[深度学习] 大模型学习4-RAG技术全景解析
在大语言模型基础知识一文中,检索增强生成(Retrieval-Augmented Generation,简称 RAG)技术作为构建大语言模型(Large Language Model,简称 LLM)应用的一种方式已被简要提及,本文将详细介绍RAG技术的实现流程及其演进趋势。
关于RAG技术更全面更系统的介绍,可以阅读以下论文:
- Retrieval-Augmented Generation for AI-Generated Content: A Survey
- Retrieval-Augmented Generation for Large Language Models: A Survey
文章目录
- 1 RAG技术解析
- 1.1 RAG技术的重要性
- 1.2 RAG系统简介
- 1.3 RAG系统工作流程详细介绍
- 2 RAG技术演进趋势和常见问题
- 2.1 RAG技术优化与演进趋势
- 2.1.1 RAG技术增强路径
- 2.1.2 RAG系统实现模式的演化
- 2.2 RAG技术典型问题与优化方案
- 2.2.1 RAG技术常见问题及解决办法
- 2.2.2 RAG系统固有挑战
- 2.2.3 RAG技术与模型指令微调的对比
- 3 实战
- 3.1 RAG系统示例代码
- 3.2 主流开源RAG框架概览
- 4 参考
1 RAG技术解析
1.1 RAG技术的重要性
仅依赖LLM的局限性
尽管LLM的参数规模与训练数据量显著增长,使其在自然语言处理任务中的能力快速提升,但模型的知识记忆能力仍受限于架构与训练范式。由于通常需要预训练数据对同一知识点进行多次曝光才能实现有效记忆,导致其记忆效率偏低,且难以全面覆盖各领域知识。
更核心的局限在于,LLM的性能高度依赖训练阶段接触的静态数据。这使其在处理实时更新信息(如最新科技、时事新闻)、长尾知识(即罕见或未纳入训练数据的内容)及动态变化内容时表现不佳,可能生成错误、不完整甚至虚构的信息,即出现 “幻觉” 问题。
此外,针对特定领域的复杂专业知识,LLM的处理效率与深度理解能力也显不足。仅依靠模型无法动态访问外部知识库,这在需依赖精确、最新信息的场景(如问答、医疗诊断、法律咨询、实时信息查询等)中尤为受限。因此,如何克服对静态数据的依赖、提升知识获取的效率与实时性、减少幻觉现象并增强领域深度理解能力,已成为当前LLM发展面临的关键挑战。
RAG技术的诞生
为弥补LLM单独使用时的局限性,检索增强生成技术应运而生。其核心原理是融合“检索”与“生成”:在接收用户查询时,系统先从外部大规模知识源(如文档、数据库)中动态检索相关信息片段,再将这些片段作为附加上下文输入生成模型,辅助其完成答案创作。借助这一机制,模型能够生成更精准、可靠且贴合上下文的答案,不仅大幅提升了生成内容的准确性、相关性与实时性,有效缓解了“幻觉”问题,还增强了答案的可追溯性与可信度;同时,通过动态引入最新信息源,RAG技术显著加快了知识更新效率。
此外,RAG技术赋予模型处理复杂任务的能力,例如串联整合多步骤推理、融合不同领域知识等。以“近期哪个品牌的新款手机拍照功能最优”这一问题为例,其可快速调取最新测评文章,并基于这些内容给出详尽解答,因此在需精准且及时信息的场景中优势显著。
简言之,RAG技术是一种通过融入外部知识库优化LLM性能的模式。关于RAG技术的起源可以参考RAG起源、演进与思考。
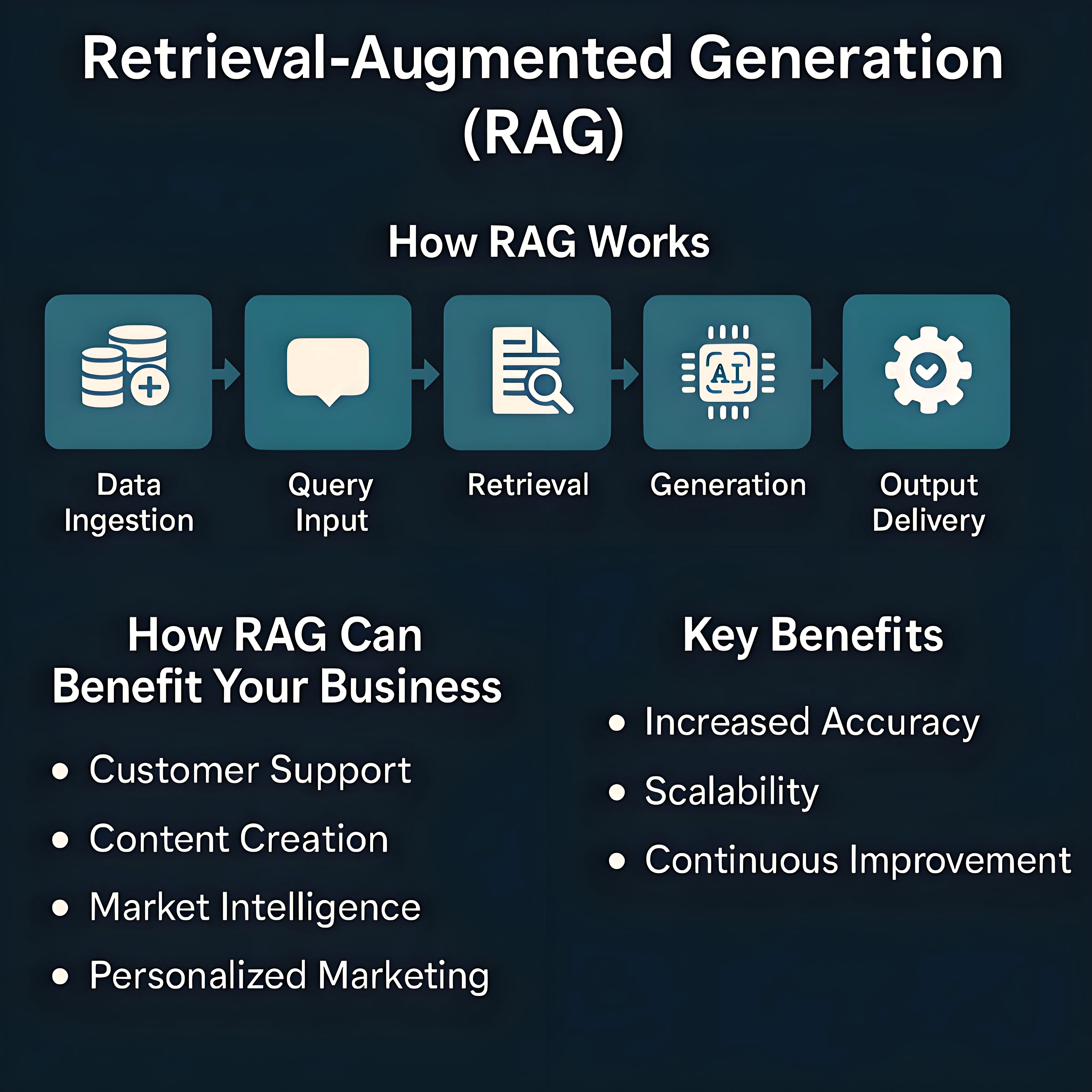
RAG技术的应用场景
RAG技术的核心优势在于整合信息检索与文本生成能力,有效突破了LLM在时效性与准确性不足等固有局限,凭借这一核心优势,其应用已延伸至智能问答、文本摘要、对话系统、教育培训、知识增强型问答与推理、个性化推荐及决策支持等多个领域。典型如:
- 在企业知识库管理中,可快速定位内部文档中的关键信息并生成结构化解读,提升团队协作效率;
- 在金融领域,能实时整合市场动态、政策变动等数据,为投资分析提供基于多源信息的趋势预判;
- 在客服场景中,可结合用户历史交互记录与产品知识库,生成贴合需求的精准回复,优化服务体验;
- 在科研领域,助力研究者整合跨学科文献、实验数据,生成具有针对性的研究思路与文献综述框架。
随着LLM的兴起,以RAG技术为核心驱动力的新一代智能搜索系统迅猛发展,深刻重塑着信息获取模式。与传统搜索引擎不同,微软Bing Chat、百度文心一言等基于RAG的系统,不仅能更智能地理解用户意图,更能提供高度个性化、上下文关联的交互体验,其角色也从单纯的信息检索工具,演进为可直接输出经信息整合与分析的精确答案的智能系统。
1.2 RAG系统简介
RAG系统工作流程概览
RAG系统的核心在于检索与生成流程的深度融合,其核心逻辑是通过动态引入外部知识,大幅提升输出内容的准确性与相关性。具体工作流程以用户查询为起点:首先,检索模块借助向量检索等技术,将用户查询转化为向量形式,从文档库、知识图谱或搜索引擎等外部知识源中快速定位、筛选并提取高度相关的信息片段;随后,以LLM为基础的生成模块会整合查询内容与检索到的上下文信息,经推理、整合与重组,最终生成连贯且精准的答案。
例如,当用户询问“2024年夏季奥运会的举办城市是哪里,有哪些特色比赛项目?”时,RAG系统会率先检索2024年奥运会的相关资料,获取举办城市为巴黎,以及新增的冲浪、滑板等特色项目,还有巴黎奥运会在塞纳河举办公开水域比赛等信息。接着,将这些信息整合,生成“2024年夏季奥运会的举办城市是法国巴黎。该届奥运会新增了冲浪、滑板等深受年轻人喜爱的项目”的回答。
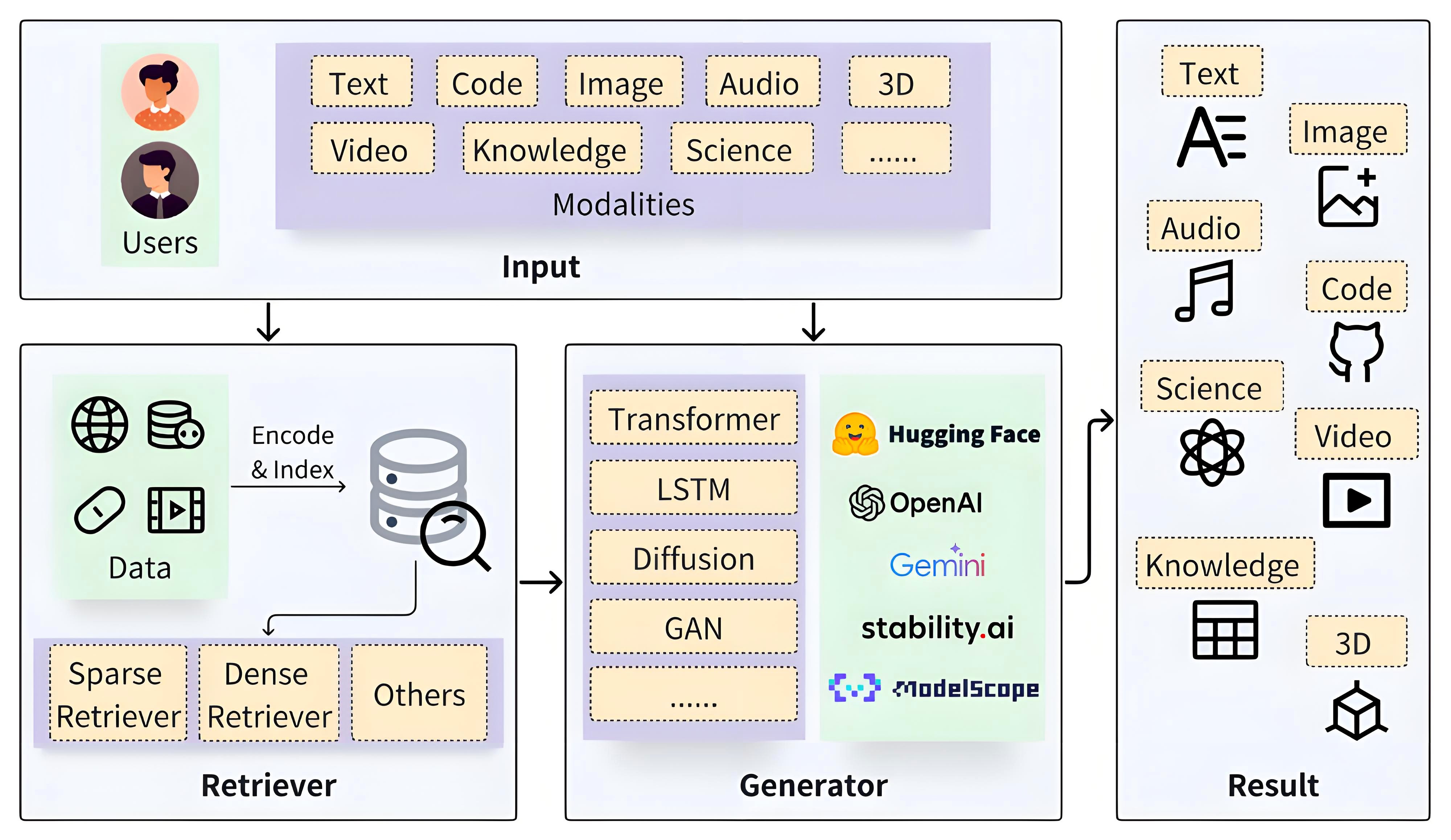
基础的RAG系统
为清晰阐述RAG系统的基本原理与实现逻辑,本部分聚焦其核心流程(检索+生成)的简化模型展开说明。
RAG系统的核心机制是在生成答案前,先从知识库中检索相关信息,再以这些信息为依据引导生成过程。这一机制带来多重优势:既能显著提升结果的准确性与相关性,有效缓解模型幻觉问题;又能通过仅更新知识库即可纳入新知识(无需重新训练模型),实现快速迭代;同时增强结果可追溯性,大幅提升大模型应用的可靠性与实用性。基础RAG系统更加详细介绍可以参考:RAG到底咋工作的。
一个基础的RAG系统通过以下核心模块协同实现上述流程:
- 文档处理模块:负责加载文章、书籍、对话、代码等各类原始文本,并将其切分为便于处理的片段。切分通常以句子为单位,且会特意保留片段间的部分重叠内容。此举可避免语义被生硬割裂,从而提高后续检索准确性。
- 向量编码器:借助Embedding模型将文本片段转化为向量。通俗而言,就是将文字“翻译”为计算机可理解的数字向量,使文本语义转化为可计算的数值特征。
- 向量数据库:作为专门存储文档片段及其对应向量的载体,在文本切分与向量编码完成后,会集中存储这些数据,为后续快速检索奠定基础。
- 检索器:作为连接用户查询与数据库的“桥梁”,接收用户查询(Query)后,通过计算查询向量与数据库中向量的相似度,快速定位最相关的文档片段。
- LLM:以检索到的相关文档片段为上下文,结合自身语言理解能力生成贴合用户需求的自然语言答案,最终实现“基于事实的智能回答”。
