【性能测试】---测试工具篇
目录
1、安装并启动jemeter
2、重点组件
2.1、线程组:
2.2、HTTP取样器编辑
2.3、查看结果树
2.4、HTTP请求默认值
2.5、HTTP信息头管理器
2.6、JSON提取器
2.7、JSON断言
2.8、同步定时器
2.9、CSV数据文件设置
2.10、HTTP Cookie管理器
3、测试报告
4、性能分析
通过三大指标来分析性能问题:4.1、响应时间
4.2、错误率(可靠率)
4.3、吞吐量
1、安装并启动jemeter
法一:

法二:将文件路径复制一下,配置环境变量,打开cmd,输入jmeter就可以打开
2、重点组件
2.1、线程组:
添加一个线程组去管理所有的线程。
开发者工具:network表示监视网络
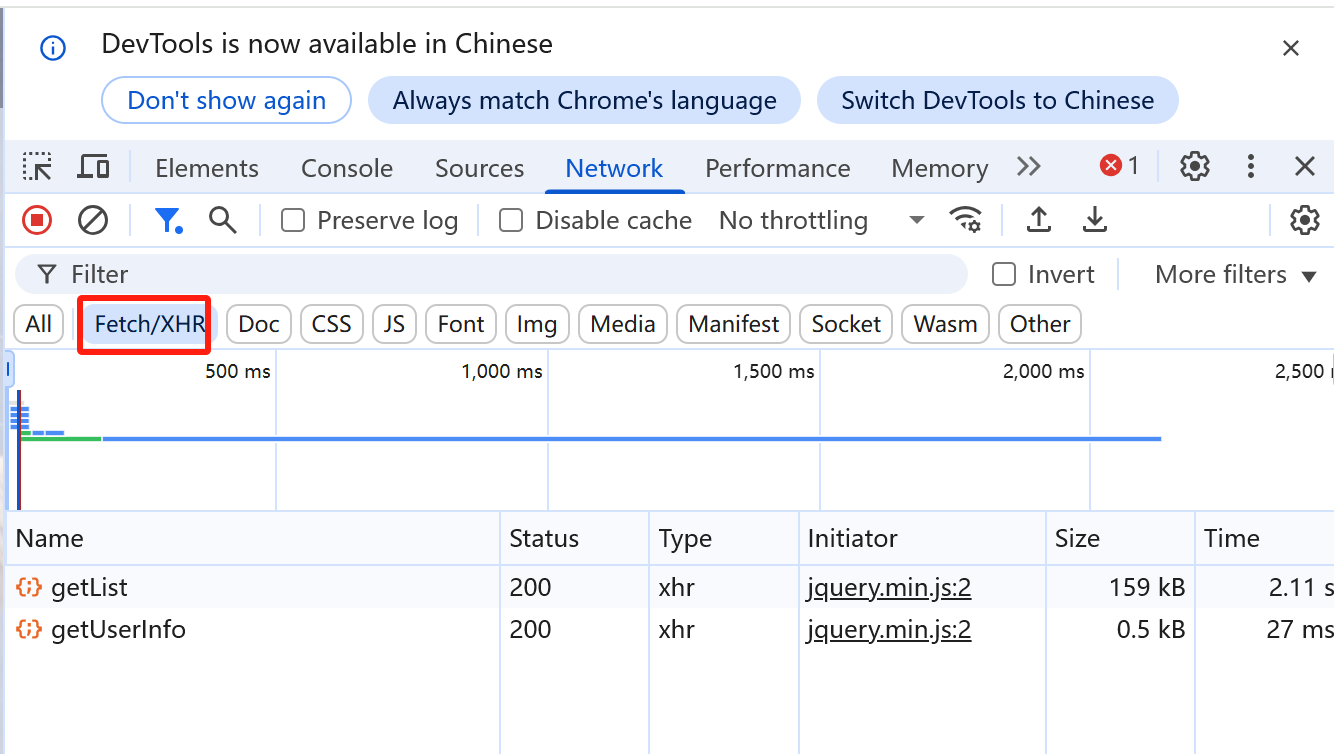
点击XHR筛选出一些后端的接口
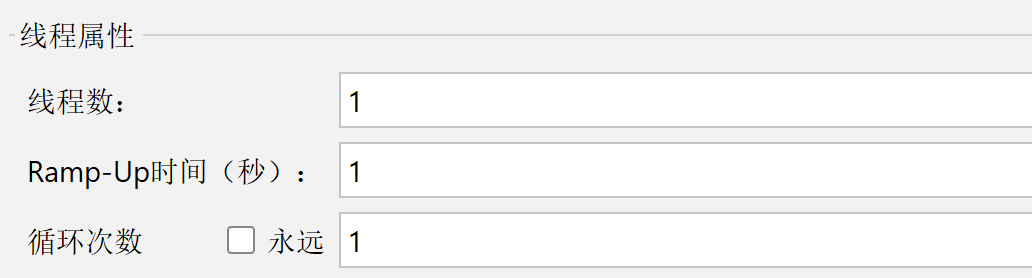
线程数:虚拟用户数/并发数
Ramp-Up:性能测试运行的时间,上面的线程数运行完的时间。
循环次数:如果线程数为10,循环次数为2,那么总共就发送了20次请求
