论文阅读: Mobile Edge Intelligence for Large LanguageModels: A Contemporary Survey
地址:Mobile Edge Intelligence for Large Language Models: A Contemporary Survey
 摘要
摘要
设备端大型语言模型(LLMs)指在边缘设备上运行 LLMs,与云端模式相比,其成本效益更高、延迟更低且更能保护隐私,因此引发了广泛关注。然而,设备端 LLMs 的性能本质上受限于边缘设备的资源约束。移动边缘智能(MEI)介于云端 AI 和设备端 AI 之间,通过在移动网络边缘提供 AI 能力,允许终端用户将繁重的 AI 计算卸载到附近的边缘服务器,为这一问题提供了可行解决方案。本文对利用 MEI 支持 LLMs 的研究进行了最新综述:首先,通过若干典型应用场景说明在网络边缘部署 LLMs 的迫切需求;其次,介绍 LLMs 和 MEI 的基础知识,以及资源高效的 LLM 技术;随后,概述面向 LLMs 的 MEI 架构(MEI4LLM),阐述其核心组件及对 LLMs 部署的支持方式;接着,深入探讨 MEI4LLM 的各个方面,包括边缘 LLM 缓存与分发、边缘 LLM 训练和边缘 LLM 推理;最后,指出未来的研究方向。希望本文能启发研究者利用移动边缘计算推动 LLMs 部署,从而在各类隐私敏感和延迟敏感型应用中释放 LLMs 的潜力。
概述
-
背景与动机
