【大模型系列】gpt-oss系列模型初探
1. 背景
前一周,大模型领域很热闹,Qwen-235B和GLM-4.5陆续推出,模型能力都非常不错,GLM-4.5更是霸榜开源大模型第一。
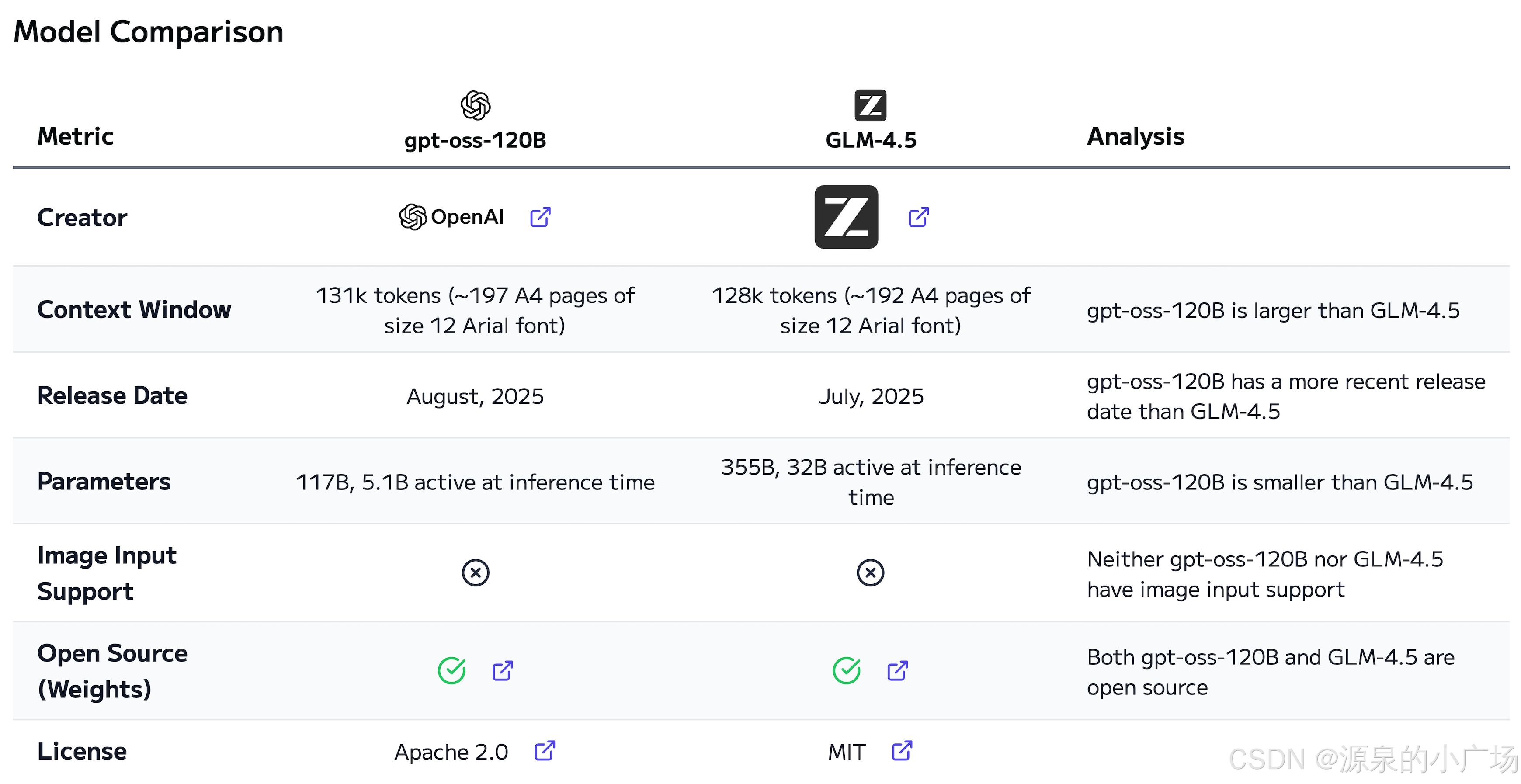
2025年8月5日Open AI也坐不住了,开源了gpt-oss系列模型【1】。他们发布了 gpt-oss-120b 和 gpt-oss-20b——两款性能不错的开源轻量级语言模型,能够在低成本环境下实现强大的实际应用表现。gpt-oss-120B vs GLM-4.5: Model Comparison做了gpt-120b与glm-4.5的对比。
现在的大模型,经过DeepSeek浪潮之后,不约而同都选择了MOE架构。

这两款模型,在同等规模的开源模型中展现出更优的推理能力,具备出色的工具使用功能,并针对消费级硬件上的高效部署进行了优化。其训练融合了强化学习技术与受 OpenAI 最先进内部模型(包括 o3 及其他前沿系统)启发的方法。
