Spark01-初识Spark
一、初识Spark
1-1、定义
Apache Spark 是一个快速且通用的大规模数据处理引擎。
Apache Spark 是一个开源的分布式计算框架,被广泛用于大数据处理。它能把数据分布到多台机器上并行处理,提升处理效率。
Spark 对 Hadoop 的 MapReduce 模型进行了扩展:
MapReduce 适合批处理,但不适合交互式查询和实时处理。
Spark 解决了这个问题,它支持:
- 交互式查询(interactive queries),比如你能像操作数据库那样探索数据;
- 流处理(stream processing),可以处理像 Twitter 这类持续不断产生的数据流。
据报道,在内存中运行时,Spark 的速度比 Hadoop MapReduce 快 100 倍,在磁盘上也快 10 倍。
因为,Hadoop MapReduce 每个中间结果都写入磁盘 → 慢;
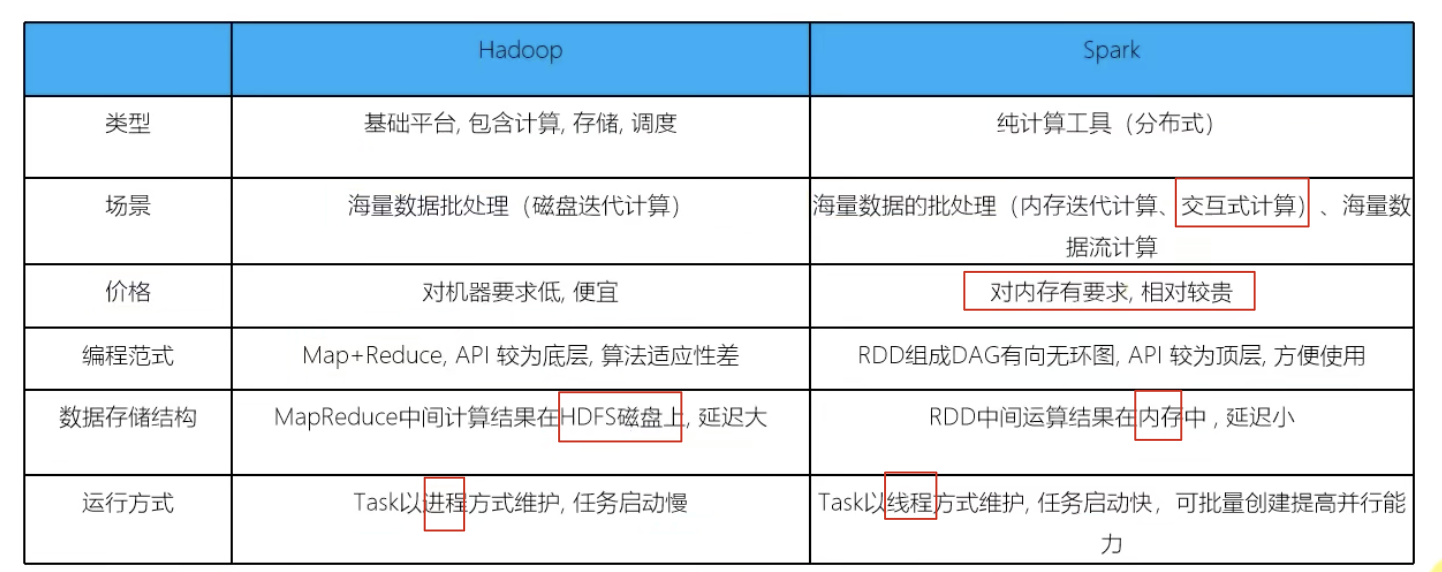
尽管Spark相对于Hadoop而言具有较大优势,但Spark并不能完全替代Hadoop
- 在计算层面,Spark相比较MR(MapReduce)有巨大的性能优势,但至今仍有许多计算工具基于MR构架,比如非常成熟的Hive;
- Spark仅做计算,而Hadoop生态圈不仅有计算(MR)也有存储(HDFS)和资源管理调度(YARN),HDFS和YARN仍是许多大数据体系的核心架构。
【备注】:
可以认为,理想的是,用Spark替代Hadoop中的MR(MapReduce)
1-2、Spark的特点
1、运行速度快
相比传统的 Hadoop MapReduce,它在内存中的执行速度高达 100 倍。
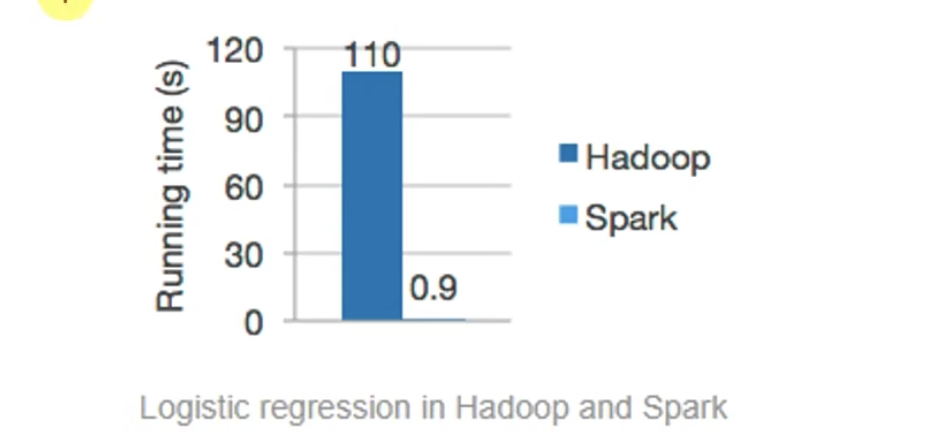
原因:
在 Hadoop 的 MapReduce 模型中,每一个任务都必须中间写入磁盘(I/O 成本高)。
Spark 则尽量在内存中完成计算(in-memory computing),省去了大量磁盘读写的开销。
2、易于使用
编程API简单,概念多!
