Patsy的dmatrix() 函数
详细解释与用法:from patsy import dmatrix
1. Patsy 库简介
Patsy 是一个 Python 库,主要用于统计建模中的数据预处理,特别是在回归分析、方差分析(ANOVA)等统计模型中。它的核心功能是将公式字符串(如 y ~ x1 + x2)转换为数值矩阵,以便机器学习或统计模型(如 statsmodels、scikit-learn)可以直接使用。
2. dmatrix() 函数的作用
dmatrix() 是 Patsy 的核心函数,用于根据给定的公式字符串创建设计矩阵(design matrix)。它可以:
- 自动处理分类变量(如
fruit列中的"apple"、"pear"等,转换为数值型) - 支持变量转换(如标准化
standardize()、中心化center()) - 创建交互项、多项式项(如
x1:x2或x1**2)
3. 题目解析
题目要求:
- 对
storage列进行标准化(standardize):- 标准化 =
(x - 均值) / 标准差,使数据均值为 0,标准差为 1。
- 标准化 =
- 对
amount列进行中心化(center):- 中心化 =
(x - 均值),使数据均值为 0,但保持原始尺度。
- 中心化 =
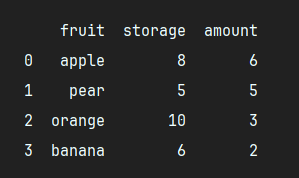
给定的数据表 fruits:
| fruit | storage | amount | |
|---|---|---|---|
| 0 | apple | 8 | 6 |
| 1 | pear | 5 | 5 |
| 2 | orange | 10 | 3 |
| 3 | banana | 6 | 2 |
4. 代码解析
import patsy
design_matrix = patsy.dmatrix('standardize(storage) + center(amount)', df)- 第一个参数
'standardize(storage) + center(amount)':standardize(storage):对storage列进行标准化。center(amount):对amount列进行中心化。+表示将两列合并为一个设计矩阵。
- 第二个参数
fruits:- 传入的数据表(Pandas DataFrame 或类似结构)。
5. 执行结果(示例)
假设 fruits 是一个 Pandas DataFrame,运行上述代码后,dmatrix() 会返回一个设计矩阵,类似:
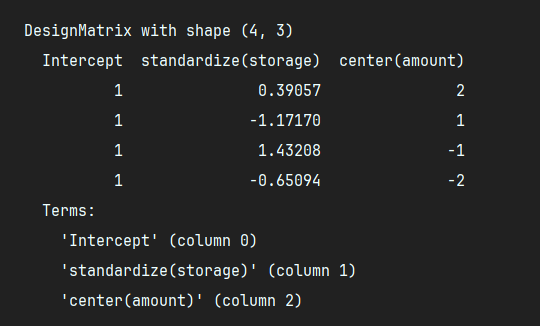
计算过程:
-
standardize(storage):- 均值 =
(8 + 5 + 10 + 6) / 4 = 7.25 - 标准差 ≈ 1.92
- 标准化后的
storage:(8 - 7.25) / 1.92 ≈ 0.2182(5 - 7.25) / 1.92 ≈ -1.0911(10 - 7.25) / 1.92 ≈ 1.5276(6 - 7.25) / 1.92 ≈ -0.6547
- 均值 =
-
center(amount):- 均值 =
(6 + 5 + 3 + 2) / 4 = 4 - 中心化后的
amount:6 - 4 = 25 - 4 = 13 - 4 = -12 - 4 = -2
- 均值 =
6. 实际应用场景
dmatrix() 常用于:
- 回归分析(如
statsmodels的OLS):import statsmodels.api as sm model = sm.OLS(y, dmatrix('x1 + x2', data)).fit() - 机器学习特征工程(如
scikit-learn的预处理):X = dmatrix('standardize(age) + center(income)', customers) - 方差分析(ANOVA):
dmatrix('C(group) + treatment', experiment_data)
