【数据结构入门】双向链表
从本篇博客开始,后面的数据结构尽量采用代码分块的思想来进行表述,不然很多读者看到大段代码就失去了阅读兴趣。
目录
1.链表的结构
2.带头的双向链表的实现
2.1 双向链表的定义
2.2 双向链表的尾插
2.3 打印双链表的值
2.4 初始化头结点
2.5 二级指针使用的时机
2.6 双向链表的尾删
2.7 双向链表的头插
2.8 双向链表的头删
2.9 双向链表按值查找
2.10 按照指定位置前插入
2.11 删除指定的位置的节点
2.12 双向链表内存释放
2.13 代码的复用
3.链表和顺序表(数组)的区别
3.1 顺序表的缺陷
3.2 链表的优点
3.3 链表的缺点
3.4 顺序表的优点
1.链表的结构
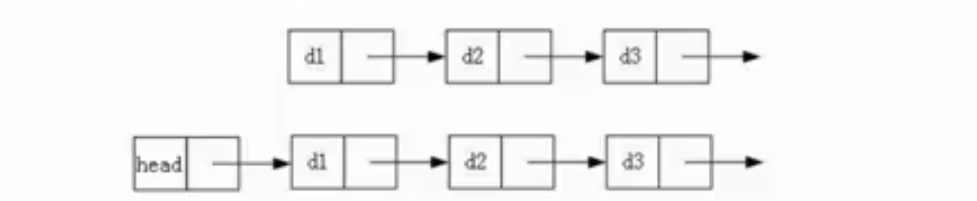
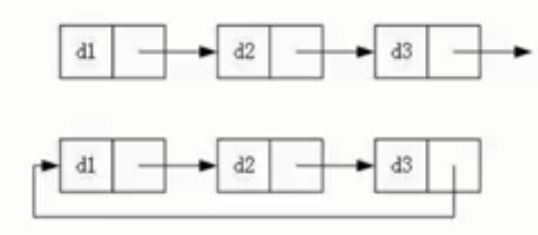
链表的结果多种多样,以下情况组合起来就有8种结构:
1.单向、双向;
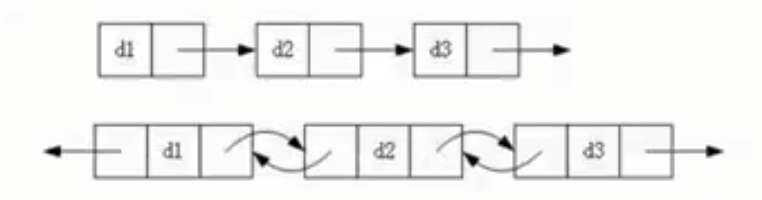
2.带头、不带头;(哨兵)
3.循环、非循环。
最常用的两种结构是:单向无头不循环(单链表)、双向带头循环;
单链表:
①oj题中常见;
②不会单独作为链表使用,一定是其他数据结构的部分,例如图、哈希表.......