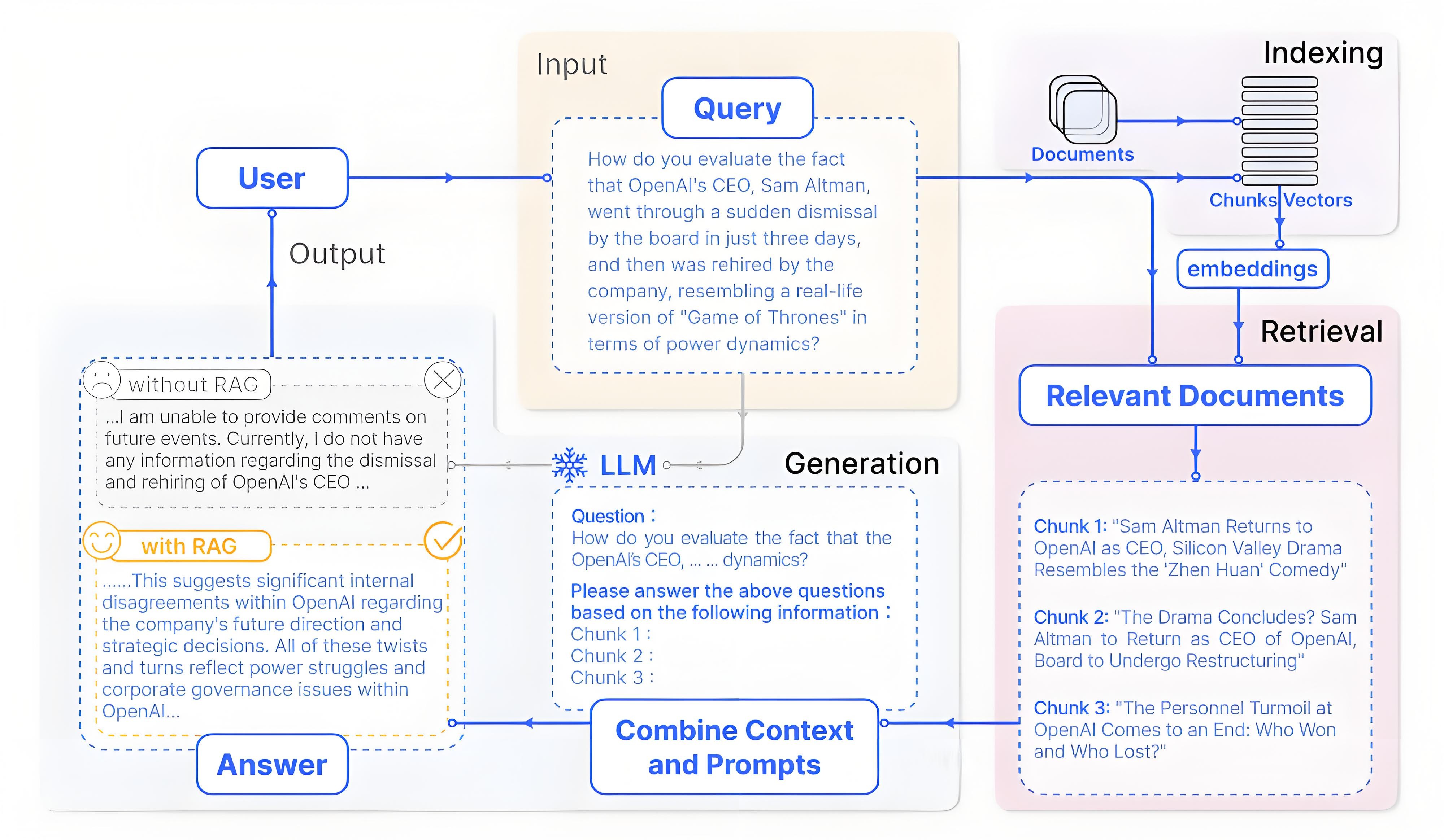
上述模块的协作可梳理为RAG的基础流程,即索引、检索、生成三个核心环节,各环节与模块的对应关系如下:
- 索引:借助文档处理模块、向量编码器、向量数据库,将文档库分割为较短片段,再通过编码器构建向量索引。
- 检索:依托上述三者,根据问题与片段的相似度检索相关文档片段。
- 生成:由LLM以检索到的上下文为条件,生成问题的回答。
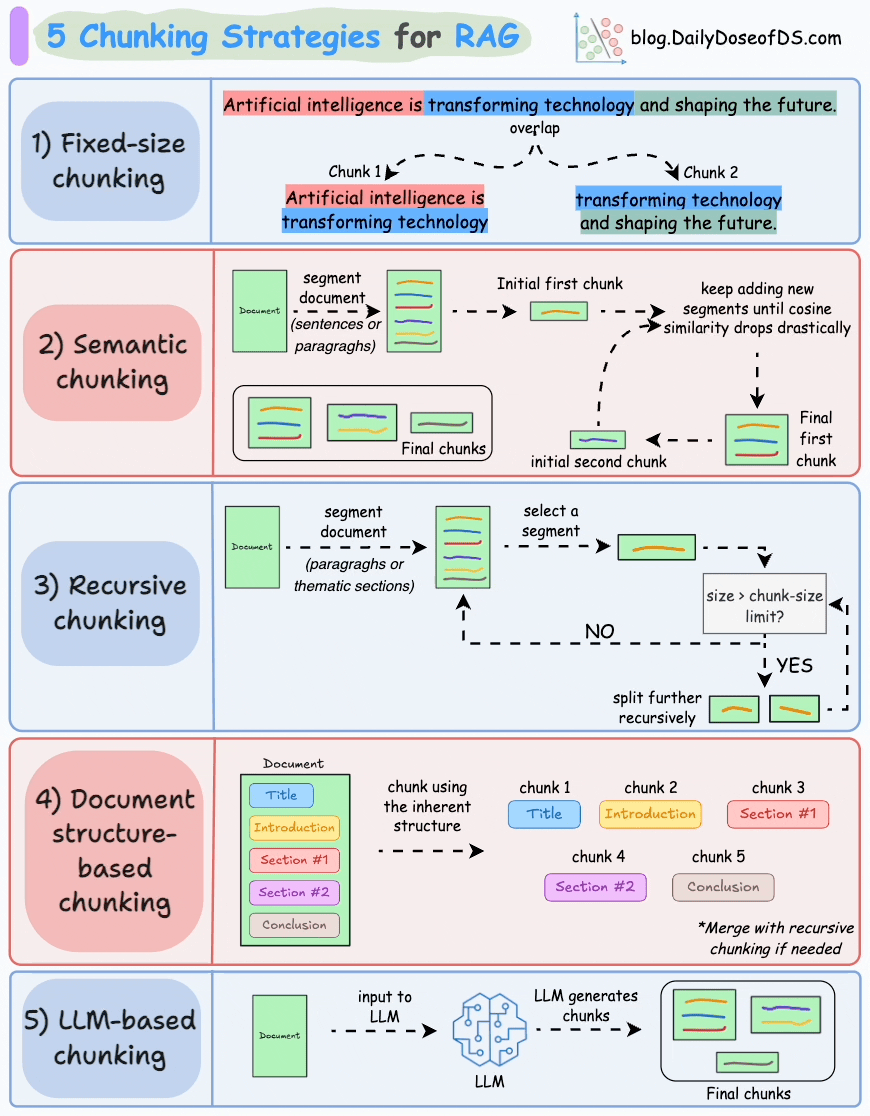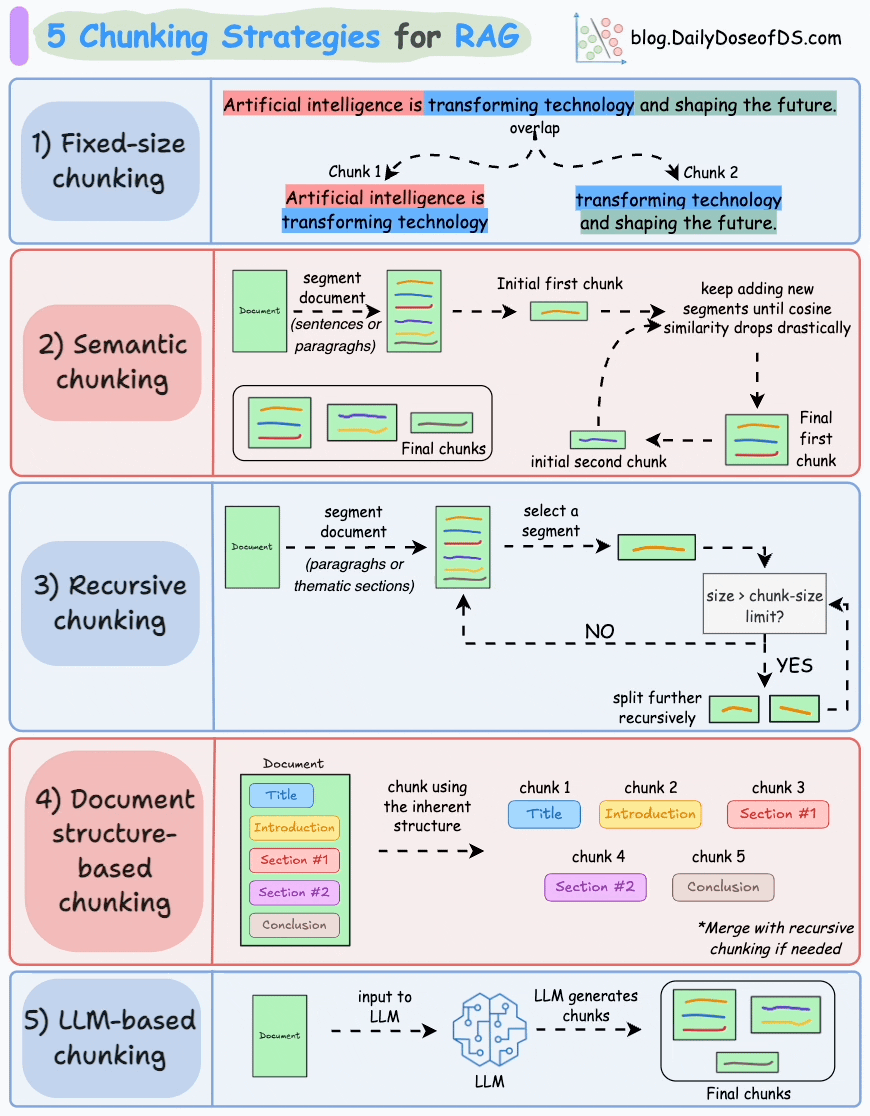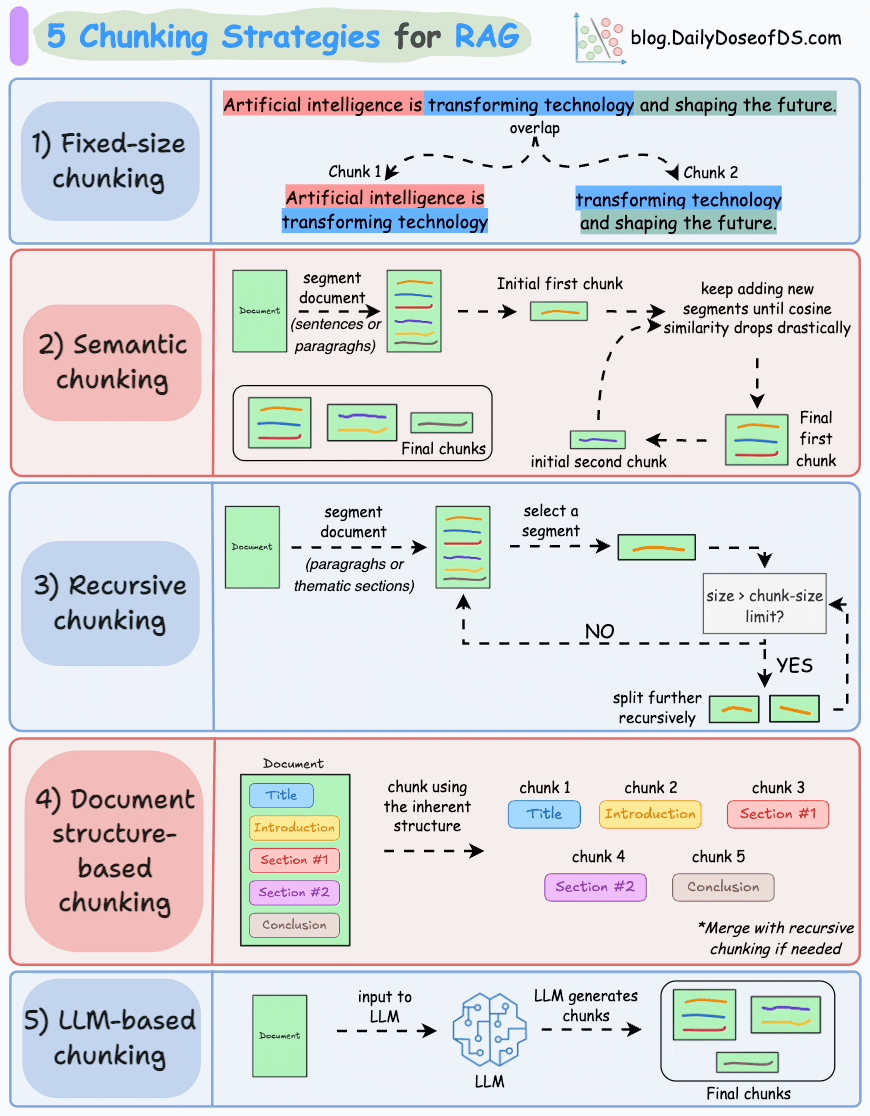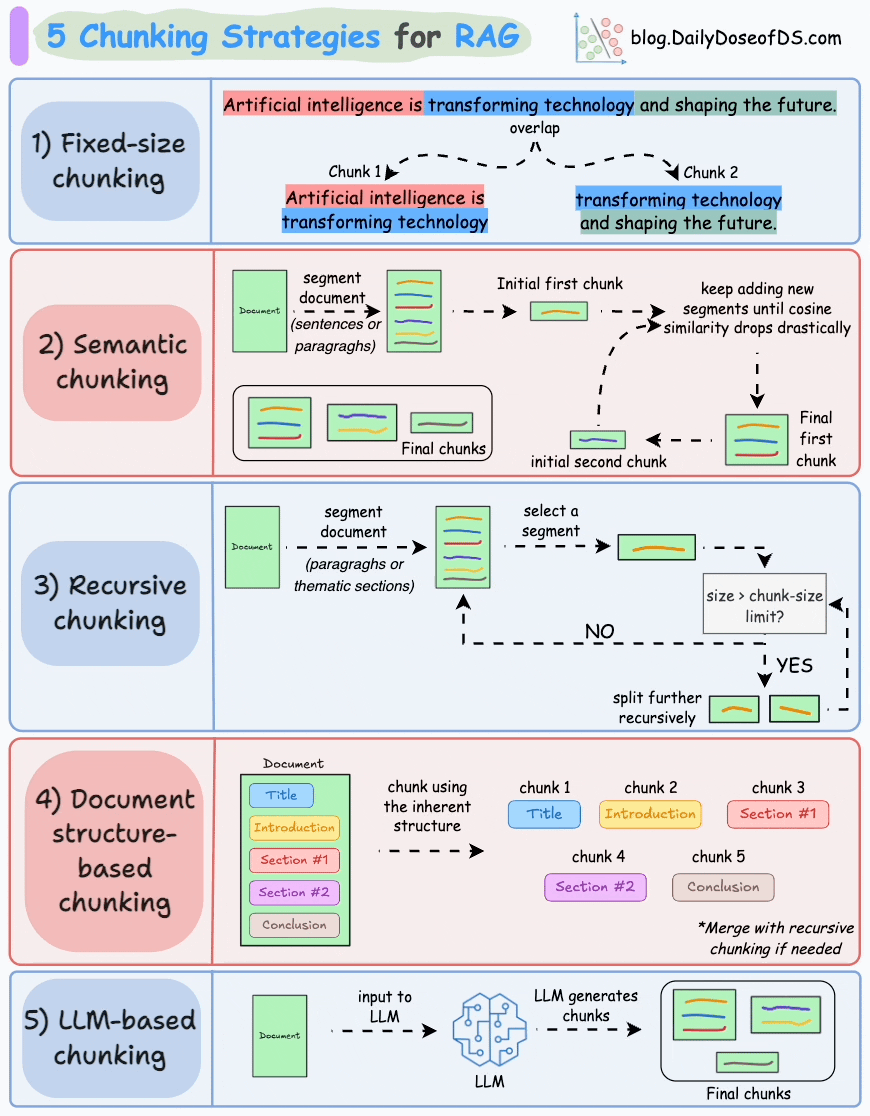
1.3 RAG系统工作流程详细介绍
本节主要在1.2节基础上详细介绍RAG系统的工作流程,相关内容更加详细的介绍可以见:16 Techniques to Supercharge and Build Real-world RAG Systems。
1.文本分段
文档处理模块首先将外部文档拆分为文本片段,目的是避免因文档过长导致的检索效率低、语义理解受限、资源浪费、生成质量下降及歧义风险增加等问题。合理分段是保障后续检索上下文有效性的前提。
- 文本片段向量化
完成文本分段后,借助向量编码器将各文本片段转化为语义向量。目前主流的做法是采用Transformer模型,其强大的上下文理解能力,正是生成高质量语义向量的关键。关于文本向量的提取方法,可参考文章:Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring。
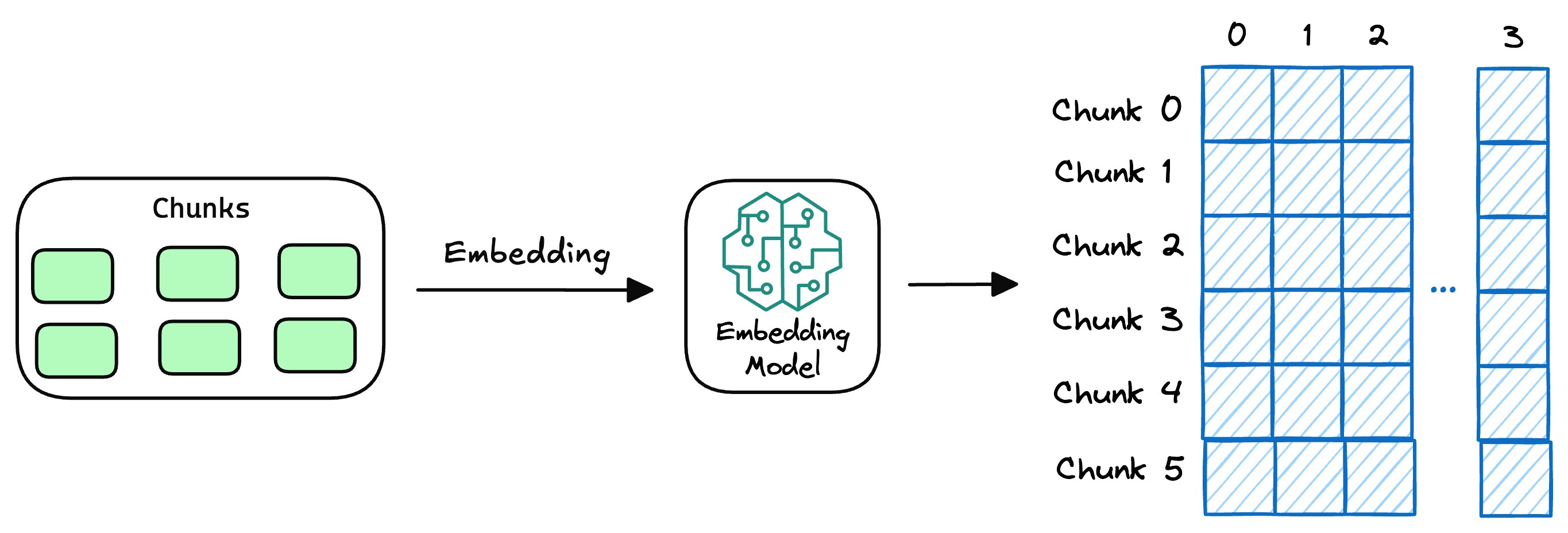
- 向量存储与知识库构建
将文本向量存入向量数据库,数据库通过关联存储原始内容与对应向量构建外部知识文本库。作为RAG的知识存储层,向量数据库聚合各类知识,为查询响应提供精准依据。
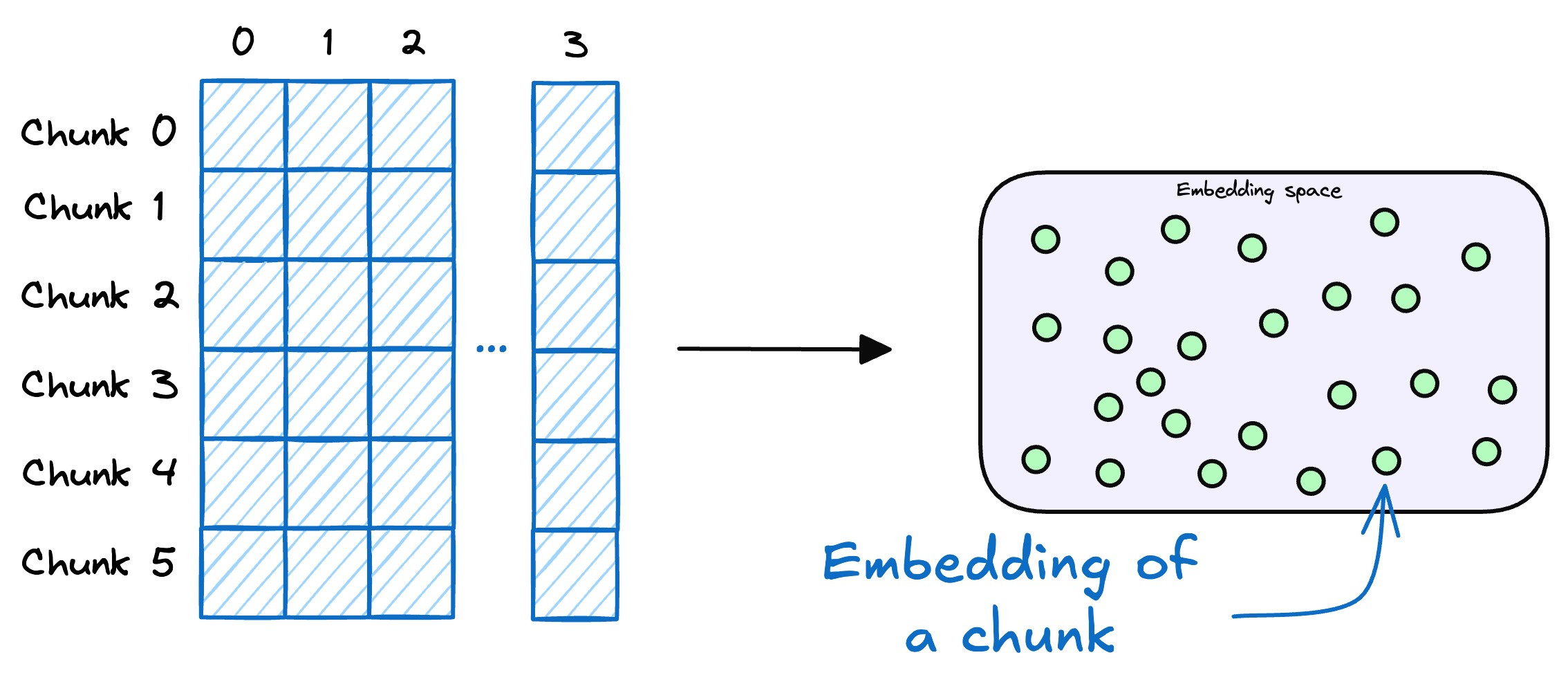
- 用户查询向量化
用户输入查询文本(query)后,系统使用与构建知识库时一致的向量编码器将其转化为向量,确保语义空间一致性。
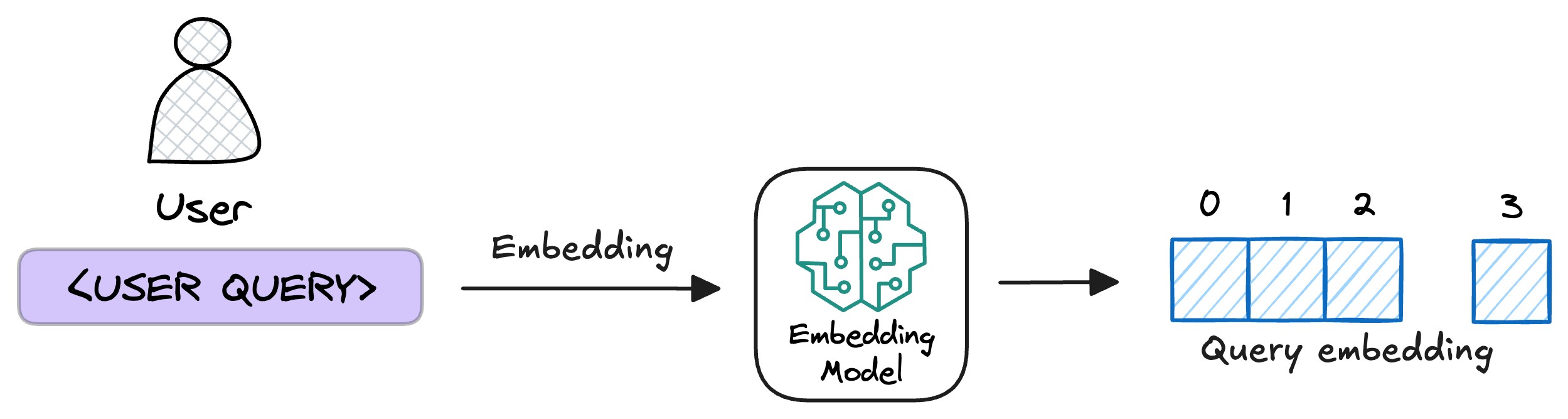
- 相似片段检索
检索器通过比对查询向量与数据库中存储的文本向量,定位相似度最高的信息。
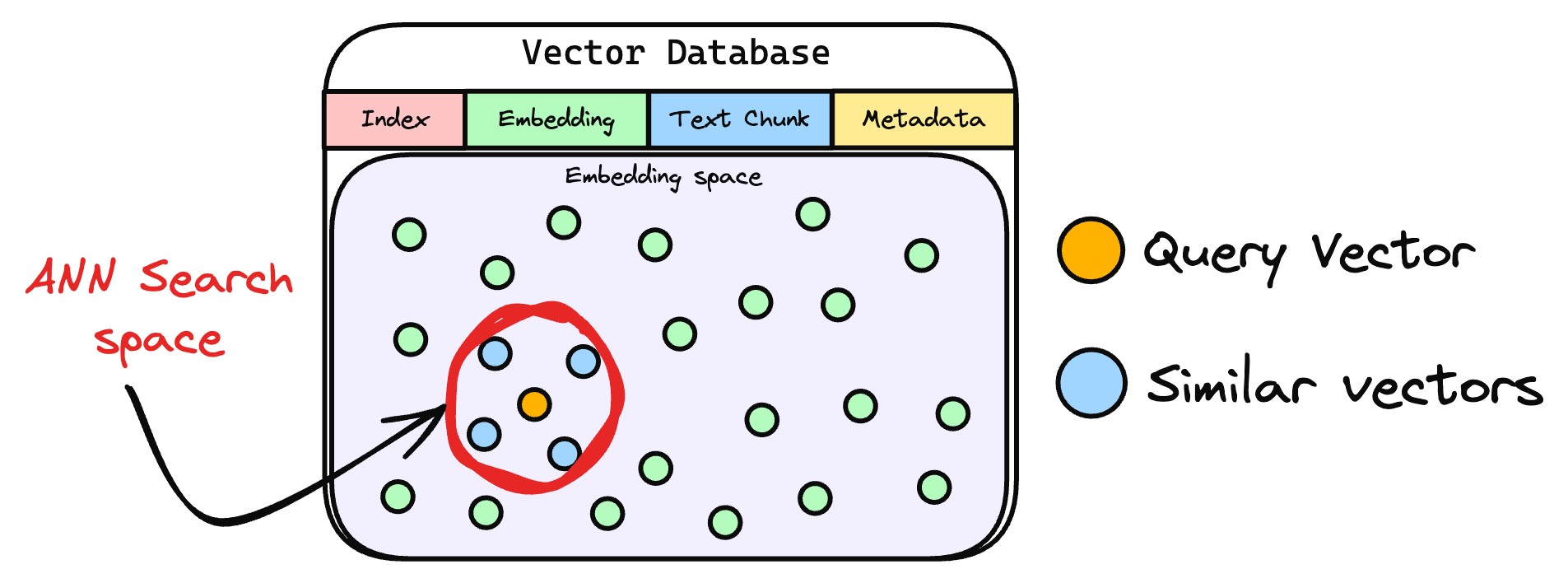
实际应用中,检索器通过近似最近邻搜索返回前k个(topk)最相似片段,这是因为复杂查询常关联多个相关内容,多结果能避免关键信息遗漏,为响应生成提供全面依据。
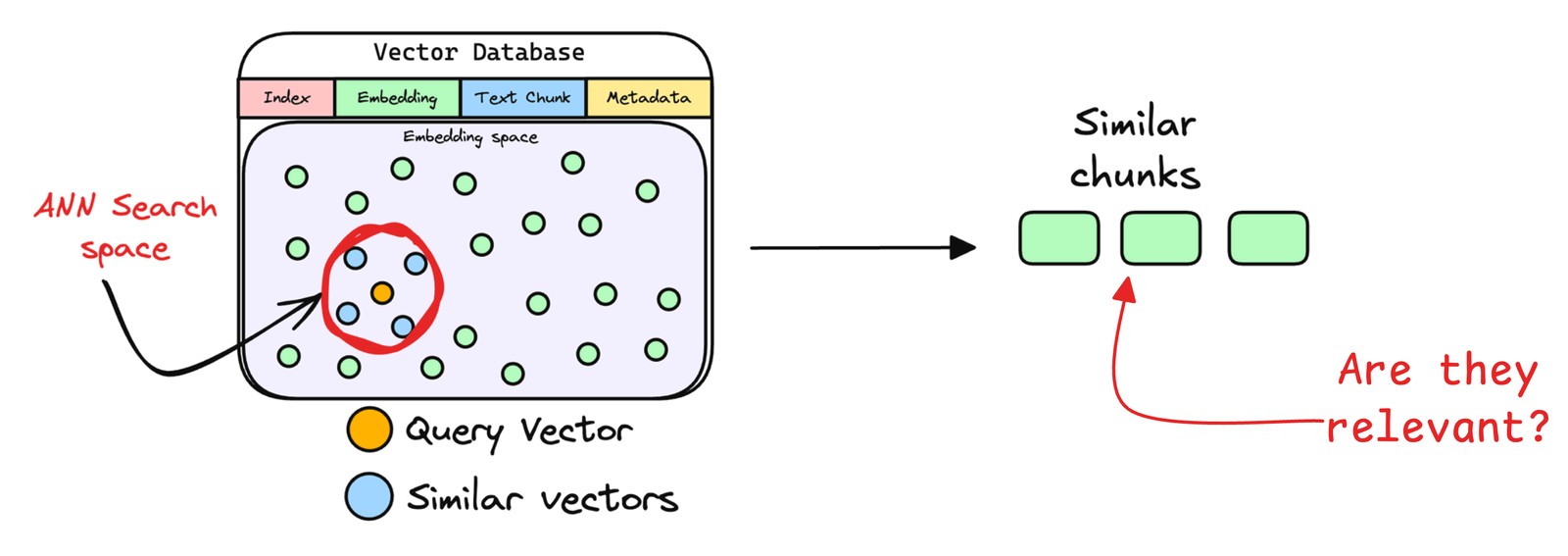
- 文本片段重排序
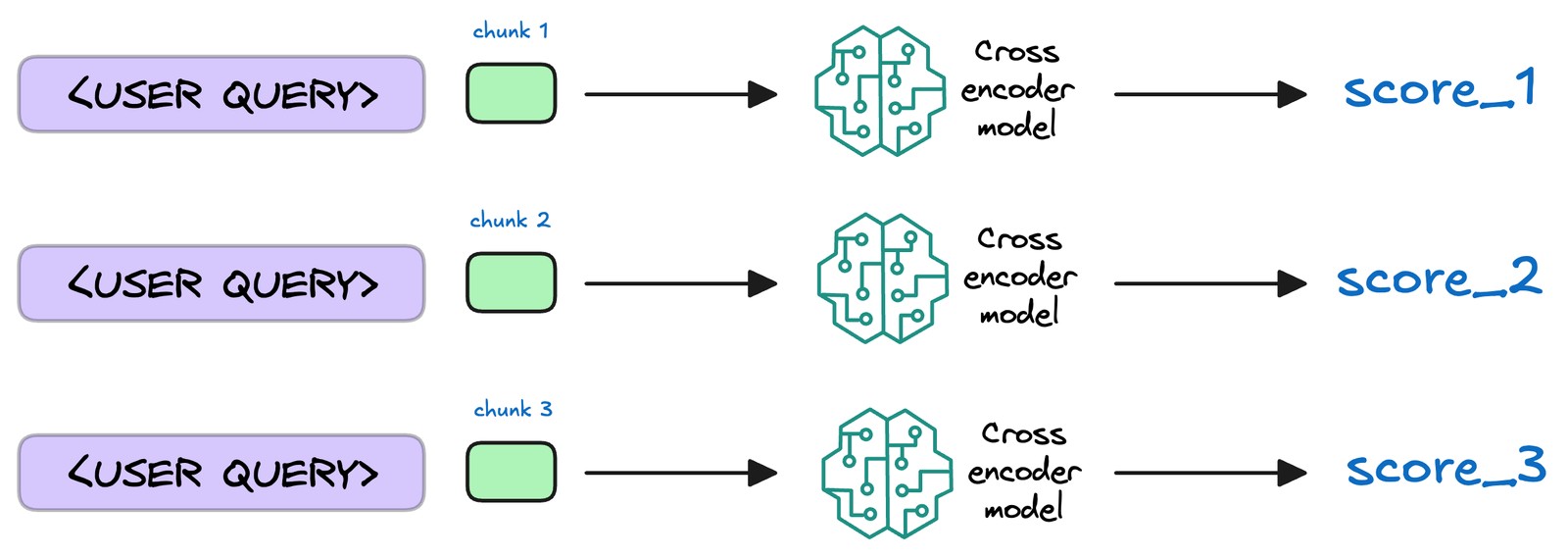
检索完成后,需进一步处理挑选出的文档片段,将相关性最高的文本段落置于最前,这一过程称为重排序。此步骤通常使用Reranker模型,这类模型多为交叉编码器,会评估查询与各候选段落的相关性并给出精确相关度分数,随后依分数重新排序,将最相关段落置于前列,便于生成模型优先选用。
这样做能提升后续生成内容的准确性和针对性,不过并非所有RAG应用都包含此步骤。
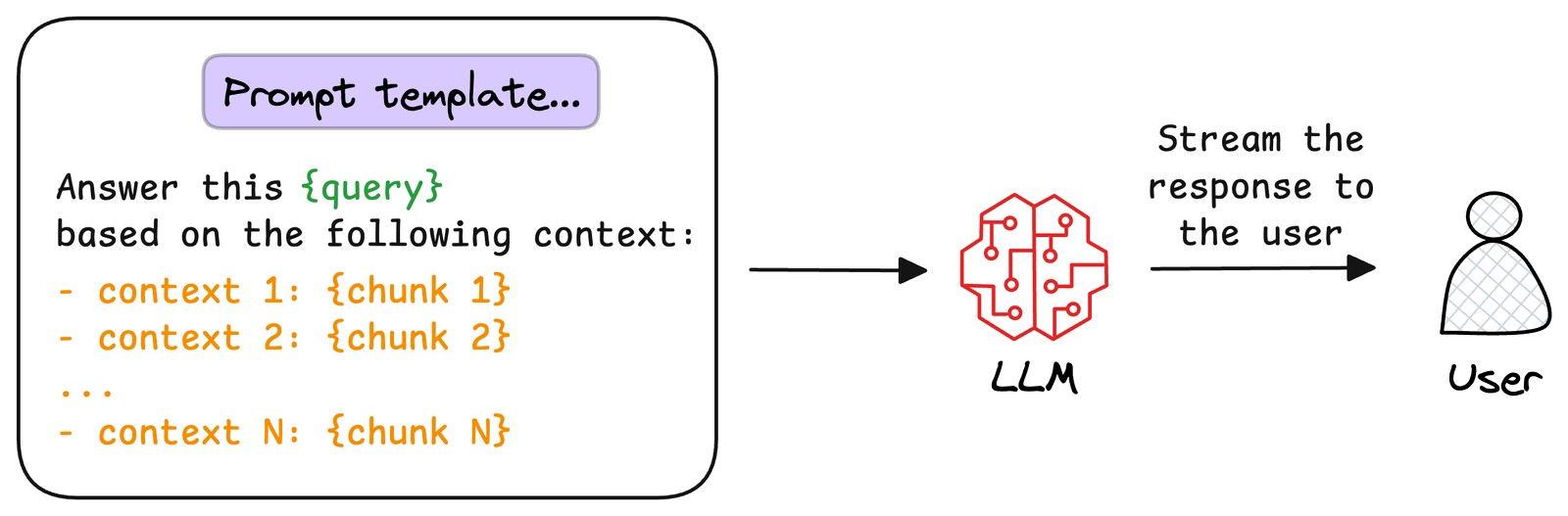
- 生成回答
将用户原始查询与检索到的文本片段整合为提示模板,输入至LLM。模型以文本片段为上下文,生成既融合文档信息、又具备连贯性和相关性的回答,直接回应用户查询。
2 RAG技术演进趋势和常见问题
2.1 RAG技术优化与演进趋势
2.1.1 RAG技术增强路径
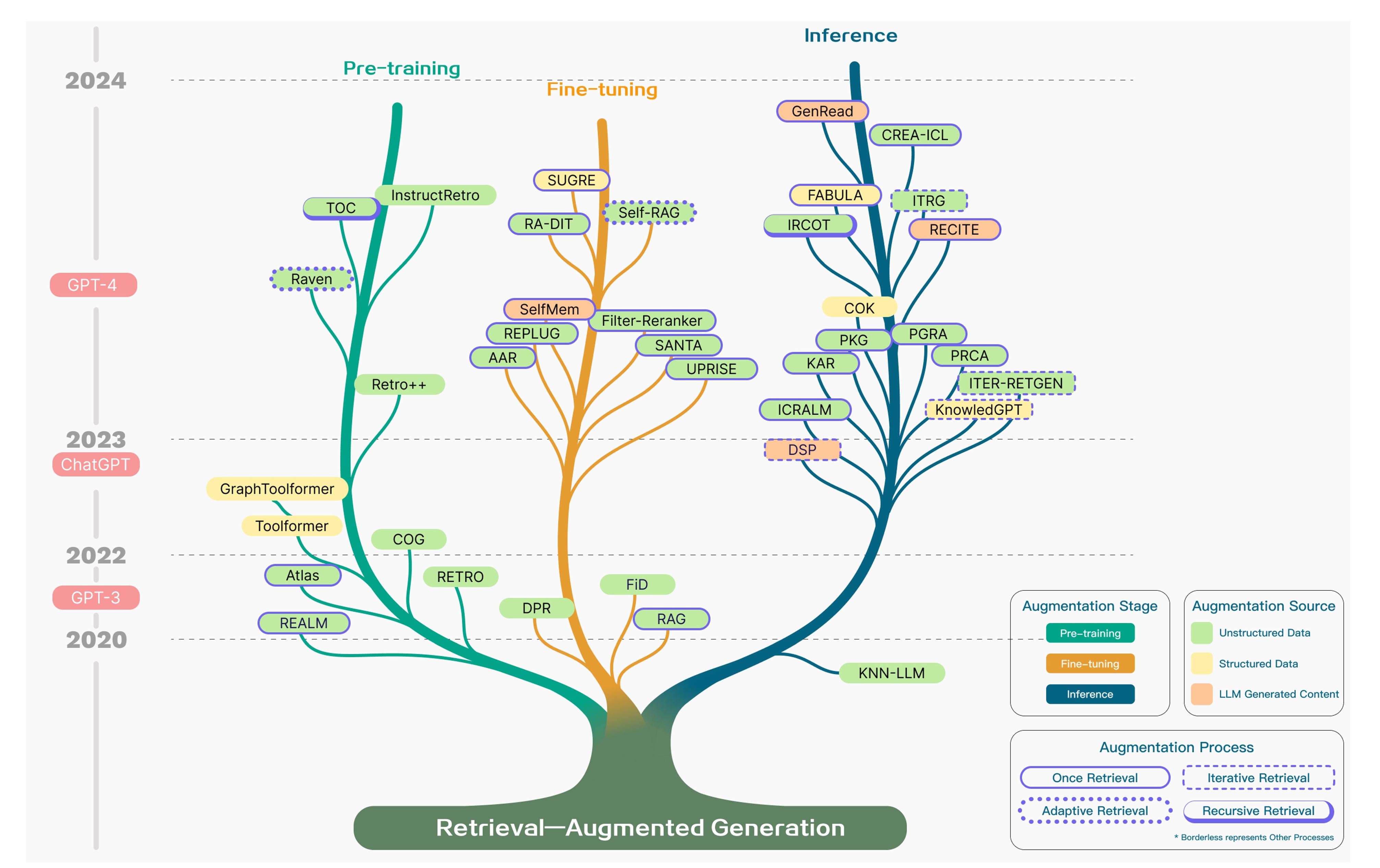
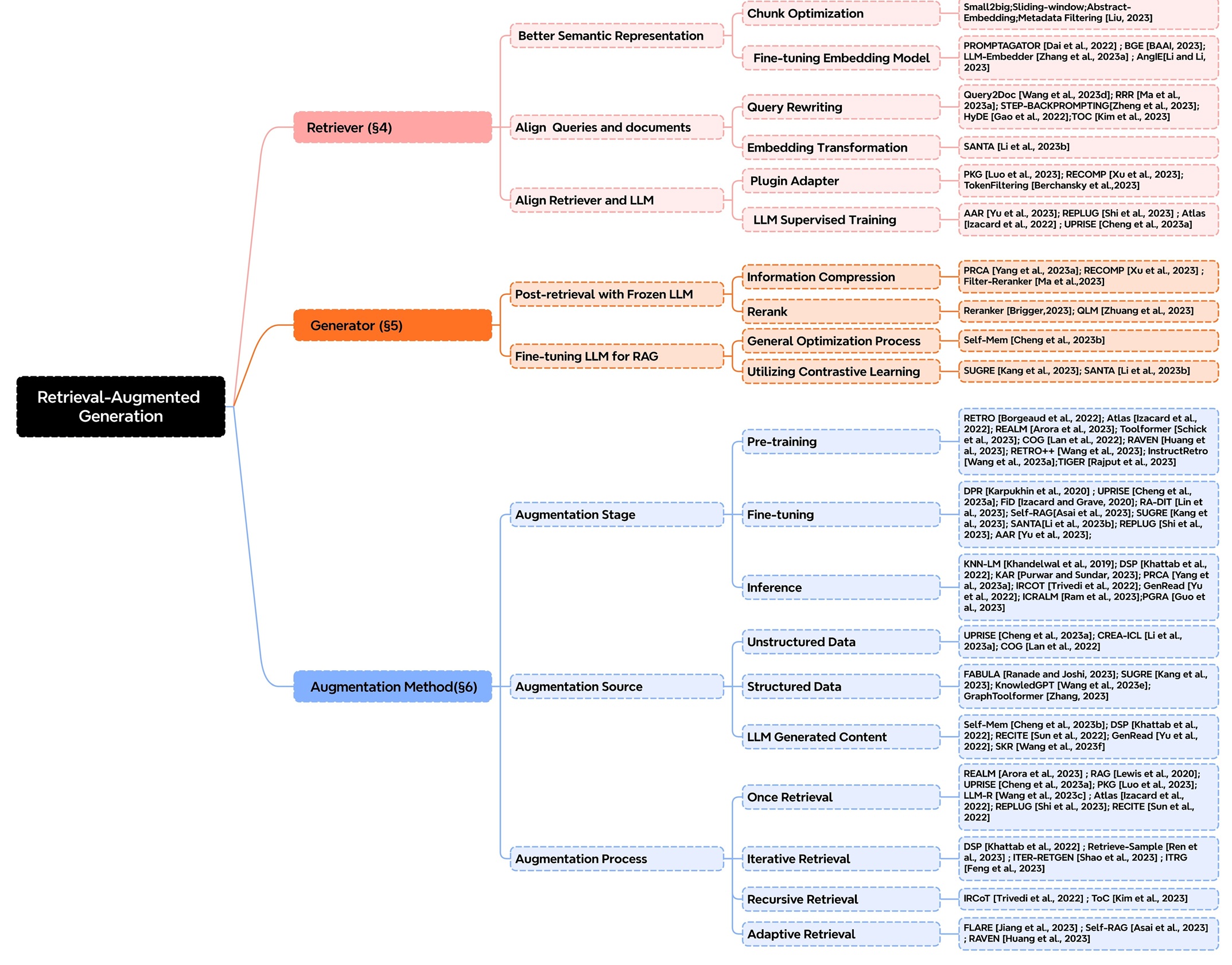
随着LLM的迅猛发展,RAG技术同步进入快速演进阶段。目前,已有大量研究与实践从多维度切入。下面将从增强阶段、增强来源和增强过程三个方面,介绍现有技术如何通过多样化手段提升RAG的检索精度并优化运行效率。
增强阶段
从技术增强的阶段特性来看,LLM在预训练、微调和推理环节的优化方式具体如下:
- Pre-training(预训练阶段):引入检索增强机制,强化模型对外部知识的融合能力
- Fine-tuning(微调阶段):依托检索优化手段,提升模型对特定任务的适配性能
- Inference(推理阶段):通过动态检索知识辅助生成过程,这也是RAG技术最核心的应用场景
增强来源
在RAG技术中,增强来源指通过外部数据弥补模型固有缺陷的信息渠道,主要包括三类:
- 非结构化数据(天然文本形式,如文章、小说)
- 定义:无固定格式的文本内容,涵盖新闻、论文、小说、网页段落等。
- 示例:
- 模型预训练时学习的百科“李白生平”纯文字词条;
- 推理阶段检索的问答网站“如何评价李白”的散文式用户回答。
- 特点:人类可直接阅读,但提取关键信息需“大海捞针”(例如从一篇论文中定位某句话)。
- 结构化数据(规整格式呈现,如表格、数据库)
- 定义:格式明确的数据形态,包括Excel表格、数据库表、知识图谱(含节点与关系)等。
- 示例:
- 模型预训练时学习的“中国诗人朝代表”(表格中包含“姓名-朝代-代表作”字段);
- 推理时查询知识图谱中“李白→好友→杜甫”的关联关系。
- 特点:数据排列规整,可精准提取信息(如直接获取表格中的“李白生卒年”),但要求模型具备解析格式的能力(如表格解析能力)。
- LLM生成内容(模型实时生成的思考草稿)
- 定义:模型在推理过程中临时产生的文本(非外部现成信息,属于思考阶段的动态产物)。
- 示例:
- 回答“李白与杜甫的关系”时,模型先自主生成假设:“他们是好友,杜甫曾作《赠李白》”(此为模型实时构思的内容);
- 随后以该假设为线索,检索《杜工部集》中的诗句进行验证。
- 特点:具备动态性与灵活性(模型边思考边生成),但可能存在误差(如假设错误需通过检索修正)。
一句话总结差异:
- 非结构化数据与结构化数据:借助外部现成的“知识储备”(他人撰写的文章、表格等);
- LLM生成内容:借助自身临时的“脑暴草稿”(模型推理中动态生成的内容,用作检索线索)。
增强过程
增强过程指模型通过检索知识辅助生成内容的机制,核心在于检索策略的逻辑设计,具体包括以下几类:
- 一次检索(Once Retrieval)
- 定义:针对问题仅执行单次检索,直接用结果生成答案。
- 类比:查字典时只翻一次页码,不论解释是否准确便直接引用。
- 特点:操作简单、效率高,但可能因检索结果不全或问题需多维度知识而遗漏信息。
- 迭代检索(Iterative Retrieval)
- 定义:基于首次生成的内容反复检索补充知识,逐步优化答案。
- 类比:写作文时先列大纲(首次生成),发现“李白的好友”仅提及杜甫,便再查高适、王昌龄等资料(迭代检索)以补充内容。
