Arxiv-Daily
Daily Paper Report - 2025-07-24 12:53
Today’s Recommended Papers
1. Multi-modal Multi-task Pre-training for Improved Point Cloud Understanding
Authors: Liwen Liu, Weidong Yang, Lipeng Ma, Ben Fei
Deep-Dive Summary:
多模态多任务预训练以改善点云理解
预印本
Liwen Liu’,Weidong Yang’,Lipeng Ma, Ben Fei
1 复旦大学
2 香港中文大学
liwenliu21@m.fudan.edu.cn, wdyang@fudan.edu.cn, lpma@m.fudan.edu.cn, benfei@cuhk.edu.hk
摘要
最近,多模态预训练方法的进步显示出通过对齐 3D 形状与其对应 2D 对应物的多模态特征来学习 3D 表示的有效性。然而,现有的多模态预训练框架主要依赖于单一预训练任务来收集多模态数据,这限制了模型从其他相关任务中获取丰富信息,从而影响其在下游任务中的性能,尤其是在复杂和多样的领域。为解决这一问题,我们提出 MMPT(Multi-modal Multi-task Pre-training),这是一个设计用于增强点云理解的多模态多任务预训练框架。具体来说,我们设计了三个预训练任务:(i) Token-level reconstruction (TLR) 旨在恢复被掩码的点 token,从而赋予模型代表性学习能力;(ii) Point-level reconstruction (PLR) 整合用于直接预测被掩码的点位置,重建的点云可视为后续任务中的变换点云;(iii) Multi-modal contrastive learning (MCL) 结合了模态内和模态间的特征对应关系,从而从 3D 点云和 2D 图像模态中以自监督方式汇集丰富的学习信号。而且,该框架无需任何 3D 标注,使其适用于大型数据集。训练后的编码器可以有效转移到各种下游任务。为了证明其有效性,我们在广泛使用的基准上评估了其在各种判别性和生成性应用中的性能,并与其他最先进方法进行了比较。
多任务 · 预训练 · 点云 · 自监督
1 引言
3D 视觉理解近年来备受关注,因为其在增强现实 (AR)、虚拟现实 (VR)、自动驾驶、元宇宙和机器人等领域中的应用日益增多 [Fei et al., 2022a, 2023, Zhu et al., 2024]。点云理解的初始阶段涉及提取判别性几何特征,使用各种神经网络,如 PointNet [Qi et al., 2017a]、PointNet++ [Qi et al., 2017b] 和 DGCNN [Wang et al., 2019],以改善下游任务,如分类和分割 [Zhang et al., 2024, Xie et al., 2024, Xu et al., 2025]。然而,收集和标注 3D 数据的过程代价高昂且劳动密集 [Yu et al., 2022, Huang et al., 2021]。虽然在合成扫描上训练显示出缓解真实世界标注数据稀缺的潜力,但以此方式训练的 GRL 模型容易受到域移位的影响 [He et al., 2022, Zhang et al., 2022a]。
自监督学习 (SSL) 作为一种无监督学习范式,为监督模型的局限性提供了解决方案,并在 2D 领域取得了成功 [Chen et al., 2020, Liu et al., 2025a,b]。这激发了最近对利用自监督学习提取 3D 点云强大特征的兴趣 [Fei et al., 2024a,b,c]。现有的自监督学习方法大多采用编码器-解码器架构,其中编码器的参数基于解码器对点云对象的重建来更新 [Liu et al., 2022]。然而,这些方法面临几个挑战,包括:i) 由于点云的离散性质,重建 3D 对象并非总是可行的;ii) 单模态损失,如均方误差和交叉熵,无法充分捕捉原始数据中的各种几何细节。
为此,研究人员探索了更丰富的可用模态,如图像,以为 3D 表示学习提供额外的监督信号 [Afham et al., 2022, Zhang et al., 2022b]。这种方法不仅改善了单模态数据的表示能力,还促进了更全面的多模态表示能力的发展 [Zhu et al., 2022]。这些努力显示出有前景的结果,并部分缓解了 3D 领域对密集标注单模态数据的需求。然而,这些多模态预训练方法仍依赖于单一预文本任务,这限制了从其他相关预文本任务中获取丰富信息,从而阻碍了预训练模型在下游任务中的性能。
为应对这些挑战,我们引入 MMPT(Multi-modal Multi-task Pre-Training),这是一个用于自监督点云表示学习的框架。具体来说,我们设计了三个预文本任务:(i) Token-Level Reconstruction (TLR) 通过交叉熵恢复被掩码的 token,这是一种常见的点云数据预训练方法。如前所述,虽然该预文本任务有助于学习全局表示,但它不足以捕捉点云的详细几何;为了增强编码器的代表性学习能力,我们结合了其他两个预文本任务;(ii) Point-Level Reconstruction (PLR) 旨在解决点云离散性质带来的重建挑战。此外,从该预文本任务重建的点云可视为变换点云,并用于最终任务;(iii) Multi-modal Contrastive Learning (MCL) 包括模态内学习和模态间学习。在无需手动标注的多模态多任务预训练后,我们可以将训练后的编码器转移到各种下游任务。我们通过与广泛使用的基准比较来证明我们的优越性能。
MMPT 的贡献可总结如下:
- 我们提出 MMPT,这是一个新颖的多模态多任务预训练框架,用于改善点云理解。这是首次将多任务预训练整合到 3D 点云预训练中。
- MMPT 框架包括三个预文本任务:token-level reconstruction、point-level reconstruction 和 multi-modal contrastive learning。这些任务协同工作,产生一个强大的编码器,可无缝转移到下游任务中,并高度有效。
- 在五个不同的下游任务上,我们实现了可比性能,超过了竞争对手,并展示了改进的泛化能力。此外,我们通过与现有自监督学习方法比较来分析我们方法的优势。
2 相关工作
2.1 自监督学习在点云上的应用
自监督学习 (SSL) 旨在从无标注数据中提取鲁棒且通用的特征,从而减少耗时的数据标注,并实现优秀的转移学习性能。
生成方法通过自重建学习特征,将点云编码成特征或分布,然后解码回原始点云 [Fei et al., 2024d, 2025a]。最近,基于 Transformer 架构的各种自监督方法被提出。例如,Point-BERT [Yu et al., 2022] 预测离散 token,而 Point-MAE [Liu et al., 2022] 随机掩码输入点云中的 patch 并重建缺失点。生成方法的替代方案是使用生成对抗网络进行生成建模。
判别方法通过利用辅助手工预设预测任务来学习点云表示。例如,Jigsaw3D [Sauder and Sievers, 2019] 使用 3D Jigsaw 拼图作为自监督任务,并利用对比技术训练编码器以用于下游任务。PointContrast [Xie et al., 2020a] 引入一个预文本任务,强调从不同视角保持单个点云一致的表示,专注于高级场景理解任务。在此基础上,它调查了一个统一的对比范式,并扩展到 3D 和 2D 模态,强调它们之间的强大共享特征。尽管需要挑战性的点云渲染结果,该方法简单且高效。为了促进对比学习任务,Du et al. [Du et al.] 提出了一种基于对比学习的框架,此外,他们主动获取接近正样本的硬负样本以增强判别特征学习过程。STRL [Huang et al., 2021] 是 BYOL 到 3D 点云的扩展,利用了类似的框架。与生成和判别方法不同,我们提出了一种更全面的方法,通过利用多任务预训练结合两者的优势,从而获得更好的表示。
2.2 多模态表示学习
本文旨在利用 3D 点云以外的模态(如 2D 图像)固有的额外学习信号。这些模态包含丰富的上下文、纹理信息以及密集语义。然而,该领域的当前方法主要关注全局特征匹配的对比学习 [Afham et al., 2022, Fei et al., 2025b, 2022b]。例如,[Jing et al., 2021] 提出了一种判别中心损失来对齐点云、网格和图像的特征。[Afham et al., 2022] 呈现了一个模态内和模态间对比学习框架,作用于增强点云及其对应 2D 图像。另一种方法涉及利用先验几何信息建立密集关联并探索细粒度局部特征匹配。例如,Liu et al. [Liu et al., 2021] 提出了一种对比知识蒸馏方法来对齐细粒度 2D 和 3D 特征,而 [Li et al., 2022] 引入了一个简单的对比学习框架,用于模态间和模态内密集特征对比,使用匈牙利算法来改善对应。最近,通过直接利用预训练 2D 图像编码器进行监督微调,已经取得了重大进展。同时,P2P [Wang et al., 2022] 提出将 3D 点云投影到 2D 图像上,并通过一个可学习的着色模块将它们输入图像主干。
2.3 多任务预训练
多任务学习涉及训练模型从单个输入预测多个输出域。一种常见技术是使用一个单一编码器获取共享表示,然后通过多个任务特定解码器 [Ghiasi et al., 2021]。与此不同,我们的方法在输入和输出中都整合了多个任务,并伴随掩码。此外,一些研究表明,仅从单一任务学习是不够的,使用一组任务可以更全面地涵盖视觉中的潜在下游任务。我们的 MMPT 利用多个任务来获取更通用的表示,从而能够处理多个下游任务。
3 MMPT 框架
3.1 概述
我们的 MMPT 整体框架如 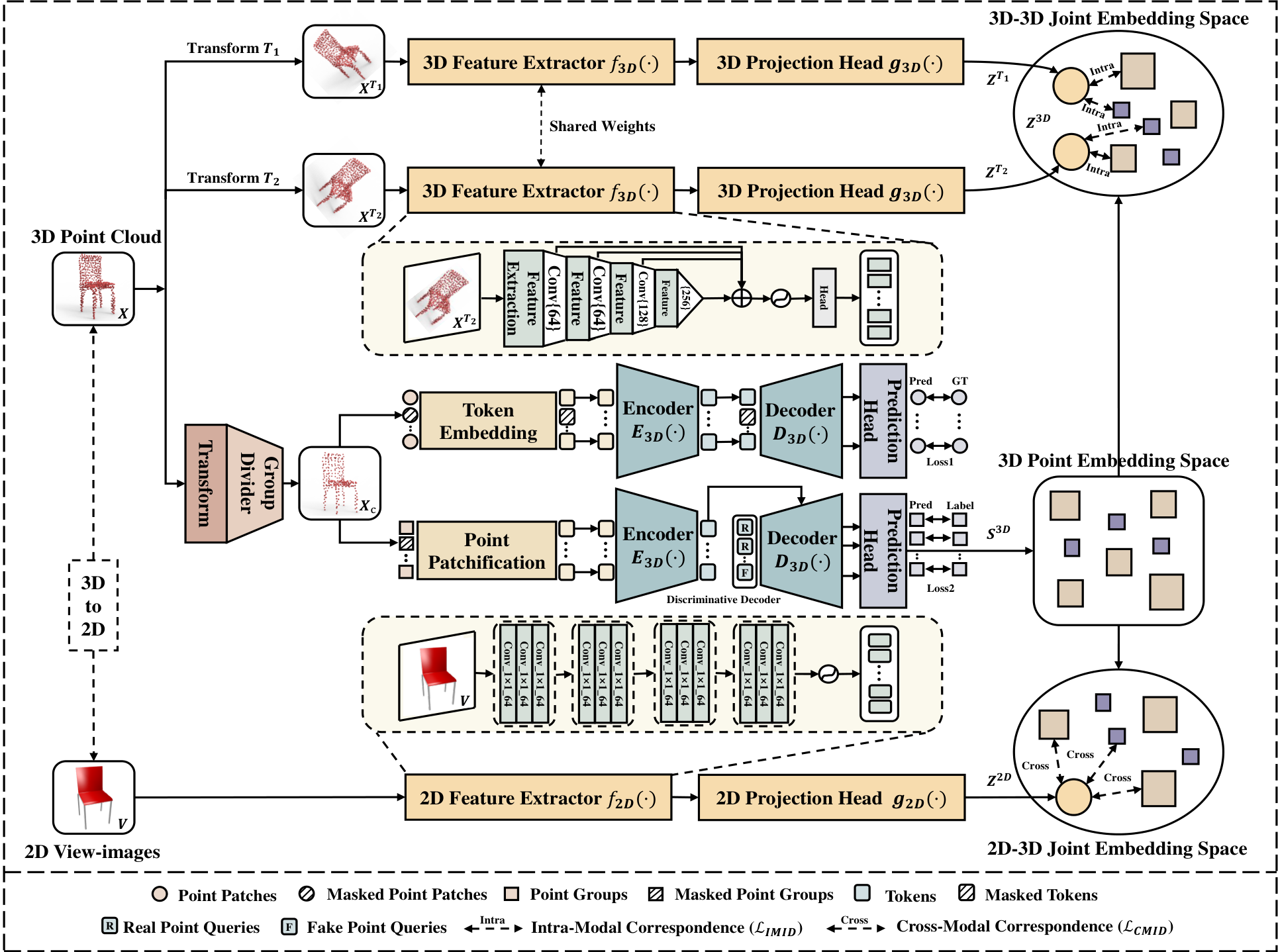 所示。MMPT 框架包括三个主要预文本任务:TLR 中的掩码点 token 预测任务、PLR 中的掩码点组预测任务,以及 MCL 中的 2D 图像-3D 点云对应任务,如第 3.2 节所述,这增强了 Transformer 架构的分类能力。然后,在第 3.3 节中,我们介绍了掩码点组预测任务,这改善了主干的生成能力。最后,在第 3.4 节中,我们详细说明了 2D 图像-3D 点云对应网络。
所示。MMPT 框架包括三个主要预文本任务:TLR 中的掩码点 token 预测任务、PLR 中的掩码点组预测任务,以及 MCL 中的 2D 图像-3D 点云对应任务,如第 3.2 节所述,这增强了 Transformer 架构的分类能力。然后,在第 3.3 节中,我们介绍了掩码点组预测任务,这改善了主干的生成能力。最后,在第 3.4 节中,我们详细说明了 2D 图像-3D 点云对应网络。
3.2 TLR 中的掩码点 token 预测任务
掩码和嵌入阶段。由于点云是一组无序点,将其分组成点 patch 已显示能更好地理解和描述 3D 形状的局部信息。如 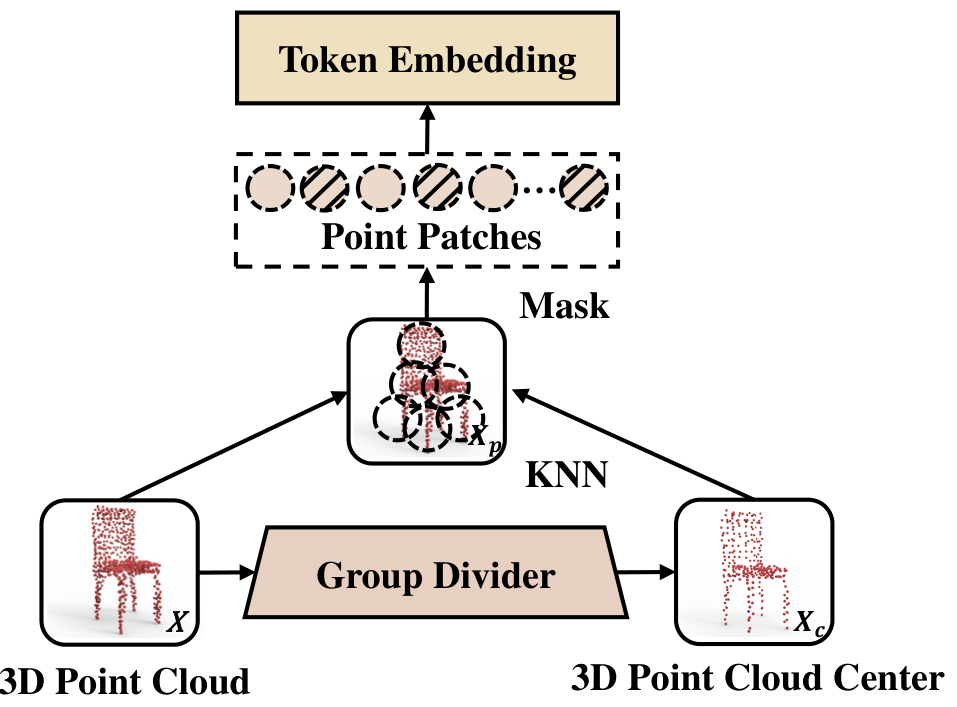 所示,掩码和嵌入阶段旨在提供更准确、详细和语义化的点云数据。在此阶段,输入点云被分为不规则点 patch,然后这些 patch 被随机掩码并嵌入成 token。
所示,掩码和嵌入阶段旨在提供更准确、详细和语义化的点云数据。在此阶段,输入点云被分为不规则点 patch,然后这些 patch 被随机掩码并嵌入成 token。
具体来说,假设输入点云为 X∈RN×3X \in \mathbb{R}^{N \times 3}X∈RN×3,我们首先使用 Furthest Point Sampling (FPS) 采样 MMM 个中心点,以固定采样比率从整体点云 XXX 中下采样。然后,通过中心点及其邻域点形成点 patch,使用 K-nearest neighborhood 算法 (KNN):
Xc=FPS(X)Xp=KNN(X,Xc)\begin{array}{c} X_c = \text{FPS}(X) \\ X_p = \text{KNN}(X, X_c) \end{array} Xc=FPS(X)Xp=KNN(X,Xc)
我们选择随机掩码策略,以尽可能分开掩码点 patch,同时通过考虑点 patch 重叠保持信息完整。对于掩码比率,我们根据实验结果设置为高比率 γ=0.8\gamma = 0.8γ=0.8,以更好地从可见点 patch PvisP_{\text{vis}}Pvis 中获取潜在表示。
应用随机掩码策略后,我们使用 mini-PointNet 实现 token 嵌入,作为编码器的输入,该网络由多层感知机 (MLP) 和最大池化组成:
Dγvi:s⟹DDO∙DDDD(Dv1˙S)\begin{array}{l} \mathcal{D}^{\gamma} v_i : s \implies \mathcal{D}^{\mathcal{D}} O^{\bullet} \mathcal{D} \mathcal{D} \mathcal{D} \mathcal{D} \left( \mathcal{D}_{v \dot{1} \mathcal{S}} \right) \end{array} Dγvi:s⟹DDO∙DDDD(Dv1˙S)
特别是,点云在 3D 数据中具有位置信息。由于点 patch 是中心归一化的,附加中心的位置嵌入是必要的。遵循先前研究 [Yu et al., 2022],我们使用一个小型 MLP 网络从中心坐标学习位置嵌入。
不对称自编码器阶段。在此阶段,我们采用将掩码 token 转移到解码器的策略,这不仅避免了泄露位置信息,还提高了计算效率。受 MAE [He et al.] 启发,我们设计了一个不对称编码器-解码器。在预训练期间,编码器以可见 token TvisT_{\text{vis}}Tvis 为输入,并在每个 Transformer 块中添加位置嵌入 (PE) 以提供 patch 位置信息。处理后,输出为 Tenc∈Rb×DT_{\text{enc}} \in \mathbb{R}^{b \times D}Tenc∈Rb×D(其中 DDD 表示嵌入维度),公式为:
Tenc=ΛbD(Tvis,PF)T_{\text{enc}} = \Lambda_{b D} \left( T_{\text{vis}}, P_{\mathcal{F}} \right) Tenc=ΛbD(Tvis,PF)
解码器类似于 Point-MAE [Pang et al., 2022],使用标准 Transformer 具有更少的块。解码器将编码的可见 token TencT_{\text{enc}}Tenc、掩码 token TmaskT_{\text{mask}}Tmask 及其位置嵌入 PE 输入标准 Transformer,定义为:
Hmask=D3D(concat(Tenc,Tmask),PE)H_{\text{mask}} = D_{3D} \left( \text{concat} \left( T_{\text{enc}}, T_{\text{mask}} \right), P_{\mathcal{E}} \right) Hmask=D3D(concat(Tenc,Tmask),PE)
最后,解码器输出 HmaskH_{\text{mask}}Hmask 输入全连接 (FC) 层以重建掩码点 patch:
Ppre=NdesJdLU(F(Hmask))P_{\text{pre}} = \mathcal{N}_{des} \mathcal{J}_d \mathcal{L} \mathcal{U} \left( \mathcal{F} \left( H_{\text{mask}} \right) \right) Ppre=NdesJdLU(F(Hmask))
3.3 PLR 中的掩码点组预测任务
在掩码点组预测任务中,包括两个主要部分:掩码 Transformer 和判别解码器。掩码 Transformer 用于建模稀疏分布的未掩码组之间的相关性,而判别解码器辅助网络基于少量可见点组预测 3D 形状。
分组和掩码阶段。如 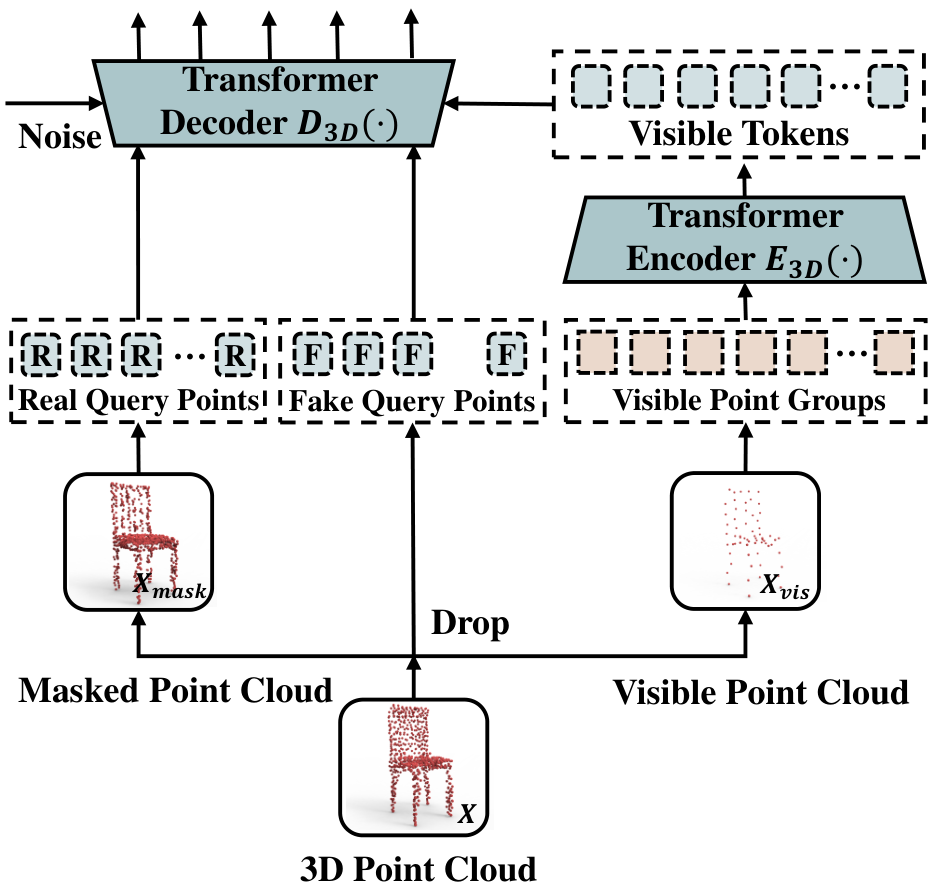 所示,首先考虑输入点云 X∈RN×3X \in \mathbb{R}^{N \times 3}X∈RN×3,使用 FPS 下采样产生 patch 中心。然后,对于每个 patch 中心,我们找到一个邻域,通过随机掩码一比例,将点组分为掩码组 XmaskX_{\text{mask}}Xmask 和未掩码组 XvisX_{\text{vis}}Xvis。
所示,首先考虑输入点云 X∈RN×3X \in \mathbb{R}^{N \times 3}X∈RN×3,使用 FPS 下采样产生 patch 中心。然后,对于每个 patch 中心,我们找到一个邻域,通过随机掩码一比例,将点组分为掩码组 XmaskX_{\text{mask}}Xmask 和未掩码组 XvisX_{\text{vis}}Xvis。
掩码 Transformer 阶段。编码器以可见局部组为输入,输出全局表示,由堆叠的多头自注意力层 (MSA) 和全连接前馈网络 (FFN) 组成。在输入编码器前,可见组 XvisX_{\text{vis}}Xvis 通过轻量级 PointNet 实例化为组嵌入 TgroupT_{\text{group}}Tgroup,并通过 MLP 转换为位置嵌入 TposT_{\text{pos}}Tpos。
形式上,我们定义深度表示作为输入嵌入 TinputT_{\text{input}}Tinput,这是 TgroupT_{\text{group}}Tgroup 和 TposT_{\text{pos}}Tpos 的组合。受 ViT 启发,我们在输入序列前面附加一个 [CLS] token,这在学习点云整体结构中起关键作用,并应用于下游任务。经过编码器网络的多个块后,我们获得最后一层的输出 Ti={[C’LS],t1,t2}T_i = \{ [\text{C'LS}], t_1, t_2 \}Ti={[C’LS],t1,t2},表示输入组的编码表示,具有全局感受野。
判别解码器阶段。解码器以特征表示为输入,通过 MLP 分类头输出 logits S3DS_{3D}S3D 和预测查询 QpreQ_{\text{pre}}Qpre。特别地,我们表示一系列从掩码组采样的真实查询 QrealQ_{\text{real}}Qreal 和从整个 3D 空间采样的假查询 QfakeQ_{\text{fake}}Qfake。随后,一层 Transformer 解码器输入 {Qreal+pos}∪{Qfake+pos}\{ Q_{\text{real}} + \text{pos} \} \cup \{ Q_{\text{fake}} + \text{pos} \}{Qreal+pos}∪{Qfake+pos},并对每个查询 q∈{Qreal,Qfake}q \in \{ Q_{\text{real}}, Q_{\text{fake}} \}q∈{Qreal,Qfake} 通过交叉注意力 CA(q,t′+pos)\text{CA}(q, t' + \text{pos})CA(q,t′+pos) 与编码器输出进行操作。这种策略训练解码器区分真实和假查询,具有两个优势:首先,它帮助网络基于少量可见点组推断 3D 结构;其次,它不预测掩码组的坐标,从而防止位置信息泄露。
3.4 MCL 中的 2D 图像-3D 点云对应任务
为了增强对 3D 点云的理解,我们以自监督方式从 3D 点云和 2D 图像中学习可转移表示,基于最近的模态内学习 [Chen et al., 2020] 和模态间学习 [He et al., 2022, Pang et al., 2022, Zhang et al., 2022a]。
模态内学习。模态内学习的目标是鼓励相同点云的不同投影向量相似,同时与其它点云的投影向量不同。我们在 IMID 中应用常见的 3D 变换,包括缩放、旋转、归一化、弹性扭曲、平移和点丢失。
这些是通过对输入点云 XXX 应用变换 TTT 的顺序组合随机获得的。为了产生变换版本的特征嵌入并构建特征向量 ZTZ^TZT 在不变空间,我们依次使用特征提取器 f3D()f_{3D}()f3D() 和投影头 g3D()g_{3D}()g3D()。作为学习目标,我们最小化变换版本的均值与 3D logits S3DS_{3D}S3D 之间的相对距离,使用超参数 TTT 通过 NT-Xent 损失 [Chen et al., 2020] 调整动态范围,定义为:
ℓi,z3D,s3D=−logexp(sim(zi3D,zk3D)/τ)+∑k=1Nexp(sim(zi3D,sk3D)/τ)∑k=1N(zii1+zit2),ZT=g3D(f3D(XT))\begin{array}{l} \ell_{i,z^{3D},s^{3D}} = \\ -\log \frac{\exp(\text{sim}(z_i^{3D}, z_k^{3D})/\tau) + \sum_{k=1}^{N} \exp(\text{sim}(z_i^{3D}, s_k^{3D})/\tau)}{\sum_{k=1}^{N} \left( z_i^{i_1} + z_i^{t_2} \right)}, \\ Z^T = g_{3D} \left( f_{3D} \left( X^T \right) \right) \end{array} ℓi,z3D,s3D=−log∑k=1N(zii1+zit2)exp(sim(zi3D,zk3D)/τ)+∑k=1Nexp(sim(zi3D,sk3D)/τ),ZT=g3D(f3D(XT))
其中 TTT 是控制输出分布平滑度的温度超参数,z3Dz^{3D}z3D 表示点云 XXX 的均值投影向量。
模态间学习。模态间学习的目标是利用 2D 图像和 3D 点云之间的隐式几何和语义相关性,从而辅助 3D 表示学习。与稀疏且不规则的点云不同,2D 图像可以提供细粒度几何和高水平语义。
我们将 2D 图像投影到特征空间作为 f2D()f_{2D}()f2D()。在 2D 特征向量之上,使用图像投影头 g2D()g_{2D}()g2D() 将它们投影到不变空间作为向量 Z2DZ^{2D}Z2D。为此,我们使用对比学习确保相似性,如:
ℓi,s3D,z2D=−logexp(sim(si3D,sk2D)/τ)+∑k=1Qexp(sim(si3D,zk2D)/τ)∑k=1Qexp(sim(si3D,zk2D)/τ)where sim(si3D,zi2D)=si3D⋅zi2D∥si3D∥∥zi2D∥\begin{array}{l} \ell_{i,s^{3D},z^{2D}} = \\ -\log \frac{\exp(\text{sim}(s_i^{3D}, s_k^{2D})/\tau) + \sum_{k=1}^{\mathcal{Q}} \exp(\text{sim}(s_i^{3D}, z_k^{2D})/\tau)}{\sum_{k=1}^{\mathcal{Q}} \exp(\text{sim}(s_i^{3D}, z_k^{2D})/\tau)} \\ \text{where } \text{sim}(s_i^{3D}, z_i^{2D}) = \frac{s_i^{3D} \cdot z_i^{2D}}{\| s_i^{3D} \| \| z_i^{2D} \|} \end{array} ℓi,s3D,z2D=−log∑k=1Qexp(sim(si3D,zk2D)/τ)exp(sim(si3D,sk2D)/τ)+∑k=1Qexp(sim(si3D,zk2D)/τ)where sim(si3D,zi2D)=∥si3D∥∥zi2D∥si3D⋅zi2D
3.5 损失函数
损失函数包括四个部分:重建项 LrecL_{\text{rec}}Lrec、MoCo 项 LMoCoL_{\text{MoCo}}LMoCo、模态内学习项 LIMLL_{\text{IML}}LIML 和模态间学习项 LCMLL_{\text{CML}}LCML。整体联合损失为:
Ljoint=αLrec+βLMoCo+γLIML+γLCML\mathcal{L}_{\text{joint}} = \alpha \mathcal{L}_{\text{rec}} + \beta \mathcal{L}_{\text{MoCo}} + \gamma \mathcal{L}_{\text{IML}} + \gamma \mathcal{L}_{\text{CML}} Ljoint=αLrec+βLMoCo+γLIML+γLCML
其中 α\alphaα、β\betaβ 和 γ\gammaγ 是平衡不同损失项的超参数。
重建项。我们通过 L2 归一化 Chamfer Distance (CD) 和二元焦点损失最小化预测 patch 与真实 patch 之间的相对距离,如:
$$
\begin{array}{c}
\mathcal{L}{\text{rec}} = \mathcal{L}{\text{rec.cd}}(P_{\text{pre}}, P_{\text{gt}}) + \mathcal{L}{\text{rec.bce}}(Q{\text{pre}}, Q_{\text{labels}}) \
= \frac{1}{|P_{\text{pre}}|} \sum_{p \in P_{\text{pre}}} \min_{g \in P_{\text{gt}}} | p - g |2^2 + \frac{1}{|P{\text{gt}}|} \sum_{g \in P_{\text{gt}}} \min_{p \in P_{\text{pre}}} | g - p |_2^2 \
- \frac{1}{N} \sum_i^N \sum_i^N \phi_i^N | l \times \log§ + (1 - l) \times \log(1 - p) |
\end{array}
$$
MoCo 项。基于掩码点组预测模块,我们获得 3D logits S3DS_{3D}S3D。MoCo 损失为:
LMoCo=1N∑i=1N−logexp(si3D⋅skilabels/τ)∑j=0Kexp(si3D⋅skjlabels)\mathcal{L}_{\text{MoCo}} = \frac{1}{N} \sum_{i=1}^{N} -\log \frac{\exp( s_i^{3D} \cdot s_{ki}^{\text{labels}} / \tau )}{\sum_{j=0}^{K} \exp( s_i^{3D} \cdot s_{kj}^{\text{labels}} )} LMoCo=N1i=1∑N−log∑j=0Kexp(si3D⋅skjlabels)exp(si3D⋅skilabels/τ)
模态内学习项。扩展方程 6,我们定义模态内学习损失为:
LIML=12M∑i=1N(ℓi,z3D,s3D+ℓi,s3D,z3D)\mathcal{L}_{\text{IML}} = \frac{1}{2M} \sum_{i=1}^{N} \left( \ell_{i, z^{3D}, s^{3D}} + \ell_{i, s^{3D}, z^{3D}} \right) LIML=2M1i=1∑N(ℓi,z3D,s3D+ℓi,s3D,z3D)
模态间学习项。扩展方程 7,我们获得模态间对比学习目标:
LCML=∑i=1N(ℓi,s3D,z2D+ℓi,z2D,s3D)\mathcal{L}_{\text{CML}} = \sum_{i=1}^{\mathcal{N}} \left( \ell_{i, s^{3D}, z^{2D}} + \ell_{i, z^{2D}, s^{3D}} \right) LCML=i=1∑N(ℓi,s3D,z2D+ℓi,z2D,s3D)
4 实验
4.1 预训练设置
预训练数据集。我们使用 ShapeNetRender [Afham et al., 2022] 作为预训练数据集,用于几个下游点云理解任务。此外,我们还利用 ShapeNetRender [Afham et al., 2022] 中的彩色单视图图片。每个 RGB 图像与深度图像、法线图和反照率图像相关联,具有更大的相机角度多样性。
Transformer 架构。我们的目标是通过多任务预训练开发一个具有鲁棒泛化能力的预训练模型。我们使用两个独立的 Transformer:一个 Token-Level Transformer Auto-Encoder 用于获取点特征,以及 MaskTransformer 用于点级重建。遵循 Point-BERT [Yu et al., 2022],我们构建了一个 12 层的标准 Transformer 编码器。
预训练细节。与 [Yu et al., 2022] 一致,我们使用 AdamW 优化器,权重衰减为 0.05,学习率为 5×10−45 \times 10^{-4}5×10−4,并余弦衰减。模型以批量大小 4 训练 100 个周期,包括随机缩放和平移数据增强。
4.2 下游任务
4.2.1 合成数据上的 3D 对象分类
我们在 ModelNet40 基准上评估 3D 对象分类方法。如 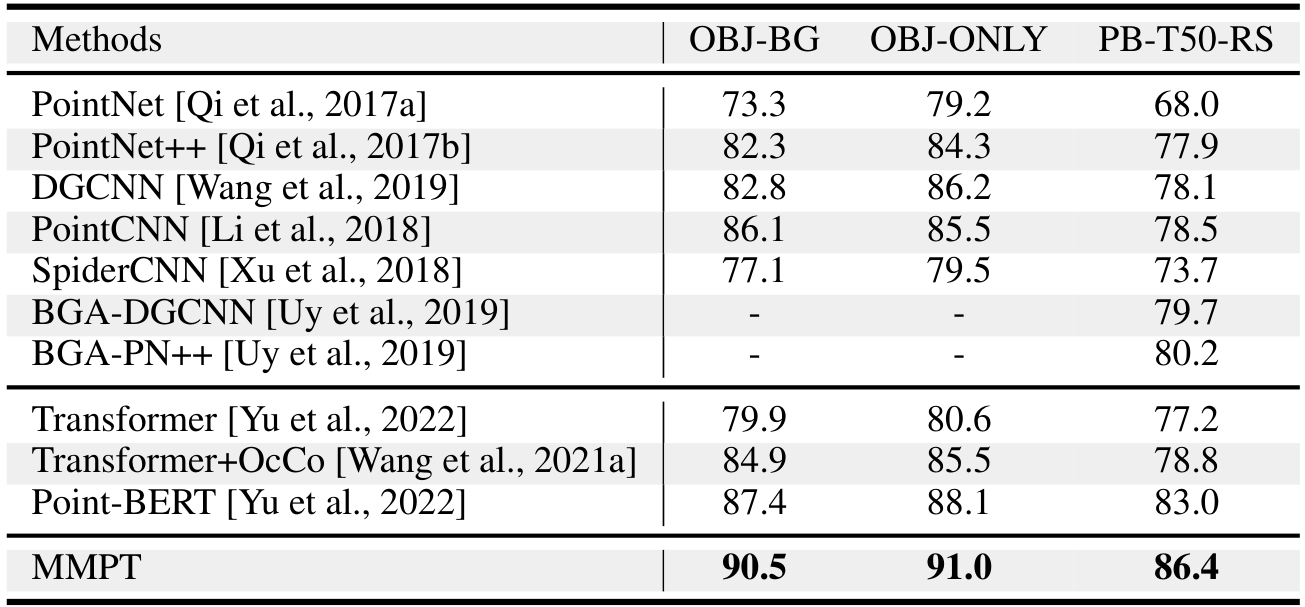 所示,我们的方法在 ModelNet40 上实现了 93.9% 的准确率,超过了竞争对手。
所示,我们的方法在 ModelNet40 上实现了 93.9% 的准确率,超过了竞争对手。
4.2.2 真实世界数据上的 3D 对象分类
我们在 ScanObjectNN 数据集上评估方法。如 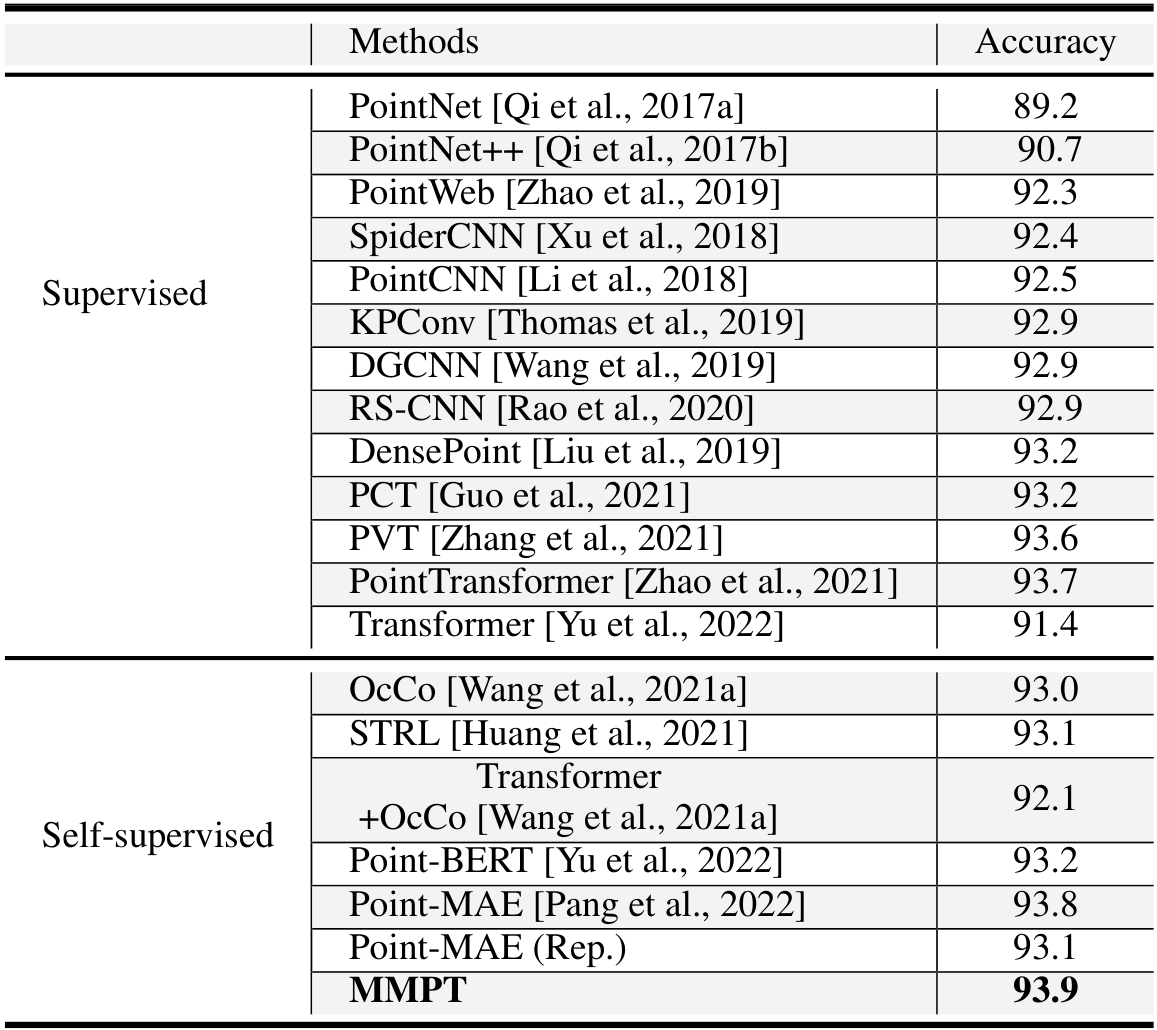 所示,我们的方法在最具挑战性的 PB-T50-RS 上达到 86.4% 的准确率。
所示,我们的方法在最具挑战性的 PB-T50-RS 上达到 86.4% 的准确率。
4.2.3 3D 部分分割
如 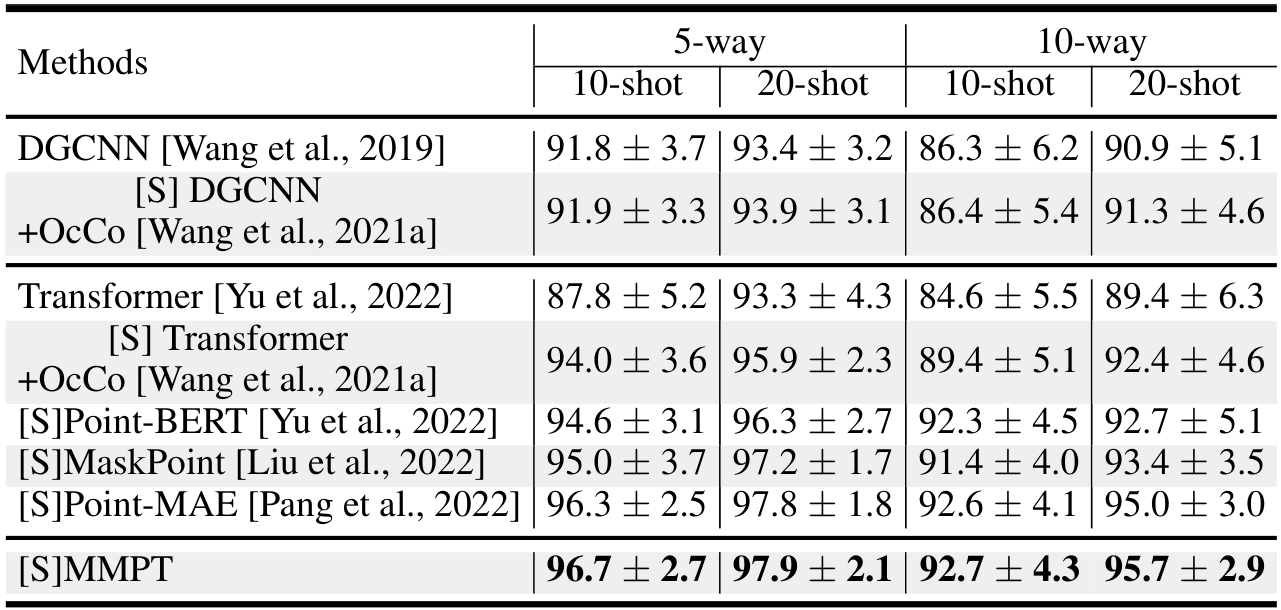 所示,我们的方法在 ShapeNetPart 上取得了领先的 mIoU。
所示,我们的方法在 ShapeNetPart 上取得了领先的 mIoU。
其他实验结果如 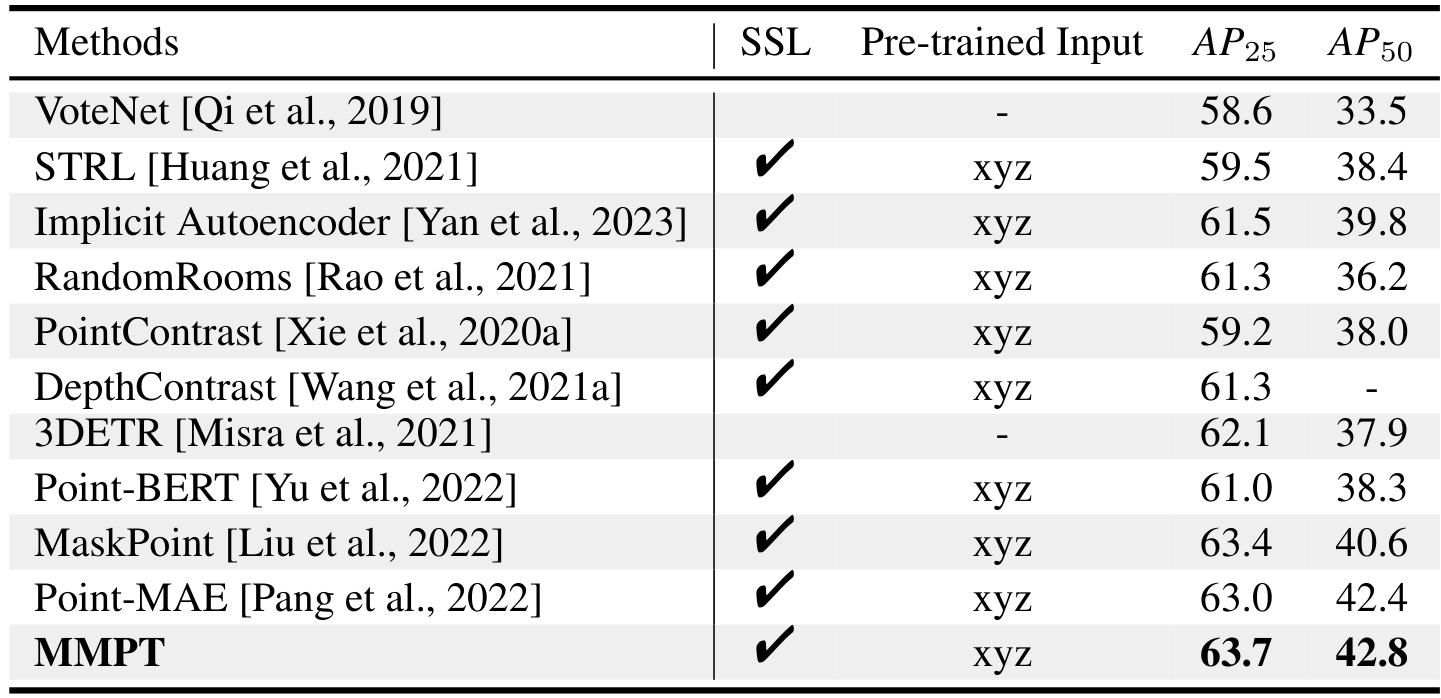 和
和 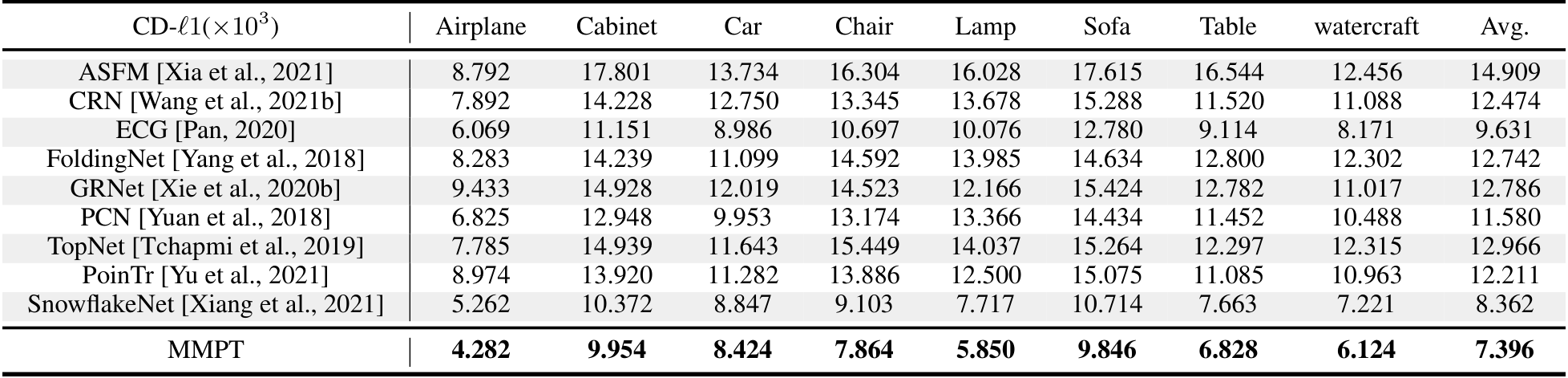 所示,证明了 MMPT 在 3D 对象检测和形状完成任务中的优越性能。
所示,证明了 MMPT 在 3D 对象检测和形状完成任务中的优越性能。
4.2.4 少样本分类
少样本学习的目的是通过利用先验知识,在有限的标记训练样本下处理新颖任务。在本研究中,我们在k类和m样本的条件下,将我们的方法与其他方法的性能进行比较,其中我们从ModelNet40中为每k类采样m个样本。具体来说,我们在Table 3中呈现了k ∈ {5, 10}和m ∈ {10, 20}的设置。结果显示,我们的方法在所有四个不同设置下 consistently 实现了最高的平均准确率,比其他方法有显著优势。特别地,我们的MMPT方法相对于Point-MAE模型[Pang et al., 2022]实现了0.4%、0.1%、0.1%和0.7%的显著改进,这突显了我们方法强大的泛化能力。
4.2.5 室内3D语义分割
此外,我们评估了我们提出的MMPT在大型场景的3D语义分割中的性能。这一任务面临重大挑战,因为它需要理解全局语义和局部几何细节。我们在Table 5中呈现了实验的详细定量结果。显著地,我们的MMPT相对于从零开始训练的Transformer,实现了3.2%的平均准确率(mAcc)和4.2%的平均交并比(mIoU)的提升。这证明了我们的MMPT有效地增强了Transformer处理 demanding 下游任务的能力。而且,我们的MMPT超越了其他自监督方法,在mAcc和mIoU上分别比第二好的方法Point-MAE提高了1.4%和0.3%。与依赖场景几何特征和颜色的方法(如Table 5中排名前四的方法)相比,我们的MMPT展示了优越性能。

