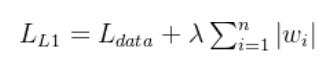机器学习概述
机器学习组成:数据、模型(机器学习算法:逻辑回归、最大熵模型、k-近邻、决策树、朴素贝叶斯、支持向量机、降维、聚类、深度学习)、性能度量准则
数据:通常需要进行预处理
模型:从机器学习模型中选择一个来对数据建模
性能度量准则:用于指导机器学习模型进行模型参数的求解,参数求解也就是训练。训练模型需要对大量参数进行反复的调整也叫做调参。在训练之前就已经设置好的参数就是超参数。
根据预测数据输出的连续性分为(分类、回归)。分类问题以离散随机变量或者离散随机变量概率分布作为输出,回归问题以连续输出作为预测输出。
在某些情况回归分类问题可以相互转换。比如估计人的年龄问题,可以把年龄估计问题看作0-100的回归,也可以量化为101个年龄类别的分类。
监督学习:样本包含标签的机器学习,将标签作为监督信息最小化损失函数,通过梯度下降或拟牛顿进行参数的调整
无监督学习:从没有标注的数据中挖掘信息,比如:降维、聚类。比如:根据用户特征然后对用户进行归类,实现精准推送
半监督学习:有部分数据有标签
根据机器学习模型是否可用于生成新的数据,分为生成模型、判别模型。
生成模型:从训练集中学习输入和输出的联合概率分布,对于新给定的样本,计算X与不同标记之间的联合概率分布,最大概率作为预测值。
判别模型:一个条件概率分布,及后验概率分布。
过拟合:在训练集效果好,测试集效果差
欠拟合:训练集、测试集效果都差
正则化:正则化一般作为损失函数的一部分被加入到原来的基于数据的损失函数中。