时序预测(论文解读)-金融领域的滞后性
论文1 Detecting the lead–lag efect in stock markets: defnition, patterns, and investment strategies
1 相关工作
在这篇文章中,作者将已有关于 lead–lag 现象的研究归纳为两大类:第一类关注于高频数据中的 lead–lag 关系识别,第二类聚焦于基于该现象的投资策略设计。
在第一类中,许多研究(如 Jong & Nijman, Huth & Abergel 等)发现,在高频数据(如分钟级别)中,股票间确实存在滞后关系,甚至可通过 Granger 因果检验、互信息或最优因果路径算法(如 Stübinger 2019)进行量化;但这类关系常常不稳定、受噪音干扰大,容易因价格同步问题、微观结构噪声或市场偶然波动导致虚假关联,因此难以在现实投资中可靠利用。
第二类文献则尝试基于高频 lead–lag 信号进行套利或构建策略,但这些策略普遍面临交易门槛高、手续费高、对机构投资者依赖强等问题,使得中小投资者难以实用。
作者指出现有文献普遍存在三个缺陷:① 没有对 lead–lag 效应进行统计意义上的明确界定,常将“偶发关系”误当“稳定效应”;② 多使用传统计量经济学方法,缺乏结构化、数据驱动的模型框架;③ 仅关注短期套利,没有将滞后结构转化为长期稳定的投资信号。
正因为这些缺陷,现有研究很难兼顾“理论定义清晰性”与“实践策略可行性”。本研究正是为了解决这些空白,尝试在低频数据中用统计检验框架正式定义效应,并探索其在真实市场中的策略价值。
2 动机
这篇论文的研究动机在于系统性地定义、识别并利用股票市场中的 lead–lag 效应,也就是某只股票的价格变动总是滞后于另一只股票的规律性现象。虽然“lead–lag 现象”早已被观察到,但现有研究普遍缺乏对其进行形式化定义与统计检验,也很少将其作为稳定可交易信号纳入投资策略中。
作者提出的核心目标有三个:
第一,基于十年中美股票数据,提出一种统计显著性的定义方法,将“偶发的跟随行为”与“长期稳定的滞后效应”区分开来,从而首次明确提出“lead–lag 效应”这一概念;
第二,建立一个基于日度收益构建的有向网络模型,结合蒙特卡洛模拟的随机网络作为对照,通过显著性阈值判定哪些股票对之间存在真实的 lead–lag 效应;
第三,进一步将检测到的效应作为有用信号,引入到量化投资中,既设计了基于 follower–leader 结构的纯 lead–lag 策略,又将其嵌入到多个经典 alpha 策略中构建增强策略,并在实证中发现这些策略能有效提升收益与稳健性。
整体来看,这项工作不仅提出并建模了 lead–lag 效应这一重要但模糊的金融市场现象,还打通了其从定义、检测到落地实用的完整链条,为低频交易场景下的信息流建模和策略设计提供了新的方向。
3 方法
构建一个用于检测股票市场中 lead–lag 效应的数据驱动网络分析模型
1.提出构建“每日 lead–lag 网络”:
计算每日收益率
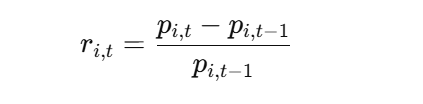
若某只股票i今天的收益率与另一只股票j昨天的收益率在一个设定阈值Δ内足够接近(即呈现“延迟跟随”关系),则认为股票i在这一天跟随了股票j。
通过这个判断标准,作者构建了一个日度的有向网络,其中边 gij,t=1表示当天 i 跟随 j。随后,作者计算每对股票之间在整个分析窗口内的累计跟随天数 dij,作为该对股票之间可能存在 lead–lag 效应的强度。
2.提出一种统计检验方法来判断是否真的存在“效应”而非偶然的“关系”
设计了一个随机网络模型作为对照(Null Model),它保留真实网络的度数分布但打乱边的连接,进而模拟出在纯随机情况下可能出现的dij分布,并据此设定一个显著性阈值d'。当实际的dij>=d',被认为存在统计显著的 lead–lag 效应,关系被保存下来。
每天构建一张网络图 Gt,然后在整个样本期内 对所有天的图进行累加统计dij,从而提取出稳定的 lead–lag 关系。
通过随机图构造 + 多轮蒙特卡洛模拟,得到一个合理的显著性阈值 d'