3、通用性强
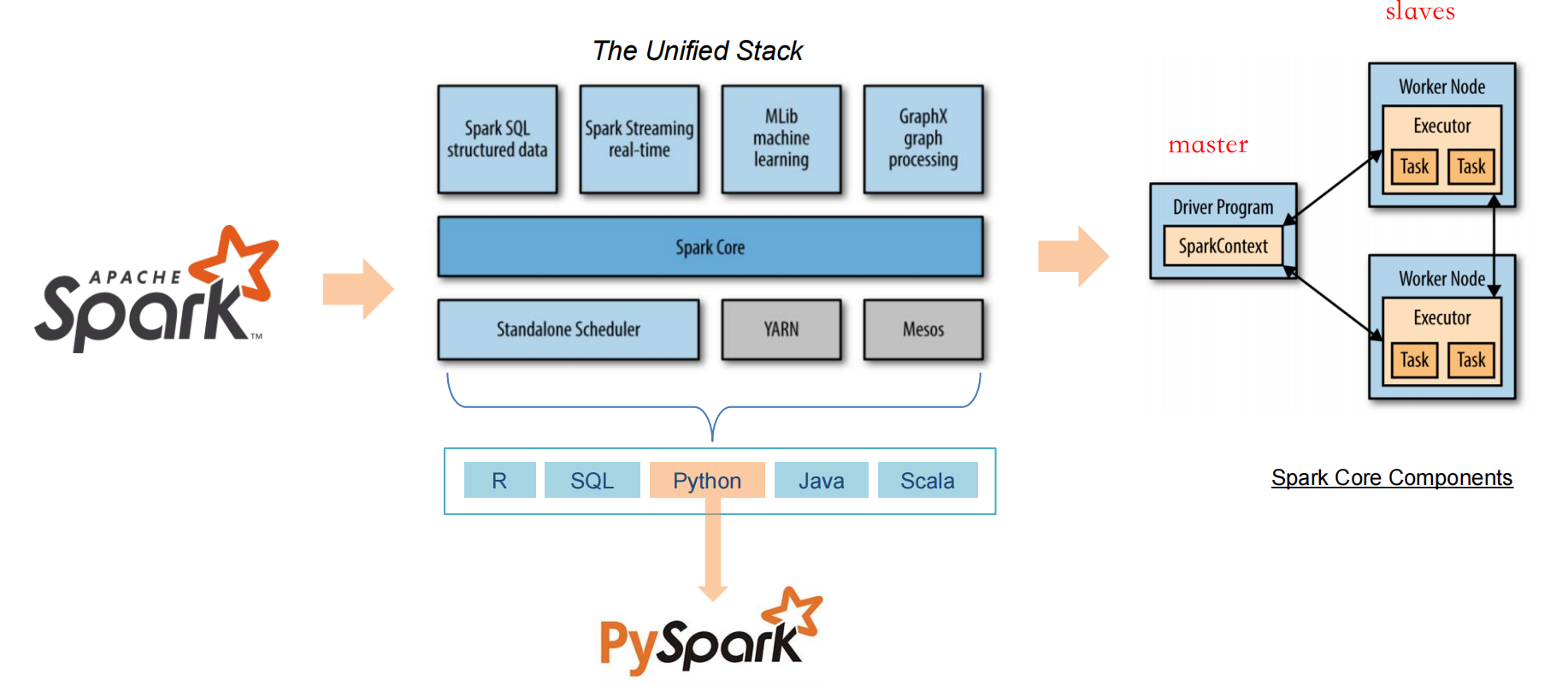
Spark 的可访问性很强,提供了简单易用的 API,支持 Python、Java、Scala 和 SQL,并包含丰富的内置库。

4、运行方式很多
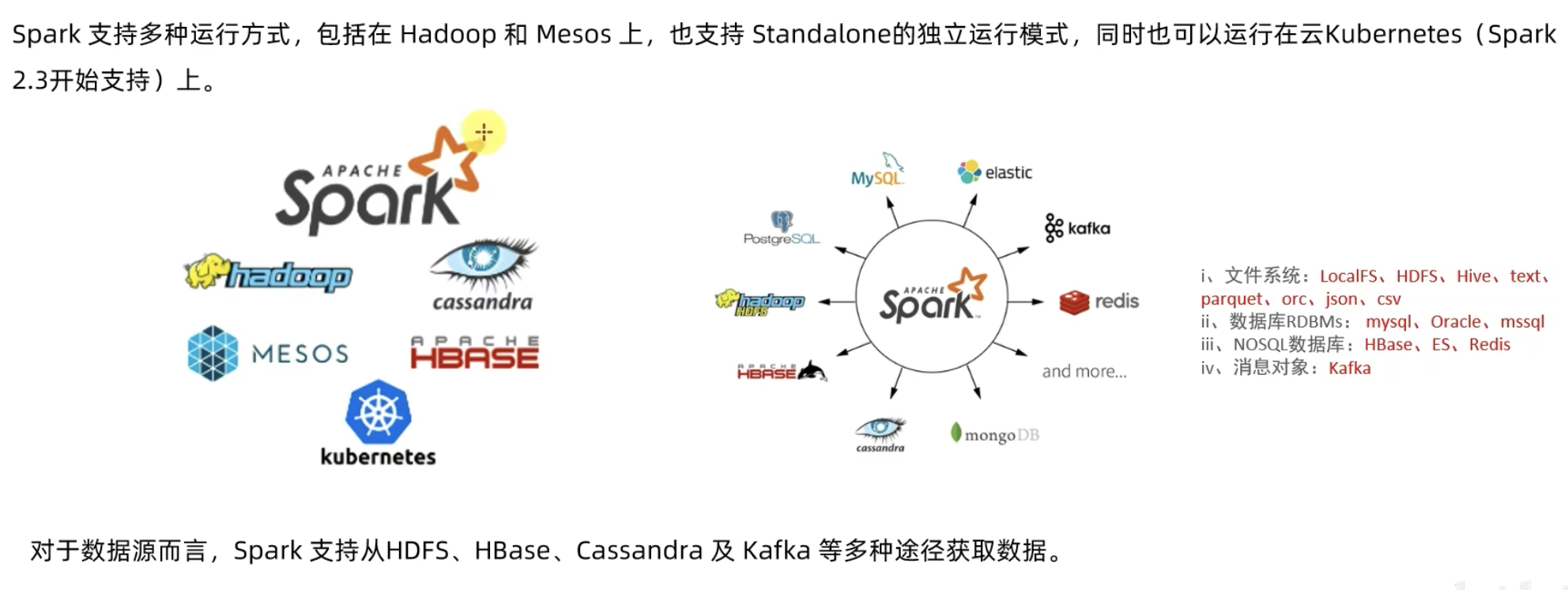
spark还支持自定义数据源
1-3、Spark的框架模块
什么是 Unified Stack?
