MySQL数据类型介绍
目录
- 数据类型分类
- 数值类型
- tinyint类型
- bit类型
- 小数类型
- float
- decimal
- 字符串类型
- char
- varchar
- char和varchar比较
- 日期和时间类型
- enum和set
数据类型分类
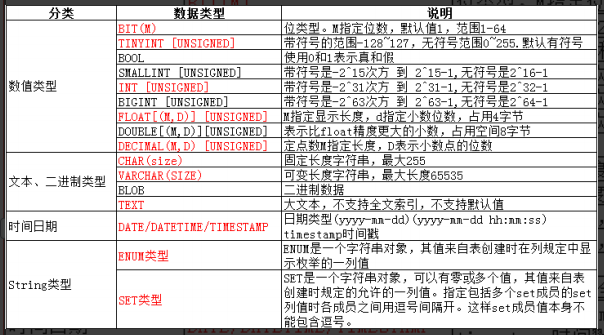
数值类型
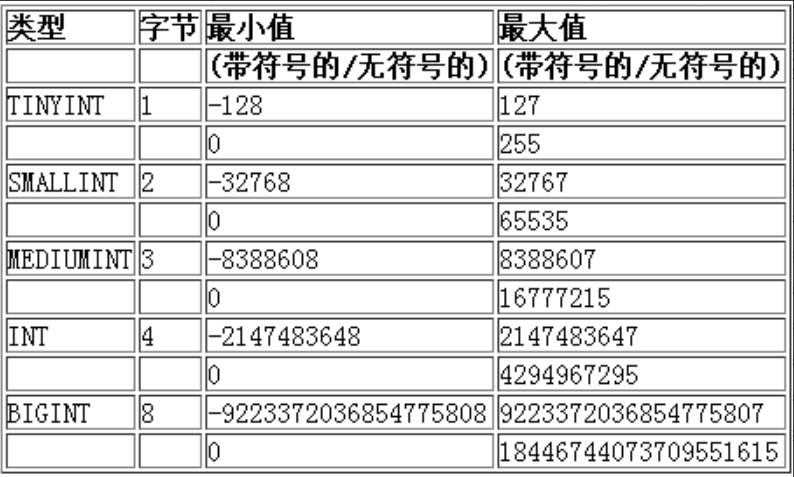
tinyint类型
数值越界测试:
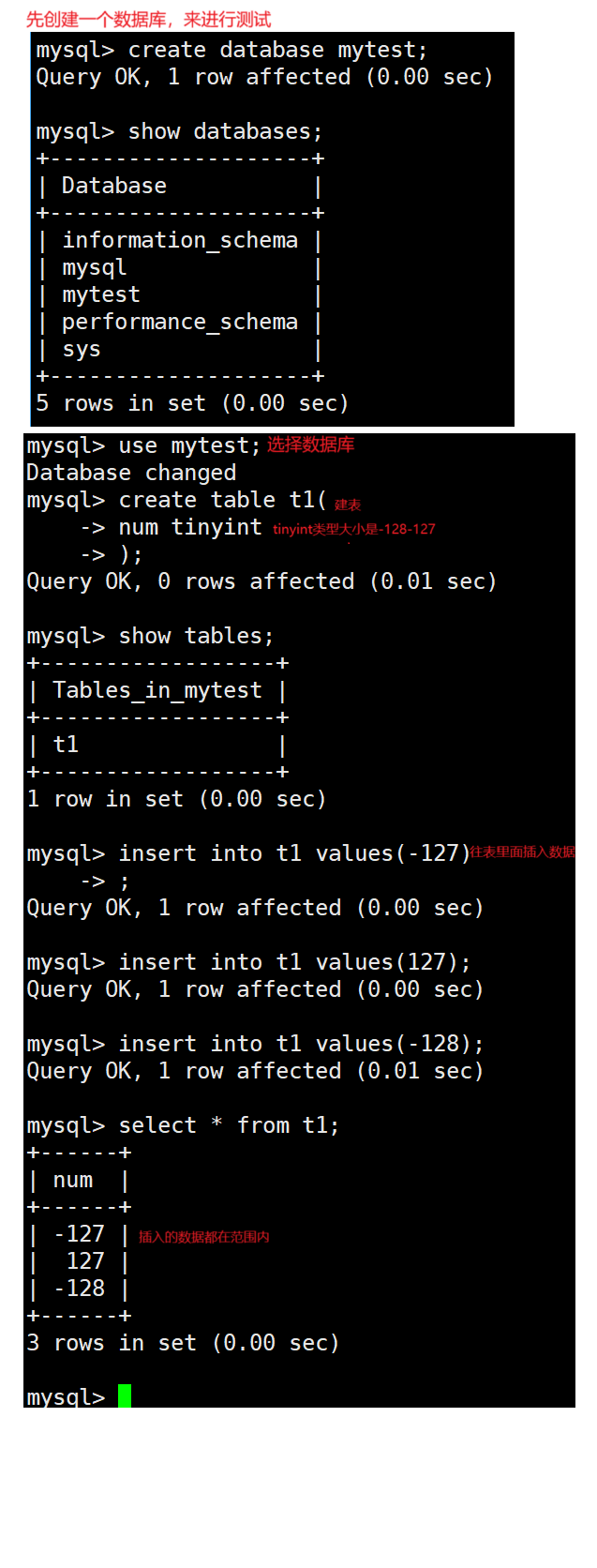
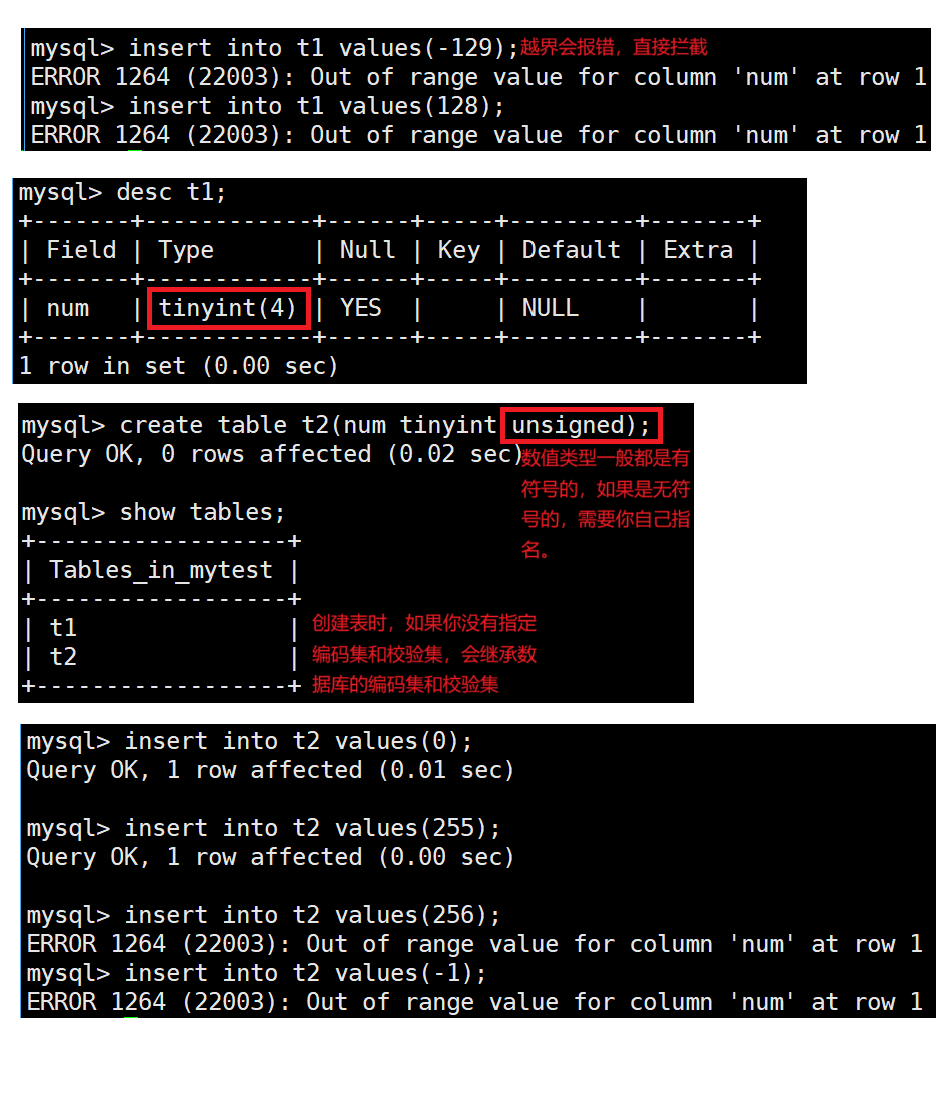
如果我们向MySQL特定的类型中插入不合法的数据,MySQL一般会直接拦截我们,不让我们做对应的操作,反过来,如果我们已经有数据被成功插入到MySQL中,一般插入的数据都是合法的。所以,MySQL中,一般而言,数据本身也是一种约束。
