(ZipList入门笔记二)为何ZipList可以实现内存压缩,可以详细介绍一下吗
文章目录
- 1. 根除指针:最大的开销来源
- 2. 变长编码:按需分配,杜绝浪费
- 3. 紧凑的整体布局
- 综合示例:一个直观的对比
- Ziplist的代价:连锁更新
我们来深入探讨一下 Ziplist(压缩列表)实现内存压缩的精髓。
理解 Ziplist 为何能极致地节省内存,关键在于理解它解决了传统数据结构(尤其是双向链表)的哪些“内存浪费”问题。
它的压缩魔法主要来源于以下三个核心设计:
1. 根除指针:最大的开销来源
这是 Ziplist 最重要、最根本的内存优化点。
传统双向链表的问题:
一个标准的双向链表,每个节点(Node)除了存储数据外,还必须包含两个指针:一个 next 指向后继节点,一个 prev 指向前驱节点。
在 64 位操作系统中,一个指针就占用 8 个字节。这意味着,每个节点都有 8 + 8 = 16 字节的固定指针开销。
想象一下,如果你要存储的数据只是一个很小的整数(例如数字 5,实际只需要 1 字节),那么为了存储这 1 字节的数据,你就要付出 16 字节的指针开销。这就像用一个巨大的集装箱去运送一粒米,内存利用率极低。
Ziplist 的解决方案:
Ziplist 将所有元素存储在一块连续的内存中,从根本上就不需要 next 和 prev 指针。
- 如何向后遍历? 因为内存是连续的,知道当前节点的起始地址和它的总长度,就可以计算出下一个节点的起始地址。
- 如何向前遍历?(这是精髓) Ziplist 的每个节点(entry)内部都包含一个
previous_entry_length字段,它记录了前一个节点的长度。当需要向前遍历时,用当前节点的起始地址减去这个长度,就能精确地定位到前一个节点的起始位置。这个previous_entry_length字段本身也是变长的(1或5字节),远比一个8字节的指针要小。
效果对比:
- 双向链表:
N个节点就有N * 16字节的指针开销。 - Ziplist:0 字节的指针开销。
2. 变长编码:按需分配,杜绝浪费
传统结构的问题:
在 C 语言等静态语言中,数据类型通常有固定的大小。例如,int 类型可能固定为 4 字节。如果你要存储数字 10,它实际上只需要 1 个字节,但系统依然会为其分配 4 字节,剩下的 3 字节就被浪费了。
Ziplist 的解决方案:
Ziplist 节点的 encoding 字段可以非常灵活地定义数据的存储方式,真正做到“用多少,给多少”。
- 对于整数:
- 如果整数值可以用 1 个字节表示(比如 0-255),
encoding就会指明这是一个单字节整数,content部分就只占用 1 字节。 - 如果需要 2 个字节,