4.2.6 室内3D物体检测
此外,我们继续评估我们的MMPT在3D物体检测任务中的性能,该任务需要方法对大型场景有 robust 理解。为此,我们在广泛使用的真实世界数据集ScanNet V2上进行了实验。结果在Table 6中以AP25和AP50指标呈现。与从零开始训练的方法和预训练方法相比,我们的方法实现了最高的AP25和AP50分数。显著地,我们的模型在AP25和AP50上分别比第二好的方法提高了0.2%。

4.2.7 3D形状补全
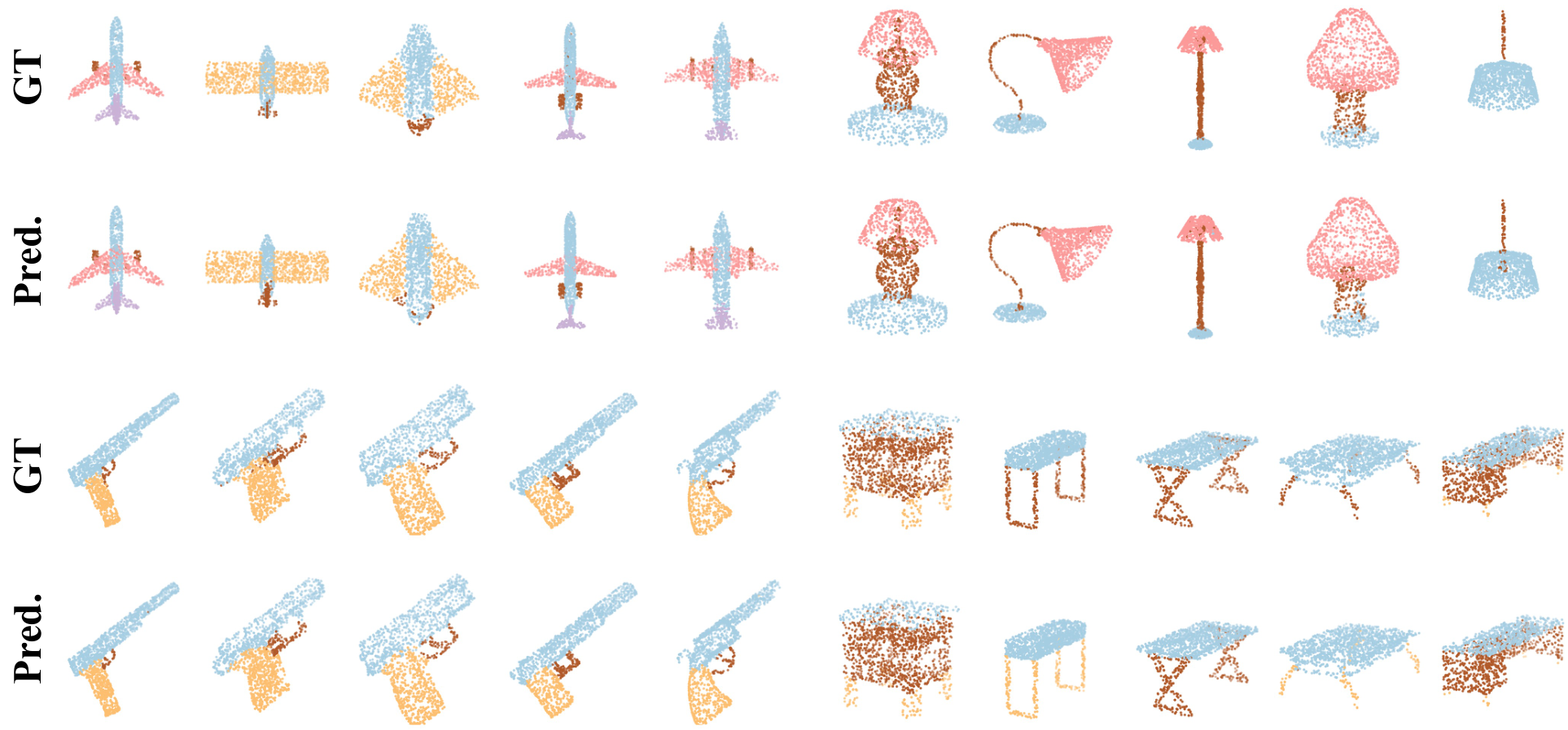
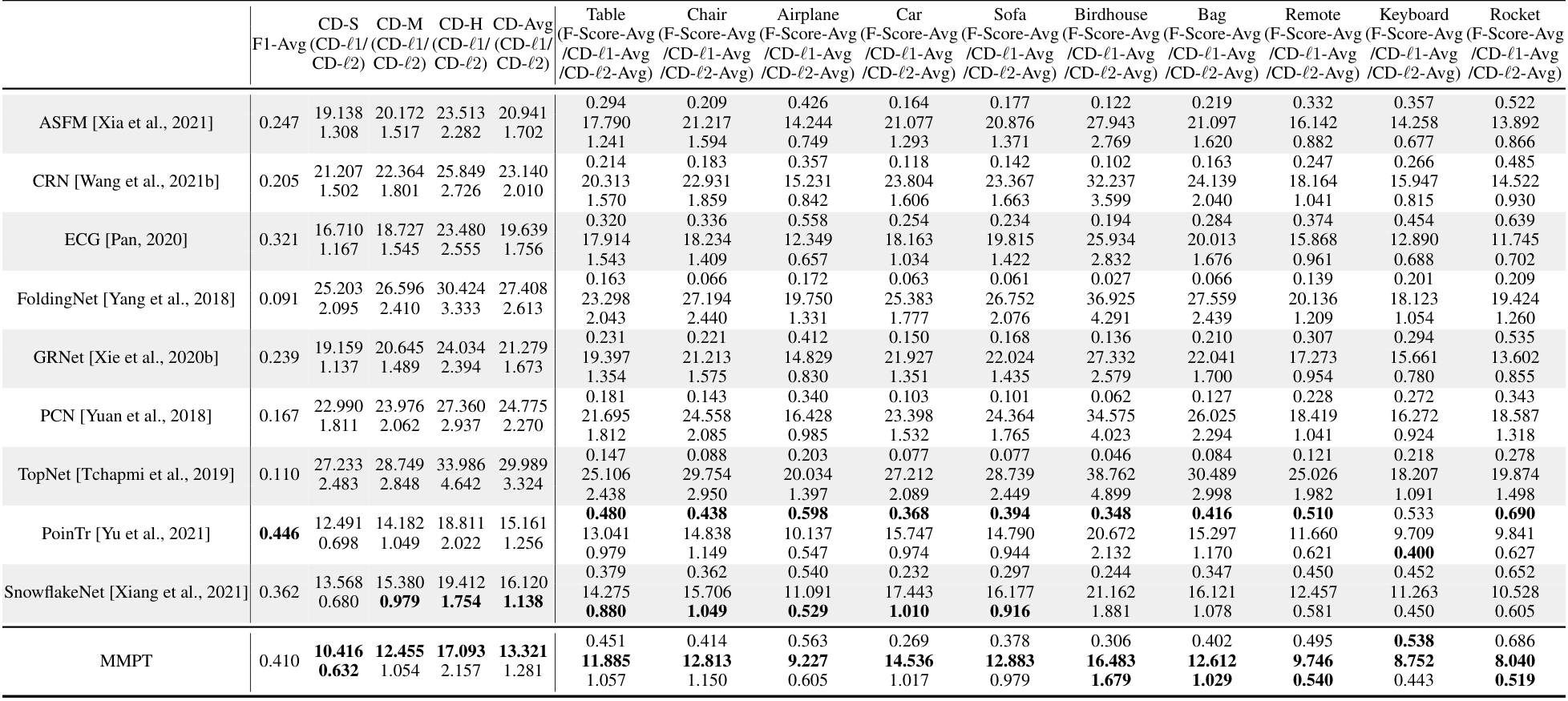
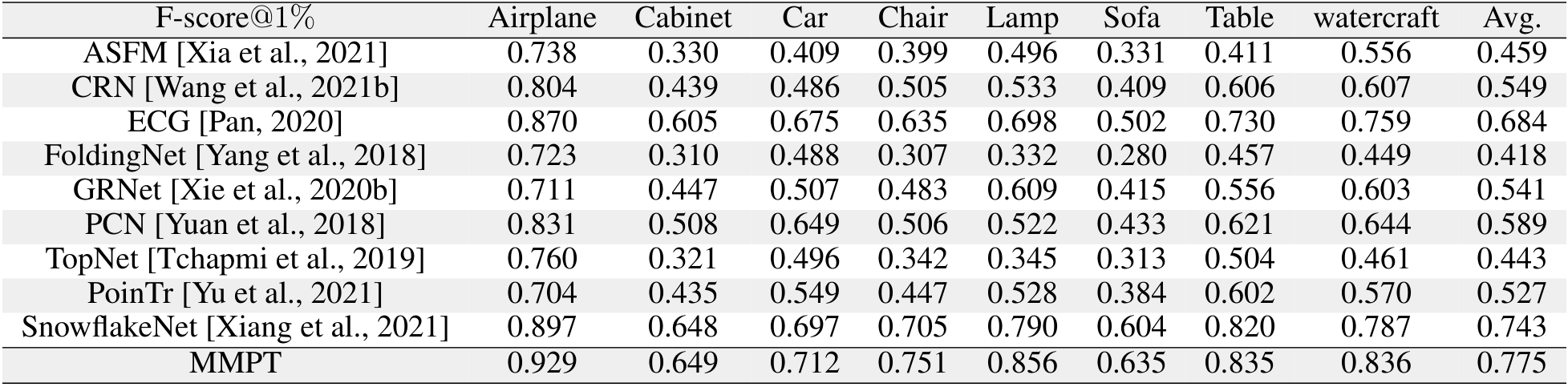
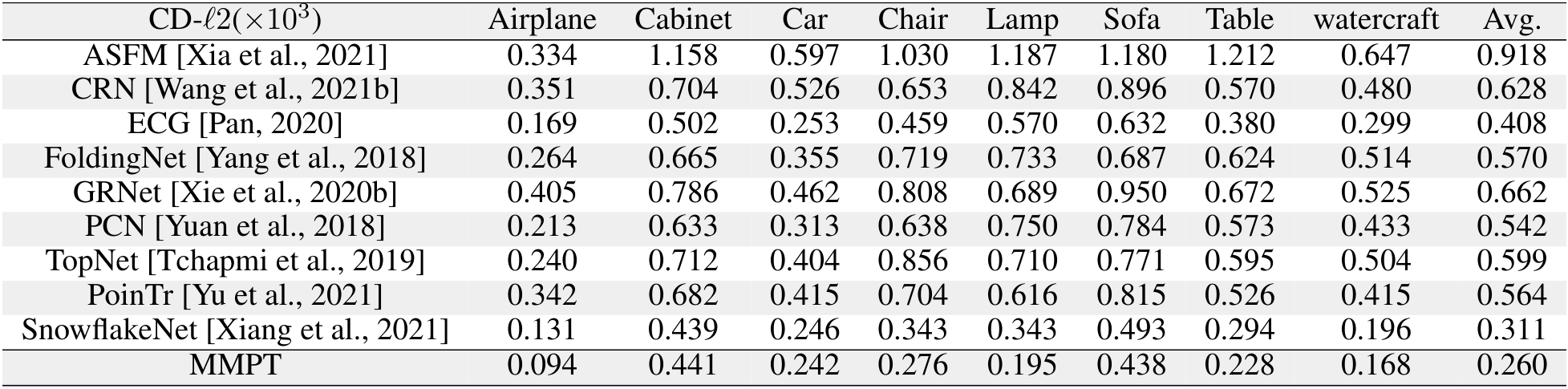
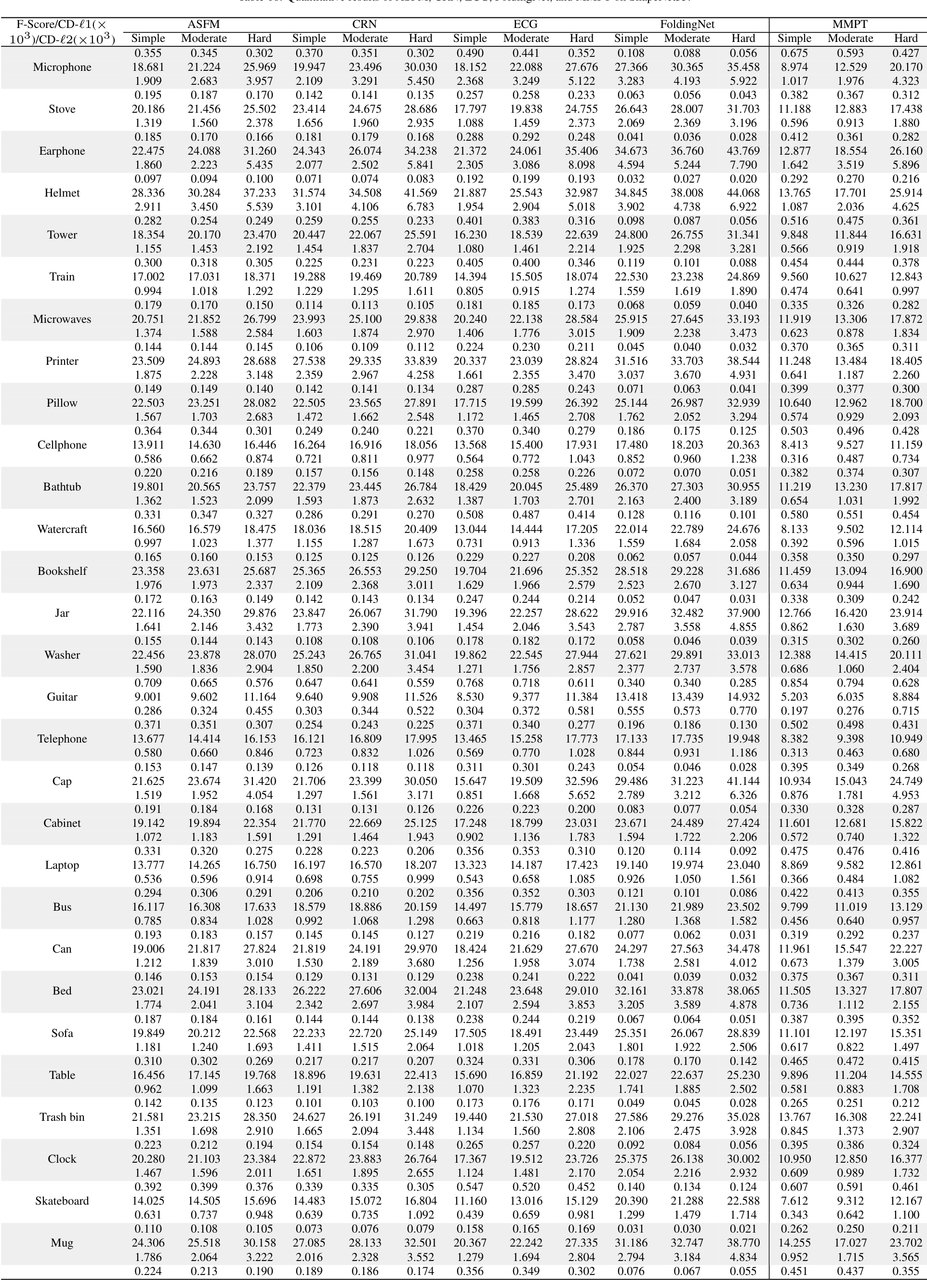
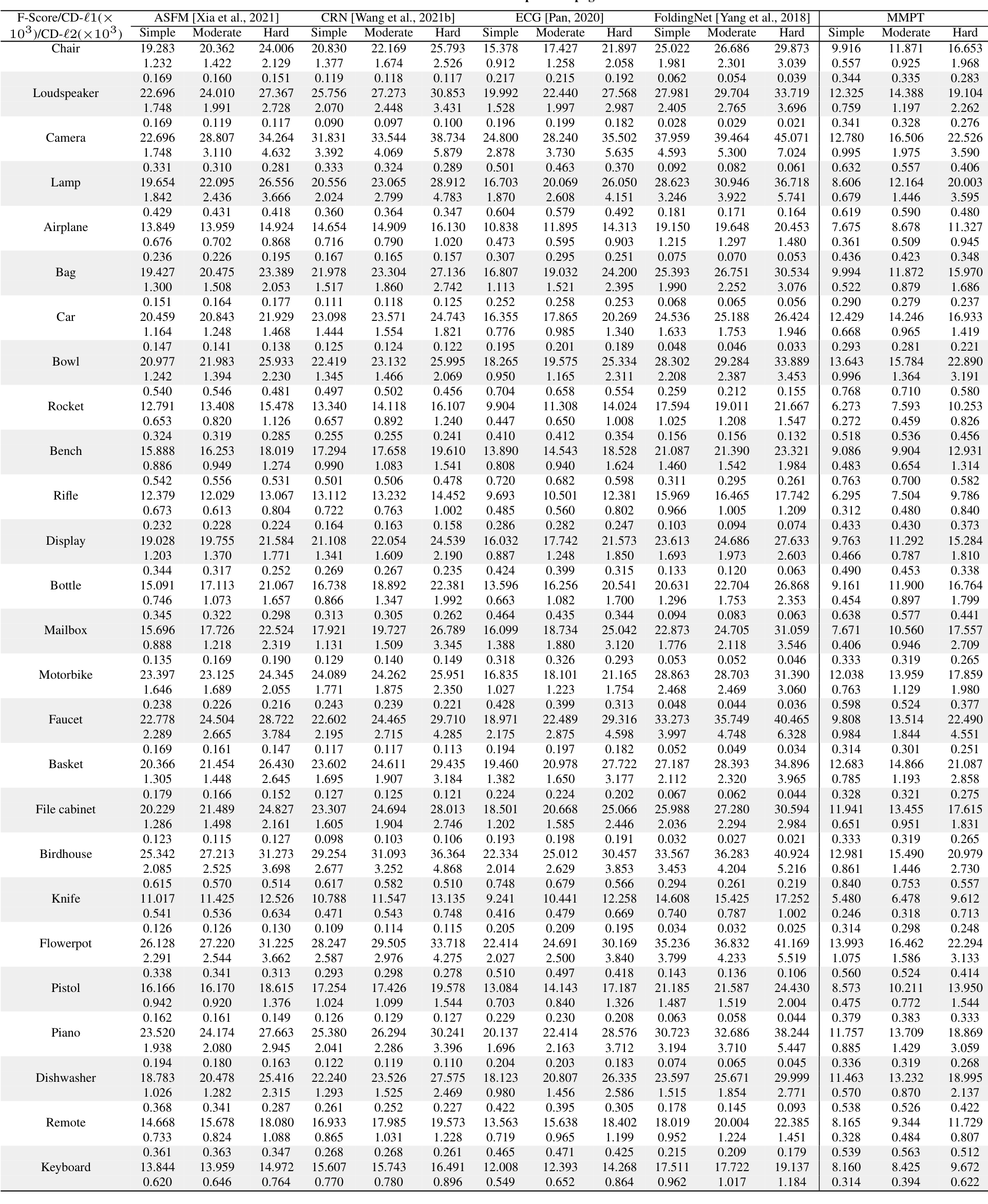
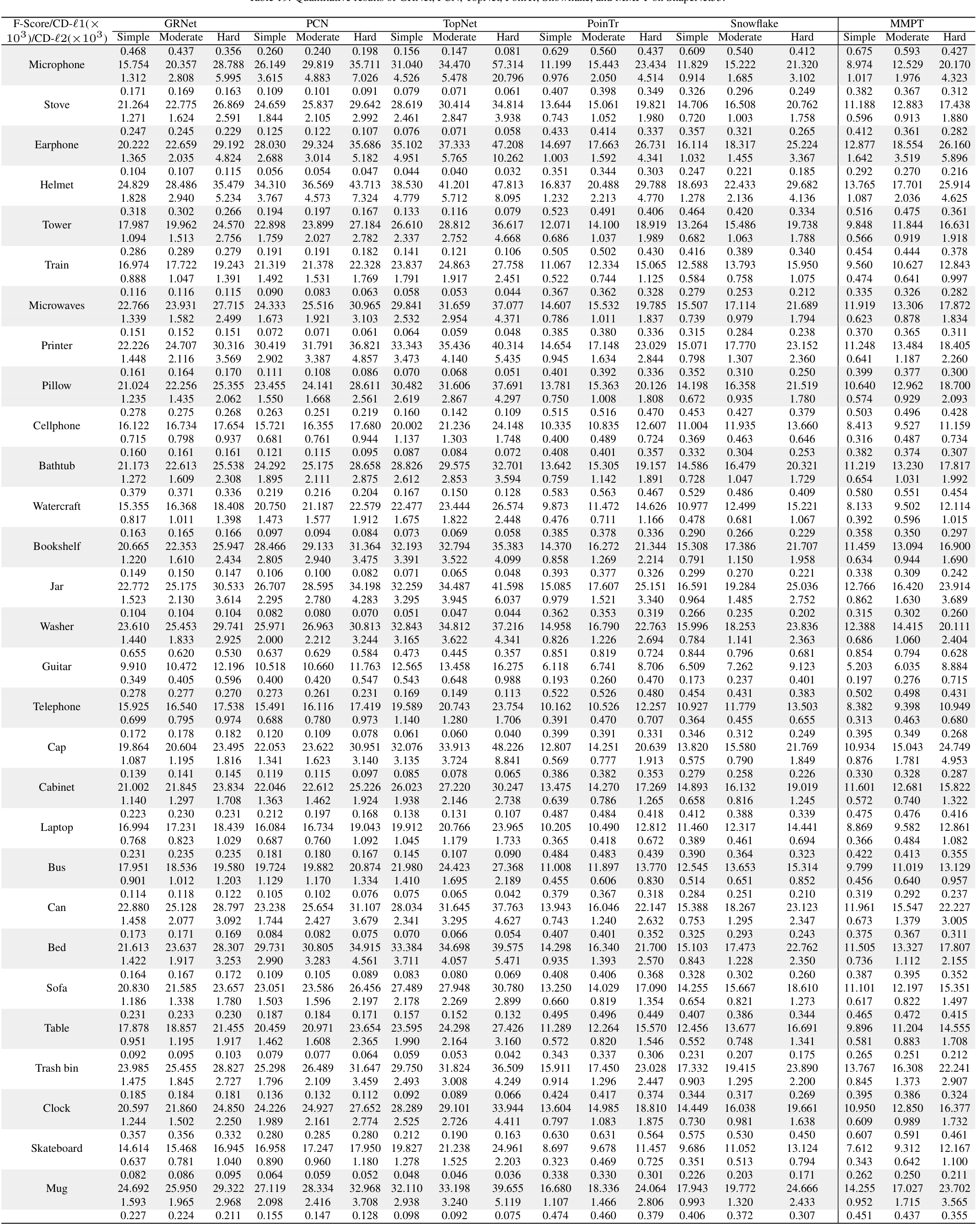
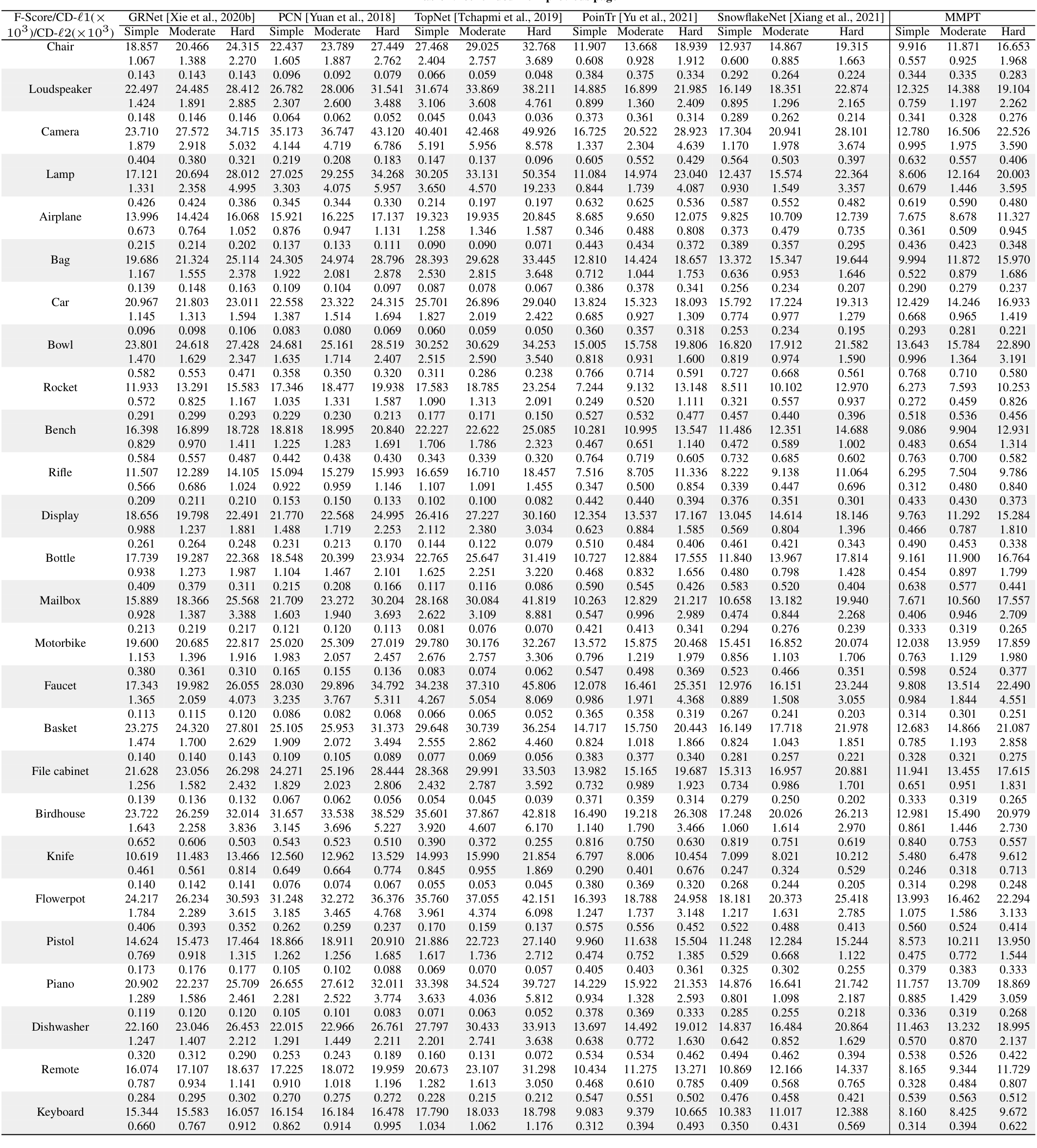
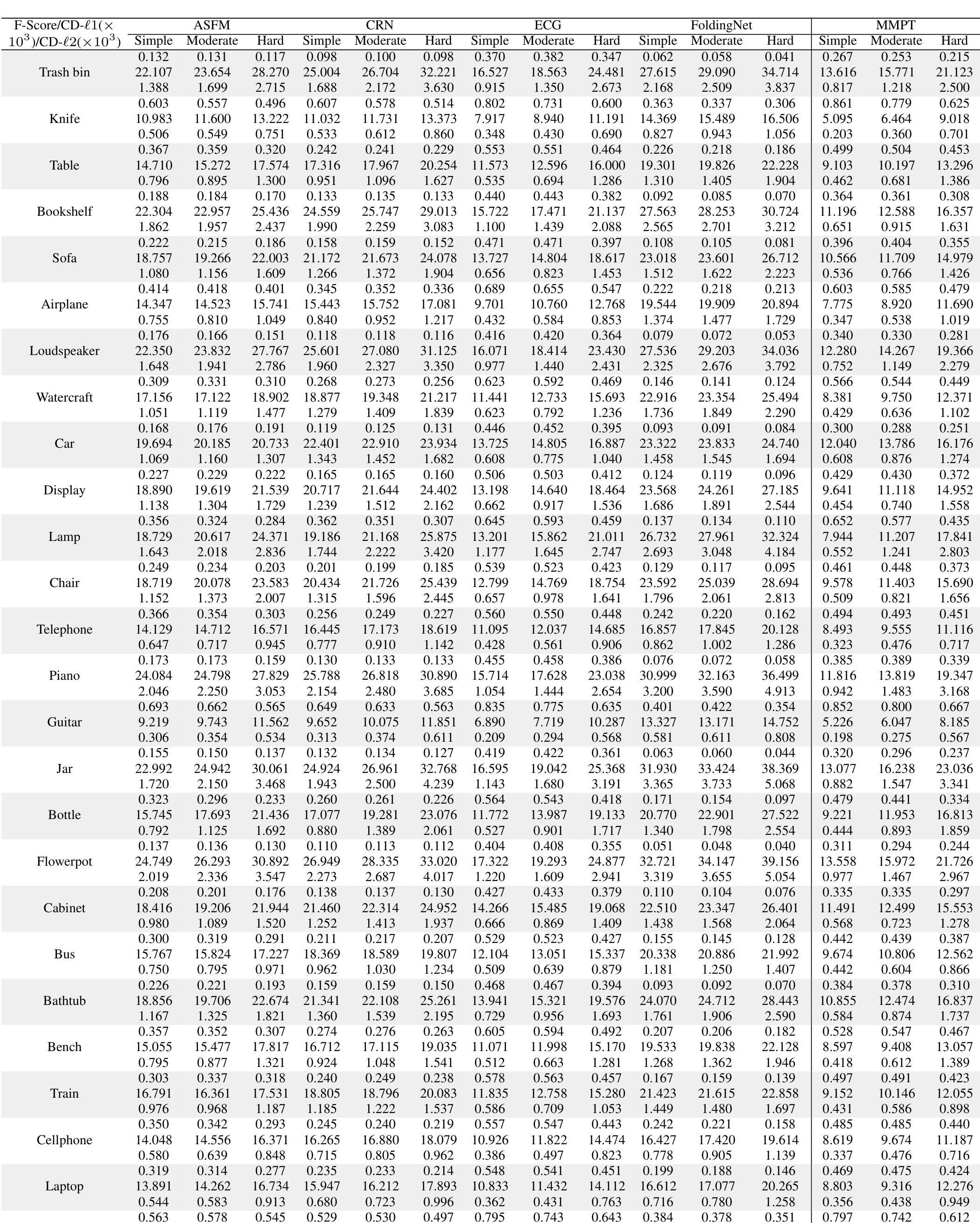
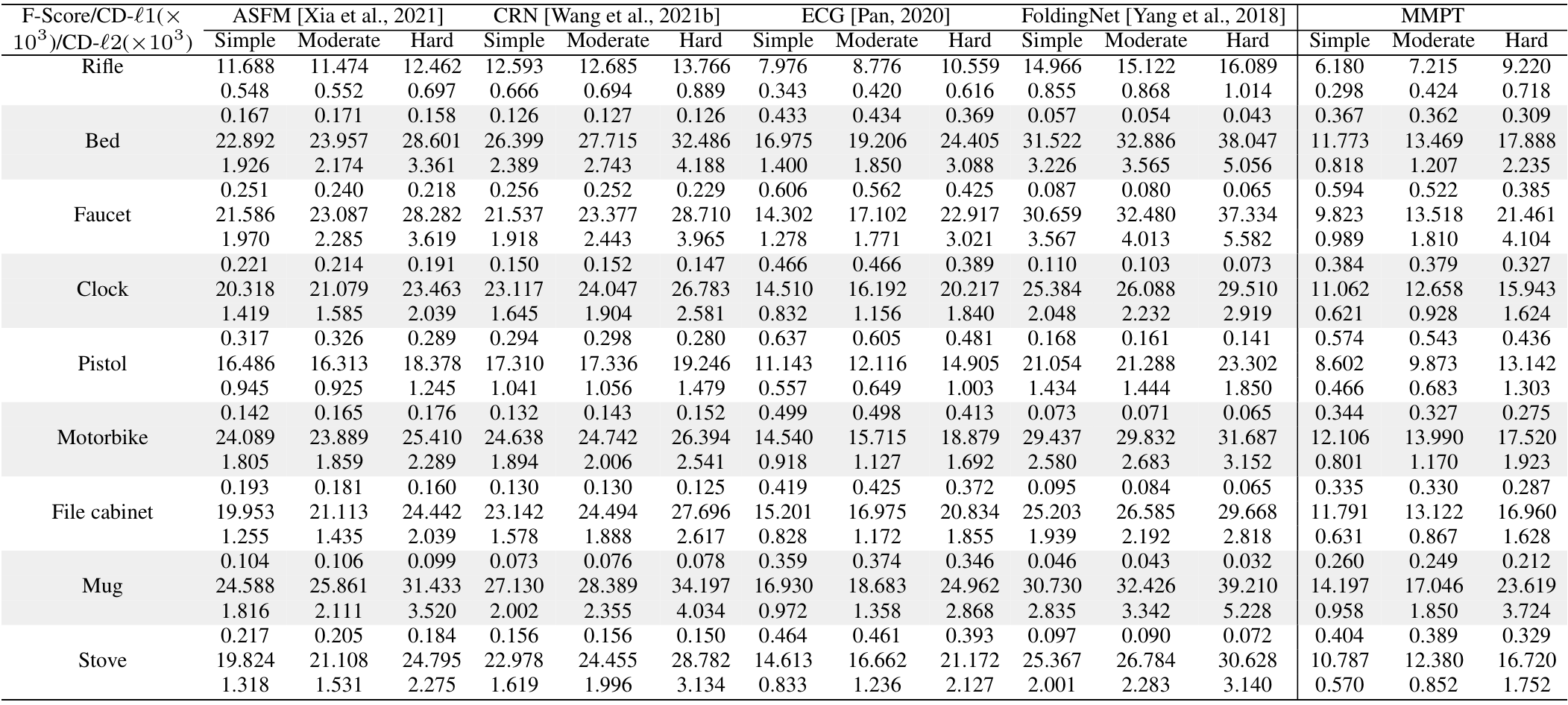
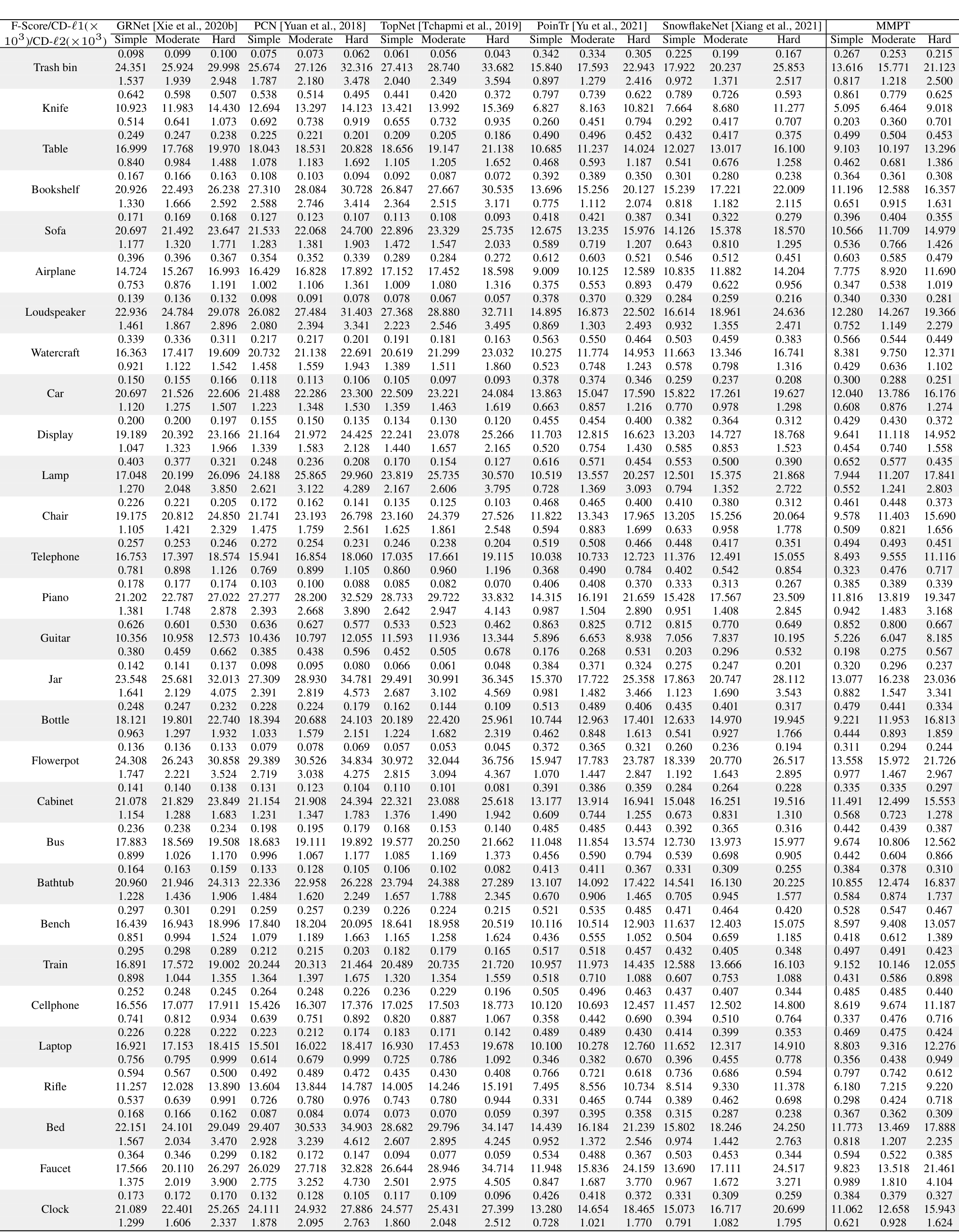
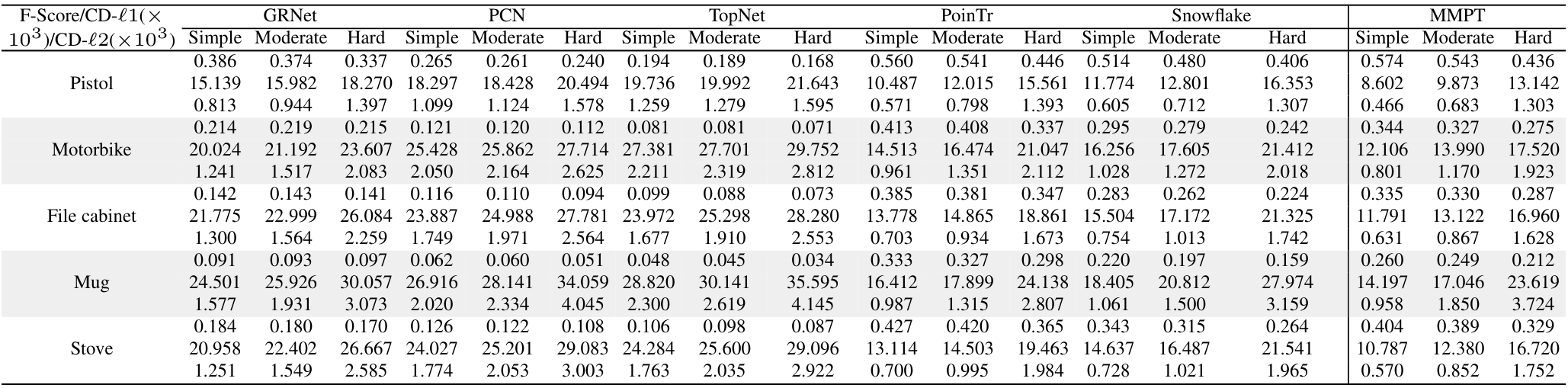
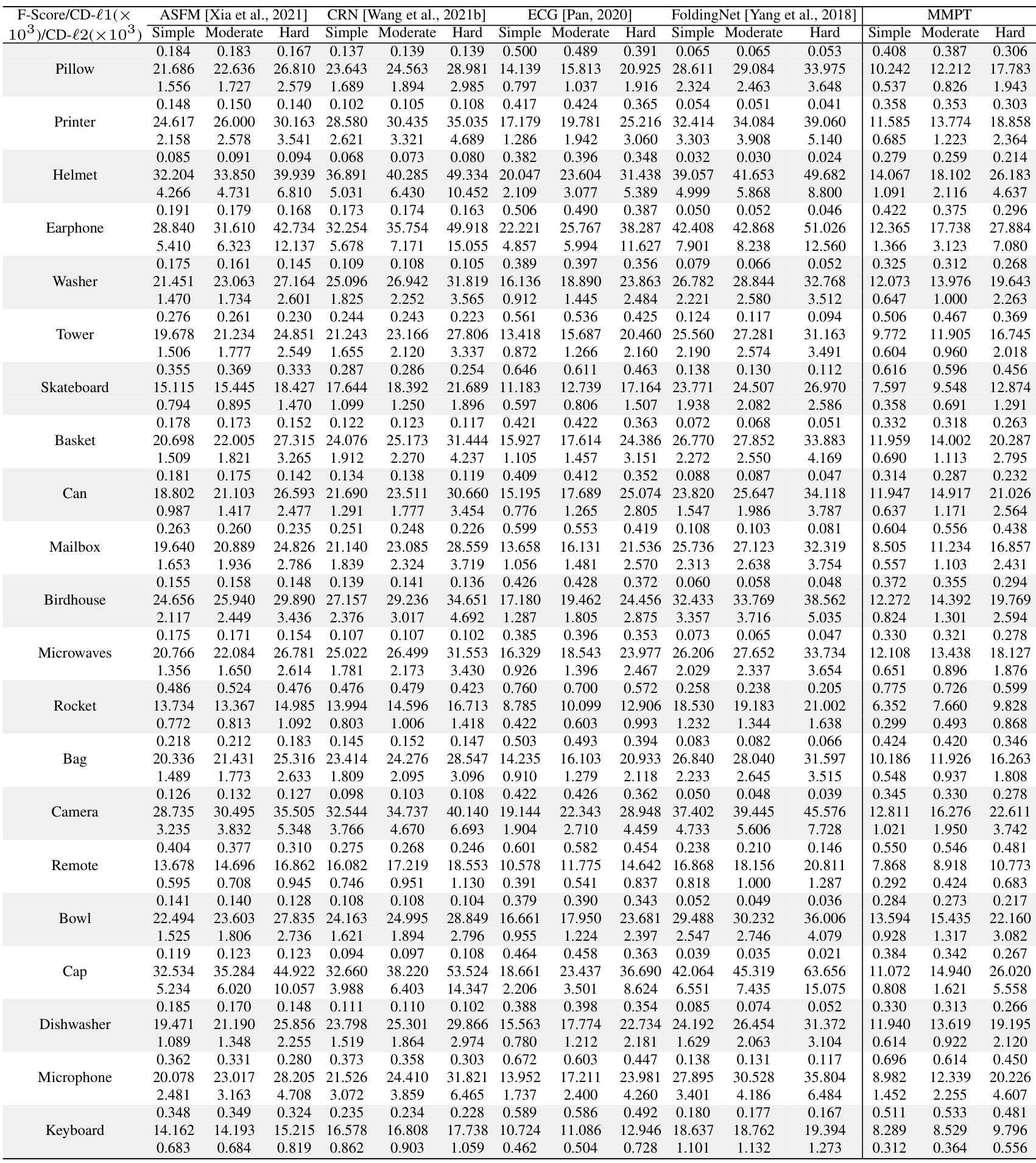
在PCN数据集上的结果。为了评估生成能力,我们在PCN数据集上微调预训练模型。Table 7和补充材料显示,我们的MMPT在所有八个类别上的平均Chamfer距离[Fan et al., 2017]中取得了 remarkable 性能。与PoinTr[Yu et al., 2021]和Snowflake[Xiang et al., 2021]相比,我们的方法在平均CD-l1上分别实现了65.10%和13.06%的相对改进,最终值为7.396。特别地,在椅子类别上,我们的MMPT实现了7.864的CD-l1,比PoinTr和Snowflake分别高出76.58%和15.76%。
为了评估重建完整形状的性能,我们在Figure 7中呈现了PCN数据集上各种方法预测的点云视觉比较。这些比较展示了我们的MMPT在缺失点云补全任务中比先前方法有 superior 视觉性能。具体地,Figure 7显示了在椅子类别的侧面和角度区域,我们的MMPT表现特别出色。
在MVP数据集上的结果。此外,我们还在MVP数据集上进行了点云补全。Table 8显示,我们的MMPT模型在所有16个类别上基于平均CD-l1取得了最佳结果。具体地,我们的MMPT模型的平均Chamfer距离(CD)为6.769,显著优于PoinTr和Snowflake的8.070和7.597。在灯类别上,我们的方法使CD-l1显著降低,比PoinTr和Snowflake分别高出55.29%和50.27%。
我们的MMPT在有效重建缺失部分和捕捉 finer 细节方面表现突出,即使输入点较稀疏。在Figure 7的最后一行,其他方法不仅无法重建摩托车的完整结构,还完全丢失了其原始信息。相比之下,我们的MMPT捕捉了更多 intricate 细节,并产生了更高 fidelity 的结果。
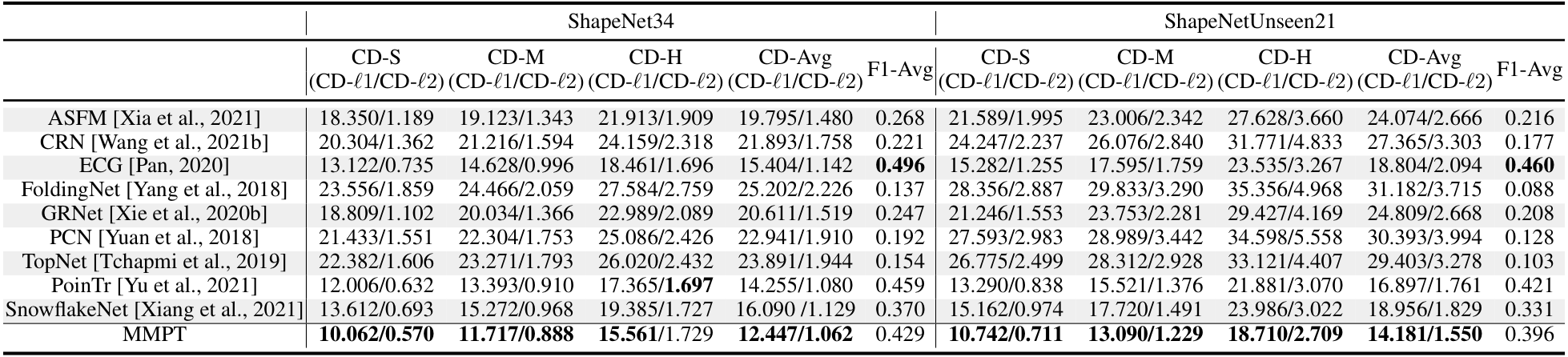
在ShapeNet55数据集上的结果。此外,为了进一步评估MMPT的生成能力,我们在更具挑战性的数据集上进行了实验。Table 9显示,MMPT在F-score和CD-l2指标上取得了 competitive 结果。显著地,MMPT在平均l1 Chamfer距离(x10^{-3})上超越了所有其他方法。在ShapeNet55的简单、中等和困难设置下,我们的MMPT模型分别实现了10.416、12.455和17.093的l1 Chamfer距离,与领先基线方法PoinTr相比,相对改进约为19.92%、13.87%和10.05%。
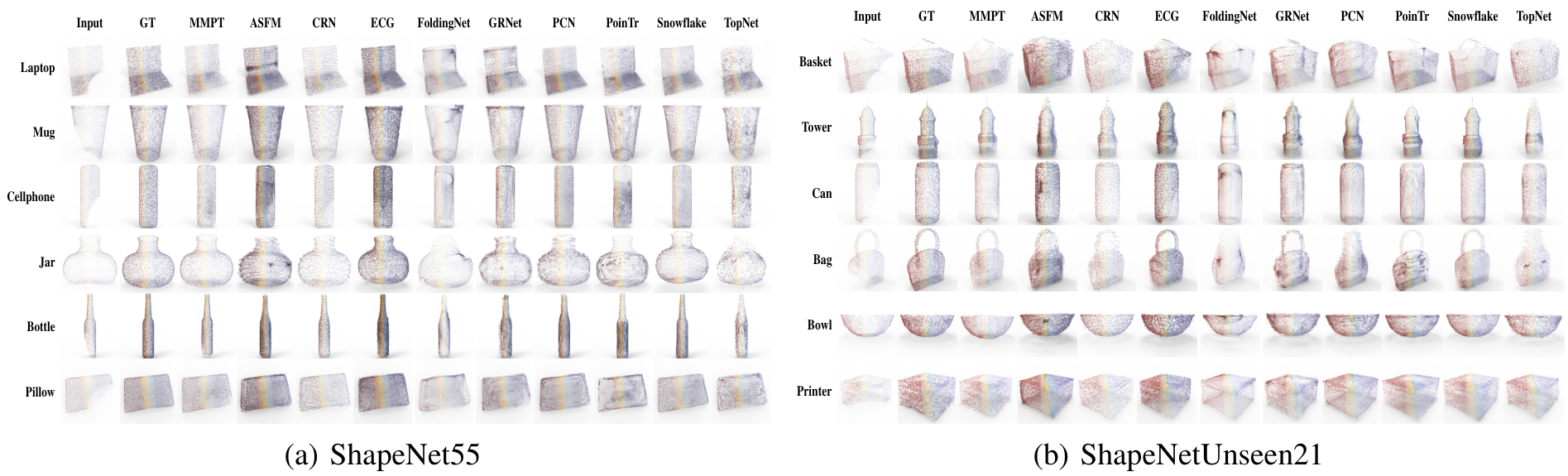
Figure 8(a)中描绘的定性可视化结果展示了我们的MMPT模型在ShapeNet55数据集的所有类别上显著提升了形状质量。基于这些结果,我们可以得出结论:我们的MMPT模型即使处理更均匀和密集分布的物体表面点云,也能实现 comparable 预测准确率。其他方法无法生成更 distinct 结构的形状或恢复减少噪声的形状细节。
在ShapeNetUnseen21数据集上的结果。在点云补全中,评估未见对象上的性能也很必要。因此,我们在ShapeNetUnseen21数据集(源自ShapeNet55)上进行了实验。Table 10总结了我们的MMPT模型与其他九个 competitive 方法在ShapeNet34和ShapeNetUnseen21数据集上的比较结果。该表显示,我们的MMPT模型在所有类别上与PoinTr或Snowflake相比实现了 comparable 或 superior 性能。如Table 10所示,我们的方法在55个类别的平均CD上,在简单、中等和困难设置下,分别比第二好的方法PoinTr提高了14.53%、1.69%、19.15%和13.61%。随着设置难度增加,所有方法的性能均显著下降。
Figure 8(b)展示了我们在ShapeNetUnseen21数据集的简单设置下,与九个方法进行的视觉比较。这些比较揭示了我们方法与基线的显著性能差距。显著地,我们的MMPT在处理篮子的不完整点云表示时表现出色,能够恢复更 precise 的细节,而其他方法无法捕捉 finer 细节。
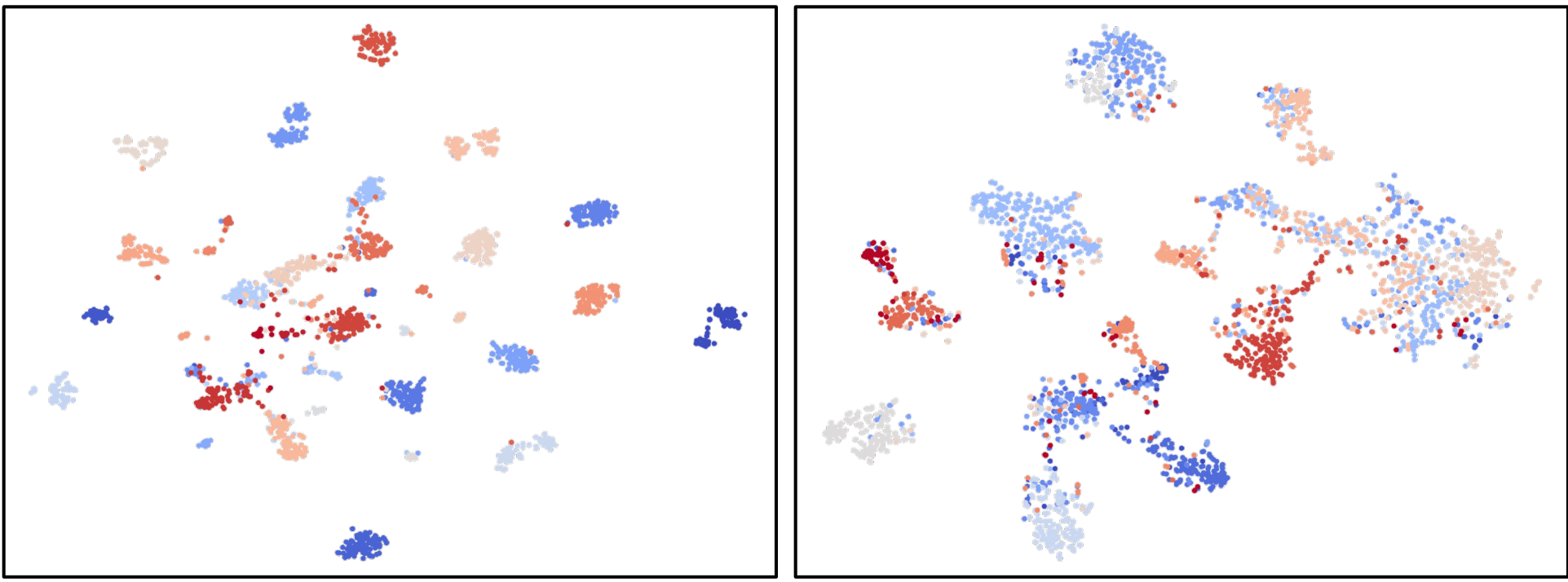
4.3 特征分布的可视化
为了更全面地理解我们方法的有效性,我们使用t-SNE[Van der Maaten and Hinton, 2008]对学习到的特征进行可视化。Fig. 9(左)显示了从ModelNet40学习到的特征的t-SNE可视化,而Fig. 9(右)展示了从ScanObjectNN学习到的特征。可视化结果表明,这些特征形成了许多 well-separated 的集群,这证实了我们方法的有效性。

消融研究和分析
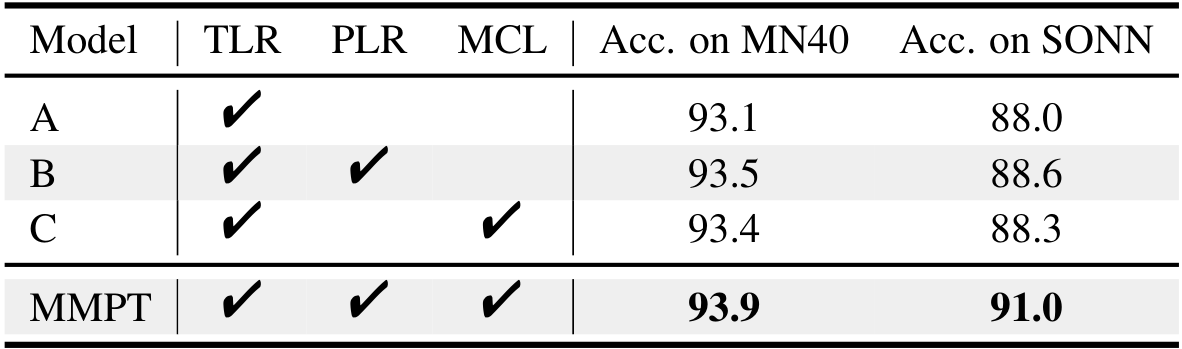
多任务组合的影响。为了深入了解多任务的有效性,我们对不同多任务组合进行了消融研究。如Table 11所示,Model A仅使用TLR任务预训练,而Model B和C使用两个预训练任务。我们的MMPT在多模态和多任务预训练下,显著超越了其他模型,这证明了我们多任务和多模态预训练框架的有效性。这些预训练任务能够协同工作,丰富Transformer’s代表性学习,并进一步提升骨干网络在下游任务上的性能。
视图数量的影响。本研究旨在通过操作渲染的2D图像数量来考察图像分支对结果的影响。具体地,我们研究了不同数量的渲染2D图像(从各种随机方向渲染)如何影响结果。当使用多个渲染2D图像时,我们计算所有投影特征的均值来进行跨模态实例区分。在ModelNet40数据集上的分类结果如Table 12所示。即使使用单个渲染2D图像,MMPT也捕捉了跨模态对应关系并获得了 superior 分类结果。有趣地,当使用超过两个渲染图像时,准确率下降,这表明2D图像模态的信息可能存在冗余。
多任务权重的影响。此外,我们对不同预训练任务的权重组合进行了消融实验。我们将TLR和PLR的比率固定为1:1,因为它们从不同视角重建点云。此外,我们将MCL的比率调整为1、0.5、0.2、0.1和0.01。如Table 13所示,MMPT在1:1:0.1的比率下取得了最佳性能。这主要是由于不同预训练任务之间的 trade-off,使它们能够协同工作并获得更强的预训练模型。
6 结论
总之,本文提出了一个多模态和多任务预训练框架,这是首次将多任务学习引入点云预训练领域。为了解决单一预训练任务在多样下游任务中的瓶颈,我们设计了三个预训练任务:TLR、PLR和MCL。这些任务协同工作,获得了一个具有丰富表示能力的预训练模型。该模型在五个下游任务上取得了满意性能。在未来,我们将基于本工作开发更多针对特定下游任务的多任务预训练模型,以促进3D领域低标注和高迁移性能预训练的发展。
A 数据集
ModelNet40[Wu et al., 2015]数据集包含来自40个物体类别的12,311个CAD模型,其中9,843个用于训练,2,468个用于测试。我们遵循先前工作,使用1024个点及其坐标信息作为输入[Yu et al., 2022, Lu et al., 2022, Ga0 et al., 2022]。
ScanObjectNN[Uy et al., 2019]基于扫描的室内场景数据,分为11,416个训练实例和2,882个验证实例。我们在三个变体上评估实验:OBJ-BG、OBJ-ONLY和PB-T50-RS,与先前工作一致。
ShapeNetPart[Yi et al., 2016]数据集包含16个不同类别和16,881个3D物体,用于评估不同方法的性能,提供全面的理解。
PCN数据集[Yuan et al., 2018]源自ShapeNet数据集,包括8种物体类型,每个完整形状由16,384个点表示,这些点从原始CAD模型表面均匀采样。
MVP数据集[Pan et al., 2021]扩展了PCN数据集的8个类别,添加了另外8个类别,包括床、长凳、书架、巴士、吉他、摩托车、手枪和滑板,从而形成一组高质量的部分和完整点云。
ShapeNet55[Yu et al., 2021]用于评估模型的泛化能力,并分为ShapeNet34和ShapeNetUnseen21。
S3DIS数据集[Armeni et al., 2016]提供六大室内区域的实例级语义分割,这些区域共包含271个房间和13个语义类别。按照惯例,我们将区域5指定为测试集,其余用于训练。
室内检测基准是ScanNet V2[Dai et al., 2017],它包含1,513个室内场景和18个物体类。我们采用VoteNet[Qi et al., 2019]的评估程序,使用mAP@0.25和mAP@0.5作为指标。
B 微调设置
我们使用ModelNet40[Wu et al., 2015]和ScanObjectNN[Uy et al., 2019]两个基准评估物体分类方法,其中ModelNet40包含12,331个网格模型来自40个类别,9,843个训练网格和2,468个测试网格,从中采样点。ScanObjectNN是一个更具挑战性的3D点云分类基准数据集,包含2,880个来自真实室内场景的遮挡物体,来自15个类别。我们遵循[Qi et al., 2017a,b]的设置进行微调。对于PointNet,我们使用Adam优化器,初始学习率为1e-3,每20个epoch衰减0.7,最小值为1e-5。对于DGCNN,我们使用SGD优化器,动量为0.9,权重衰减为1e-4。学习率从0.1开始,使用余弦退火衰减到1e-3。我们在全连接层前应用dropout,PointNet的dropout率为0.7,DGCNN为0.5。我们训练所有模型200个epoch,batch大小为32。
对于细粒度3D识别任务的部分分割,我们使用ShapeNetPart[Yi et al., 2016],它包含16,881个物体,2,048个点来自16个类别,共50个部分。与PointNet[Qi et al., 2017a]类似,我们采样2,048个点。对于PointNet,我们使用Adam优化器,初始学习率为1e-3,每20个epoch衰减0.5,最小值为1e-5。对于DGCNN,我们使用SGD优化器,动量为0.9,权重衰减为1e-4。学习率从0.1开始,使用余弦退火衰减到1e-3。我们训练模型250个epoch,batch大小为16。
对于点云补全任务,我们使用标准Transformer编码器和SnowflakeNet[Xiang et al., 2021]中的强大Transformer-based解码器。我们在点云补全基准上微调模型200个epoch。