如果你不是一个很好的使用者,MySQL也能保证数据插入的合法性,就能保证数据库中的数据是可预期的(符合数据的范围),完整的(没有发生截断)。
bit类型
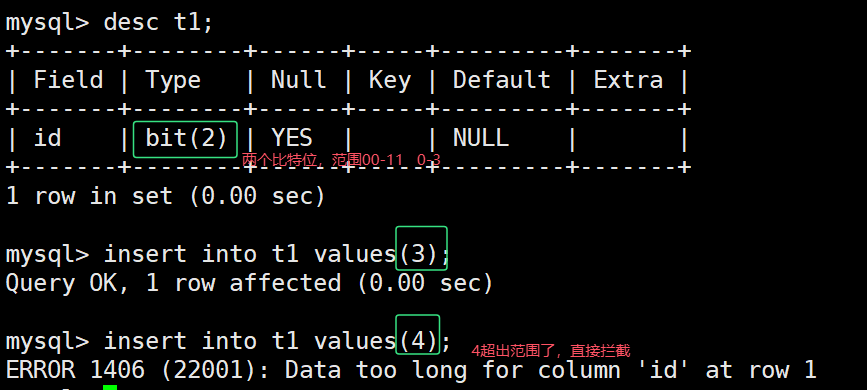
bit[(M)] : 位字段类型。M表示每个值的位数,范围从1到64。如果M被忽略,默认为1。
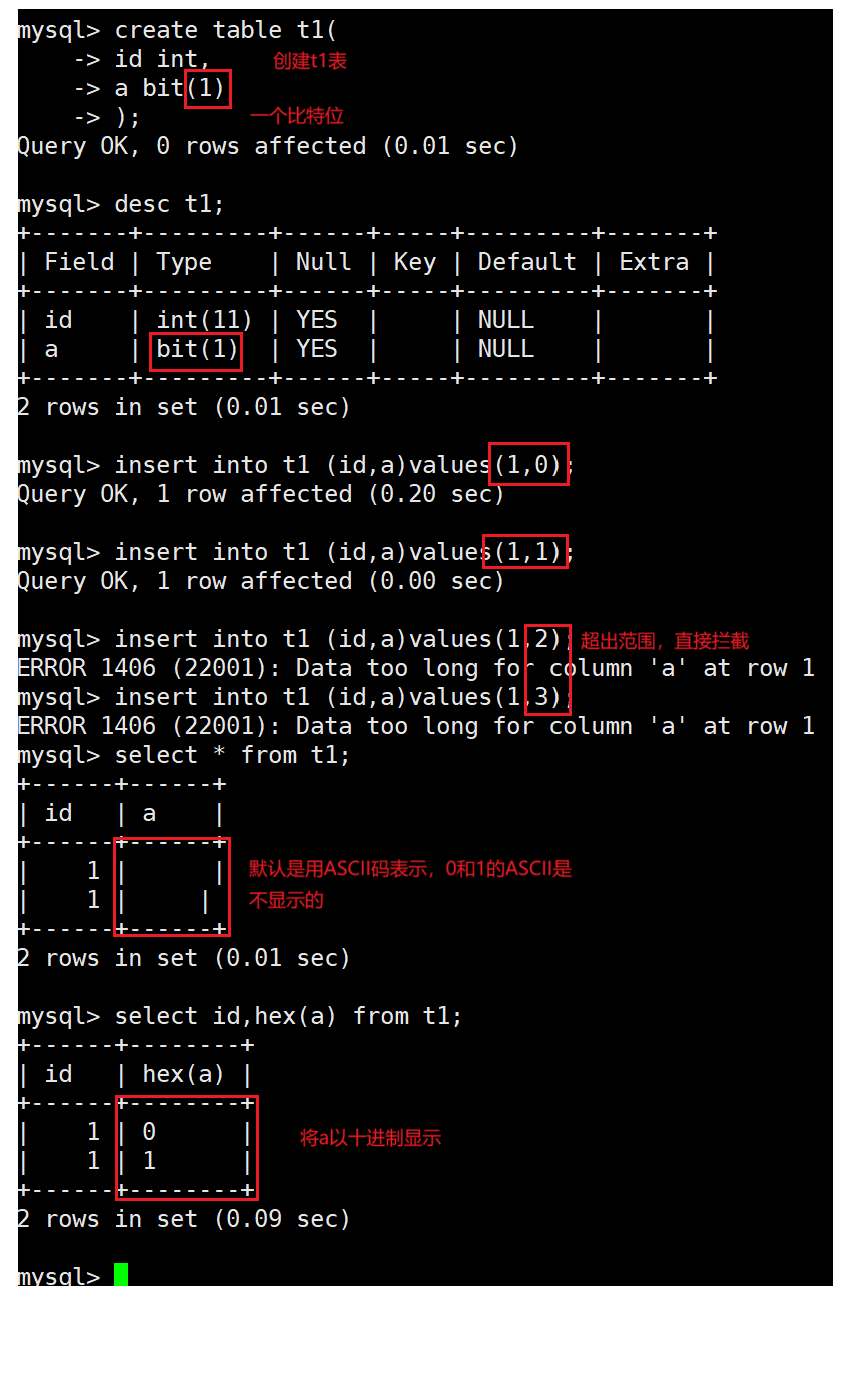
注意:hex()表示的是将字符串的每个字符转换为对应的 ASCII 码的十六进制值,不是十进制。
- bit字段在显示时,是按照ASCII码对应的值显示。
- 如果我们有这样的值,只存放0或1,这时可以定义bit(1)。这样可以节省空间。
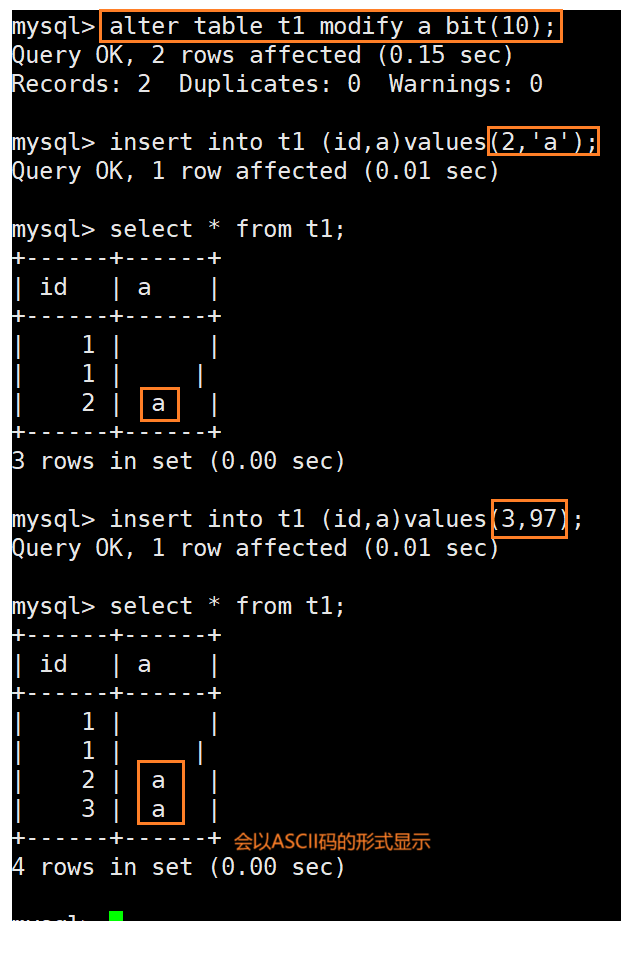
M 的具体含义和影响:
定义存储容量: BIT(M) 可以存储一个由 M 个二进制位(0 或 1) 组成的序列。
例如:
BIT(1):只能存储 0 或 1 (1 位)。