- 云端 LLMs 存在隐私泄露、带宽成本高、延迟长等问题;设备端 LLMs 受限于资源,难以支持大规模模型和复杂任务。
- MEI 作为折中方案,通过边缘服务器提供 AI 能力,平衡计算资源、延迟和隐私需求,成为 6G 时代 LLMs 部署的关键方向。
-
核心应用场景
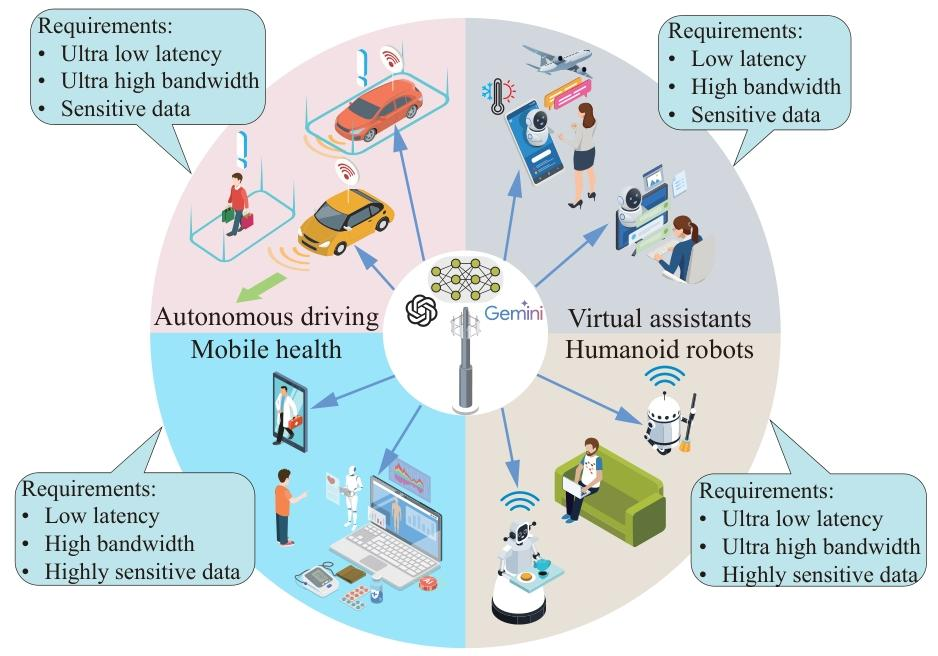
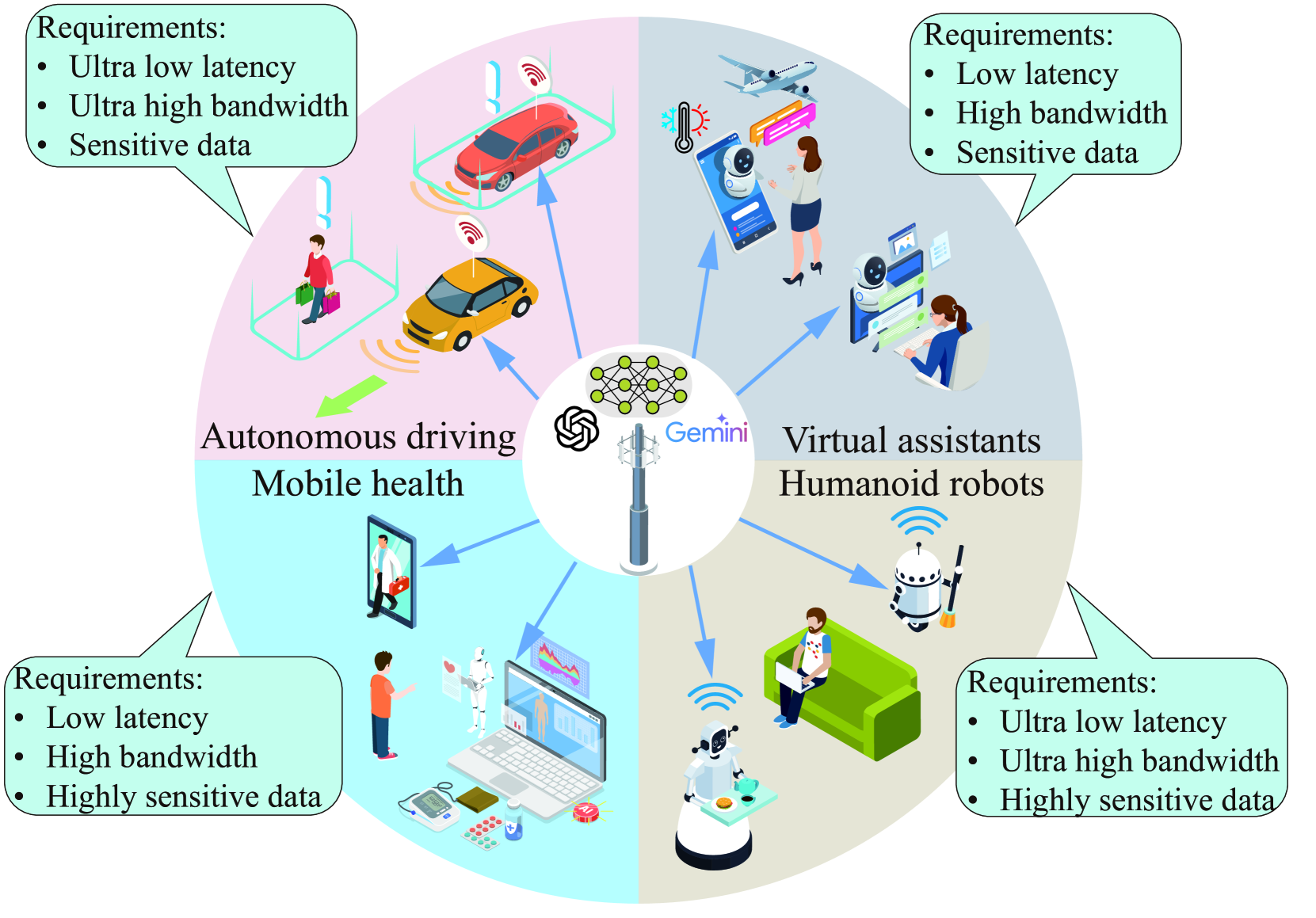
聚焦四个对边缘部署 LLMs 需求迫切的场景:- 移动医疗:需低延迟处理敏感健康数据,符合隐私法规(如 GDPR);
- 类人机器人:依赖实时响应(10-100ms 延迟)和本地化数据处理;
- 虚拟助手:要求低延迟交互(<200ms)和用户数据隐私保护;
- 自动驾驶:需超低延迟(10ms 级)和处理海量多模态传感器数据。
-
基础技术
- LLMs 基础:基于 Transformer 架构,分为编码器仅用、解码器仅用、编码器 - 解码器三类,支持文本、图像等多模态输入,存在自回归生成等特性。
- MEI 基础:融合移动边缘计算与 AI,通过边缘服务器实现分布式训练和推理,支持联邦学习、拆分学习等框架。
- 资源高效技术:包括模型压缩(量化、剪枝、知识蒸馏)、快速解码(投机解码、早期退出)、参数高效微调(LoRA、前缀调优)等。
-
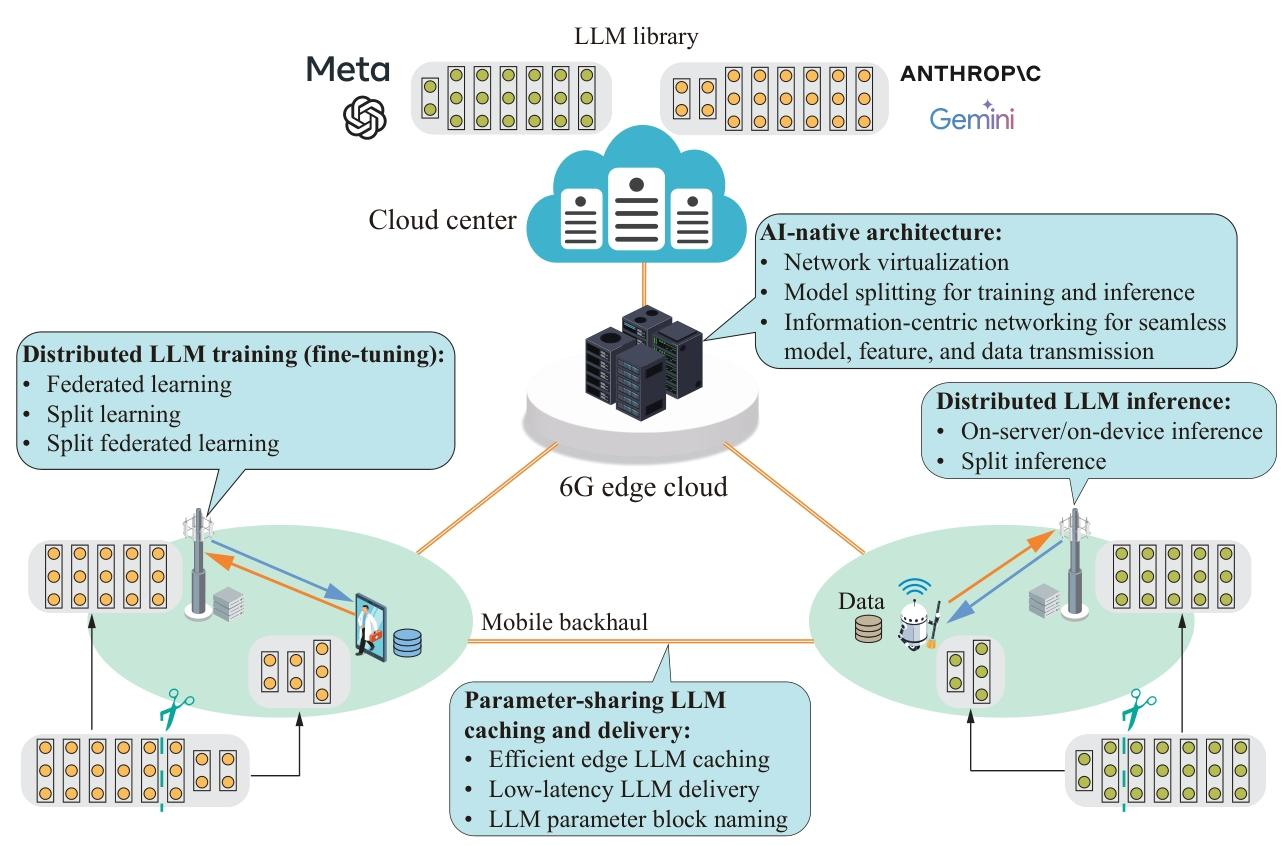
MEI4LLM 架构
- 核心组件:AI 原生网络架构、参数共享的 LLM 缓存与分发、分布式 LLM 训练、分布式 LLM 推理。