Spark 不只是一个单一的处理引擎,而是一个完整的“大数据处理生态系统”,由多个模块组成,这些模块之间配合非常紧密,可以像“拼积木”一样组合使用。
Spark 包含多个模块,例如:
- Spark SQL:用于结构化查询;
- Spark Streaming:用于流式处理;
- MLlib:机器学习库;
- GraphX:图计算;
它们不是彼此孤立的,而是可以协同运行,比如:
你可以在处理流数据的同时用 SQL 查询它,也可以对结果做机器学习预测。
所有组件都像“一个完整系统”一样无缝协作,而不是像 Hadoop 生态系统那样,各个工具(Hive、Pig、Mahout)互相独立、整合麻烦。
举个例子:
你可以用 Spark SQL 读取数据 → 再用 MLlib 做机器学习 → 最后用 Spark Streaming 实时预测 → 整个流程都运行在同一个 Spark 应用里。
1-4、Spark的运行模式
Spark 提供多种运行模式,包括:
- 本地模式(单机)Local
本地模式就是以一个独立的进程,通过其内部的多个线程来模拟整个 Spark 运行时环境。
开发,测试环境
- Standalone 模式(集群)
Spark 中的各个角色以独立进程的形式存在,并组成 Spark 集群环境 - Hadoop YARN 模式(集群)
Spark 中的各个角色运行在 YARN 的容器内部,并组成 Spark 集群环境 - Kubernetes 模式(容器集群)
Spark 中的各个角色运行在 Kubernetes 的容器内部,并组成 Spark 集群环境 - 云服务模式(运行在云平台上)
……
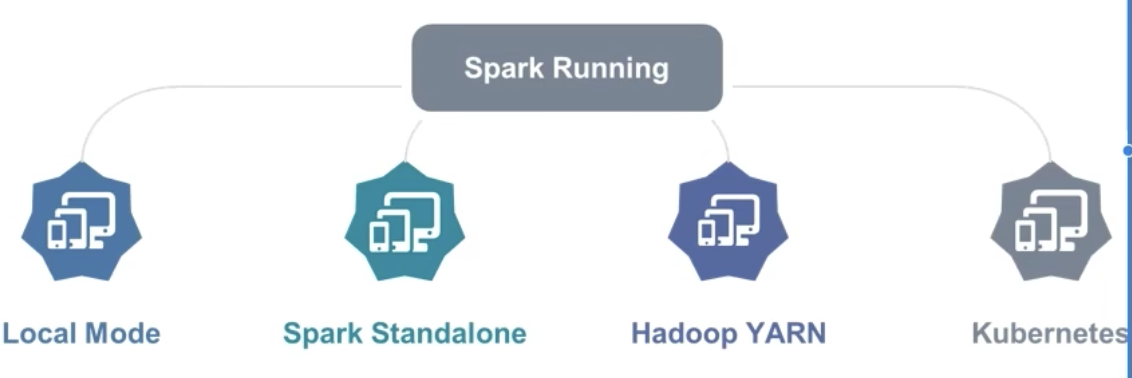
【小结】:三种运行模式:
1、本地模式
2、集群模式
3、云模式
1-5、Spark的架构角色
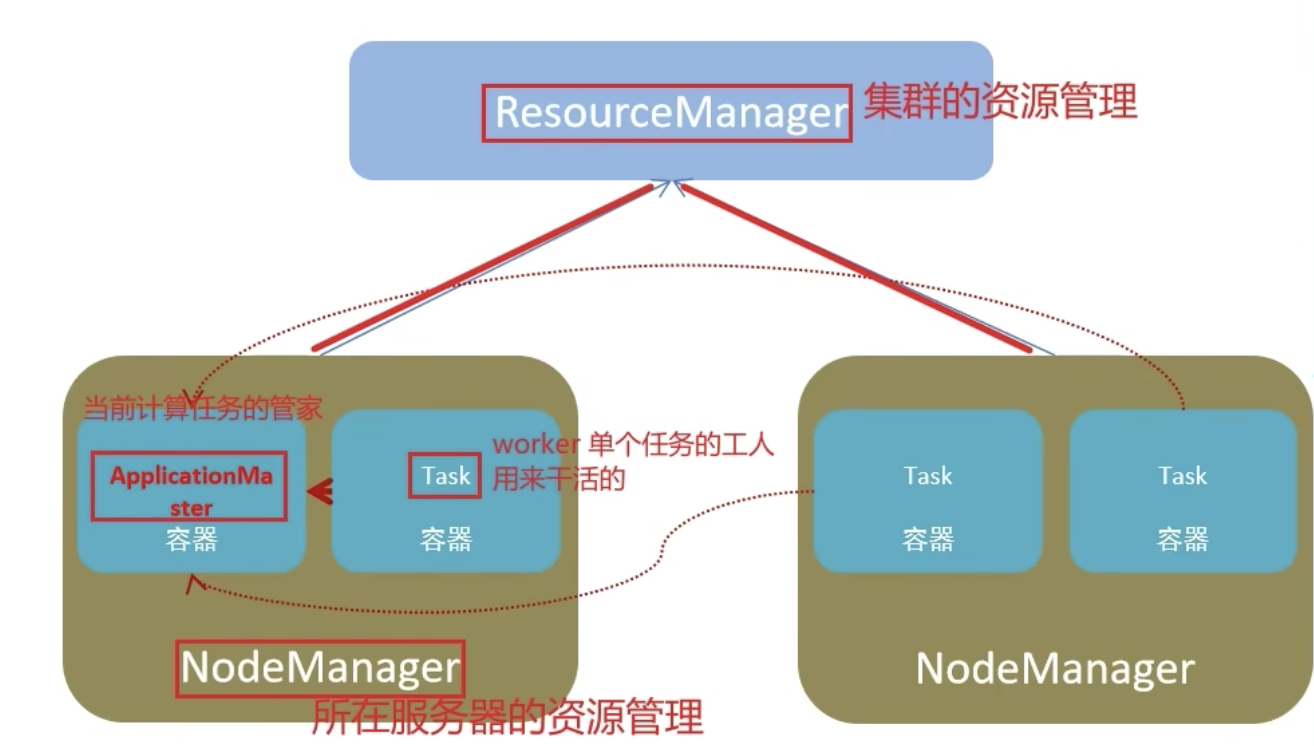
1、yarn的角色回顾
YARN 主要有 4 类角色,从 2 个层面去看:
(1)资源管理层面
- 集群资源管理者(Master):ResourceManager
- 单机资源管理者(Worker):NodeManager
(2)任务计算层面
- 单任务管理者(Master):ApplicationMaster
- 单任务执行者(Worker):Task(容器内计算框架的工作角色)
[1]、讲解:资源管理层面(重点是资源的分配与管理)
这个层面关注的是:“有多少资源(CPU、内存)?给谁用?怎么分?”