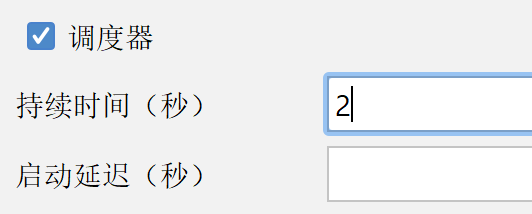
如果选择了永远,就必须要配置调度器,否则性能测试就是一个死循环。
如果配置了调度器,配置了持续时间,就会在2s内不断发送请求
2.2、HTTP取样器
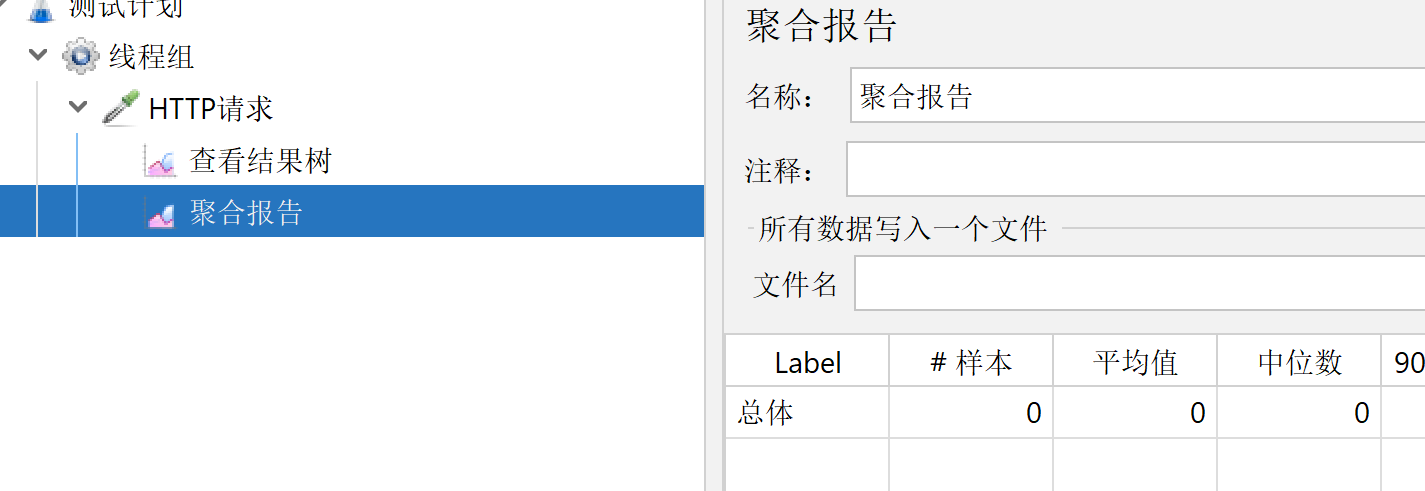
我们就可以在聚合报告中查看在两秒内一个发送了多少次请求
2.3、查看结果树
出现错误时:
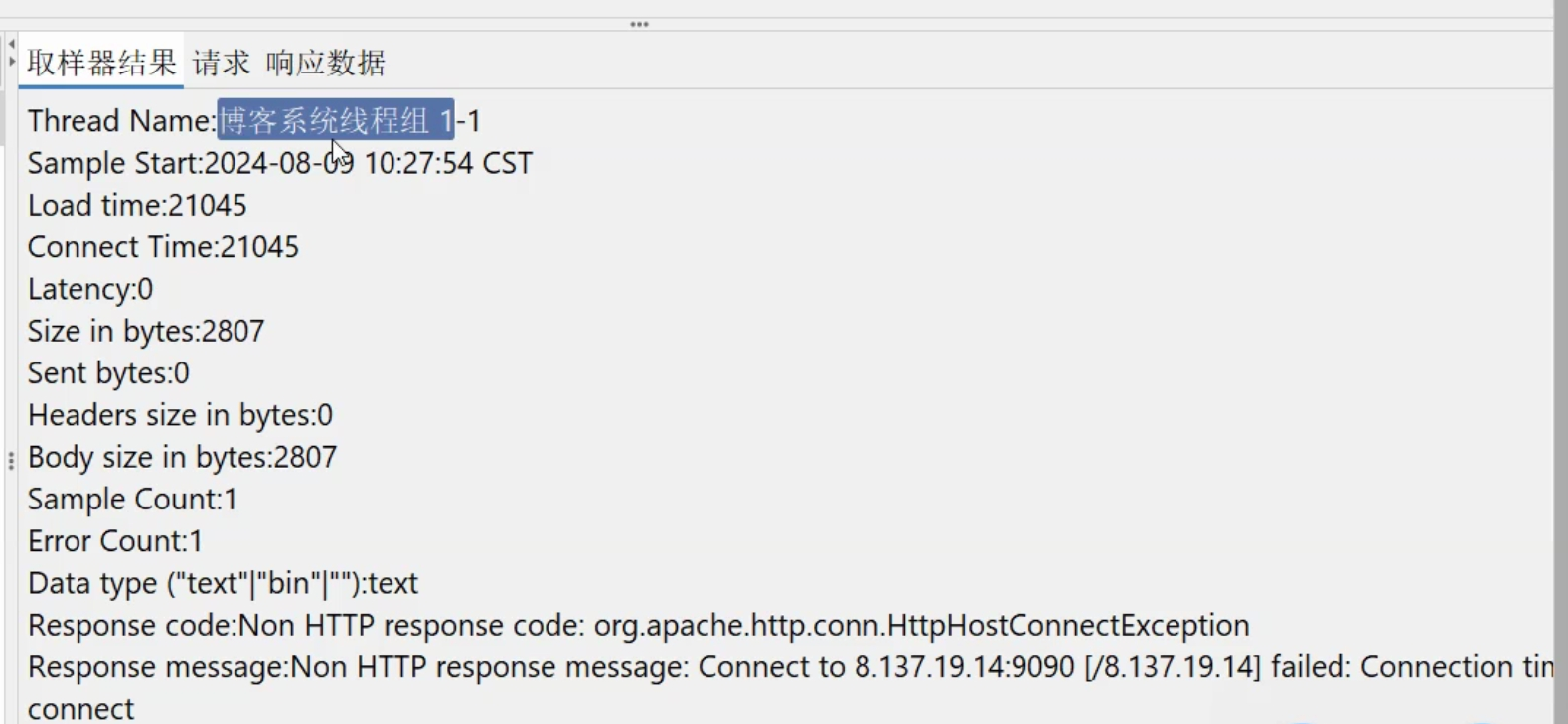
我们应该重点关注Load time响应时间和Response code状态码
2.4、HTTP请求默认值
如果是在同一个web系统那么他的每个界面的协议、ip、端口号、内容编码(utf-8)都是一样的,因此我们就可以设置HTTP请求默认值,这样就不用每次都填写了。
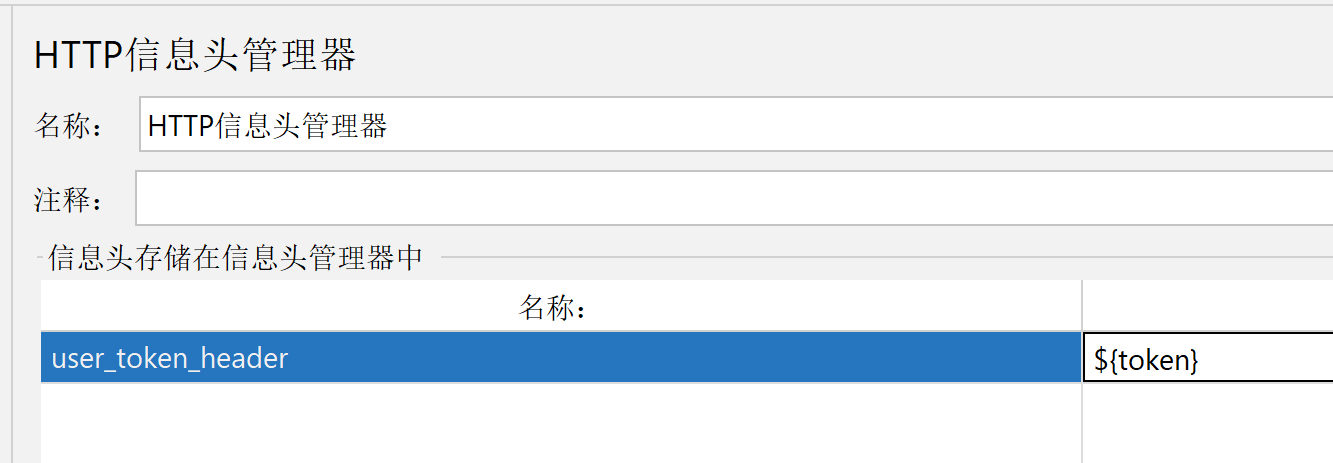
2.5、HTTP信息头管理器
列表页要添加请求信息,否则就会报错
添加HTTP管理头,只作用在列表页

这样运行结果正确
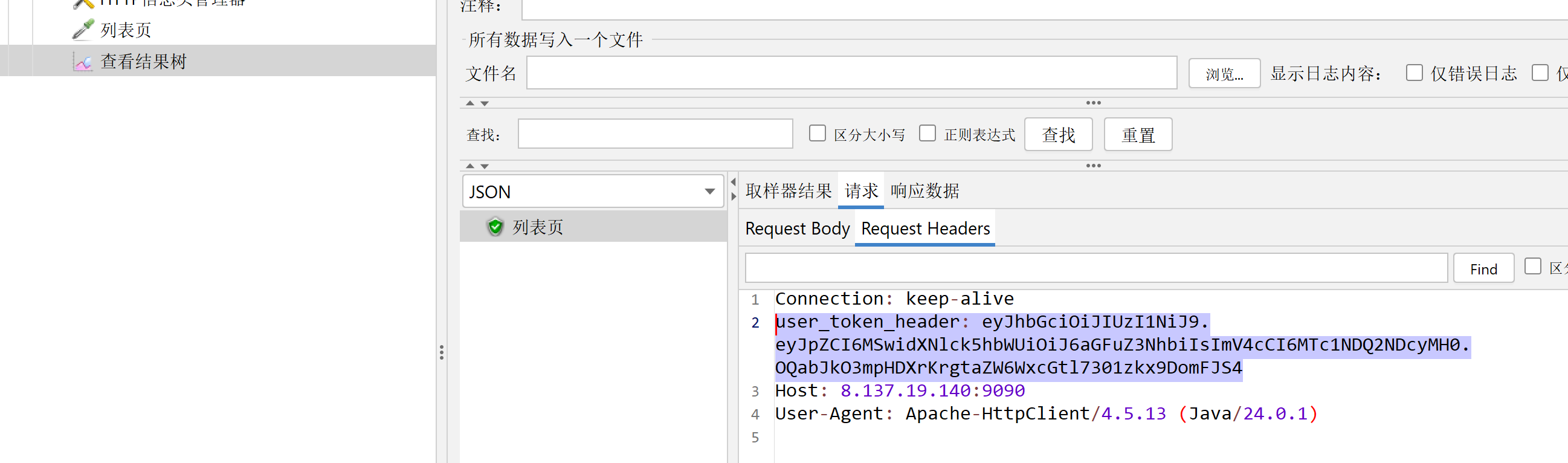