Original Abstract: Recent advances in multi-modal pre-training methods have shown promising
effectiveness in learning 3D representations by aligning multi-modal features
between 3D shapes and their corresponding 2D counterparts. However, existing
multi-modal pre-training frameworks primarily rely on a single pre-training
task to gather multi-modal data in 3D applications. This limitation prevents
the models from obtaining the abundant information provided by other relevant
tasks, which can hinder their performance in downstream tasks, particularly in
complex and diverse domains. In order to tackle this issue, we propose MMPT, a
Multi-modal Multi-task Pre-training framework designed to enhance point cloud
understanding. Specifically, three pre-training tasks are devised: (i)
Token-level reconstruction (TLR) aims to recover masked point tokens, endowing
the model with representative learning abilities. (ii) Point-level
reconstruction (PLR) is integrated to predict the masked point positions
directly, and the reconstructed point cloud can be considered as a transformed
point cloud used in the subsequent task. (iii) Multi-modal contrastive learning
(MCL) combines feature correspondences within and across modalities, thus
assembling a rich learning signal from both 3D point cloud and 2D image
modalities in a self-supervised manner. Moreover, this framework operates
without requiring any 3D annotations, making it scalable for use with large
datasets. The trained encoder can be effectively transferred to various
downstream tasks. To demonstrate its effectiveness, we evaluated its
performance compared to state-of-the-art methods in various discriminant and
generative applications under widely-used benchmarks.
PDF Link: 2507.17533v1
3. VL-CLIP: Enhancing Multimodal Recommendations via Visual Grounding and LLM-Augmented CLIP Embeddings
Authors: Ramin Giahi, Kehui Yao, Sriram Kollipara, Kai Zhao, Vahid Mirjalili, Jianpeng Xu, Topojoy Biswas, Evren Korpeoglu, Kannan Achan
Deep-Dive Summary:
VL-CLIP:通过视觉定位和LLM增强的CLIP嵌入提升多模态推荐
Ramin Giahi
Walmart Global Tech
Sunnyvale, CA, USA
ramin.giahi@walmart.com
Kehui Yao*
Walmart Global Tech
Bellevue, WA, USA
kehui.yao@walmart.com
Sriram Kollipara
Walmart Global Tech
Sunnyvale, CA, USA
sriram.kollipara@walmart.com
Kai Zhao*
Walmart Global Tech
Sunnyvale, CA, USA
kai.zhao@walmart.com
Vahid Mirjalili*
Walmart Global Tech
Sunnyvale, CA, USA
vahid.mirjalili@walmart.com
Jianpeng Xu
Walmart Global Tech
Sunnyvale, CA, USA
jianpeng.xu@walmart.com
Topojoy Biswas
Walmart Global Tech
Sunnyvale, CA, USA
topojoy.biswas@walmart.com
Evren Korpeoglu
Walmart Global Tech
Sunnyvale, CA, USA
ekorpeoglu@walmart.com
Kannan Achan
Walmart Global Tech
Sunnyvale, CA, USA
kannan.achan@walmart.com
摘要
多模态学习在当今的电子商务推荐平台中发挥关键作用,能够实现准确的推荐和产品理解。然而,现有的视觉-语言模型,如 CLIP,在电子商务推荐系统中面临几个关键挑战:1) 弱对象级对齐,全球图像嵌入无法捕获细粒度的产品属性,导致检索性能不佳;2) 模糊的文本表示,产品描述往往缺乏上下文清晰度,影响跨模态匹配;3) 领域不匹配,通用的视觉-语言模型可能无法很好地泛化到电子商务特定数据。为解决这些限制,我们提出一个框架 VL-CLIP,通过整合视觉定位来增强 CLIP 嵌入,以实现细粒度的视觉理解,并使用 LLM 代理生成丰富的文本嵌入。视觉定位通过定位关键产品来细化图像表示,而 LLM 代理通过消除歧义来增强文本特征。我们在美国的最大电子商务平台之一上,对数千万个商品进行了实验,验证了该框架在准确性、多模态检索有效性和推荐准确性方面的提升,提高了点击率 (CTR) 18.6%、添加购物车率 (ATC) 15.5% 和总商品价值 (GMV) 4.0%。额外的实验结果显示,我们的框架在精度和语义对齐方面优于其他视觉-语言模型,包括 CLIP、FashionCLIP 和 GCL,展示了结合对象感知视觉定位和 LLM 增强文本表示的潜力,用于稳健的多模态推荐。
CCS 概念
· 信息系统 —> 推荐系统;用户和交互式检索。
关键词
多模态学习、电子商务、CLIP、视觉定位、大语言模型、图像-文本表示、检索、AI 用于推荐
ACM 参考格式
Ramin Giahi, Kehui Yao, Sriram Kollipara, Kai Zhao, Vahid Mirjalili, Jianpeng Xu, Topojoy Biswas, Evren Korpeoglu, Kannan Achan. VL-CLIP: Enhancing Multimodal Recommendations via Visual Grounding and LLM-Augmented CLIP Embeddings. In Proceedings of the Nine-22-26, 2025, Prague, Czech Republic. ACM, New York, NY, USA, 19 pages. https://doi.org/10.1145/3705328.3748064
1 引言
电子商务平台彻底改变了消费者与产品的互动方式,提供广泛的产品目录,以满足多样化的偏好。随着产品数量呈指数级增长,提供高度相关的个性化推荐变得越来越复杂。消费者经常依赖多模态互动——使用文本查询和图像组合进行搜索——来找到他们想要的产品。因此,提高多模态表示学习对于提升搜索准确性、推荐质量和整体用户体验至关重要 [34]。
最近的视觉-语言模型进展显著改善了跨模态检索。特别是 CLIP [23],它通过对比学习在共享嵌入空间中对齐图像和文本表示。尽管取得了成功,但 CLIP 在电子商务场景中存在几个限制。

首先,CLIP 对图像进行全局处理,无法捕获细粒度的产品属性,这些属性对于区分视觉相似但语义不同的物品至关重要。例如,两个手提包在全局嵌入空间中可能看起来几乎相同,即使其中一个有独特的纹理或扣设计。这种弱对象级对齐导致了在大型电子商务平台上的次优检索性能。
另一个主要挑战是文本表示的模糊性。电子商务目录中的产品描述在质量和一致性上差异很大。有些描述过于冗长,包含无关信息,而有些则过于简略,缺少关键细节。CLIP 的文本编码器难以处理这些不一致性,尤其是在长文本描述中,导致文本和视觉表示之间的语义对齐较差。没有结构化和丰富的文本输入,CLIP 可能误解产品意图,从而降低多模态检索的准确性。
此外,现有的多模态模型通常在通用数据集(如 LAION-400M [25])上训练,这些数据集包含广泛的图像-文本对。虽然这种训练范式支持广泛的零样本学习,但当应用于电子商务时,也会引入显著的领域不匹配。产品图像通常包含受控背景、专业照明或生活方式描绘,这些与开放域数据集中的多样化、嘈杂图像不同。因此,预训练模型无法有效泛化到电子商务特定数据,需要领域适应策略 [14]。
为了克服这些限制,我们提出一个新框架,通过两个关键创新来增强 CLIP 嵌入:(1) 整合视觉定位以实现细粒度的对象定位,以及 (2) 使用大语言模型 (LLM) 来细化文本嵌入。视觉定位 [15] 使 CLIP 的视觉编码器能够专注于图像中最相关的区域,从而改善对象级对齐。
在文本方面,我们使用 LLM 代理来丰富产品描述,通过生成结构化、语义上有意义的文本表示来消除噪声并注入领域特定知识。这种增强缓解了 CLIP 在处理模糊文本时的困难,并确保图像-文本对齐更稳健、准确和上下文感知。
图 1 展示了我们的方法在视觉和文本推荐中的有效性。在图 1 (a) 中,传统方法基于类别相似性,往往忽略细粒度的视觉一致性。相比之下,我们的视觉推荐系统通过视觉定位和增强 CLIP 嵌入,检索视觉和语义上对齐的物品,从而改善推荐相关性。同样,图 1 (b) 突出了我们的模型如何提升电子商务搜索。传统基于关键词的搜索在处理复杂查询(如 “带有宠物图案的地毯” 或 “锦缎丝绸床单”)时可能产生不一致结果。我们的模型有效地将文本查询与最相关的视觉内容对齐,确保搜索结果在文本和视觉上都准确。这些改进验证了我们的方法在捕获细粒度细节和提供语义上有意义检索方面的优势,最终提升用户体验。
本文的贡献有三方面:首先,我们引入了一个新多模态管道,整合视觉定位和 LLM 增强嵌入,以改善电子商务应用中的细粒度对齐;其次,我们开发了一个可扩展的检索和排名系统,能够高效处理大规模产品目录;第三,我们通过在 Walmart.com 上对数千万个物品进行的广泛实验,验证了我们的方法在检索准确性、推荐质量和整体系统性能方面相对于现有最先进多模态模型的显著提升。
本文的其余部分组织如下。第 2 节讨论了多模态学习、视觉-语言模型和电子商务推荐系统的相关工作。第 3 节描述了我们提出的框架,详细说明了图像和文本表示的增强。第 4 节呈现了实验结果,包括比较评估和消融研究。第 5 节总结全文。
2 相关工作
多模态学习长期以来一直是活跃的研究领域。预训练视觉-语言模型的进展使之应用于各种领域,如医疗 [9, 20]、金融 [7]、社交网络 [1, 22]、搜索引擎 [6, 31] 和电子商务 [10, 17]。基于 Transformer 的架构 revolutionized 多模态学习,通过自注意力机制和跨注意力机制将文本和视觉输入整合到统一的潜在空间中,模型如 VL-BERT [26]、ViLBERT [16] 和 LXMERT [27] 奠定了稳健的视觉-语言推理基础。随后模型,包括 VisualBERT [11]、UNITER [3] 和 OSCAR [13],进一步完善了这些能力,在多个基准上实现了最先进性能,并支持了泛化表示学习。
与注意力机制并行,Radford 等人引入了 CLIP [23] 模型,这是一种双编码器方法,在大量嘈杂的图像-文本数据上训练。它展示了在各种视觉-语言任务上的稳健性能,使用对比学习机制直接在共享空间中对齐视觉和文本嵌入,从而实现了令人印象深刻的零样本检索能力。许多工作扩展了 CLIP,通过扩展数据 [4]、改进数据整理 [4, 24]、改变输入 [8, 28]、细化损失函数或对齐策略 [18, 29]、适应新任务 [21, 32]、排名 [33] 和领域适应 [5, 12]。
基于 CLIP 的能力,我们微调其双编码器架构以适应电子商务领域,其中多模态检索对于匹配文本查询和产品图像至关重要。我们的方法利用包含嘈杂和多样化图像-文本对的领域特定数据集,这是在电子商务平台的标志。我们通过定制 CLIP 以处理电子商务特定挑战,旨在实现优越的对齐和检索性能,最终改善搜索和推荐系统的客户体验。
3 方法论
在本节中,我们介绍 VL-CLIP,这是一个系统框架,用于微调 CLIP 模型以实现稳健的图像-文本对齐。它整合了先进的视觉-语言技术,包括三个阶段:1) 使用视觉定位进行图像区域细化,2) LLM 驱动的文本查询合成,以及 3) 与 CLIP 优化的对比训练。下面,我们对每个组件进行全面分解,包括实现细节和设计理由。这种稳健方法解决了数据噪声、领域特定对齐和可扩展性的挑战。所有数学公式都总结如下。
3.1 图像区域细化使用视觉定位
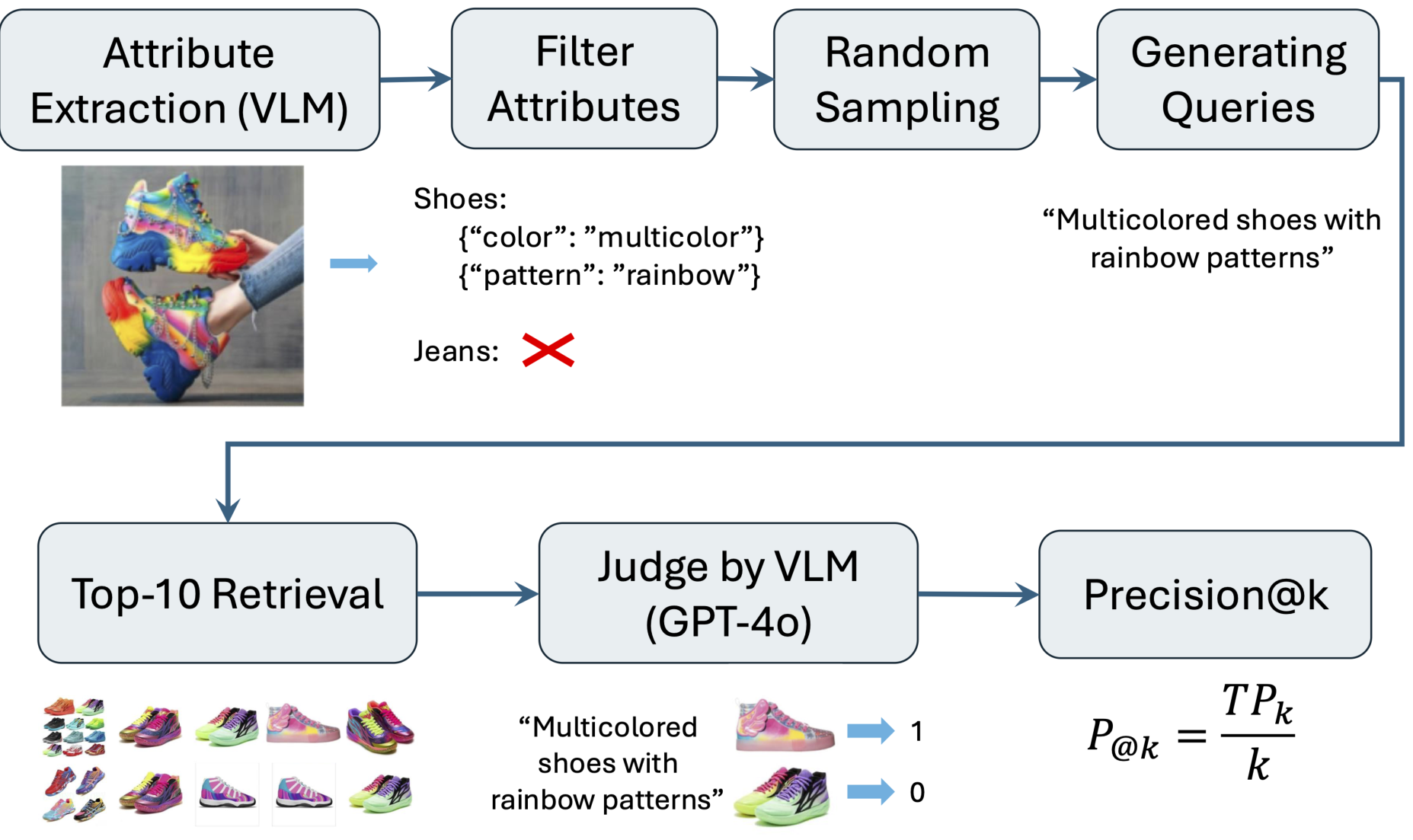
为了专注于产品相关区域,我们使用了 GroundingDINO (GD)——一个零样本对象检测模型,通过文本提示对齐视觉区域 [15]。对于每张图像,从产品元数据中提取的产品类型(例如,“连衣裙”、“背包”)用作文本提示,以生成候选框和置信度分数。选择得分最高的框,并对其区域进行裁剪和调整大小。如果没有框超过置信度阈值,则保留原始图像,以避免丢失关键上下文。视觉定位利用语义文本提示确保精确定位产品中心区域,减少无关背景(如工作室道具)的噪声。为了增强对产品相关视觉元素的关注,我们采用以下步骤细化图像输入:
给定图像 III,GroundingDINO 生成一组 NNN 个边界框提案:
B={b1,b2,…,bN}B=\{b_{1},b_{2},\ldots,b_{N}\} B={b1,b2,…,bN}
每个边界框 bi∈Bb_i \in Bbi∈B 与置信度分数 sis_isi 相关联:
si=exp(ϕimage(vi)⋅ϕtext(P)/τDINO)∑j=1Nexp(ϕimage(vj)⋅ϕtext(P)/τDINO)s_{i}=\frac{\exp(\phi_{\mathrm{image}}(v_{i})\cdot\phi_{\mathrm{text}}(P)/\tau_{\mathrm{DINO}})}{\sum_{j=1}^{N}\mathrm{exp}(\phi_{\mathrm{image}}(v_{j})\cdot\phi_{\mathrm{text}}(P)/\tau_{\mathrm{DINO}})} si=∑j=1Nexp(ϕimage(vj)⋅ϕtext(P)/τDINO)exp(ϕimage(vi)⋅ϕtext(P)/τDINO)
其中 ϕimage(vi)\phi_{\mathrm{image}}(v_i)ϕimage(vi) 和 ϕtext(P)\phi_{\mathrm{text}}(P)ϕtext(P) 表示 GroundingDINO 的图像区域 viv_ivi 和文本提示 PPP 的编码器,τDINO\tau_{\mathrm{DINO}}τDINO 是温度参数,sis_isi 表示 bib_ibi 是最相关区域的概率。选择置信度最高的边界框 b∗b^*b∗ 使用:
i∗=argmaxi∈{1,...,N}sii^{*}=\arg\max_{i\in\{1,...,N\}}s_{i} i∗=argi∈{1,...,N}maxsi
如果 bi∗b_i^*bi∗ 的置信度分数低于预定义阈值 TthreshT_{\text{thresh}}Tthresh,则保留完整图像:
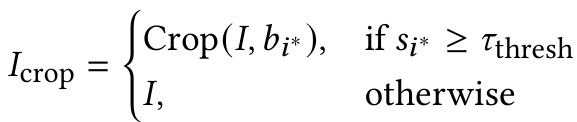
其中 Crop(I,bi∗)\text{Crop}(I, b_i^*)Crop(I,bi∗) 根据选定的边界框提取产品中心区域,IcropI_{\text{crop}}Icrop 是最终细化图像输入。一旦获得细化图像 IcropI_{\text{crop}}Icrop,将其传递通过:
v=ϕCLIP−image(Icrop)∣∣ϕCLIP−image(Icrop)∣∣v=\frac{\phi_{\mathrm{CLIP-image}}(I_{\mathrm{crop}})}{||\phi_{\mathrm{CLIP-image}}(I_{\mathrm{crop}})||} v=∣∣ϕCLIP−image(Icrop)∣∣ϕCLIP−image(Icrop)
其中 vvv 是归一化图像嵌入。通过利用视觉定位进行区域细化,我们确保提取的嵌入捕获细粒度的产品属性,从而改善多模态检索中的对齐。
3.2 LLM 驱动的文本查询合成
为了改善多模态检索中的文本表示,我们引入了一个 LLM 驱动的文本细化过程。该过程通过生成结构化且语义丰富的查询来增强产品描述,从而更好地与视觉特征对齐。该方法包括三个主要组件:总结、评估和细化。
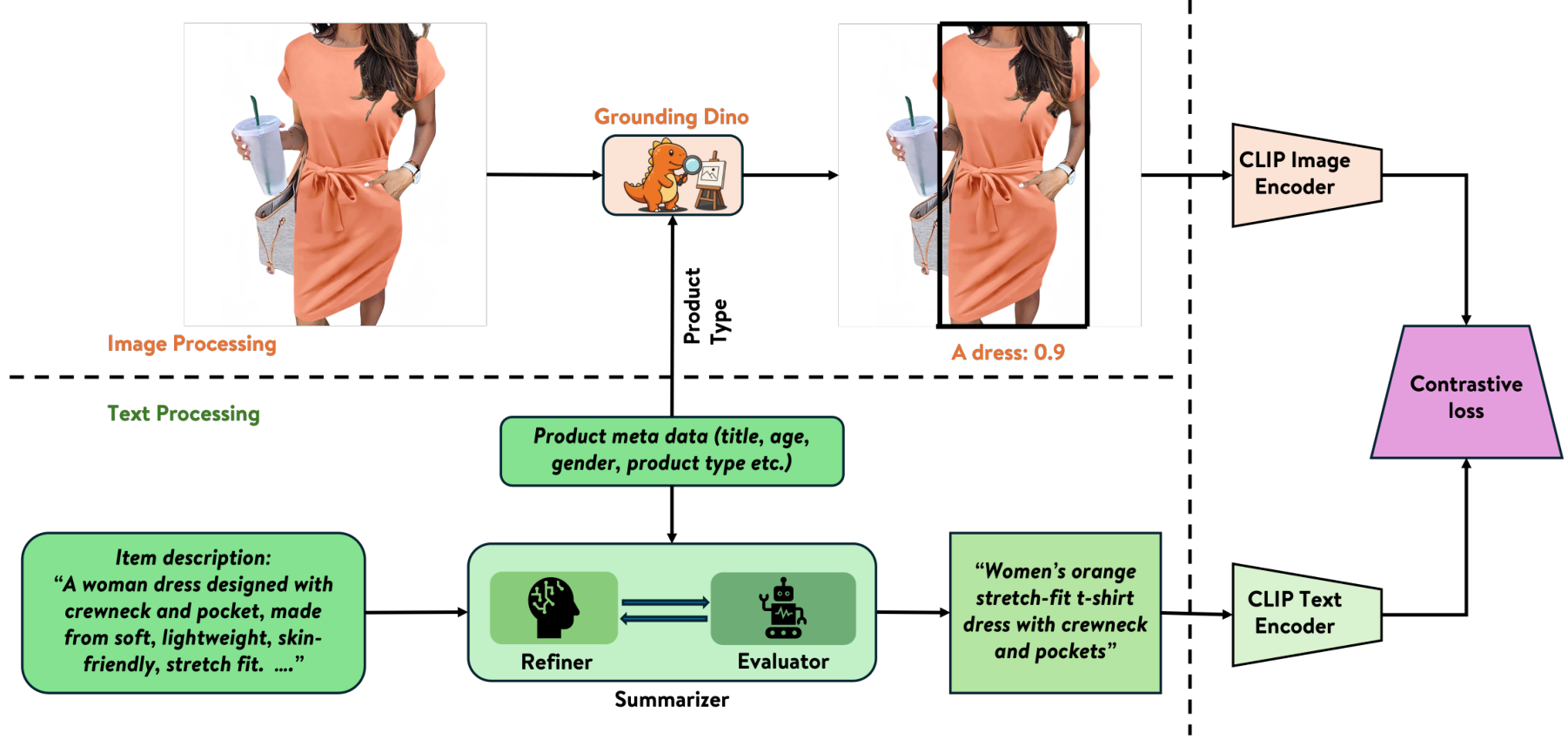
给定原始文本输入,包括结构化和非结构化产品信息,我们首先构建一个初始的连接元数据表示 tconcatt_{\text{concat}}tconcat。tconcat=[tp∣∣tg∣∣traw∣∣tin-context]t_{\text{concat}} = [t_p \, || \, t_g \, || \, t_{\text{raw}} \, || \, t_{\text{in-context}}]tconcat=[tp∣∣tg∣∣traw∣∣tin-context],其中 tpt_ptp 表示产品类型(例如,“T 恤”、“手提包”),tgt_gtg 表示年龄和性别属性(如果适用),trawt_{\text{raw}}traw 表示原始产品标题和描述,tin-contextt_{\text{in-context}}tin-context 包含少样本示例,用于指导 LLM 在模糊情况下的行为。此连接信息由 LLM 基于总结器总结,形成初始查询 qinit=Summarizer(tconcat)q_{\text{init}} = \text{Summarizer}(t_{\text{concat}})qinit=Summarizer(tconcat)。
考虑到 LLM 的强大少样本能力 [2],我们利用一组专门设计来处理 tin-contextt_{\text{in-context}}tin-context 中 LLM 错位的场景的少样本示例。这允许我们强化期望行为并改善性能,同时保持模型的泛化性。
接下来,我们使用两个专门的 LLM 基于模块——评估器和细化器——对初始查询进行迭代细化。
让 Evaluator(q,tconcat)\text{Evaluator}(q, t_{\text{concat}})Evaluator(q,tconcat) 是一个基于 LLM 的函数,根据以下标准评估查询 qqq 的质量:
(1) 属性一致性:确保查询反映输入中的属性。例如,如果 qqq 指定颜色为红色,该标准评估 tconcatt_{\text{concat}}tconcat 是否包含颜色属性且确实为红色。
(2) 简洁性:将查询长度限制在 10-20 词,同时保留含义。
(3) 与视觉数据的对齐:仅保留可视属性。例如,如果 tconcatt_{\text{concat}}tconcat 提到 T 恤是“条纹和速干的”,则仅保留“条纹”,因为它是可视的,而排除“速干”作为非视觉功能属性。
评估器输出一个细化建议或特殊令牌。让 Refiner(q,e)\text{Refiner}(q, e)Refiner(q,e) 是一个基于 LLM 的函数,使用当前查询 qqq 和评估器的反馈 eee 生成细化查询。我们将迭代 iii 中的评估器输出和细化查询分别记为 eie_iei 和 qiq_iqi。
从 qinitq_{\text{init}}qinit 作为 q0q^0q0 开始,在每个迭代 iii (1 ≤ i ≤ imaxi_{\text{max}}imax) 中,评估器首先评估前一个迭代的查询 qi−1q_{i-1}qi−1 并提供反馈 ei=Evaluator(qi−1,tconcat)e_i = \text{Evaluator}(q_{i-1}, t_{\text{concat}})ei=Evaluator(qi−1,tconcat)。如果评估器指示无需进一步改进(通过返回
迭代细化结束后,我们获得最终查询 qfinalq^{\text{final}}qfinal,通过文本编码器 ϕT\phi_TϕT 在语义空间中生成适合多模态检索的归一化嵌入向量 ttt:
t=ϕCLIP−text(qfinal)∣∣ϕCLIP−text(qfinal)∣∣t=\frac{\phi_{\mathrm{CLIP-text}}(q^{\mathrm{final}})}{||\phi_{\mathrm{CLIP-text}}(q^{\mathrm{final}})||} t=∣∣ϕCLIP−text(qfinal)∣∣ϕCLIP−text(qfinal)
其中 ttt 表示用于与图像嵌入匹配的归一化文本嵌入。通过采用这种 LLM 驱动的合成方法,文本表示变得更结构化、更与视觉对齐,并适应领域,从而最终提升多模态检索系统的性能。该迭代循环如图 3 所示,体现了自反和自纠机制。
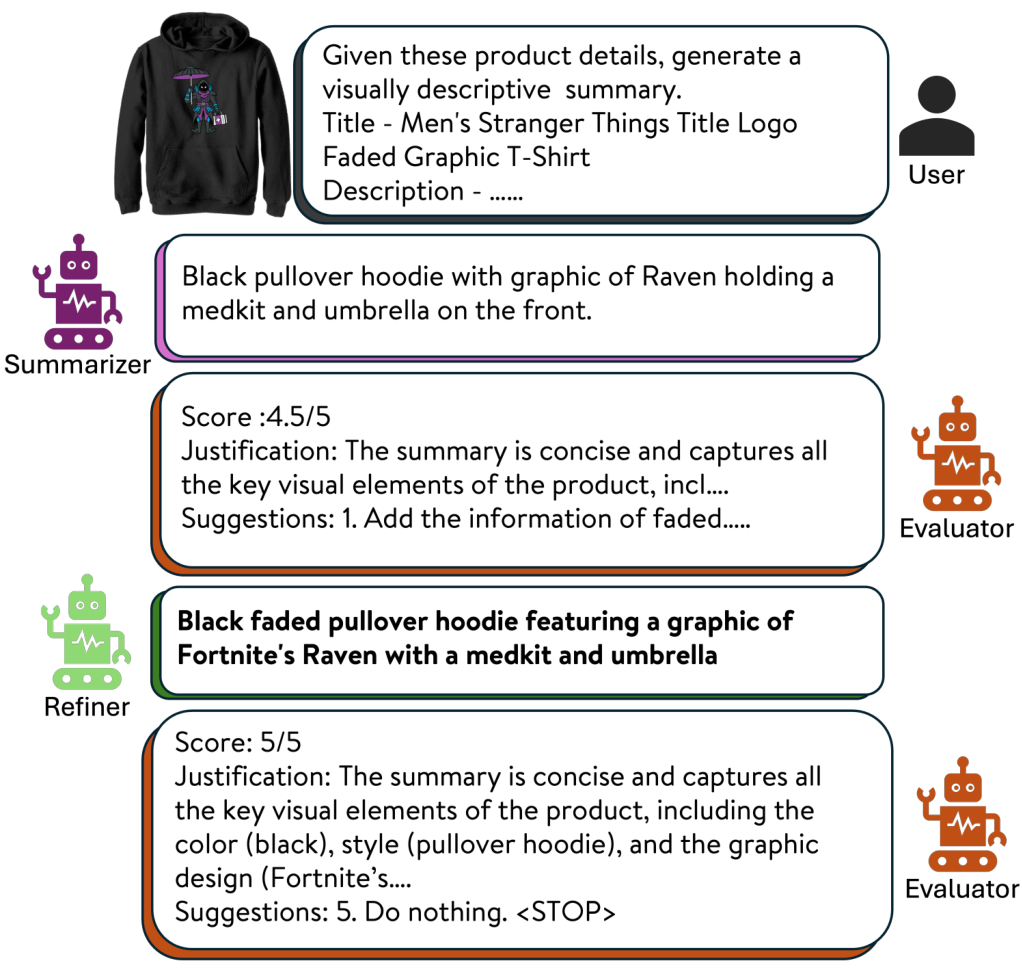
总结器、评估器和细化器的提示在附录 C.1 中提供。
3.3 CLIP 的对比微调
为了在共享语义空间中对齐图像和文本嵌入,我们微调 CLIP,以克服通用模型的限制。我们采用对称对比损失函数,最大化匹配图像-文本对的相似性,同时最小化不匹配对的相似性,从而确保跨模态的稳健对齐。微调的 ViT-B/32 处理裁剪图像,而基于 Transformer 的文本编码器细化 LLM 增强查询。两者产生 512 维嵌入,针对电子商务特定检索任务进行优化。训练涉及多个周期,利用领域特定增强来实现检索和分类任务的更高精度。该损失函数为:
LCLIP=−12N∑i=1N[logevi⋅ti/τ∑j=1Nevi⋅tj/τ+logeti⋅vi/τ∑j=1Neti⋅vj/τ]\mathcal{L}_{\mathrm{CLIP}}=-\frac{1}{2N}\sum_{i=1}^{N}\left[\log\frac{e^{v_{i}\cdot t_{i}/\tau}}{\sum_{j=1}^{N}e^{v_{i}\cdot t_{j}/\tau}}+\log\frac{e^{t_{i}\cdot v_{i}/\tau}}{\sum_{j=1}^{N}e^{t_{i}\cdot v_{j}/\tau}}\right] LCLIP=−2N1i=1∑N[log∑j=1Nevi⋅tj/τevi⋅ti/τ+log∑j=1Neti⋅vj/τeti⋅vi/τ]
其中 τ\tauτ 是对比损失的温度。我们在附录 C 中的算法 1 中总结了 VL-CLIP 训练的步步过程。
3.4 在线部署和可扩展性
在本节中,我们介绍了我们的管道以及如何在 Walmart 的电子商务平台上对数千万购物物品进行大规模部署。该生产推理管道结合了多模态处理、高效索引和可扩展检索,以为电子商务应用提供推荐。以下详细说明每个组件、其可扩展性和在系统中的作用。
3.4.1 图像和文本预处理。我们使用感知哈希 (pHash) [30],这是一种生成紧凑且稳健的图像哈希表示的技术,可生成对缩放和压缩不变的指纹。通过感知哈希技术对图像进行哈希,以识别和移除重复项,减少目录中的冗余。去重后,图像通过视觉定位处理以裁剪产品中心区域。这减少了由背景变化(如同一件连衣裙在不同人体模型上)引起的假阳性。视觉定位使用元数据派生的提示(如“手提包”)动态裁剪产品中心区域。
3.4.2 层次可导航小世界 (HNSW) 索引。嵌入使用 HNSW [19] 进行索引,这是一种基于图的近似最近邻 (ANN) 算法,针对高召回率和低延迟进行了优化。层次图结构允许对数时间搜索复杂度。将元数据(如产品类型)与裁剪图像融合,创建统一数据集。这确保检索同时考虑视觉和上下文信号。为了处理大规模电子商务数据,我们维护一个图像嵌入数据库。在多个配备 T4 GPU 的机器上分配工作负载。
3.4.3 检索和配对排名。对于查询嵌入 eee,HNSW 索引使用余弦相似度检索前 kkk 候选。我们优化过程,通过基于产品类型分组物品并为每个组构建单独索引。
3.4.4 可扩展性。该架构已在 Walmart 的电子商务平台上全面部署,支持实时推荐和多模态检索。该管道无缝整合数据预处理、嵌入生成和检索。这些优化减少了搜索空间和内存使用,同时保持质量。pHash 提高了 MRR 7.2%;基于产品类型的 HNSW 索引提高了 Precision@1 9% 并将延迟减少 81%,相比 IVF 索引。附录 D 中的算法 2 显示了推理过程。
4 实验
4.1 数据准备
数百万产品图像和元数据(如描述、标题、属性)来自广泛的电子商务目录。该多样化数据集包括服装和家居用品,确保类别的全面表示。每个样本包括产品图像(可能高质量,但可能包含 distracting 元素,如真实场景或生活方式场景),以及文本元数据,包括结构化属性(产品类型、性别、年龄组)和非结构化数据(标题、描述)。
我们采用以下预处理步骤清洁输入数据:1) 图像归一化:调整图像大小并使用 CLIP 的预处理管道归一化,Inorm=Iresized−μI_{\text{norm}} = I_{\text{resized}} - \muInorm=Iresized−μ,其中 μ\muμ 和 σ\sigmaσ 是通道-wise 均值和标准差。2) 文本净化:移除 HTML 标签、特殊字符和冗余关键词。保留描述性关键词,同时排除噪声(如“免费 shipping”),产生语义丰富的输入。3) 类别平衡:分层采样确保产品类型的比例表示,以缓解偏差。我们使用 Walmart.com 的时尚和家居类别中的 700 万产品微调 VL-CLIP 模型,如图 2 所述。我们在包含时尚和家居物品的数据集上评估模型。为确保多样性,我们跨不同产品类型(如 T 恤、连衣裙和咖啡桌)等采样物品,结果为时尚 10 个产品类型和家居 7 个,总计 17 个产品类型。总共,我们获得时尚类别 10,000 个样本和家居类别 10,000 个样本用于评估。
4.2 评估指标
VL-CLIP 的性能与现有方法(如 CLIP [23]、GCL [33] 和 FashionCLIP [5])在 Walmart 数据上的多模态检索任务进行比较。CLIP 是一个基础模型,通过对比学习从大规模图像-文本对学习联合表示 [23]。GCL 是一个对比学习框架的泛化,整合排名信息和多个输入字段 [33]。FashionCLIP 是 CLIP 的专门适应,针对时尚领域设计,利用细粒度注释和领域特定特征 [5]。
我们使用两个标准指标测量检索性能:
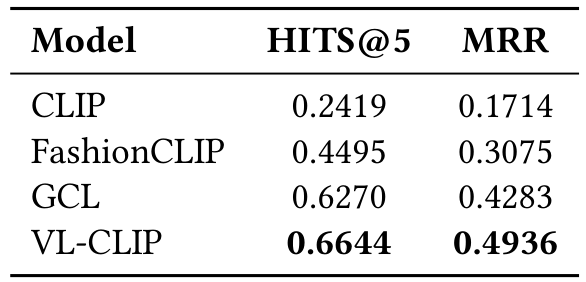
· HITS@ k:报告查询中正确物品位于前 k 结果的比例。对于 N 个查询,每个查询 i 有 ground-truth 正确物品 cic_ici。根据相似性分数排名后,让 rank(cic_ici) 是 cic_ici 的位置。HITS@k=1N∑I(rank(ci)≤k)HITS@k = \frac{1}{N} \sum I(\text{rank}(c_i) \leq k)HITS@k=N1∑I(rank(ci)≤k),其中 I 是指示函数。在我们的评估中,使用 HITS@5。
· 平均倒数排名 (MRR):对于查询 i,如果正确物品 cic_ici 排名为 rank(cic_ici),其倒数排名为 RRi=1/rank(ci)RR_i = 1 / \text{rank}(c_i)RRi=1/rank(ci)。MRR 是这些倒数排名的平均值,该指标特别青睐列表中排名较高的正确物品。
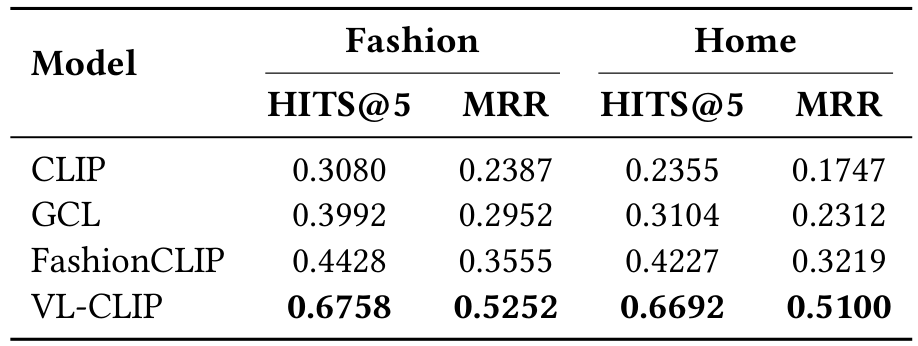
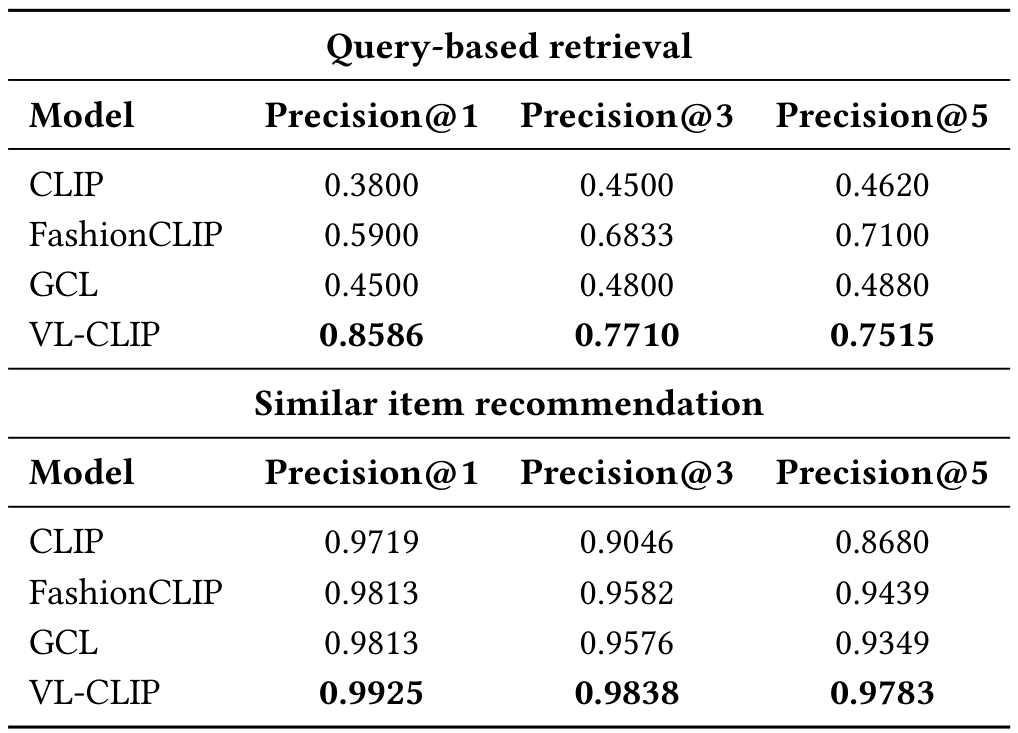
4.3 检索结果
表 1 展示了 CLIP、GCL、FashionCLIP 和我们提出的 VL-CLIP 在时尚和家居数据集上的 HITS@5 和 MRR 指标。CLIP 作为基线,显示出适度的检索能力(时尚 HITS@5 为 0.3080,家居为 0.2355),可能是因为其全球嵌入难以捕获细粒度产品属性。多模态检索任务涉及基于文本描述从给定集合中识别最相关图像。例如,在产品检索场景中,目标是将产品描述与其对应图像匹配。
GCL 通过整合排名信息,实现更高指标(时尚 HITS@5 为 0.3992,家居为 0.3104)。然而,仅依赖排名信息无法完全解决产品图像和文本描述中的领域特定细微差别。
FashionCLIP 通过针对时尚优化的领域适应策略,进一步改善性能(时尚 HITS@5 为 0.4428,家居为 0.4227)。这允许模型更好地编码风格和设计元素。
VL-CLIP 在两个数据集上实现最高的检索准确性和排名质量(时尚 HITS@5 为 0.6758 和 MRR 为 0.5252,家居为 0.6692 和 0.5100)。通过整合局部对象级定位和 LLM 增强文本嵌入,VL-CLIP 更有效地捕获关键产品细节并解决模糊文本描述。
4.4 消融研究
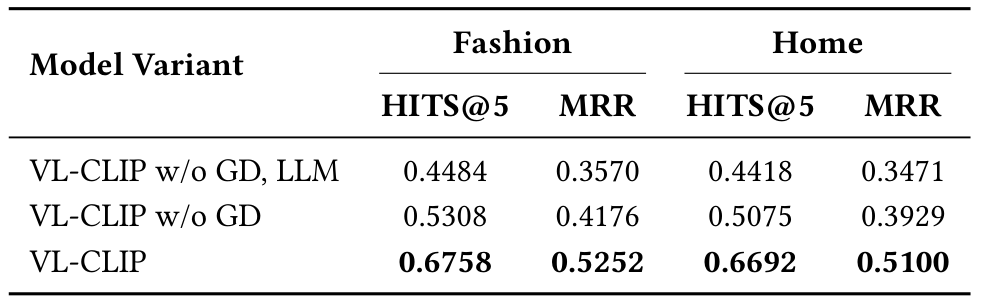
为了深入了解 VL-CLIP 框架中每个组件的作用,我们进行消融研究,通过消除关键模块(视觉定位和 LLM 基于查询细化)并评估其对检索性能的影响。
表 2 总结了消融分析结果。完整的 VL-CLIP 模型实现最高性能(HITS@5 为 0.6758 和 MRR 为 0.5252)。移除视觉定位导致时尚和家居类别中 HITS@5 和 MRR 平均下降 15.34% 和 11.23%,证明了背景移除和关注主要物品的重要性。此外,移除 LLM 基于查询细化步骤导致额外下降(相比缺少视觉定位的模型,HITS@5 下降 7.40%,MRR 下降 5.32%),表明细化文本查询通过提供更清晰、更精确的描述改善了检索准确性。该消融研究突显了视觉定位和 LLM 基于查询增强在提升检索有效性中的关键作用。
4.5 零样本分类
除了信息检索和消融测试,我们还进行了零样本分类任务。我们执行了两个时尚物品属性分类任务:领口分类和图案分类。对于领口分类,我们手动选择了 1,000 个时尚物品,每个属于以下类别:V 领、圆领、挖领、Henley 领、模拟领和船领。我们使用零样本分类方法,为每个类生成描述性文本(如“带有挖领的 T 恤”),并通过文本编码器传递。然后,通过比较图像嵌入与这些文本嵌入找到最近匹配,从而确定预测类。同样,对于图案分类,我们使用以下类别:“纯色”、“卡通人物”、“心形符号”和“花卉印花”。
表 3 呈现了两个分类任务的模型准确性。VL-CLIP consistently 优于其他模型,使其成为时尚属性零样本分类的最可靠选择。其优越性能归功于视觉定位的去噪能力和 LLM 细化查询,提升了文本-图像对齐质量。
4.6 VLM-Agent Evaluation
由于文本和图像信息的对齐非常主观,我们采用VLM代理进行评估。我们的评估包括两个检索任务:基于查询的检索和类似物品推荐。基于查询的检索特别针对细粒度的产品属性,以确保准确检索细微的产品特性。例如,“Teal floral print blouse”是在寻找匹配颜色和图案特性的物品;“Beige V-neck short-sleeve T-shirt”是在寻找颜色、领型和袖型特性的物品。对于基于查询的评估,每个查询对应的检索图像与查询配对,并传递给VLM。VLM模型被要求评估提供的图像是否准确匹配给定查询,输出二进制结果:0(不匹配)或1(匹配)。同样,对于类似物品评估,检索图像与锚点图像配对,VLM被要求评估两幅图像在视觉特性方面是否匹配。我们使用VLM-as-judge评估框架来评估方法的有效性。关于自动查询生成和VLM评估过程的更多细节,请参阅附录E。
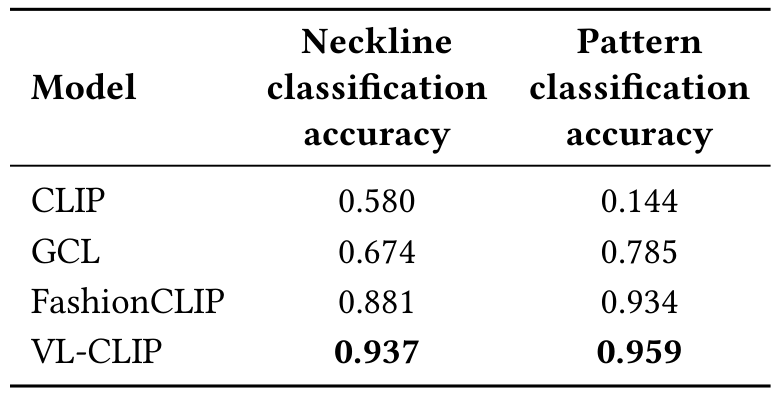
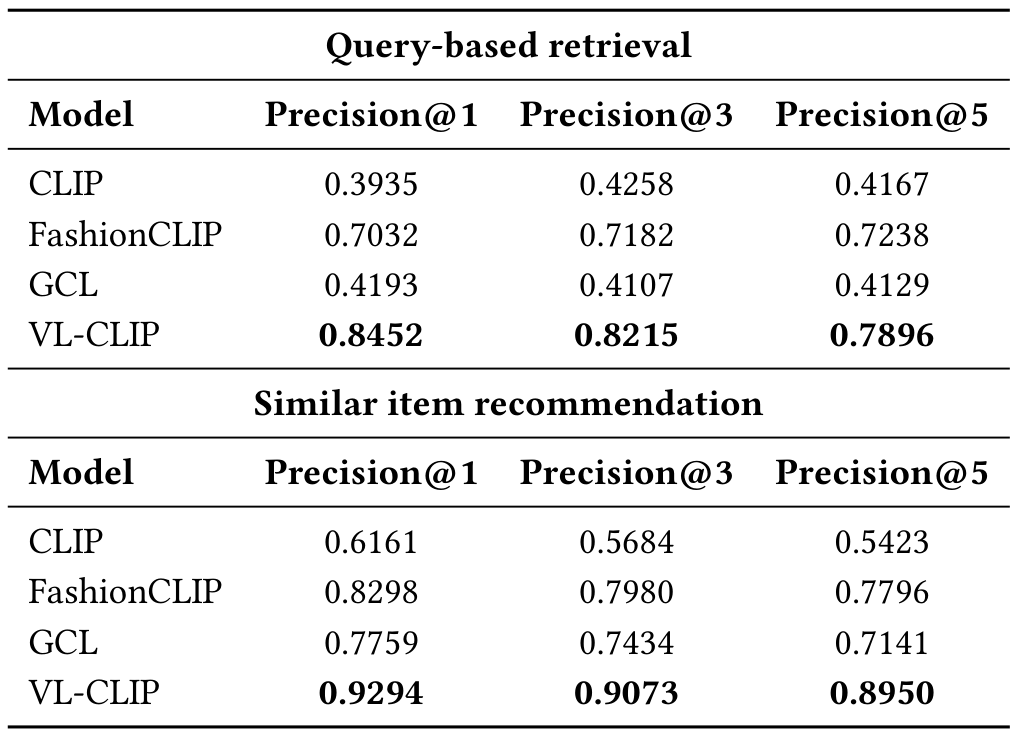
表4展示了Walmart.com电子商务数据集上基于查询的检索性能和类似物品推荐性能。性能使用Precision@1、3、5报告。结果显示,我们的VL-CLIP模型比基准模型(如CLIP、FashionClip和GCL)表现更好。请注意,VL-CLIP的最高值出现在Precision@1,并逐渐下降到Precision@3和Precision@5。这种模式表明,其排名最高的物品几乎总是相关的,而后续位置虽然相关,但相关性略低。相比之下,像CLIP这样的模型有时显示出相反的模式——Precision@1低于Precision@5——表明其顶级推荐 nem总是最佳匹配,尽管它们在较低排名位置包括相关物品。基于查询和类似物品(SI)推荐任务的示例请参阅附录B。
这些改进归功于Visual Grounding和LLM在完善检索过程中的互补作用。Visual Grounding帮助模型关注图像中的主要物品,过滤背景干扰,并强调细粒度的产品属性。同时,LLM通过使查询更结构化和与真实用户意图对齐,从而提升查询质量。这些增强共同实现了更准确地检索匹配特定属性查询的产品。
4.7 Computation Efficiency
VL-CLIP是在Walmart.com时尚和家居类别中的数百万产品上进行微调的。使用分层采样方法确保了超过500种产品类型的多样化比例表示。VL-CLIP在6个周期内实现了稳健的电子商务检索性能,并在提前停止前表现良好(见图4)。模型在视觉和文本嵌入之间显示出强烈的对齐,验证集的对比损失从0.38稳步减少到0.28。
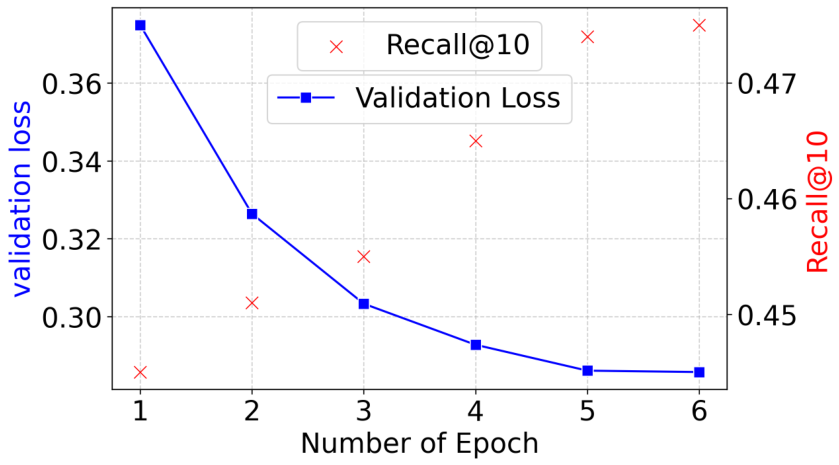
检索性能通过Recall@10衡量,表示模型在47%的查询中有效识别了前10个结果中的相关物品。训练超过这个点会导致Recall@10的轻微下降,表明过度拟合到噪声对或学习能力的饱和。这突显了提前停止的重要性,第6个周期是部署的最佳检查点。这些结果验证了我们结合Visual Grounding、LLM和对比损失的管道在可扩展电子商务推荐系统中的有效性。
4.8 Cross-Domain Generalization
为了评估VL-CLIP的泛化能力,我们在公共Google Shopping数据集上进行零样本评估。该数据集跨越各种电子商务类别,为测试模型在无需额外微调的情况下向新领域转移知识的能力提供了稳健基准。它专为训练和基准细粒度排名任务的多模态检索模型而设计。如表5和表6所示,VL-CLIP在该新数据集上 consistently优于其他模型。
我们进一步在Walmart.com的Art和Toys类别上评估零样本性能,VL-CLIP再次比其他模型取得优越结果。这些发现突显了模型对新型产品领域的强大转移能力(见附录F)。
4.9 Online A/B Test
为了验证VL-CLIP模型的有效性,我们在美国两大电子商务平台之一上进行大规模A/B测试。实验将我们的VL-CLIP与部署的基准模型进行比较。测试持续四周,涉及数百万用户交互和各种产品类别。评估的关键指标包括:点击通过率(CTR)、添加至购物车率(ATC)和总商品价值(GMV)。
表7突显了我们的系统相对于基准模型的相对改进。在线A/B测试验证了VL-CLIP的有效性,显示CTR增加了18.6%,ATC率增加了15.5%,GMV提升了4%,这突显了VL-CLIP的实际功效。这些结果突显了VL-CLIP在理解用户意图和使推荐与用户偏好对齐方面的性能。