- 关键技术:
- 缓存与分发:利用参数共享特性优化边缘缓存(如 TrimCaching),通过多播和量化减少传输成本;
- 训练:支持集中式边缘学习、联邦学习、拆分学习和分层协同学习,结合参数高效微调降低资源消耗;
- 推理:包括集中式推理(边缘服务器统一处理)、拆分推理(设备与服务器分工)、协同推理(设备生成初步结果,服务器验证)。
-
未来方向
- 绿色边缘 LLM(降低能耗)、安全边缘 LLM(防御隐私攻击)、质量感知的边缘 LLM 训练(数据质量控制)。
一、相关技术总结
-
资源高效的 LLM 技术
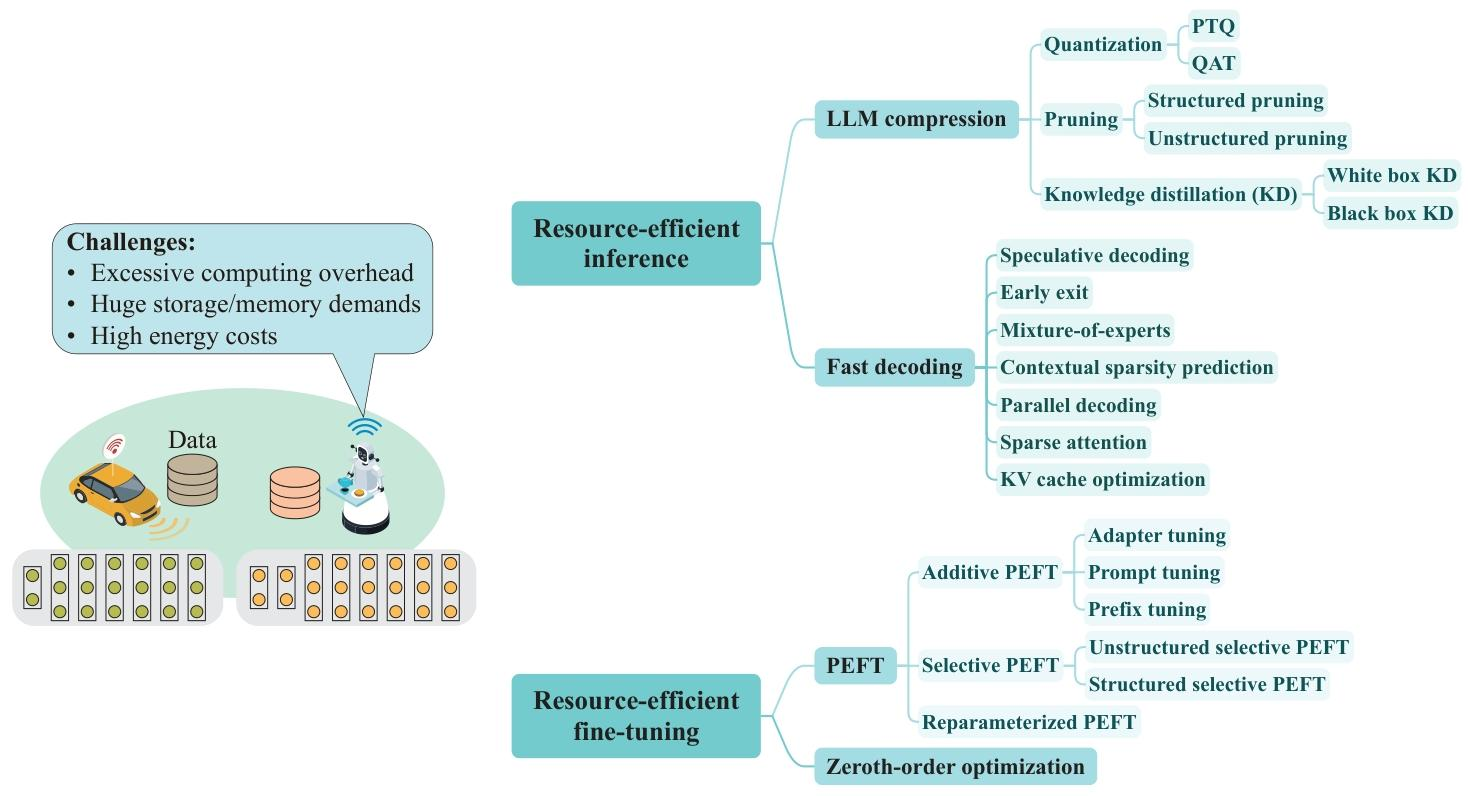
技术类别 具体方法 核心原理 优点 缺点 性能表现(典型案例) 模型压缩 量化(PTQ/QAT) 将高精度参数(如 FP16)转为低精度(如 INT4/INT8) 减少存储和计算量,适配边缘设备内存 可能导致精度损失,QAT 需额外训练资源 Llama2-7B 经 4-bit 量化后内存从 28GB 降至 3.5GB,精度损失 <1% [8,131] 剪枝(结构化 / 非结构化) 移除冗余参数(如注意力头、权重) 降低模型复杂度,加速推理 非结构化剪枝需专用硬件支持 GPT-3 经 60% 非结构化剪枝后,精度无显著损失 [133] 知识蒸馏 用小模型(学生)学习大模型(教师)的输出分布 保留核心能力,模型体积大幅缩减(如 10 倍) 蒸馏过程需大量标注数据,可能丢失细粒度知识 