Android渲染/合成底层原理详解
一、核心组件详解
1. 核心硬件
-
GPU:执行图形渲染,将绘图指令转为像素数据(OpenGL ES/Vulkan)。
-
DPU(显示处理单元):负责图层合成(重叠区域计算/缩放/格式转换)。
-
HWC(硬件合成器):HAL(HWC)对合成操作进行了抽象,屏蔽了具体实现.绝大多数情况下hwc的实现者是DPU,除了合成工作外,hwc模块还负责送显以及发送VSync信号。
2. GraphicBuffer
-
作用:GraphicBuffer是整个图形系统的核心,所有的渲染操作都将在此对象上进行,包括同步给GPU和HWC每当应用有显示需求时,应用会向系统申请一块GraphicBuffer内存,这块内存将会共享给GPU用于执行渲染工作,接着会同步给HWC用于合成和显示。我们可以把每一个GraphicBuffer对象看做是一个个渲染完成的图层。
-
生命周期状态:
-
FREE:空闲状态,APP可申请使用。 -
DEQUEUED:APP正在渲染(GPU写入数据)。 -
QUEUED:渲染完成,等待SF消费。 -
ACQUIRED:SF正在合成(HWC/GPU读取)。
-
-
生命周期具体描述:
渲染阶段:应用有绘图需求了,由GPU分配一块内存给应用,应用调用GPU执行绘图,此时使用者是GPU
合成阶段:GPU渲染完成后将图层传递给sf进程,sf进程决定由谁来合成,hwc或者GPU如果使用GPU合成,那么此时buffer的使用者依旧是GPU,如果使用hwc合成,那么此时buffer的使用者是hwc。显示阶段:所有的buffer在此阶段的使用者都是hwc,因为hwc控制着显示芯片从生命周期可以看出GraphicBuffer对象在流转的过程中,会被GPU、CPU、DPU三个不同的硬件访问,如果同一块内存能够被多个硬件设备访问,就需要一个同步机制。在Android图形系统中,Fence机制就是用来保证跨硬件访问时的数据安全
-
同步机制:Fence(硬件锁)
-
原理:每个硬件访问GraphicBuffer前需等待Fence信号(如GPU渲染完成才允许DPU读取)。
-
类型:
acquire_fence(消费者锁),release_fence(生产者锁)。
-
3. BufferQueue
-
角色:协调生产者(APP)和消费者(SF)的核心队列。
-
从名称就可以看出来,它是一个封装了GraphicBuffer的队列,BufferQueue对外提供了GraphicBuffer对象出列/入列的接口
-
工作流程:
图表

-
三重缓冲:默认3个GraphicBuffer循环使用,避免帧等待(VSync周期内可预渲染下一帧)。
4. Surface
-
定位:APP的绘图入口,封装BufferQueue的生产者接口。
-
详细描述:应用中所有的绘图操作最终都是在Surface中执行的,Surface作为图像的生产者,持有BufferQueue的引用,并且封装了出列和入列两个方法
以2D绘图的流程来举例:1、需要显示图形时,首先创建一个Surface对象
2、调用Surface#lockCanvas()获取Canvas对象
3、调用Canvas的draw开头的函数执行一系列的绘图操作
4、调用Surface#unlockCanvasAndPost()将绘制完成的图层提交,等待下一步合成显示第二步的[lockCanvas()]方法返回了Canvas对象供开发者绘图使用,其内部就调用了BufferQueue#dequeueBuffer()申请一块图形buffer,后续所有的绘图结果都会写入这块内存中