我们在图5中展示了一些案例研究。第一列是锚点物品,其余是基于VL-CLIP的前五个推荐物品。在图5(a)中,锚点物品是绿色花朵中长裙。VL-CLIP检索了类似风格的裙子,捕捉了图案和长度的变化,同时保持整体美学。图5(b)中的物品是黑色裹身式长袖裙。VL-CLIP推荐了具有类似袖长和结构轮廓的物品,关注颜色和风格。图5©、(d)和(e)展示了VL-CLIP的强大时尚理解能力。更多案例研究请参阅附录B中的图6-8。
5 Conclusion and Future Work
在本研究中,我们通过引入VL-CLIP框架解决了电子商务多模态表示学习的关键挑战,该框架集成了Visual Grounding用于视觉表示增强和LLM增强的文本嵌入。VL-CLIP在电子商务数据集上展示了比最先进基准模型优越的性能。具体而言,HITS@5在Home数据集上提高了184.16%,在Fashion数据集上提高了119.42%。此外,LLM评估结果表明,基于查询的检索提高了62.66%,类似物品推荐提高了12.71%。在线A/B测试进一步验证了VL-CLIP的有效性,显示CTR增加了18.6%,ATC率增加了15.5%,GMV提升了4%,突显了VL-CLIP的实际功效。在Walmart.com上部署VL-CLIP突显了其可扩展性和现实影响。该框架的层次索引和分布式计算管道高效处理了数百万目录物品。
VL-CLIP: Enhancing Multimodal Recommendations via Multimodal Recommendations viaVisual Grounding and LLM-Augmented CLIP Embeddings: -Augmented CLIP Embeddings:Appendix
Ramin Giahi*Walmart Global TechSunnyvale, CA, USAramin.giahi@walmart.com
Kehui Yao *Walmart Global TechBellevue, WA, USAkehui.yao@walmart.com
Sriram Kollipara* 米Walmart Global TechSunnyvale, CA, USAsriram.kollipara@walmart.com
Kai Zhao* *Walmart Global TechSunnyvale, CA, USAkai.zhao@walmart.com
Vahid MirjaliliWalmart Global TechSunnyvale, CA, USAvahid.mirjalili@walmart.com
Jianpeng XuWalmart Global TechSunnyvale, CA, USAjianpeng.xu@walmart.com
Topojoy BiswasWalmart Global TechSunnyvale, CA, USAtopojoy.biswas@walmart.com
Evren KorpeogluWalmart Global TechSunnyvale, CA, USAekorpeoglu@walmart.com
Kannan AchanWalmart Global TechSunnyvale, CA, USAkannan.achan@walmart.com
A Nomenclature
本节呈现了命名表,包括贯穿论文中使用的数学符号的定义和解释。
B Visualization for Query-based retrieval andSimilar item recommendation task
本节呈现了时尚和家居物品的基于查询的检索和类似物品推荐(SI)任务的可视化。图6、7和8展示了基于文本查询和锚点图像的顶级检索结果。
在图6和7中,每行第一列是文本查询,其余列是前5个推荐产品。时尚查询范围从特定服装类型(如“ankara dress”“UCLA football t-shirt”)到主题查询如“mickey mouse for school”。家居相关查询包括装饰和家具物品,如“marble top coffee table with gold legs”和“stripe bed sheet”。结果反映了模型从文本中捕捉细粒度语义细节的能力。
图8展示了家居产品的类似物品推荐,其中每个锚点图像后跟视觉相似的物品。示例包括装饰椅、花纹地毯、床罩和电视柜。推荐物品在材料、颜色方案和整体风格方面与锚点紧密匹配,突显了模型在基于图像的相似性检索中的有效性。
这些示例共同展示了VL-CLIP在跨产品类别的多模态理解和视觉匹配方面的优势。
query-based recommendations
[外链图片转存中…(img-UzanrhL5-1754397503743)]


图8: 家居物品的类似物品推荐示例:第一列是锚点物品,其余是基于图像相似性的前5个推荐物品。(a) 锚点图像是现代白金装饰椅。推荐物品共享类似的白调内饰和金色或金属腿,保持当代优雅美学。(b) 锚点图像是色彩鲜艳的几何图案地毯。推荐物品特征鲜艳的几何或抽象图案,与锚点在颜色和设计上相似。© 锚点图像是浅蓝色薄纱窗帘。推荐物品包括薄纱或半薄纱窗帘,具有花朵、植物或抽象图案,保留柔和通风外观。(d) 锚点图像是带有红色和粉红色玫瑰的花朵图案床罩。检索物品强调类似颜色的花朵图案和复杂设计,保持舒适装饰外观。(e) 锚点图像是带有开放式架子和黑色金属框架的木质电视柜。推荐物品特征类似工业或乡村风格,结合木表面和黑色金属元素用于结构支持和美学。
C Training Algorithm
算法1概述了构建VL-CLIP模型的逐步过程,包括构建图像/文本对、定位、查询细化和最终微调模型。
Algorithm 1 VL-CLIP Algorithm
“productName”: “Unique Bargains Women’s SleevelessHalterNeckBohoElasticWaistFloralMaxiSundressSBlack”,
“productLongDesc”: “Machine Wash Cold with LikeColors. Floral. Regular. Long. Sleeveless. Boho. 100%Polyester. Imported”,
“productShortDesc”: "This floral boho dress is madeof several design point: floral pattern,
halter,sleeveless, beach maxi dress. Styled with theearings, hand bag and high heels as your chic look!Floral Maxi Dress, Boho Dress, Halter Neck, ElasticWaist. Suit for summer and many occasion,such asbeach, party, vacation dating. MoDEL SHow: RegularFit. Wear in size Xs. Wash Cold with Like Color…'productType": “Dresses”
Sleevelesshalterneckfloralmaxisundresswithelastic waist, black, boho style.
<Evaluator iteration 1> 1> # Score: 4/5
Justification: The summary is concise and captureskey visual elements such as the sleeveless halterneck, floral pattern, maxi length, elastic waist, andboho style. However, the inclusion of the materialcomposition (100% polyester) is not visuallyobservable.
Suggestions:
- Remove the information of [1oo% polyester].
<Refiner iteration 1> iteration 1>
Sleevelesshalterneckfloralmaxisundresswithelastic waist, black, boho style.
KEvaluatoriteration 2> # C.1 Agent Prompts
在本节中,我们在表9中列出了系统提示,在表10中列出了用户提示。
C.2 LLM-Driven Textual Query SynthesisExamples
Score: 5/5
Justification: The summary is concise and captureskey visual elements such as the sleeveless halterneck, floral pattern, maxi length, elastic waist, andboho style. It also includes the color (black), whichis visually observable. No non-visual details areincluded, and the summary is less than 20 words.Suggestions: 5. Do nothing.


“productName”: “Caster Chair Company 7-Piece42x[42/60] Caster Dining Set Wood Edge Laminate TableTop & Desert Chairs”,
“productLongDesc”: “DURABLE AND STYLISH: This 7-piecediningsetfeaturesasolidoakwoodedgelaminatetable top with a steel base, paired with 6 casterchairs upholstered in desert polyurethane andoak-finished plywood arms. COMFORTABLE SEATING: The28"D x 23"w x 36"H caster chairs have a 360-degreeswivel and tilt mechanism, making it easy to move andadjust your seating position. Each chair has a weight.·…”.
'productShortDesc": "Introducing Frankie 7-PieceCaster Dining Set by Caster Chair Company \u2013 astunning combination of durability, style, andversatility! ",
'productType": “Dining Furniture Sets”
Summary>
Seven-piece dining set with oak wood edge laminatetable, steel base, and six desert polyurethane casterchairs with oak-finished arms.
<Evaluator iteration 1> iteration 1> # Score: 4/5
Justification: The summary is concise and captureskey visual elements such as the oak wood edge laminatetable, steel base, and desert polyurethane casterchairs with oak-finished arms. However, it couldinclude more specific details about the table’sextendable feature and the solid oak wood crowns onthe chair andtable bases.
Suggestions:
-
Add the information of [extendable bow-end tabletop] .
-
Add the information of [solid oak wood crowns onchairandtablebases].
<Refiner iteration 1>
Seven-piece dining set with extendable bow-end oakwood edge laminate table, steel base, and desertpolyurethane caster chairs with oak-finished arms andsolid oak wood crowns.
<Evaluator iteration 2> iteration 2> # Score: 4/5
Justification: The summary is concise and captureskey visual elements such as the extendable bow-end oakwood edge laminate table, steel base, and desertpolyurethane caster chairs with oak-finished arms andsolid oak wood crowns. However, it is slightly overthe word limit.
Suggestions:
- Shorten the summary.
<Refiner iteration 2> iteration 2>
Seven-piecediningsetwithoakwoodedgelaminatetable, steel base, and desert polyurethane casterchairs with oak-finished arms.
<Evaluator iteration 3>
Score: 5/5
Justification: The summary is concise and captureskey visual elements such as the oak wood edge laminatetable, steel base, and desert polyurethane casterchairs with oak-finished arms.No non-visual detailsare included, and the summary is less than 20 words.Suggestions: 5. Do nothing.
D Deployment Algorithm
本节描述了VL-CLIP框架的部署算法,包括可扩展处理、嵌入生成和使用HNSW索引的效率检索步骤。

E VLM Evaluation Process
我们使用VLM-based评估框架评估我们在Walmart.com电子商务数据集上基于查询的检索方法的有效性。我们的方法遵循结构化管道,包括自动查询生成和VLM-as-judge评估,如图9所述。
E.1 Automated Query Generation
● 属性提取:我们应用Vision-Language Model(VLM)从产品物品的随机子集提取结构化属性。给定输入图像,提取的属性可以表示为
A={(a1,v1),(a2,v2),…,(am,vm)}A=\{(a_{1},v_{1}),(a_{2},v_{2}),\ldots,(a_{m},v_{m})\} A={(a1,v1),(a2,v2),…,(am,vm)}
其中$ a_i 表示属性类型(如“color”),表示属性类型(如“color”),表示属性类型(如“color”), v_i 是其值(如“blue”或“multicolor”)。提取的属性被过滤以确保它们直接相关于图像中的主要物品,从而得到是其值(如“blue”或“multicolor”)。提取的属性被过滤以确保它们直接相关于图像中的主要物品,从而得到是其值(如“blue”或“multicolor”)。提取的属性被过滤以确保它们直接相关于图像中的主要物品,从而得到 A_{\text{filtered}} $。
· 使用产品数据中存在的细节。· 排除产品细节中未找到的信息。· 将摘要限制在20词以内。· 仅关注可视可观察属性:颜色、纹理、形状和材料。· 不包括测量、价格、品牌名称或益处。· 提供一个最终精炼摘要,没有额外评论。

· 查询生成:我们利用LLM从提取的属性生成搜索查询。给定物品X的过滤属性集$ A_{\text{filtered}} ,查询由,查询由,查询由 Q = \text{LLM}(A_{\text{filtered}}) $生成。例如,一个“T-shirt”产品具有属性“sleeve_length” = “long sleeves”, “pattern_placement” = “front, center”,会被转化为查询:“T-shirt with long sleeves and Mickey Mouse pattern on front”。
这种结构化方法在数据集之间实现了公平比较,同时确保生成的查询与真实搜索行为对齐。
E.2 VLM-as-judge Evaluation
● Top-K检索:对于每个查询,我们检索前K结果,$ R_k $:
Rk={I1,I2,...,IK}R_{k}=\{I_{1},I_{2},...,I_{K}\} Rk={I1,I2,...,IK}
其中K=10。检索物品基于其与查询的相关性进行排名。
· 相关性评估:每个检索图像$ I_j $与其对应查询配对,并由VLM(GPT-4o)测量相关性,分配二进制相关性分数:
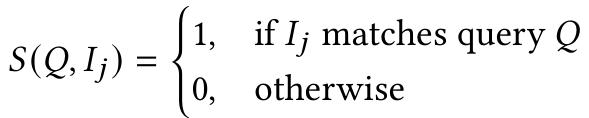
用于此评估的提示列在表11中。
· 性能指标:我们计算Precision@k,其中k ∈ {1, 3, 5}。
Precision@k=TPkk\text{Precision}@k = \frac{\text{TP}_k}{k} Precision@k=kTPk
其中,TPk是前k中正确检索的相关物品数量,k是检索结果总数。
E.3 Similar Item Recommendation
我们还通过类似物品推荐任务评估模型性能,如下:
· 我们随机选择N个锚点物品,其中N=100。对于每个锚点,我们检索前K推荐,其中K ∈ {1, 3, 5}。每个锚点与其推荐物品配对,并使用大型语言模型(GPT-4o)评估相似性。模型为每个锚点-推荐对分配二进制相关性分数(0或1),其中1表示对相似,0表示不相似。用于评估视觉相似性的特定提示在表11中提供。· 我们使用与基于查询的检索方法相同的性能指标。
表11显示了用于VLM-as-Judge评估的提示。

