保姆级教程:从0手写RAG智能问答系统,接入Qwen大模型|Python实战
在大模型落地的众多路径中,RAG(检索增强生成)是几乎“最值得掌握”的一项技术。它将知识库与大模型结合,让模型不仅“知道”,还能“答得准、说得清”。
在前两期课程中,我们基于Dify平台完成了RAG系统的快速搭建。适合初学者理解核心概念,快速体验模型效果(往期课程见文末)。但平台封装程度高,细节难以修改,也难以服务真实业务。
本期课程《借助RAG知识库优化电商智能问答》,我们不再依赖平台,转向从0编写完整系统。不只是搭出来,而是理解每一个模块,控制每一层逻辑,真正做到“能用、好用、可扩展”。
学习:https://www.heywhale.com/u/b2f366
系统搭建核心:知识库、检索与生成的协同机制
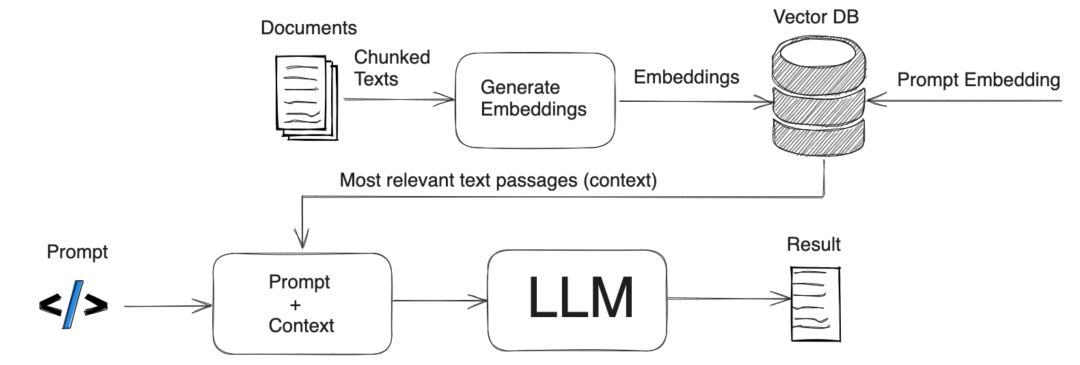
RAG系统的本质,是知识库与大模型之间的高效协同。为了实现这点,我们从三个关键模块入手:知识库构建 → 精准检索 → 智能生成,层层构建。
1、知识库构建
这一阶段的核心,是让文档变成结构化、可检索的知识单元。课程围绕电商业务,从产品目录、营销政策、物流规则、FAQ、售后文档中构建知识源。
-
通过文本规范化、去除噪声、结构化处理等步骤,清洗原始文档。
-