MiniLLM 在文本生成任务上性能接近教师模型,体积缩减 90% [134] 快速解码 投机解码 轻量模型生成候选 token,大模型验证修正 减少自回归迭代次数,延迟降低 50% 以上 需维护轻量模型,验证错误可能引入额外成本 llama.cpp 中投机解码使生成速度提升 2 倍,能耗降低 50% [129] 早期退出 在中间层设置出口,满足置信度时终止推理 动态平衡速度与精度,短文本任务加速显著 长文本生成中需保留 KV 缓存,增加内存占用 BERT 经早期退出优化后,推理速度提升 40%,精度损失 <2% [137] 参数高效微调 LoRA 冻结预训练权重,仅训练低秩矩阵 微调参数减少 99%,适配边缘设备计算能力 推理时需合并低秩矩阵,可能增加延迟 LLaMA-7B 经 LoRA 微调后,下游任务性能接近全量微调,参数仅增加 0.1% [153] 前缀调优 在输入前添加可训练的软提示(Soft Prompt) 无需修改模型结构,适配多任务场景 提示设计依赖人工经验,复杂任务性能有限 GPT-2 通过前缀调优在机器翻译任务上 BLEU 值达 69,接近全量微调 [149] - 模型压缩:
- 量化:将高精度参数转为低精度(如 INT4),减少存储和计算量(如 GPTQ、AWQ);
- 剪枝:移除冗余参数,分结构化(剪枝注意力头)和非结构化(稀疏化权重)两类;
- 知识蒸馏:通过 “教师 - 学生” 模型传递知识,适配边缘设备(如 MiniLLM)。
- 快速解码:
- 投机解码:用轻量模型生成候选 tokens,由大模型验证,减少迭代次数;
- 早期退出:在中间层终止推理,平衡速度与精度;
- KV 缓存优化:压缩或动态管理缓存,减少内存占用(如 MiniCache)。
- 参数高效微调:
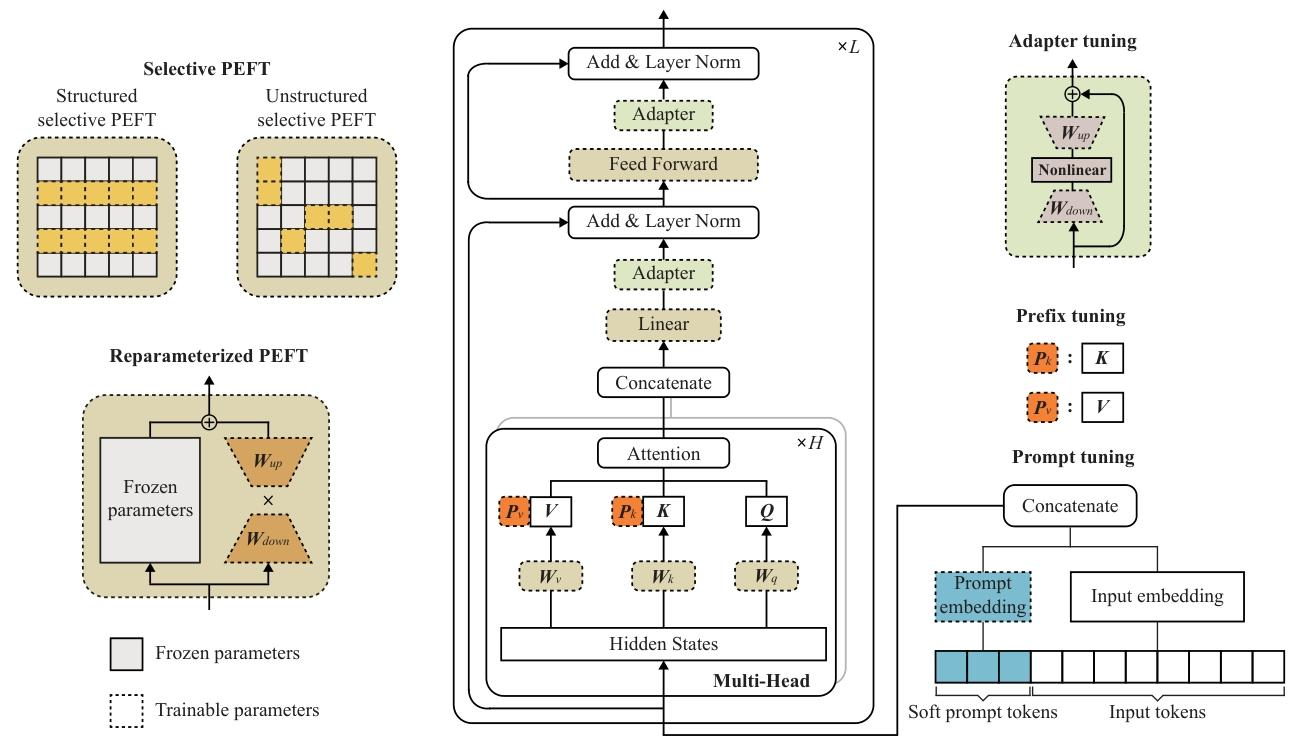
- 适配器调优(Adapter Tuning)、前缀调优(Prefix Tuning)等,仅更新少量参数即可适配下游任务;
- LoRA 通过低秩矩阵分解减少微调参数,兼容边缘设备。
- 模型压缩:
-
边缘 LLM 缓存与分发
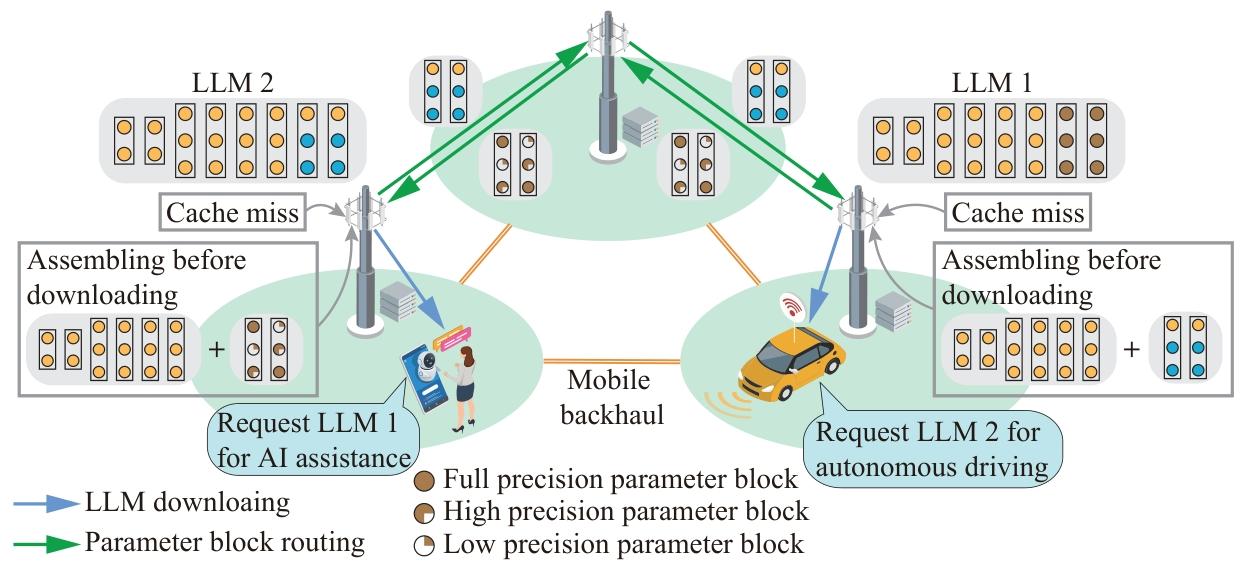
技术方法 核心原理 优点 缺点 性能表现(典型案例) 参数共享缓存 缓存共享参数块(如预训练权重),仅存储任务特定参数(如 LoRA 适配器) 存储效率提升 5-10 倍,支持多模型并发 缓存替换策略复杂,依赖参数共享度 TrimCaching 在 12 个边缘服务器部署 100 个微调模型,缓存命中率提升至 80% [197] 多播分发 对共享参数块多播,任务特定参数单播 传输效率提升 3-5 倍,减少带宽消耗 多播组管理复杂,适用于密集用户场景 多播分发 Llama2-7B,下载延迟从 5s 降至 1.2s [198] 量化传输 模型参数量化后传输,边缘设备解压使用 传输量减少 4-8 倍,适配低带宽边缘网络 解压增加设备计算负担,可能损失精度 4-bit 量化传输 GPT-3,传输时间减少 75%,精度损失 <2% [199] - 缓存策略:利用 LLM 参数共享特性(如 LoRA 微调模型共享预训练权重),采用 TrimCaching 等方法减少存储冗余;