FCross-Domain Generalization F
为了评估我们的方法的泛化能力,我们将实验扩展到原始领域之外,通过在零样本设置下评估Walmart Art和Toys类别。
表12报告了Art和Toys类别的零样本多模态检索结果。我们观察到VL-CLIP consistently优于其他模型,展示了其对新产品类型的强大转移能力。
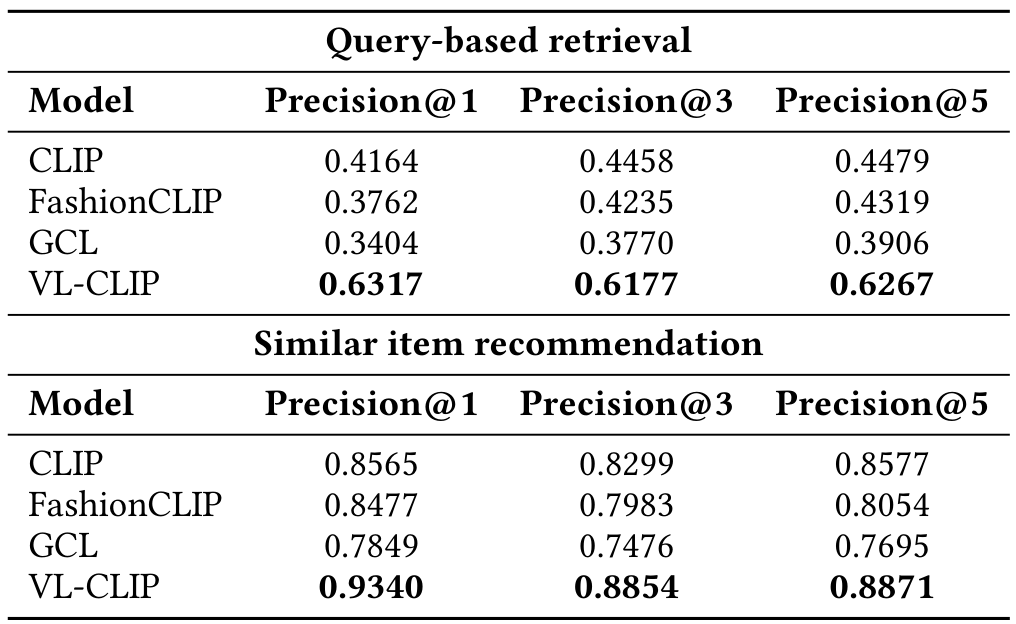
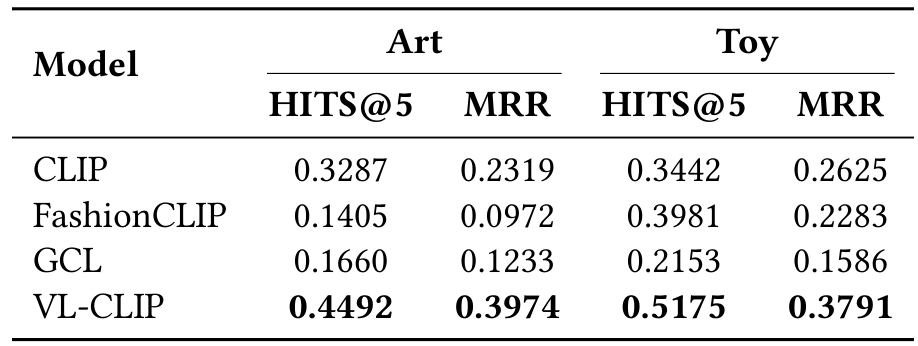
表13显示了Walmart的Art和Toys类别的基于查询的检索和类似物品推荐的LLM-based评估。
Original Abstract: Multimodal learning plays a critical role in e-commerce recommendation
platforms today, enabling accurate recommendations and product understanding.
However, existing vision-language models, such as CLIP, face key challenges in
e-commerce recommendation systems: 1) Weak object-level alignment, where global
image embeddings fail to capture fine-grained product attributes, leading to
suboptimal retrieval performance; 2) Ambiguous textual representations, where
product descriptions often lack contextual clarity, affecting cross-modal
matching; and 3) Domain mismatch, as generic vision-language models may not
generalize well to e-commerce-specific data. To address these limitations, we
propose a framework, VL-CLIP, that enhances CLIP embeddings by integrating
Visual Grounding for fine-grained visual understanding and an LLM-based agent
for generating enriched text embeddings. Visual Grounding refines image
representations by localizing key products, while the LLM agent enhances
textual features by disambiguating product descriptions. Our approach
significantly improves retrieval accuracy, multimodal retrieval effectiveness,
and recommendation quality across tens of millions of items on one of the
largest e-commerce platforms in the U.S., increasing CTR by 18.6%, ATC by
15.5%, and GMV by 4.0%. Additional experimental results show that our framework
outperforms vision-language models, including CLIP, FashionCLIP, and GCL, in
both precision and semantic alignment, demonstrating the potential of combining
object-aware visual grounding and LLM-enhanced text representation for robust
multimodal recommendations.
PDF Link: 2507.17080v1
5. BetterCheck: Towards Safeguarding VLMs for Automotive Perception Systems
Authors: Malsha Ashani Mahawatta Dona, Beatriz Cabrero-Daniel, Yinan Yu, Christian Berger
Deep-Dive Summary:
BetterCheck: 面向汽车感知系统的视觉语言模型安全保障
Malsha Ashani Mahawatta Dona, Beatriz Cabrero-Daniel, Yinan Yu, Christian Berger
University of Gothenburg and Chalmers University of Technology
Gothenburg, Sweden
{malsha.mahawatta,beatriz.cabrero-daniel,christian.berger} @ gu.se, yinan @ chalmers.se
摘要
大型语言模型(LLMs)正日益扩展到处理多模态数据,例如文本和视频。它们在理解图像内容方面的表现已超越专用的神经网络(如YOLO),后者仅支持有限的词汇表,即可检测的对象。在不受限制的情况下,LLMs,尤其是最先进的视觉语言模型(VLMs),在描述复杂交通情况方面表现出色,这使得它们可能成为汽车感知系统的潜在组件,以支持理解复杂交通或边缘情况。然而,LLMs 和 VLMs 容易出现幻觉,即可能忽略真实存在的交通参与者(如易受伤害的道路使用者),或虚构不存在的交通参与者。前者可能导致先进的驾驶员辅助系统(ADAS)或自动驾驶系统(ADS)做出灾难性决策,而后者可能导致不必要的减速。在本研究中,我们系统评估了 3 种最先进的 VLMs 在 Waymo Open 数据集的多样子集上的性能,以支持检测此类幻觉并为 VLM 支持的感知系统提供安全保障。我们观察到,专有和开源 VLMs 都表现出卓越的图像理解能力,甚至能注意人类难以察觉的细微细节。然而,它们仍容易在描述中虚构元素,因此需要如我们提出的 BetterCheck 等幻觉检测策略。
I. 引言
如今,大型语言模型(LLMs)的采用已扩展到各种领域,包括教育、研究、制造和医疗等领域 [1],[2]。如预训练 Transformer(GPT)等 LLMs 的应用,在这些领域产生了积极影响,通过其出色的理解和生成能力开辟了新机遇 [1]。
A. 问题领域和动机
随着现代车辆发展为智能的网络物理系统(CPS)[3],它们能够容纳强大的集中式处理单元和硬件加速器(如 GPU),执行专用的神经网络(NNs)变得越来越可行,从而支持先进的驾驶员辅助系统(ADAS)和自动驾驶(AD)。这些高级功能使实时感知、决策、控制功能成为可能,甚至可以在本地运行 LLMs,而不依赖云基础设施 [4],[5]。
处理多模态数据的 LLMs 提供了计算机视觉和自然语言处理能力,当应用于理解图像流时,被称为视觉语言模型(VLMs)[6]。这些 VLMs 旨在理解视觉输入(如图像和视频)并生成基于文本的响应。在图像描述、视觉问答和多模态推理等任务中,VLMs 显示出非凡的能力,展示了它们在汽车上下文中的感知和监控任务中的潜力 [7]。由于其出色的自然语言通信能力,它们还可以用作人机界面(HMI)来支持车内乘客,从而使车辆更易访问和包容 [8]。
然而,由于 LLMs 可能产生的幻觉 [9],此类 LLMs 辅助系统的可信度仍存疑。因此,在安全关键系统(如车辆)中使用 LLMs 时,必须设计包含 VLMs 的数据处理管道,并添加安全保障机制来检测和缓解潜在幻觉。
B. 研究目标和研究问题
现有文献提出了针对 LLMs 辅助任务的幻觉检测策略。Manakul 等人 [10] 评估并扩展了 SelfCheckGPT 技术,用于识别 LLMs 在文本输出中生成的不合理信息。Dona 等人 [7] 提出 SelfCheckGPT 的变体,用于检测多模态上下文中的幻觉,特别是针对汽车应用。本研究的目的是确定适应后的 SelfCheckGPT 方法在不同最先进 LLMs 用于图像描述和幻觉检测时的性能,特别是关注 LLMs 在描述中忽略关键交通参与者的程度,从而影响 LLMs 辅助感知和监控系统的可信度。
- RQ-1: 根据人类评估者意见,最先进 VLMs 在描述真实汽车视频片段方面的质量如何?
- RQ-2: 每个测试的 VLM 在虚构或忽略交通参与者的程度上如何?
- RQ-3: 选定的 VLMs 在检查自身结果方面的能力如何,从而丢弃可能包含幻觉或忽略关键交通参与者的描述?
C. 贡献和范围
我们系统评估了适应后的 SelfCheckGPT 幻觉检测框架在不同 LLMs 组合下的性能,主要贡献是扩展该框架以减少忽略潜在交通参与者的可能性,并系统评估 VLMs 作为描述者和检查者的性能。
D. 论文结构
论文结构如下:第 II 节回顾现有的幻觉检测和缓解策略;第 III 节概述实验管道;第 IV 节讨论结果和解释;第 V 节进行分析和讨论;第 VI 节总结并展望未来工作。
II. 相关工作
我们探讨了 SelfCheckGPT [10] 的采用和使用场景,以识别现有文献中的空白和限制,并审查选定的研究以了解其在汽车领域的适用性,特别是针对 LLMs 辅助感知系统。
最近,Sawczyn 等人 [11] 提出了基于 SelfCheckGPT 的幻觉检测技术 FactSelfCheck,该方法在事实级别进行检测而非句子或段落级别。通过将事实表示为知识图谱并分析事实一致性来计算句子和段落级一致性。作者声称该技术优于 SelfCheckGPT,但要应用于汽车上下文,需要适应处理图像和视频数据,而非仅文本。此外,添加映射视觉内容为知识三元组的中间层可能会增加复杂性,挑战实时检测需求。
SelfCheckAgent [12] 是一种以 SelfCheckGPT 为基准的幻觉检测技术,它结合多个代理提供多维方法。作者引入了三个代理:符号代理评估响应的事实性、专门检测代理使用微调的 Transformer-based LLM 识别幻觉,以及上下文一致性代理利用零样本和思维链提示。虽然上下文一致性代理可适应汽车领域,但前两个代理限于文本数据,且整体方法不包含多模态数据。
Yang 等人 [13] 提出了一种利用输入文本中识别的变形关系的新型幻觉检测技术,声称在相同条件下优于 SelfCheckGPT。该技术通过提示 LLMs 使用同义词和反义词生成响应,然后使用 SelfCheckGPT 进行一致性检查。尽管在某些温度设置下表现更好,但使用同义词和反义词可能引入双重否定等语义问题。
Dona 等人 [7] 为汽车上下文提出 SelfCheckGPT 的适应版本,探索其在图像序列感知任务中的适用性。作者多次记录图像序列的描述,然后将第一描述的句子与剩余描述比较,以评估支持度。基于句子级一致性分数,实现排除机制移除不一致句子。该技术显示了在汽车感知系统中检测和缓解幻觉的潜力。
III. 方法论
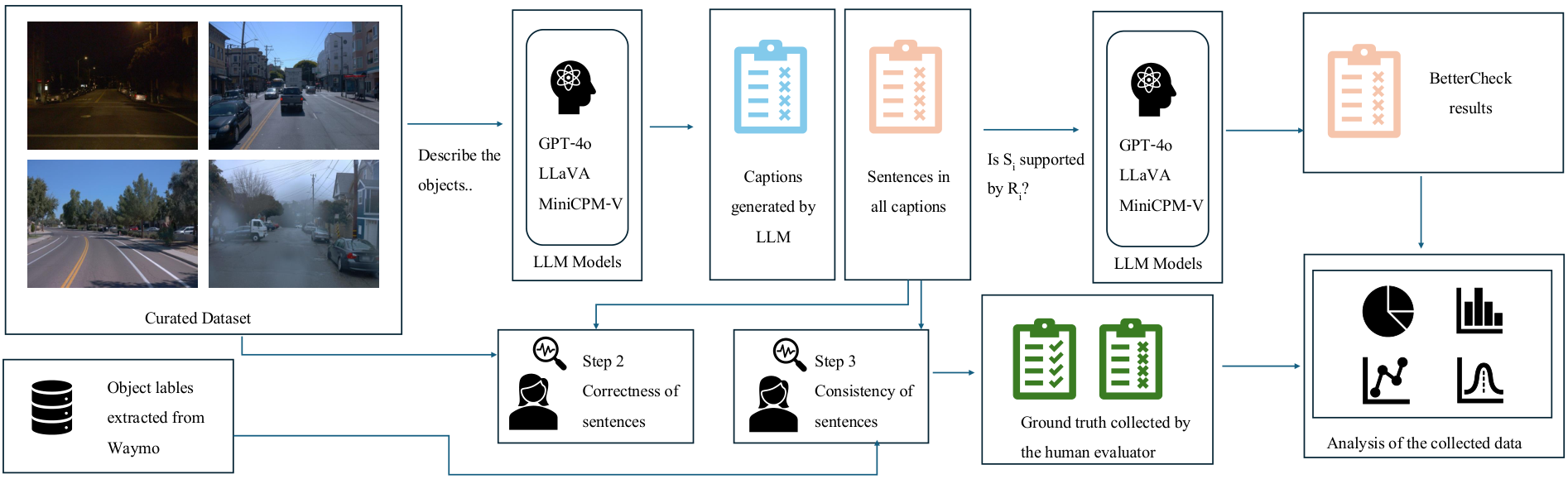
实验管道概述如图 1 所示。我们从 Waymo Open 数据集选择了 20 个驾驶场景,并提取相应对象标签。将选定的图像重复输入三个最先进的 LLMs(GPT-4o、LLaVA 和 MiniCPM-V),使用预定义提示记录响应。然后处理和统计分析这些结果以回答研究问题。
A. 数据集整理和准备
我们使用 Waymo Open 数据集 [14],该数据集于 2021 年由 Google 收集,涵盖美国城市和郊区地区,包括 2030 个约 20 秒的片段。每帧视频包含来自五个摄像头、LiDAR 和雷达传感器的数据,覆盖各种驾驶场景、天气条件、白天/夜晚和社区。
在实验中,我们从训练集中采样每十帧,专注于前置摄像头图像(分辨率为 1920x1280 像素)。最终数据集包括从 20 个不同驾驶场景中选出的 500 张图像,确保多样性,包括不同社区、天气和昼夜条件。从每个场景中手动检查 25 张图像,以确保图像差异性。图 2 显示了从 Waymo 数据集中选出的样本图像。

B. 数据收集
如图 1 所示,我们将整理后的数据集输入三个最先进的 LLMs:专有模型 GPT-4o [15],以及本地执行的 LLaVA [16] 和 MiniCPM-V [17]。我们使用 Ollama Python 库 [18] 访问这些模型。
首先,使用以下提示让每个 LLMs 描述图像中的不同对象,该提示经过多次迭代以获取简短句子,每个句子解释一个对象。我们采用“Best of Three (BO3)”策略 [20],对每个图像重复三次提示,以获得更精确的响应。
提示:
“Describe the different objects visible in the image. Please write very simple and clear sentences. Use the format: “There are [object]”. For example, There are cars. There are people. There are cyclists. Look carefully and make sure to mention all types of objects you see, especially people. If there are multiple types of objects in the image, provide a separate sentence for each type.”
接下来,将每个响应 R 分解为句子级元素 s1…n。由人类标注者评估每个句子与图像的正确性和与 Waymo 对象标签的一致性,以检查 LLMs 是否忽略了可见交通对象。这一点对于感知任务至关重要,因为忽略交通参与者可能导致严重后果。
我们使用 Cohen’s kappa [21] 评估人类标注者之间的 inter-rater 一致性。
然后,应用适应后的 SelfCheckGPT [7],使用相同的 LLMs 检查自身响应,以检测幻觉。提示格式为:
Context: CONTEXT Sentence: SENTENCE Is the sentence supported by the context above? Answer Yes or No:
C. 数据分析
数据处理步骤包括:
- 图像描述: 对每个图像使用测试 VLMs 三次生成描述,并存储响应和执行时间。
- 正确性标注: 人类标注者评估每个句子的正确性,丢弃超过 50 个字符的句子。
2.1. Inter-rater 一致性: 一致性范围为 50% 到 80%,部分由于语义差异。 - 标签一致性标注: 与 Waymo 标签比较,检查忽略的交通对象。
- 自检查: 将句子与图像的其他描述配对。
- 统计分析: 计算正确率、幻觉率和忽略率等指标。
IV. 结果
A. 描述的评估(步骤 1 和 2)
GPT-4o 生成的描述准确、精确,句子简短,每个解释一个对象,未忽略或虚构对象。
示例: “There are cars. There are buildings. There are streetlights. …”
MiniCPM-V 在描述图像方面表现出色,能识别远处对象,但有时不严格遵守提示,生成较长句子,可能部分不正确。
示例: “There’s an SUV parked on a curb to our left. …”
LLaVA 生成的描述简短、遵守提示,但经常虚构对象,如消防栓,并忽略某些对象。
示例: “The sky is overcast. There are buildings along the street. …”
- 不涉及 Waymo 标注交通参与者的描述: GPT-4o 常提及街道、建筑物等(图 3a);MiniCPM-V 常提及道路、云等(图 3b);LLaVA 常提及街道、建筑物等(图 3c)。