第四步的[unlockCanvasAndPost()]方法内部调用了BufferQueue#queueBuffer()方法将绘制完成的Buffer入列,等待sf进程在下一次同步信号周期合成并完成送显
-
关键方法:
-
lockCanvas()→ 调用dequeueBuffer()获取Canvas绘图。 -
unlockCanvasAndPost()→ 调用queueBuffer()提交数据。
-
-
底层绑定:
ANativeWindow(NDK层),为OpenGL ES/Vulkan提供绘图表面。
5. SurfaceFlinger (SF,由init.rc启动)
-
职责:
-
接收所有Layer的GraphicBuffer。
-
调用HWC合成图层。
-
通过DRM/KMS驱动送显。
-
职责总结:SurfaceFlinger进程负责接受来自APP进程的图形数据,调用hwc进行合成并完成最终的送显(“请求VSync”和“执行合成工作”)
-
-
核心成员:
-
mHWC:硬件合成器代理。 -
mEventThread:分发VSync-app/VSync-sf信号。 -
mPrimaryDispSync:预测硬件VSync模型。
-
6. HWComposer (HWC)
-
作用:辅助SF完成接受硬件的VSync信号以及完成图层合成工作
-
合成策略:
-
硬件合成:普通图层(无透明/变形),由DPU直接合成(低功耗)。
-
GPU合成:复杂特效图层(调用OpenGL ES)。
-
-
查看方式:
adb shell dumpsys SurfaceFlinger→DEVICE(硬件合成)/CLIENT(GPU合成)。
| 组件 | 作用 |
|---|---|
| GraphicBuffer | 图形内存块,存储渲染结果,共享给GPU/DPU |
| BufferQueue | 生产者-消费者模型管理GraphicBuffer,状态包括:FREE → DEQUEUED → QUEUED → ACQUIRED |
| Surface | APP绘图入口,封装BufferQueue的出列/入列操作 |
| SurfaceFlinger (SF) | 系统服务进程:接收图层、调用HWC合成、送显 |
二、显示全流程
1. 进程启动与视图绑定
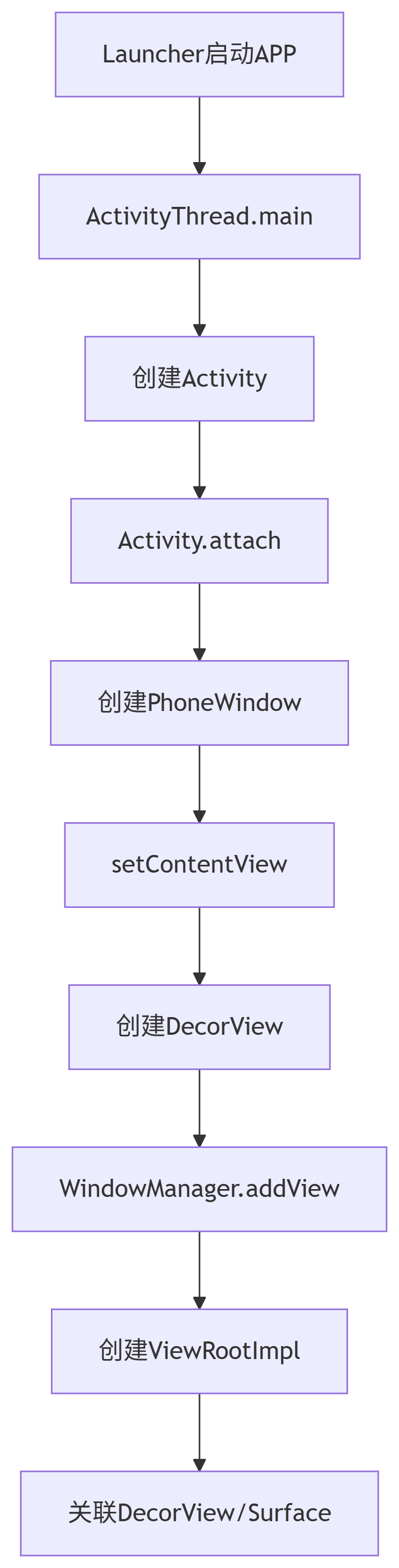
2. ViewRootImpl核心能力
-
成员:
-
mView:持有DecorView,控制视图树。 -
mSurface:绑定BufferQueue,管理绘图内存。 -
mChoreographer:接收VSync驱动绘制。
-
-
首次绘制:
-
ViewRootImpl.setView()→requestLayout()→ 请求VSync。 -
VSync到达 → 执行
performTraversals()(measure/layout/draw)。
-
3. 渲染加速机制
| 方式 | 执行线程 | 实现 | 适用场景 |
|---|---|---|---|
| 软件渲染 | UI线程 | CPU直接绘制到Canvas | 简单视图/兼容模式 |
| 硬件加速 | RenderThread | 构建DisplayList → GPU渲染 | 复杂动画/现代APP |
| SurfaceView | 任意线程 | 独立Surface → 直接提交Buffer | 游戏/视频播放器 |
4. SF合成五部曲
-
预处理 (
preComposition):检查新增图层。 -
重建图层栈 (
rebuildLayerStacks):计算脏区域/Z序。 -
准备HWC (
setUpHWComposer):分配合成方式。 -
执行合成 (
doComposition):-