- 分发优化:通过参数块多播、量化传输、联合缓存与路由优化,降低传输延迟和带宽消耗。
-
边缘 LLM 训练与推理
- 训练框架:
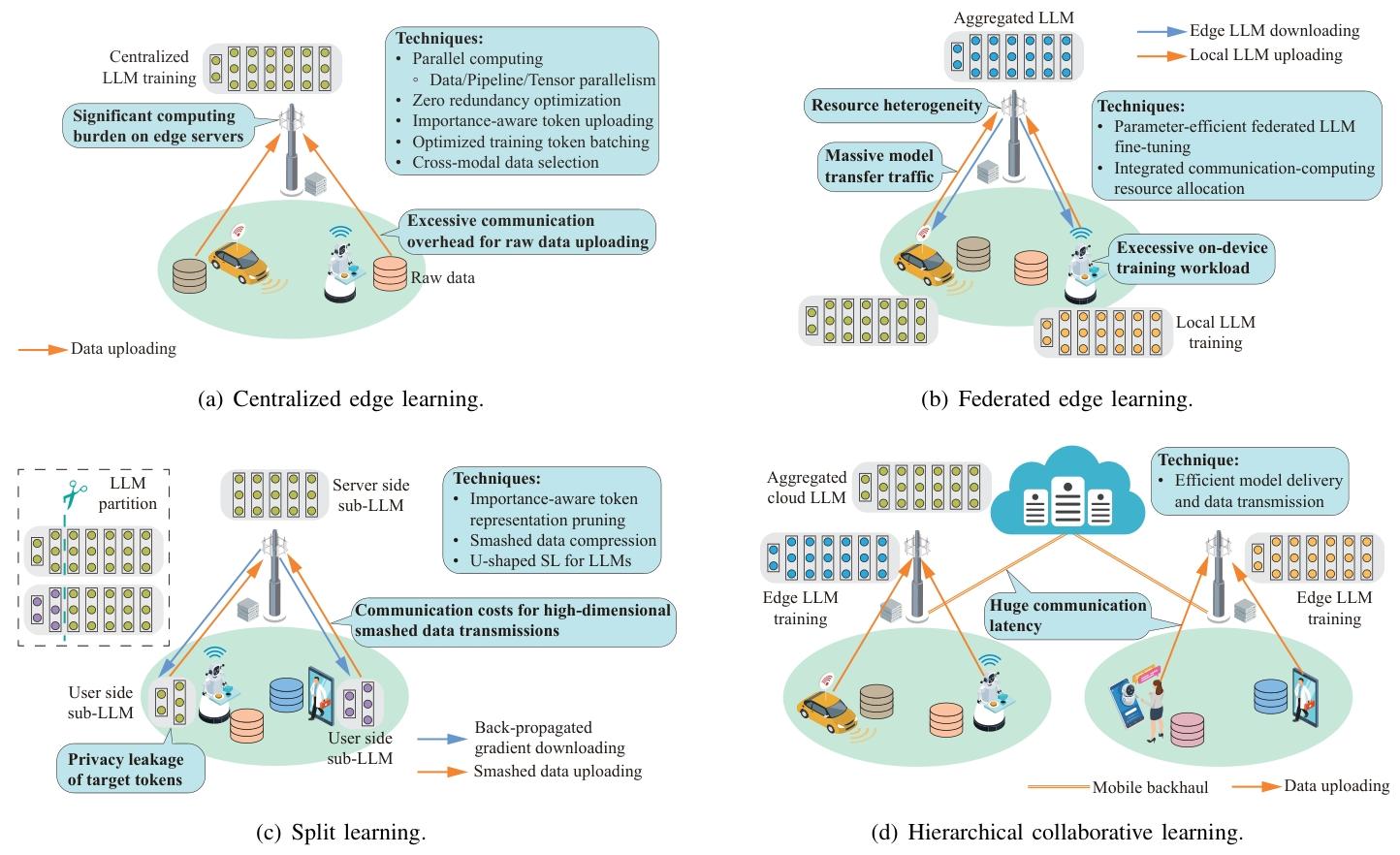
训练框架 核心原理 优点 缺点 性能表现(典型案例) 集中式边缘学习 边缘设备上传数据至服务器,统一训练 训练效率高,适合数据非敏感场景 隐私风险高,上传海量多模态数据消耗带宽 用 12 个边缘服务器并行训练 LLaMA-2 7B,每轮迭代 latency 降低至 80s [216] 联邦学习(FL) 设备本地训练,仅上传模型更新,服务器聚合 保护数据隐私,适配分布式数据场景 通信成本高,设备异构性导致训练不稳定 联邦 LoRA 微调 LLaMA-13B,通信量减少 99%,精度损失 <3% [218] 拆分学习(SL) 模型拆分为设备端和服务器端子模型,通过中间特征交互训练 避免原始数据上传,平衡隐私与计算效率 中间特征传输仍可能泄露隐私,拆分点选择影响性能 拆分 GPT-3 在医疗数据上训练,隐私泄露风险降低 70%,精度保持 95% [225] 分层协同学习 云 - 边缘 - 设备三级协同,边缘聚合本地模型,云端聚合全局知识 兼顾全局泛化与本地适配,支持大规模部署 架构复杂,跨层通信延迟高 自动驾驶场景中,分层训练使模型适配不同区域路况,精度提升 15% [228] - 联邦学习:边缘设备本地训练,仅上传模型更新,保护数据隐私(如 FedLoRA);