- 特点:形成“生成→反馈→再检索”的循环,类似“游戏中复活后继续闯关”。
- 自适应检索(Adaptive Pattern)
- 定义:根据任务类型或生成状态动态调整检索策略,例如切换数据库、调整检索范围等。
- 类比:玩游戏时,遇“历史题”切换至历史数据库,遇“数学题”切换至公式库;或发现生成内容模糊时,扩大检索范围。
- 特点:灵活性强,如同“智能切换武器”,但需模型具备判断“何时使用何种策略”的能力。
- 递归检索(Recursive Retrieval)
- 定义:将复杂问题拆解为子问题,逐层递归检索,像“俄罗斯套娃”般深入探究。
- 类比:破案时,先查“李白的死因”(主问题),拆解为“李白晚年健康状况”(子问题1),再拆解为“唐朝医疗水平”(子问题2),每层均进行检索。
- 核心逻辑:遵循“问题→拆解→子检索→再拆解→深层检索”的路径,与递归函数思路一致。
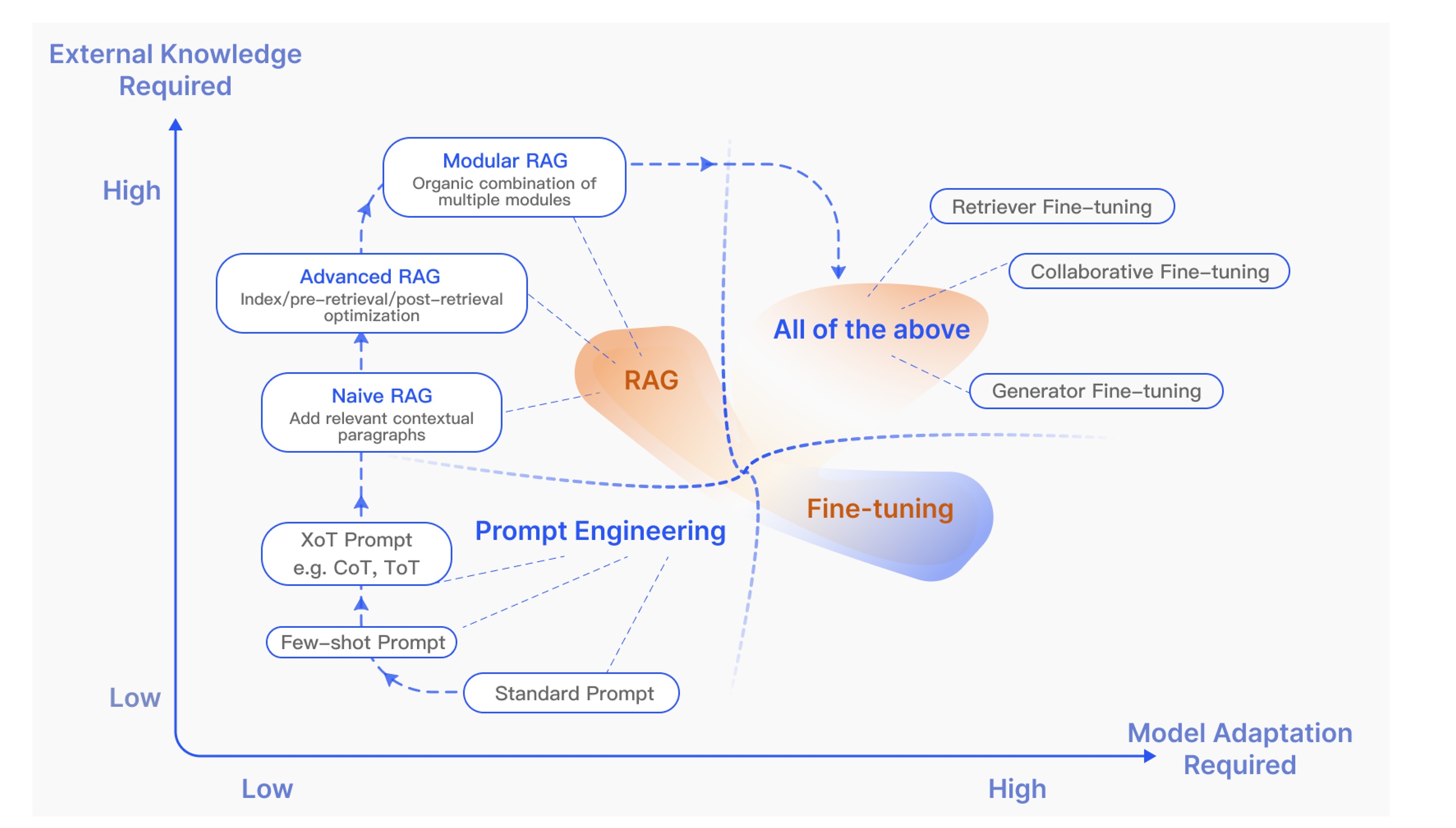
总之,RAG发展的三大关键技术包括增强阶段、数据来源及处理过程,这三大技术能够清晰呈现RAG核心组件的分类体系,同时RAG的实现模式也在不断演变。早期的RAG可能只是 “简单检索+直接生成” 的模式,而随着技术进步,其实现中已融入更复杂的环节,这些具体实现方法始终处于动态变化中,愈发精细且能更好地适配不同场景。
搭建RAG系统时,技术选型的应该以需求适配为导向,兼顾效果的评估与优化,选择能高效支撑目标场景且表现更优的方案。关于RAG系统的构建和技术选型可以参考:文章17种RAG架构实现原理与选型或参考下一节内容。
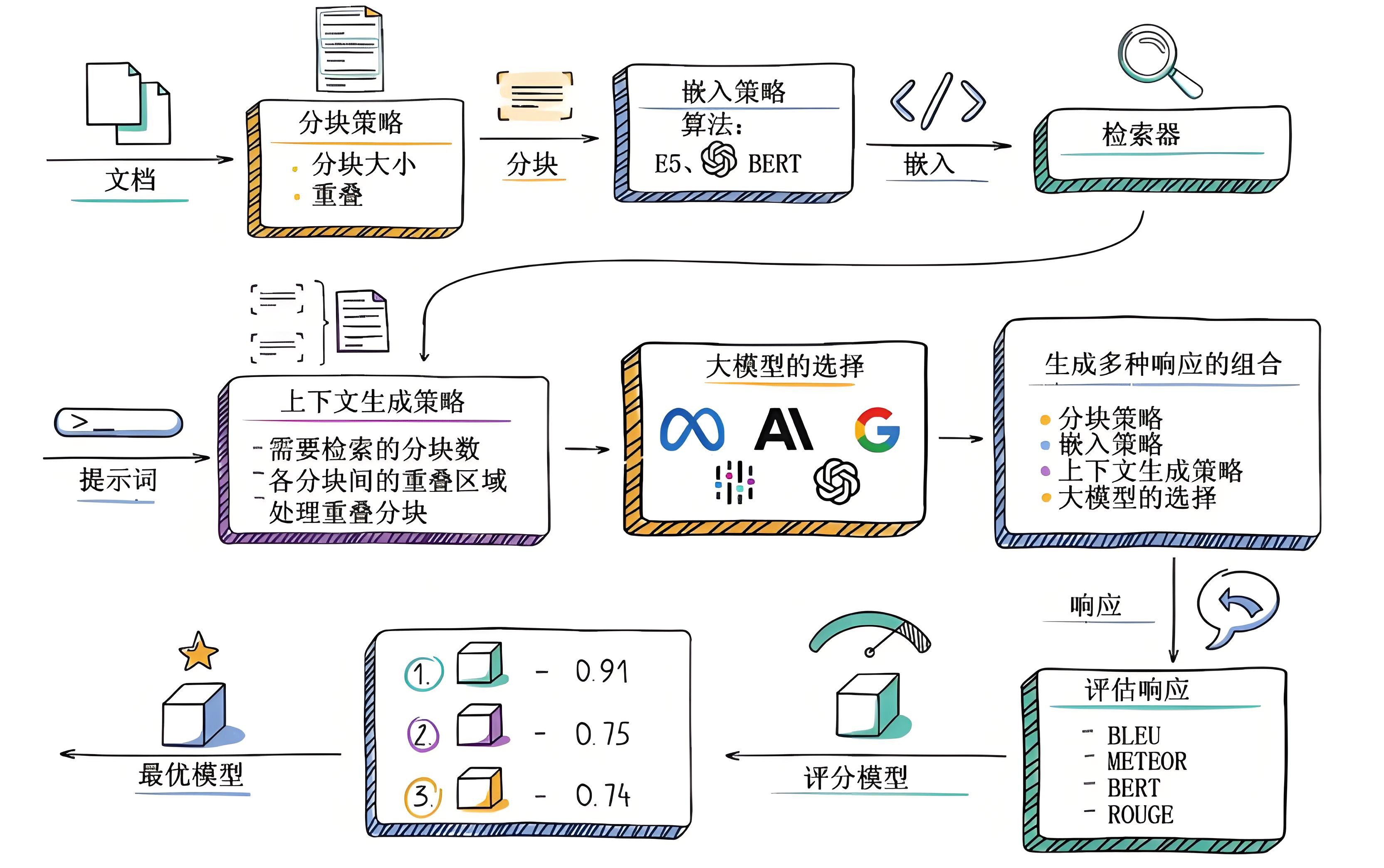
2.1.2 RAG系统实现模式的演化
实现高效文档检索需要解决三大核心问题:
- 构建精确的语义表示,确保文档和查询的嵌入能准确捕捉其含义。
- 对齐查询与文档的语义空间,缩小检索模型理解的查询意图与文档实际内容之间的语义鸿沟。
- 适配检索器输出与LLM偏好,使检索到的上下文信息更符合下游大型语言模型的生成需求。
为应对上述挑战,在RAG架构之上引入了检索前优化和检索后优化的策略。
- 检索前优化,提升索引质量如文档切分粒度优化、元数据增强和查询处理如语义转换、关键词扩展,旨在改善检索相关性。
- 检索后优化,对检索结果进行过滤、去冗余、重排序按重要性和信息压缩整合,确保输入LLM的上下文信息更精炼相关。
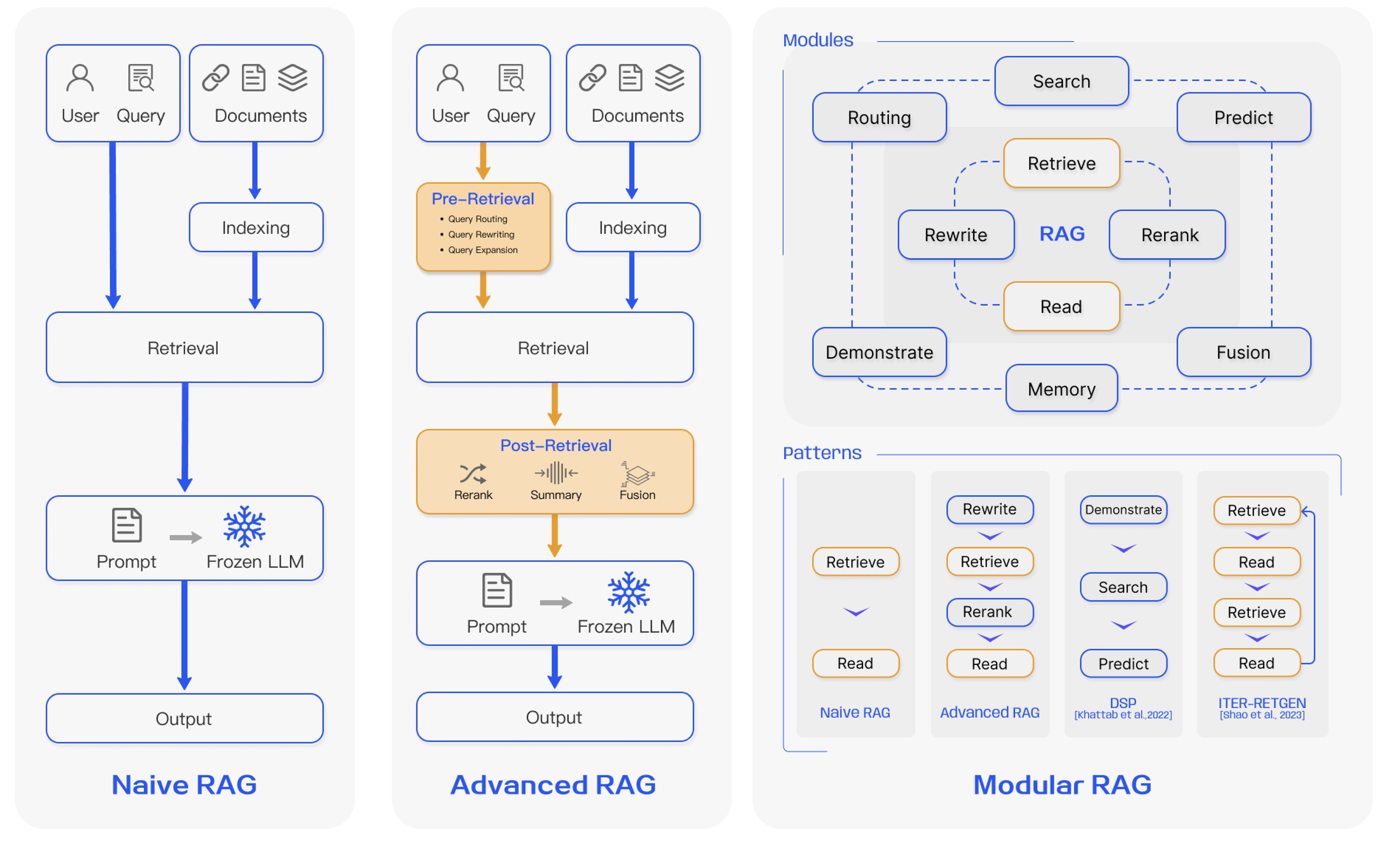
基于优化策略的应用深度,当前RAG研究形成了三种主要范式:
-
基础RAG(Naive RAG)
- 遵循基础流程索引、检索、生成。
- 主要痛点:
- 检索质量低,导致检索结果不精准不全面。
- 生成质量受限,LLM易产生幻觉,难以有效融合检索到的上下文与当前生成任务。
- 信息冗余与风格冲突,检索结果常包含重复冗余信息,且不同来源文本风格语气不一致,影响生成连贯性。
- 过度依赖风险,LLM可能过度依赖有时不准确的检索信息。
-
进阶RAG(Advanced RAG)
- 通过强化检索前和检索后优化的流程,并改进索引如滑动窗口、细粒度分割、元数据利用,以解决基础RAG的缺陷。
- 检索前优化:包括数据粒度优化、索引结构调整、元数据注入、向量对齐、混合检索如结合稀疏与稠密检索等。
- 检索核心:依赖嵌入模型计算查询与文档块的相似度。
- 检索后优化:采用重排序和提示压缩技术,克服上下文窗口限制,提炼关键信息。
- 潜在挑战:以复杂度换效果,提升了基础RAG性能,但其额外模块的引入也带来了效率、泛化性和可维护性的新挑战。
-
模块化RAG(Modular RAG)
- 强调框架的高度灵活性与适应性,可将RAG流程拆解为可替换可重组的模块,以解决特定问题。
- 优化方向:
- 提升信息效率与质量,整合多种检索技术,优化检索步骤如引入认知回溯机制,实施多样化查询策略,有效利用嵌入相似性。
- 支持复杂交互,模块化设计便于处理迭代检索与多轮生成,如对回溯提示的响应。
- 潜在挑战:当LLM对主题知识匮乏时,依赖检索信息可能导致错误率上升。
事实上除了这三种RAG范式,还有其他更多的范式,具体可参考:一篇搞明白RAG的几种不同类型。
总之,RAG技术及其构成体系具有较强的复杂性,涵盖知识获取、数据预处理、索引构建、检索策略优化、生成模型调优等多个环节。对于应用层面者而言,优先聚焦于检索模块的精准性提升(如向量数据库选型、相似度算法优化)与生成模块的语义连贯性构建(如提示词工程、大模型适配)这两大核心基础,是快速掌握技术应用逻辑的有效路径。
2.2 RAG技术典型问题与优化方案
2.2.1 RAG技术常见问题及解决办法
本节主要介绍RAG技术的常见问题及相应解决办法,更详细的内容可参考文章Traditional RAG vs. HyDE。
- 问题与答案语义不匹配
检索到的文档可能与问题无关,甚至无关文档的余弦相似度可能高于含答案的文档。
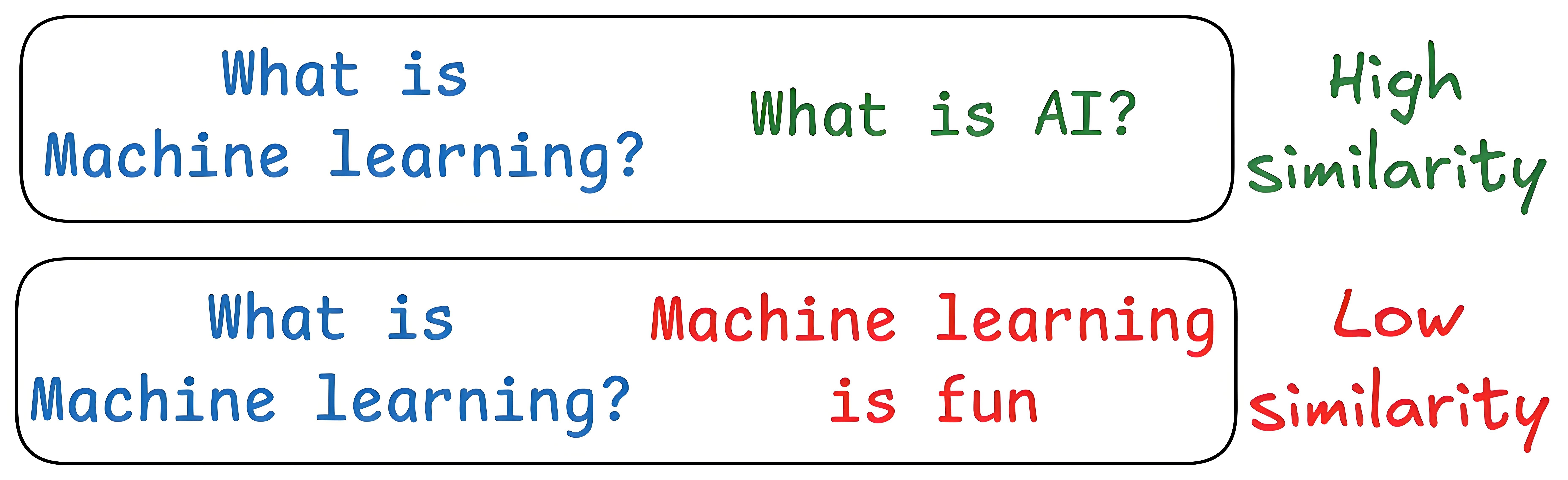
一种优化方案为:先用LLM针对问题生成假设答案,弥补表述模糊以明确语义指向;再将问题与假设答案转化为文本向量,通过向量拼接或加权求和等方式;最后用该文本向量查询向量数据库,提升匹配精度。
例如,对于问题“需要适合新手,考虑学习难度低,入门成本适中,便于携带的入门乐器”,LLM可生成假设答案以明确指向;再结合该问题与假设答案的语义向量查询数据库,就能精准匹配到“尤克里里学习难度低,入门成本低,体积小便于携带,适合新手入门”这类结果。
需注意这种方法只能在一定程度上减轻问题影响,无法完全消除问题本身的局限性。
- 语义相似性可能被弱化
部分含重要信息的长文本常夹杂背景描述、细节补充等无关内容,会稀释核心信息。如同糖水加水后味道变淡,导致RAG计算语义相似度时,与搜索内容的匹配度下降。反观短文本,即便内容不重要,若含少量相关词,因干扰少且相关词集中,与搜索内容的相似度反而更高。最终可能导致系统输出无关信息或遗漏关键信息,影响整体效果。
采用文本摘要或关键句抽取技术预处理长文档,同步进行精准分段、冗余清洗与核心内容提取,仅将浓缩后的核心信息存入语义向量库,再结合优化的检索策略精准匹配相关片段,是应对该问题的有效方法。
- 检索文档的关注偏差
基于相似性搜索从数据库检索文档时,通常按相似性度量排序,但LLM基于这些文档生成回答时,虽能通过位置编码明确感知输入顺序,其关注重点却不遵循人类“前序优先”的主观倾向,而是由注意力机制与上下文长度共同决定,短上下文时处理更均匀,长上下文则因“注意力稀释”更关注首尾文档。若高相似文档因位置靠后被忽略,会造成“检索优质但利用低效”,最终降低回答质量。
例如问“缓解颈椎痛的好办法”,数据库检索出6篇文档,按相似性从高到低排序,第4篇最相关,写了具体的穴位按摩法,第1篇只说“别久坐”。LLM处理这6篇长上下文时,注意力稀释,主要关注首尾,未太关注第4篇,最终回答只提“别久坐”,遗漏了最有效的穴位按摩法。明明检索到了优质信息却没用好,回答自然不够好。