BIT(4):可以存储 0000 到 1111(4位),对应十进制 0 到 15。
BIT(8):可以存储 00000000 到 11111111(8位),对应十进制 0 到 255。
BIT(64):可以存储非常大的数字(0 到 18,446,744,073,709,551,615)。
小数类型
float
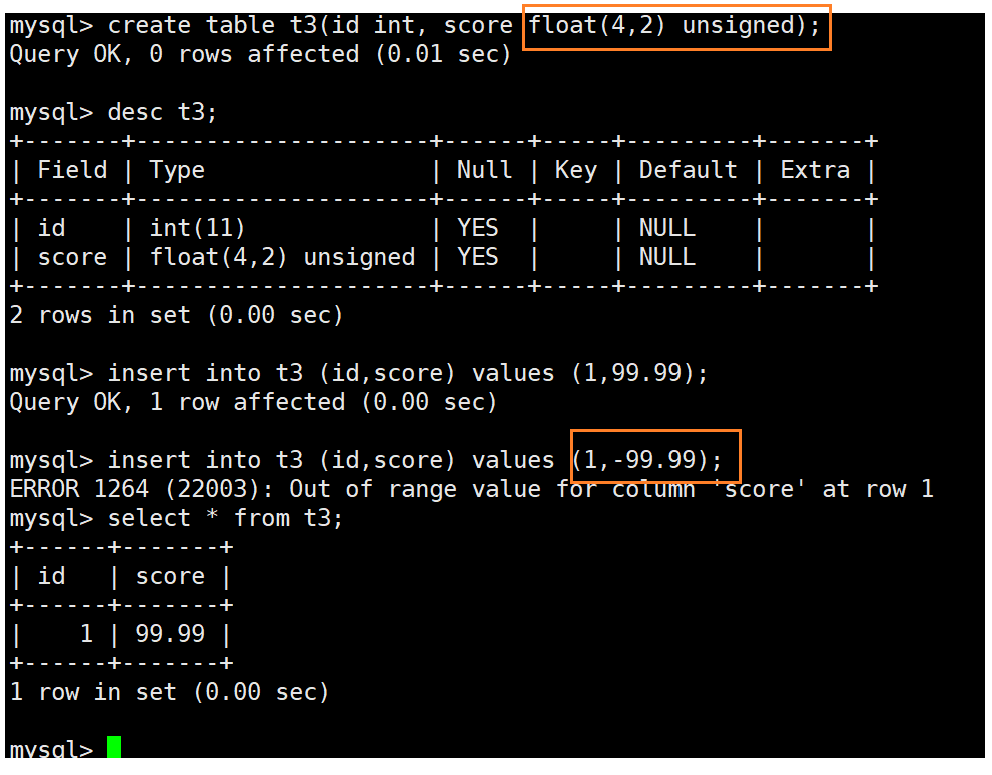
float[(m, d)] [unsigned] : M指定显示长度,d指定小数位数,占用空间4个字节
案例:
小数:float(4,2)表示的范围是-99.99 ~ 99.99,MySQL在保存值时会进行四舍五入。
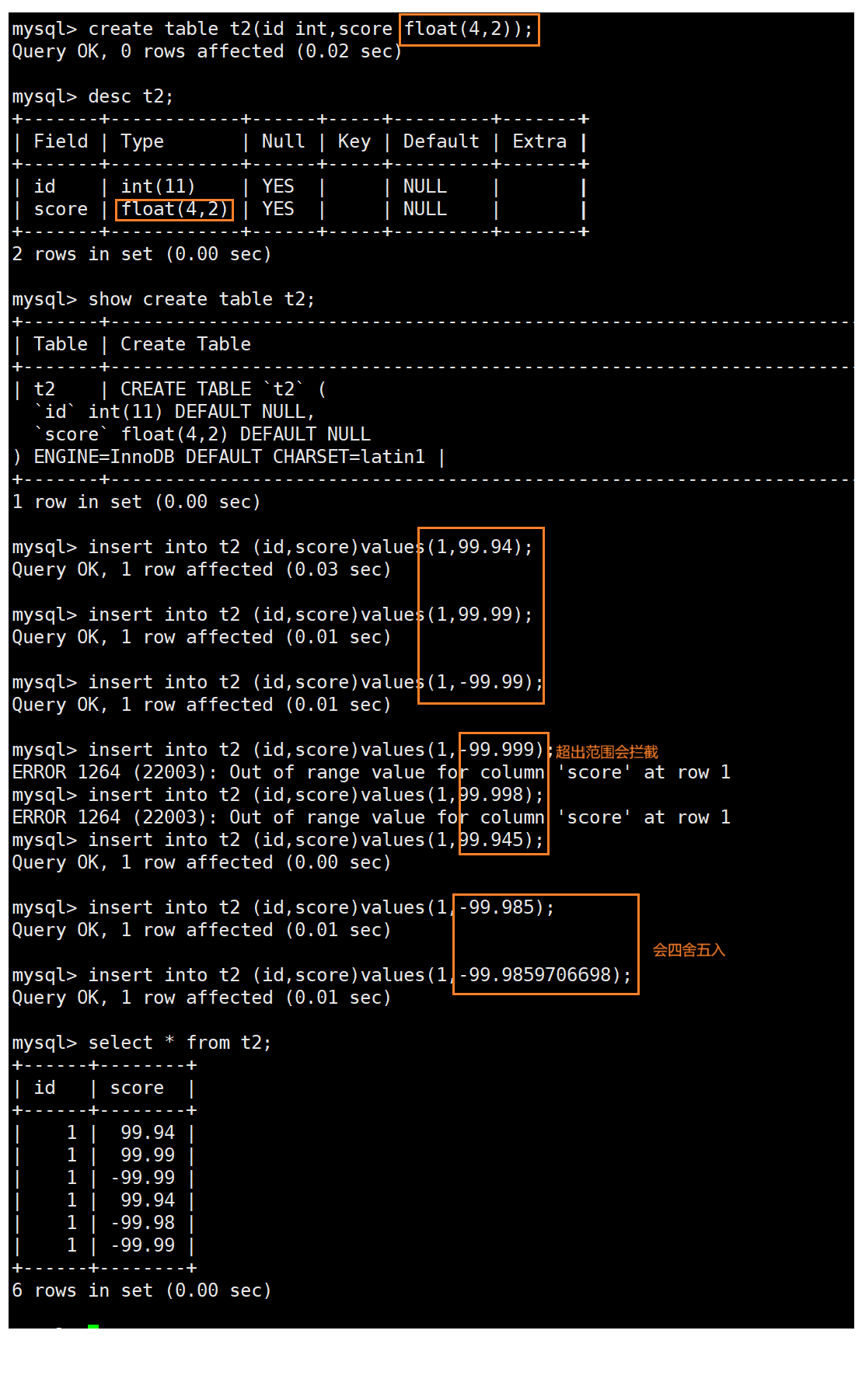
当我们的float(4,2)如果是一个有符号的,则表示范围是-99.99 ~ 99.99,如果float(4,2)是一个无符号的,则表示范围是0 ~ 99.99。
decimal
语法:
decimal(m, d) [unsigned] : 定点数m指定长度,d表示小数点的位数
decimal(5,2) 表示的范围是 -999.99 ~ 999.99
decimal(5,2) unsigned 表示的范围 0 ~ 999.99
decimal和float很像,但是有区别:
float和decimal表示的精度不一样
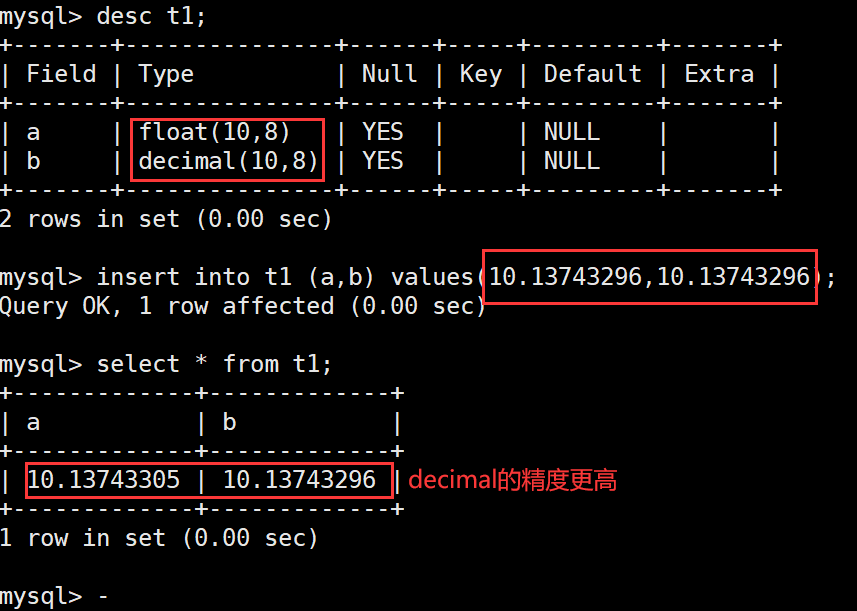
说明:float表示的精度大约是7位。
decimal整数最大位数m为65。支持小数最大位数d是30。如果d被省略,默认为0.如果m被省略,
默认是10。
建议:如果希望小数的精度高,推荐使用decimal。
字符串类型
char
语法:
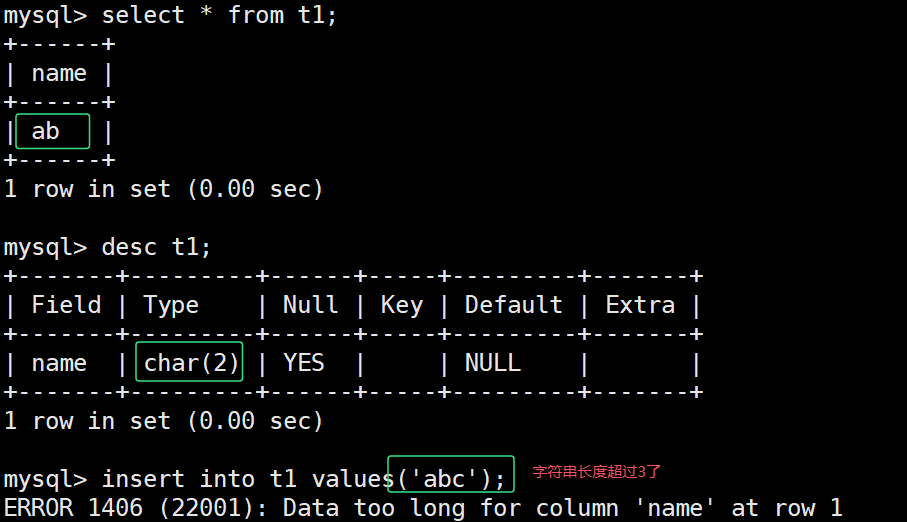
char(L): 固定长度字符串,L是可以存储的长度,单位为字符,最大长度值可以为255
说明:
char(2) 表示可以存放两个字符,可以是字母或汉字,但是不能超过2个, 最多只能是255。

