MLP-Mixer: An all-MLP Architecture for Vision
Google Research
纯MLP视觉模型
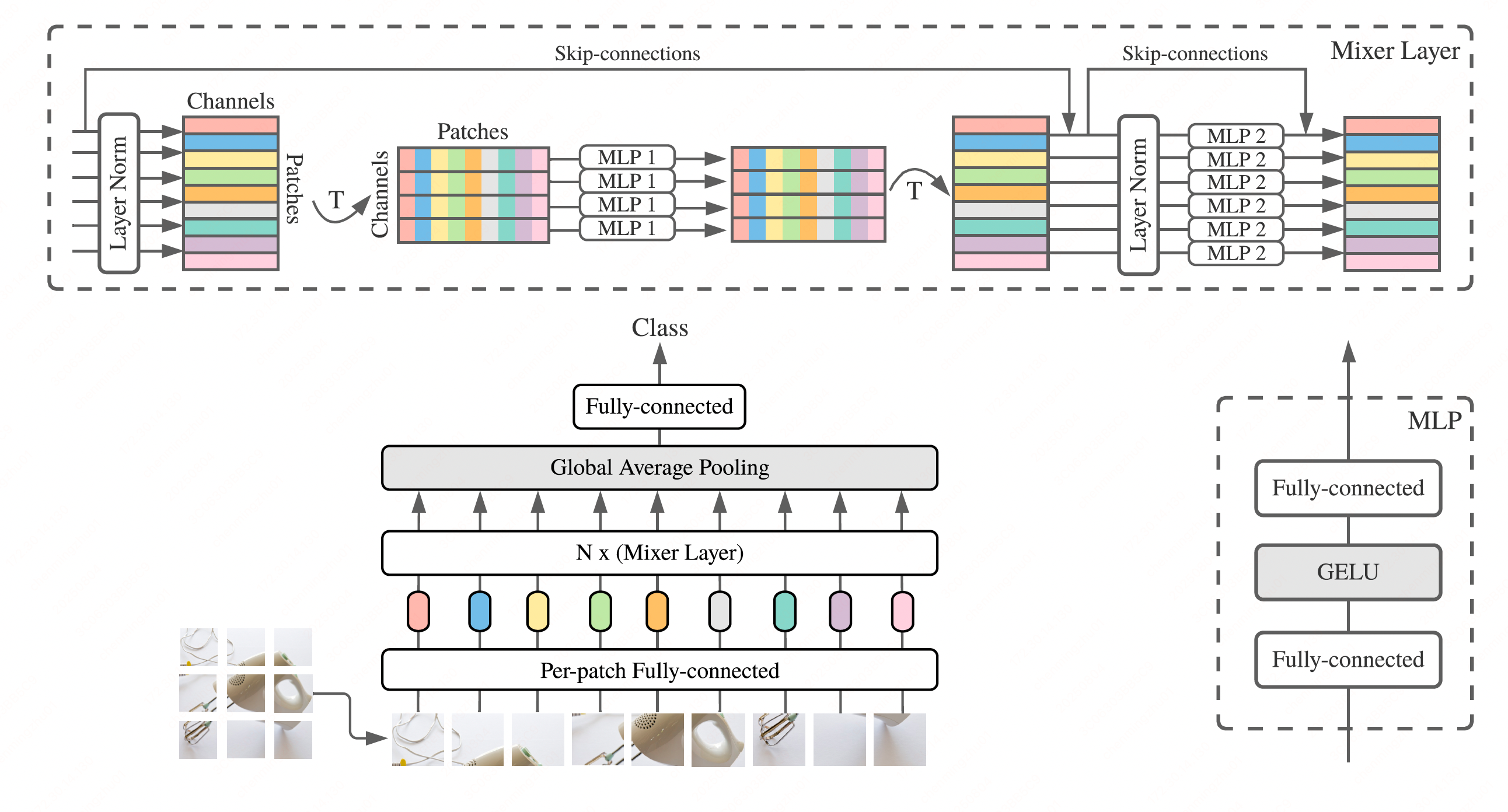
模型组成
- patch生成embedding(per-patch linear embedding)
- 多个MLP layer
- 2种layer:
- patch维度(token-mixing),每层处理单个patch
- 通道维度(channel-mixing),每层按通道处理多个patch
- 2种layer交替组织
- layer内部:
- 2个全连接层 + 1个GELU(nonlinearity activation)
- 宽度参数:D:D_S, D_C
- Others:skip connection,dropout,layerNorm
- 2种layer:
- 分类头
特殊情况
将mixers视为一种特殊的CNN,对应:
- channel mixing:1*1 conv
- token mixing:single channel depth-wise conv with full receptive field
❌ 不能反之亦然:
- 普通的CNN不是特殊情况的Mixer
- conv比MLP的矩阵乘更复杂,需要额外的reduction(?)、特殊实现(specialized implementation)
前向步骤
- 将图像处理成S个non-overlapping image patches,每patch生成C维embedding
- 输出记为 X
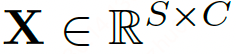
- 例如:输入图像大小(H,W),patch大小(P,P)patch数量S=(HW/P^2)
- 所有patch使用同一个matrix线性映射
- MLP层处理:
- token-mixing MLP:X转置(C*S),S维度上处理
- channel-mixing MLP:C维度上处理

- σ:GELU
features
parameter tying
1. 避免网络参数量随着隐藏层维度C、序列长度S的增加,随之的过快增长,从而节省内存
2. 不会影响效果
Mixer每层输入size不变
固定宽度,类似transformer、RNN,不像CNN通常是金字塔形状
不使用位置编码
和vit不同;因为token-mixing MLP对token顺序本身敏感
关注效果
- 下游任务精度
- 预训练计算量
- 推理耗时