循环双向链表:
①作为链表使用,例如STL中的list;
2.带头的双向链表的实现
2.1 双向链表的定义
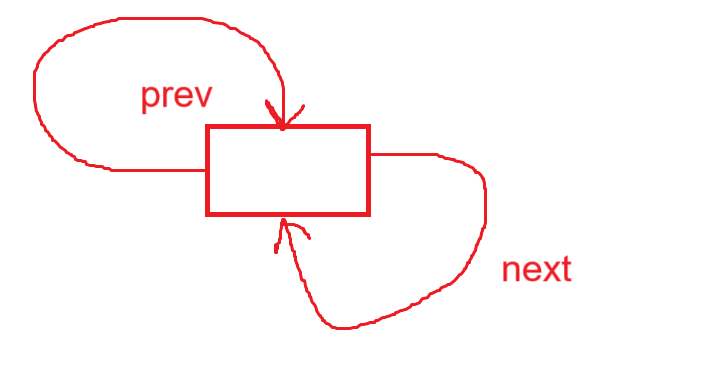
由于双向链表,需要访问当前节点的相邻节点,所以需要两个指针分别指向前后节点;
// 双链表的结构体定义
typedef struct ListNode
{ListNode* next;ListNode* prev;dataType data;
}ListNode;
2.2 双向链表的尾插
这里的头结点是不存有效值的,这是因为后面的代码可以复用一套,如果头结点要存值,后面的代码需要单独给出逻辑去处理,所以这里浪费一个节点,反而将代码变得更简洁了。
对于空表来说,是这样的状态:概括来说就是两个指针分别指向头结点。
那么当后插节点的时候,需要找到链表的最后一个节点,此时是头;最后一个节点的next指向新节点,prev指向原来的最后的节点,新节点的next指向头,头的prev改成新节点。
下图是只有头结点的尾插,此时的头结点的prev本应该在正常情况下指向链表的尾,但由于只有头结点,所以这套逻辑,可以完美复用在正常的、有多个节点的双链表中。
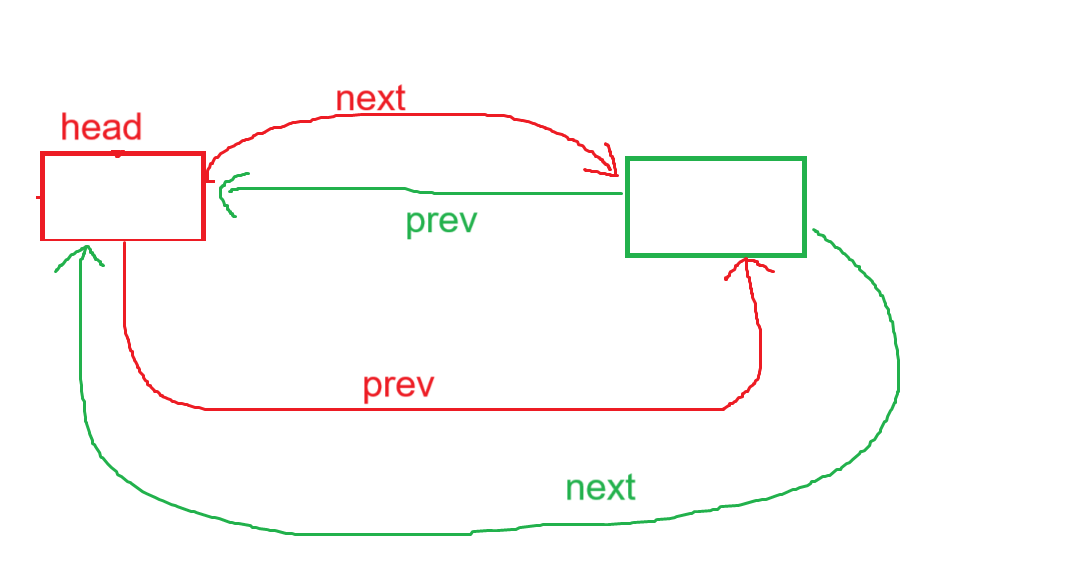
①将头指针的prev保存下来,正常情况下是尾指针,若只有一个节点那就是head本身。
②创建一个新的节点。
③将尾指针的next指向新节点,新节点的next指向head。
④将head的prev指向新节点,将新节点的prev指向尾结点。
3、4没有强制顺序要求,合理即可。
// 创建新节点
ListNode* createNode(dataType x)
{ListNode* node = (ListNode*)malloc(sizeof(ListNode));node->data = x;node->next = NULL;node->prev = NULL;return node;
}// 尾插
void push_back(ListNode* head, dataType x)
{assert(head);ListNode* tail = head->prev;ListNode* newNode = createNode(x);tail->next = newNode;newNode->next = head;head->prev = newNode;newNode->prev = tail;
}2.3 打印双链表的值
便于调试双链表,这里最好写一个可以遍历打印双链表的方法,但是双链表是一个循环链表,如果遍历打印,那不就死循环了吗?还有一点就是通过上面的尾插,我们可以看到头结点是不存值的,所以既不能遍历打印也不能打印头结点,我们该怎么做呢?