3.将检测出的 lead–lag 股票对应用于投资策略中
具体包含两个步骤
一是设计“纯 lead–lag 策略”,即基于 leader 对 follower 的影响强度,构建权重加权投资组合
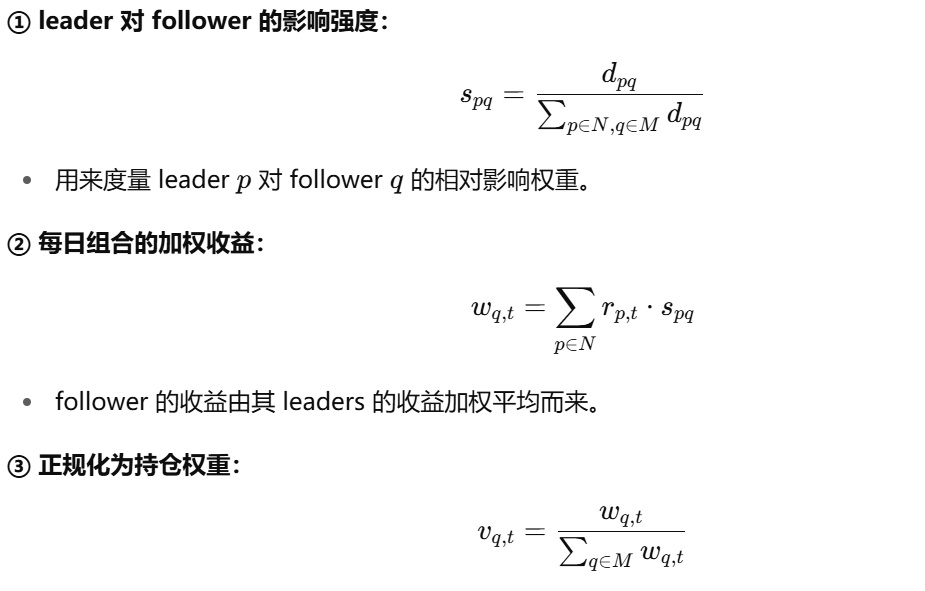
二是将该策略作为增强信号,嵌入到经典 alpha-factor 策略(如 Alpha-101)中,从而构建“增强型投资策略”,提升整体回报和风险调整收益。
例如:用 alpha 策略选出一组股票,比如 top 50。 用 lead-lag 检测结果判断这些股票里谁是 follower、谁是 leader。 根据 follower 所受到的影响强度(lead-lag 强度),来重新分配这些股票的持仓权重
这一方法的动机在于:当前大多数文献仅识别“lead–lag 关系”却没有定义清晰可测的“lead–lag 效应”;而作者的目标是以统计意义上的显著性为标准,筛选出真正具有预测意义的关系,并将其转化为实用的投资信号,最终在中美市场中均展示了策略的有效性和稳定性。整套方法体现了从“模式识别”到“策略落地”的完整闭环。
4 实验
这篇论文的实验部分围绕三个核心问题展开:是否存在 lead–lag 效应?这种效应是否稳定?它是否具有可用于投资的价值?作者设计了四类实验,分别对应四个目的。
第一类实验是效应检验实验,目的是验证所定义的 lead–lag 效应是否真实存在。研究者在中国(CSI 300)与美国(S&P 500)两个市场上分别构建了每日的 lead–lag 网络,并通过蒙特卡洛模拟生成随机网络,以计算累计跟随天数 dij 的显著性阈值 d‘,结果发现实际股票之间存在大量显著高于 d’ 的关系对,证实了 lead–lag 效应在两个市场中均广泛存在。
第二类实验是效应结构分析实验,意在探究 lead–lag 网络的结构特征。作者发现这些网络呈现幂律分布,即大多数股票对之间几乎无效应,但少数股票对之间滞后关系极其强烈,且整个网络具有高度异质性和稳定的节点结构(即有“信息领导者”反复出现),表明市场中确实存在一小部分股票对拥有持久的信息主导地位。
第三类实验是策略回测实验,分为两组:一是基于 lead–lag 效应本身构建“纯 lead–lag 策略”,即根据历史检测出的 leader→follower 结构构造投资组合;二是将 lead–lag 加入现有 alpha 策略中作为加权因子(增强策略)。回测结果显示,在 CSI 300 与 S&P 500 上,两种策略均取得了优于基准的累计收益率和夏普比率,同时降低了最大回撤,特别是增强策略在提升原有 alpha 策略表现上效果明显。