下图是开发者工具中列表页的User_token_header 需要添加这个名称和值 到HTTP信息头管理器才可以请求成功
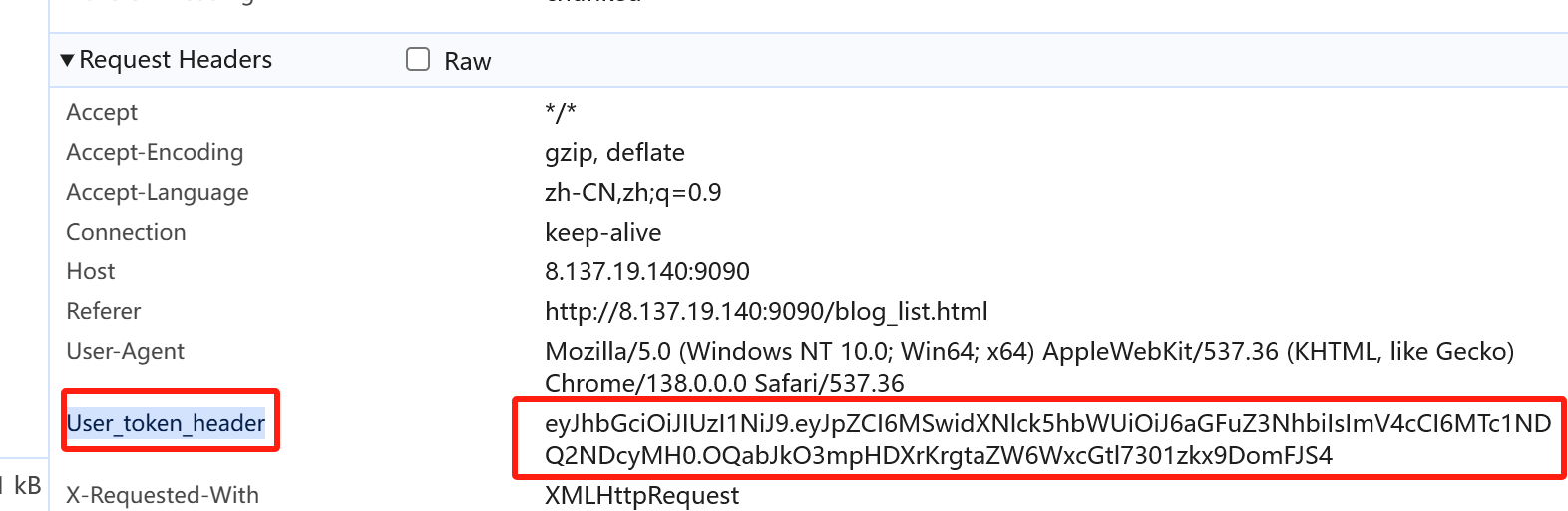
因为我们是给了一个固定的值,它会过期,所以我们就必须要使用JSON提取器来解决问题
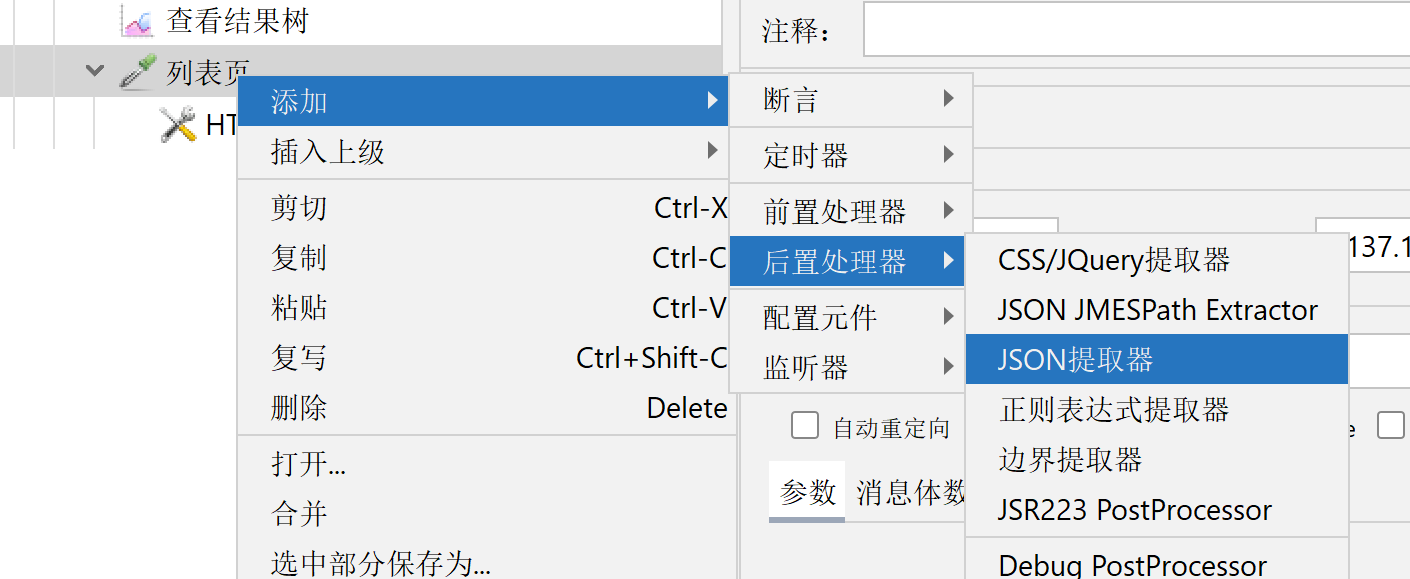
2.6、JSON提取器
接口响应成功,通过提取返回值对应字段,可用于其他接口的参数配置
我们可以用登录页的data值来配置别表页
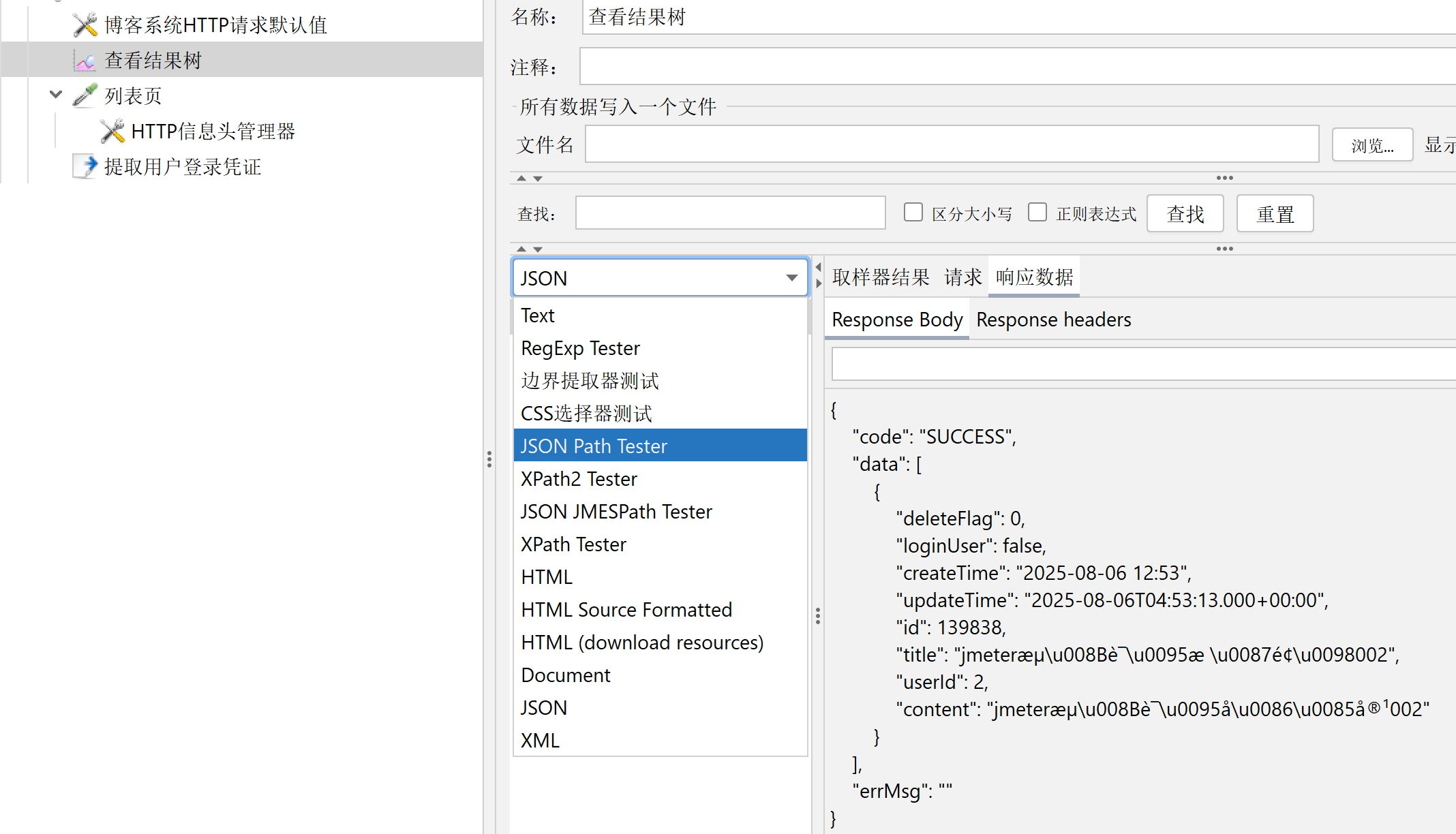
可以对表达式进行测试,看写的对不对:在查看结果树中,将响应数据的格式改为JSON Path Tester,在JSON Path Expression中输入表达式,可以测试提取表达式是否正确
补充知识:如何对JSON进行提取

[{"postTime": "2024-04-18 05:20:16","title": "ddddd","blogId": 13,"userId": 3,"content": "# 在这⾥写下⼀篇博客\r\ndddd"},{"postTime": "2022-10-22 