达梦包含OR条件的SQL特定优化----INJECT-HINT优化方法
应用迭代发版须执行如下动作
1、按目标需求全面压力测试,优化潜在慢SQL或设置特殊优化参数(如:OPTIMIZER_OR_NBEXP)
2、达梦数据库有数据导入,必须收集统计信息
达梦使用SF_INJECT_HINT系统函数对指定SQL增加HINT,保证SQL在不同环境的执行计划相同,稳定执行效率。适合在SQL执行计划较差或者走错(比如走了索引但回表代价高于全表扫描、表连接错误等情况)且业务调整SQL语句代价比较大,需要立即优化见效的情况下使用。
一、SF_INJECT_HINT功能说明
SF_INJECT_HINT使用介绍
SF_INJECT_HINT系统函数的功能是对指定SQL增加HINT。可通过SYSINJECTHINT视图查看已指定的SQL语句和对应的HINT;
SQL> select * from sys.SYSINJECTHINT;
使用方法如下:
SF_INJECT_HINT(SQL_TEXT,HINT_TEXT,NAME,DESCRIPTION,VALIDATA,FUZZY);
参数说明如下:
SQL_TEXT:要指定HINT的SQL语句或者片段;
HINT_TEXT:要为SQL指定的HINT;多个hint使用空格隔开;语法:参数名称(参数值)
NAME:配置这条规则的名称,通过这个名字,可以通过 sp_deinject_hint('名字'),进行规则取消
DESCRIPTION:对规则的详细描述,可为NULL;
VALIDATA:规则是否生效,可为NULL,则为默认值TRUE;
FUZZY:SQL的匹配规则为精准匹配或模糊匹配。值为TRUE或NULL时,模糊匹配;值为FALSE或缺省时,精准匹配;
说明:FUZZY参数在老的版本中是不支持的(DM V8 1-1-190附近的版本才开始支持)
使用时的限制条件如下:
(1)INI参数ENABLE_INJECT_HINT需设置为1;
(2)SQL只能是语法正确的增删改查语句;
(3)SQL会经过系统格式化,格式化之后的SQL和指定的规则名称必须全局唯一;
(4)HINT一指定,则全局生效;
(5)系统检查SQL匹配时,必须是整条语句完全匹配,不能是语句中子查询匹配;
使用场景:
通过SF_INJECT_HINT函数为SQL指定HINT的方式,适合在SQL执行计划较差或者走错(比如走了索引但回表代价高于全表扫描、表连接错误等情况)且业务调整SQL语句代价比较大的情况下使用。
说明:
INJECT_HINT使用示例
(1)设置INI参数ENABLE_INJECT_HINT为1
ENABLE_INJECT_HINT参数表示是否启用SQL指定HINT的功能,0:不启用;1:启用,默认0。动态,会话级参数,修改后无需重启数据库生效。
SQL> SP_SET_PARA_VALUE(1,'ENABLE_INJECT_HINT',1);
(2)会话级开启MONITOR_SQL_EXEC,方便使用ET查看SQL执行计划各个操作消耗的时间
sf_set_session_para_value('MONITOR_SQL_EXEC',1);
(3)首先查看测试SQL执行时间以及SQL执行计划各个操作的耗时
执行sql:select * from tab1 where v1 like 'sdf%' or v2 like 'sdf%' limit 10
使用et(sql执行号)查看执行计划中各个步骤的耗时情况
SQL> et(2748105249)
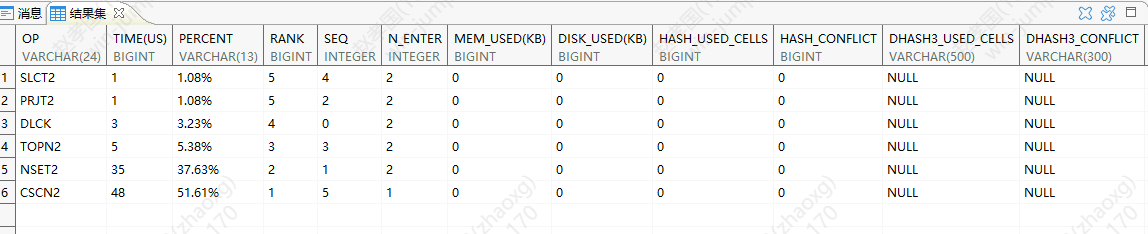
通过上面3步可发现执行计划慢在哪一步,对于遇到sql包含OR条件,通过OPTIMIZER_OR_NBEXP可以优化OR表达式。在不变动参数的全局影响时,可以通过HINT方式,对个别SQL进行调整(这种HINT可以注入在后台,不需要修改应用代码,可以随时取消)
参数名字:OPTIMIZER_OR_NBEXP
默认值:0
属性:动态会话级
0:不优化;
1:生成 UNION_FOR_OR 操作符时,优化为无 KEY 比较方式;
2:OR 表达式优先考虑整体处理方式;
4:相关子查询的 OR 表达也优考虑整体处理方式;
8:OR 布尔表达式的范围合并优化;
16:同一列上同时存在常量范围过滤和 IS NULL 过滤时的优化,如 C1 > 5 OR C1 IS NULL。
支持使用上述有效值的组合值,如 7 表示同时进行 1、2、4 的优化
在个别SQL中,我们可能调整为2,效果更好。
二、样例测试说明
达梦版本:DM8.1.4.6
--1、构造数据
create table tab1(v1 varchar(30000),v2 varchar(30000),v3 varchar(30000));
create index idx_tab1_v1 on tab1(v1);
--2、待分析SQL
select * from tab1 where v1 like 'sdf%' or v2 like 'sdf%' limit 10
执行计划如下
1 #NSET2: [1, 2, 156]
2 #PRJT2: [1, 2, 156]; exp_num(4), is_atom(FALSE)
3 #TOPN2: [1, 2, 156]; top_num(10)
4 #UNION FOR OR2: [1, 2, 156]; key_num(0), outer_join(-)
5 #BLKUP2: [1, 1, 156]; idx_tab1_v1(tab1)
6 #SSEK2: [1, 1, 156]; scan_type(ASC), idx_tab1_v1(tab1), scan_range['sdf','sdg'), is_global(0)
7 #SLCT2: [1, 1, 156]; (tab1.v2 >= 'sdf' AND tab1.v2 < 'sdg' AND exp11)
8 #CSCN2: [1, 1, 156]; INDEX33609591(tab1); btr_scan(1)
从如上执行计划来看,这个sql的or条件被拆分了两个sql,然后union结果集;
在保持全局参数为0的情况下,希望使用 OPTIMIZER_OR_NBEXP 为 2的效果,如何为这个语句修改参数?