最后一组是稳健性实验,测试 Δ 阈值、样本窗口长度和样本外预测能力对策略表现的影响,结果表明模型对参数选择鲁棒,策略在不同市场环境中仍具稳定表现。
实验部分从“是否存在效应”、“效应结构特征”到“能否转化为可行策略”三个维度,系统验证了作者提出的 lead–lag 效应建模框架的有效性、稳定性和可投资性,支撑了其作为一种结构化市场信息建模工具的研究价值。
论文2 Emergence of statistically validated financial intraday lead-lag relationships
1 相关工作
论文将以往对股票市场中 lead–lag 效应(滞后效应)的研究大致分为两类:
第一类研究主要基于因果分析工具,比如 Granger 因果检验,这种方法侧重于检验某个股票或因子在过去是否对另一个变量具有统计意义上的预测能力。虽然这些方法有严格的统计基础,但它们通常只适用于少量变量之间的两两关系检验,计算成本高且难以扩展到成百上千只股票的高维市场环境中。更重要的是,这类方法通常依赖于严格的假设前提,如平稳性、线性关系等,因此在实际金融市场的复杂非线性结构中往往存在适用性不足的问题。
第二类研究则采用结构建模方法,比如构建因子网络、协整图或动态因果图等方式来捕捉股票间的系统性结构关系。这类方法具有更好的可视化能力和解释性,并能在网络层面揭示出市场中的“主导者–跟随者”模式。然而,这类方法大多依赖高频数据(如分钟或秒级交易数据),在日度或低频数据中往往难以稳定识别结构;此外,很多方法本质上是静态建模,缺乏对时变性和强弱程度的量化建模,因此在动态组合策略中效果受限。
总结来说,现有研究要么在方法论上太“精细”(如 Granger 检验,不适合大规模股票),要么太“粗略”(如静态图网络,难以刻画动态传导强度),因而难以在低频数据下有效刻画复杂的滞后效应,也缺乏将这种结构信息融合进实际投资策略(如 alpha 策略)的系统方法 ->上篇论文已经提出了一种方法
2 动机
本研究的动机源于一个关键观察:虽然金融市场中广泛存在 lead–lag(主导–滞后)效应,即某些股票的价格走势会领先于其他股票,但目前尚缺乏一种系统、可扩展、能落地到策略中的建模方法来捕捉和利用这种效应。传统因果分析方法(如 Granger 检验)难以扩展到成百上千只股票的大规模市场环境,结构建模方法又大多依赖高频数据,缺乏面向日度收益数据的通用方法。