varchar
语法:
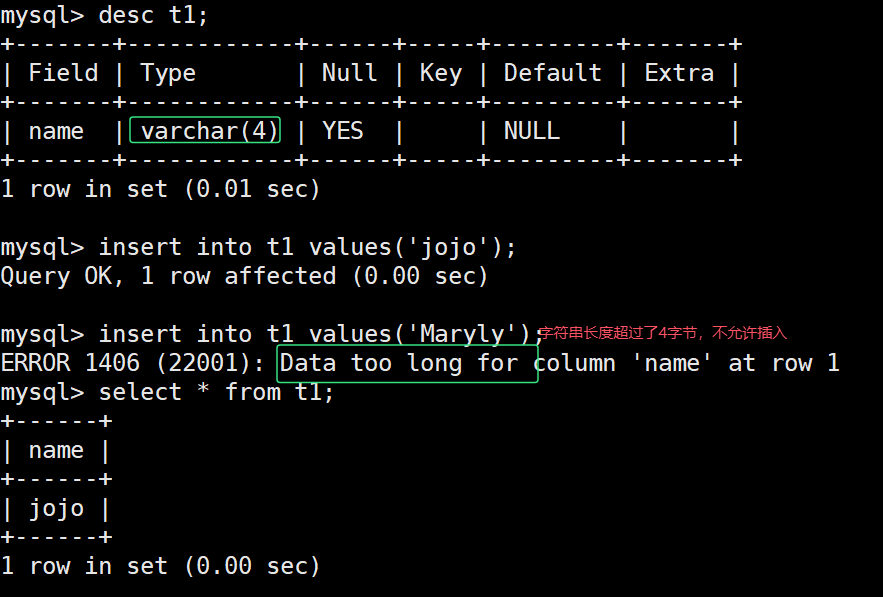
varchar(L): 可变长度字符串,L表示字符长度,最大长度65535个字节
说明:
关于varchar(len),len到底是多大,这个len值,和表的编码密切相关:
varchar长度可以指定为0到65535之间的值,但是有1 - 3 个字节用于记录数据大小,所以说有效字节数是65532。
当我们的表的编码是utf8时,varchar(n)的参数n最大值是65532/3=21844[因为utf中,一个字符占用3个字节],如果编码是gbk,varchar(n)的参数n最大是65532/2=32766(因为gbk中,一个字符占用2字节)。
mysql> create table t11( name varchar(21845))charset=utf8; //--验证了utf8确实是不能超过21844