02:38:21","title": "同学,请问你今天学习了吗","blogId": 12,"userId": 3,"content": "今天是2022年10⽉22⽇17:42分,为了能够早⽇将最新版本的测试课件呈现给同学们,我已经开始奋..."}]获取相应中的所有blogId元素:$..blogId获取第⼀个blogId元素:$.[0]blogId
测试提取正确之后,就将值写到JSON提取器中。
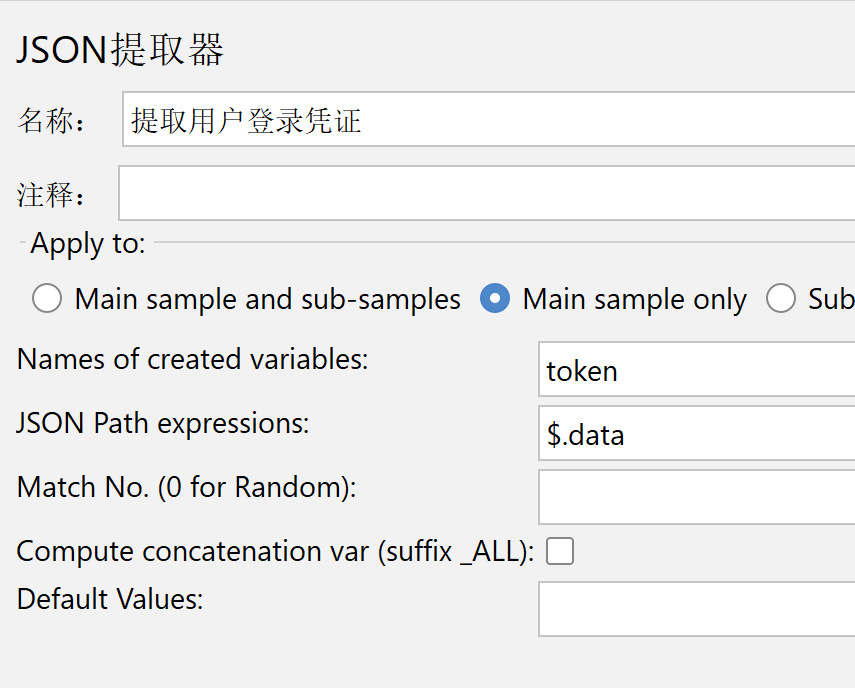
书写格式:${变量名}
那为什么要添加这个呢???
HTTP协议本身是无状态的,服务器需要通过会话标识来识别用户身份。
用户登录之后,服务器返回一个认证凭证,后续请求必须携带该凭证(如访问列表页),否则服务器会返回401/403未授权
浏览器在登录后会自动管理Cookie/Token,并在后续请求中自动附加这些信息。
JMeter需要手动实现这一过程,否则列表页请求会被视为“未登录用户”的请求。
JMeter如何实现?
通过 提取器(正则/JSON) + HTTP信息头管理器 或 Cookie管理器 动态传递凭证。