手工对sql执行效率
select /*+OPTIMIZER_OR_NBEXP(2)*/ * from tab1 where v1 like 'sdf%' or v2 like 'sdf%' limit 10
1 #NSET2: [1, 1, 156]
2 #PRJT2: [1, 1, 156]; exp_num(4), is_atom(FALSE)
3 #TOPN2: [1, 1, 156]; top_num(10)
4 #SLCT2: [1, 1, 156]; ((tab1.v1 >= 'sdf' AND tab1.v1 < 'sdg') OR (tab1.v2 >= 'sdf' AND tab1.v2 < 'sdg'))
5 #CSCN2: [1, 1, 156]; INDEX33609591(tab1); btr_scan(1)
select /*+OPTIMIZER_OR_NBEXP(0)*/ * from tab1 where v1 like 'sdf%' or v2 like 'sdf%' limit 10
1 #NSET2: [1, 2, 156]
2 #PRJT2: [1, 2, 156]; exp_num(4), is_atom(FALSE)
3 #TOPN2: [1, 2, 156]; top_num(10)
4 #UNION FOR OR2: [1, 2, 156]; key_num(1), outer_join(-)
5 #BLKUP2: [1, 1, 156]; idx_tab1_v1(tab1)
6 #SSEK2: [1, 1, 156]; scan_type(ASC), idx_tab1_v1(tab1), scan_range['sdf','sdg'), is_global(0)
7 #SLCT2: [1, 1, 156]; (tab1.v2 >= 'sdf' AND tab1.v2 < 'sdg') SLCT_PUSHDOWN(TRUE)
8 #CSCN2: [1, 1, 156]; INDEX33609591(tab1) NEED_SLCT(TRUE); btr_scan(1)
--3、为特定SQLSQL语句修改参数 OPTIMIZER_OR_NBEXP 为 2
sf_inject_hint(
'* from tab1 where v1 like ''sdf%'' or v2 like ''sdf%'' limit',--sql语句或者片段
'OPTIMIZER_OR_NBEXP(2)',--参数调整说明,语法:参数名称(参数值)
'inject_20250806',--这条调整规则的名字,通过这个名字,我们可以通过 sp_deinject_hint('名字'),进行规则取消
null,true,true
);
--4、查看计划:确实修改成功了,or根据 OPTIMIZER_OR_NBEXP 为 2 的规则,作为一个整体处理了
1 #NSET2: [1, 1, 156]
2 #PRJT2: [1, 1, 156]; exp_num(4), is_atom(FALSE)
3 #TOPN2: [1, 1, 156]; top_num(10)
4 #SLCT2: [1, 1, 156]; ((tab1.v1 >= 'sdf' AND tab1.v1 < 'sdg') OR (tab1.v2 >= 'sdf' AND tab1.v2 < 'sdg'))
5 #CSCN2: [1, 1, 156]; INDEX33609591(tab1); btr_scan(1)
或查看系统视图
SQL>select * from sys.SYSINJECTHINT;

- -5、规则取消
sf_deinject_hint('inject_20250806'); -- 进行规则取消
三、会影响SQL性能常用参数
除了上面说的参数(OPTIMIZER_OR_NBEXP)可以通过HINT优化外,还有如下两个常用的参数会影响SQL性能
1、参数名字:COMPLEX_VIEW_MERGING
默认值:0
属性:动态会话级
对于复杂视图(一般含有GROUP或者集函数等)会执行合并操作,
使得 GROUP 分组操作在连接之后才执行。
0:不启用;
1: 对不包含别名和同名列的视图进行合并;
2: 视图定义包含别名或同名列时也进行合并
在个别SQL中,我们可能调整为2,效果更好。
2、参数名字:FILTER_PUSH_DOWN
默认值:0
属性:动态会话级
对单表条件是否下放的不同处理方式。
0: 表示条件不下放;
1: 表示在新优化器下, 对单表过滤条件进行下放处理;
2:表示在新优化器下对外连接、半连接进行下放条件优化处理;
4: 语义分析阶段考虑单表过滤条件的选择率, 超过0.5 则不下放,由后面进行代价计算选择是否下放, 参数值 4 仅在参数取值包含 2 时有效,即将参数值设为 6 时有效;
8: 表示尝试将包含非相关子查询的布尔表达式进行下放。
支持使用上述有效值的组合值, 如 6 表示同时进行 2 和 4 的优化
在个别SQL中,我们可能调整为1,效果更好。
----end----