这篇论文旨在提出一种低频数据下构建 lead–lag 网络的方法框架,以捕捉并量化市场中个股之间的滞后关系,并进一步将其转化为可用于 alpha 策略增强的组合构建信号。具体来说,作者通过构造每日的有向图网络,提取长期稳定的 follower–leader 结构,用统计方法筛选出显著的滞后关系,并提出一套归一化的影响强度建模方式,将这些结构信息嵌入到已有因子策略中作为加权机制,形成增强型组合策略。这种方法实现了从“结构感知”到“可交易信号”的转化,填补了现有研究中 lead–lag 模型与实际量化投资之间的落地空白,也为刻画金融市场中的信息流动路径提供了新的建模思路。
3 方法
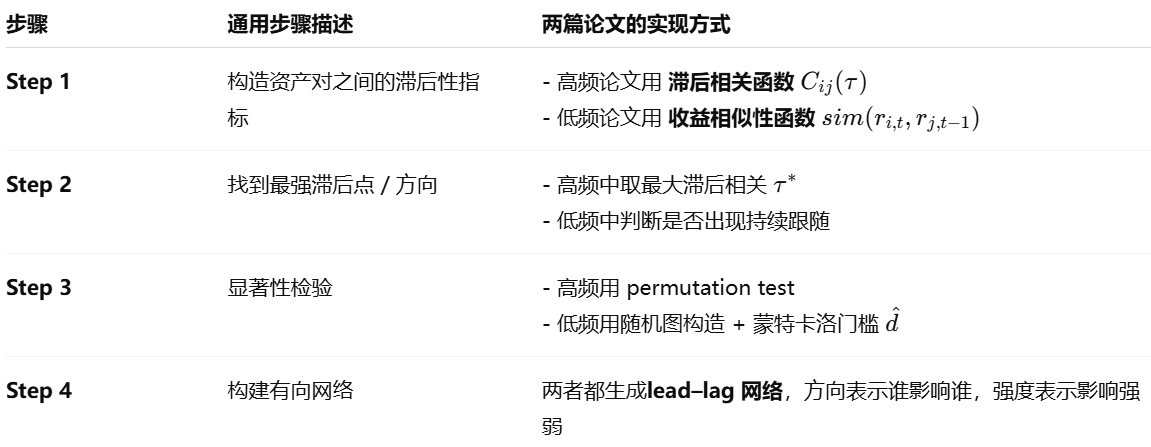
该论文的核心方法旨在从高频金融市场中提取出具有统计显著性的滞后关系(lead-lag relationships),并以网络的形式描述市场中不同资产之间的因果结构。为此,作者提出了一种系统的流程,首先基于交易数据(如价格序列)构造资产间的时间延迟交叉相关性,继而通过延迟相关函数(lagged correlation function)计算每对资产在不同时间滞后下的相关程度。具体来说,对于任意两个资产 AAA 和 BBB,作者考虑在多个时间滞后 τ下的相关性 CAB(τ),以捕捉出“谁先动、谁后动”的因果模式。
接着,为了避免噪声和多重比较问题,作者引入了统计显著性检验机制(statistical validation)。他们基于随机重排检验(permutation test)来构建无 lead-lag 假设下的对照分布,并通过设定显著性水平(如 1% 或 5%),筛选出真正具有稳定先后影响关系的资产对。这一设计动机是为了克服高频数据中大量偶然同步性(spurious correlation)的问题,从而保证最终识别出的网络结构具有统计稳健性。
最终,所有通过显著性检验的资产对被构建为一张有向 lead–lag 网络:边的方向表示因果顺序(谁领先谁滞后),边的权重则由最显著的滞后相关强度决定。这张网络可以揭示出金融市场中信息流的路径、主导资产群体,以及市场结构的层级性(如核心-边缘结构)。与传统方法相比,该方法具有三大优势:第一,它可处理大规模资产集;第二,它不依赖线性假设;第三,它能显式地量化 lead–lag 的方向性和强度。




