论文学习19:Multi-view Aggregation Network for Dichotomous Image Segmentation
代码来源
https://github.com/qianyu-dlut/MVANet
模块作用
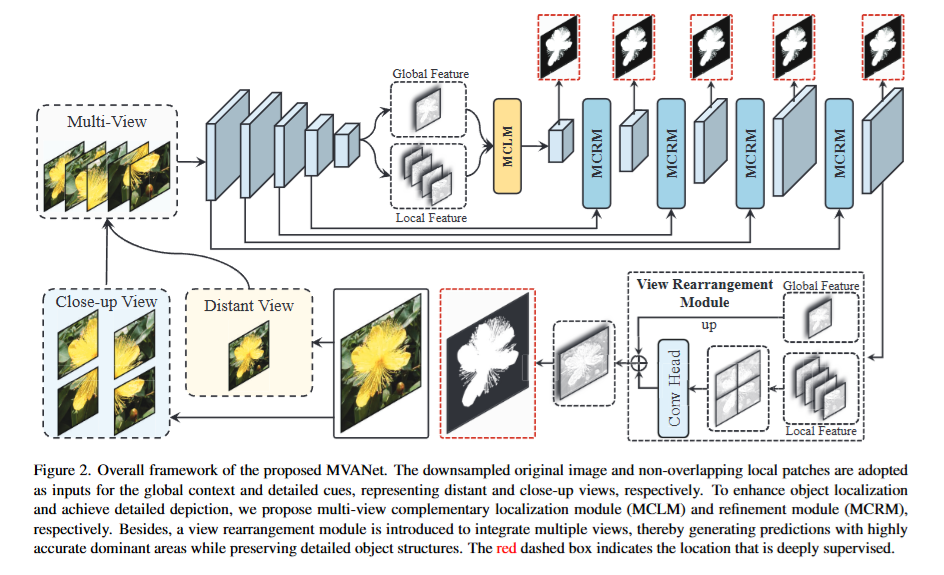
DIS 任务因需要处理高分辨率图像中的复杂细节(如细微边缘、遮挡、光照变化等)而具有挑战性。传统方法通常采用多阶段、多流的复杂模型,先通过全局定位识别目标物体,再逐步精炼局部细节。然而,这种方法增加了计算复杂度和内存需求,限制了其在实时应用(如自动驾驶、视频处理)中的实用性。本文提出的MVANet 的设计避免了传统方法的复杂性,并在保持高精度的同时显著降低了计算负担。
模块结构
-
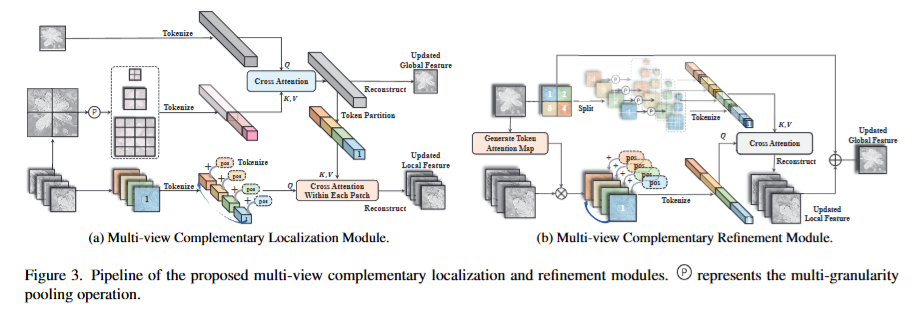
多视图互补定位模块(MCLM): 解决了多视图目标对齐的挑战,通过共同计算目标的协同注意力区域,实现了长距离、深刻的跨视图视觉交互 。它确保了全局上下文的正确引导,为后续的精细化奠定了基础。
-
多视图互补细化模块(MCRM): MCRM 嵌入到解码器的每个块中,能够充分整合互补的局部信息,弥补单一视图补丁的语义缺陷 。通过动态优化全局表示中缺失的细粒度细节,它使得细节丰富的特写视图特征能够聚焦于高度纤细的结构,从而显著提升了分割的精度和鲁棒性 。
-
视图重排模块(VRM): 在 MCLM 和 MCRM 有效融合特征的基础上,VRM 通过轻量级操作完成了最终的高分辨率预测重排,有效解决了补丁边界错位问题,确保了最终输出的无缝性和高质量 。
代码
class MCLM(nn.Module): def __init__(self, d_model, num_heads, pool_ratios=[1, 4, 8]):super(MCLM, self).__init__()self.attention = nn.ModuleList([nn.MultiheadAttention(d_model, num_heads, dropout=0.1),nn.MultiheadAttention(d_model, num_heads, dropout=0.1),nn.MultiheadAttention(d_model, num_heads, dropout=0.1),nn.MultiheadAttention(d_model, num_heads, dropout=0.1),nn.MultiheadAttention(d_model, num_heads, dropout=0.1)])self.linear3 = nn.Linear(d_model, d_model * 2)self.linear4 = nn.Linear(d_model * 2, d_model)self.linear5 = nn.Linear(d_model, d_model * 2)self.linear6 = nn.Linear(d_model * 2, d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(0.1)self.dropout1 = nn.Dropout(0.1)self.dropout2 = nn.Dropout(0.1)self.activation = get_activation_fn('relu')self.pool_ratios = pool_ratiosself.p_poses = []self.g_pos = Noneself.positional_encoding = PositionEmbeddingSine(num_pos_feats=d_model // 2, normalize=True)def forward(self, l, g):"""l: 4,c,h,wg: 1,c,h,w"""b, c, h, w = l.size() # 4,c,h,w -> 1,c,2h,2wconcated_locs = rearrange(l, '(hg wg b) c h w -> b c (hg h) (wg w)', hg=2, wg=2)pools = []for pool_ratio in self.pool_ratios:# b,c,h,wtgt_hw = (round(h / pool_ratio), round(w / pool_ratio))pool = F.adaptive_avg_pool2d(concated_locs, tgt_hw)pools.append(rearrange(pool, 'b c h w -> (h w) b c'))if self.g_pos is None:pos_emb = self.positional_encoding(pool.shape[0], pool.shape[2], pool.shape[3])pos_emb = rearrange(pos_emb, 'b c h w -> (h w) b c')self.p_poses.append(pos_emb)pools = torch.cat(pools, 0)if self.g_pos is None:self.p_poses = torch.cat(self.p_poses, dim=0)pos_emb = self.positional_encoding(g.shape[0], g.shape[2], g.shape[3])self.g_pos = rearrange(pos_emb, 'b c h w -> (h w) b c')# attention between glb (q) & multisensory concated-locs (k,v)g_hw_b_c = rearrange(g, 'b c h w -> (h w) b c')g_hw_b_c = g_hw_b_c + self.dropout1(self.attention[0](g_hw_b_c + self.g_pos, pools + self.p_poses, pools)[0])g_hw_b_c = self.norm1(g_hw_b_c)g_hw_b_c = g_hw_b_c + self.dropout2(self.linear6(self.dropout(self.activation(self.linear5(g_hw_b_c)).clone())))g_hw_b_c = self.norm2(g_hw_b_c)# attention between origin locs (q) & freashed glb (k,v)l_hw_b_c = rearrange(l, "b c h w -> (h w) b c")_g_hw_b_c = rearrange(g_hw_b_c, '(h w) b c -> h w b c', h=h, w=w)_g_hw_b_c = rearrange(_g_hw_b_c, "(ng h) (nw w) b c -> (h w) (ng nw b) c", ng=2, nw=2)outputs_re = []for i, (_l, _g) in enumerate(zip(l_hw_b_c.chunk(4, dim=1), _g_hw_b_c.chunk(4, dim=1))):outputs_re.append(self.attention[i + 1](_l, _g, _g)[0]) # (h w) 1 coutputs_re = torch.cat(outputs_re, 1) # (h w) 4 cl_hw_b_c = l_hw_b_c + self.dropout1(outputs_re)l_hw_b_c = self.norm1(l_hw_b_c)l_hw_b_c = l_hw_b_c + self.dropout2(self.linear4(self.dropout(self.activation(self.linear3(l_hw_b_c)).clone())))l_hw_b_c = self.norm2(l_hw_b_c) l = torch.cat((l_hw_b_c, g_hw_b_c), 1) # hw,b(5),creturn rearrange(l, "(h w) b c -> b c h w", h=h, w=w) ## (5,c,h*w)class MCRM(nn.Module):def __init__(self, d_model, num_heads, pool_ratios=[4, 8, 16], h=None):super(MCRM, self).__init__()self.attention = nn.ModuleList([nn.MultiheadAttention(d_model, num_heads, dropout=0.1),nn.MultiheadAttention(d_model, num_heads, dropout=0.1),nn.MultiheadAttention(d_model, num_heads, dropout=0.1),nn.MultiheadAttention(d_model, num_heads, dropout=0.1)])self.linear3 = nn.Linear(d_model, d_model * 2)self.linear4 = nn.Linear(d_model * 2, d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(0.1)self.dropout1 = nn.Dropout(0.1)self.dropout2 = nn.Dropout(0.1)self.sigmoid = nn.Sigmoid()self.activation = get_activation_fn('relu')self.sal_conv = nn.Conv2d(d_model, 1, 1)self.pool_ratios = pool_ratiosself.positional_encoding = PositionEmbeddingSine(num_pos_feats=d_model // 2, normalize=True)def forward(self, x):b, c, h, w = x.size() loc, glb = x.split([4, 1], dim=0) # 4,c,h,w; 1,c,h,w# b(4),c,h,wpatched_glb = rearrange(glb, 'b c (hg h) (wg w) -> (hg wg b) c h w', hg=2, wg=2)# generate token attention maptoken_attention_map = self.sigmoid(self.sal_conv(glb))token_attention_map = F.interpolate(token_attention_map, size=patches2image(loc).shape[-2:], mode='nearest')loc = loc * rearrange(token_attention_map, 'b c (hg h) (wg w) -> (hg wg b) c h w', hg=2, wg=2)pools = []for pool_ratio in self.pool_ratios:tgt_hw = (round(h / pool_ratio), round(w / pool_ratio))pool = F.adaptive_avg_pool2d(patched_glb, tgt_hw)pools.append(rearrange(pool, 'nl c h w -> nl c (h w)')) # nl(4),c,hw# nl(4),c,nphw -> nl(4),nphw,1,cpools = rearrange(torch.cat(pools, 2), "nl c nphw -> nl nphw 1 c")loc_ = rearrange(loc, 'nl c h w -> nl (h w) 1 c')outputs = []for i, q in enumerate(loc_.unbind(dim=0)): # traverse all local patches# np*hw,1,cv = pools[i]k = voutputs.append(self.attention[i](q, k, v)[0])outputs = torch.cat(outputs, 1) src = loc.view(4, c, -1).permute(2, 0, 1) + self.dropout1(outputs)src = self.norm1(src)src = src + self.dropout2(self.linear4(self.dropout(self.activation(self.linear3(src)).clone())))src = self.norm2(src)src = src.permute(1, 2, 0).reshape(4, c, h, w) # freshed locglb = glb + F.interpolate(patches2image(src), size=glb.shape[-2:], mode='nearest') # freshed glbreturn torch.cat((src, glb), 0), token_attention_mapclass MVANet(nn.Module): def __init__(self):super().__init__()self.backbone = SwinB(pretrained=True)emb_dim = 128self.sideout5 = nn.Sequential(nn.Conv2d(emb_dim, 1, kernel_size=3, padding=1))self.sideout4 = nn.Sequential(nn.Conv2d(emb_dim, 1, kernel_size=3, padding=1))self.sideout3 = nn.Sequential(nn.Conv2d(emb_dim, 1, kernel_size=3, padding=1))self.sideout2 = nn.Sequential(nn.Conv2d(emb_dim, 1, kernel_size=3, padding=1))self.sideout1 = nn.Sequential(nn.Conv2d(emb_dim, 1, kernel_size=3, padding=1))self.output5 = make_cbr(1024, emb_dim)self.output4 = make_cbr(512, emb_dim)self.output3 = make_cbr(256, emb_dim)self.output2 = make_cbr(128, emb_dim)self.output1 = make_cbr(128, emb_dim)self.multifieldcrossatt = MCLM(emb_dim, 1, [1, 4, 8])self.conv1 = make_cbr(emb_dim, emb_dim)self.conv2 = make_cbr(emb_dim, emb_dim)self.conv3 = make_cbr(emb_dim, emb_dim)self.conv4 = make_cbr(emb_dim, emb_dim)self.dec_blk1 = MCRM(emb_dim, 1, [2, 4, 8])self.dec_blk2 = MCRM(emb_dim, 1, [2, 4, 8])self.dec_blk3 = MCRM(emb_dim, 1, [2, 4, 8])self.dec_blk4 = MCRM(emb_dim, 1, [2, 4, 8])self.insmask_head = nn.Sequential(nn.Conv2d(emb_dim, 384, kernel_size=3, padding=1),nn.BatchNorm2d(384),nn.PReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1),nn.BatchNorm2d(384),nn.PReLU(),nn.Conv2d(384, emb_dim, kernel_size=3, padding=1))self.shallow = nn.Sequential(nn.Conv2d(3, emb_dim, kernel_size=3, padding=1))self.upsample1 = make_cbg(emb_dim, emb_dim)self.upsample2 = make_cbg(emb_dim, emb_dim)self.output = nn.Sequential(nn.Conv2d(emb_dim, 1, kernel_size=3, padding=1))for m in self.modules():if