Python-机器学习初识
目录
一、定义
1、分类
1.1 监督学习
1.2 半监督学习
1.3 无监督学习
1.4 强化学习
2、流程/步骤
二、scikit-learn
1、安装
三、数据集
3.1 sklearn玩具数据集
3.2 sklearn现实数据集
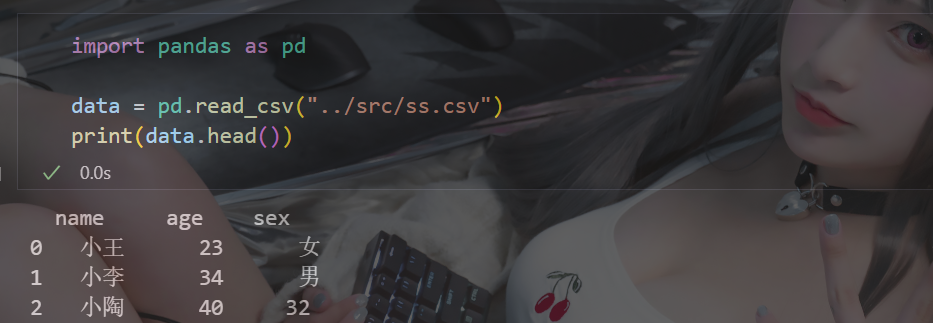
3.3 本地csv数据
一、定义
机器学习(Machine Learning)本质上就是让计算机自己在数据中学习规律,并根据所得到的规律对未来数据进行预测。机器学习包括如聚类、分类、决策树、贝叶斯、神经网络、深度学习(Deep Learning)等算法
1、分类
机器学习经过几十年的发展,衍生出了很多种分类方法,这里按学习模式的不同,可分为监督学习、半监督学习、无监督学习和强化学习
1.1 监督学习
监督学习(Supervised Learning)是从有标签的训练数据中学习模型,然后对某个给定的新数据利用模型预测它的标签(监督学习主要用于回归和分类)
常见的监督学习的回归算法有线性回归、回归树、K邻近、Adaboost、神经网络等。
常见的监督学习的分类算法有朴素贝叶斯、决策树、SVM、逻辑回归、K邻近、Adaboost、神经网络等。
1.2 半监督学习
半监督学习(Semi-Supervised Learning)是利用少量标注数据和大量无标注数据进行学习的模式
常见的半监督学习算法有Pseudo-Label、Π-Model、Temporal Ensembling、Mean Teacher、VAT、UDA、MixMatch、ReMixMatch、FixMatch等
1.3 无监督学习
无监督学习(Unsupervised Learning)是从未标注数据中寻找隐含结构的过程
无监督学习主要用于关联分析、聚类和降维
常见的无监督学习算法有稀疏自编码(Sparse Auto-Encoder)、主成分分析(Principal Component Analysis, PCA)、K-Means算法(K均值算法)、DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)、最大期望算法(Expectation-Maximization algorithm, EM)等
1.4 强化学习
强化学习(Reinforcement Learning)类似于监督学习,但未使用样本数据进行训练,是通过不断试错进行学习的模式
在强化学习中,有两个可以进行交互的对象:智能体(Agnet)和环境(Environment),还有四个核心要素:策略(Policy)、回报函数(收益信号,Reward Function)、价值函数(Value Function)和环境模型(Environment Model),其中环境模型是可选的
(通过奖励引导行为,逐渐学会最优策略)
2、流程/步骤
有5个基本步骤用于执行机器学习任务:
1、收集数据:无论是来自excel,access,文本文件等的原始数据,构成了未来学习的基础
2、准备数据: 任何分析过程都会依赖于使用的数据质量如何
3、练模型:此步骤涉及以模型的形式选择适当的算法和数据表示。清理后的数据分为两部分 - 训练和测试,训练集用于开发模型,测试集用于参考依据
4、评估模型:为了测试准确性,使用提前划分的测试集,根据结果确定算法选择的精度
5、提高性能:此步骤可能涉及选择完全不同的模型或引入更多变量来提高效率。这就是为什 么需要花费大量时间进行数据收集和准备的原因
(在后面的代码实现中,可以参考下面的流程)

二、scikit-learn