若多个接口中都有符合条件JSON字段,则会发生覆盖
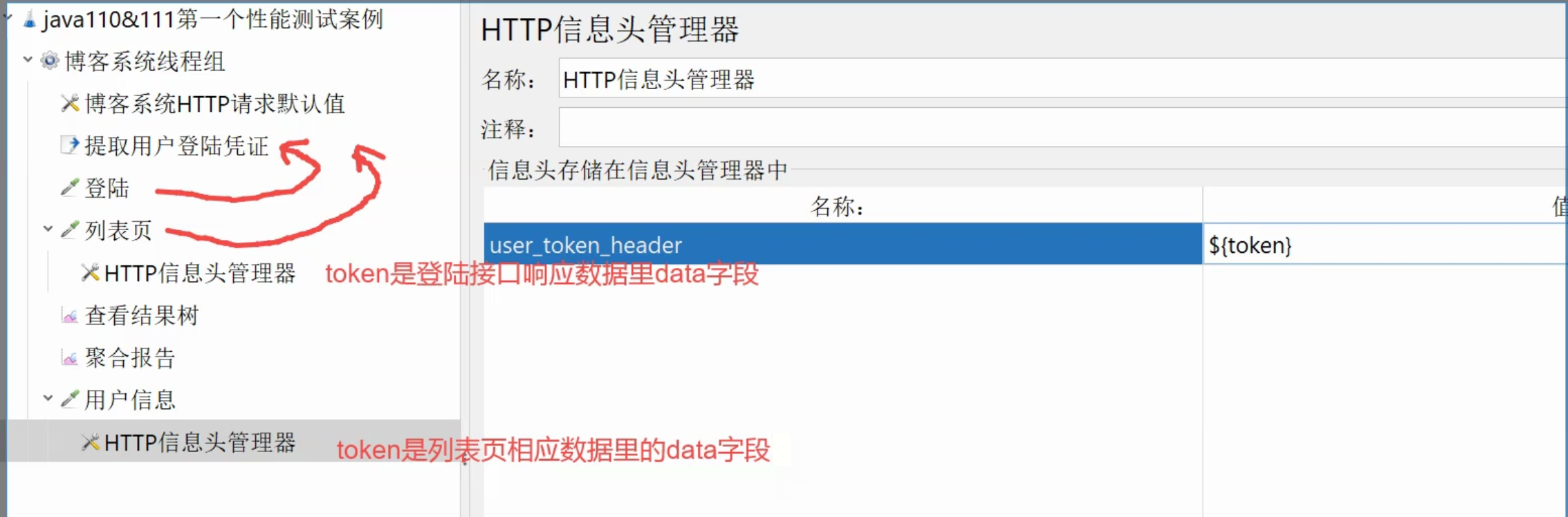
要将提取用户凭证(JSON提取器)放在登录的下面,然后只要一个HTTP信息头管理器
token只取登录接口返回值里的data字段。然后直接保存在HTTP信息头管理器
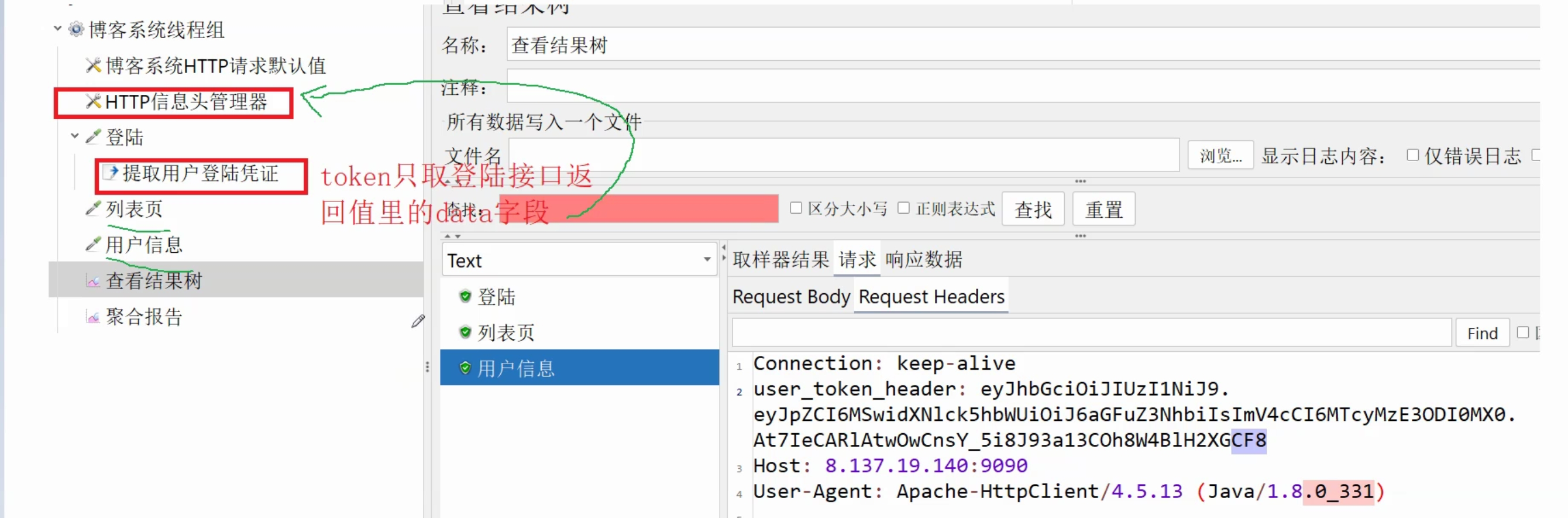
不能只看通过了、和响应时间、还有状态码没问题就代表没有问题,还要查看响应体,要返回博客的标题和博客的内容
当有两百个详情页接口,每个接口都要用到写死的id值,而这个id值后续可能需要修改----最好的方式就是用批量修改的方式
补充:
为什么postman可以请求成功,但是放到jmeter之后就请求失败了?
我们可以将把开发者工具上的数据和jmeter的数据进行对比进行对比。在postman上验证一下是不是这个问题,但是修改的时候要注意作用域问题。
2.7、JSON断言

举例:
1、检查字段是否存在
1)JOSN Path exists:这个值是点击查看结果树,将格式选为JSON Path Tester 然后在输入框中输入JSON提取的书写格式,对JSON进行提取