据报告,gpt-oss-120b 在核心推理基准测试中的表现接近 OpenAI 的 o4-mini 模型,同时可在单个 80GB GPU 上高效运行;而 gpt-oss-20b 在常见基准测试中与 OpenAI 的 o3-mini 模型水平相当,且仅需 16GB 内存即可在边缘设备上运行,使其成为设备端应用、本地推理或低资源快速迭代的理想选择。两款模型在工具调用、少样本函数执行、思维链推理(CoT)以及 HealthBench 测试中均表现强劲,部分结果甚至优于 OpenAI o1 和 GPT-4o 等专有模型。
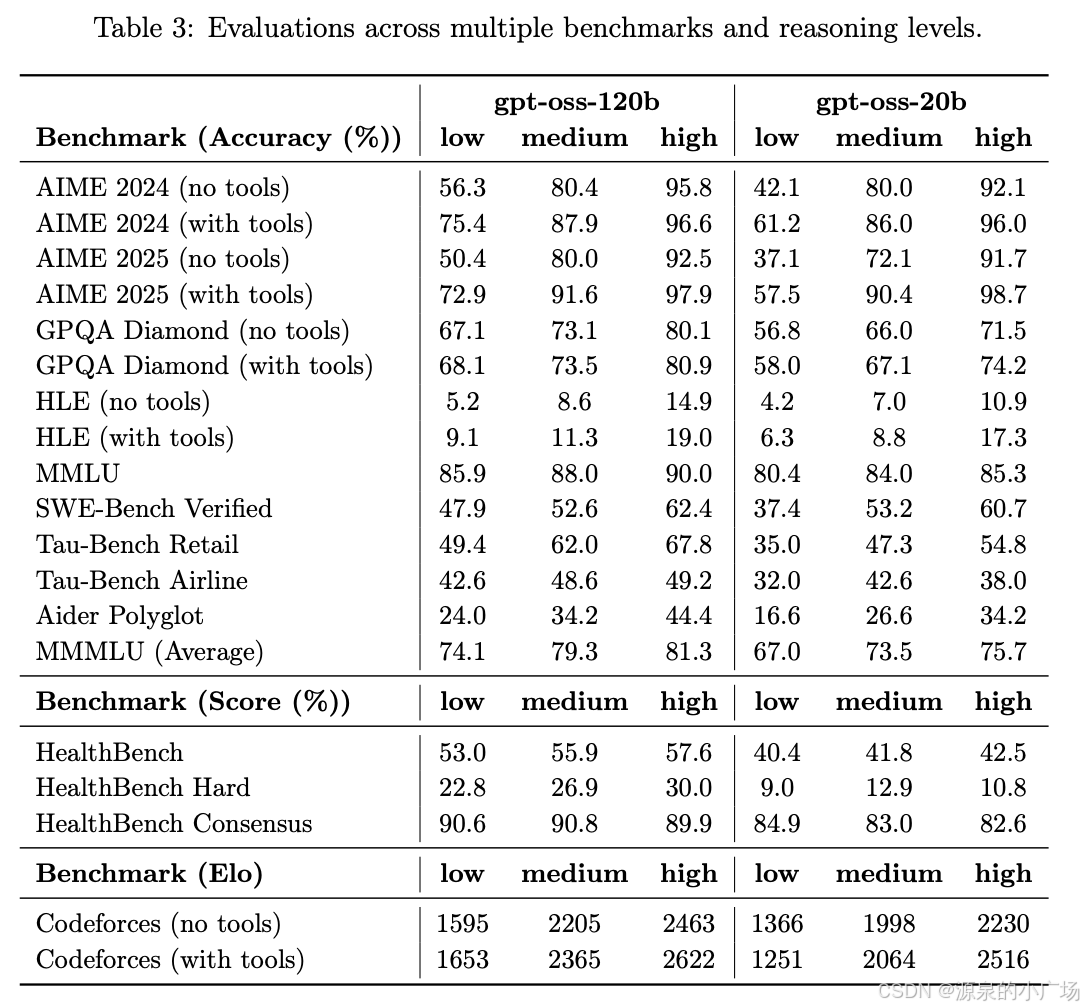
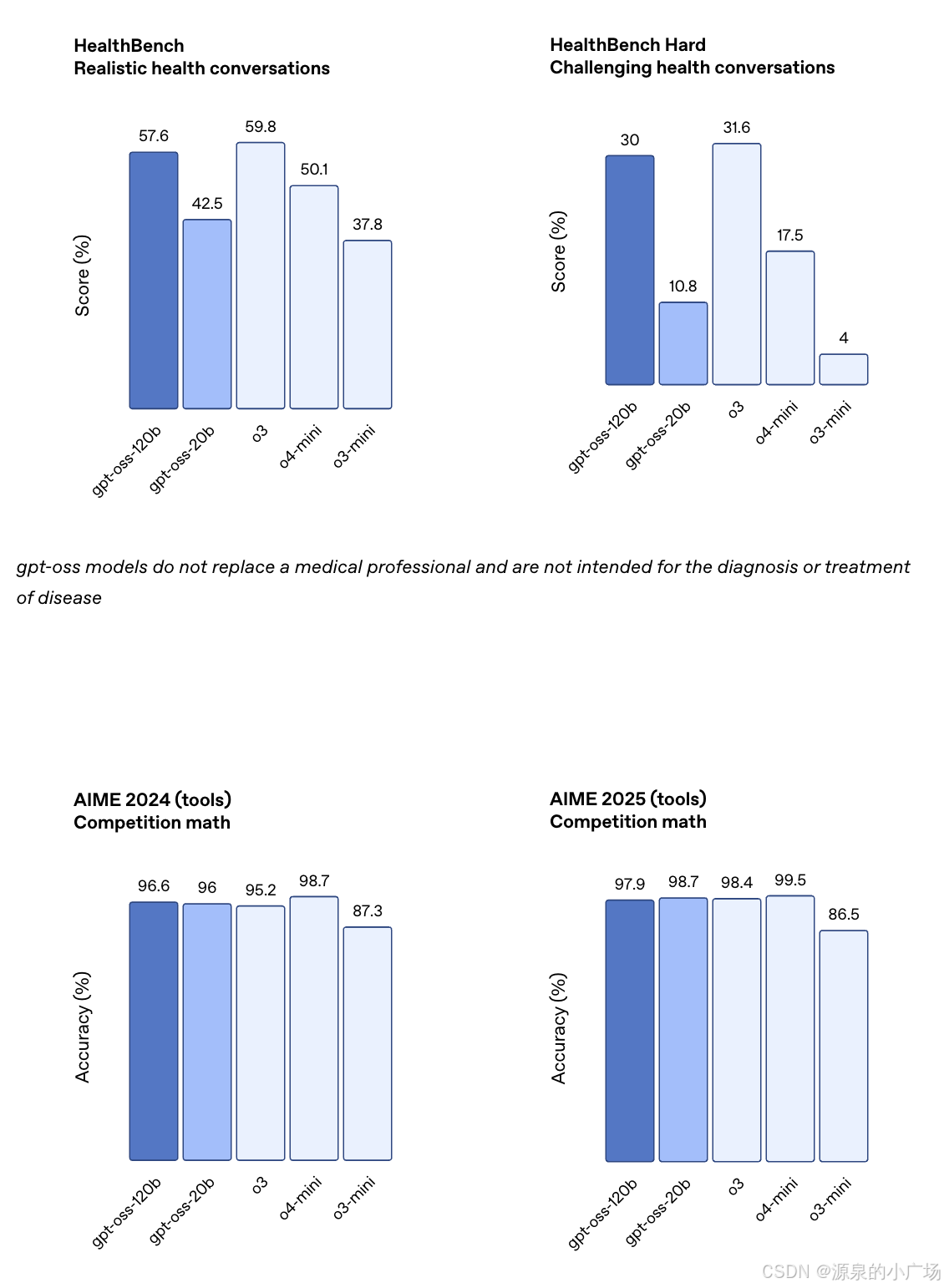