scikit-learn官网:scikit-learn: machine learning in Python — scikit-learn 1.7.1 documentationscikit-learn: machine learning in Python — scikit-learn 1.7.1 documentationscikit-learn: machine learning in Python — scikit-learn 1.7.1 documentationscikit-learn: machine learning in Python — scikit-learn 1.7.1 documentationscikit-learn: machine learning in Python — scikit-learn 1.7.1 documentation
scikit-learn中文文档:sklearn
scikit-learn中文社区:scikit-learn中文社区
scikit-learn是Python语言机器学习工具,包括许多智能的机器学习算法的实现
1、安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn(推荐使用镜像源下载,不然网络不好,直接下载会失败)
三、数据集
return_X_y:决定返回值的情况False(默认值):函数返回一个对象,能够数据集所有的属性True:函数返回一个元组,第一个元素为特征数据集,第二个元素为目标数据集3.1 sklearn玩具数据集
| 函数 | 返回 |
| load_boston | 加载并返回波士顿房价数据集(回归) |
| load_iris | 加载并返回鸢尾花数据集(分类) |
| load_diabetes | 加载并返回糖尿病数据集(回归) |
| load_digits | 加载并返回数字数据集(分类) |
| load_linnerud | 加载并返回linnerud物理锻炼数据集 |
| load_wine | 加载并返回葡萄酒数据集(分类) |
| load_breast_cancer | 加载并返回威斯康星州乳腺癌数据集(分类) |
数据量小,数据在sklearn库的本地,通过 datasets 使用
示例:(以鸢尾花为例,数据的获取)
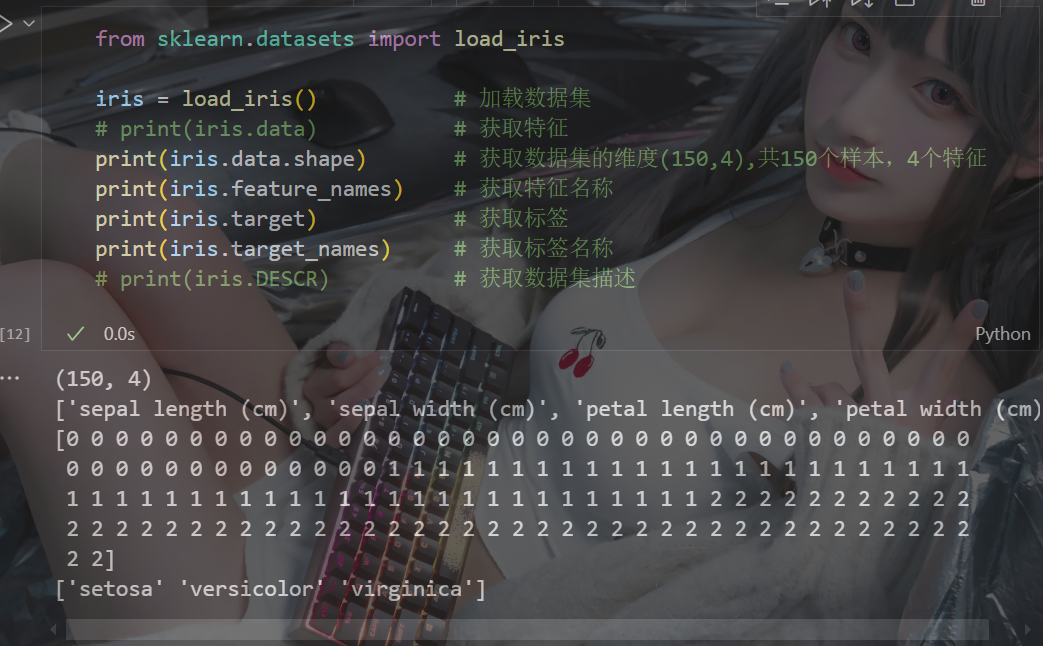
(使用其他数据集时,可以查下资料,了解一下那数据集有些什么属性)
3.2 sklearn现实数据集
| 函数 | 说明 |
| fetch_olivetti_faces | 从AT&T(分类)中加载Olivetti人脸数据集 |
| fetch_20newsgroups | 从20个新闻组数据集中加载文件名和数据(分类) |
| fetch_20newsgroups_vectorized | 加载20个新闻组数据集并将其矢量化为令牌计数(分类) |
| fetch_lfw_people | 将标签的面孔加载到Wild(LFW)人数据集中(分类) |
| fetch_lfw_pairs | 在“Wild(LFW)”对数据集中加载标签的面部(分类) |
| fetch_covtype | 加载covtype(植被型数据集)数据集(分类) |
| fetch_rcv1 | 加载RCV1多标签数据集(分类) |
| fetch_kddcup99 | 加载kddcup99(网络入侵检测)数据集(分类) |
| fetch_california_housing | 加载加利福尼亚住房数据集(回归) |
数据量大,数据只能通过网络获取,同样通过 datasets 使用
from sklearn import datasets
datasets.get_data_home() #查看数据集默认存放的位置通过上面这段代码,就能找到数据集默认的下载地址

参数:
data_home:None:默认值,下载到默认地址自定义路径:指定下载路径
subset:"train",只下载训练集"test",只下载测试集"all",下载的数据包含了训练集和测试集3.3 本地csv数据
(创建csv文件的方法很多,感兴趣可以自己了解一下)
其实不止csv文件,只要是数据都可以获取使用,这里只展示使用pandas获取csv类型数据