2)不选中同时验证字段值
3)不选中选使用正则匹配
4)不输入预期值
如果
userId存在,断言通过;否则失败2、验证字段值
1)JOSN Path exists:这个值是点击查看结果树,将格式选为JSON Path Tester 然后在输入框中输入JSON提取的书写格式,对JSON进行提取:$.code
2)选中同时验证字段值
3)不选中使用正则匹配
4)输入预期值:200
如果
code等于200,断言通过;否则失败。3、使用正则表达式匹配
1)JOSN Path exists:这个值是点击查看结果树,将格式选为JSON Path Tester 然后在输入框中输入JSON提取的书写格式,对JSON进行提取:$.email
2)选中同时验证字段值
3)选中使用正则匹配
4)输入预期值:
.+@.+\\..+(匹配邮箱格式)如果



前后JSON的关系

通过变量提取+断言机制
2.8、同步定时器
我们要实现线程并发执行就必须添加同步定时器
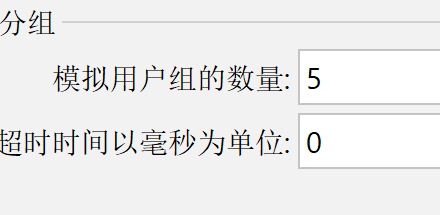
如果没有打开循环,那么最好配置和开始设定的线程数相同的数字,大于就会一直等,小于就小于就会导致后面的线程数量达不到就不运行。打开循环之后是可以的。