1. ResourceManager(集群资源管理者,Master)
角色:整个集群的“大管家”
职责:
全局管理集群中的资源。
接收用户提交的应用(比如 MapReduce、Spark、Flink 等)。
决定资源分配给哪个应用(哪个 ApplicationMaster)。
注意:它本身不参与任务运行,只负责资源分配和协调。
2. NodeManager(单机资源管理者,Worker)
角色:每台工作节点的“管家”
职责:
管理本机资源(CPU、内存等),汇报给 ResourceManager。
启动/停止容器(Container)来运行任务。
监控容器的运行状态,反馈给 ResourceManager。
你可以理解为:NodeManager 是每台机器上的执行代理。
[2]、讲解:任务计算层面(重点是任务的执行与调度)
这个层面关注的是:“我要跑的这个任务,怎么切分?在哪执行?”
3. ApplicationMaster(单任务管理者,Master)
角色:每个任务(比如一次 Spark 作业)自己的调度器
职责:
为特定任务(一个应用)负责整个生命周期。
向 ResourceManager 请求资源。
与 NodeManager 协商启动具体的 Task。
监控任务执行,处理失败重试等。
每一个任务(App)启动时,都会有一个对应的 ApplicationMaster。
4. Task(单任务执行者,Worker,通常运行在容器Container中)
角色:具体干活的“工人”
职责:
执行任务中具体的一小部分(比如处理某段数据)。
是容器(Container)中的实际执行线程或进程。
所运行的逻辑通常由某个计算框架提供(比如 SparkExecutor、Map Task、Reduce Task 等)。
[3]、总结一下:
| 层面 | 角色 | 位置 | 主要职责 |
|---|---|---|---|
| 资源管理层面 | ResourceManager | 集群中心机 | 分配资源,调度 ApplicationMaster |
| NodeManager | 每台节点机 | 管理本机资源,启动/监控任务容器 | |
| 任务计算层面 | ApplicationMaster | 每个任务独有 | 向RM请求资源,调度 Task 执行 |
| Task | 每个任务中 | 实际执行任务逻辑 |
[4]、延伸理解:
YARN 本质上是一个资源管理系统,它并不关心你运行的是 Spark 任务、MapReduce 任务还是其他框架。
各个任务(Application)通过自己的 ApplicationMaster 来协调资源和调度执行。