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBsmysql> create table t11( name varchar(21844))charset=utf8;
Query OK, 0 rows affected (0.01 sec)char和varchar比较
🧱 CHAR:死心眼的“固定工位”
想象公司给每个员工分配固定大小的工位,不管你是只放一台笔记本,还是堆满文件文具,工位大小绝不改变。
怎么用? CHAR(10) 表示固定占用 10 个字符的位置。
存 “Hi”(2字符):实际占用 10个位置,后面自动补 8个空格填满。
→ 相当于工位空荡荡也要占着茅坑。
存 “HelloWorld”(10字符):刚好占满 10个位置,不用补空格。
优点:找东西快!
因为每个位置大小固定,数据库能瞬间算出第N条数据在哪(像按工号找工位)。
缺点:可能浪费空间
存短内容时,补的空格纯属占地方(如存手机号 CHAR(11) 存 “13800138000” 刚好,但存 “10086” 就浪费6字符空间)。
适用场景: 长度几乎不变的数据
✅ 身份证号(18位)、手机号(11位)、固定长度的代码(如国家代码 CN/US)
🎈 VARCHAR:灵活的“伸缩背包”
就像你背的双肩包,装多少东西,背包就撑多大。只装钥匙时瘪瘪的,塞进电脑水杯就鼓起来。
怎么用? VARCHAR(10) 表示最多能存 10 个字符,但按实际内容伸缩。
存 “Hi”(2字符):实际只占 2字符 + 1字节(记录长度的“小标签”)。
→ 背包里只有钥匙,绝不塞废纸充数!
存 “HelloWorld”(10字符):占 10字符 + 1字节(小标签)。
优点:省空间!
存多长就占多大,特别适合长短不一的内容(如用户名、文章标题)。
缺点:找东西稍慢
因为数据长度不定,数据库需要查看“小标签”才知道这条数据多长(像在背包里摸钥匙)。
适用场景: 长度变化大的数据
✅ 用户名、商品标题、文章内容、地址描述
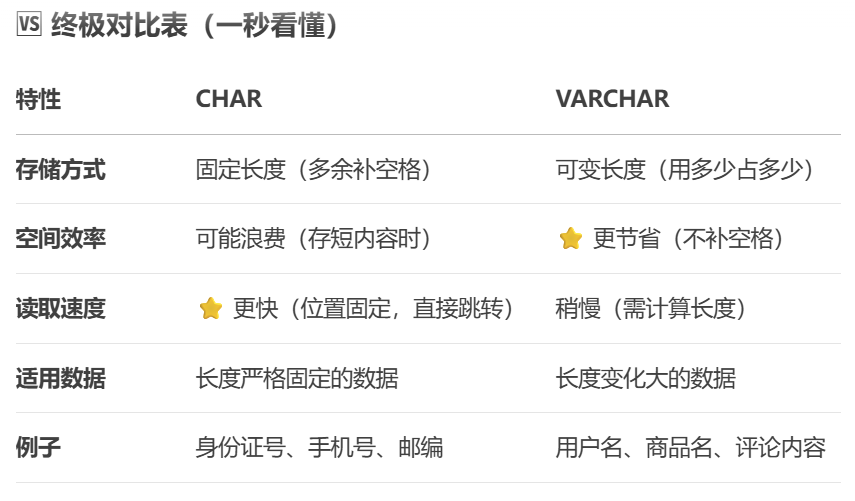
总结一句话:
CHAR —— 我不管,我就要这么大的地方!