4 实验
该论文的实验部分主要围绕如何在真实金融市场中提取有效的 lead–lag 网络结构展开。作者选取了法国股票市场的高频交易数据,以分钟为单位构建收益序列,并以此为基础计算不同股票对之间的延迟相关函数 Cij(τ),进而构建滞后关系网络。实验的首要目的是验证该方法是否能稳定识别出具有统计显著性的股票间主导–跟随关系,以及这些关系是否能反映市场结构的某些稳定特征。
为此,作者首先通过permutation test 对每一对股票的滞后相关最大值 Cijmax进行显著性检验,并使用Bonferroni 校正来控制多重检验误差。经过检验后,仅保留那些显著的、有方向的股票对作为网络中的边,最终构建出一张有向滞后关系网络。随后,作者从多个维度对网络结构进行了分析,包括节点的入度/出度分布、边权强度、信息流密度等,目的在于识别市场中是否存在“信息主导者”(high out-degree)与“信息接收者”(high in-degree),并验证市场结构是否具有明显的层次性。
实验结果显示,该网络中确实存在若干“核心”节点,它们对其他股票有较强的领先作用,说明市场中信息并非完全同步传播,而是存在明确的信息传导路径和层级结构。此外,网络中也展现出小世界性质和分层结构,表明市场内部存在稳定的信息主导机制。作者进一步讨论这些结构如何揭示市场效率边界以及潜在套利机会,指出这类网络可为理解市场行为与系统性风险传播提供结构性视角。
市场中的信息传导多集中于 1–5 分钟内,尤其以 2 分钟为峰值,这一结果表明金融市场的信息反应极其迅速
两篇论文对比:
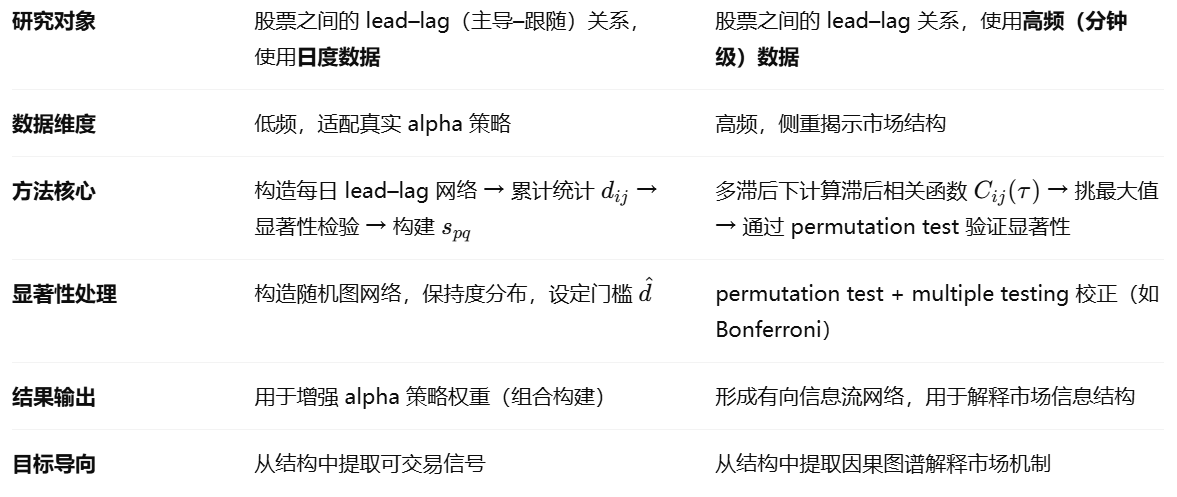
第一篇论文 是面向“投资落地”的,最终是要服务于组合优化,所以重点是如何从 lead–lag 中抽取可用权重信号。第二篇论文 更偏向“市场机制刻画”,强调如何通过滞后结构理解市场的“因果网络”、“主导–从属关系”,偏理论研究。
共同点:在股票市场中,存在资产间的滞后关系(lead–lag effect),可以通过网络建模方式提取并验证其显著性,然后服务于更高层次的金融任务(如理解市场结构或增强策略表现)。