每个任务最终由若干 Task 完成,而这些 Task 是在 NodeManager 所管理的容器中运行的。
2、Spark的角色
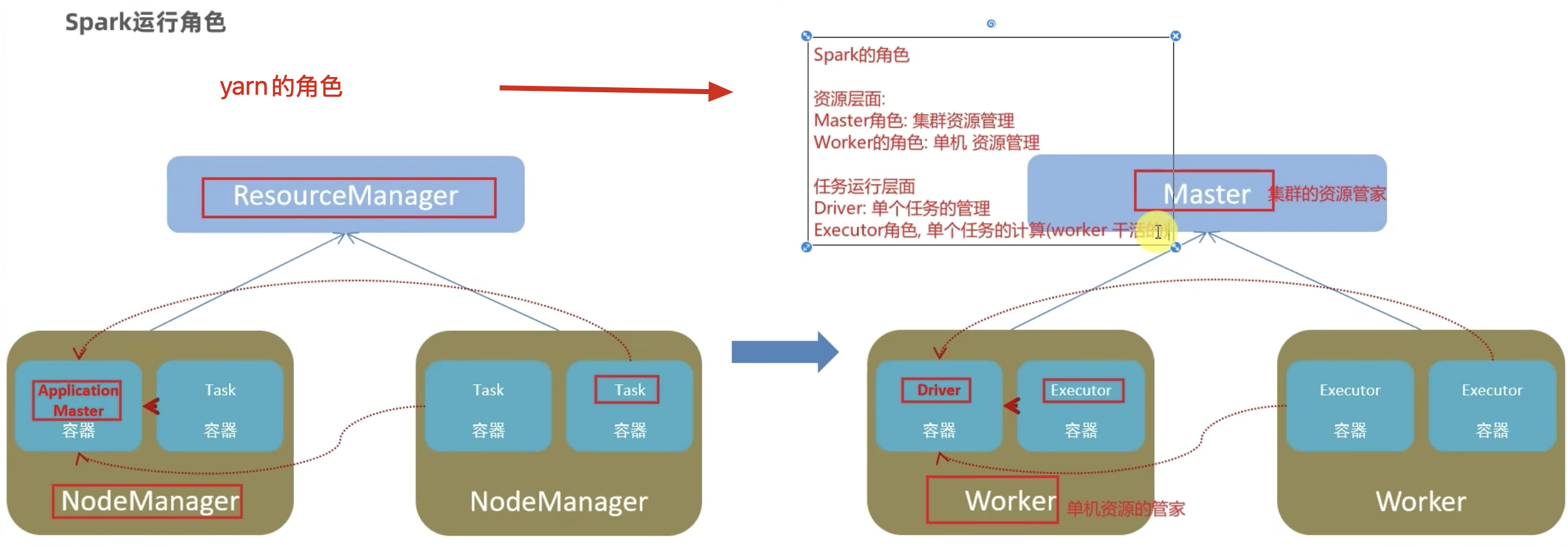
Spark 中由 4 类角色组成整个 Spark 的运行时环境
- Master 角色,管理整个集群的资源,类比与 YARN 的 ResouceManager
- Worker 角色,管理单个服务器的资源,类比于 YARN 的 NodeManager
- Driver 角色,管理单个 Spark 任务在运行的时候的工作,类比于 YARN 的 ApplicationMaster
- Executor 角色,单个任务运行的时候的一堆工作者,干活的。类比于 YARN 的容器内运行的 TASK
从 2 个层面划分:
(1)、资源管理层面:
- 管理者:Spark 是 Master 角色,YARN 是 ResourceManager
- 工作中:Spark 是 Worker 角色,YARN 是 NodeManager
(2)、从任务执行层面:
- 某任务管理者:Spark 是 Driver 角色,YARN 是 ApplicationMaster
- 某任务执行者:Spark 是 Executor 角色,YARN 是容器中运行的具体工作进程。
【注意】:
正常情况下,Executor 角色是干活的,不过在特殊场合下(local模式),Driver可以既管理又干活。
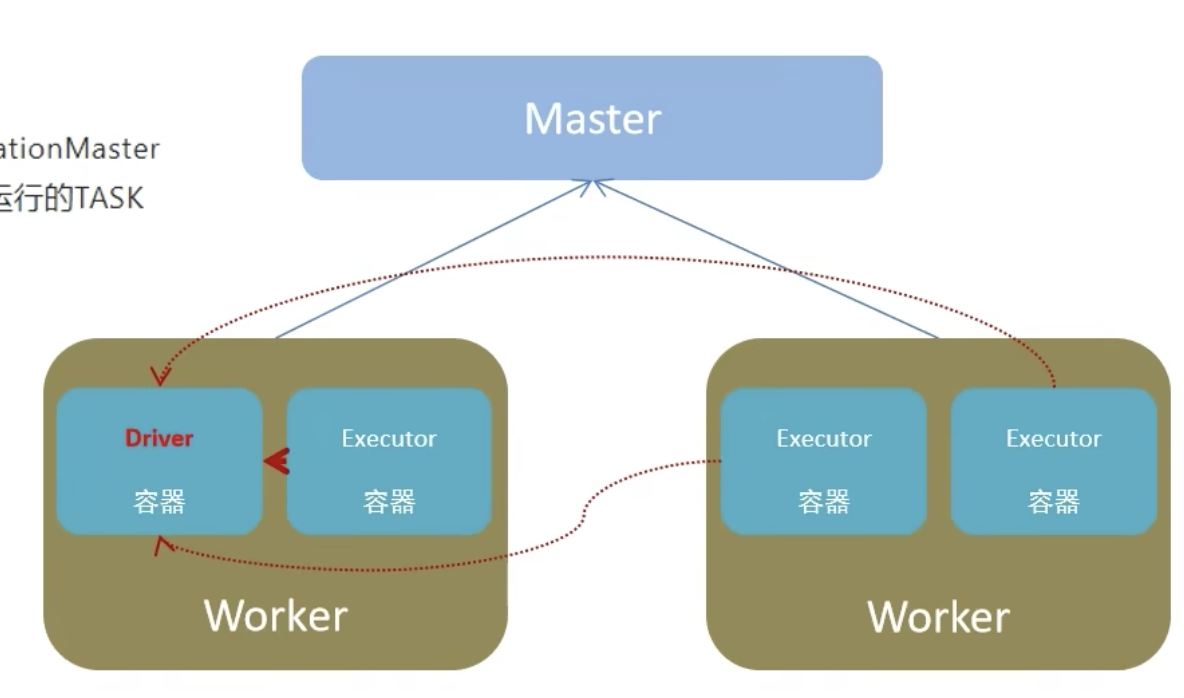
Driver VS. Worker Node(Excutor)
Driver Program 是什么?
它是你写的 Spark 应用程序的“主控中枢”。
一旦你启动一个 Spark 程序,Driver Program 就会运行其中的主函数(如 Python 中的
if __name__ == "__main__":部分)。它负责:
与集群建立连接(通过 SparkContext);
创建并分发任务;
收集并汇总结果;
监控执行状态。
驱动程序通过一个名为
SparkContext(sc)的对象访问 Spark,该对象代表与计算集群的连接。
SparkContext 是什么?
SparkContext是 Driver 和 Spark 集群之间的“桥梁”。创建
SparkContext后,你的程序就可以提交任务到集群运行了。
Worker Node / Executor 是什么?
