基本原则,并将其形式化,为构建计算模型提供理论依据。
方法与步骤:
3.1. 融合传统语言学与认知神经科学,探寻语义处理的神经基础
中国传统语言文字学,特别是训诂学,蕴含着丰富的关于语义演变、关联和语境依赖的洞见 。例如,“因声求义”原则揭示了语音和意义之间的深刻联系。我们可以将这些古典原则“操作化”,转化为现代认知神经科学的实验范式。
建议一:将训诂学原则转化为ERP/fMRI实验设计。
- 任务设计:针对“因声求义”,可以设计 语音启动任务(phonological priming task) 。在实验中,向被试呈现与目标词同音但意义无关的启动词,通过观察事件相关电位(ERP)中的N400成分来测量大脑对后续语义整合的难度 。N400波幅的异常变化可以量化语音线索对语义通达的促进或干扰,从而在神经层面验证“因声求义”的认知现实性。多项研究已证实,ERP和fMRI技术是研究汉语语音和语义处理的有效工具,尤其是在区分语音、语义和正字法加工的脑区激活上 。
- 任务设计:针对训诂学中的“语义流变”分析,可以设计语义异常检测任务。利用古典文献,构建在古代语境中语义通顺、但在现代语境中语义异常的句子。通过ERP/fMRI技术,观察被试在阅读这些句子时大脑如何处理这种“历时性”的语义冲突 。这不仅能揭示大脑处理语义一致性的机制,还能为历时语义学提供实证支持。
产出:通过上述实验,我们可以获得关于人类(特别是汉语使用者)在处理语义一致性、语音-语义关联、语境依赖等问题时的 神经标记(neural markers) 和脑功能网络图谱。这些数据将成为构建下一阶段计算模型的生物学约束和“认知先验”。
循环二:从模型到人类(Model-to-Human)—— 构建并检验计算理论
这一循环的目标是将在认知层面发现的规律,融入计算模型中,并利用这些模型生成可被进一步认知实验检验的新假说。
方法与步骤:
3.2. 融合信息论与知识图谱,量化语义一致性
当前的知识图谱(KG)研究主要通过链接预测的准确率(如MRR, Hits@K)来间接评估模型性能,但缺乏对“语义一致性”本身的直接量化 。搜索结果显示,在知识图谱架构中直接嵌入信息论度量来量化语义一致性的研究尚属空白 。
- 建议二:在知识图谱嵌入(KGE)的损失函数中引入信息论度量。
- 具体方法:我们建议,超越传统的几何距离损失函数(如TransE的L2距离),探索基于 点互信息(PMI) 或条件熵的损失函数。例如,一个好的嵌入模型应该最大化一个有效三元组
(h, r, t)中t和(h, r)之间的互信息,同时最小化无效三元组的互信息。这促使模型学习的不再是简单的空间位置,而是实体与关系之间的统计依赖性和信息增益,从而更深刻地捕捉语义一致性。虽然当前模型并未直接采用此方法,但已有研究开始探索语义驱动的损失函数,例如通过注入背景知识来提升语义感知能力 ,这与我们的建议方向一致。
- 具体方法:我们建议,超越传统的几何距离损失函数(如TransE的L2距离),探索基于 点互信息(PMI) 或条件熵的损失函数。例如,一个好的嵌入模型应该最大化一个有效三元组
3.3. 融合知识图谱与神经符号系统,检验逻辑一致性
神经符号(Neuro-Symbolic, NeSy)系统旨在结合神经网络的学习能力和符号系统的推理能力,是检验逻辑一致性的理想平台 。
- 建议三:使用神经符号基准来评估和迭代我们的计算模型。
- 评估框架:利用如 NeSyBench 这样的标准化基准测试套件 。NeSyBench的设计目标之一就是评估系统在处理带有噪声和不一致性的OWL 2本体时的能力 这与我们对“灵活的逻辑一致性”的探索高度契合。
- 底层机制:在这些系统中,逻辑矛盾的检测通常依赖于底层的符号推理机(如HermiT, Pellet),它们实现了基于Tableau算法的高效推理 。这为我们提供了一个“逻辑真值”的参照系。
- 闭环检验:我们可以将前一步开发的、基于信息论的知识图谱模型作为神经符号系统中的“神经”部分,然后在其上层叠加一个符号推理层。通过在NeSyBench上进行评估,我们可以量化我们的模型在多大程度上捕捉到了形式逻辑所定义的“一致性”。如果模型的表现与人类在认知实验中的表现(例如,对不同类型逻辑错误的敏感度)呈现相关性,那么我们就向着统一认知与计算的目标迈进了一大步。
4. 整合框架下的具体研究步骤与展望
4.1. 建议的研究路线图(5年计划)
- 第一阶段:基础数据与范式构建(第1-2年)
- 数据库建设:系统整理中国训诂学文献,构建一个包含词义演变、音义关联、形义关系的大规模“历时语义知识图谱”。
- 范式开发:开发并验证一系列ERP/fMRI实验范式,将“因声求义”、“形声说”、“语义引申”等古典原则转化为可测量的认知任务 。
- 第二阶段:计算模型研发与集成(第2-4年)
- 模型创新:研发集成信息论度量(如PMI、熵)的新型知识图谱嵌入模型,目标是直接优化语义一致性。
- 系统集成:构建结合了上述KGE模型和符号推理机的神经符号系统原型。
- 第三阶段:跨域验证与理论迭代(第4-5年)
- 认知-计算验证:用第一阶段收集的神经认知数据(如大脑对不同语义距离的反应模式)来指导和约束第二阶段模型的架构设计。
- 计算-认知验证:用第二阶段的计算模型(在NeSyBench等基准上评估后)生成关于人类如何处理复杂逻辑推理的新假说,并设计新的认知实验进行检验,从而完成“认知-计算”双循环。
4.2. 最终展望与科学价值
本研究框架的最终目标,是超越当前AI的局限,迈向一个能够理解和运用人类智慧中那种灵活、深刻的逻辑一致性的新范式。我们期望达成以下愿景:
- 理论层面:构建一个关于“人类认知一致性”的统一理论,该理论能够解释从大脑的毫秒级电活动到语言数千年的演化规律。
- 技术层面:推动新一代人工智能的发展,使其具备更强的常识推理、可解释性和鲁棒性,能够真正理解人类语言的细微之处,进行有意义的、符合逻辑的人机交互。
- 学科层面:为文、理、工、医等多个学科的深度交叉融合提供一个可行的范例,证明人类智慧的古老结晶(如训诂学)能够在前沿科学探索中焕发新的生命力。
通过这一系统性、前瞻性的研究,我们不仅有望揭开人类心智的奥秘,更有可能为人类与机器智能的未来共生奠定坚实的科学基础。