【IQA技术专题】大模型评级IQA:Q-Align

大模型离散类别IQA:Q-Align:Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels(2024 CVPR)
- 专题介绍
- 一、研究背景
- 二、Q-Align方法
- 2.1 人类和LMM评分分析
- 2.1.1人类评分
- 2.1.2 LMM评分
- 2.1.3 评级和打分的互相转换
- 2.2 方法总览
- 三、实验
- 四、总结
本文将围绕《Q-Align:Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels》展开完整解析。Q-Align实现的是无参考的图像质量评价指标,可以有效地对图像的感知(Fidelity)质量进行评估。参考资料如下,本专栏提到的IQA-pytorch也收录了该方法,感兴趣的可以体验:
[1]. 论文地址
[2]. 代码地址
专题介绍
图像质量评价(Image Quality Assessment, IQA)是图像处理、计算机视觉和多媒体通信等领域的关键技术之一。IQA不仅被用于学术研究,更在影像相关行业内实现了完整的商业化应用,涉及影视、智能手机、专业相机、安防监控、工业质检、医疗影像等。IQA与图像如影随形,其重要程度可见一斑。
但随着算法侧的能力不断突破,AIGC技术发展火热,早期的IQA或已无法准确评估新技术的能力。另一方面,千行百业中各类应用对图像质量的需求也存在差异和变化,旧标准也面临着适应性不足的挑战。
本专题旨在梳理和跟进IQA技术发展内容和趋势,为读者分享有价值、有意思的IQA。希望能够为底层视觉领域内的研究者和从业者提供一些参考和思路。
系列文章如下:
【1】🔥IQA综述
【2】PSNR&SSIM
【3】Q-Insight
【4】VSI
【5】LPIPS
【6】DISTS
一、研究背景
在线视觉内容的爆炸式增长强调了对准确的机器评估器的需求,希望能可靠地评估不同类型的视觉内容的分数。虽然最近的研究已经证明了大型多模态模型(LMM)在广泛的相关领域的非凡潜力,该论文探索了如何教它们进行与人类意见一致的视觉评级,也算是比较早的探索如何使用大型LMM在IQA上的应用文章。
综上,此论文的贡献可以总结为以下3点:
- 提出了一个有效的IQA评分框架,可以使用LMM对图像进行打分。通过实验证明了LMM基于分类的打分方式比直接打分的方式更有效。
- 提出的Q-ALIGN在多个视觉评估任务上达到了最先进的精度和泛化能力。可以使用更少数据和更少的训练迭代收敛达到更好的效果。
- 统一的视觉评分模型。图像质量评估(IQA)、图像美学评估(IAA)和视频质量评估(VQA)在同一结构下有效地独立学习,该论文进一步提出了ONEALIGN,将这三个任务统一在一个模型下。
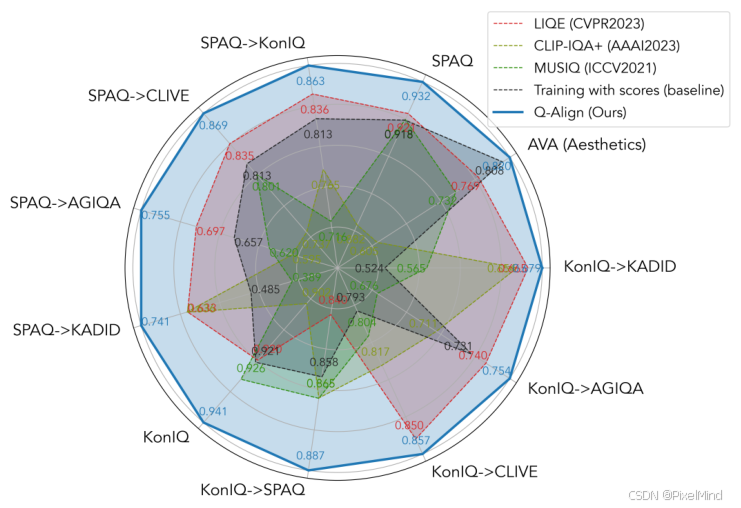
下图是作者做的定量实验可视化图,可以看到本文提出的方法是SOTA的。
二、Q-Align方法
2.1 人类和LMM评分分析
2.1.1人类评分
通常分为以下3步,如图所示:
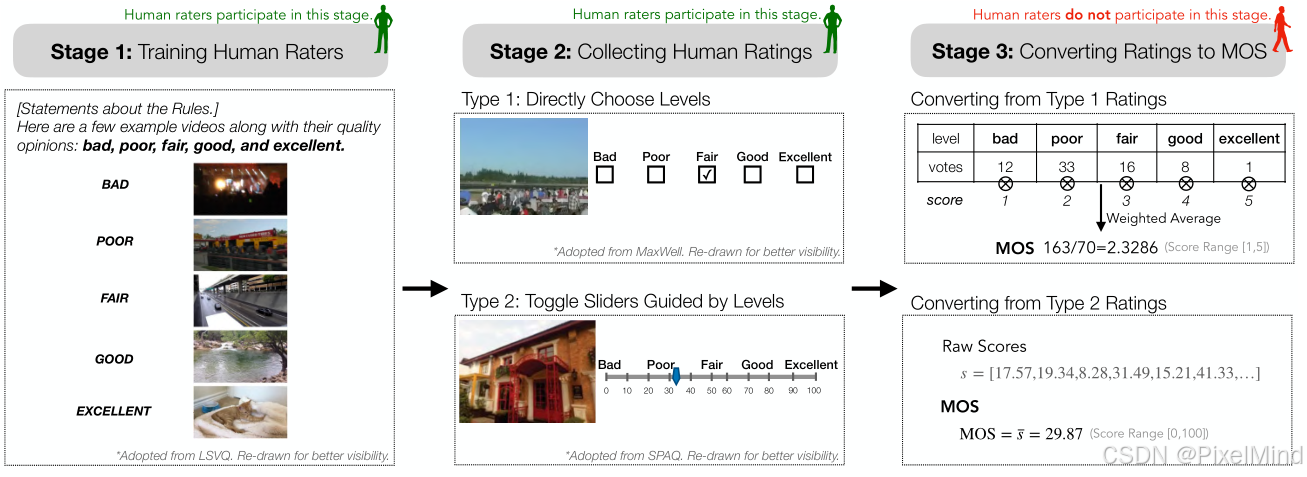
- 训练人类评级员。作为收集人类意见的标准过程,使用评级规则对人类评级员的训练过程至关重要,包括将人类评级员与每个评级级别的一个或多个示例对齐,如上图stage1所示。不过在此过程中,示例的精确质量分数不会显示给人类评分员,一般只是一个定性的结果。
- 收集人类评分。在训练完人类评分员后,核心阶段是收集人类的初始评分。一般情况下,人类评级员提供意见的方式有两种:一是直接选择评级等级;二是切换滑块以生成分数。无论哪种方式,人类评分者都不需要直接输入分数来提供他们的意见,这也符合我们定性评价的方式,如stage2所示。
- 将人类评级转换为MOS。如stage3所示,在视觉评分数据集中,初始评分被平均为MOS。人类评分员不参与这一阶段。
2.1.2 LMM评分
接下来,作者设计了一个prompt来对多个不同的LMM进行提问,看各个LMM输出的格式,prompt如下所示:

输出结果如下图所示:

可以看到在特定对齐之前,LMM主要用定性形容词来回应。因此,论文认为如果将分数作为LMM的学习目标,LMM首先需要学习输出分数的格式,然后学习如何准确地评分。为了避免这种额外的格式成本,本文选择评级级别这种形式。
这里可以看出跟Q-insight的区别,文章直接学习的分数,这可能跟前期设计的prompt相关,假设加上打分的要求,这个结论是否会反转?
2.1.3 评级和打分的互相转换
- 数据集评分转换为评级:借助于以下的公式:L(s)=liif m+i−15×(M−m)<s≤m+i5×(M−m)L(s) = l_i \ \text{if} \ \displaystyle \mathrm{m} + \frac{i - 1}{5} \times (\mathrm{M} - \mathrm{m}) < s \leq \mathrm{m} + \frac{i}{5} \times (\mathrm{M} - \mathrm{m}) L(s)=li if m+5i−1×(M−m)<s≤m+5i×(M−m)其中,{li∣i=15}={bad,poor,fair,good,excellent}\left\{ l_i \big\vert_{i = 1}^5 \right\} = \{ \text{bad}, \text{poor}, \text{fair}, \text{good}, \text{excellent} \}{li∣∣i=15}={bad,poor,fair,good,excellent},可以看到论文选用了5个评级,m\text{m}m和M\text{M}M是数据集中评分的最小值和最大值。简单来说,是将所有评分分数从小到大进行5等分,分为5个等级,在哪个区间里面就是哪个等级。
显然这是一个多对一的映射,不可避免地会稍微损害GT的精度。作者做了一个转换精度的实验,用PLCC来评估转换前后的精度:

考虑到MOS值在此精度范围内具有一定的随机性,作者认为转换后的评级水平作为训练标签具有足够的准确性。
- LMM的预测评级转换为评分:训练后,需要将LMM预测的评级级别转换回分数。如下所示:SLMM=∑i=15pliG(li)=i×exli∑j=15exljS_{\text{LMM}} = \sum_{i=1}^{5} p_{l_i} G(l_i) = i \times \frac{e^{x_{l_i}}}{\sum_{j=1}^{5} e^{x_{l_j}}}SLMM=i=1∑5pliG(li)=i×∑j=15exljexli公式中对于前面讲到的5个不同的等级进行一个加权求和,这样得到一个最后的分数。
2.2 方法总览
如下图所示,前一节已经讲过了Training Conversion和最后的Inference Conversion。

中间的过程是文章训练IQA、IAA和VQA3个不同任务的过程。重点的地方在于2个,第一个是模型,第二个是prompt的设计。
- 模型结构:

作者采用开源LMM模型mPLUG-Owl-2,能够有效完成视觉感知和语言理解。通过视觉编码器将图像转换为embedding向量后,借助视觉抽象器将每张图像的维度从1024显著压缩至64。基于LLaMA2的2048上下文长度特性,在监督微调阶段可同时处理30张图像(未使用抽象器时为2张)。这种设计使得系统能够将视频作为图像序列输入LMM,并统一处理图像(IQA、IAA)和视频(VQA)评分任务。模型优化采用标签与logits间的交叉熵损失函数。 - prompt设计:如下图所示

为每个任务定义格式,< img >和< level >中夹的分别是图像和预测的类别。
三、实验
论文从mPLUG-Owl2的预训练权值进行微调。数据集配置如下:
IQA:选择了KonIQ-10k,SPAQ和KADID-10k作为训练集,在IQA上训练Q-ALIGN。除了对三个训练数据集的测试集进行评估外,另外对四个未见过的数据集进行了评估:LIVE Challenge、AGIQA-3K、LIVE和CSIQ,考察其OOD泛化能力。
IAA:AVA数据集,分别包含236K训练图像和19K测试图像。
VQA:最大的野外VQA数据集LSVQ,与IQA类似,在LSVQ的两个官方测试集(LSVQtest和LSVQ1080P)和两个未见的数据集(KoNViD-1k和MaxWell)上进行OOD评估。
首先是IQA任务上定量实验。

IQA任务上使用同等大小的数据集表现更好,使用few-shot效果仍然会好于一般方法。
后续作者做了IQA任务上混合数据集的实验:

通过简单的混合策略,Q-ALIGN能够在混合数据集时保持或提高单个数据集的准确性。
IAA任务上定量实验:

IAA效果,结论一样,使用同等大小的数据集表现更好,使用few-shot效果仍然会好于一般方法。
VQA任务上定量实验:

在所有四个评估数据集上,Q-ALIGN和FAST-VQA的集成证明比DOVER优势超过1%。另一方面,虽然Q-ALIGN (1fps)是有效的,但由于还没有将视频的所有帧输入到LMM中,因此未来仍有改进的空间。
多任务混合实验结果如下:

onealign,混合多任务效果也会更好。
训练和推理成本结果如下:



训练成本上是更小,只需要迭代2个epoch即可达到最佳性能,推理上在3090显卡上可以以23fps近实时推理图像,视频也可以以一个可接受的耗时完成推理。
消融实验如下,性能选用了SRCC和PLCC的平均值:

与基于分数的方式相比,使用基于评级的方式可以使跨数据集(OOD)评估平均提高10%,这表明基于评级的方式更好地利用了LMM的视觉能力。基于分数的方式的准确性甚至不能在任何设置上超过现有的最先进的技术,浪费了这些强大的基础模型。
定性实验如下:

将ONEALIGN的IQA和IAA预测结果可视化在两张真实图像上。显然该方法可以判断(A)和(B)在质量和美学上的差异,为了捕捉到更细微的差别,可以关注每张图的第二个级别(下划线),它可以提供更精细的评估,即(B)的美学介于一般和较差之间,而其质量介于较差和较差之间。此外,作者发现模型不会预测非相邻评级(例如好和差)的第一和第二高水平,这表明LMM本质上理解这些文本定义的评级。
四、总结
此论文利用离散的文本定义图像的质量,借助大模型的知识实现了更准确的感知评分,将IQA、IAA、VQA3个不同的评价任务进行了组合实现了更高的性能,提升了其通用性。
感谢阅读,欢迎留言或私信,一起探讨和交流,如果对你有帮助的话,也希望可以给博主点一个关注,谢谢。