应对方案可采用“关键文档首尾双曝光”策略:将检索结果中最相关的文档交替置于输入序列的头部和尾部,如复制最关键的1-3篇文档到首尾位置;利用LLM在长上下文中天然关注首尾的“注意力锚点效应”,首尾信息稀释度最低;确保高价值内容不被中间位置淹没,同时辅以文档内容浓缩,通过摘要压缩文本减少冗余干扰,以及显式指令引导,在输入中标注“请重点参考以下高相关文档”。三重措施协同突破注意力稀释瓶颈,显著提升优质检索结果的利用率。
- 需避免询问需整合全局信息的问题
使用RAG系统时,需避免需要全局信息汇总的问题,这类问题需整合大量分散数据,而RAG系统依赖的相似性搜索通常只能定位少数最相关文档,难以覆盖全部必要信息源,导致答案常出错。若答案集中在一两份文档中,相似性搜索精准高效,RAG系统表现良好,但若答案需遍历所有文档、聚合分散信息,相似性搜索则力不从心。本质上,RAG系统是检索增强工具,而非全局数据聚合器,处理跨文档汇总和统计类问题时存在天然局限。
在RAG系统中缓解全局汇总问题,核心是结合混合检索向量+关键词提升覆盖度,并通过查询分解让RAG系统分步处理子问题,最后聚合结果。若需强统计能力,需整合传统数据库执行聚合计算。
2.2.2 RAG系统固有挑战
除上述问题外,RAG系统还存在以下固有挑战:
- 检索效率与延迟问题:面对百万级文档等大规模知识库时,检索易产生高延迟,难以满足实时交互需求。
- 对知识库质量的高度依赖:生成结果直接受检索内容影响。若知识库存在数据过时、信息不完整或包含噪声等问题,会导致输出错误;同时,在小众领域等未覆盖场景中,其领域适应性较差。
- 上下文窗口限制:受生成模型上下文窗口容量所限,检索到的长文档可能被截断,造成关键信息丢失。
- 生成与检索的协同问题:
- 模型可能忽略检索结果,仅依赖自身参数生成错误信息(即"检索无用");
- 或过度依赖检索内容,机械复制片段而缺乏逻辑整合。
- 评估体系缺失:目前缺乏统一的量化指标来评估检索与生成的协同效果,人工评估成本高且难以标准化,阻碍了模型迭代优化。
RAG的这些固有挑战,源于检索与生成这两个复杂系统的耦合,其中涉及算法、数据及工程等多方面的权衡。由于目前这些挑战尚无法完全解决,因此在使用RAG技术时需要加以考量。关于这些固有挑战的详细介绍,可参考论文:Seven Failure Points When Engineering a Retrieval Augmented Generation System。
2.2.3 RAG技术与模型指令微调的对比
在构建LLM应用时,除了RAG技术,模型指令微调也是一种被广泛采用的技术路径。关于这两种技术的详细对比,可以参考文章Full-model Fine-tuning vs. LoRA vs. RAG。
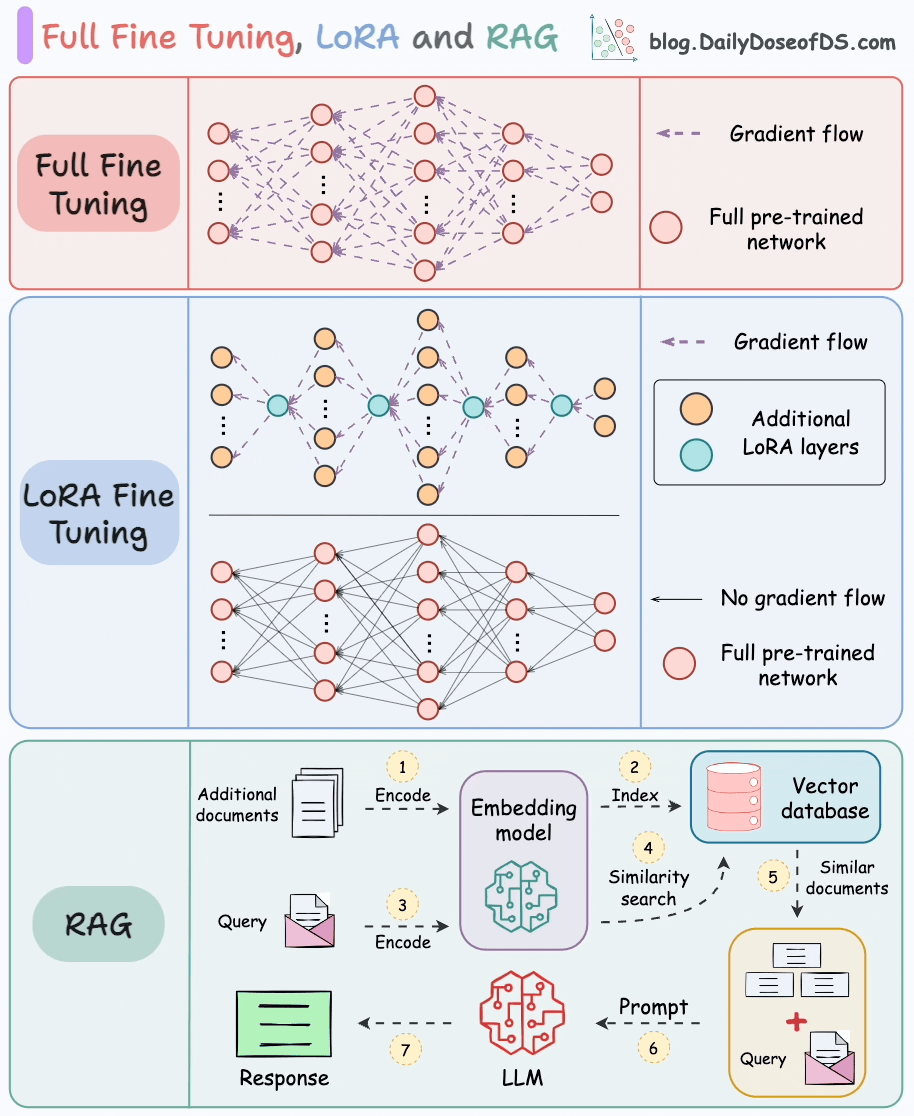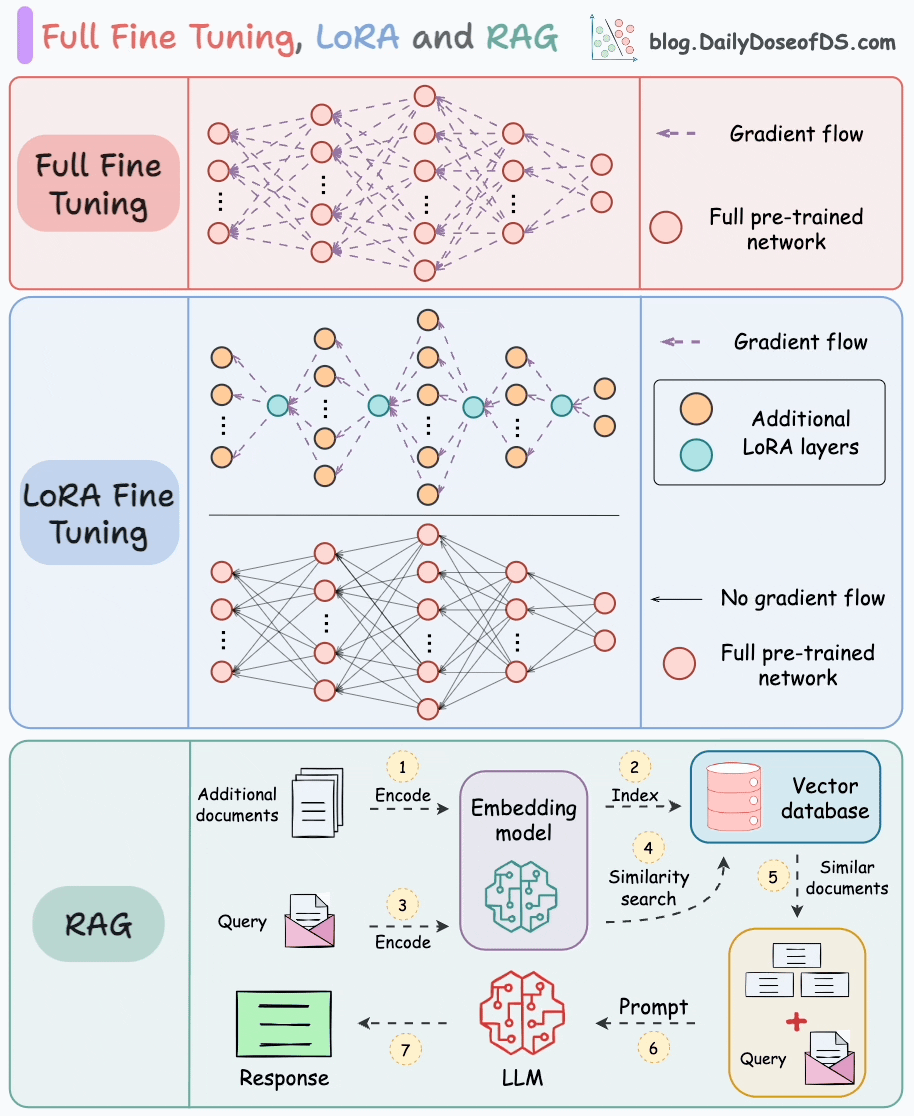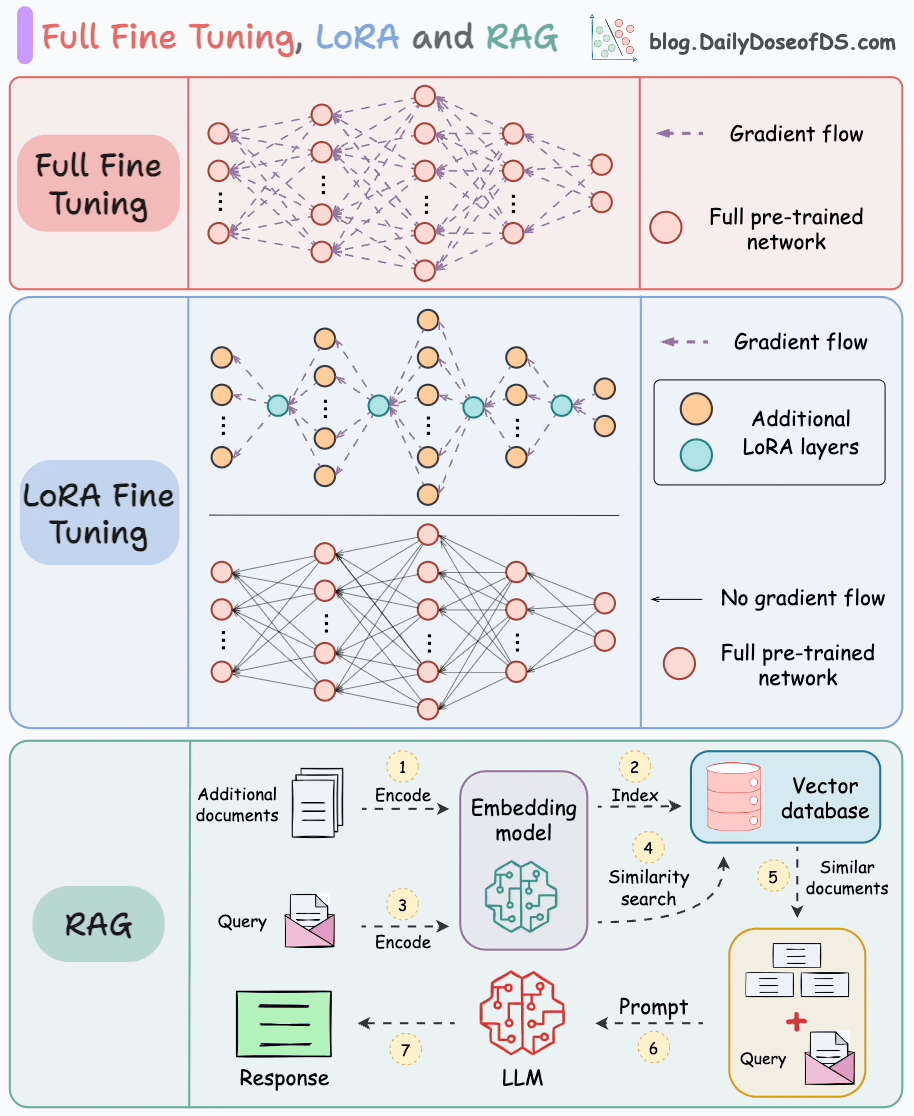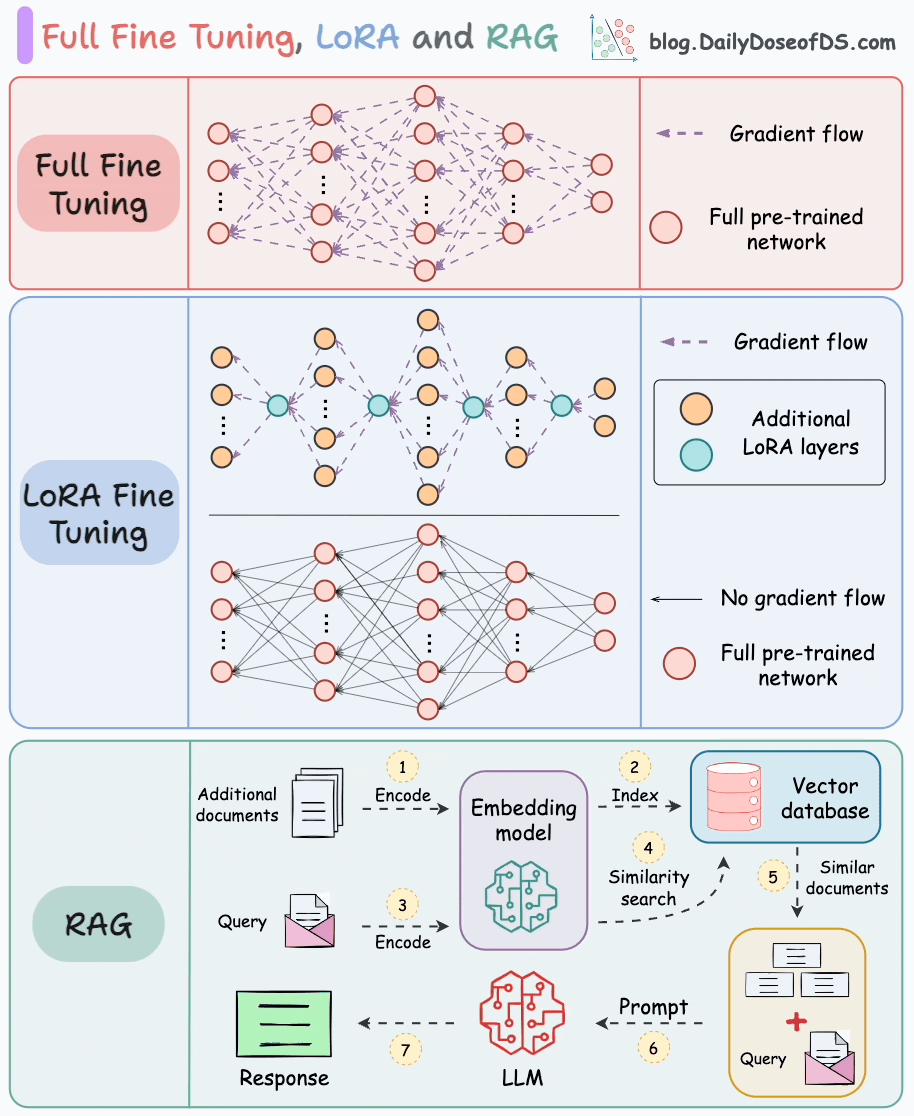
对比内容概览如下:
- 基础机制与数据需求
- RAG :通过检索外部知识库(文档、数据库等)获取信息,结合生成模型输出答案;无需修改模型参数,依赖知识库质量,无需标注训练数据。
- 指令微调 :在特定标注数据集上调整预训练模型参数,适配特定任务/领域;需高质量标注数据,直接修改模型参数。
- 更新机制与成本
- RAG :支持实时更新知识库,模型无需重新训练;仅涉及检索+生成,推理成本低。
- 指令微调 :知识更新需重新微调或增量训练,成本高(依赖GPU资源);无检索步骤,推理速度快。
- 优势与局限
- RAG :
✅ 优势:灵活适应新知识、降低幻觉风险(依赖权威数据源)、无需训练数据。
❌ 局限:检索延迟可能影响响应速度、依赖知识库质量、生成逻辑受限于检索片段。 - 指令微调 :
✅ 优势:输出风格可控、领域内任务性能更优、推理速度快(无检索步骤)。
❌ 局限:数据不足时易过拟合、知识更新需重新训练、可能产生事实性幻觉。
- 适用场景与典型应用
- RAG :适用于知识密集型任务(需动态/领域外知识),如开放域问答、医疗咨询、产品文档客服。
- 指令微调 :适用于需特定输出风格或领域专精的任务,如代码生成、情感分析、法律文本生成、专业术语翻译。
- 技术代表
- RAG :FAISS + GPT、DPR + BART
- 指令微调 :LoRA、Adapter、全参数微调
3 实战
3.1 RAG系统示例代码
本文第一章已详细阐述了RAG系统的基本工作流程,其核心环节涵盖:文本分段、文本片段向量化、向量存储与知识库构建、用户查询向量化、相似片段检索、文本片段重排序以及生成回答。
为了更好地解释RAG模型的原理和实现,本章将提供完整的示例代码,系统性地演示如何实现上述各个环节,从而构建一个可运行的最小化RAG应用系统。该部分内容参考自:Happy-LLM。
下面将介绍该示例各部分代码。所有代码需放在同一文件夹中,最后一个模块,即生成回答的代码为运行入口。请注意,代码中使用的均为基础版模型。
若回答效果欠佳,可能源于多方面因素:文档分块不合理、向量提取模型对领域语义捕捉不足、检索策略未返回最相关上下文、大语言模型对检索内容利用不充分,或测试文件与问题相关性低、对话历史累积造成干扰等。这些环节都会影响最终回答的准确性和针对性。实际搭建RAG系统可参考本文3.2节内容
0. 生成示例数据
这段代码文件是一个用于生成RAG系统测试文件的Python脚本,主要功能是创建几个包含特定内容的文本文件,注意输出文件都为txt格式。
# Generate.py
import osdef generate_rag_test_files(folder_name:str ="rag_test_files"):"""生成RAG测试文件并保存到指定文件夹"""# 创建存放文件的文件夹if not os.path.exists(folder_name):os.makedirs(folder_name)# 定义文件内容planets_content = """太阳系行星基础知识1. 水星(Mercury)
- 位置:距离太阳最近的行星(约0.39天文单位)
- 特征:表面布满陨石坑,没有大气层保护,昼夜温差极大(白天约430℃,夜晚约-180℃)
- 自转周期:58.6地球日,公转周期:88地球日2. 金星(Venus)
- 位置:距离太阳第二近(约0.72天文单位)
- 特征:被浓密的二氧化碳大气层覆盖,产生强烈温室效应,表面温度约467℃(太阳系中最热的行星)
- 特殊点:自转方向与其他行星相反(自东向西),自转周期243地球日,公转周期225地球日3. 地球(Earth)
- 位置:距离太阳第三近(约1天文单位)
- 唯一已知存在液态水和生命的行星,大气层以氮和氧为主
- 自转周期23小时56分,公转周期365.24天4. 火星(Mars)
- 位置:距离太阳第四近(约1.52天文单位)
- 特征:表面呈红色(因富含氧化铁),有稀薄的二氧化碳大气层,存在极地冰盖(主要是干冰和水冰)