论文3 Information-theoretic approach to lead-lag effect on financial markets
1 相关工作
以往关于金融市场滞后关系的研究主要可以分为两类:基于回归模型的方法和基于统计检验的网络构建方法。
第一类方法往往使用向量自回归(VAR)、Granger 因果检验等工具,尝试在一组资产间刻画出显式的因果结构。然而,这类方法通常存在两个主要缺点:一是它们对建模假设要求较强,如线性关系、平稳性、正态性等,使得在真实市场高噪声、非线性的背景下应用受限;二是它们往往难以扩展到大规模资产集,因为随着资产数量增加,模型参数呈指数增长,极易过拟合。
第二类方法则主要关注从实证数据中直接提取显著的滞后关系,例如利用延迟相关系数(lagged cross-correlation)加上 permutation 检验来构建有向网络。这种方式虽然更具灵活性与稳健性,但早期方法大多忽略了多重检验问题,导致滞后关系的“假阳性”较多,且部分研究未能将这些结构信息进一步用于金融任务(如收益预测、风险管理),因此缺乏实际应用价值。此外,已有研究很少关注 lead–lag 网络结构的“层级性”、“行业依赖性”或“稳定性”等宏观特征,限制了对市场整体信息流动机制的理解。因此,当前工作尝试综合这两类方法的优点,构建一种具有统计显著性验证能力、可扩展性强、并能揭示信息结构层级性的滞后关系识别框架
2 动机
这篇论文的研究动机源于一个核心问题:在高频金融市场中,尽管信息在不同资产间传导速度极快,但仍普遍存在某些资产价格变动系统性地领先于其他资产的现象,即 lead–lag 效应。传统方法往往难以在高频数据下识别这些复杂的滞后关系,同时缺乏一种能够在无需强建模假设的前提下、自动从海量数据中挖掘出显著结构的通用方法。
这篇论文旨在提出一种新的框架,通过非参数统计方法和信息理论指标,在无监督的条件下从高频交易数据中提取具有统计显著性的滞后关系,并构建成一张lead–lag 信息流网络。具体建模方式包括三大步骤:首先利用价格信号构建延迟相关性指标,识别某一资产对另一资产的潜在领先时间窗口;其次,通过 permutation 检验与信息熵检验联合筛选出显著的滞后结构,控制假阳性率;最后,将这些结构以有向网络形式表示,并进一步分析其宏观特征(如中心性、传导路径等),以理解金融市场中信息流的结构性机制。论文的核心目标在于,不仅发现个别资产之间的先后关系,更重要的是刻画市场中系统性、可量化的信息传导结构,为市场理解、风险监控乃至策略构建提供支持。
3 方法
提出了一种以“延迟相关性 + 重排检验”为核心的建模方法,旨在从高频价格数据中构建一张稳健、可解释的 lead–lag 有向网络。
首先,作者以每对资产的收益时间序列为基础,计算其在多个滞后时间点 τ 下的延迟相关函数 Cij(τ),用于刻画资产 j 的收益变动是否会在延迟 τ 时间后显著影响资产 i。为了排除偶然同步的影响,作者引入了 permutation test(重排检验):通过打乱资产 j 的时间序列,构造其滞后相关性的“零假设分布”,并将真实的 Cijmax 与该分布进行比较,从而判断该 lead–lag 关系是否显著。
此外,为了减少由于数据噪声或局部异常引起的伪信号,论文还引入 信息熵指标 来量化每条路径的信息集中程度,仅保留那些同时满足相关性显著与信息熵较低的滞后路径。
最终,作者将所有显著关系构建为一张 lead–lag 有向网络,边的方向表示“谁领先谁”,边的强度表示“影响强度”,网络结构中还嵌入了滞后时间信息。
这种方法不仅具备非参数建模的鲁棒性,也允许在无需强假设的前提下,直接从数据中发现市场中潜在的信息主导路径与结构分层,从而为后续的金融行为分析、风险预测或量化交易提供清晰的结构信号。
延迟相关函数:
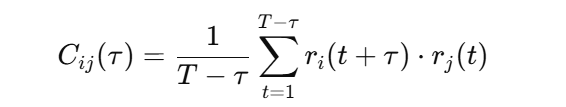