添加了同步定时器之后,线程是在都准备好之后才开始的,就可以做到并发
2.9、CSV数据文件设置
为了模拟更真实的登录环境,我们需要提供更多的用户和密码来实现登录操作
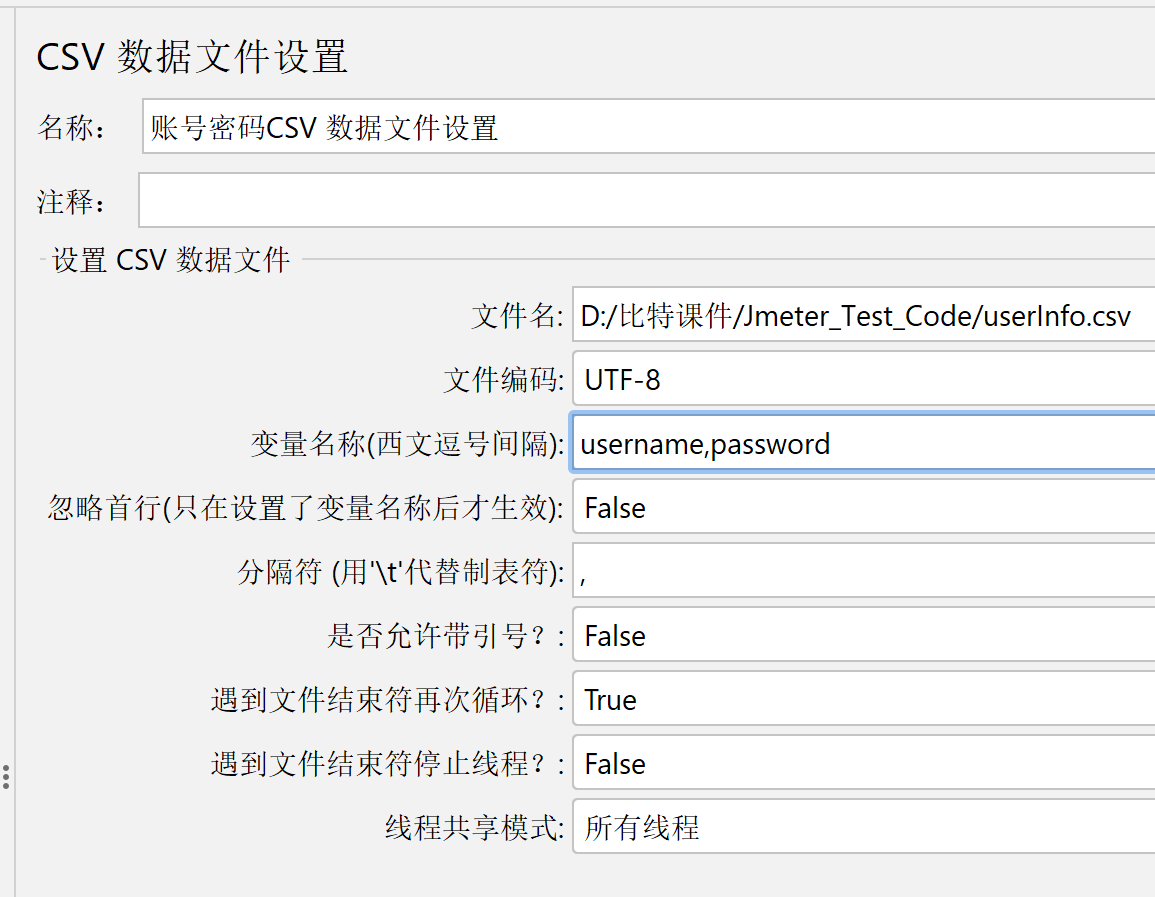
在当前文件的相同文件夹里面添加一个execl表格,里面写用户名和密码。遇到文件结束符再次循环选True,就会循环的去模拟登录。
2.10、HTTP Cookie管理器
HTTP Cookie管理器像Web浏览器⼀样存储和发送Cookie。如果HTTP请求并且响应包含cookie,则 Cookie管理器会⾃动存储该cookie,并将其⽤于将来对该特定⽹站的所有请求。每个JMeter线程都有 ⾃⼰的"cookie存储区"。因此,正在测试使⽤cookie存储会话信息的⽹站,则每个JMeter线程都将拥 有⾃⼰的会话。此类Cookie不会显⽰在Cookie管理器显⽰屏上,可以使⽤"查看结果树监听器"查看。缓存配置可选择standard(标准)或compatibility(兼容的),当然也可以⼿⼯添加⼀些cookie.