- 地标:奥林匹斯山(太阳系最高山峰,约21千米)、水手谷(长约4000千米的峡谷)5. 木星(Jupiter)
- 位置:距离太阳第五近(约5.2天文单位)
- 特征:太阳系中最大的行星(质量是其他所有行星总和的2.5倍),由氢和氦组成,表面有明显的条纹和“大红斑”(持续数百年的风暴)
- 卫星:已知有95颗卫星,其中最大的4颗是“伽利略卫星”(木卫一至木卫四)
"""purifier_content = """家用空气净化器(型号:CleanAir X5)使用指南一、核心功能
1. 净化范围:适用面积20-30㎡(密闭空间)
2. 过滤系统:- 初级滤网:拦截毛发、灰尘等大颗粒- HEPA滤网:过滤PM2.5、花粉、细菌(效率99.97%@0.3μm)- 活性炭滤网:吸附甲醛、TVOC等有害气体
3. 运行模式:- 自动模式:根据内置传感器检测的空气质量自动调节风速- 睡眠模式:风速最低,噪音≤30分贝,适合夜间使用二、操作步骤
1. 首次使用:- 拆除滤网外层的塑料包装(否则会影响净化效果)- 连接电源,按机身“电源键”开机(默认进入自动模式)
2. 更换滤网提示:- 当机身“滤网指示灯”亮起时,需更换对应滤网(HEPA滤网建议6-8个月更换一次,活性炭滤网建议3-4个月更换一次)- 更换方法:打开机器背部面板,取出旧滤网,按标识方向装入新滤网三、注意事项
1. 避免在潮湿环境(如浴室)使用,以免滤网受潮发霉
2. 长期不使用时,需断开电源并清洁机身表面
3. 若出现异响或净化效果下降,检查是否滤网安装错误或风扇故障
"""reimbursement_content = """HelloWorld公司员工报销流程指南(2024版)一、可报销费用类型
1. 差旅费用:- 包含:交通(机票/高铁票需提供行程单)、住宿(需提供酒店发票和住宿清单)、市内交通(地铁/打车票,单日上限200元)- 标准:一线城市住宿上限800元/晚,二线城市600元/晚
2. 办公采购:- 需提前在OA系统提交“采购申请单”,审批通过后凭发票报销(单笔超过5000元需走对公转账)
3. 业务招待:- 需注明招待对象、事由,单次招待金额超过2000元需部门总监审批二、报销流程步骤
1. 收集凭证:保留所有费用的原始发票(电子发票需打印纸质版并签字)
2. 提交申请:在OA系统“报销模块”填写报销单,上传发票照片并关联对应项目编号
3. 审批环节:- 单笔≤1000元:部门经理审批→财务审核→打款- 单笔>1000元:部门经理→财务主管→总经理→财务审核→打款
4. 到账时间:财务审核通过后3个工作日内,款项将打入员工工资卡三、常见问题
1. 发票抬头必须为“XX科技有限公司”,否则不予报销
2. 差旅报销需在出差结束后15天内提交,逾期视为自动放弃
3. 虚报费用将扣除当月绩效20%,并记录违规一次
"""# 定义要创建的文件列表files = [{"name": "太阳系行星知识.txt", "content": planets_content},{"name": "家用空气净化器使用指南.txt", "content": purifier_content},{"name": "公司报销流程指南.txt", "content": reimbursement_content}]# 将内容写入文件for file in files:file_path = os.path.join(folder_name, file["name"])with open(file_path, "w", encoding="utf-8") as f:f.write(file["content"])print(f"已生成3个RAG测试文件,存放于:{os.path.abspath(folder_name)}")return folder_name# 调用函数生成文件
if __name__ == "__main__":generate_rag_test_files()
1. 文本分段
以下代码文件实现了ReadFiles类,用于文档加载与切分:读取指定文件夹中的所有txt文件,以最大token长度为依据,先按换行符初步切分,单行token超限时则进一步按token分割,同时保留相邻片段的重叠内容以提升后续检索准确性。此外,该文件还包含Documents类,用于将数据解析结果存入JSON格式文档,并返回相应接口。
# Utils.py
import os
import json
import tiktoken # 导入tiktoken库,用于计算文本的token数量# 初始化编码器,使用cl100k_base编码方式
enc = tiktoken.get_encoding("cl100k_base")class ReadFiles:"""读取指定目录下的文本文件,并根据token长度进行分块处理的类主要用于将长文本分割为适合大语言模型处理的小块"""def __init__(self, path: str) -> None:"""初始化ReadFiles实例:param path: 目标文件夹路径,用于读取其中的文本文件"""self._path = path # 存储目标文件夹路径self.file_list = self.get_files() # 获取文件夹中所有符合条件的文件路径列表def get_files(self):"""遍历指定文件夹及其子文件夹,收集所有.txt后缀的文件路径:return: 包含所有txt文件绝对路径的列表"""file_list = []# os.walk递归遍历文件夹:返回当前路径、子文件夹列表、文件列表for filepath, dirnames, filenames in os.walk(self._path):for filename in filenames:# 筛选出后缀为.txt的文件if filename.endswith(".txt"):# 拼接完整文件路径并添加到列表file_list.append(os.path.join(filepath, filename))return file_listdef get_content(self, max_token_len: int = 600, cover_content: int = 150):"""读取所有文件内容,并按指定token长度进行分块处理:param max_token_len: 每个块的最大token长度,默认600:param cover_content: 块之间重叠的内容长度(字符数),用于保持上下文连贯性,默认150:return: 所有文件分块后的内容列表"""docs = []# 遍历每个文件并处理for file in self.file_list:# 读取文件内容content = self.read_file_content(file)# 对内容进行分块chunk_content = self.get_chunk(content, max_token_len=max_token_len, cover_content=cover_content)# 