content就占用 2 字节。 - …以此类推,支持多种长度的整数。
- 如果整数值可以用 1 个字节表示(比如 0-255),
- 对于字符串:
encoding字段会记录字符串的长度,然后content部分就紧跟相应长度的字节数组。
这种设计避免了为了容纳“可能的最大值”而预先分配固定大小的空间,而是根据“实际值”来动态决定使用多大的空间。
3. 紧凑的整体布局
除了上述两点,Ziplist 还有一个整体上的优势:
- 单一的头部信息: 整个 Ziplist 只有一个
zlbytes,zltail,zllen的头部(总共 10 字节)。而双向链表的“头部”(即指针)是分散在每一个节点里的。 - 连续内存: 连续的内存布局减少了内存碎片,并且有利于 CPU 的缓存(Cache),在遍历时能获得更好的性能。
综合示例:一个直观的对比
假设我们要在 64 位系统上存储一个列表:["hello", 99]

-
双向链表实现:
- 节点1 (“hello”): 16字节(指针) + 6字节(数据"hello\0") ≈ 22字节
- 节点2 (99): 16字节(指针) + 8字节(假设用long存储) = 24字节
- 总计 ≈ 46 字节
-
Ziplist 实现:
-
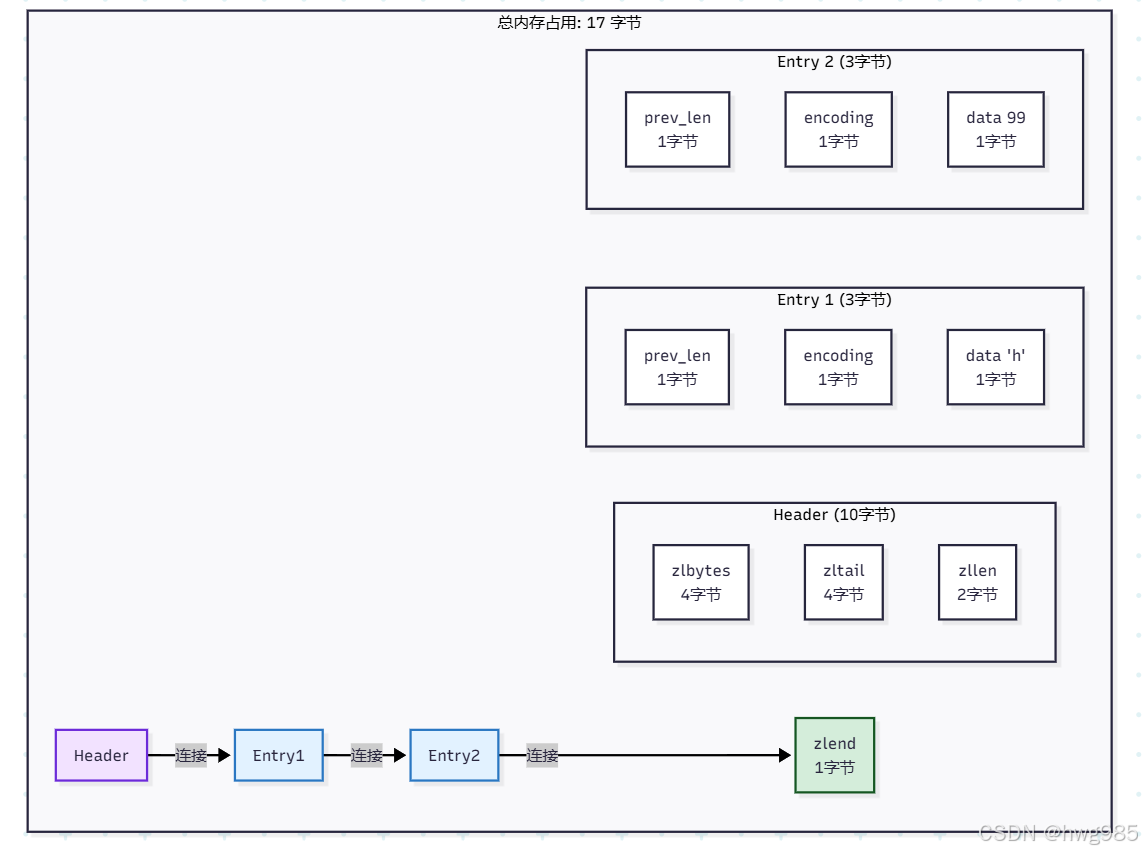
- 头部: 10字节 (
zlbytes+zltail+zllen) - 节点1 (“hello”): 1字节(
prev_len) + 1字节(encoding) + 5字节(数据) = 7字节 - 节点2 (99): 1字节(
prev_len) + 1字节(encoding) + 1字节(数据) = 3字节 - 结尾: 1字节 (
zlend) - 总计 = 10 + 7 + 3 + 1 = 21 字节
- 头部: 10字节 (
可以看到,对于小数据量的场景,Ziplist 的内存压缩效果非常显著。
Ziplist的代价:连锁更新
这种极致的压缩是有代价的。最主要的问题就是连锁更新(Cascading Update)。由于每个节点记录的是前一个节点的长度,当在列表的某个位置插入一个新节点,或者删除了一个节点,可能会导致其后续所有节点的 previous_entry_length 字段需要更新,这种更新可能会像多米诺骨牌一样传播下去,导致一次插入/删除操作的时间复杂度在最坏情况下达到 O(N²),性能较差。
正因为如此,Ziplist 只适用于存储元素数量较少、内容较小的场景(List, Hash, Zset),并且在后来的 Redis 版本中,逐渐被性能更稳定的 Listpack 所取代。