从head的next节点开始遍历,直到当前指针指向了head就停止。
// 打印双链表节点
void printList(ListNode* head)
{assert(head);if (head->next == head) {printf("空链表无法打印!");exit(-1);}ListNode* curr = head->next;while (curr != head) {printf("%d ",curr->data);curr = curr->next;}
}2.4 初始化头结点
我们之前的函数都需要判断头结点不能为NULL,所以我们需要对头结点进行初始化,这里可以使用之前的createNode的接口实现。
// 初始化头结点
ListNode* initHead()
{ListNode* newNode = createNode(0);newNode->next = newNode;newNode->prev = newNode;return newNode;
}2.5 二级指针使用的时机
很多人觉得,需要修改链表的时候就需要穿入一个二级指针(head的地址),这种说法是错误的,传入二级指针的时机是,如果程序内部需要对头节点进行修改,那么就可以传入头结点的地址,这就是二级指针。
例如上面的尾插:这里并没有对头结点本身进行修改,只是对头结点的成员(next和prev)进行修改,所以不需要传入二级指针。
// 尾插
void push_back(ListNode* head, dataType x)
{assert(head);ListNode* tail = head->prev;ListNode* newNode = createNode(x);tail->next = newNode;newNode->next = head;head->prev = newNode;newNode->prev = tail;
}再例如初始化头结点,我们使用二级指针的方式:我们需要修改head的值(原本是NULL),此时就不需要返回值了,这里已经通过解引用的方式对head本身进行修改了。
// 初始化头节点(必须用二级指针)
void initHead(ListNode** head)
{*head = createNode(0); // 修改head指针本身的指向(*head)->next = *head;(*head)->prev = *head;
}// 调用
ListNode* head = NULL;
initHead(&head);2.6 双向链表的尾删
①找到保存两个节点:最后一个节点、倒数第二个节点。
②将head的prev指向倒数第二个节点,倒数第二个节点的next指向head。
③将倒数第一个节点的内存释放。
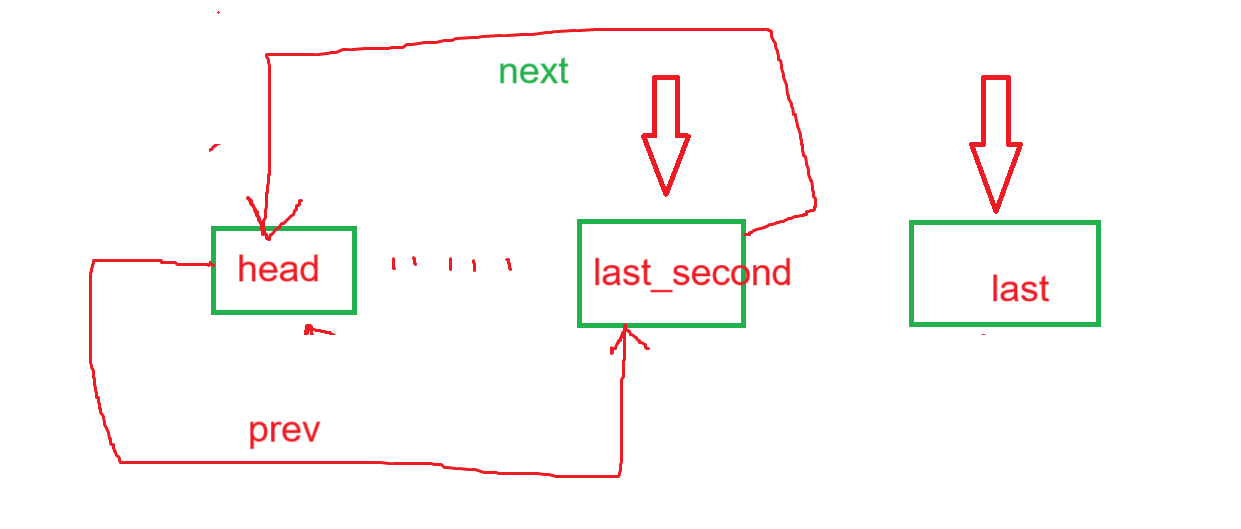
// 尾删
void pop_back(ListNode* head)
{assert(head);assert(head->next != head); // 只剩头结点(空链表)// 保存最后一个元素ListNode* last = head->prev;// 保存倒数第二个元素ListNode* last_second = last->prev;head->prev = last_second;last_second->next = head;free(last);
}2.7 双向链表的头插
非常简单,只需要保存head的next节点,首先将head的next指向新节点,新节点的prev指向head,然后新节点的next指向之前保存的next,然后保存的next的prev指向新节点。
其实就是新节点分别和head和原来的head->next分别进行绑定。
// 头插
void push_front(ListNode* head, dataType x)
{assert(head);// 保存head的nextListNode* next = head->next;ListNode* newNode = createNode(x);head->next = newNode;newNode->prev = head;newNode->next = next;next->prev = newNode;