将分块结果添加到总列表docs.extend(chunk_content)return docs@classmethoddef get_chunk(cls, text: str, max_token_len: int = 600, cover_content: int = 150):"""将文本按token长度分块,处理长文本并保持块之间的重叠:param text: 要分块的原始文本:param max_token_len: 每个块的最大token长度:param cover_content: 块之间重叠的内容长度(字符数):return: 分块后的文本列表"""chunk_text = [] # 存储分块结果curr_len = 0 # 当前块的token长度curr_chunk = '' # 当前块的文本内容# 实际可用的token长度 = 最大长度 - 重叠部分(为重叠内容预留空间)token_len = max_token_len - cover_content# 按行分割文本(假设行是有意义的文本单元)lines = text.splitlines()for line in lines:# 去除行首尾空格,但保留行内空格line = line.strip()# 计算当前行的token长度line_len = len(enc.encode(line))# 情况1:当前行的token长度超过最大限制if line_len > max_token_len:# 如果当前块有内容,先保存if curr_chunk:chunk_text.append(curr_chunk)curr_chunk = ''curr_len = 0# 将超长行按token长度分割成多个块line_tokens = enc.encode(line)# 计算需要分成多少块num_chunks = (len(line_tokens) + token_len - 1) // token_lenfor i in range(num_chunks):# 计算当前块的token起始和结束位置start_token = i * token_lenend_token = min(start_token + token_len, len(line_tokens))# 将token片段解码回文本chunk_tokens = line_tokens[start_token:end_token]chunk_part = enc.decode(chunk_tokens)# 除了第一个块,其他块都添加前一个块的结尾作为重叠内容if i > 0 and chunk_text:prev_chunk = chunk_text[-1]# 取前一个块的最后cover_content个字符作为重叠内容cover_part = prev_chunk[-cover_content:] if len(prev_chunk) > cover_content else prev_chunkchunk_part = cover_part + chunk_partchunk_text.append(chunk_part)# 重置当前块状态curr_chunk = ''curr_len = 0# 情况2:当前行可以加入当前块(加上换行符的1个token)elif curr_len + line_len + 1 <= token_len: # +1 是为换行符预留的tokenif curr_chunk: # 如果当前块已有内容,先加换行符curr_chunk += '\n'curr_len += 1 # 换行符算1个tokencurr_chunk += line # 添加当前行文本curr_len += line_len # 更新当前块的token长度# 情况3:当前行无法加入当前块,需要开始新块else:# 保存当前块if curr_chunk:chunk_text.append(curr_chunk)# 开始新块,添加与前一块的重叠内容if chunk_text: # 如果已有块,添加重叠部分prev_chunk = chunk_text[-1]cover_part = prev_chunk[-cover_content:] if len(prev_chunk) > cover_content else prev_chunkcurr_chunk = cover_part + '\n' + line# 计算新块的初始token长度(重叠部分+换行符+当前行)curr_len = len(enc.encode(cover_part)) + 1 + line_lenelse: # 如果是第一个块,直接添加当前行curr_chunk = linecurr_len = line_len# 添加最后一个未处理的块(如果有内容)if curr_chunk:chunk_text.append(curr_chunk)return chunk_text@classmethoddef read_file_content(cls, file_path: str):"""根据文件类型读取内容(目前仅支持txt文件):param file_path: 文件路径:return: 文件内容字符串:raises ValueError: 如果文件类型不支持"""if file_path.endswith('.txt'):return cls.read_text(file_path)else:raise ValueError("Unsupported file type") # 抛出不支持文件类型的异常@classmethoddef read_text(cls, file_path: str):"""读取文本文件内容:param file_path: txt文件路径:return: 文件内容字符串"""# 使用utf-8编码打开并读取文件with open(file_path, 'r', encoding='utf-8') as file:return file.read()class Documents:"""读取已分类的JSON格式文档的类用于获取预先处理好的JSON格式内容"""def __init__(self, path: str = '') -> None:"""初始化Documents实例:param path: JSON文件路径,默认为空字符串"""self.path = path # 存储JSON文件路径def get_content(self):"""读取并解析JSON文件内容:return: 解析后的JSON数据(通常为字典或列表)"""with open(self.path, mode='r', encoding='utf-8') as f:content = json.load(f) # 加载并解析JSON数据return content
2. 文本片段向量化
以下代码文件主要实现了文本片段向量化相关功能,核心是将文本转换为数值向量并提供向量相似度计算能力,具体包括:
-
定义了抽象基类
BaseEmbeddings,规定了向量提取模型(嵌入模型)的基本接口:- 存储模型路径的初始化方法