B. 描述的质量(步骤 2 和 3)
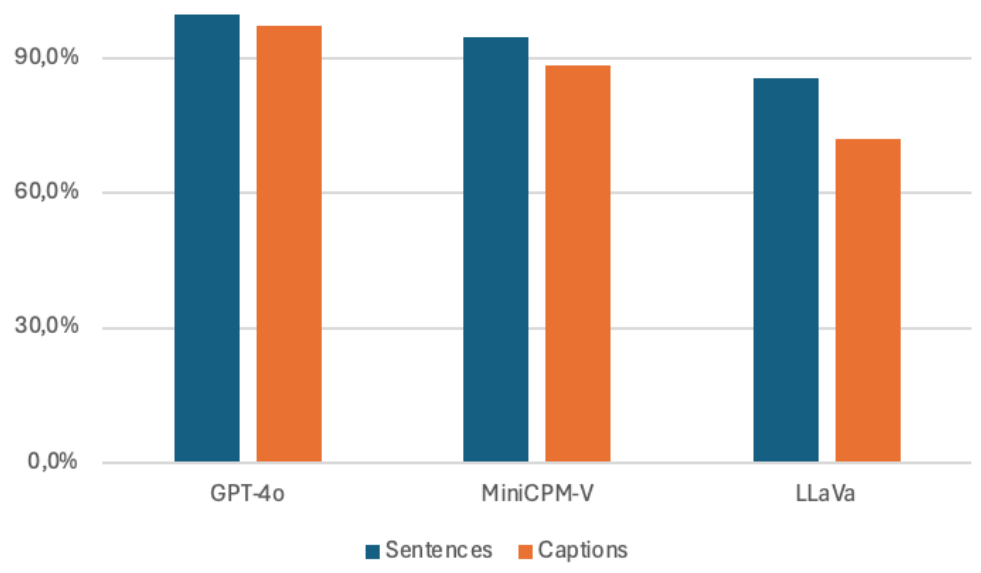
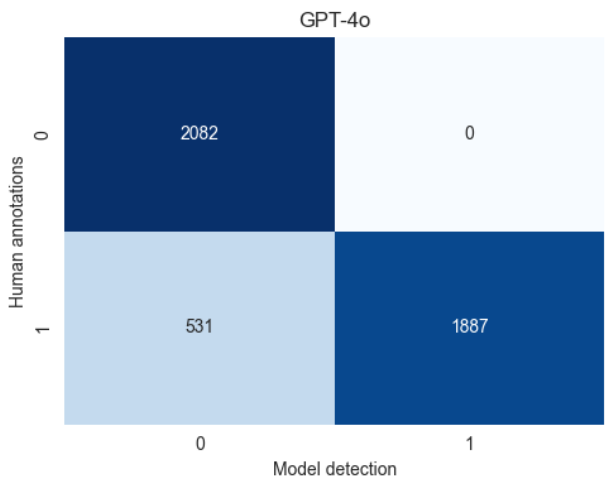
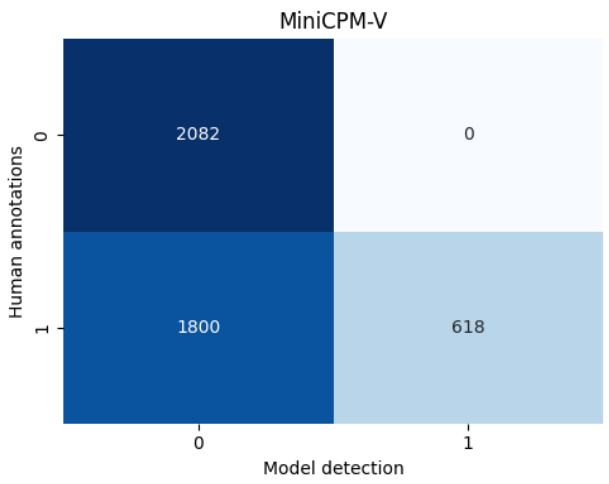
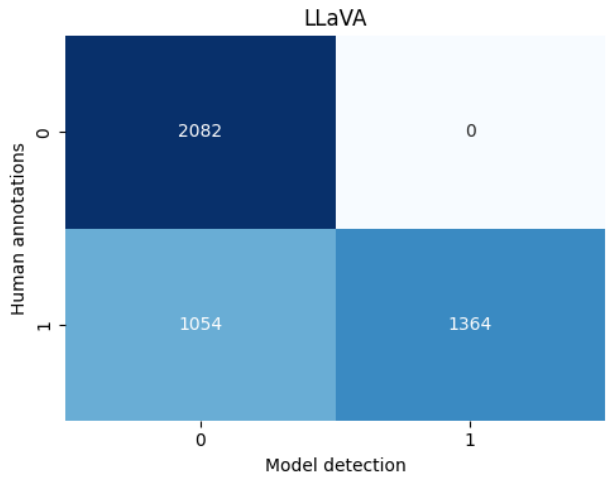
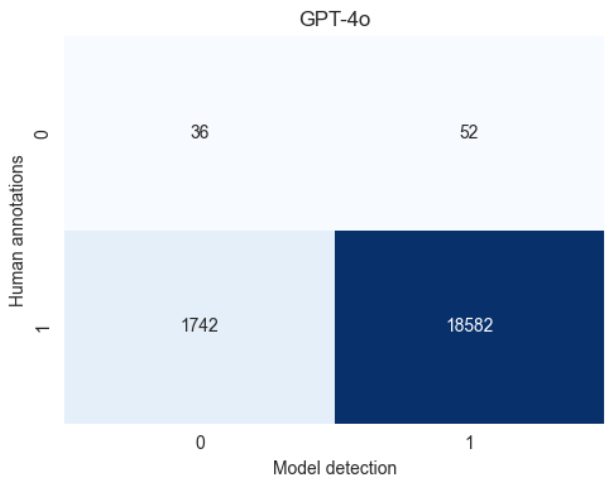
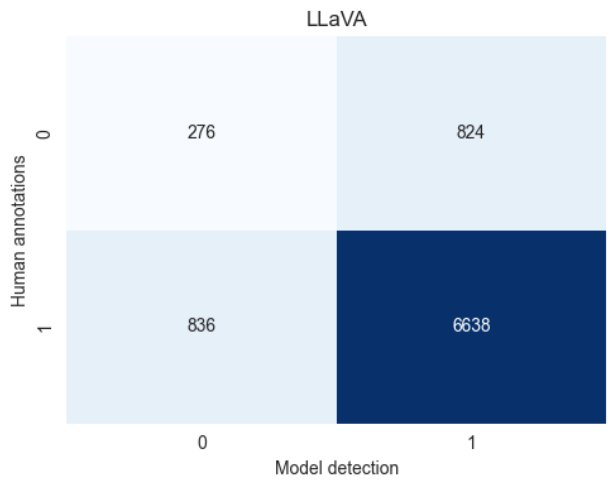
GPT-4o 的句子级正确率为 99.6%,描述级为 97.1%。MiniCPM-V 的句子级正确率为 94.8%,描述级为 88%。LLaVA 的句子级正确率为 85.6%,描述级为 71.9%。图 4 显示了这些结果。
统计指标:GPT-4o 的精确率为 100.0%,召回率为 78.04%;MiniCPM-V 的精确率为 100.0%,召回率为 25.56%;LLaVA 的精确率为 100.0%,召回率为 56.41%。
C. BetterCheck(步骤 4)
使用相同 LLMs 检查自身响应:GPT-4o 的精确率为 99.72%,召回率为 91.43%;MiniCPM-V 的精确率为 100.0%,召回率为 25.56%;LLaVA 的精确率为 88.96%,召回率为 88.81%。
V. 分析和讨论
针对 RQ-1,我们比较了 VLMs 生成正确描述的能力。GPT-4o 和 MiniCPM-V 表现出色,但 LLaVA 幻觉较多(图 4)。
针对 RQ-2,我们分析了幻觉和忽略情况。所有模型都忽略了某些交通参与者,如图 5 所示。
针对 RQ-3,我们评估了自检查性能,结果显示模型能通过重复提示改善描述的一致性。
VI. 结论和未来工作
最先进的 VLMs 在处理多模态数据方面表现出色,但仍可能忽略或虚构交通参与者。为汽车感知系统添加安全保障机制不可或缺。我们提出的 BetterCheck 是 SelfCheckGPT 的扩展,尽管当前 VLMs 在计算资源上存在挑战,但未来版本预计会改进这些方面,并优化提示技术以适应感知系统。
ACKNOWLEDGMENTS
本节是对本文研究资助来源的致谢。该研究获得了以下机构的资助:
- 瑞典战略研究基金会 (SSF),资助编号 FUS21-0004SAICOM。
- 瑞典研究理事会 (VR),包括根据资助协议 2023-03810 的支持。
- 瓦伦伯格人工智能、自主系统和软件程序 (WASP),该程序由克努特和艾丽斯·瓦伦伯格基金会提供资金。
Original Abstract: Large language models (LLMs) are growingly extended to process multimodal
data such as text and video simultaneously. Their remarkable performance in
understanding what is shown in images is surpassing specialized neural networks
(NNs) such as Yolo that is supporting only a well-formed but very limited
vocabulary, ie., objects that they are able to detect. When being
non-restricted, LLMs and in particular state-of-the-art vision language models
(VLMs) show impressive performance to describe even complex traffic situations.
This is making them potentially suitable components for automotive perception
systems to support the understanding of complex traffic situations or edge case
situation. However, LLMs and VLMs are prone to hallucination, which mean to
either potentially not seeing traffic agents such as vulnerable road users who
are present in a situation, or to seeing traffic agents who are not there in
reality. While the latter is unwanted making an ADAS or autonomous driving
systems (ADS) to unnecessarily slow down, the former could lead to disastrous
decisions from an ADS. In our work, we are systematically assessing the
performance of 3 state-of-the-art VLMs on a diverse subset of traffic
situations sampled from the Waymo Open Dataset to support safety guardrails for
capturing such hallucinations in VLM-supported perception systems. We observe
that both, proprietary and open VLMs exhibit remarkable image understanding
capabilities even paying thorough attention to fine details sometimes difficult
to spot for us humans. However, they are also still prone to making up elements
in their descriptions to date requiring hallucination detection strategies such
as BetterCheck that we propose in our work.
PDF Link: 2507.17722v1
7. ERMV: Editing 4D Robotic Multi-view images to enhance embodied agents
Authors: Chang Nie, Guangming Wang, Zhe Lie, Hesheng Wang
Deep-Dive Summary:
ERMV: 编辑 4D 机器人多视图图像以增强具身代理
作者: Mingming Wang, Zhe Liu, IEEE 会员, 和 Hesheng Wang, IEEE 资深会员
摘要— 机器人模仿学习依赖于 4D 多视图序列图像。然而,数据收集的高成本和高品质数据的稀缺性严重限制了具身智能策略(如 Vision-Language-Action (VLA) 模型)的泛化性和应用性。数据增强是一种强大的策略来克服数据稀缺问题,但目前缺乏针对操作任务编辑 4D 多视图序列图像的方法。因此,我们提出 ERMV(Editing Robotic Multi-View 4D 数据),一个新型的数据增强框架,它基于单帧编辑和机器人状态条件高效地编辑整个多视图序列。该任务面临三个核心挑战:(1) 在动态视图和长时序中维护几何和外观一致性;(2) 以低计算成本扩展工作窗口;(3) 确保关键对象(如机器人臂)的语义完整性。ERMV 通过一系列创新来解决这些挑战。首先,为了确保运动模糊下的时空一致性,我们引入一个新型的极线运动感知注意力(EMA-Attn)机制,该机制在应用几何约束之前学习由运动引起的像素偏移。其次,为了最大化编辑工作窗口,ERMV 率先提出一个稀疏时空(STT)模块,该模块解耦时空视图,并通过稀疏采样将问题重塑为单帧多视图问题,从而降低计算需求。第三,为了缓解错误积累,我们引入一个反馈干预机制,该机制使用多模态大语言模型(MLLM)检测不一致性,并在必要时请求针对性专家指导。大量实验表明,ERMV 增强的数据显著提高了 VLA 模型在模拟和真实世界环境中的鲁棒性和泛化性。此外,ERMV 可以将模拟图像转化为真实风格,从而有效桥接模拟到真实差距。代码将发布在 https://github.com/IRMVLab/ERMV。
索引术语: 具身智能,多视图编辑,机器人数据增强。
I. 引言
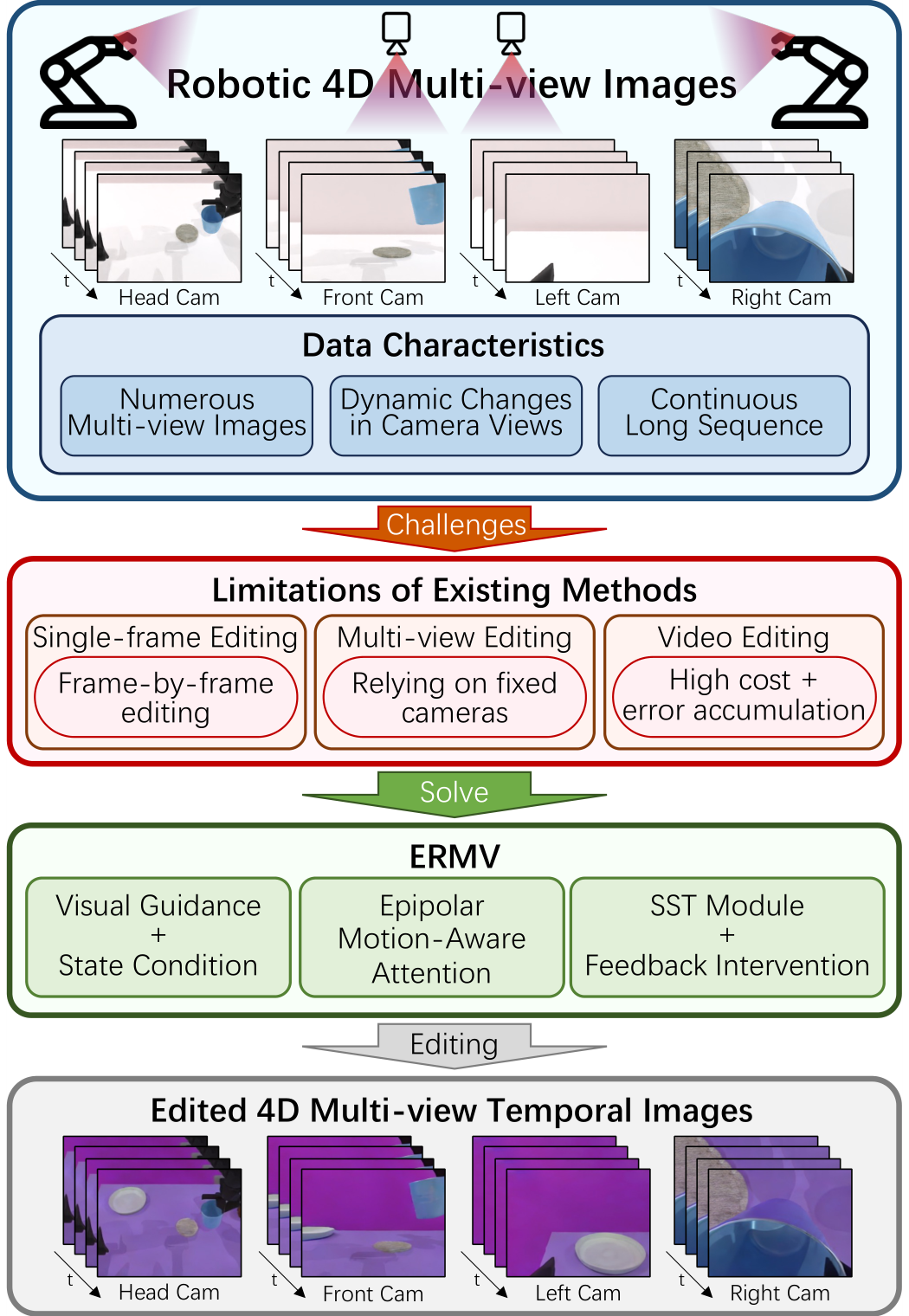
模仿学习,通过观察和模仿专家演示来获取技能,已经成为训练具身代理(如 VLA 模型)的基石。该范式的核心在于学习从多视图、时序图像(如 4D 序列)到动作轨迹的复杂映射。然而,收集高质量专家演示的高成本和时间密集性导致了显著的数据瓶颈。这种稀缺性严重限制了 VLA 在开放世界场景中的泛化性和鲁棒性。虽然数据增强是一种有前景的方法,但现有方法主要针对静态图像。这对于现代 VLA(如 RDT [3] 和 OpenVLA [4])来说是根本不足的,因为它们需要时序连续的 4D 数据进行训练。这一差异揭示了数据增强的一个未充分探索的领域:编辑 4D 机器人多视图序列图像。
编辑 4D 机器人多视图序列图像的难度源于三个基本技术障碍:维护时空一致性、在小工作窗口内操作,以及确保任务关键对象的质量。首先,最重要的是,在编辑 4D 数据时维护时空一致性。空间上,现有的方法专注于编辑固定多相机图像(如在自动驾驶车辆上),通过固定相邻视图关系维护空间一致性 [5]-[7]。然而,机器人操作涉及动态变化的多相机系统,使得这些固定相机方法无效。时间上,编辑必须在长时序中保持连贯性。当前的多图像编辑方法仅能实现顺序单视图视频编辑 [8]-[12]。多视图视频编辑尚未解决,因为难以确保时空一致性。此外,重构 3D 场景并编辑它们可以解决多个视点的一致性问题 [13],[14]。但难以准确编辑机器人与对象之间的交互。而且,一个经常被忽略的难点是运动模糊,由相机和对象的同时运动引起。这种动态效应打破了标准几何约束(如极线)的假设,使得建立准确特征对应变得困难。因此,缺乏有效运动建模的现有方法难以恢复运动模糊并维护真实性。
另一个重大挑战是受计算成本和效率限制的小工作窗口。 state-of-the-art 生成视频模型依赖于密集时空注意力来建立时间相关性。这意味着,使用大工作窗口提取长时序特征需要大量 GPU 内存 [15]-[17]。这种硬件条件限制了它们的可用性和实际应用。相反,大多数机器人操作场景涉及相对静态的背景,帧间差异不多,因此不需要如此密集的注意力机制。因此,实现一个方便、低成本的序列编辑框架而不牺牲 4D 一致性是提高生成或编辑模型在该领域的可用性的关键。此外,一个单一的操作序列可能包含数千张图像,使得传统的逐视图编辑不可行。因此,一个高效且准确的编辑指导方法至关重要。
最后一个挑战在于错误的累积效应。随着编辑图像被自回归地输入网络作为历史帧,积累的错误会逐渐导致图像质量下降。这种问题在机器人多视图图像编辑任务中特别严重,因为它要求在整个 4D 序列中严格保持机器人臂和被操作对象的一致性。这已成为现有方法在长时序数据生成和编辑中的常见障碍 [18]-[20]。因此,建立一个有效的评估和错误修正策略对于确保编辑长序列的质量至关重要。
如图 1 所示,为了解决这些挑战,我们提出 ERMV(Editing Robotic Multi-View 4D 数据),一个用于增强具身代理的新型编辑框架。ERMV 引入了一系列解决方案来解决 4D 数据编辑的核心挑战。首先,为了避免文本提示的模糊性,我们采用一个精确的视觉指导策略,使用一个用户编辑的单帧作为视觉指导,并结合机器人状态作为物理条件(Sec. II-B)。其次,为了在保持小计算成本的同时扩展工作窗口,我们率先提出一个稀疏时空(SST)模块。通过在时空解耦的大工作窗口中稀疏采样视图,ERMV 将视频编辑任务重塑为低成本的单帧多视图编辑问题,从而能够在单个消费级 GPU 上训练。
第三,为了建立准确的几何约束并保留动态环境中的运动模糊,我们设计了一个新型的极线运动感知注意力(EMA-Attn)机制。该机制通过学习预测运动引起的像素偏移,然后应用极线几何来指导特征聚合,从而确保运动期间的鲁棒对应。
最后,为了防止自回归错误积累导致的核心对象(如机器人臂或被操作对象)的逐渐退化,我们引入一个实用的反馈干预机制。该策略使用多模态大语言模型(MLLM)自动检查编辑前后核心对象的一致性,并在必要时仅涉及专家提供核心对象的分割掩码。
我们在公共 RoboTwin 模拟基准上验证了 ERMV,在未知环境中,ERMV 增强的数据显著提高了 VLA 模型的成功率和泛化性。此外,在真实世界 RDT 数据集和我们的真实双臂机器人平台上的实验表明,ERMV 可以有效编辑和增强真实世界数据,从而改善下游策略的性能和鲁棒性。而且,ERMV 甚至可以将模拟数据编辑为匹配真实世界的外观,从而显著缩小模拟到真实差距并减少对高保真物理模拟的依赖。
ERMV 的主要贡献如下:
- 我们提出 ERMV,一个用于编辑 4D 机器人多视图序列图像的新型框架。它能有效缓解 VLA 训练中的数据稀缺问题,并增强 VLA 模型的鲁棒性。
- ERMV 通过极线运动感知注意力机制和稀疏时空模块确保时空一致性。此外,ERMV 引入了一个实用的反馈干预机制,利用 MLLM 以最小专家努力来保护核心对象的一致性。
- 我们进行了广泛实验,包括模拟环境、真实世界和真实机器人平台。此外,我们验证了其对下游 VLA 策略的数据增强效果。而且,ERMV 不仅可以作为世界模型,还可以桥接模拟到真实差距。
II. 相关工作
A. 机器人图像生成和编辑
高保真生成和编辑模型的出现,特别是扩散模型,在机器人领域开辟了新前沿。当前的研究主要在两个方面使用这些模型:机器人高层任务规划和机器人训练数据增强。
用于任务规划的生成。 许多研究使用生成模型产生面向目标的图像来规划机器人动作。早期工作探索使用预训练的文本到图像模型进行零样本重排对象的最终位置。例如,DALL-E-Bot [21] 首先推断场景中对象的文本描述。然后,根据期望目标生成对象最终状态的图像。最后,要求机器人根据生成的图像放置对象。这种过程实现了操作对象的规划。SuSIE [22] 将长时序任务分解为更易管理的关键帧。它采用分层方法,其中一个微调的图像编辑扩散模型充当高层规划器,提出一个未来子目标图像。然后,一个低层、条件目标策略负责达到该特定子目标。最近,生成模型已发展为创建全面的世界模型,作为机器人操作的交互模拟器。总之,这些方法虽然对规划和生成图像有用,但其主要焦点是生成期望结果,而不是编辑现有 4D 图像用于数据增强。
用于数据增强的编辑。 当前的机器人模仿学习需要大量成本和人力来收集高质量数据,这限制了模型如 VLA 的鲁棒性和泛化性。一个有前景的方向是数据增强,旨在扩展现有的高质量机器人数据集。早期方法使用文本到图像生成模型添加语义多样性。方法如 CACTI [1]、ROSIE [2] 和 GenAug [23] 表明,将修复技术应用于单视图图像可以有效修改场景并多样化训练数据。例如,CACTI [1] 利用专家收集的数据,并使用生成模型添加场景和布局变化。ROSIE [2] 通过使用文本到图像扩散模型进行积极数据增强,创建未见对象、背景和干扰项。GenAug [23] 引入一个框架,通过生成对象和背景的语义意义视觉多样性,同时旨在维护动作的功能不变性来重定向行为。为了实现更精细的控制和更物理合理的結果,后续工作 [24] 纳入了显式 3D 信息,如对象网格和深度指导。方法如 RoboAgent [25] 寻求进一步自动化和扩展该过程。RoboAgent 整合了如 Segment Anything Model (SAM) [26] 的分割模型与修复,以自动识别和编辑帧中的对象。然而,这些方法的基本限制是逐帧编辑。这种方法不仅对视频数据无效,而且更关键地,未能强制执行编辑 4D 机器人操作轨迹所需的时间和多视图一致性。最近的工作 EVAC [27],一个生成模型而非编辑模型,尝试基于机器人动作生成时间连贯的视频。但它通过合并多视图输入并依赖计算密集的视频模型隐式学习一致性,而不是显式建模 3D 几何。这突出编辑机器人 4D 数据面临的挑战,需要不仅仅是可伸缩性和丰富的语义,还需要保证时空一致性。
B. 多视图图像生成和编辑
除了机器人领域,多视图一致性生成技术已在自动驾驶和 3D 对象合成等领域得到探索。
结构化环境中的一致性。 在自动驾驶中,生成真实且可控的数据对于鲁棒模拟和模型训练至关重要。几 种方法利用固定环绕相机支架的强先验,从统一的 Bird’s-Eye-View (BEV) 表示合成街景。这种 BEV 空间作为编辑的共同基础,允许开发人员构建特定场景。BEVGen [7] 引入一个条件生成模型,从语义 BEV 布局合成周围视图图像。它利用自回归变压器架构,并纳入一个新颖的成对相机偏差,学习不同相机视图之间的空间关系以确保一致性。BEVControl [6] 被提出以实现更准确和更细粒度的对单个街景元素的控制。BEVControl 支持更灵活的 BEV 草图布局,而不是详细的语义地图,便于用户编辑。它采用一个两阶段的基于扩散的方法,包括一个“Controller”用于几何一致性和一个“Coordinator”带有跨视图-跨元素注意力来协调不同视点。更近来,MagicDrive [5] 实现了 state-of-the-art,通过启用多样且直接的 3D 几何控制。它解决了 BEV-only 条件化的限制,可能导致几何模糊,如不正确对象高度或道路高程。MagicDrive 使用扩散模型分别编码各种输入,包括 BEV 路线图、显式 3D 边界框、相机位姿和文本描述。其多视图一致性通过带有硬编码相邻视图的跨视图注意力实现。这些现有的多视图编辑方法严重依赖于多个相机的固定相对位置。然而,这些方法无法解决机器人操作期间动态变化多视图图像的编辑问题。
3D 资产生成和编辑。 在 3D 资产相关领域,许多方法通过几何约束或 3D 表示强制执行多视图一致性。基础工作如 Zero-1-to-3 [28] 证明,预训练的 2D 扩散模型可以微调以理解相对相机变换。然后,该模型可以使用学到的几何先验从单个图像零样本合成新视图。在此基础上,前馈框架如 InstantMesh [29] 通过首先使用多视图扩散模型生成一组稀疏一致图像,然后输入到一个 Large Reconstruction Model (LRM) 来直接在几秒内产生高质量 3D 网格,从而实现显著效率。为了进一步增强几何连贯性,3D-Adapter [30] 引入一个插件模块,通过“3D 反馈增强”循环将显式 3D 意识注入去噪过程,其中中间多视图特征被解码为 3D 表示,如 3D Gaussian Splatting (3DGS)。而且,在 3D 编辑领域,DGE [31] 跳过缓慢的迭代优化,通过在多视图一致性下编辑 2D 图像。其时空注意力和极线约束从场景几何中提取,允许直接且高效地更新 3DGS 模型。对于不受约束场景的复杂 3D 修复,IMFine [32] 提出一个几何指导的管道,使用测试时适应微调每个场景的多视图精炼网络,修正从修复参考视图到其他视图的扭曲伪像。然而,这些方法缺乏处理机器人操作任务中固有的运动模糊图像和复杂工具-对象交互的机制。
总之,现有的研究未能解决机器人领域的关键需求:一种用于动态操作任务的多视图时序图像一致且可控编辑的方法。我们的工作旨在填补这一空白,通过提出一个框架来实现 4D 机器人数据的轻松编辑。
III. 方法
A. 问题表述和框架概述
问题表述。 给定一个 4D 机器人操作轨迹 T=(Xt,at)t=1…TT = (X_t, a_t)_{t=1 \dots T}T=(Xt,at)t=1…T,其中 Xt={Itv}v=1…NX_t = \{I_t^v\}_{v=1 \dots N}Xt={Itv}v=1…N 表示时间步 ttt 的 NNN 个多视图图像集,at∈Aa_t \in Aat∈A 是对应的机器人动作。主要目标是对图像序列 X={Xt}t=1…TX = \{X_t\}_{t=1 \dots T}X={Xt}t=1…T 进行针对性编辑,以生成一个新的、视觉上不同但语义上一致的序列 X′X'X′。这个新序列与原始未修改的动作序列 {at}t=1…T\{a_t\}_{t=1 \dots T}{at}t=1…T 配对,形成增强的数据对 T′=(Xt′,at)t=1…TT' = (X'_t, a_t)_{t=1 \dots T}T′=(Xt′,at)t=1…T。这一过程作为一种强大的数据增强策略来缓解具身智能中的数据稀缺问题。