}2.8 双向链表的头删
只需要保存head的next以备删除,保存head的next的next,作为新的第一个节点,只需要将head的next指向新节点,新节点的prev指向head即可。
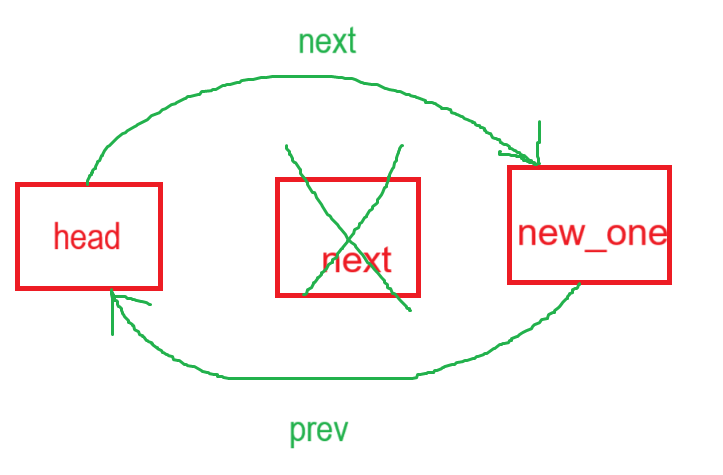
// 头删
void pop_front(ListNode* head)
{assert(head);assert(head->next != head); // 只剩头结点(空链表)ListNode* next = head->next;ListNode* new_one = next->next; // 新的head之后的节点head->next = new_one;new_one->prev = head;free(next);}2.9 双向链表按值查找
返回这个节点的地址即可,这个可以和后面的指定位置插入值进行配合使用,主要逻辑是遍历双向链表,按照值进行比对,返回第一个等于这个值的节点的指针。
// 根据值查找节点
ListNode* find(ListNode* head, dataType x)
{assert(head);assert(head->next != head);// 空链表就不必查了ListNode* curr = head->next;while (curr != head){if (curr->data == x){return curr;}curr = curr->next;}return NULL;
}2.10 按照指定位置前插入
这里需要保存pos之前的节点,使得新节点的位置在:
prev newnode pos中,让newnode分别和prev和pos相连即可。
// 根据位置(指针)前插入节点
void insertList(ListNode* pos, dataType x)
{assert(pos);// posPrev newnode posListNode* posPrev = pos->prev;ListNode* newNode = createNode(x);newNode->next = pos;pos->prev = newNode;newNode->next = pos;posPrev->next = newNode;newNode->prev = posPrev;
}
2.11 删除指定的位置的节点
这里需要注意的是,该节点不能是head,不然会破坏掉双向链表的结构,所以函数的形参要传入一个head,这里由于只是测试功能所以没有加head作为形参;
这个也很简单,首先需要知道该指定位置的prev和next,让prev和next相连即可,最后释放pos即可。
// 根据位置删除节点
void deleteList(ListNode* pos)
{assert(pos);// 注意pos不能是head,删除head会破坏结构,可以传入head// prev pos nextListNode* posPrev = pos->prev;ListNode* posNext = pos->next;posPrev->next = posNext;posNext->prev = posPrev;free(pos);
}我们测试的时候可以先用find查找指定值的地址,再根据insertList对该节点的前面进行插入:
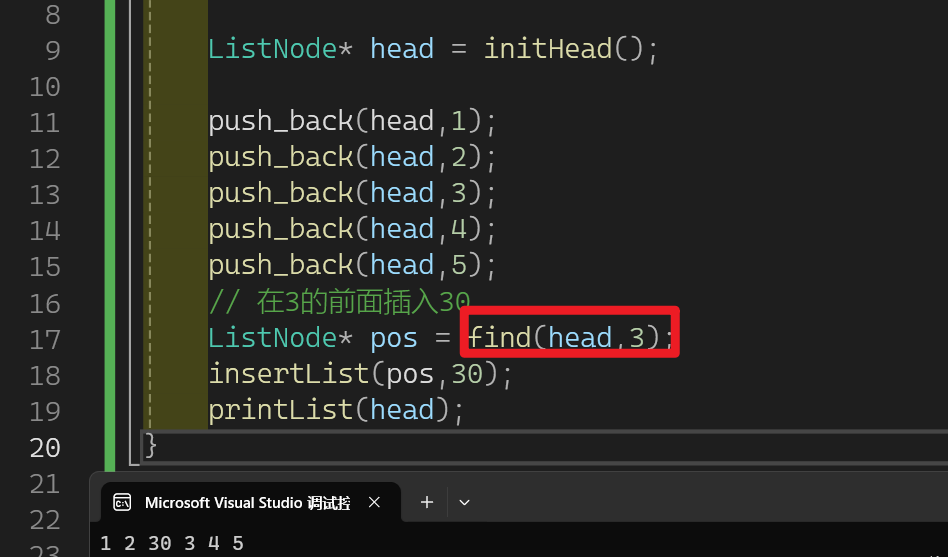
2.12 双向链表内存释放
这里分为两种情况,如果待会链表需要继续使用,那么我们可以保留头结点,如果链表使用完毕那么我们需要将链表全部销毁,所以我们可以先写保留头结点的接口,clearList:
指针指向head的下一个节点,需要保存curr的next节点,以便指针后移,每次指针指向的内容,内存释放,然后进入下一个节点继续释放,直到head为止,请空链表之后需要保证结构的合理性,所以head的prev和next都需要指向自己。