在集群中,真正运行代码、处理数据的不是 Driver,而是多个 Executor 节点。
每个 Worker 上的 Executor:
负责接收 Driver 发来的任务;
执行代码和操作(如 map、filter、reduce);
将结果返回给 Driver。
二、PySpark的简易安装
可以通过 Docker + Jupyter Notebook 来使用 Spark(特别是 PySpark),这也是数据科学和教学中常用的一种便捷组合方式。
你可以拉一个带 Spark + PySpark + Jupyter Notebook 的 Docker 镜像,然后在浏览器中用 Jupyter Notebook 写 Spark 程序,像平常写 Python 一样简单。
2-1、推荐的方式:使用 jupyter/pyspark-notebook 镜像
这个镜像由官方 Jupyter 团队维护,预装了:
Apache Spark(通常是 Spark 3.x)
Hadoop
PySpark
Jupyter Notebook 环境
Scala、Java、Python 环境
2-2、步骤如下:
第一步:拉镜像
docker pull jupyter/pyspark-notebook
或者带 Hadoop 支持的镜像(如果你需要更复杂的数据操作):
docker pull jupyter/pyspark-notebook:spark-3.5.0
第二步:启动容器
docker run -it --rm -p 8888:8888 \-v "$PWD":/home/jovyan/work \jupyter/pyspark-notebook
说明:
-p 8888:8888:映射 Jupyter Notebook 的端口-v "$PWD":/home/jovyan/work:把当前目录映射到容器里,可以保存你写的 notebook
启动成功后,终端会输出一段链接,类似这样:
http://127.0.0.1:8888/?token=xxxxx
复制这个链接,在浏览器中打开即可进入 Jupyter Notebook。
第三步:创建 notebook,测试 PySpark
创建一个新的 Notebook(Python 环境),然后试试这个代码:
from pyspark.sql import SparkSessionspark = SparkSession.builder \.appName("Test") \.getOrCreate()df = spark.createDataFrame([("Alice", 25), ("Bob", 30), ("Cathy", 28)
], ["name", "age"])df.show()
如果输出了表格,说明 Spark 正常运行。
2-3、对应的角色关系
你在 Jupyter Notebook 中写的 Spark 代码,相当于是运行在 Driver 上的代码。
在 Spark 中,程序的执行是分为两个角色的:
| 角色 | 作用 |
|---|---|
| Driver | 运行你的 Spark 应用的主程序,负责任务的调度和协调。你写的 Spark 代码就运行在这里。 |
| Executor | 实际执行任务(比如 map、reduce、filter 等)的工作节点,执行的是 Driver 分发下来的任务。 |
示例:
你在 Jupyter Notebook 中运行:

sc.parallelize(...):在 Driver(Jupyter内核) 中调用,会把数据拆分为多个分区,发送到集群中的各个 Executor 上。map(lambda x: x * 2):这个 lambda 函数会被 序列化并发送到各个 Executor 上执行。collect():会把 Executor 上处理完的结果 返回到 Driver(也就是你写代码的 Notebook)。
三、RDD(弹性分布式数据集)
3-1、什么是 RDD?
RDD 是 Spark 最基础的数据结构,你可以把它想成:
一个可以分布在集群上的、可以并行操作的“超大数组”。
它具备以下三大特点:
Resilient(弹性):具有容错能力。如果某个节点宕机,它可以根据“血统(lineage)”重新计算数据,而不需要从头来。
Distributed(分布式):数据自动分布在集群多个节点上。
Dataset(数据集):它是一个包含多个元素的数据集合,比如整数列表、行记录等。
不可变性:一旦创建就不能修改,只能通过转换(transformations)生成新的 RDD。
3-2、什么是分区(Partition)?
分区就是把 RDD 拆分成的小块,每块可以独立在不同的机器上处理。
举例来说,如果你有一个 1 亿行的 RDD,可以划分为 100 个分区,然后让 10 台机器同时各处理 10 个分区 → 实现并行计算,显著加快处理速度。
3-3、你能对 RDD 做什么?
Spark 中的所有操作,都是围绕 RDD 展开的:
Spark 的程序本质上是围绕 RDD 的三个阶段组成的:
创建 RDD(如读取外部数据或并行化集合)
转换 RDD(如 map、filter、flatMap,返回新的 RDD)
行动操作(如 count、collect、saveAsTextFile,触发真正的执行计算)
在 Spark 中,你可以对 RDD 执行各种操作,如:
Transformation(转换):如
map()、filter(),不会立即执行,返回新的 RDD。Action(行动):如