model card【2】给出了两个模型在不同推理水平上的准确性差异。
这些模型与其回复 API兼容,专为智能体工作流设计,具备出色的指令执行能力、工具集成能力(如网页搜索和 Python 代码执行)以及灵活的推理能力,可根据任务需求动态调整推理强度,尤其适用于对延迟敏感或无需深度推理的场景。模型支持完整的思维链输出和结构化输出,并允许用户进行深度定制。
安全被视作模型发布的核心原则,尤其是在开源背景下更为重要。除常规的安全训练与评估外,他们还引入了额外的评估层级:通过测试一个经过对抗性微调的 gpt-oss-120b 版本,在其《防范准备框架》下验证模型的安全性。结果显示,gpt-oss 系列模型在内部安全基准上的表现与其最先进的闭源模型相当,为开发者提供了与近期专有模型同等的安全保障。
2. 模型介绍
他们介绍了 gpt-oss 模型的预训练方法与模型架构。这些模型采用了其最先进的预训练和后训练技术,重点优化了推理能力、运行效率以及在多种部署环境下的实用性。尽管他们此前已开源了如 Whisper 和 CLIP 等模型,但 gpt-oss 系列是自 GPT‑2以来首次发布的开放大型语言模型。
每个 gpt-oss 模型均基于 Transformer 架构,并引入了专家混合机制(MoE),以降低处理输入时所需的激活参数数量,从而提升计算效率。其中,gpt-oss-120b 在每个令牌处理过程中激活 51 亿参数,总参数量达 1,170 亿;gpt-oss-20b 则激活 36 亿参数,总参数量为 210 亿。模型采用了交替的密集注意力与局部带状稀疏注意力结构,设计上与 GPT‑3 相似。为进一步提升推理速度和内存使用效率,模型还集成了分组多查询注意力机制,分组大小为 8。
在位置编码方面,他们采用了旋转位置嵌入(RoPE),并原生支持最长 128k 的上下文长度,适用于长文本处理任务。