// 清空链表
void clearList(ListNode* head)
{assert(head);ListNode* curr = head->next;ListNode* next = curr->next;while (curr != head){free(curr);curr = next;next = next->next;}head->next = head;head->prev = head;
}如果要对head进行销毁,那么只需要调用上面的方法,然后传入二级指针,即head的地址,这样才能对head进行修改,直接free head然后让head指向空。
// 销毁链表
void destroyList(ListNode** head)
{clearList(*head);// 释放头free(*head);*head = NULL;
}2.13 代码的复用
目前的代码的复用情况不好,我们写了根据位置插入、删除节点,那么头插和尾插等方法可以进行复用。
复用后的整体代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include"list.h"// 创建新节点
ListNode* createNode(dataType x)
{ListNode* node = (ListNode*)malloc(sizeof(ListNode));node->data = x;node->next = NULL;node->prev = NULL;return node;
}// 尾插
void push_back(ListNode* head, dataType x)
{/*assert(head);ListNode* tail = head->prev;ListNode* newNode = createNode(x);tail->next = newNode;newNode->next = head;head->prev = newNode;newNode->prev = tail;*/insertList(head,x); // 在head之前插入
}// 打印双链表节点
void printList(ListNode* head)
{assert(head);if (head->next == head){printf("空链表无法打印!");exit(-1);}ListNode* curr = head->next;while (curr != head){printf("%d ", curr->data);curr = curr->next;}
}// 初始化头结点
ListNode* initHead()
{ListNode* newNode = createNode(0);newNode->next = newNode;newNode->prev = newNode;return newNode;
}// 尾删
void pop_back(ListNode* head)
{//assert(head);//assert(head->next != head); // 只剩头结点(空链表)//// 保存最后一个元素//ListNode* last = head->prev;//// 保存倒数第二个元素//ListNode* last_second = last->prev;//head->prev = last_second;//last_second->next = head;//free(last);deleteList(head->prev);
}// 头插
void push_front(ListNode* head, dataType x)
{//assert(head);//// 保存head的next//ListNode* next = head->next;//ListNode* newNode = createNode(x);//head->next = newNode;//newNode->prev = head;//newNode->next = next;//next->prev = newNode;insertList(head->next,x);