- 拆分学习:将模型拆分为设备端和服务器端子模型,通过中间特征交互协同训练,减少原始数据传输;
- 分层协同学习:结合云、边缘、设备三级资源,平衡全局知识与本地适配。
- 推理框架:
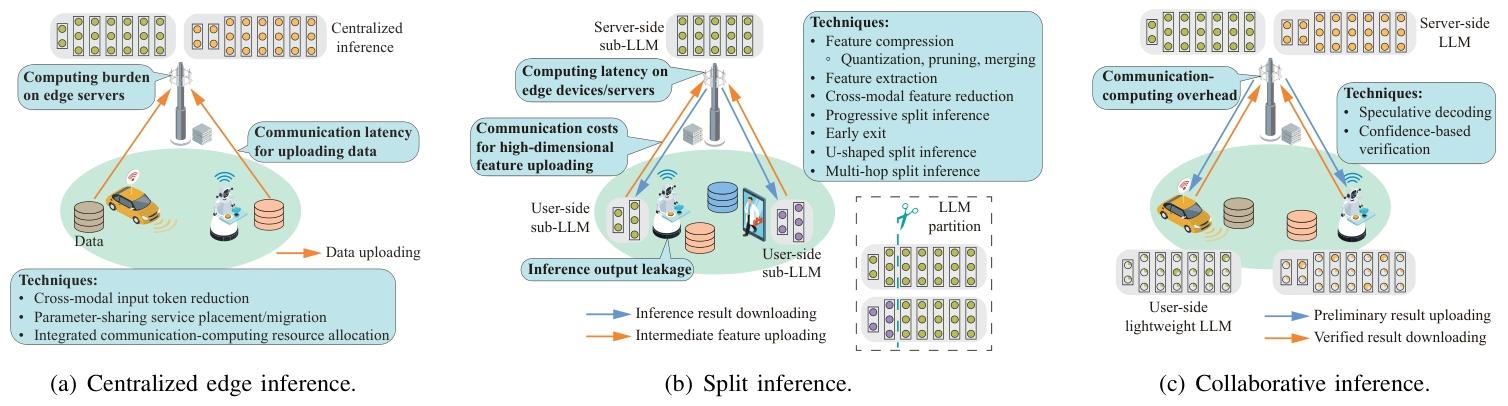
推理框架 核心原理 优点 缺点 性能表现(典型案例) ** 集中式推理 设备上传数据至边缘服务器,由服务器执行完整推理 利用服务器强算力,支持大模型 隐私风险高,上传多模态数据带宽消耗大 边缘服务器部署 Llama2-70B,推理延迟比云端低 60% [24] ** 拆分推理 设备处理底层网络,服务器处理高层网络,通过中间特征交互 减少原始数据传输,平衡隐私与延迟 特征传输仍占带宽,拆分点需优化 拆分 GPT-4 在自动驾驶场景中,延迟降至 50ms,带宽消耗减少 40% [277] ** 协同推理 设备用轻量模型生成初步结果,服务器用大模型验证修正 设备端快速响应,服务器保证精度 验证错误可能导致返工,需协调设备与服务器模型 虚拟助手场景中,协同推理使响应延迟 <100ms,准确率达 92% [278] - 集中式推理:边缘服务器统一处理,适用于非敏感数据;
- 拆分推理:设备处理部分层并上传中间特征,服务器完成剩余计算,平衡隐私与延迟;
- 协同推理:设备用轻量模型生成初步结果,服务器用大模型验证,提升效率(如投机解码)。