collect()、count(),会触发实际计算。
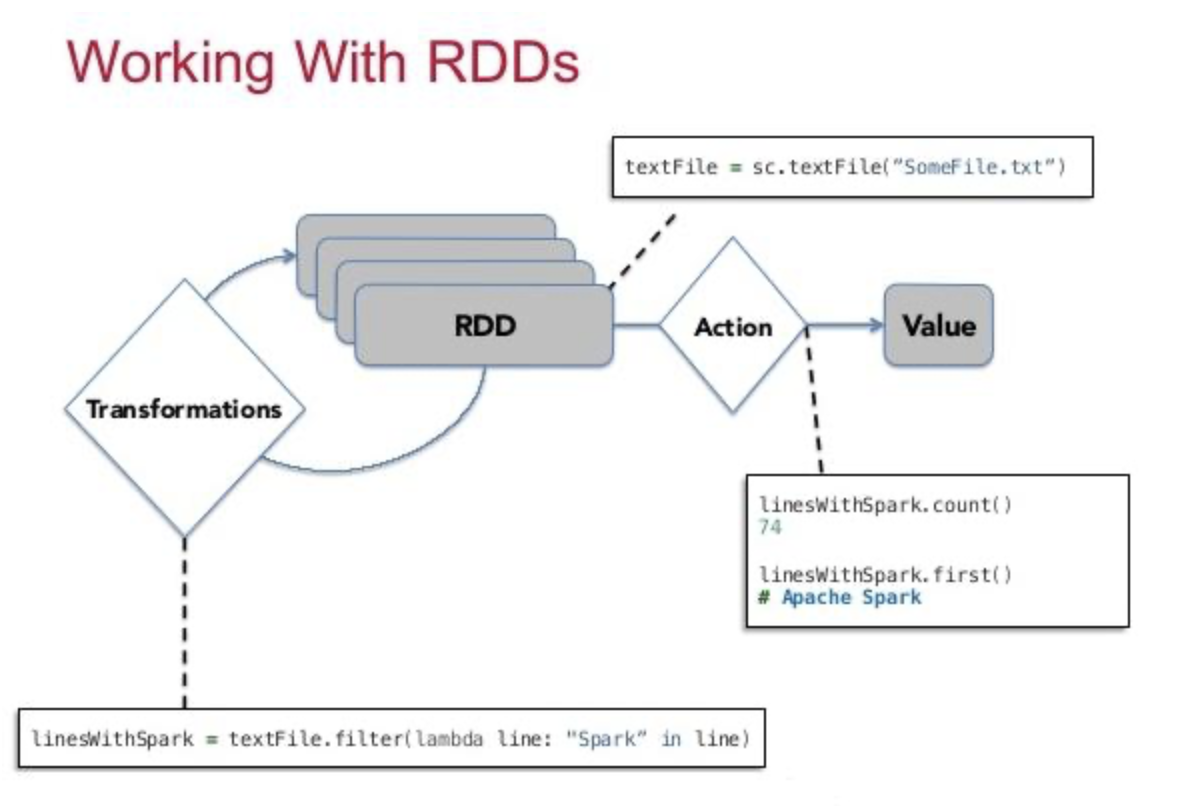
3-4、背后的执行机制(under the hood):
Spark 会自动将 RDD 数据切分成多个 partition(分区);
每个分区可以被分配到不同的工作节点(executor)上并发执行;
所以你写的代码是逻辑上的,而 Spark 会负责将数据并行分布执行。
总结一句话:
RDD 是 Spark 的核心数据结构,它可以自动分布在集群上,并提供容错性、并行性,是所有高层 API(如 DataFrame、Dataset)的基础。
3-5、如何创建 RDD?
Spark 提供两种常用方式来创建 RDD:
方法 1:使用 parallelize() 从本地集合创建 RDD
用于将 Python 中的列表、元组等本地数据结构转换为分布式数据集,适用于小规模测试数据。

parallelize()会将列表拆分成多个分区(默认根据系统核数);每个分区可在不同节点上并行处理;
collect()是一个 Action,用于把分布式数据收集到本地并打印出来(仅适用于小数据)。
方法 2:使用 textFile() 从外部文件创建 RDD
用于处理大数据,读取本地文件或分布式文件系统(如 HDFS)中的文本数据。

textFile()自动将文件分成若干分区(默认每 128MB 为一个分区);可以读取本地路径(如
file:///Users/name/file.txt)或 HDFS 路径;使用
take(n)可以安全地预览前 n 条记录。
| 方法 | 使用场景 | 示例函数 |
|---|---|---|
parallelize() | 小规模测试数据 | sc.parallelize(list) |
textFile() | 加载文本文件 | sc.textFile("路径") |
【注意】:
每个 PySpark 应用只能创建一个
SparkContext;关闭 Spark 应用后应使用
sc.stop()。
3-6、RDD 操作类型详解
在 PySpark(或 Spark)中,RDD 提供了两大类操作:
1. 转换操作(Transformations)
2. 行动操作(Actions)
1. 转换操作(Transformations)
定义:转换操作是指在一个 RDD 上进行操作,返回一个新的 RDD,不会立刻执行,是 惰性求值(lazy evaluation)。
常见的转换操作包括:
| 操作名 | 说明 |
|---|---|
map(func) | 对 RDD 的每个元素应用一个函数,返回新的 RDD |
filter(func) | 保留满足条件的元素 |
flatMap(func) | 类似 map,但可以返回多个结果然后扁平化 |
distinct() | 去重 |
union() | 合并两个 RDD |
join() | 连接两个(键值对)RDD |
groupByKey() | 将相同 key 的值分组 |
关键点:
每次转换返回的是一个新的 RDD;
实际上并没有真正计算,只是记录了“要做什么”(生成了执行计划);
真正的计算要等到遇到一个“行动操作”。
2. 行动操作(Actions)
定义:行动操作是指对 RDD 进行真正计算的操作,会触发 Spark 执行整个任务,并返回结果给 Driver 程序,或者写入存储系统。
常见的行动操作包括:
| 操作名 | 说明 |
|---|---|
collect() | 将整个 RDD 的数据收集到 Driver 中(⚠️ 仅适合小数据) |
count() | 返回 RDD 中元素个数 |
first() | 返回 RDD 中的第一个元素 |
take(n) | 返回前 n 个元素 |
reduce(func) | 聚合 RDD 中的元素 |
saveAsTextFile(path) | 将 RDD 数据保存为文本文件 |
关键点:
一旦调用 Action,Spark 会根据之前的转换操作生成的“执行计划”,触发任务执行;
数据会在集群中被处理,并将结果返回到 Driver 或保存。
3. 小结:Transformations vs Actions
| 对比点 | Transformations | Actions |
|---|---|---|
| 是否立刻执行 | ❌ 惰性 | ✅ 立刻触发 |
| 返回类型 | 返回新 RDD | 返回结果或触发计算 |
| 示例 | map()、filter() | count()、collect() |
示例说明(Python):
from pyspark import SparkContext
sc = SparkContext("local", "RDD Operations")# 创建一个 RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])# Transformation: map 操作(不会立即执行)
rdd2 = rdd.map(lambda x: x * 2)# Action: count(触发计算)
print(rdd2.count()) # 输出: 5# Action: collect(收集结果)
print(rdd2.collect()) # 输出: [2, 4, 6, 8, 10]sc.stop()
为什么 Spark 要区分 Transformations 和 Actions?