}// 头删
void pop_front(ListNode* head)
{//assert(head);//assert(head->next != head); // 只剩头结点(空链表)//ListNode* next = head->next;//ListNode* new_one = next->next; // 新的head之后的节点//head->next = new_one;//new_one->prev = head;//free(next);deleteList(head->next);
}// 根据值查找节点
ListNode* find(ListNode* head, dataType x)
{assert(head);assert(head->next != head);// 空链表就不必查了ListNode* curr = head->next;while (curr != head){if (curr->data == x){return curr;}curr = curr->next;}return NULL;
}// 根据位置(指针)前插入节点
void insertList(ListNode* pos, dataType x)
{assert(pos);// posPrev newnode posListNode* posPrev = pos->prev;ListNode* newNode = createNode(x);newNode->next = pos;pos->prev = newNode;newNode->next = pos;posPrev->next = newNode;newNode->prev = posPrev;}// 根据位置删除节点
void deleteList(ListNode* pos)
{assert(pos);// 注意pos不能是head,删除head会破坏结构,可以传入head// prev pos nextListNode* posPrev = pos->prev;ListNode* posNext = pos->next;posPrev->next = posNext;posNext->prev = posPrev;free(pos);
}// 销毁链表
void destroyList(ListNode** head)
{clearList(*head);// 释放头free(*head);*head = NULL;
}// 清空链表
void clearList(ListNode* head)
{assert(head);ListNode* curr = head->next;ListNode* next = curr->next;while (curr != head){free(curr);curr = next;next = next->next;}head->next = head;head->prev = head;
}3.链表和顺序表(数组)的区别
3.1 顺序表的缺陷
①顺序表每次扩容都是n倍扩容,这会造成空间的浪费。
②顺序表的头部、中间插入,效率低下,需要挪动后面的所有元素,时间复杂度是O(N)。
③顺序表的扩容会有效率的损失。
3.2 链表的优点
①链表扩容每次只扩一个,不会造成空间的浪费。
②链表的头插、尾插速度很快,时间复杂度是O(1)。
③链表每次扩容只增加一个节点,所以不会有效率的损失。
3.3 链表的缺点
①不能随机访问,即不能通过下表进行访问数据,很多的排序都无法使用链表。
②由于是在堆上随机开辟空间,内存不连续,会有内存碎片的问题。
③由于②缓存利用率就不高。
3.4 顺序表的优点
①可以通过下表随机访问。
②在内存中是连续存储的,不会存在内存碎片的问题。
③缓存的命中率很高,当读取第一个数据的时候,预加载后面的数据都会命中,因为这里是连续存储的。