重排检验


有向网络



信息熵
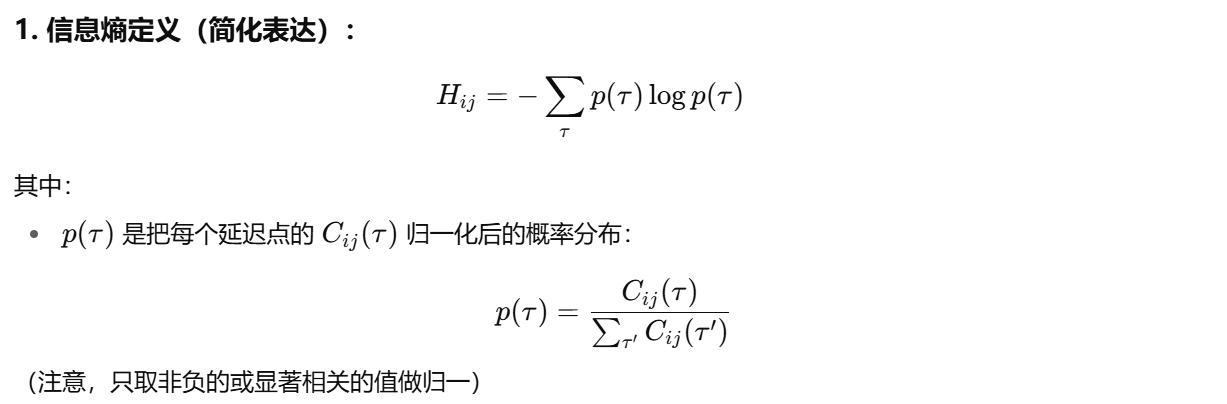
4 实验




滞后性网络结构分析





论文4 DAM: A Universal Dual Attention Mechanism for Multimodal Timeseries Cryptocurrency Trend Forecasting
1 相关工作




2 动机
现有的加密货币趋势预测方法在处理“情绪数据”和“金融市场数据”的融合上做得不够好。虽然很多研究已经开始引入情绪数据(如新闻、社交媒体),但大多只是简单地将这些数据拼接起来输入模型,没有建模它们之间的内在联系、相互作用以及滞后性。此外,大多数研究要么只用新闻,要么只用社交媒体,忽视了“客观情绪 + 主观情绪”的互补性。
这篇论文提出了一个全新的建模思路:通过设计一个双重注意力机制(Dual Attention Mechanism, DAM),分别在每个模态内部建模时间依赖(intra-modal attention)以及不同模态之间的信息融合(cross-modal attention),来提高预测性能并增强模型的可解释性。具体建模上,作者将情绪数据(由 CryptoBERT 分析得出的新闻和社交媒体情绪)与传统金融时间序列(如开盘价、成交量等)作为两个模态,先经过各自的注意力机制捕捉时序特征,再进行融合,最后送入 LSTM 进行趋势预测。整个模型是端到端的,可同时学习各模态内部结构与跨模态的关联,显著提升了预测精度。
3 方法

4 实验
在这篇论文中,作者设计了两类核心实验:对比实验 和 消融实验(Ablation Study),目的是为了验证他们提出的双注意力机制(DAM)是否真正有效,以及每个模块对最终预测准确率的具体贡献。
首先,在对比实验中,作者将他们的 DAM-LSTM 模型和多个主流的时间序列预测模型进行比较,包括:
不同融合方式的 LSTM(如简单拼接)、
CNN-LSTM、
NeuralProphet(一个改进的 Prophet 模型)、
Temporal Fusion Transformer(TFT)等。
实验设置中,他们使用比特币每日数据作为输入,目标是预测每日收盘价。模型性能通过 MAE 和 MAPE 进行评估,同时还考虑了是否输入了“平稳化处理”(即用差分方式处理高波动性)。结果显示,DAM-LSTM 的预测精度最高,比普通 LSTM 提升约 20%,而且在输入平稳化数据后表现提升明显(MAE下降近50%)。这说明该模型在处理高噪声、非平稳金融数据时表现更鲁棒。
然后是消融实验,作者为了验证双注意力结构中每个模块的贡献,分别移除了单模态注意力模块和跨模态注意力模块,并比较了预测误差。结果发现:
去掉跨模态注意力后,模型性能下降最明显;
去掉单模态注意力也有负面影响;
只有双模块同时保留时,预测性能最好。
这说明模态内建模+模态间融合是互补的,两者缺一不可,而且这种结构优于简单拼接方式。
平稳化

情感分析模型

论文5 From News to Forecast: Integrating Event Analysis in LLM-Based Time Series Forecasting with Reflection
1 相关工作