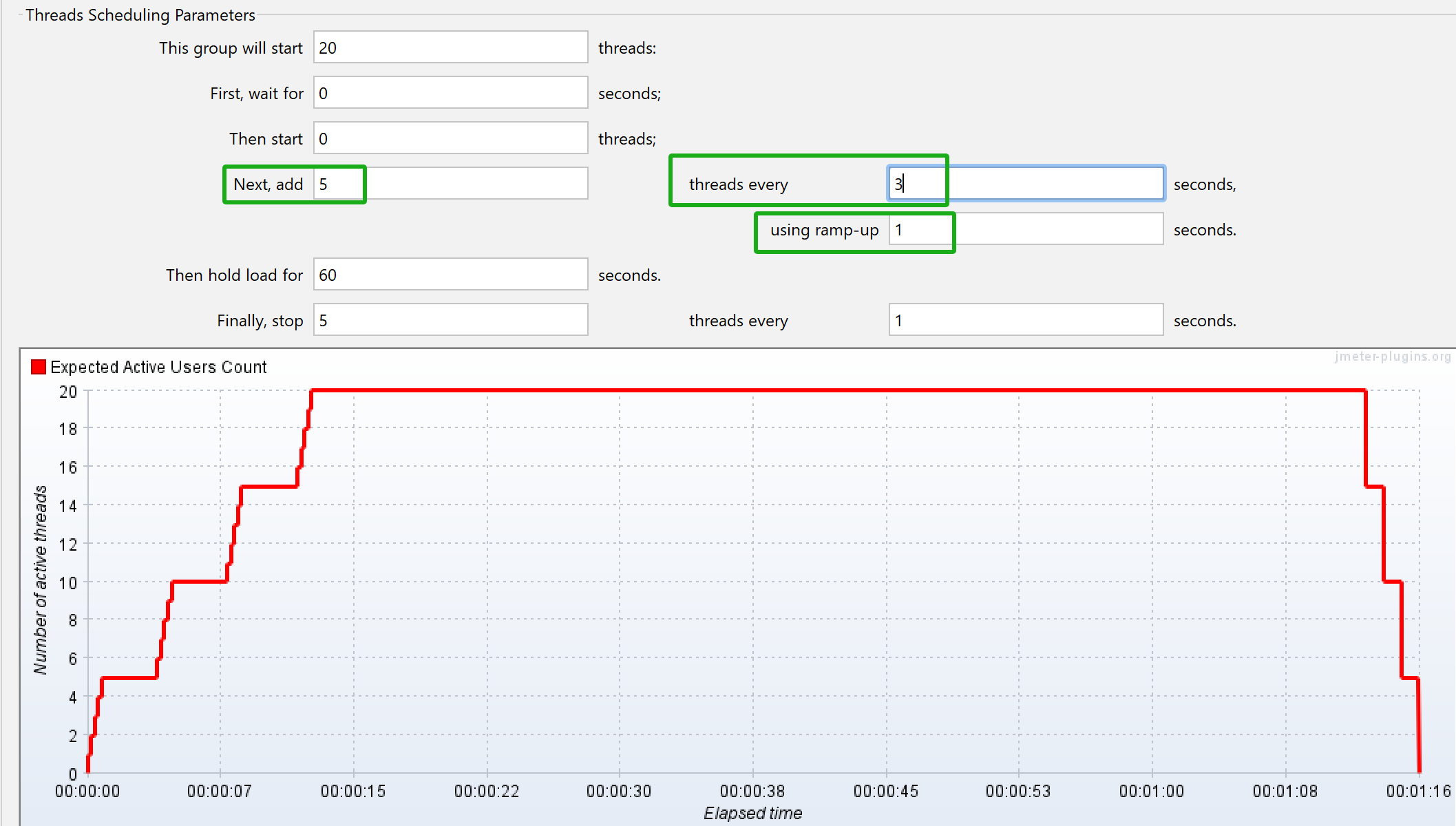
每次启动5个线程,隔3s就启动五个线程,这5个线程在1s内启动完成
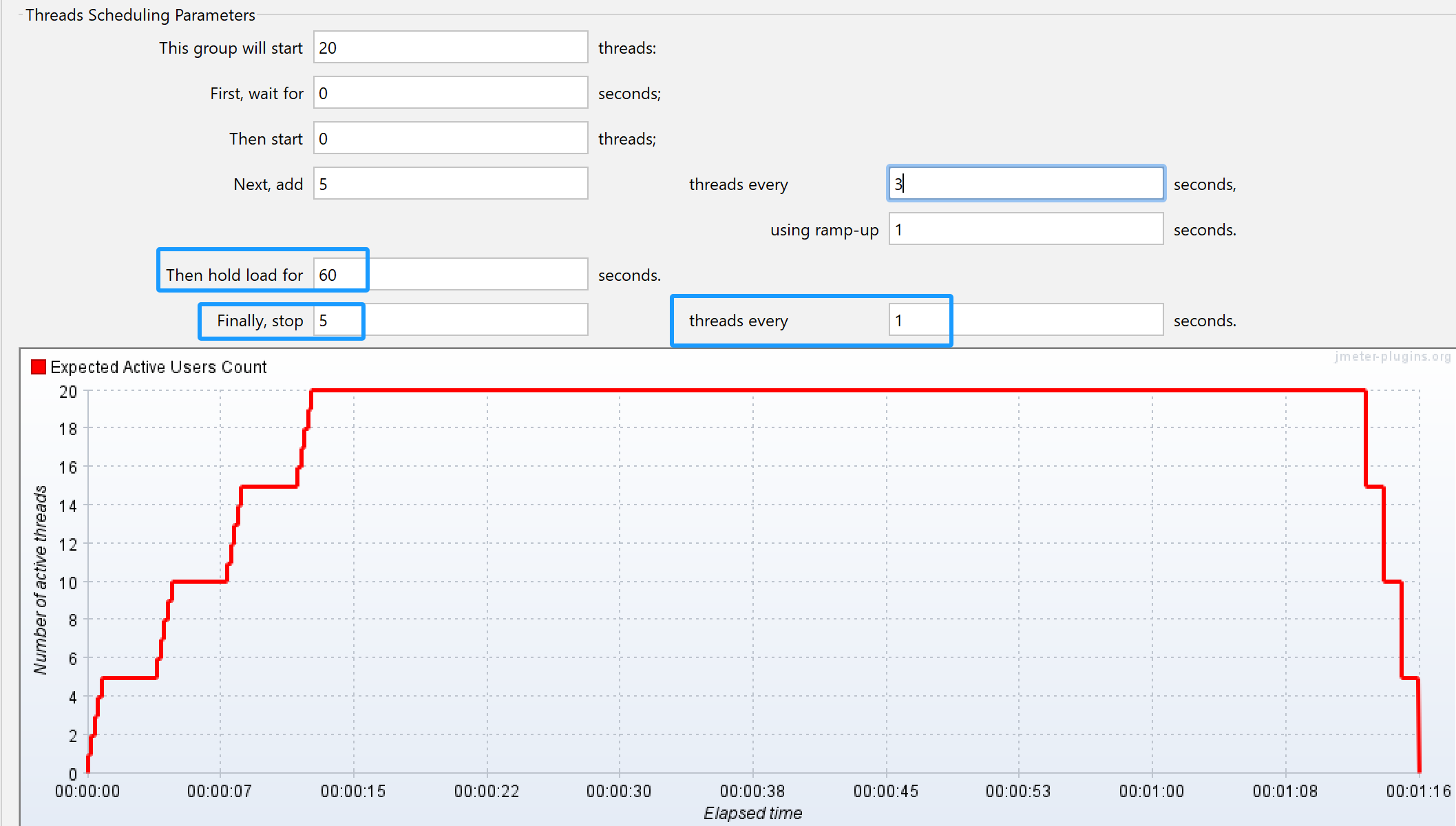
让线程持续运行60s,最后每隔1s结束5个线程。
补充:查看结果树一般在调试阶段会用到,在运行的时候的一般不用
3、测试报告
当性能测试完毕之后,我们要出具测试报告
打开cmd
可以先进入存放当前测试文件的同级目录
输入命令 jmeter -n -t 测试的文件(第一个测试案例.jmx) -l first.jtl -e -o ./first/.(先创建一个文件夹)
4、性能分析
通过三大指标来分析性能问题:
4.1、响应时间
4.2、错误率(可靠率)
错误率高的原因:
4.3、吞吐量
吞吐量越大,性能越好;吞吐量相对稳定或者变低,可能系统达到了性能瓶颈
吞吐量变化规律:
波动很大:代表系统不稳定
慢慢变高再趋于稳定:和并发量强相关。如果并发量小于吞吐量,慢慢增大并发量,吞吐量也会随之增加
慢慢变低,并发量也减少了:说明性能测试要结束了,并发减少;也可能是系统变得卡顿,从而导致响应时间变慢,导致单个线程发起的并发量变少。