- 抽象方法
get_embedding(需子类实现文本到向量的转换) - 类方法
cosine_similarity(计算两个向量的余弦相似度,衡量文本相似度)
-
实现了具体子类
SentenceEmbedding:- 基于Sentence-BERT模型实现文本嵌入功能
- 支持从Hugging Face或ModelScope加载预训练模型
- 实现
get_embedding方法,将文本预处理后转换为向量
-
提供了测试代码:
- 初始化默认模型(sentence-transformers/all-MiniLM-L6-v2)
- 演示文本嵌入过程并输出向量维度和示例值
- 向量输出维度默认为384
总之,该代码整体功能是将文本转化为计算机可理解的向量表示,为后续的文本相似度计算、语义搜索等任务提供基础。
# Embeddings.py
from typing import List
import numpy as npclass BaseEmbeddings:"""嵌入模型的基类,定义了所有嵌入模型应实现的基本接口作为抽象基类,不能直接实例化,需通过子类实现具体功能"""def __init__(self, path: str) -> None:"""初始化嵌入基类,存储模型或数据的路径Args:path (str): 模型或数据的路径,可以是本地路径或远程仓库地址"""self.path = path # 存储模型路径供后续使用def get_embedding(self, text: str) -> List[float]:"""获取文本的嵌入向量表示的抽象方法子类必须实现此方法以提供具体的嵌入计算逻辑Args:text (str): 需要转换为嵌入向量的输入文本Returns:List[float]: 文本对应的嵌入向量,以浮点数列表形式返回Raises:NotImplementedError: 如果子类未实现此方法则会抛出此异常"""# 抛出未实现异常,强制子类实现该方法raise NotImplementedError@classmethoddef cosine_similarity(cls, vector1: List[float], vector2: List[float]) -> float:"""计算两个向量之间的余弦相似度余弦相似度是衡量两个向量方向相似性的指标,值越接近1表示方向越相似Args:vector1 (List[float]): 第一个向量vector2 (List[float]): 第二个向量Returns:float: 两个向量的余弦相似度,范围在[-1, 1]之间1表示完全相似,-1表示完全相反,0表示正交"""# 将输入的Python列表转换为numpy数组,并指定数据类型为float32以节省内存v1 = np.array(vector1, dtype=np.float32)v2 = np.array(vector2, dtype=np.float32)# 检查向量中是否包含无穷大或NaN值,这些值会导致计算错误if not np.all(np.isfinite(v1)) or not np.all(np.isfinite(v2)):return 0.0 # 存在无效值时返回0表示无相似性# 计算两个向量的点积(内积)dot_product = np.dot(v1, v2)# 计算每个向量的L2范数(欧几里得长度)norm_v1 = np.linalg.norm(v1)norm_v2 = np.linalg.norm(v2)# 计算两个向量范数的乘积作为分母magnitude = norm_v1 * norm_v2# 处理分母为0的特殊情况(避免除以零错误)if magnitude == 0:return 0.0 # 零向量之间的相似度定义为0# 返回余弦相似度:点积除以范数乘积return dot_product / magnitudeclass SentenceEmbedding(BaseEmbeddings):"""基于Sentence-BERT的句子嵌入实现类继承自BaseEmbeddings,实现了具体的句子嵌入计算功能"""def __init__(self, path: str = "sentence-transformers/all-MiniLM-L6-v2") -> None:"""初始化SentenceEmbedding实例,加载指定的句子嵌入模型Args:path (str, optional): 模型路径,默认为预训练模型"sentence-transformers/all-MiniLM-L6-v2"可以是modelscope模型仓库名称或本地模型路径"""# 调用父类的初始化方法,存储模型路径super().__init__(path)try:from sentence_transformers import SentenceTransformer# 利用modelscope加速下载from modelscope import snapshot_downloadmodel_name = path # 模型名称/路径# 从模型仓库下载模型到本地(如果本地已存在则直接使用)model_dir = snapshot_download(model_name)# 初始化SentenceTransformer模型实例self.model = SentenceTransformer(model_dir)except Exception as e:# 捕获所有可能的异常并包装为运行时错误,提供更明确的错误信息raise RuntimeError(f"加载SentenceTransformer模型失败: {str(e)}")def get_embedding(self, text: str) -> List[float]:"""实现父类的抽象方法,获取文本的嵌入向量Args:text (str): 需要转换为嵌入向量的输入文本Returns:List[float]: 文本对应的嵌入向量,以浮点数列表形式返回"""# 文本预处理:将换行符替换为空格,避免模型处理换行符可能带来的问题text = text.replace("\n", " ")# 使用加载的模型对文本进行编码,获取嵌入向量(numpy数组格式)embedding = self.model.encode(text)# 将numpy数组转换为Python列表并返回return embedding.tolist()# 当脚本作为主程序运行时执行以下代码
if __name__ == "__main__":# 创建SentenceEmbedding实例,使用默认模型embedding = SentenceEmbedding()# 定义测试文本text = "这是一个测试文本"# 获取文本的嵌入向量vectors = embedding.get_embedding(text)# 打印嵌入向量的维度和前10个元素,验证功能是否正常print(f"嵌入向量维度: {len(vectors)}")print(f"嵌入向量示例: {vectors[:10]}...")