2 动机

3 方法
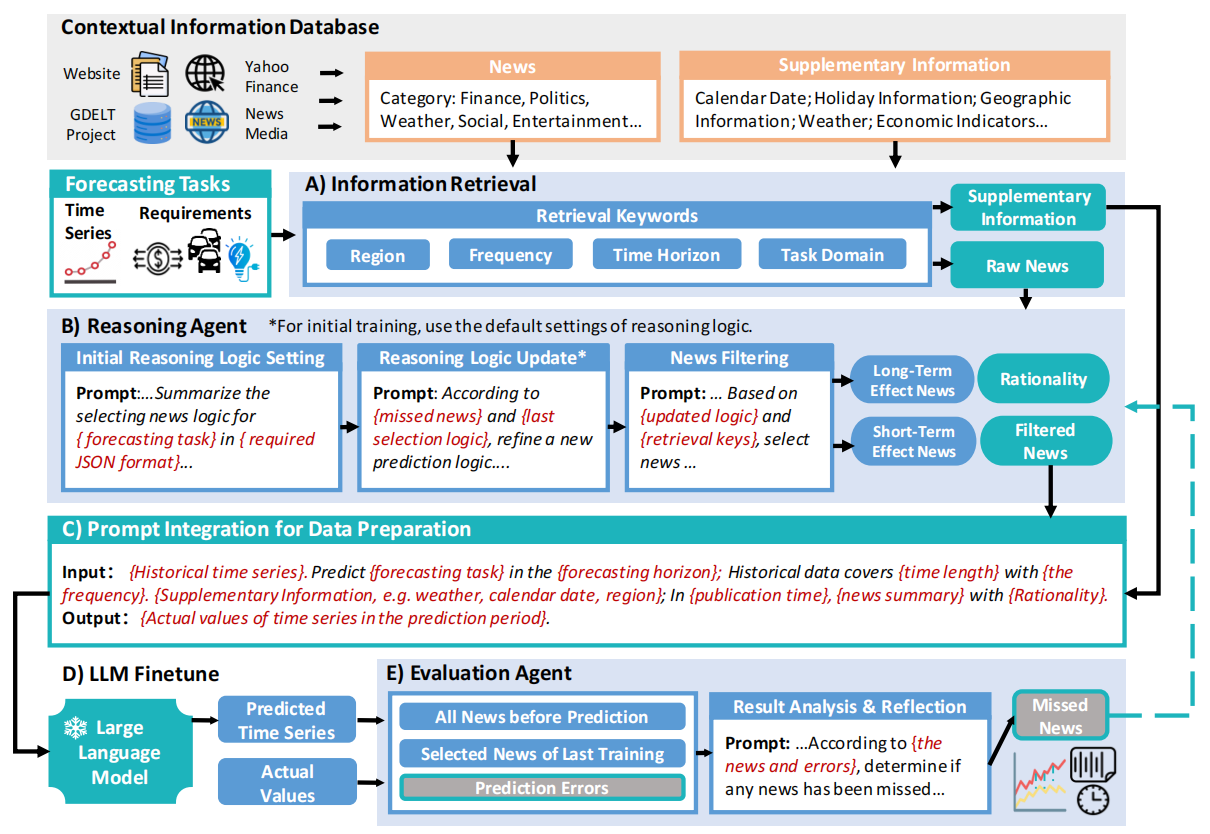
用类人推理的 LLM Agent 来动态筛选新闻,并将筛选出的新闻与时间序列融合,通过 prompt 和微调后的 LLM 实现上下文感知的预测,同时用评估代理不断优化新闻筛选逻辑。







4 实验
论文想回答三个核心问题:
引入新闻和补充信息,到底能不能提升时间序列预测?
评估 agent 帮助模型反思、选择更优新闻,这个机制是否真的有效?
相比现有主流方法,这种“LLM+新闻”方法是否具有竞争力?




论文6 Time-MMD: Multi-Domain Multimodal Dataset for Time Series Analysis
1 动机
作者指出了三大缺口:
领域窄:目前数据集大多集中在金融领域(如股票预测),不具备跨领域泛化能力。
模态对齐粗糙:文本和数值数据来自同一大领域(如股价+股评),但未保证时间同步或语义相关性,导致引入大量无关文本噪声。
数据污染严重:
文本中往往含有预测内容(如“预计明年通胀上升”),容易在训练中引发标签泄露。
数据集文本有可能被大型语言模型预训练过,导致评估不公正(例如GPT或LLaMA在预训练中可能读过这些报告)。
2 方法