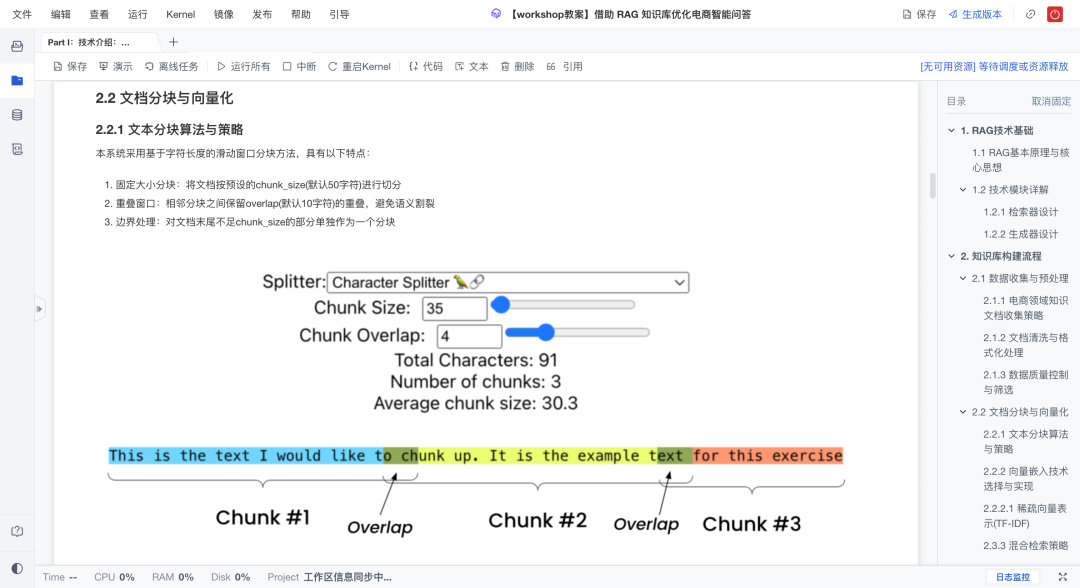
分块策略采用滑动窗口(chunk_size+overlap)机制,同时保留语义连贯性。
-
向量化阶段采用TF-IDF构建稀疏向量,后续也支持密集向量嵌入。
2、检索模块
本课程实现了一套混合检索策略。
-
结合稀疏(BM25)与密集(向量)检索,通过权重融合提升匹配精准度。
-
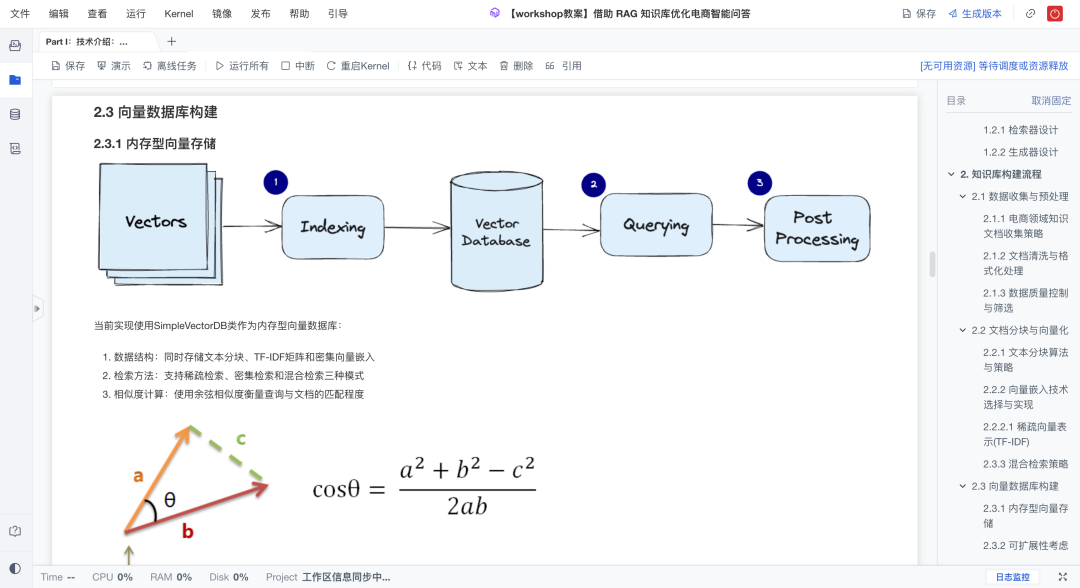
相似度计算基于余弦相似度,支持top-k返回。
-
支持从TF-IDF向量空间与向量数据库中双向检索。
此外,我们预留了Milvus/FAISS等持久化数据库的扩展口,也实现了增量更新能力,方便后期迭代。
3、生成模块
本系统采用Qwen3-4B作为生成模型,使用Hugging Face Transformers加载模型,并将模型加载到GPU上以加速推理。为提高生成质量做了一下设计与优化:
-
Prompt模板结构清晰,包含已知信息+用户提问+回答指令,确保上下文关联与指令清晰。
-
通过Top-p采样、Beam Search等参数配置,优化生成质量与风格。
-
实现异常处理机制,保障模型在边界条件下稳定运行。
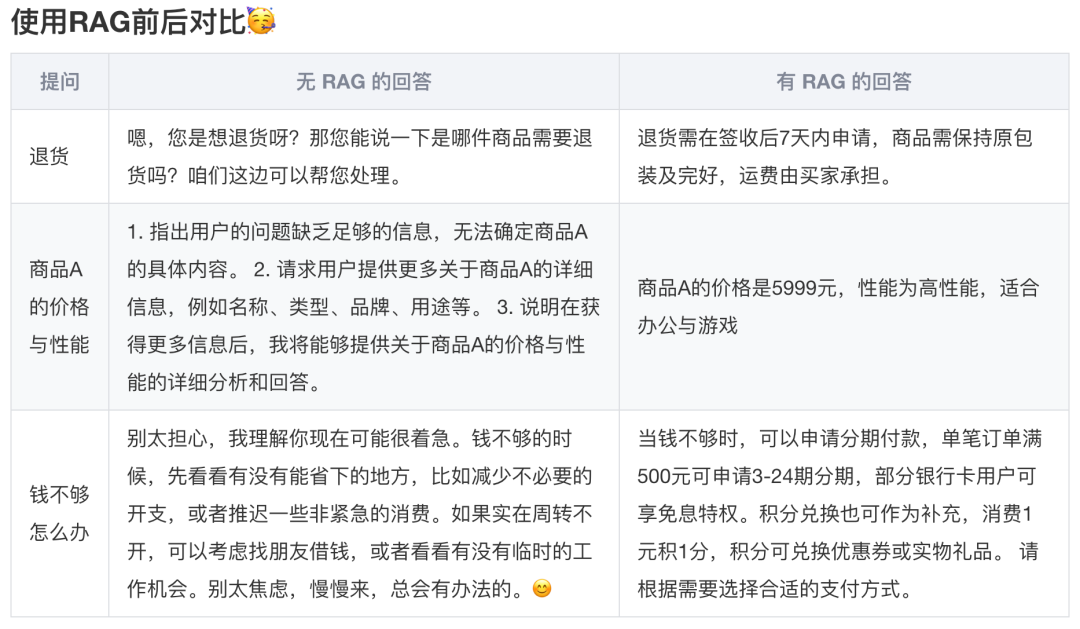