框架概述。 为了实现可控编辑,我们提出 ERMV(Editing for Robotic Multi-view 数据),一个基于潜在扩散模型 (LDMs) [33] 的框架。我们的方法核心是一个条件生成器 GθG_\thetaGθ,它基于原始图像 XXX、细粒度状态条件 CstateC_{\text{state}}Cstate 和记忆特征 ChistoryC_{\text{history}}Chistory 合成编辑后的多视图序列 X′X'X′。整体生成过程可以表述为学习一个条件概率分布:
D(X′∣X,Cgulde,CState,Chistory)\mathcal{D}\big({\cal X}^{\prime}\big\vert{\cal X}\,,\mathcal{C}_{g\,u l d e},\mathcal{C}_{S\,t a t e},\mathcal{C}_{h\,i\,s t\,o r\,y}\big) D(X′X,Cgulde,CState,Chistory)
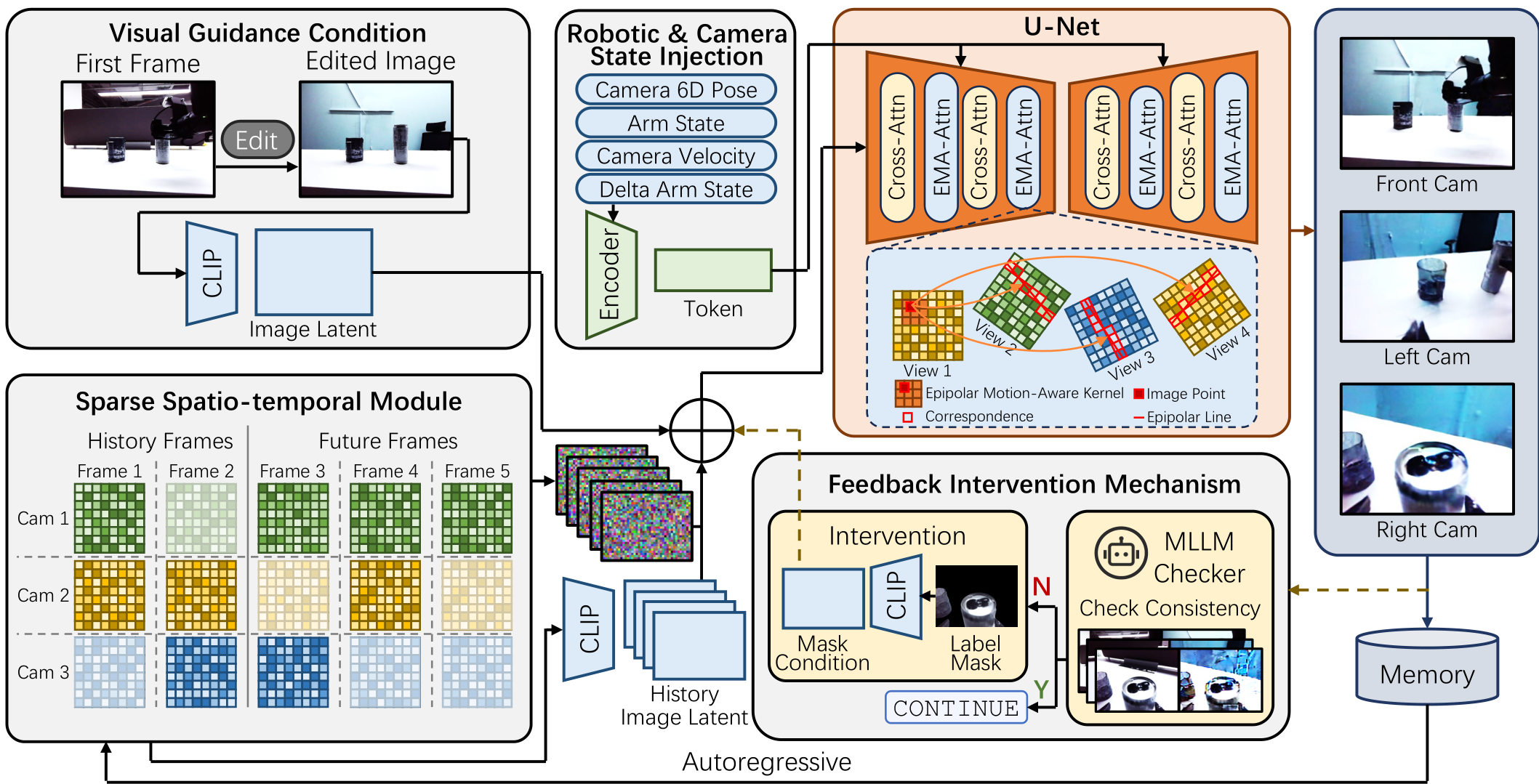
如图 2 所示,我们的框架系统地克服了该任务的核心困难。过程从建立精确的视觉指导开始(Section III-B)。为了克服文本提示的模糊性,我们使用一个编辑后的单图像作为期望修改的丰富视觉蓝图。为了在视图和时间步上保持一致编辑,我们通过显式注入相机位姿、机器人状态及其时间动态的时空注意力将模型 grounding 在场景的物理现实中(Section III-C)。此外,ERMV 通过稀疏时空 (SST) 模块在有限条件下最大化工作窗口(Section III-D),该策略通过将视频生成重构为单帧多图像问题,以低计算成本捕获长程记忆。在生成模型中,ERMV 引入极线运动感知注意力 (EMA-Attn) 来捕获运动特征(Section III-E),以真实渲染机器人操作中常见的运动模糊。最后,为了防止语义漂移和错误积累,一个反馈干预机制利用 MLLM 来保护关键场景元素如机器人臂和被操作对象的完整性(Section III-F)。然后,仅在必要时请求专家修正。在当前工作窗口中编辑的图像被存储在记忆中,以自回归方式编辑未来帧。
扩散过程在潜在空间中操作,以提高计算效率,使用预训练的自编码器(编码器 EEE 和解码器 DDD)在生成器 GθG_\thetaGθ 中。将高斯噪声 ϵ\epsilonϵ 添加到潜在表示 Z0=E(X)Z_0 = E(X)Z0=E(X) 以产生噪声潜在表示 ZtZ_tZt。模型 GθG_\thetaGθ 被训练从 ZtZ_tZt 预测添加的噪声,条件于时间步 ttt 和我们的全面条件集 C={Cguide,Cstate,Chistory}C = \{C_{\text{guide}}, C_{\text{state}}, C_{\text{history}}\}C={Cguide,Cstate,Chistory}。损失函数为:
LDM=EZ0(X),t,C,ϵ[∥ϵ−Gθ(Zt,t,C)∥2]\mathcal{L}_{\text{DM}} = \mathbb{E}_{Z_0(X), t, C, \epsilon} \left[ \left\| \epsilon - G_\theta(Z_t, t, C) \right\|^2 \right] LDM=EZ0(X),t,C,ϵ[∥ϵ−Gθ(Zt,t,C)∥2]
B. 视觉指导条件
编辑机器人图像的基本挑战是准确遵循期望。虽然文本提示在创造性图像编辑中是标准的 [34]-[36],但它们无法提供对物理 grounding 场景至关重要的细粒度几何和空间控制。例如,“将背景更改为办公室”这样的提示缺乏对颜色、类型或方向的特定性。结果甚至可能与机器人动作冲突。编辑图像与动作之间的一致性对于训练鲁棒机器人策略至关重要。
提前准确编辑全局图像以实现期望效果可以有效防止对期望编辑的误解。因此,ERMV 采用视觉指导策略。我们首先选择一个全局信息丰富的帧,通常是主相机中的第一帧 x11x_1^1x11,它捕获整体场景上下文。然后,使用高级修复模型 [35]-[37] 或手动编辑仔细编辑该帧,以创建目标指导图像 xguidex_{\text{guide}}xguide。该图像作为期望修改的显式、无歧义的视觉蓝图。然后,指导条件 CguideC_{\text{guide}}Cguide 通过编码器如 CLIP [38] 编码:
Cguide=ΠCLIP(xguide)\mathcal{C}_{g u i d e} = \Pi_{\text{CLIP}}(x_{\text{guide}}) Cguide=ΠCLIP(xguide)
这个丰富的嵌入提供了一个精确、空间感知的语义目标,使扩散模型能够在所有视图和时间步上一致传播编辑。
C. 机器人和相机状态注入
生成连贯的 4D 序列需要不仅仅是视觉目标。模型必须理解机器人和相机在每个时刻的精确几何和动态状态。缺乏此信息会阻止正确定位机器人臂在每个视图中并阻碍运动模糊的真实渲染。为了从机器人相机视点和时间步准确渲染场景,我们将显式状态信息作为条件 CstateC_{\text{state}}Cstate 的一部分,其中包括两个组件:
位姿和状态条件。 对于每个目标图像,位姿 qt∈SE(3)q_t \in \text{SE}(3)qt∈SE(3) 和机器人动作 qt∈Rdq_t \in \mathbb{R}^dqt∈Rd(例如,关节位置,其中 ddd 是自由度)。这允许模型在正确的几何上下文中 grounding 生成。
运动动态条件。 机器人操作图像的常见且具有挑战性的特征是运动模糊,由相机和对象的同步运动引起。未能建模此现象将导致不自然的锐利和不现实的视频。为了显式捕获这些动态,我们计算位姿和动作的时间差 Δqt=qt−qt−1\Delta q_t = q_t - q_{t-1}Δqt=qt−qt−1。
这些静态和动态特征被连接以形成每个图像的全面状态向量 Ct,vC_{t,v}Ct,v,使用带有位置编码的 Multi-Layer Perceptron (MLP) 编码为序列嵌入标记,然后输入 U-Net 主干的交叉注意力层:
Cstate(t,v)=Ψ(MLP(Ct,v))\mathcal{C}_{s t a t e}^{(t,v)} = \Psi(\text{MLP}(C_{t,v})) Cstate(t,v)=Ψ(MLP(Ct,v))
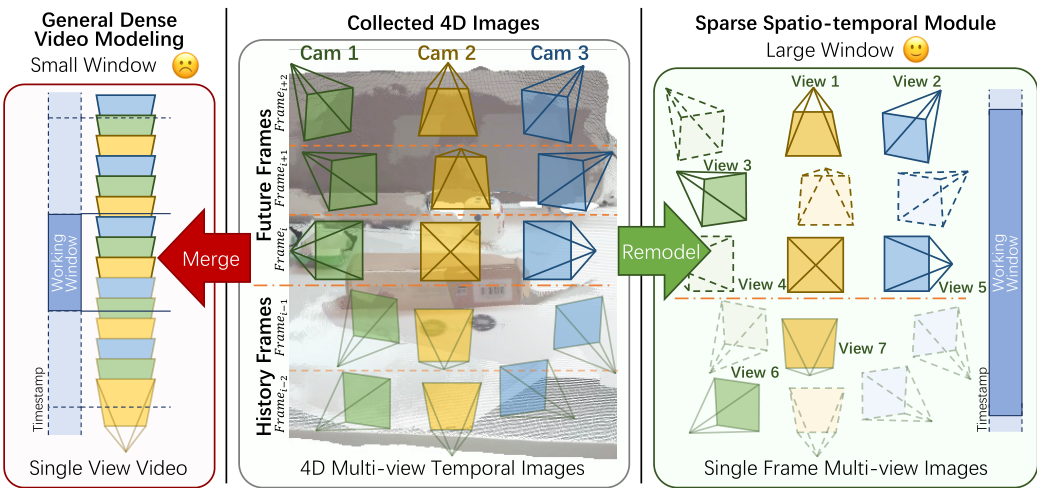
D. 稀疏时空模块
先前的方法通常使用视频扩散模型 [39] 来处理多视图时序图像 [27], [40]。这种模型通过密集帧间交叉注意力隐式提取几何信息,导致计算成本过高,尤其是对于大工作窗口。然而,在许多操作场景中,背景 largely 静态且图像变化缓慢。受此启发,我们提出稀疏时空 (SST) 模块,以在有限 GPU 内存内最大化工作窗口。
如图 3 所示,给定一个滑动窗口的 LLL 个连续时间步,而不是处理所有 L×NL \times NL×N 张图像,我们随机采样固定大小的子集 KKK 张图像,其中 K≪L×NK \ll L \times NK≪L×N。让采样集为 Xsample={Ik}k=1…KX_{\text{sample}} = \{I_k\}_{k=1 \dots K}Xsample={Ik}k=1…K,其中包括历史视图 ChistoryC_{\text{history}}Chistory 和未来视图。每个采样图像 IkI_kIk 对应于原始图像 ItkvkI_{t_k}^{v_k}Itkvk 来自时间步 tkt_ktk 和视图 vkv_kvk。为了保留采样期间丢失的原始时空结构,我们显式编码原始索引 (tk,vk)(t_k, v_k)(tk,vk) 并将它们作为每个相应图像的条件注入。值得注意的是,ERMV 不仅将历史帧作为条件注入网络,还与未来帧一起生成。这种同时生成方法允许未来帧更好地从历史帧提取几何结构信息,从而改善时间一致性。通过建模联合概率分布:
P(Xsample∣E(Xk)k=1…K)\mathcal{P}(X_{\text{sample}} \mid E(X_k)_{k=1 \dots K}) P(Xsample∣E(Xk)k=1…K)
模型学习整个稀疏帧集的特征。因此,SST 模块允许模型以固定计算预算推理更广泛的时间上下文,有效地将视频生成问题重构为低成本的单帧多视图生成任务。
E. 极线运动感知注意力
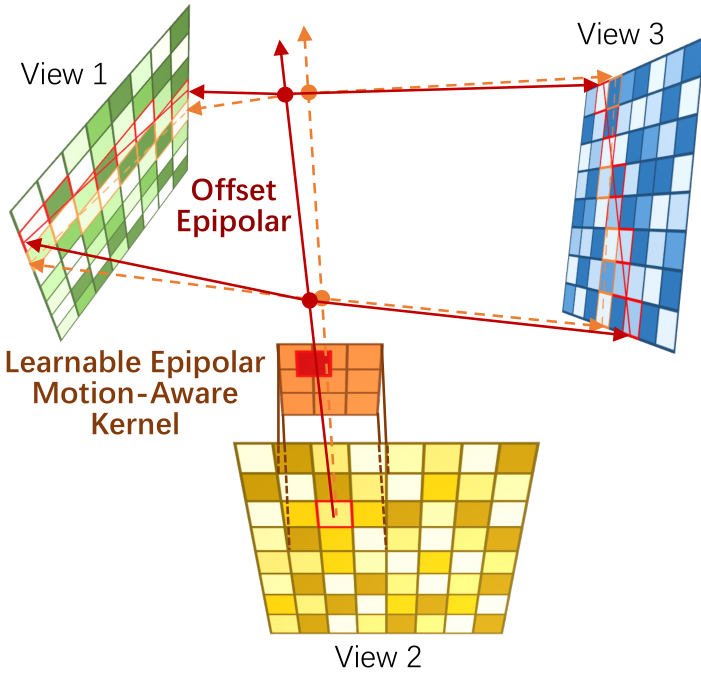
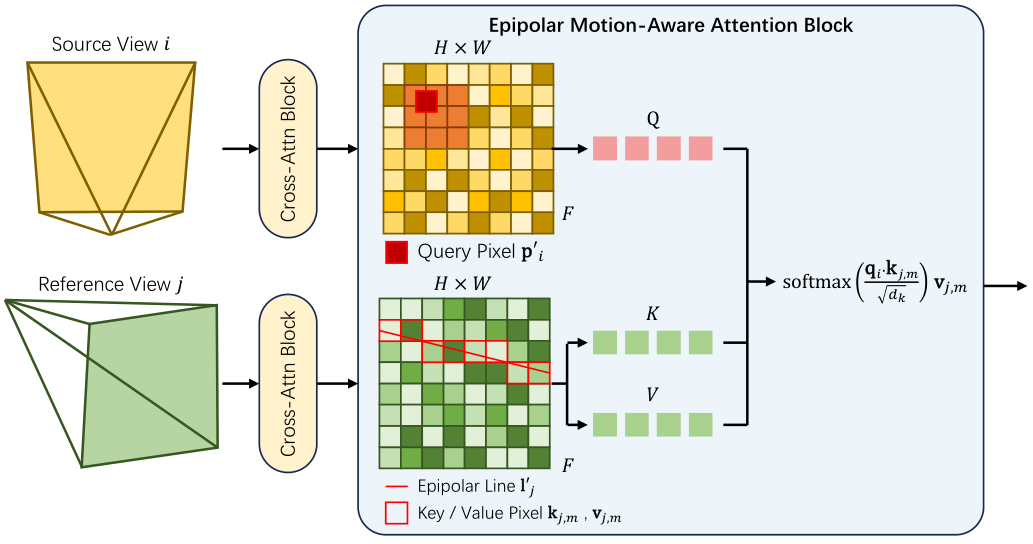
虽然稀疏采样是低成本的,但它提出了一个新挑战:如何在稀疏选择的帧之间有效传播信息并强制几何一致性。极线指导注意力 [41] 提供了一个强大的几何基础。然而,标准实现未能考虑机器人领域的运动模糊,因为在模糊图像中沿精确极线采样的特征可能不对应于真实像素位置。
为了解决这个挑战,我们引入一个新型的极线运动感知 (EMA) 注意力。如图 4 所示,对于视图 vvv 中的查询像素 ppp,ERMV 没有假设其对应位于另一个视图 v′v'v′ 中的极线 l=Fpl = F pl=Fp 上。相反,ERMV 首先使用一个小网络 ϕ\phiϕ 预测一个运动引起的偏移 Δp\Delta pΔp:
Δp=ϕ(p,Cstatet,v)\Delta p = \phi(p, C_{\text{state}}^{t,v}) Δp=ϕ(p,Cstatet,v)
然后,在对应的新的点 p′=p+Δpp' = p + \Delta pp′=p+Δp 的极线上执行特征聚合。如图 5 所示,注意力机制从点 pm′,m=1…Mp'_m, m=1 \dots Mpm′,m=1…M 沿修改后的极线 l′=Fp′l' = F p'l′=Fp′ 聚合特征:
AttentionEMA(qi,Kj,Vj)=∑m=1Msoftmax(qi⋅kj,mdk)vj,m\text{Attention}_{\text{EMA}}(q_i, K_j, V_j) = \sum_{m=1}^{M} \text{softmax}\left( \frac{q_i \cdot k_{j,m}}{\sqrt{d_k}} \right) v_{j,m} AttentionEMA(qi,Kj,Vj)=m=1∑Msoftmax(dkqi⋅kj,m)vj,m
其中 qiq_iqi 是 p′p'p′ 处的查询特征,kj,m,Vj,mk_{j,m}, V_{j,m}kj,m,Vj,m 是视图 v′v'v′ 中运动感知极线上的采样点的关键/值对。这允许模型学习运动特定的对应,提高几何一致性和真实性。
F.Feedback Intervention Mechanism
自回归图像生成容易出现错误积累 [42]-[44],这会导致图像质量下降,并使图像偏离预期。此外,在训练视觉语言动作 (VLA) 模型时,被操纵物体的图像质量和机器人臂的图像质量尤为重要。这些关键区域的质量下降不仅会导致视觉不准确,还会使策略学习数据无效。因此,保持这些区域的质量至关重要。
一个简单的解决方案是,在每个帧中分割核心物体(如机器人臂和被操纵物体),以强制保留它们。这种方法可以有两种实现方式:一方面,训练一个通用的分割模型来处理被操纵物体。然而,被操纵物体多样且经常是新颖的。此外,许多机器人摄像头的视角具有挑战性且以自我为中心。这些障碍使得这种训练在技术上不可行。另一方面,手动标注核心物体可以取得很好的结果。但需要标注数千张图像,这将耗费大量人力。
左侧图像是原始图像,右侧图像是背景已编辑的图像。编辑后的图像中的与原始图像匹配吗?如果将物体的退化程度从0-10进行评分,请评估退化程度。
步骤1:仅观察两张图像中的;其他背景无需关注。
步骤2:如果右侧图像中未找到,则图像严重退化,直接评分10。
步骤3:比较两张图像中的相似性,然后评分图像的退化程度。
步骤4:如果分数大于5,则表示严重退化,输出 {“is consistent”:False} 的 JSON 格式;否则,表示退化不严重,输出 {“is consistent”:True}。

为了解决这一困境,我们提出了一个反馈干预机制。对于第 k 步生成的图像 ( v_t^{(k)} ),我们使用多模态大型语言模型 (MLLM) Φ 作为自动检查器。它通过基于 Chain-of-Thought (CoT) 的任务描述提示 ( P_{\text{coT}} ) 将生成的图像与原始图像 ( c_t ) 进行比较,以检查关键物体的一致性:
KaTeX parse error: Undefined control sequence: \y at position 28: …{i}\mathrm{S}_{\̲y̲\atop}}\mathrm{…
示例提示 ( P_{\text{coT}} ) 如 TABLE I 所示。如果 ( \text{is_consistent} ) 为 false,则系统标记该图像,并建议专家为核心物体提供分割掩码 ( M_t ),以用于纠正再生的额外条件 ( C_{\text{mask}} )。这种反馈循环的优势在于,它能以手术般的精确性有效防止语义漂移,同时将专家标注负担最小化,仅限于模型失败的少数情况。这种反馈确保了增强数据的完整性,而不会创建难以管理的流程。
IV. EXPERIMENTS
本节全面评估 ERMV 在机器人操纵的多视图时序图像编辑任务中的性能。我们首先介绍实验设置。随后,通过模拟环境中的一系列实验,我们定量评估 ERMV 作为数据增强技术的有效性,以及其提升下游具身代理策略性能的能力。然后,我们在公共真实世界数据集上验证 ERMV 的编辑质量。此外,我们在物理机器人平台上部署并测试 ERMV,以检查其在物理世界的实际适用性。最后,通过详细的消融研究,我们分析模型关键组件的贡献。

A. Implementation Details
ERMV 使用 Stable Diffusion 2.1 [33] 的 U-Net 骨干网络。模型以批量大小 4 进行训练。我们使用 AdamW 优化器,学习率为恒定的 1e-5。所有模型均在 PyTorch 中实现,并在单个 NVIDIA RTX 4090 GPU 上训练和评估。为了平衡生成质量和计算效率,我们采用 SST 采样策略:历史上下文窗口从过去 8 帧的 4 个视图中随机采样图像,而未来动作窗口从未来 8 帧的 6 个视图中采样图像。在反馈干预机制中,我们使用 Qwen2.5-VL [45] 作为多模态大型语言模型 (MLLM) 来评估和指导生成过程。
B. Simulation Experiments
我们在双臂模拟平台 RoboTwin [47] 上进行实验,该平台提供了一系列标准化的机器人操纵任务。对于所有任务,我们收集 4D 轨迹数据 ( T = (X_t, a_t) ),其中 ( t = 1 \ldots T ),包括多视图图像、机器人和摄像头状态,用于模型训练。我们要求 ERMV 编辑这些收集的数据以增强训练数据。此外,SOTA 单图像编辑方法 Step1X-Edit [46] 也被用作比较。
我们首先比较模拟环境中不同方法的编辑效果定量结果,如 TABLE II 所示。与其他图像编辑方法 [49] 使用的指标类似,我们使用 SSIM (结构相似性指数)、PSNR (峰值信噪比)和 LPIPS (学习感知图像补丁相似性) 作为评估指标。结果显示,ERMV 的编辑结果大大领先于单帧编辑方法 Step1X-Edit。这归功于 ERMV 通过 EMA-Attn 保持的出色时空一致性。此外,定性比较结果如 Fig. 7 所示,ERMV 实现了高保真度的编辑效果。特别是,桌子上的阴影和瓶子表面的光折射被准确编辑。这归因于视觉引导条件能准确表示所需的细节效果。

整个编辑后的 4D 序列准确响应了输入。相比之下,即使是 SOTA 单图像编辑方法 Step1X-Edit,通过文本提示引导,也难以准确表达所需的编辑效果,甚至完全破坏了原始图像的语义。此外,ERM 编辑后同一帧的多视图之间的一致性被准确维护。这是因为 ERMV 提出的极点运动感知注意力模块利用多视图几何约束,确保了不同视角的静态背景高度一致。同时,SST 模块结合运动注入有效保持了被操纵物体和机器人臂的运动与历史帧一致,确保了平滑的时空一致性。相反,Step1X-Edit 由于没有维护时间一致性的机制,即使使用相同的文本提示,也会编辑出完全不同的内容。
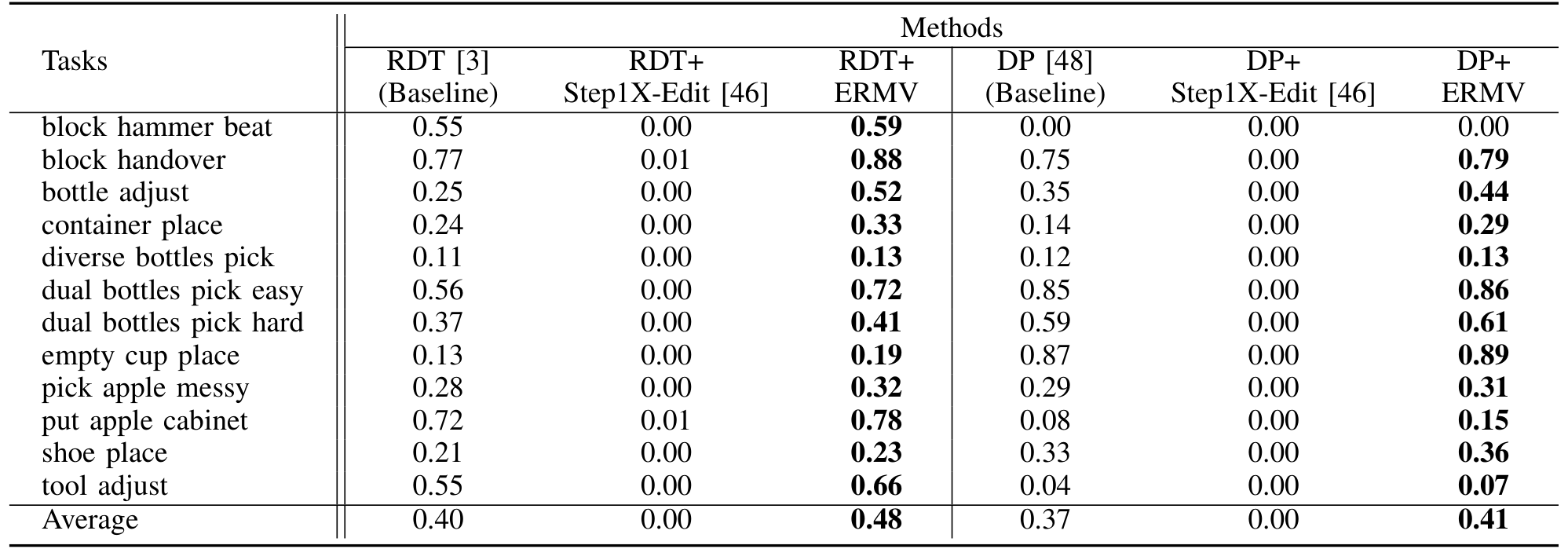
为了量化 ERMV 生成数据的作用,我们将其作为数据增强方法训练下游具身代理策略。我们选择 RDT [3] 和 Diffusion Policy (DP) [48] 作为策略模型。有三种训练配置:“Baseline”,仅在原始收集的模拟数据上训练策略模型;“+Step1X-Edit”,用 Step1X-Edit 编辑的数据替换 80% 的原始数据;“+ERMV”,用 ERMV 增强的数据替换 80% 的原始数据。然后,我们在 RoboTwin 的标准测试任务中评估不同配置下策略模型的平均成功率 (SR)。
如 TABLE II 所示,使用 ERMV 生成数据增强的模型 (“+ERMV”) 在 RDT (AVG: 0.40 vs. 0.48) 和 DP (AVG: 0.37 vs. 0.41) 上显示出显著的成功率提升。这是因为基线模型仅在单一简单场景上训练,而 ERMV 增强数据包含了各种复杂场景。这一结果证实了 ERMV 增强数据的有效性,源于 ERMV 强大的维护时空一致性的能力。特别是 SST 模块确保了整个时序范围内的操纵图像连续性,从而为策略模型提供高质量且物理一致的训练信号。然而,Step1X-Edit 编辑的数据导致 VLA 模型性能严重下降,因为它严重破坏了原始图像的语义。
为了全面评估增强策略模型的泛化能力,我们基于 RoboTwin 的原始测试任务创建更具挑战性的“杂乱场景”。为此,我们在环境中引入随机 distracting 对象,并随机化桌子的纹理和背景,同时保持核心被操纵物体不变。
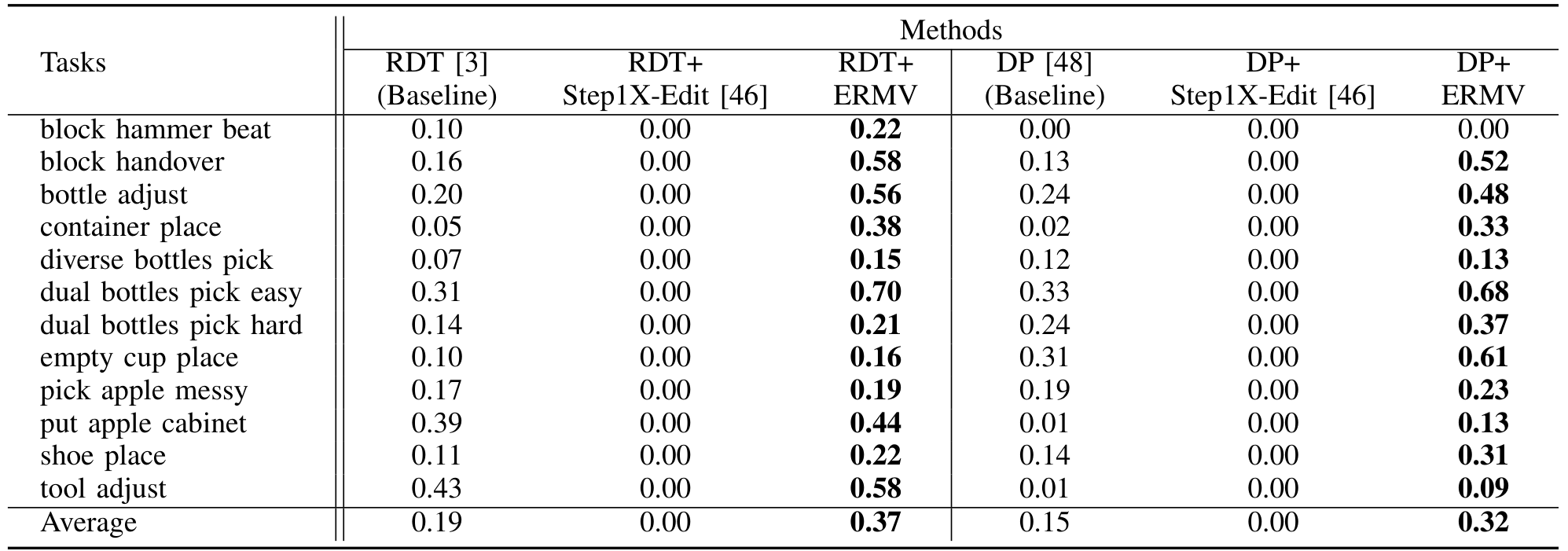
值得注意的是,在新颖的“未见杂乱场景”的零样本泛化测试中,基线模型的性能急剧下降。这是因为基线模型在非常单一的场景上训练。相比之下,使用 ERMV 增强数据训练的模型表现出优越的鲁棒性和泛化能力,在 RDT (AVG: 0.19 vs. 0.37) 和 DP (AVG: 0.15 vs. 0.32) 上成功率远超基线模型。这一结果有力证明了 ERMV 作为强大数据增强引擎的能力,它可以通过创建多样、高质量的域外训练数据显著提升下游策略的泛化能力。通过对场景元素的控制编辑,ERM 可以轻松增强现有高质量数据。这种增强的鲁棒性直接缓解了收集大规模多样数据的挑战。
C. Real-World Experiments
- Real-World Dataset Experiments: 为了评估 ERMV 在真实场景中的编辑能力和长时序稳定性,我们在公共双臂操纵数据集 RDT-ft-data [3] 上进行实验。
如 Fig. 8 所示,ERM 可以成功编辑真实世界的机器人操纵序列,例如替换相同的 grasping 动作的背景和桌子环境。值得注意的是,模型在编辑过程中准确保留了核心被操纵物体的形态和运动,如 grasped box,以及机器人臂。这主要归功于我们的 EMA-Attn 机制,它通过建模多视图几何关系有效区分动态前景和静态背景,从而实现对被操纵物体的精确保留。此外,编辑后的图像甚至能准确再现由摄像头移动或快速机器人臂运动引起的运动模糊效果。这证明了运动信息的多层注入成功捕获并渲染了这些微妙动态特征。虽然 Step1X-Edit 能够基于文本提示编辑原始图像到相应的样式,但它不仅破坏了单帧的语义,而且时间变化也不一致。
- Real Robot Experiments: 我们进一步在由两个 Franka Emika Panda 机器人臂组成的定制双臂机器人平台上进行物理实验,如 Fig. 10 (a) 所示。我们首先为几个 pick-and-place 任务收集操纵数据,并在这些数据上训练 Action Chunking with Transformers (ACT) [50] 策略模型作为基线。随后,如 Fig. 9 所示,我们使用 ERMV 编辑这些数据以增强训练集,并重新训练 ACT 模型。
如 Fig. 10 (b) 所示,我们首先在简单原始场景中进行测试。ACT 和增强后的 ACT+ERM 都成功完成了任务。然而,在杂乱的未见场景 (Fig. 10 ©) 中,基线 ACT 由于过度干扰而无法正确 grasping 对象。由于 ERMV 通过编辑先前收集的数据进行增强,训练后的 ACT+ERM 显著提升了鲁棒性。ACT+ERM 能够在未见杂乱场景中成功完成任务。