模型的训练基于一个高质量、以英文为主的纯文本数据集,重点覆盖 STEM、编程以及通用知识领域。在数据令牌化过程中,使用了名为 ‘o200k_harmony’ 的分词器,该分词器是 OpenAI o4-mini 和 GPT‑4o 所用分词器的超集,他们也于同日将其开源。
gpt-oss 采用了与 OpenAI o4-mini 类似的后训练流程,包括监督式微调阶段以及高计算量的强化学习阶段。其主要目标是使模型符合《OpenAI 模型规范》,并具备在生成回答前主动应用思维链(CoT)推理和工具使用的能力。通过借鉴其最先进的专有推理模型所使用的技术,这些开源模型在完成训练后展现出优异的综合性能。
与 OpenAI o 系列推理模型在 API 中的实现方式类似,gpt-oss-120b 和 gpt-oss-20b 支持三种可调节的推理强度——低、中、高,允许在响应延迟与推理质量之间进行灵活权衡。开发者可通过在系统消息中添加简短指令,轻松设定所需的推理难度。
3. 模型评测
在评估方面,他们对 gpt-oss-120b 和 gpt-oss-20b 在多个标准学术基准上进行了测试,涵盖编程、竞赛数学、医疗问答以及智能体工具使用能力,并与 OpenAI 的多个推理模型(包括 o3、o3-mini 和 o4-mini)进行了对比。
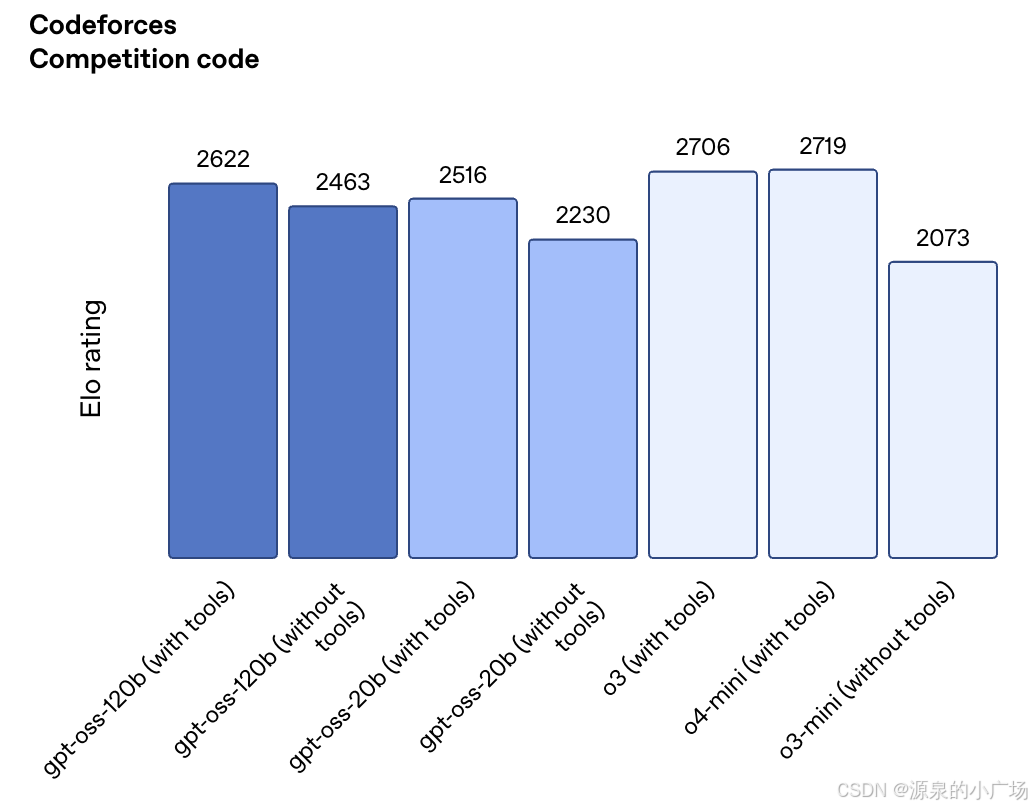
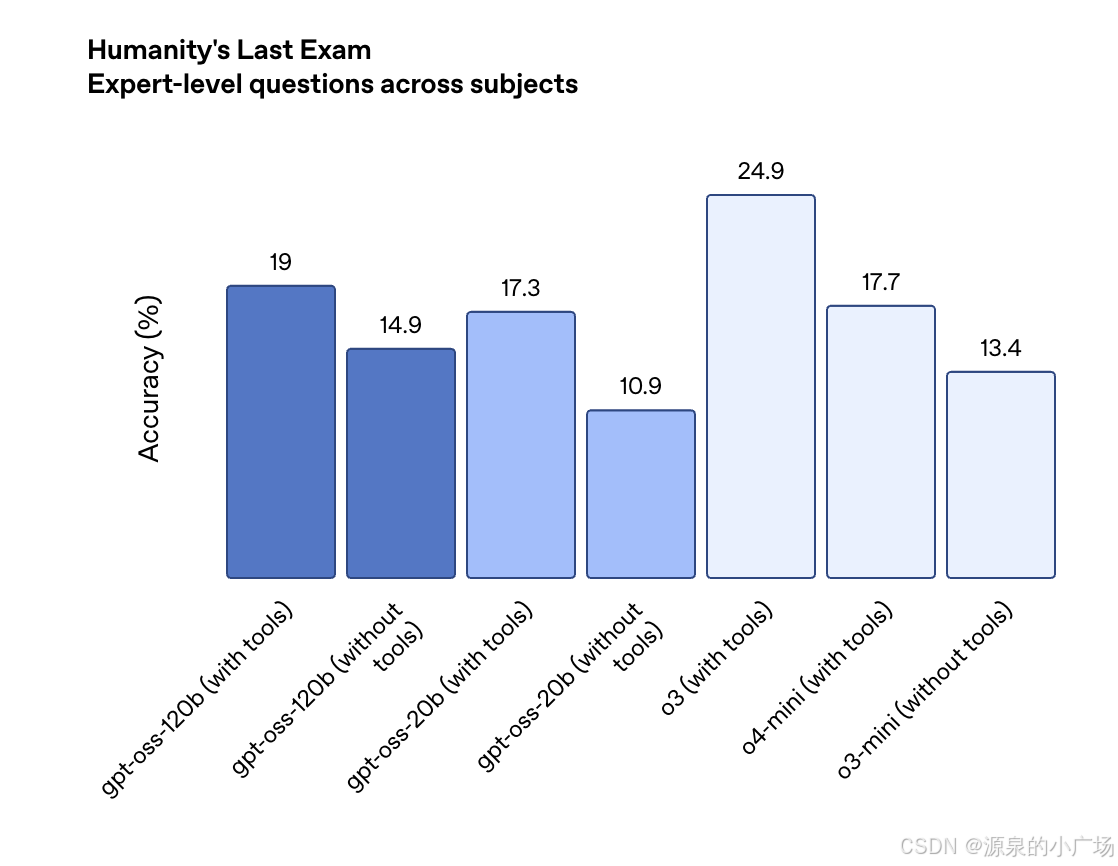
评估结果显示,gpt-oss-120b 在竞赛编程(Codeforces)、通用知识问答(MMLU 和 HLE)以及工具调用能力(TauBench)方面优于 o3-mini,表现与 o4-mini 相当甚至更优。此外,它在健康领域任务(HealthBench)和竞赛数学(AIME 2024 与 2025)上的表现也超过了 o4-mini。尽管 gpt-oss-20b 规模较小,但在相同测试中仍达到了与 o3-mini 相当或更优的水平,尤其在竞赛数学和医疗任务中表现突出。