同时,生成内容紧密依托检索结果,杜绝模型幻觉,提高可解释性与准确度。
从原理到实践:搭建一套完整电商RAG系统
理论学完,开始落地。课程的第二部分是企业级RAG系统的实战搭建。我们不再用平台点击,而是手写全部代码,从数据采集到模型问答,环环相扣,逐步构建。核心能力包括:
-
电商知识文档的采集与格式转换
-
向量化策略、分块算法的定制实现
-
混合检索模块的组装与相似度排序
-
Qwen模型接入与Prompt编排
-
模块串联,形成端到端问答能力
最终,你将完成一个具备真实问答能力、可持续扩展的 AI 应用系统。
为什么手写代码而不继续用Dify?
Dify 平台能跑通流程,也能快速实现效果。但系统封闭、可控性低,不适合应对业务复杂度高、定制化要求强的真实场景。
相对依靠平台,本课程手写代码搭建RAG系统的方式有三大优势:
灵活:每个模块可自由替换、优化,比如Prompt模板、检索策略、解码方式。
透明:了解每一步发生了什么,调试容易,便于维护和优化。
可控:能将系统部署在企业私有云或本地,数据不出域,更安全。
通过这门课程,你将完整掌握构建企业级RAG系统的核心方法。它不仅带你理解RAG的底层逻辑,更带你走进真正可落地的AI应用场景。适合开发者、产品经理、技术负责人等,对AI应用落地有明确需求的人群。