VARCHAR —— 用多少拿多少,节约光荣✨
日期和时间类型
常用的日期有如下三个:
date :日期 ‘yyyy-mm-dd’ ,占用三字节
datetime: 时间日期格式 ‘yyyy-mm-dd HH:ii:ss’ 表示范围从 1000 到 9999 ,占用八字节
timestamp :时间戳,从1970年开始的 yyyy-mm-dd HH:ii:ss 格式和 datetime 完全一致,占用四字节
mysql> create table t1( a date, b datetime, c timestamp ); //创建三种时间
Query OK, 0 rows affected (0.01 sec)mysql> desc t1;
+-------+-----------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------+------+-----+-------------------+-----------------------------+
| a | date | YES | | NULL | |
| b | datetime | YES | | NULL | |
| c | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
+-------+-----------+------+-----+-------------------+-----------------------------+
3 rows in set (0.00 sec)mysql> insert into t1 (a,b)values('1991-1-1','2002-1-1 12:24:12');//插入两种不同的时间
Query OK, 1 row affected (0.02 sec)mysql> select * from t1;
+------------+---------------------+---------------------+
| a | b | c |
+------------+---------------------+---------------------+
| 1991-01-01 | 2002-01-01 12:24:12 | 2025-08-05 19:39:02 | //添加数据时,时间戳自动补上当前时间
+------------+---------------------+---------------------+
1 row in set (0.00 sec)//更新时间
mysql> select * from t1;
+------------+---------------------+---------------------+
| a | b | c |
+------------+---------------------+---------------------+
| 2004-10-25 | 2002-01-01 12:24:12 | 2025-08-05 19:43:31 | //更新数据,时间戳会更新成当前时间
+------------+---------------------+---------------------+
1 row in set (0.00 sec)enum和set
语法:
enum:枚举,“单选”类型;
enum('选项1','选项2','选项3',...);
该设定只是提供了若干个选项的值,最终一个单元格中,实际只存储了其中一个值;而且出于效率考
虑,这些值实际存储的是“数字”,因为这些选项的每个选项值依次对应如下数字:1,2,3,…最多65535
个;当我们添加枚举值时,也可以添加对应的数字编号。
set:集合,“多选”类型;
set('选项值1','选项值2','选项值3', ...);
该设定只是提供了若干个选项的值,最终一个单元格中,设计可存储了其中任意多个值;而且出于效率
考虑,这些值实际存储的是“数字”,因为这些选项的每个选项值依次对应如下数字:1,2,4,8,16,32,…
最多64个。
说明:不建议在添加枚举值,集合值的时候采用数字的方式,因为不利于阅读。
🎯 ENUM:单选题答题卡
想象考试中的单选题:题目明确说“只能选一个”,选项印在试卷上(比如 A.苹果 B.香蕉 C.橘子)。你填答题卡时,必须且只能涂黑一个框 ✅。
数据库版 ENUM
sql
CREATE TABLE fruits (fruit ENUM('苹果', '香蕉', '橘子') -- 定义时写好“标准答案”
);
怎么存数据?
✅ 合法值:‘苹果’、‘香蕉’、‘橘子’(必须三选一)
❌ 非法值:‘西瓜’(不在选项里)、‘苹果,香蕉’(不能多选!)
优点:
省空间:实际存的是选项编号(1,2,3),不是完整字符串
防手抖:避免存入无效值(比如 萍果 错别字)
适用场景
✅ 性别(男/女/保密)、订单状态(待付款/已发货/已完成)、用户类型(普通/VIP/管理员)
💡 一句话总结 ENUM:
固定选项池,必须单选,像考试涂答题卡!
🧩 SET:多选爱好调查表
想象一份兴趣爱好调查表:选项有“读书、健身、旅行、摄影”,你可以勾选多个 ✅✅(比如同时选读书和旅行)。
数据库版 SET
sql
CREATE TABLE users (hobbies SET('读书','健身','旅行','摄影') -- 定义可选爱好
);
怎么存数据?
✅ 合法值:
‘读书’(单选)、‘健身,旅行’(多选)、‘读书,摄影’(跳选)
❌ 非法值:‘打游戏’(不在选项里)、‘读书,读书’(重复无效)
底层存储奥秘
每个选项对应一个比特位(二进制开关):
text
读书 → 0001 (1)
健身 → 0010 (2)
旅行 → 0100 (4)
摄影 → 1000 (8)
选 '健身,旅行' 实际存 0010 + 0100 = 0110 (6) → 节省空间!适用场景
✅ 用户标签、文章分类、权限组合(读+写+执行)、多选兴趣爱好
💡 一句话总结 SET:
固定选项池,支持多选,像勾调查表复选框!