- 训练框架:
二、未来研究方向
-
绿色边缘 LLM:聚焦降低边缘 LLM 训练和推理的能耗,通过优化算法(如基于零阶优化器减少内存消耗)、硬件创新(如三星的 PIM 和 PNM 技术提升内存带宽与容量同时降低能耗),适配电池供电的边缘设备,满足可持续发展需求 。
-
安全边缘 LLM:抵御隐私攻击(如防止通过中间特征恢复原始数据)、对抗攻击(如数据投毒),保障 LLM 在边缘安全运行。研究安全聚合协议、加密机制,确保联邦学习中模型更新安全传输;开发鲁棒训练算法,提升模型抗攻击能力 。
-
质量感知的边缘 LLM 训练:在边缘数据质量参差不齐的情况下,实现数据质量控制。研究数据筛选、增强技术,结合边缘设备数据特性优化训练过程,如利用分层协同学习框架,在不同层次对数据质量进行评估与处理,提升模型泛化性和准确性 。
三、难点
-
通信瓶颈:现有研究多关注计算效率,忽视通信对 LLM 训练、推理、缓存及分发的影响。在移动边缘网络中,多模态数据上传下载、中间特征传输消耗大量带宽,制约 LLM 性能,需设计通信高效的边缘架构与协议 。
-
模型与网络协同优化:当前 LLM 资源高效技术与无线边缘网络相互作用研究不足。如参数高效微调、分割推理等技术在复杂网络环境下性能不稳定,需联合优化模型部署与网络资源分配 。
-
边缘设备异构性:边缘设备在计算、内存、存储能力上差异大,难以统一适配 LLM。需开发自适应技术,根据设备能力动态调整模型配置、训练推理策略,保障不同设备上 LLM 的可用性与性能 。