isinstance(m, nn.ReLU) or isinstance(m, nn.Dropout):m.inplace = Truedef forward(self, x):shallow = self.shallow(x)glb = rescale_to(x, scale_factor=0.5, interpolation='bilinear')loc = image2patches(x)input = torch.cat((loc, glb), dim=0)feature = self.backbone(input)e5 = self.output5(feature[4]) # (5,128,16,16)e4 = self.output4(feature[3]) # (5,128,32,32)e3 = self.output3(feature[2]) # (5,128,64,64)e2 = self.output2(feature[1]) # (5,128,128,128)e1 = self.output1(feature[0]) # (5,128,128,128)loc_e5, glb_e5 = e5.split([4, 1], dim=0)e5 = self.multifieldcrossatt(loc_e5, glb_e5) # (4,128,16,16)e4, tokenattmap4 = self.dec_blk4(e4 + resize_as(e5, e4))e4 = self.conv4(e4) e3, tokenattmap3 = self.dec_blk3(e3 + resize_as(e4, e3))e3 = self.conv3(e3)e2, tokenattmap2 = self.dec_blk2(e2 + resize_as(e3, e2))e2 = self.conv2(e2)e1, tokenattmap1 = self.dec_blk1(e1 + resize_as(e2, e1))e1 = self.conv1(e1)loc_e1, glb_e1 = e1.split([4, 1], dim=0)output1_cat = patches2image(loc_e1) # (1,128,256,256)# add glb feat inoutput1_cat = output1_cat + resize_as(glb_e1, output1_cat)# mergefinal_output = self.insmask_head(output1_cat) # (1,128,256,256)# shallow feature mergefinal_output = final_output + resize_as(shallow, final_output)final_output = self.upsample1(rescale_to(final_output))final_output = rescale_to(final_output + resize_as(shallow, final_output))final_output = self.upsample2(final_output)final_output = self.output(final_output)####sideout5 = self.sideout5(e5).cuda()sideout4 = self.sideout4(e4) sideout3 = self.sideout3(e3) sideout2 = self.sideout2(e2) sideout1 = self.sideout1(e1) #######glb_sideouts ######glb5 = self.sideout5(glb_e5)glb4 = sideout4[-1,:,:,:].unsqueeze(0)glb3 = sideout3[-1,:,:,:].unsqueeze(0)glb2 = sideout2[-1,:,:,:].unsqueeze(0)glb1 = sideout1[-1,:,:,:].unsqueeze(0)####### concat 4 to 1 #######sideout1 = patches2image(sideout1[:-1]).cuda()sideout2 = patches2image(sideout2[:-1]).cuda()####(5,c,h,w) -> (1 c 2h,2w)sideout3 = patches2image(sideout3[:-1]).cuda()sideout4 = patches2image(sideout4[:-1]).cuda()sideout5 = patches2image(sideout5[:-1]).cuda()if self.training:return sideout5, sideout4,sideout3,sideout2,sideout1,final_output, glb5, glb4, glb3, glb2, glb1,tokenattmap4, tokenattmap3,tokenattmap2,tokenattmap1else:return final_output总结
本文将高精度 DIS 建模为多视图物体感知问题,并提出了一个简洁、精简的多视图聚合网络,旨在在模型设计、精度和推理速度之间取得更好的平衡。为了解决多视图的目标对齐问题,本文提出了多视图互补定位模块来联合计算目标的共同注意区域。此外,本文提出的多视图互补细化模块嵌入到每个解码器块中,以充分整合互补的局部信息并弥补单视图块的语义缺陷,最终仅用一个卷积层即可完成视图重排。大量实验表明,提出的模型在 DIS 数据集上表现良好。