3. 向量存储与知识库构建
完成文档切分与Embedding模型加载后,需构建向量数据库存储文档片段及其向量表示,并设计检索模块实现查询响应。以下代码文件实现了一个向量存储与知识库构建类,主要功能如下:
- 管理文档及其对应的向量:存储文本文档及其对应的向量表示
- 向量生成:通过文本片段向量化将文档转换为向量
- 持久化存储:将文档和向量数据保存到本地文件系统,也可从本地加载
- 相似度计算:提供向量间的余弦相似度计算功能
- 相似性查询:根据输入的查询文本,找到最相似的前k个文档
# VectorBase.py
import os
from typing import List
import json
from Embeddings import BaseEmbeddings
import numpy as np
# 导入进度条库,用于显示处理进度
from tqdm import tqdmclass VectorStore:"""向量存储类,用于管理文档及其对应的向量表示提供向量计算、持久化存储、相似度查询等功能"""def __init__(self, document: List[str] = ['']) -> None:"""初始化向量存储实例参数:document: 初始文档列表,默认为包含一个空字符串的列表"""self.document = document # 存储文档内容的列表self.vectors = [] # 存储文档对应的向量表示def get_vector(self, EmbeddingModel: BaseEmbeddings) -> List[List[float]]:"""使用嵌入模型为文档生成向量表示参数:EmbeddingModel: 用于生成嵌入向量的模型实例,需继承自BaseEmbeddings返回:文档列表对应的向量列表,每个向量是一个浮点数列表"""self.vectors = []# 使用tqdm显示处理进度,desc设置进度条描述for doc in tqdm(self.document, desc="Calculating embeddings"):# 为每个文档生成嵌入向量并添加到列表self.vectors.append(EmbeddingModel.get_embedding(doc))return self.vectorsdef persist(self, path: str = 'storage'):"""将文档和向量数据持久化存储到文件系统参数:path: 存储目录路径,默认为'storage'"""# 如果目录不存在则创建if not os.path.exists(path):os.makedirs(path)# 保存文档内容到JSON文件with open(f"{path}/doecment.json", 'w', encoding='utf-8') as f:json.dump(self.document, f, ensure_ascii=False)# 如果存在向量数据,则保存向量到JSON文件if self.vectors:with open(f"{path}/vectors.json", 'w', encoding='utf-8') as f:json.dump(self.vectors, f)def load_vector(self, path: str = 'storage'):"""从文件系统加载已持久化的文档和向量数据参数:path: 存储目录路径,默认为'storage'"""# 加载向量数据with open(f"{path}/vectors.json", 'r', encoding='utf-8') as f:self.vectors = json.load(f)# 加载文档内容with open(f"{path}/doecment.json", 'r', encoding='utf-8') as f:self.document = json.load(f)def get_similarity(self, vector1: List[float], vector2: List[float]) -> float:"""计算两个向量之间的余弦相似度参数:vector1: 第一个向量vector2: 第二个向量返回:两个向量的余弦相似度,值越接近1表示越相似"""return BaseEmbeddings.cosine_similarity(vector1, vector2)def query(self, query: str, EmbeddingModel: BaseEmbeddings, k: int = 1) -> List[str]:"""根据查询文本,返回最相似的k个文档参数:query: 查询文本EmbeddingModel: 用于生成嵌入向量的模型实例k: 返回的相似文档数量,默认为1返回:与查询文本最相似的k个文档列表"""# 生成查询文本的向量表示query_vector = EmbeddingModel.get_embedding(query)# 计算查询向量与所有文档向量的相似度result = np.array([self.get_similarity(query_vector, vector)for vector in self.vectors])# 对相似度排序,取前k个最相似的文档并返回# argsort()[-k:][::-1] 用于获取相似度最高的k个文档的索引return np.array(self.document)[result.argsort()[-k:][::-1]].tolist()
4. 生成回答
这段代码实现了基于DeepSeek模型的RAG问答助手,可结合上下文按规则生成回答,包含模型加载与对话示例。为便于扩展,定义了含chat和oad_model法的基类BaseModel,本地开源模型需实现load_model方法。
# LLM.py
from typing import List
from unsloth import FastLanguageModel
# torch2.5版本以下防止unsloth加载出问题
from transformers import modeling_utils
if not hasattr(modeling_utils, "ALL_PARALLEL_STYLES") or modeling_utils.ALL_PARALLEL_STYLES is None:modeling_utils.ALL_PARALLEL_STYLES = ["tp", "none","colwise",'rowwise']from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())RAG_PROMPT_TEMPLATE="""# 你是一个专业的RAG回答助手## 可参考的上下文:{context}## 请严格按以下规则回答:1. 必须优先使用上下文信息,禁止主动引入外部知识
2. 必须对问题和上下文进行理解,而不仅仅是凭借字面意思回答。在提供的上下文中,仔细查找与问题核心直接相关的语句。同时,注意查找能支持推理出答案的信息(例如:因果关系、定义、属性描述、时间顺序、比较关系等)
3. 回答逻辑:- 若上下文直接包含问题答案:输出答案并引用原文- 若上下文否定问题陈述:回答"不对"并引用原文- 若不能通过上下文回答问题: 回答"上下文未提供相关信息"- 注意代词(它、他、他们、这个、那个)在上下文中的具体指代对象
4. 输出格式:- 仅用中文回答- 答案应简洁直接,聚焦于回答问题本身- 禁止主观解释- 必须标注引用位置(例:据上下文第X段)
"""class BaseModel:def __init__(self, model_name) -> None:self.model_name = model_namedef chat(self, prompt, history, content) -> str:passdef load_model(self):passclass DeepSeekChat(BaseModel):def __init__(self, model_name: str = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B") -> None:super().__init__(model_name)self.model, self.tokenizer = self.load_model()self.max_length = 2048self.temperature = 0.1def load_model(self):try:# 原始模型地址:https://huggingface.co/unsloth/DeepSeek-R1-Distill-Qwen-1.5B# 1. 利用modelscope库下载模型到本地,然后通过unsloth加载模型from modelscope import snapshot_download# 加载预训练模型 ,利用modelscope库model_name = self.model_name # 假设这是支持分词的模型名称# 下载模型model_dir = snapshot_download(model_name)# 从huggingface的镜像https://hf-mirror.com/中下载模型到本地# model_dir= "./DeepSeek-R1-Distill-Qwen-1.5B"# 设置最大序列长度,表示模型在一次前向传递中可以处理的最大令牌数量。max_seq_length = 2048 # https://hf-mirror.com/# 调用FastLanguageModel.from_pretrained()方法加载预训练的模型和对应的Tokenizer(分词器)。model, tokenizer = FastLanguageModel.from_pretrained(model_name = model_dir, # 从hf中直接调用:model_name = unsloth/DeepSeek-R1-Distill-Qwen-1.5Bmax_seq_length = max_seq_length, # 最大序列长度,表示模型在一次前向传递中可以处理的最大令牌数量。dtype = None, # 自动检测(BF16或FP16)。BF16范围大,FP16精度高local_files_only=True # 只用本地文件)except Exception as e:raise RuntimeError(f"加载 DeepSeek 模型失败")return model, tokenizerdef chat(self, prompt: str, history: List[dict], content: List[str]) -> str:# 构建上下文(优化格式)formatted_context = "\n".join([f"【上下文第{idx}段】{text}" for idx, text in enumerate(content, 1) if text.strip()])# 构建系统提示system_prompt = RAG_PROMPT_TEMPLATE.format(context=formatted_context.strip())# 构建完整消息队列messages = []# 1. 添加当前系统提示messages.append({"role": "system", "content": system_prompt})# 2. 添加历史对话(过滤旧系统消息)for msg in history:if msg["role"] != "system": # 过滤历史中的系统消息messages.append(msg)# 3. 添加当前用户问题messages.append({"role": "user", "content": prompt})# 应用对话模板,添加生成引导符inputs = self.tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)inputs = self.tokenizer(inputs, return_tensors="pt", padding=True, truncation=True).to("cuda")input_length = inputs["input_ids"].shape[1] # 记录输入长度用于截取生成内容outputs = self.model.generate(**inputs,max_new_tokens=self.max_length,temperature=self.temperature,pad_token_id=self.tokenizer.eos_token_id )# 只返回新生成的文本(去掉输入提示)generated_tokens = outputs[0][input_length:] # 直接截取生成的tokenresponse = self.tokenizer.decode(generated_tokens, skip_special_tokens=True).strip()return response# 示例:使用 DeepSeekChat 进行对话
def main():# 初始化模型print("正在加载 DeepSeek 模型...")chat_model = DeepSeekChat() # 也可以尝试其他 DeepSeek 模型# 示例上下文,内容为假数据context = ["""DeepSeek 是深度求索公司开发的大语言模型。当前最新版本是 DeepSeek-V3,知识截止日期为2024年7月。该模型支持最大128K上下文长度,擅长中文和英文任务。"""]# 示例对话历史history = [{"role": "system", "content": "你是一个乐于助人的AI助手。"},{"role": "user", "content": "你好,请介绍一下你自己"},{"role": "assistant", "content": "我是基于DeepSeek模型构建的AI助手,很高兴为您服务。"}]# 第一个问题question1 = "DeepSeek模型最新版本的知识截止日期是什么?"print(f"\n用户提问: {question1}")response1 = chat_model.chat(question1, history, context)print(f"AI回答: {response1}")# 将回答添加到历史记录中history.append({"role": "user", "content": question1})history.append({"role": "assistant", "content": response1})# 第二个问题(测试历史对话+上下文)question2 = "它支持最大的上下文长度是多少?" # "它"指代历史对话中的DeepSeek模型print(f"\n用户提问: {question2}")response2 = chat_model.chat(question2, history, context)print(f"AI回答: {response2}")if __name__ == "__main__":main()
5. 调用代码
以下代码实现了一个简单RAG系统的调用流程:生成测试文件后,智能加载或新建向量数据库,再通过DeepSeek模型结合检索到的相关上下文与对话历史,依次处理预设问题并生成回答,核心是借助向量检索提升回答准确性。
# main.py
import os
from Generate import generate_rag_test_files
from VectorBase import VectorStore
from Utils import ReadFiles
from LLM import DeepSeekChat
from Embeddings import SentenceEmbeddingdef main():# 生成测试文件folder_name = generate_rag_test_files()# 向量存储路径vector_path = 'storage'# 初始化嵌入模型embedding = SentenceEmbedding()# 智能加载向量存储:存在则加载,否则生成并持久化if os.path.exists(vector_path):print("加载本地向量数据库...")vector = VectorStore([]) # 空文档初始化,后续加载本地数据vector.load_vector(vector_path)else:print("生成新的向量数据库...")# 读取并分割文档docs = ReadFiles(folder_name).get_content(max_token_len=600, cover_content=150)vector = VectorStore(docs)# 生成并持久化向量vector.get_vector(EmbeddingModel=embedding)vector.persist(path=vector_path)# 初始化对话模型chat = DeepSeekChat()# 初始化对话历史chat_history = []# 待处理的问题列表questions = ["HelloWorld公司三线城市住宿上限是多少?","HelloWorld公司差旅报销在出差结束后20天提交,有什么后果?",# "CleanAir X5空气净化器若净化效果下降,怎么解决?",# "地球自转周期是48小时吗?",# "太阳系行星距离太阳第四近的是哪个?"]# 依次处理每个问题,维护对话历史for idx, question in enumerate(questions, 1):print(f"\n===== 问题 {idx} =====")print(f"用户: {question}")# 检索相关上下文content = vector.query(question, EmbeddingModel=embedding, k=2)# 调用模型生成回答(传入历史记录)response = chat.chat(question, chat_history, content)print(f"AI: {response}")# 更新对话历史chat_history.append({"role": "user", "content": question})chat_history.append({"role": "assistant", "content": response})if __name__ == "__main__":main()
3.2 主流开源RAG框架概览
前文介绍的自建RAG系统更适用于学习与演示场景;而在实际开发过程中,基于成熟的开源框架搭建RAG系统则是更优选择。以下为当前主流的15个开源RAG框架排名及核心特性解析:
| 排名 | 框架 | 核心聚焦 | 最佳适用场景 | 核心功能 | 部署复杂度 | GitHub星标数 |
|---|---|---|---|---|---|---|
| 1 | LangChain | 组件链合 | 通用RAG应用 | 数据连接、模型灵活性 | 中 | 105k |
| 2 | Dify | 可视化开发 | 非技术用户、企业 | 可视化编辑器、多模型支持 | 低 | 90.5k |
| 3 | RAGFlow | 文档处理 | 复杂文档handling | 深度文档理解、GraphRAG | 中 | 48.5k |
| 4 | LlamaIndex | 数据索引 | 自定义知识源 | 灵活连接器、自定义索引 | 低 | 40.8k |
| 5 | Milvus | 向量存储 | 大规模向量搜索 | 高级向量搜索、水平扩展 | 中 | 33.9k |
| 6 | mem0 | 持久记忆 | 需上下文保留的助手 | 多级记忆、自动处理 | 低 | 27.3k |
| 7 | DSPy | 提示优化 | 需自我改进的系统 | 自动优化、模块化 | 中 | 23k |
| 8 | Haystack | 管道编排 | 生产应用 | 灵活组件、技术无关 | 中 | 20.2k |
| 9 | LightRAG | 性能 | 速度关键应用 | 简单架构、高效检索 | 低 | 14.6k |
| 10 | LLMWare | 资源效率 | 边缘/CPU部署 | 小型模型、并行解析 | 低 | 12.7k |
| 11 | txtai | 一体化解决方案 | 简化实现 | 嵌入数据库、多模态 | 低 | 10.7k |
| 12 | RAGAS | 评估 | RAG系统测试 | 客观指标、测试生成 | 低 | 8.7k |
| 13 | R2R | 代理式RAG | 复杂查询 | 多模态摄入、代理推理 | 中 | 6.3k |
| 14 | Ragatouille | 高级检索 | 高精度搜索 | 晚期交互检索、微调 | 中 | 3.4k |
| 15 | FlashRAG | 研究 | 实验与基准测试 | 预处理数据集、多算法 | 中 | 2.1k |
以上内容参考自:15 Best Open-Source RAG Frameworks in 2025。不同开源RAG框架的核心差异主要体现在技术定位与功能特性上,在进行框架选型时,需结合应用规模、性能指标、开发周期等实际需求综合判断。需要特别强调的是,无论选择何种框架,知识库的质量始终是决定RAG系统效果的核心因素。
具体选型建议如下:
- 若以易用性为优先考量:推荐Dify、LlamaIndex、mem0、LightRAG、txtai
- 针对文档密集型应用:优先考虑RAGFlow、LLMWare
- 面向大规模生产部署:适合选择Milvus、Haystack、LangChain
- 硬件资源受限场景:优先选用LLMWare、LightRAG
- 存在复杂推理需求的场景:建议探索R2R、DSPy
- 需进行系统评估的场景:推荐使用RAGAS
- 研究与实验场景:适合选择FlashRAG
4 参考
- 大语言模型基础知识
- Retrieval-Augmented Generation for AI-Generated Content: A Survey
- Retrieval-Augmented Generation for Large Language Models: A Survey
- RAG起源、演进与思考
- RAG到底咋工作的
- 16 Techniques to Supercharge and Build Real-world RAG Systems
- Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring
- 17种RAG架构实现原理与选型
- 一篇搞明白RAG的几种不同类型
- Traditional RAG vs. HyDE
- Seven Failure Points When Engineering a Retrieval Augmented Generation System
- Full-model Fine-tuning vs. LoRA vs. RAG
- Happy-LLM
- 15 Best Open-Source RAG Frameworks in 2025