惰性求值可以让 Spark 优化整个计算图;
避免中间结果反复写磁盘,提高性能;
支持容错机制(通过 Lineage 血统恢复)。
3-7、什么是 Transformations(转换操作)?
转换操作是对一个 RDD 执行操作后返回一个新的RDD 的过程。
它不会修改原来的 RDD(RDD 是不可变的 immutable);
而是返回一个新的 RDD 引用;
并且这种操作是惰性执行的(lazy evaluation),只有在后面调用一个行动操作(action)时才真正执行。
示例代码解析

textFile("log.txt")会把文件中的每一行加载为一个字符串,形成inputRDD;filter()是一个 转换操作,它会在逻辑上定义一个新的rdd;注意:此时并不会实际读取文件或执行过滤操作!(因为是惰性求值);
原来的RDD lines 没有被修改,它仍然可以用于其他操作,比如 lines
.filter(... "warning")。
1、惰性求值(Lazy Evaluation)
❓为什么叫“惰性”?
Spark 在你执行 filter()、map() 等转换操作时,只是记录你要做什么,并不会立刻执行。
真正执行时间:
只有当你执行一个 Action 操作(如 count()、collect()、saveAsTextFile())时,Spark 才会:
分析你的所有转换链;
优化执行路径(如合并操作);
启动作业并分布式计算。
2、血统图(Lineage Graph)
什么是 Lineage Graph?
是 Spark 内部维护的一张图,记录了 RDD 之间的转换关系;
也就是说,当你从
inputRDD变成errorsRDD、再变成errorsRDD.map(...),Spark 会记录:inputRDD → filter → map → ...
用途:
按需计算:Spark 可以根据血统图,只计算你最后需要的部分;
容错恢复:如果某个节点的分区丢失,Spark 可以根据血统图重新计算该分区,而不需要重新执行整个程序。
例子总结:
假设你做了以下操作:

那么执行过程是:
Spark 记录下从
rdd1→rdd2→rdd3的“转换链”;一直到你调用
count(),Spark 才会触发整个流程,从文件读取开始,到过滤、map,再到统计;如果中途某个分区计算失败,Spark 可根据血统信息从头恢复该分区。
3-8、Actions(行动操作)
在 Spark 中:
Transformation 只是定义计算逻辑,不会真正执行;
Action 是触发执行的操作,返回结果到驱动器(Driver)程序,或者 写入外部存储系统;
Action 会强制 Spark 执行其依赖的所有 Transformation。
示例:

3-9、Shared Variables(共享变量)
在 Spark 中,任务(Task)在远程工作节点Driver上运行时,不会共享变量的副本,默认是每个任务拷贝一份变量本地使用,修改也不会反映到 Driver。
为了解决这个问题,Spark 提供了两种共享变量:
广播变量(Broadcast) — 让所有节点只读共享变量;
累加器(Accumulator) — 实现跨任务的计数、求和等。
1、Broadcast Variables(广播变量)
将一个只读变量(如:大列表、模型、查找表)发送到所有执行节点;
节点任务使用的是缓存副本,避免反复传输。
示例:

2、Accumulators(累加器)
用于任务之间的共享“只加不减”的变量;
典型场景:计数器、求和器;
只能在 Driver 程序中读取值,任务中不能读取,只能累加。
示例:

| 类型 | 作用 | 示例 |
|---|---|---|
| Action | 触发执行并返回结果或保存输出 | count()、top() |
| Broadcast | 节点共享只读数据,减少通信成本 | sc.broadcast(value) |
| Accumulator | 分布式变量,只支持累加,用于统计 | sc.accumulator(0) |
四、在 Spark 中如何传递函数
Spark 会将你在本地编写的函数发送到集群上的每个节点去执行。
为了让这些函数可以正确地被传输和执行,有三种推荐的写法方式。
4-1、背景知识:为什么要“传函数”?
在 Spark 中,比如你对一个 RDD 或 DataFrame 使用 .map()、.filter() 等操作时,实际上是把你写的函数发送到每个 分布式节点上运行,而不是只在本地运行。
所以你写的函数必须是 可以序列化、可以被发送到远端、不会引用无法传递的本地状态 的。
4-2、三种推荐方式:
1. Lambda expressions(匿名函数)
适合写简单的一行表达式。
例子:
rdd.map(lambda x: x + 1)
缺点:❗不适合复杂逻辑
2. Local defs(本地定义的函数)
适合稍复杂的函数逻辑,但又不想把函数放在模块外。
例子:
def process_data(rdd):def transform(x):return x * 2 + 1return rdd.map(transform)
定义在使用它的函数内部(transform是局部函数,会被process_data()调用)
可以正常序列化,传递给 Spark 节点
不能引用外围不能序列化的对象(比如某个类的实例)
3. Top-level functions(模块顶层函数)
适合代码较复杂、需要在多个地方复用的函数。
例子(在 module.py 中):
# module.py
def clean_record(x):return x.strip().lower()
# main.py
from module import clean_record
rdd.map(clean_record)
函数是模块的“顶级函数”,可直接被序列化
推荐用于大型项目或函数较多的场景
❗不能是类的方法(特别是绑定的实例方法)
⚠️ 不推荐的方式(反例)
❌ 类方法或带状态的闭包
class Processor:def __init__(self, value):self.value = valuedef process(self, x):return x + self.valuerdd.map(Processor(10).process) # ❌
原因是:实例方法或闭包里引用了类的状态,这种函数不能被序列化,会报错。
总结(如何选择?)
| 函数复杂度 | 推荐写法 | 备注 |
|---|---|---|
| 简单一行 | Lambda表达式 | lambda x: x + 1 |
| 中等复杂 | 局部函数(local def) | 写在函数内部 |
| 较复杂或复用 | 顶层函数(module-level) | 写在模块里,import 使用 |