GPU合成:HWC无法处理的图层。
-
硬件合成:DPU直接合成图层。
-
-
送显 (
postComposition):DRM提交帧 → 等下次硬件VSync显示。
三、VSync同步机制
1. VSync信号流
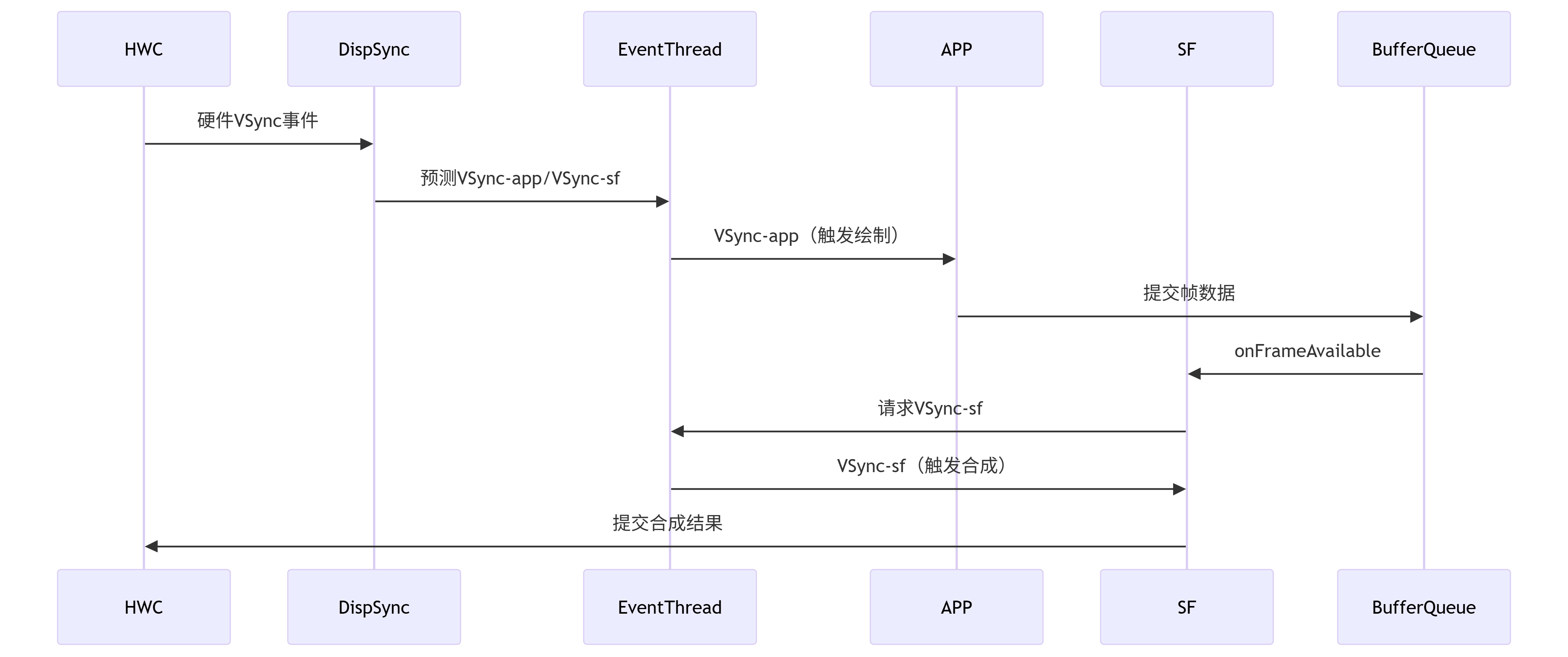
2. 关键优化
-
VSync Offset:错开APP/SF的VSync信号(APP先执行,SF延迟执行),实现流水线处理。
-
同步屏障:VSync到来时阻塞普通消息,优先执行绘制(
ViewRootImpl#scheduleTraversals())。
四、常见问题
Q1: 为什么要有Fence机制?
答:防止多硬件(GPU/DPU)同时写GraphicBuffer导致数据竞争。例如:
-
GPU渲染未完成时,DPU若读取Buffer会显示残缺帧。
-
Fence工作流:DPU消费前等待
acquire_fence(GPU渲染完成信号)。
Q2: SurfaceView为什么不会阻塞UI线程?
答:
-
拥有独立Surface和BufferQueue,渲染在子线程执行。
-
不受主线程VSync约束,通过
unlockCanvasAndPost()直接提交帧。(SurfaceView让应用无需等待VSync信号的到来便可以执行绘制工作,这是它和普通View最大的区别)
Q3: 丢帧的根本原因是什么?
答:任一阶段超时:
-
APP渲染 > 16.6ms(60Hz)
-
SF合成 > 16.6ms
-
Buffer排队(未及时释放FREE Buffer)
Q4: HWC如何提升性能?
答:
-
硬件合成比GPU合成功耗低30%+。
-
减少GPU负载 → 降低发热/提升续航。
Q5: 三重缓冲如何减少卡顿?
答:允许APP在SF消费前一帧时,提前渲染下一帧(VSync周期内可排队2帧),避免等SF释放Buffer。
总结:
Q:Android点击应用图标到画面显示的完整流程。
A:
整个过程分为四个阶段:
-
进程启动与视图创建
-
AMS通知Zygote孵化APP进程,创建ActivityThread。
-
Activity创建PhoneWindow和DecorView,通过WindowManager关联到ViewRootImpl。
-
ViewRootImpl初始化Surface和Choreographer,准备接收VSync信号。
-
-
VSync驱动绘制
-
APP首次调用
requestLayout()请求VSync-app。 -
VSync-app到达 → Choreographer触发
ViewRootImpl#performTraversals()。 -
执行measure/layout/draw:
-
软件渲染:UI线程直接绘制Canvas。
-
硬件加速:构建DisplayList → RenderThread异步执行GPU渲染。
-
-
绘制结束 → Surface提交GraphicBuffer到BufferQueue。
-
-
SurfaceFlinger合成
-
BufferQueue通知SF有帧就绪 → SF请求VSync-sf。
-
VSync-sf到达 → SF执行合成五部曲:
-
预处理检查新图层。
-
重建图层栈(计算脏区域/Z序)。
-
HWC分配合成方式(硬件/GPU)。
-
执行合成并提交结果到显示框架。
-
-
HWC等待下次硬件VSync切换帧。
-
-
显示
-
显示器在硬件VSync信号到来时切换帧缓冲区,用户看到画面。
-
参考资料:https://juejin.cn/post/7132777622487957517#heading-43