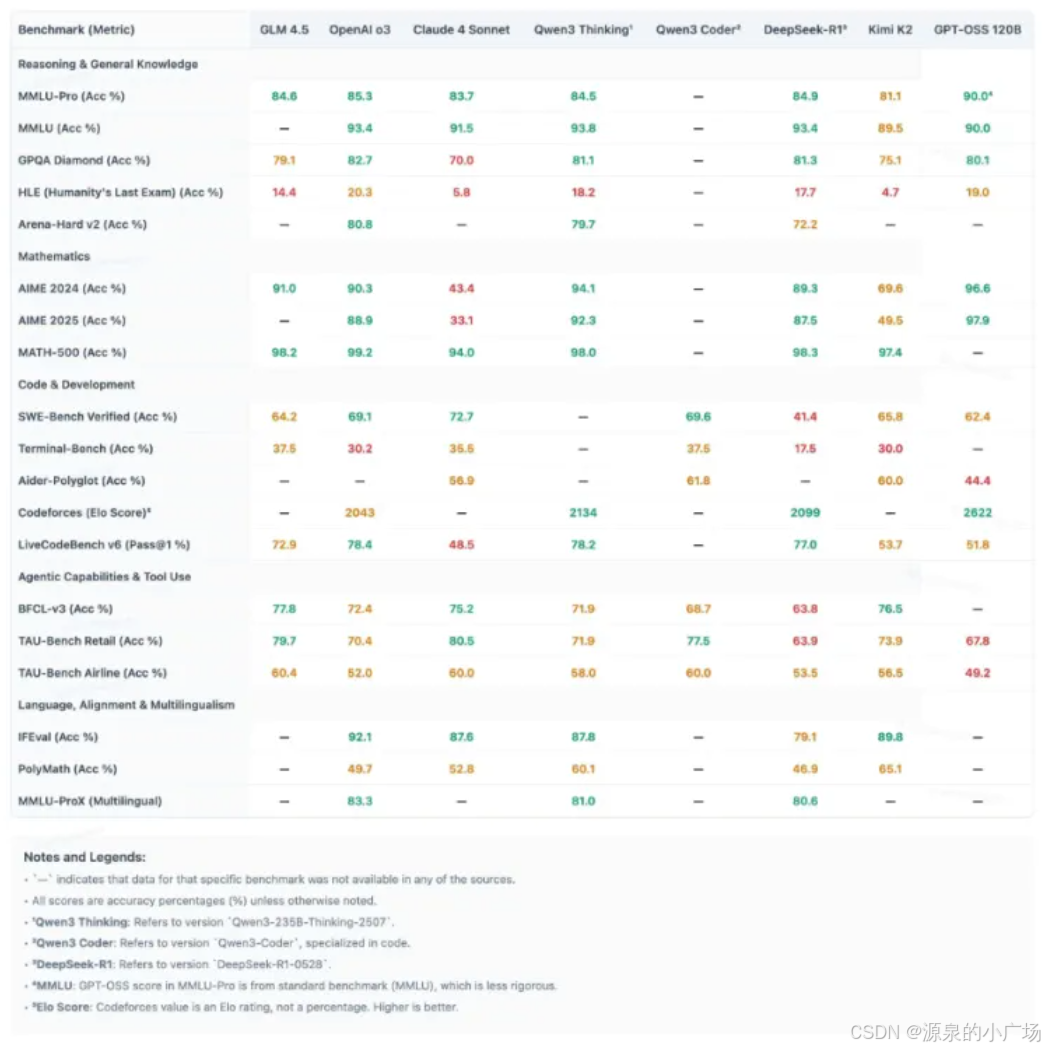
还有一份更详细的但比较模糊的对比报告,哈哈,先让子弹飞一会【3】。
4. 模型试用
不得不说,激活参数只有5.1B的时候,性能是杠杠的,推理速度非常快!可以在gpt-oss playground【4】进行试用。
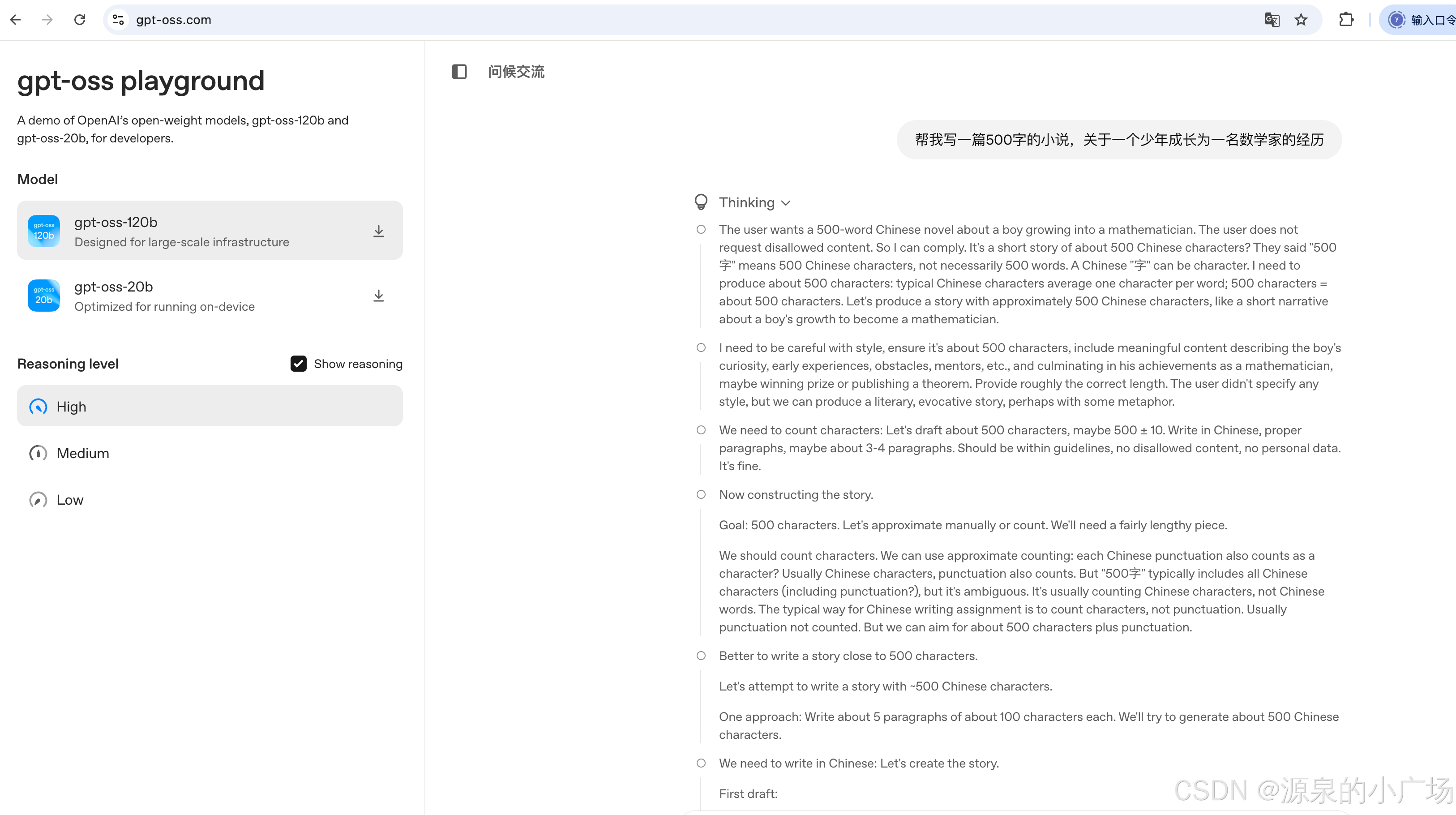 说实话,推理链中出现一些奇怪的描述,还挺有意思:
说实话,推理链中出现一些奇怪的描述,还挺有意思:



5. 参考材料
【1】https://huggingface.co/blog/welcome-openai-gpt-oss
【2】gpt-oss model card
【3】gpt-oss from 赛博禅心
【4】gpt-oss