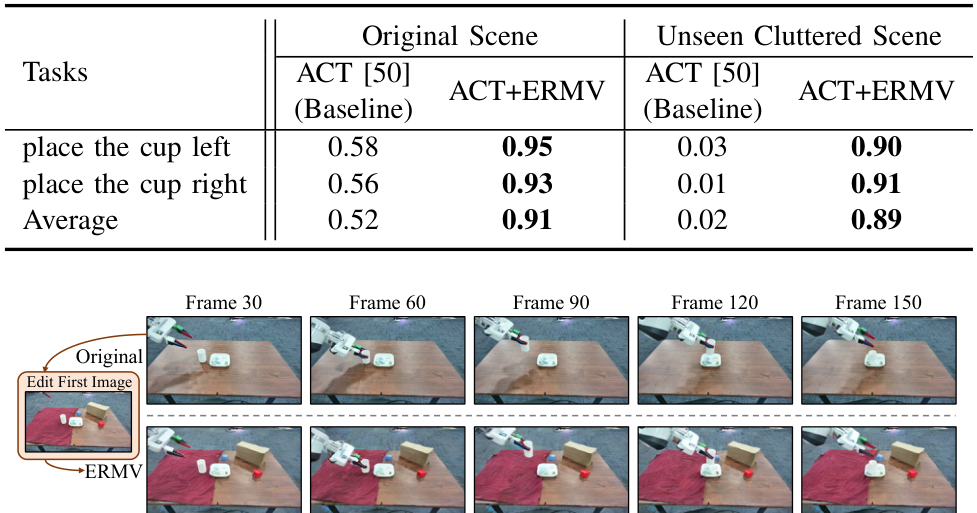
定量实验结果如 TABLE V 所示,在原始场景中,增强训练后的 ACT+ERM 的平均成功率从 0.52 增加到 0.91。这表明 ERMV 增强数据能提升下游 VLA 模型的稳定性。在未见杂乱场景中,ERM 的效果更加明显。ACT+ERM 的平均成功率保持在 0.89,而基线 ACT 的成功率仅为 0.02。这证明了 ACT+ERM 的鲁棒性得到了极大提升。这归功于 ERMV 准确编辑了收集的数据。这种高质量且多样的增强数据使下游策略模型能够学习到对真实世界视觉变化更鲁棒的特征,从而有效提升其在物理世界中的性能。这一实验结果也证实了 IV-B 节中模拟环境中的结论。
D. Generation Capabilities
ERMV 的一个新兴应用是作为世界模型,用于低成本、高效率的具身代理验证,而无需物理交互。此外,将模拟图像编辑成真实场景也是一个新颖应用,可弥补模拟到真实差距。我们通过两个实验验证这一点。
World Model for Policy Validation. 当以单个初始原始帧和 VLA 模型的动作序列为条件时,ERM 可以作为世界模型预测性地生成相应的多视图时空图像序列。如 Fig. 11 所示,生成的交互序列与 Ground Truth (GT) 图像高度一致。这种准确预测主要归功于我们的机器人和摄像头状态注入机制,它确保生成过程严格遵守输入动作命令。这证明了 ERMV 可以作为一个可靠且确定性的世界模型,用于排练和验证机器人策略,从而显著加速策略迭代周期,避免在不成熟阶段进行风险物理试验,并消除构建高保真模拟环境的需求。
Bridging the Sim-to-Real gap. 我们进行实验探索 ERMV 在弥合模拟到真实差距方面的潜力。ERM 首先用真实世界视觉样式编辑模拟轨迹的初始帧。然后,使用此作为视觉条件以及模拟中的原始机器人动作序列,ERM 编辑一个完整的“伪真实”4D 多视图轨迹,该轨迹在外观上真实且在运动上物理一致。如 Fig. 12 所示,生成的数据成功融合了真实场景的纹理和照明与连贯的物理动作。我们使用这些“伪真实”数据训练 ACT 策略模型,并将其部署到真实机器人。Fig. 12 显示,该 ACT 能够在真实场景中直接完成任务,这有力证明了 ERMV 在缓解真实数据稀缺性和弥合模拟与真实差距方面的潜力。



E. Ablation Study
为了验证 ERMV 中每个关键组件的有效性,我们进行了全面的消融研究。
Effect of Motion Conditioning. 我们移除了 Motion Dynamics Conditioning 和 EMA-Attn 模块。如 Fig. 13 所示,模型失去了准确捕获运动信息的能力,从而无法生成具有现实运动模糊效果的图像。虽然生成的图像在视觉上类似,但它们无法模拟真实相机捕获的动态。这证明了多层运动信息注入能够有效模拟摄像头和机器人臂的动态。
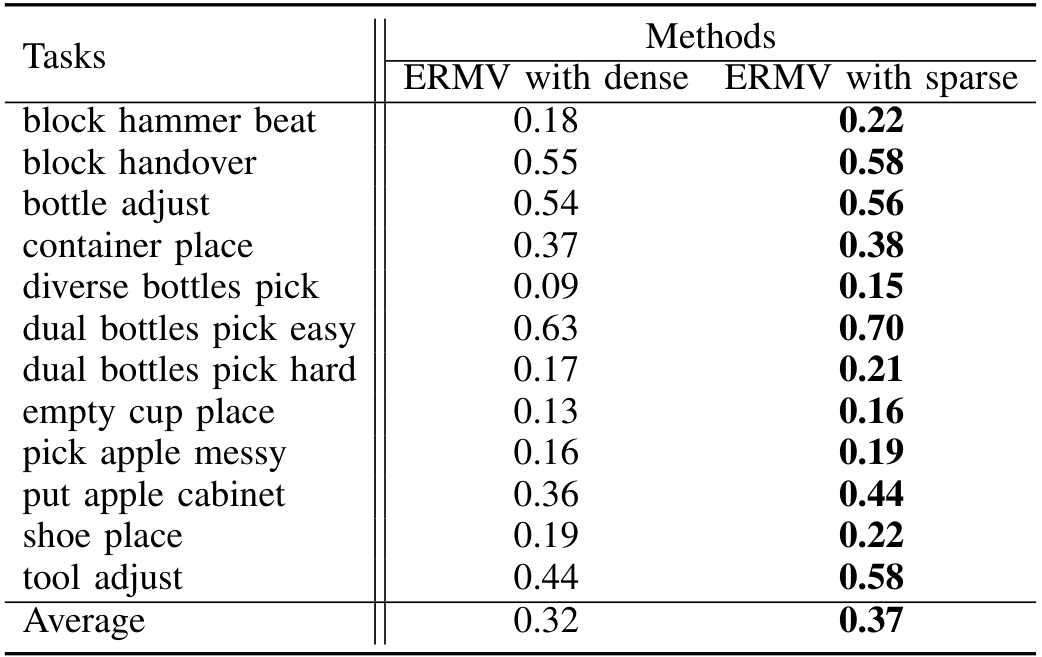
Efficiency of Sparse Spatio-Temporal Module. 我们将稀疏方法与密集方法进行比较。TABLE VI 显示,ERM 中的 SST 模块取得了更好的性能。因为稀疏方法在相同的 GPU 内存下可以设置更大的工作窗口。这样,稀疏方法允许更好地提取历史信息,并在长时序上维护一致性。
此外,当固定相同的工作窗口时,稀疏方法可以将 GPU 内存需求减少 50%。这使 ERMV 能够在内存较小的消费级 GPU 上训练,从而大大提高了算法的实用性和可扩展性。
Effect of Feedback Intervention Mechanism. 在处理长时序 4D 数据时,传统的自回归模型往往由于错误积累导致语义漂移和细节模糊。如 Fig. 14 所示,我们禁用了反馈干预策略来评估其效果。没有该策略的模型会逐渐质量下降,表现出严重的 artifacts 和语义漂移。由于错误积累。而使用反馈干预机制的模型在整个序列中保持高质量和一致性。这归功于反馈干预机制,它在推理过程中进行自我评估,及时检测并纠正潜在偏差,从而确保长序列的高质量和一致编辑。

V. DISCUSSION
在本论文中,我们引入了 ERMV 框架,其主要目标是打破机器人模仿学习中的数据瓶颈。我们的研究证实了一个关键论点:通过高效且一致地编辑现有高质量数据,可以显著提升视觉语言动作 (VLA) 模型的性能。除了架构创新外,ERM 实用地融入了反馈干预机制。这种“MLLM 审查 + 专家纠正”范式为构建可信赖 AI 系统提供了一个实用的中间路径。它不仅是一种确保数据质量的技术工具,还是使 AI 系统行为与高层任务目标(如维护机器人臂的物理真实性)一致的有效策略。
此外,ERM 的强大编辑能力为研究机器人策略的泛化性和鲁棒性开辟了一个新范式。通过改变任务场景的背景、照明甚至物体布局,我们可以低成本、大规模地将现有高质量数据编辑成真实世界中难以构建的测试环境。这使研究者能够在不投资大量资源构建复杂实验场景或高保真模拟环境的情况下,有系统地扩展机器人策略可用数据类型。ERM 甚至可以编辑难以从真实机器人中收集的数据,例如碰撞前 4D 机器人图像。同样,其作为世界模型生成从单个帧和动作的连续 4D 数据的能力,为机器人运动规划提供了一个安全、高效的离线评估解决方案,有效减少了对高风险物理硬件测试的需求。
尽管这些鼓舞人心的结果,我们也认识到 ERMV 的局限性。当前的 ERMV 框架未引入诸如深度图像、3D 高斯飞溅等富含 3D 结构信息的数据。这是因为这些数据的编辑比单帧图像更复杂。然而,很明显,添加这些数据可以显著提升 4D 数据编辑的有效性。我们将在未来探索如何引入更多 3D 信息来增强性能。此外,为了完全自动化数据编辑管道,我们将探索使用先进的语义分割或物体检测技术来替换当前部分手动标注和干预过程,从而进一步提高 ERMV 框架的效率和可扩展性。
最后,ERM 中应用的根本原则,如 SST 模块和运动感知注意力,为其他动态视频生成领域提供了启发。它们可能适用于更广泛的应用。
VI. CONCLUSION
在本论文中,我们通过引入 ERMV 缓解了机器人模仿学习中的关键数据瓶颈,这是一个用于增强 4D 多视图顺序数据的新颖框架。在详细的单帧图像编辑指导下,ERM 高效且准确地控制了整个序列的编辑目标。借助稀疏时空模块,ERM 能够在有限硬件下最大化工作窗口。此外,极点运动感知注意力通过几何指导确保了多视图一致性和运动模糊恢复。而且,反馈干预策略有效缓解了错误积累并提升了自回归编辑的质量。我们的大量实验证明,ERM 增强的数据可以显著提升 VLA 模型的性能和鲁棒性。此外,ERM 不仅可以用作策略评估工具,还能弥合模拟与真实差距。
Original Abstract: Robot imitation learning relies on 4D multi-view sequential images. However,
the high cost of data collection and the scarcity of high-quality data severely
constrain the generalization and application of embodied intelligence policies
like Vision-Language-Action (VLA) models. Data augmentation is a powerful
strategy to overcome data scarcity, but methods for editing 4D multi-view
sequential images for manipulation tasks are currently lacking. Thus, we
propose ERMV (Editing Robotic Multi-View 4D data), a novel data augmentation
framework that efficiently edits an entire multi-view sequence based on
single-frame editing and robot state conditions. This task presents three core
challenges: (1) maintaining geometric and appearance consistency across dynamic
views and long time horizons; (2) expanding the working window with low
computational costs; and (3) ensuring the semantic integrity of critical
objects like the robot arm. ERMV addresses these challenges through a series of
innovations. First, to ensure spatio-temporal consistency in motion blur, we
introduce a novel Epipolar Motion-Aware Attention (EMA-Attn) mechanism that
learns pixel shift caused by movement before applying geometric constraints.
Second, to maximize the editing working window, ERMV pioneers a Sparse
Spatio-Temporal (STT) module, which decouples the temporal and spatial views
and remodels a single-frame multi-view problem through sparse sampling of the
views to reduce computational demands. Third, to alleviate error accumulation,
we incorporate a feedback intervention Mechanism, which uses a Multimodal Large
Language Model (MLLM) to check editing inconsistencies and request targeted
expert guidance only when necessary. Extensive experiments demonstrate that
ERMV-augmented data significantly boosts the robustness and generalization of
VLA models in both simulated and real-world environments.
PDF Link: 2507.17462v1
9. Triple X: A LLM-Based Multilingual Speech Recognition System for the INTERSPEECH2025 MLC-SLM Challenge
Authors: Miaomiao Gao, Xiaoxiao Xiang, Yiwen Guo
Deep-Dive Summary:
Triple X: A LLM-Based Multilingual Speech Recognition System for the INTERSPEECH 2025 MLC-SLM Challenge
1 Aerospace Information Research Institute, Chinese Academy of Sciences
2 LIGHTSPEED
3 University of Chinese Academy of Sciences
4 Independent Researcher
xiangxiaoxiaol8@mails.ucas.ac.cn, gaomiaomiao20@mails.ucas.ac.cn
摘要
本文介绍了我们提交到多语言对话语音语言建模(MLC-SLM)挑战赛 Task 1 的 Triple X 语音识别系统。我们的工作重点是通过创新的编码器-适配器-LLM 架构优化多语言对话场景下的语音识别准确性。该框架利用了基于文本的大型语言模型(LLM)的强大推理能力,同时结合了特定领域的适应性。为进一步提升多语言识别性能,我们使用了广泛的多语言音频数据集。实验结果显示,我们的方法在开发集和测试集上实现了具有竞争力的词错误率(WER)表现,在挑战赛排名中获得第二名。
索引术语:语音识别、多语言对话环境、多阶段训练
1. 引言
语音识别是将语音转录成文本的任务。它在广泛的应用中发挥着至关重要的作用,包括人机交互、语音助手、实时转录和内容创建。高精度的语音识别系统可以显著提升用户体验和可访问性,尤其是在多语言和对话环境中。
经典的端到端自动语音识别(ASR)框架近年来取得了巨大成功。代表性方法包括 Paraformer [1]、OWSM v3.1 [2]、FireRedASR-AED [3] 和 Whisper [4]。这些模型通常采用编码器-解码器范式,并可分为几个主流建模方法:连接主义时序分类(CTC)[5]、循环神经网络转录器(RNN-T)[6]、循环神经网络对齐器(RNA)[7] 和编码器-解码器方法[8]。所有这些方法都旨在通过利用大规模配对的语音和文本数据集,学习声学特征序列与文本标记序列之间的复杂映射。
最近,基于文本的大型语言模型(LLM)在各种下游任务中展示了出色的性能,包括机器翻译、问答和长文本生成。模型如 DeepSeek [9]、GPT [10]、Qwen [11] 和 LLaMA [12] 已成为自然语言理解和生成的基石,因为它们能够从海量文本语料中捕获丰富的语言和上下文知识。受到预训练 LLM 在文本领域成功的启发,最近的研究探索了将它们的推理和生成能力整合到 ASR 管道中。值得注意的例子包括 Qwen-Audio [13] 和 FireRedASR-LLM [3],这些方法在语义复杂或噪声条件下提升了性能。然而,尽管这些进展,现有的 LLM 增强 ASR 系统尚未充分解决真实世界多语言对话场景的挑战,这些场景涉及代码切换、说话者多样性和非正式语音模式。这突显了需要更鲁棒的架构和专门针对多语言对话 ASR 的训练策略。
MLC-SLM 比赛的 Task 1 旨在开发基于 LLM 的 ASR 系统,以提高多语言对话场景中的语音识别准确性。为此,我们采用编码器-适配器-LLM 架构,利用 LLM 的能力。编码器从语音中提取丰富的声学和语义表示,而适配器将编码器输出桥接到 LLM 的语义空间。然后,LLM 通过解释音频派生特征和给定任务指令来生成转录。通过利用 LLM,Triple X 利用了它们的先进文本处理能力和推理潜力,从而实现更准确的语音到文本转换,并更好地适应多样化的语言模式和上下文。
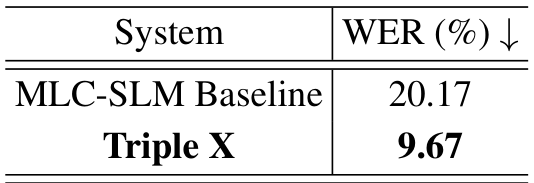
采用这种方法,我们在验证集和测试集上分别实现了 9.73% 和 9.67% 的词错误率,在官方排行榜上获得第二名。这些结果证明了我们架构在多语言环境下的 ASR 性能提升,与其他最先进模型相比具有竞争力。
2. 方法
在本节中,我们首先介绍网络架构,然后描述实验中使用的数据集。最后,我们详细说明实验设置,包括训练策略、输入特征和损失函数。
2.1. 网络架构
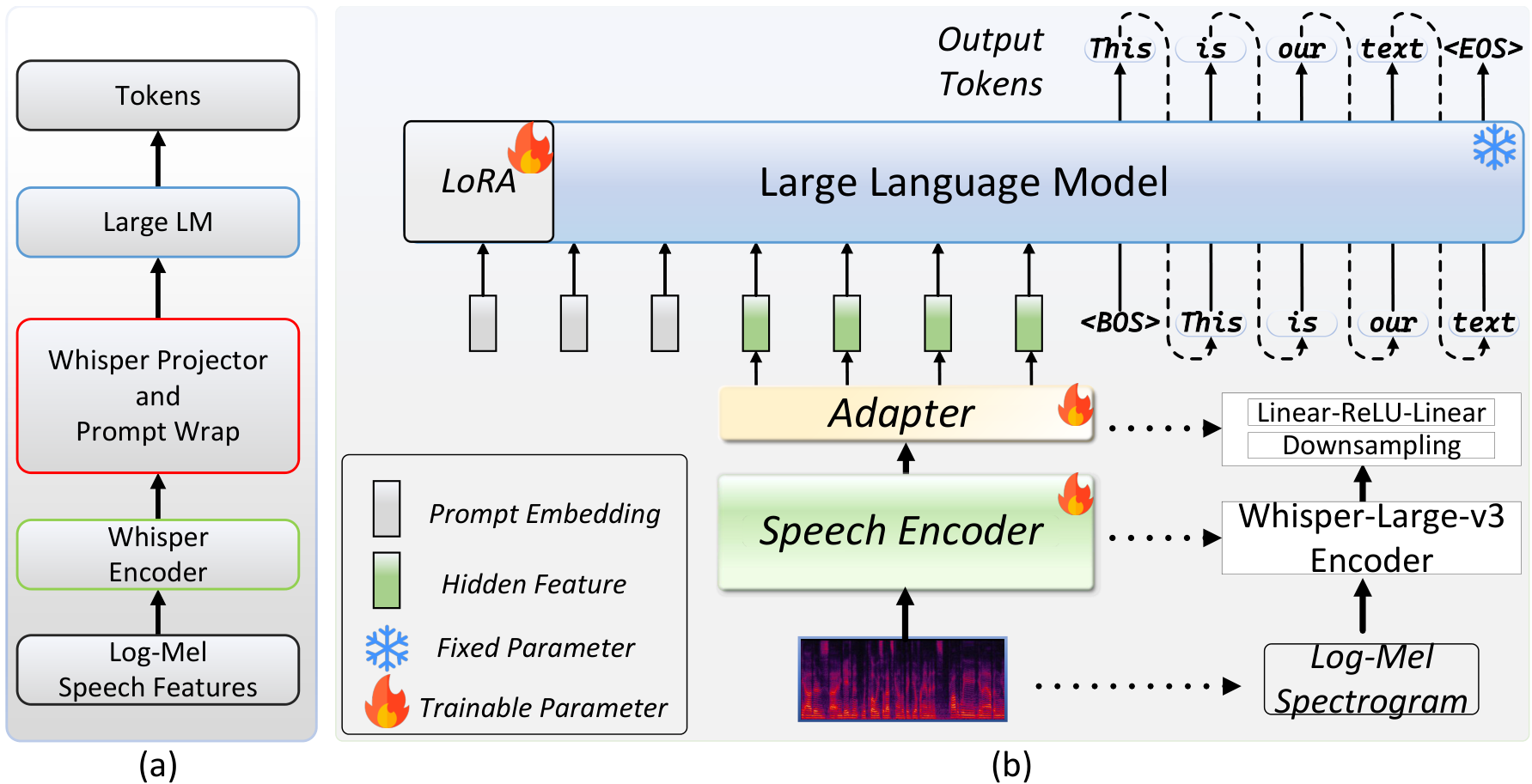
我们提出的 Triple X 系统采用了广泛使用的编码器-适配器-LLM 架构,如图 1 所示。具体来说,我们使用 Whisper-large-v3 编码器从输入语音中提取丰富的声学和语义特征。该编码器遵循标准的 Transformer 架构。然而,编码器的输出序列比文本的序列更长,这可能对 LLM 的处理效率产生负面影响。为了减少序列长度并将音频编码器的输出维度与预训练文本-based LLM 的输入嵌入维度对齐,我们的适配器首先应用一个下采样模块来减少序列长度,然后使用 Linear-ReLU-Linear 变换将编码器的输出语义信息映射到 LLM 的语义空间。值得注意的是,我们使用最简单的帧拼接作为下采样模块,因为我们发现不同的下采样方法会产生类似的结果。对于 Triple X 中的 LLM 组件,我们使用 Qwen-3B 的预训练权重进行初始化。如图 1 所示,LLM 的输入包括编码器的输出特征和用户提示。
2.2. 数据集
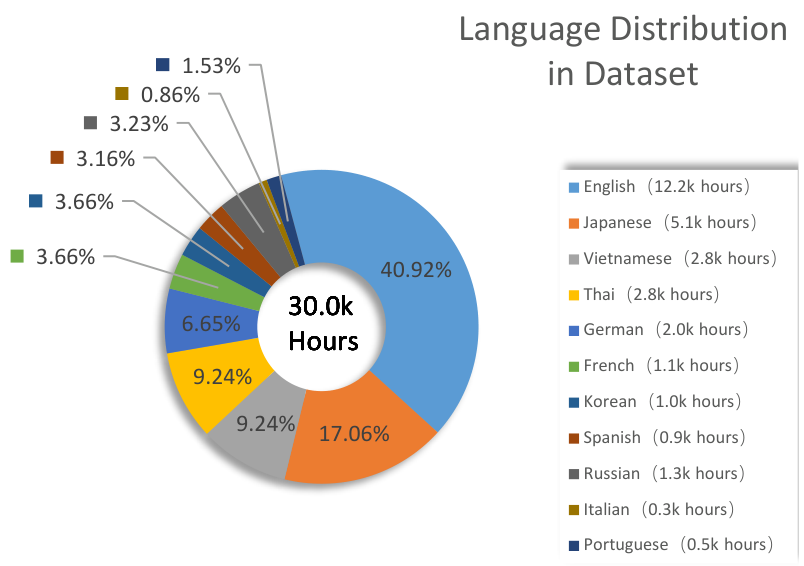
在我们的实验中,我们使用了两种类型的训练集。第一种训练集由比赛组织者提供的约 1,500 小时多语言对话语音数据组成。它涵盖了约 11 种语言,包括英语、法语、德语、意大利语、葡萄牙语、西班牙语、日语、韩语、俄语、泰语和越南语。英语部分包括约 500 小时来自不同地区的录音,包括英国、美国、澳大利亚、印度和菲律宾英语,而其他每种语言大约贡献 100 小时。我们应用了预言分割并使用说话者标签对长话语进行分割。第二种训练集是从公开可用数据集构建的,包括 GigaSpeech2 [14]、KsponSpeech [15]、Reazonspeech [16] 和 Multilingual LibriSpeech [17]。我们从这些数据集选择了 30,000 小时音频数据,数据集的语言分布和数据量统计信息如图 2 所示。
为了评估模型,我们使用了比赛组织者提供的开发集和评估集,评估集包含每种语言 4 小时的录音。
2.3. 实验设置
我们采用精心设计的三阶段训练策略来提高多语言语音识别准确性。首先,我们微调 Whisper-large-v3,并使用结果的编码器权重初始化 Triple X 的编码器。这增强了编码器的语音特征表示能力,并促进了后续训练阶段的更快收敛。接下来,我们冻结编码器并训练适配器参数,以将编码表示中的语义信息与 LLM 的语义空间对齐。最后,我们应用可训练的低秩适应(LoRA)来微调 LLM,同时保持其核心参数固定。这种方法在适应性和保留预训练知识之间取得了平衡。对于输入语音,类似于传统的端到端 ASR 系统,我们应用 SpecAug [18] 和速度扰动 [19] 进行数据增强。我们提取 128 维的 log-Mel 谱图作为编码器的输入特征,使用 25ms 的窗口、10ms 的跳长,而不应用全局均值和方差归一化。在训练过程中,使用交叉熵损失,仅在对应于文本转录的位置计算损失。
3. 评估
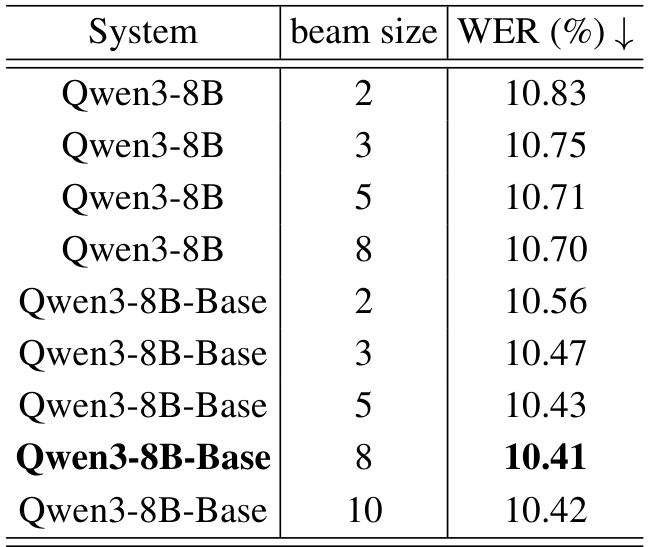
我们最初使用比赛组织者提供的训练集优化模型,以便快速模型选择和性能验证。表 1 展示了 Qwen3-8B 和 Qwen3-8B-Base 在评估集上的结果,揭示了几个关键洞见。首先,Qwen3-8B-Base 在各种 beam 设置下 consistently 实现了更高的语音识别准确性,这体现在更低的 WER 分数上。这表明基础版本可能更适合语音识别任务。其次,增加 beam 大小最初提高了识别准确性,但随后导致了下降,最佳性能(最低 WER)出现在 beam 大小为 8 时。因此,为了平衡计算效率和识别准确性,我们在后续实验中采用 beam 大小为 8 作为最优设置。
即使不加入额外数据,这些模型已经取得了令人印象深刻的性能,超过了 80% 的参与者。为了进一步提升结果,我们收集了大量公开可用数据集,以更好地将编码表示的语义信息映射到 LLM 的语义空间。这些数据集的分布如图 2 所示。在预训练后,我们使用官方训练集以降低的学习率微调适配器和 LoRA 模块。如表 2 所示,所提出的方法在官方评估集上实现了 9.67% 的 WER,对应的识别准确率为 90.33%。这比基线的 79.83% 准确率提高了 13.15%。总体上,我们的模型在验证集和评估集上分别实现了 9.73% 和 9.67% 的 WER,在比赛排行榜上获得第二名。
4. 结论
我们开发了一个名为 Triple X 的多语言语音识别系统,该系统利用了 LLM。通过采用多阶段训练策略,我们的系统在 MLC-SLM 评估集上实现了 9.67% 的 WER,在排行榜上获得第二名。对于未来的工作,我们计划收集更多广泛的多语言对话数据集,以进一步提升多语言对话场景下的识别准确性。此外,我们旨在将当前的 ASR 模型扩展为支持语音识别和响应生成在内的统一框架。
5. 参考文献
[1] Z. Gao, S. Zhang, I. McLoughlin, and Z. Yan, “Paraformer: Fast and accurate parallel transformer for non-autoregressive end-to-end speech recognition, arXiv preprint arXiv:2206.08317, 2022.
[2] Y. Peng, J. Tian, W. Chen, S. Arora, B. Yan, Y. Sudo, M. Shakeel, K. Choi, J. Shi, X. Chang et al., “Owsm v3. 1: Better and faster arXiv preprint arXiv:2401.16658, 2024. open whisper-style speech models based on e-branchformer,"
[3] K.-T. Xu, F-L. Xie, X. Tang, and Y. Hu, “Fireredasr:Open-source industrial-grade mandarin speech recognition mod-els from encoder-decoder to llm integration,’ arXiv preprint arXiv:2501.14350, 2025.
[4] A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” in International conference on machine learning. PMLR, 2023, pp. 28 492-28 518.
[5] A. Graves, S. Fernandez, F. Gomez, and J. Schmidhuber, “Con-nectionist temporal classification: labelling unsegmented se-quence data with recurrent neural networks,” in Proceedings of the 23rd international conference on Machine learning, 2006, pp. 369-376.
[6] A. Graves, A.-r. Mohamed, and G. Hinton, “Speech recognition with deep recurrent neural networks,’ in 2013 IEEE international conference on acoustics, speech and signal processing. IEEE, 2013, pp. 6645-6649.
[7] H. Sak, M. Shannon, K. Rao, and F. Beaufays, “Recurrent neural aligner: An encoder-decoder neural network model for sequence to sequence mapping” in Interspeech, vol. 8, 2017, pp. 1298-1302.
[8] W. Chan, N. Jaitly, Q. Le, and O. Vinyals, “Listen, attend and spell: A neural network for large vocabulary conversational speech recognition,” in 2016 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2016, pp. 4960-4964.
[9] A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan et al., “Deepseek-v3 technical re-port, arXiv preprint arXiv:2412.19437, 2024.
[10] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Ale-man, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al., "Gpt-4 technical report,” arXiv preprint arXiv:2303.08774, 2023.
[11] J. Bai, S. Bai, Y. Chu, Z. Cui, K. Dang, X. Deng, Y. Fan, W. Ge, Y. Han, F. Huang et al., “Qwen technical report,” arXiv preprint arXiv:2309.16609, 2023.
[12] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Roziere, N. Goyal, E. Hambro, F. Azhar et al., "Llama: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023.
[13] Y. Chu, J. Xu, X. Zhou, Q. Yang, S. Zhang, Z. Yan, C. Zhou, and J. Zhou, “Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models,” arXiv preprint arXiv:2311.07919, 2023.
[14] Y. Yang, Z. Song, J. Zhuo, M. Cui, J. Li, B. Yang, Y. Du, Z. Ma, X. Liu, Z. Wang et al., “Gigaspeech 2: An evolving, large-scale and multi-domain asr corpus for low-resource languages with au-arXiv:2406.11546, 2024.
[15] J.-U. Bang, S. Yun, S.-H. Kim, M.-Y. Choi, M.-K. Lee, Y-J. Kim, D.-H. Kim, J. Park, Y-J. Lee, and S.-H. Kim, “Ksponspeech: Korean spontaneous speech corpus for automatic speech recog-nition,” Applied Sciences, vol. 10, no. 19, p. 6936, 2020.
[16] Y. Y. D. M. S. Fujimoto, "Reazonspeech: A free and massive cor-pus for japanese asr,” 2016.
[17] V. Pratap, Q. Xu, A. Sriram, G. Synnaeve, and R. Collobert, “Mls: A large-scale multilingual dataset for speech research, arXiv preprint arXiv:2012.03411, 2020.
[18] D. S. Park, W. Chan, Y. Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V. Le, “Specaugment: A simple data augmen-tation method for automatic speech recognition,” arXiv preprint arXiv:1904.08779, 2019.
[19] T. Ko, V. Peddinti, D. Povey, and S. Khudanpur, “Audio augmen-tation for speech recognition.” in Interspeech, vol. 2015, 2015, p. 3586.
Original Abstract: This paper describes our Triple X speech recognition system submitted to Task
1 of the Multi-Lingual Conversational Speech Language Modeling (MLC-SLM)
Challenge. Our work focuses on optimizing speech recognition accuracy in
multilingual conversational scenarios through an innovative encoder-adapter-LLM
architecture. This framework harnesses the powerful reasoning capabilities of
text-based large language models while incorporating domain-specific
adaptations. To further enhance multilingual recognition performance, we
adopted a meticulously designed multi-stage training strategy leveraging
extensive multilingual audio datasets. Experimental results demonstrate that
our approach achieves competitive Word Error Rate (WER) performance on both dev
and test sets, obtaining second place in the challenge ranking.
PDF Link: 2507.17288v1
